目录
前言
一、MySQL日志管理
1、存放日志和数据文件的目录
2、日志的分类
2.1 错误日志
2.2 通用查询日志
2.3 二进制日志
2.4 慢查询日志
2.5 中继日志
3、日志综合配置
4、查询日志是否开启
二、数据备份概述
1、数据备份的重要性
2、备份类型
2.1 从物理与逻辑角度分类
2.2 从数据库的备份策略角度分类
3、数据备份方法
3.1 物理冷备份
3.2 专用备份工具 mysqldump 或 mysqlhotcopy
3.3 通过启用二进制日志进行增量备份
3.4 通过第三方工具备份
三、数据完全备份与恢复
1、物理冷备份与恢复
2、mysqldump备份与恢复
2.1 mysqldump温备份
2.2 恢复数据库
2.3 恢复表
2.4 使用mysqldump备份加不加--databases的区别
2.5 建立计划任务
四、数据增量备份与恢复
1、增量备份
1.1 开启二进制日志功能
1.2 二进制日志(binlog)记录格式
1.3 查看二进制日志文件
1.4 备份操作
2、数据增量恢复
2.1 一般恢复
2.1.1 重定向恢复
2.1.2 二进制日志恢复
2.2 基于位置恢复
2.3 基于时间点恢复
五、总结
1、物理冷备份
2、逻辑热备份
3、完全恢复
4、增量备份
前言
在生产环境中,数据的安全性至关重要,任何数据的丢失都可能产生严重的后果,那么对于数据的备份就将显的十分重要。对于MySQL而言,在其备份中,日志起到了很重要的作用
一、MySQL日志管理
1、存放日志和数据文件的目录
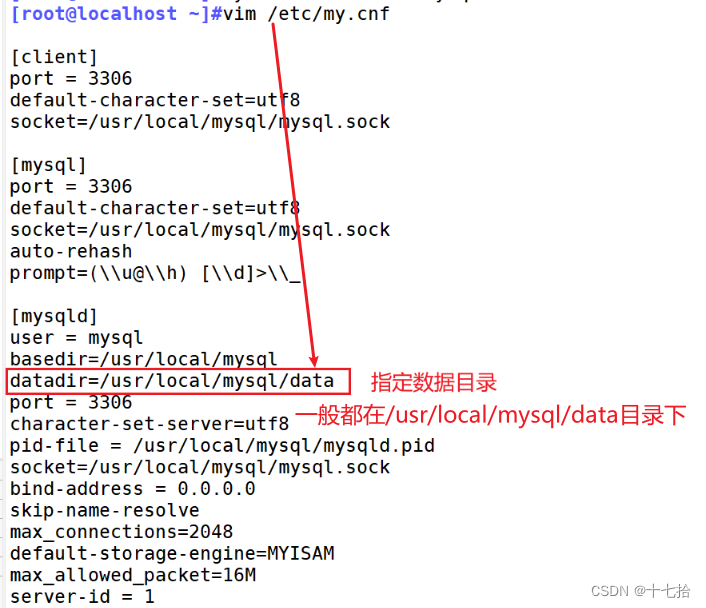
- mysql的日志默认的保存位置为/usr/local/mysql/data
- MYSQL的主配置文件为/etc/my.cnf ,在其中的【mysqld】项里指定日志存放的位置
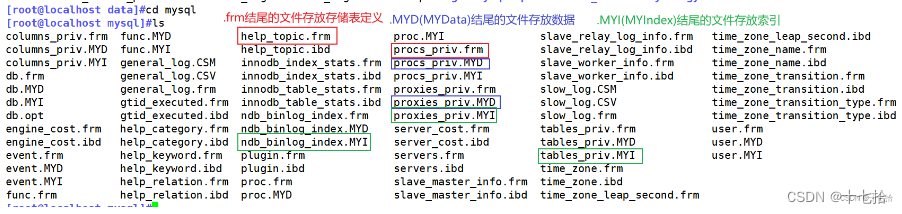
- MySQL数据库的数据文件存放在/usr/local/mysql/data目录下,每个数据库对应一个子目录,用于存储数据表文件。每个数据表对应为三个文件,分别为表结构定义文件(.frm)、数据文件(.MYD)和索引文件(.MYI)
![]()
2、日志的分类
2.1 错误日志
用来记录当mysql启动、停止或运行时发生的错误信息,默认已开启
[mysqld]
log-error=/usr/local/mysql/data/mysql_error.log 2.2 通用查询日志
用来记录MySQL的所有连接和语句,默认是关闭的
[mysqld]
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log2.3 二进制日志
用来记录所有更新了数据或者已经潜在更新了数据的语句,记录了数据的更改,可用于数据恢复,默认已开启
[mysqld]
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log2.4 慢查询日志
用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,以便于优化,默认是关闭的
[mysqld]
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5 #单位时间为s,缺省时为10s慢查询日志也可用来查询哪些搜索的字段超时,可以选择是否需要增加索引,加快查询速度
2.5 中继日志
一般情况下,它在MySQL主从同步(复制)、读写分离集群的从节点开启,主节点一般不需要这个日志
3、日志综合配置
修改MYSQL的主配置文件为/etc/my.cnf ,并在其中的【mysqld】项里指定日志存放的位置,然后保存配置,重启mysqld服务
[root@localhost ~]#vim /etc/my.cnf[mysqld]
#错误日志
log-error=/usr/local/mysql/data/mysql_error.log
#通用查询日志
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
#二进制日志
log-bin=mysql-bin
#慢查询日志
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5[root@localhost ~]#systemctl restart mysql #配置文件添加完后需要重启MySQL

4、查询日志是否开启
show variables like 'general%'; #查看通用查询日志是否开启
show variables like 'log_bin%'; #查看二进制日志是否开启
show variables like '%slow%'; #查看慢查询日功能是否开启
show variables like 'long_query_time'; #查看慢查询时间设置
set global slow_query_log=ON; #在数据库中设置开启慢查询的方法

二、数据备份概述
MySQL数据库中的数据备份是一种重要的数据保护策略,用于防止数据丢失、损坏或其他灾难性事件。备份可以帮助在数据遭受损害或丢失时恢复到之前的状态
1、数据备份的重要性
在企业中,数据的价值至关重要,数据保障了企业业务的正常运行。因此,数据的安全性及数据的可靠性是运维的重中之重,任何数据的吊事都可能对企业产生严重的后果
数据丢失可以由多种原因引起,包括但不限于:
- 人为错误:不小心删除数据或执行错误的数据库命令是数据丢失的常见原因
- 硬件故障:硬盘驱动器损坏、电源故障或其他硬件问题可能导致数据不可访问或丢失
- 软件故障:数据库软件或操作系统中的缺陷可能导致数据损坏
- 病毒和恶意软件:攻击者可能通过病毒、勒索软件或其他恶意软件破坏或加密数据,使其不可用
- 自然灾害:火灾、洪水、地震等自然灾害可能导致物理设备损坏,从而导致数据丢失
- 网络攻击:SQL注入、DDoS攻击等网络安全威胁可能导致数据泄露或丢失
备份可以在数据丢失、损坏或其他不可预见事件发生时,提供一种恢复数据的手段,从而减少业务中断的时间和损失的程度
- 数据恢复:在数据不慎被删除或损坏时,备份是恢复数据的唯一途径
- 灾难恢复:自然灾害、硬件故障或网络攻击等事件可能导致数据中心损坏,备份数据可以帮助快速恢复业务
- 数据分析和报告:备份可以用于创建数据的非生产副本,供进行数据分析和生成报告,而不影响生产环境的性能
- 法规遵从:许多行业标准和法律法规要求企业必须定期备份并保留数据副本,以确保数据的完整性和可审计性
- 业务连续性:在面对数据丢失的情况下,备份确保业务能够继续运行,减少对客户服务和公司声誉的影响
2、备份类型
2.1 从物理与逻辑角度分类
从物理与逻辑角度分类,数据库备份可以分为物理备份和逻辑备份
- 物理备份
物理备份是对数据库操作系统的物理文件(如数据文件、日志文件等)的备份。这种类型的备份适用于在出现问题的时候需要快速恢复的大型重要数据库
物理备份又可以成为冷备份(脱机备份)、热备份(连接备份)和温备份
① 冷备份 (脱机备份) :是在关闭数据库的时候进行的(tar)
② 热备份 (联机备份) :数据库处于运行状态,依赖于数据库的日志文件(mysqlhotcopy mysqlbackup)
③ 温备份 :数据库锁定表格(不可写入但可读)的状态下进行备份操作(mysqldump)
- 逻辑备份
逻辑备份:对数据库逻辑组件的备份,表示为逻辑数据库结构,这种类型的备份适用于可以编辑数据值或表结构
2.2 从数据库的备份策略角度分类
从数据库的备份策略角度,数据库的备份可分为完全备份、差异备份和增量备份。
-
完全备份:每次对数据进行完整的备份,即对整个数据库、数据库结构和文件结构的备份,保存的是备份完成时刻的数据库,是差异备份与增量备份的基础。完全备份的备份与恢复操作都非常简单方便,但是数据存在大量的重复,并且会占用大量的磁盘空间,备份的时间也很长

-
差异备份:备份那些自从上次完全备份之后被修改过的所有文件,备份的时间节点是从上次完整备份起,备份数据量会越来越大。恢复数据时,只需恢复上次的完全备份与最近的一次差异备份

-
增量备份:只有那些在上次完全备份或者增量备份后被修改的文件才会被备份。以上次完整备份或上次增量备份的时间为时间点,仅备份这之间的数据变化,因而备份的数据量小,占用空间小,备份速度快。但恢复时,需要从上一次的完整备份开始到最后一次增量备份之的所有增量依次恢复,如中间某次的备份数据损坏,将导致数据的丢失

备份方式比较:
| 操作/备份方式 | 完全备份 | 差异备份 | 增量备份 |
|---|---|---|---|
| 完全备份时的状态 | 表1 | 表1 | 表1 |
| 第1次添加内容 | 创建表2 | 创建表2 | 创建表2 |
| 备份内容 | 表1、表2 | 表2 | 表2 |
| 第2次添加内容 | 创建表3 | 创建表3 | 创建表3 |
| 备份内容 | 表1、表2、表3 | 表2、表3 | 表3 |
| …… | …… | …… | …… |
| 占用额外空间 | 大 | 有一定占用 | 不占用 |
| 备份速度 | 刚开始快,后面会变慢 | 比完全备份快 | 最快 |
| 恢复速度 | 最快 | 比完全备份慢 | 最慢 |
3、数据备份方法
数据库的备份可以采用很多种方式,如直接打包数据库文件(物理冷备份)、专用备份工具(mysqldump)、二进制日志增量备份、第三方工具备份等
3.1 物理冷备份
- 物理冷备份时需要在数据库处于关闭状态下,能够较好地保证数据库的完整性
- 物理冷备份一般用于非核心业务,这类业务一般都允许中断
- 物理冷备份的特点就是速度快,恢复时也是最为简单的
- 通常通过直接打包数据库文件夹(/usr/local/mysql/data)来实现备份
3.2 专用备份工具 mysqldump 或 mysqlhotcopy
- mysqldump程序和mysqlhotcopy都可以做备份
- mysqldump是客户端常用逻辑备份程序,能够产生一组被执行以后再现原始数据库对象定义和表数据的SQL语句。它可以转储一个到多个MySQL数据库,对其进行备份或传输到远程SQL服务器。mysqldump更为通用,因为它可以备份各种表
- mysqlhotcopy仅适用于某些存储引擎(MyISAM和ARCHIVE)
3.3 通过启用二进制日志进行增量备份
- 支持增量备份,进行增量备份时必须启用二进制日志
- 二进制日志文件为用户提供复制,对执行备份点后进行的数据库更改所需的信息进行恢复
- 如果进行增量备份(包含自上次完全备份或增量备份以来发生的数据修改) ,需要刷新二进制日志
3.4 通过第三方工具备份
第三方工具Percona xtraBackup是一个免费的MysQL热备份软件,支持在线热备份Innodb和xtraDB,也可以支持MySQL表备份,不过MyISAM表的备份要在表锁的情况下进行
三、数据完全备份与恢复
1、物理冷备份与恢复
大概步骤:
①关闭MySQL数据库
②使用tar命令直接打包数据库文件夹
③直接替换现有MySQL目录即可
详细步骤:
(1)关闭MySQL数据库,使用tar命令直接打包数据库文件夹
#关闭mysql数据库
[root@localhost ~]#systemctl stop mysqld
[root@localhost ~]#yum -y install xz
#压缩备份
[root@localhost ~]#cd /usr/local/mysql/data
[root@localhost data]#tar /opt/jcvf mysql_all_$(date +%F).tar.xz /usr/local/mysql/data
[root@localhost data]#ls /opt
[root@localhost data]#systemctl start mysqld
(2)模拟数据丢失,删除数据库
#模拟数据丢失,删除数据库
[root@localhost data]#mysql -uroot -p123456 -e "drop database xgy;"
(3)解压恢复,直接替换现有MySQL目录
#解压恢复
[root@localhost data]#tar jxvf /opt/mysql_all_2022-06-21.tar.xz -C /usr/local/mysql/data
[root@localhost data]#cd /usr/local/mysql/data
[root@localhost data]#mv usr/local/mysql/data/* ./
(4)数据库恢复

2、mysqldump备份与恢复
大概步骤:
①MySQL自带的备份工具,可方便实现对MySQL的备份
②可以将指定的库、表导出为SQL 脚本
③使用命令mysq|导入备份的数据
2.1 mysqldump温备份
(1) 完全备份一个或多个完整的库 (包括其中所有的表)
mysqldump -u 用户名 -p 密码 --databases 库名1 [库名2] ... > /备份路径/备份文件名.sql
#导出的就是数据库脚本文件
#如:
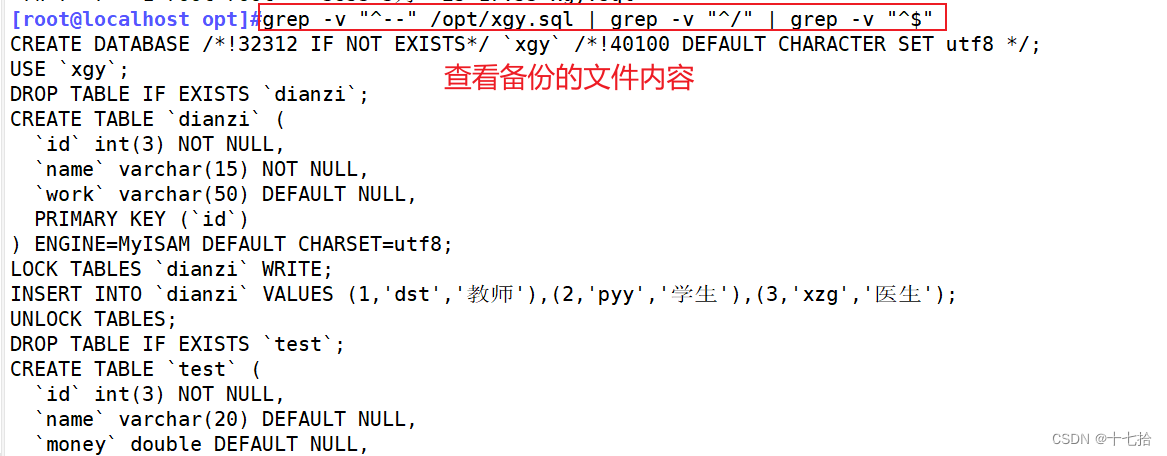
mysqldump -uroot -p123456 --databases xgy > /opt/xgy.sql #备份一个xgy库
mysqldump -uroot -p123456 --databases mysql xgy > /opt/mysql-xgy.sql #备份mysql与xgy两个库
grep -v "^--" /opt/xgy.sql | grep -v "^/" | grep -v "^$"
#查看备份的文件内容
(2) 完全备份 MySQL 服务器中所有的库
mysqldump -u 用户名 -p 密码 --all-databases > /备份路径/备份文件名.sql
#如:
mysqldump -uroot -p123456 --all-databases > /opt/all.sql
(3) 完全备份指定库中的部分表
mysqldump -u 用户名 -p 密码 库名 [表名1] [表名2] ... > /备份路径/备份文件名.sql
#如:
mysqldump -u root -p123456 [-d] xgy dianzi tongxin > /opt/xgy_dt.sql
#使用“-d”选项,说明只保存数据库的表结构;不使用“-d"选项,说明表数据也进行备份
#查看保留表结构和表数据的备份文件内容
grep -v "^--" /opt/xgy_dt.sql | grep -v "^/" | grep -v "^$"
#查看只保留表结构的备份文件内容
grep -v "^--" /opt/xgy_jiegou.sql | grep -v "^/" | grep -v "^$"
2.2 恢复数据库
方法一:source恢复
#使用mysqldump导出的文件,可使用导入的方法:进入数据库,使用source命令导入数据库备份文件
source /opt/xgy.sql #登录到MySQL数据库,执行source备份sql脚本的路径(1)模拟丢失数据,删除xgy数据库
1010报错解决方法:


(2) 登录到MySQL数据库,执行source恢复

方法二:mysql命令恢复
mysql -u 用户名 -p 密码 < xxx.sql #恢复整个库mysql -uroot -p123456 < /opt/xgy.sql(1)模拟丢失数据,删除xgy数据库
(2) 无须登录到MySQL数据库,使用mysql命令恢复

2.3 恢复表
方法一:source恢复
#使用mysqldump导出的文件,可使用导入的方法:进入数据库,使用source命令导入数据表备份文件
use xgy; #登录到MySQL数据库并进入指定的xgy数据库,执行source备份sql脚本的路径
source /opt/xgy_dt.sql (1)模拟丢失数据,删除备份过的两个数据表

(2)登录到MySQL数据库,执行source恢复


方法二:mysql命令恢复
mysql -u 用户名 -p 密码 库名 < xxx.sql #恢复指定数据库中的表mysql -uroot -p123456 xgy < /opt/xgy_dt.sql(1)模拟丢失数据,删除备份过的两个数据表
(2)无须登录到MySQL数据库,使用mysql命令恢复
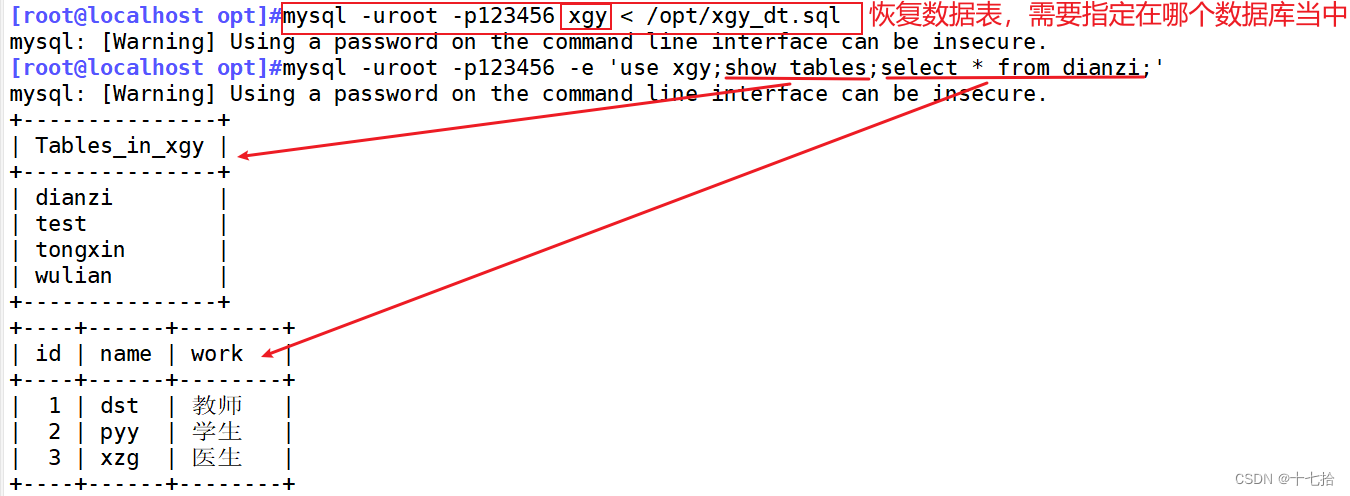
2.4 使用mysqldump备份加不加--databases的区别
mysqldump严格来说属于温备份,会需要对表进行写入的锁定
在全量备份与恢复实验中,假设现有xgy库,xgy库中有一个dianzi表,需要注意的一点为:
①当备份时加 --databases,表示针对于xgy整个库(包括库下的所有表)
#备份命令
mysqldump -uroot -p123456 --databases xgy > /opt/xgy_1.sql#模拟丢失数据,删除xgy数据库
mysql -uroot -p123456 -e 'drop database xgy;'
mysql -uroot -p123456 -e "show databases;"#使用mysql恢复命令
mysql -uroot -p123456 < /opt/xgy_1.sql


②当备份时不加 --databases,表示针对xgy库下的所有表(不包括xgy库,所以导入数据时,需要先建库)
#当备份时不加 --databases,表示针对school库下的所有表#备份命令
mysqldump -uroot -p123456 xgy > /opt/xgy_2.sql#登录到mysql数据库中,模拟删除xgy数据库
mysql -uroot -p123456
drop database xgy;#恢复过程
source /opt/xgy_2.sql #会报错:没有数据库去选择
create database xgy;
use xgy;
source /opt/xgy_2.sql #建完数据库后再恢复数据,就不会报错





2.5 建立计划任务
[root@localhost ~]#crontab -e
0 2 * * 0 /usr/local/mysql/bin/mysqldump -uroot -p'123456' xgy dianzi tongxin > /opt/class_all_$(date +%Y%m%d).sql;/usr/local/mysql/bin/mysqladmin -u root -p flush-logs
#每周日凌晨2点,使用mysqldump工具备份MySQL数据库school中的class class1表的数据,并将备份数据保存到/opt/目录下的scholl_classall_$(date +%Y%m%d).sql文件中,然后使用mysqladmin工具刷新MySQL的日志
[root@localhost ~]#crontab -r
#删除计划任务四、数据增量备份与恢复
1、增量备份
MySQL的增量备份通常使用二进制日志(binary log)来实现。二进制日志是MySQL的一种日志,它记录了所有对数据库的更改操作,包括插入、更新、删除等操作
1.1 开启二进制日志功能
修改MYSQL的主配置文件为/etc/my.cnf ,并在其中的【mysqld】项里指定日志存放的位置,然后保存配置,重启mysqld服务
[root@localhost ~]#vim /etc/my.cnf[mysqld]
#错误日志
log-error=/usr/local/mysql/data/mysql_error.log
#通用查询日志
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
#二进制日志
log-bin=mysql-bin
#慢查询日志
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5[root@localhost ~]#systemctl restart mysql #配置文件添加完后需要重启MySQL1.2 二进制日志(binlog)记录格式
二进制日志(binlog)有3种不同的记录格式: STATEMENT (基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT
- STATEMENT(基于SQL语句):每一条涉及到被修改的sql 都会记录在binlog中
缺点:日志量过大,如sleep()函数,last_insert_id()>,以及user-defined fuctions(udf)、主从复制等架构记录日志时会出现问题
- ROW(基于行):只记录变动的记录,不记录sql的上下文环境
缺点:如果遇到update......set....where true 那么binlog的数据量会越来越大
- MIXED(推荐使用):会根据SQL语句的类型来选择使用Statement格式还是Row格式
缺点:可能会因为SQL语句的类型而导致日志文件的大小和恢复的准确性有所不同
1.3 查看二进制日志文件
mysqlbinlog --no-defaults --base64-output=decode-rows -v /usr/local/mysql/data/mysql-bin.000001
# --base64-output=decode-rows:使用64位编码机制去解码(decode)并按行读取(rows)
# -v: 显示详细内容
# --no-defaults : 默认字符集(不加会报UTF-8的错误)
二进制日志中需要关注的部分:
- at :开始的位置点
- end_log_pos:结束的位置
- 时间戳: 240325 18:01:18
- SQL语句
1.4 备份操作
(1)部署环境
#新建库和表
create database school;
use school;
create table class (id char(5) not null primary key,name varchar(15) not null,work varchar(50) not null);#在新建的表中插入数据
insert into class values (1,'cxl','老师');
insert into class values (2,'kys','学生');
select * from class;
(2)进行完全备份
mysqldump -uroot -p123456 school class > /opt/school_class_$(date +%F).sql
(3)生成新的二进制日志文件
[root@localhost ~]#cd /usr/local/mysql/data/
[root@localhost data]#mysqladmin -u root -p123456 flush-logs
[root@localhost data]#cp mysql-bin.000001 /mnt/
2、数据增量恢复
2.1 一般恢复
2.1.1 重定向恢复
mysql -u root -p123456 school < /opt/school_class_2024-03-25.sql(1)模拟丢失数据,删除表

(2) 将备份文件重定向数据库,恢复数据

2.1.2 二进制日志恢复
mysqlbinlog --no-defaults /mnt/mysql-bin.000001 | mysql -u root -p123456(1)模拟丢失数据,删除库(日志文件里有创建库的动作,避免冲突)

(2) 基于二进制日志文件:mysql-bin.000001,恢复数据

2.2 基于位置恢复
- 数据库在某一时间点可能既有错误的操作也有正确的操作
- 可以基于精准的位置跳过错误的操作
- 发生错误节点之前的一个节点,上一次正确操作的位置点停止
mysqlbinlog --no-defaults --start-position='操作ID1' --stop-position='操作ID2' 二进制日志文件 | mysql -u 用户名 -p 密码要求:实现目标:class 表中5条数据,1、2条记录在mysql-bin.000001日志,3-5条记录在mysql-bin.000001日志,模拟第4条数据操作故障,实现跳过第4条断点恢复
(1)插入第3~5条数据
insert into class values (3,'zzd','学生');
insert into class values (4,'mii','学生');
insert into class values (5,'fsq','老师');
(2)备份二进制日志:mysql-bin.000002
[root@localhost data]#cp mysql-bin.000002 /mnt/
(3) 生成新的二进制日志,并删除 class 表
[root@localhost data]#mysqladmin -u root -p123456 flush-logs
[root@localhost data]#mysql -uroot -p123456 -e 'drop table school.class;'
(4)基于位置点恢复
查看mysql-bin.000001日志:mysql-bin.000001日志存放从建库到插入前两条数据
[root@localhost data]#mysqlbinlog --no-defaults --base64-output=decode-rows -v /mnt/mysql-bin.000001
恢复前两条数据:school 库未删除,恢复到操作 ID 为“384"之后的数据
[root@localhost data]#mysqlbinlog --no-defaults --start-position='384' /mnt/mysql-bin.000001 | mysql -uroot -p123456
查看mysql-bin.000002日志:
[root@localhost data]#mysqlbinlog --no-defaults --base64-output=decode-rows -v /mnt/mysql-bin.000002
恢复第三条数据:从操作 ID 为“4319"到操作 ID 为“4596”之间的数据
[root@localhost ~]#mysqlbinlog --no-defaults --start-position='4319' --stop-position='4596' /mnt/mysql-bin.000002 | mysql -uroot -p123456
查看mysql-bin.000002日志:
[root@localhost data]#mysqlbinlog --no-defaults --base64-output=decode-rows -v /mnt/mysql-bin.000002
恢复第五条数据:从操作 ID 为“4873"之后的数据
[root@localhost data]#mysqlbinlog --no-defaults --start-position='4873' /mnt/mysql-bin.000002 | mysql -uroot -p123456
2.3 基于时间点恢复
- 跳过某个发生错误的时间点实现数据恢复
- 在错误时间点停止,在下一个正确时间点开始
时间点恢复与断点恢复同理,只需要将 at 值改为对应的时间即可
mysqlbinlog [--no-defaults] --start-datetime='年-月-日 小时:分钟:秒' --stop-datetime='年-月-日小时:分钟:秒' 二进制日志 | mysql -u 用户名 -p 密码(1) 模拟数据丢失,删除 class 表

(2)基于时间点恢复
查看mysql-bin.000001日志:
[root@localhost data]#mysqlbinlog --no-defaults --base64-output=decode-rows -v /mnt/mysql-bin.000001
恢复前两条数据:school 库未删除,恢复到时间点为“2024-3-25 21:05:09"之后的数据
[root@localhost data]#mysqlbinlog --no-defaults --start-datetime='2024-3-25 21:05:09' /mnt/mysql-bin.000001 | mysql -uroot -p123456
#仅恢复到2024-3-25 21:05:09之后的数据
查看mysql-bin.000002日志:
[root@localhost data]#mysqlbinlog --no-defaults --base64-output=decode-rows -v /mnt/mysql-bin.000002
恢复第三条数据:从时间点为“2024-3-25 21:36:32"到时间点为“2024-3-25 21:36:48"之间的数据
[root@localhost data]#mysqlbinlog --no-defaults --start-datetime='2024-3-25 21:36:32' --stop-datetime='2024-3-25 21:36:48' /mnt/mysql-bin.000002 | mysql -uroot -p123456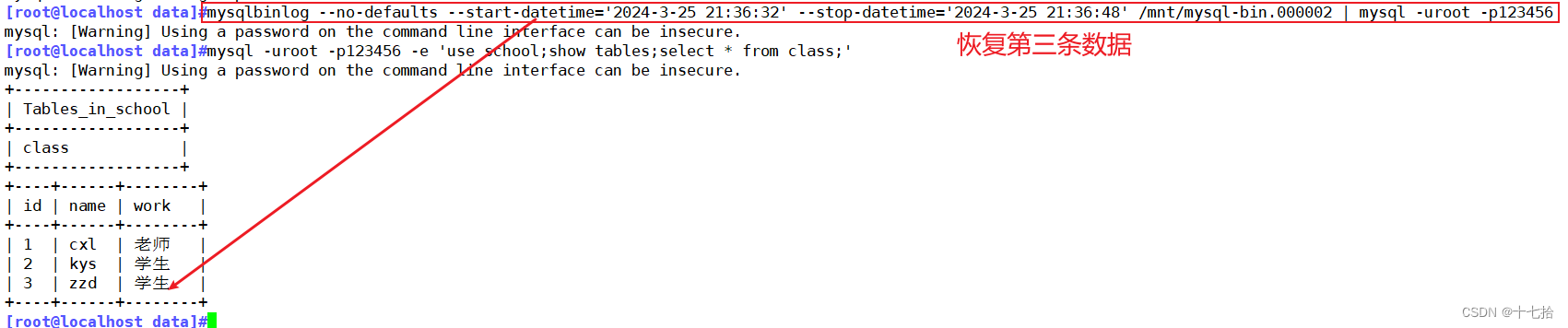
查看mysql-bin.000002日志:
[root@localhost data]#mysqlbinlog --no-defaults --base64-output=decode-rows -v /mnt/mysql-bin.000002 恢复第五条数据:从时间点为“2024-03-25 21:37:03”之后的数据
恢复第五条数据:从时间点为“2024-03-25 21:37:03”之后的数据
[root@localhost data]#mysqlbinlog --no-defaults --start-datetime='2024-03-25 21:37:03' /mnt/mysql-bin.000002 | mysql -uroot -p123456
#仅恢复到2024-03-25 21:37:03之后的数据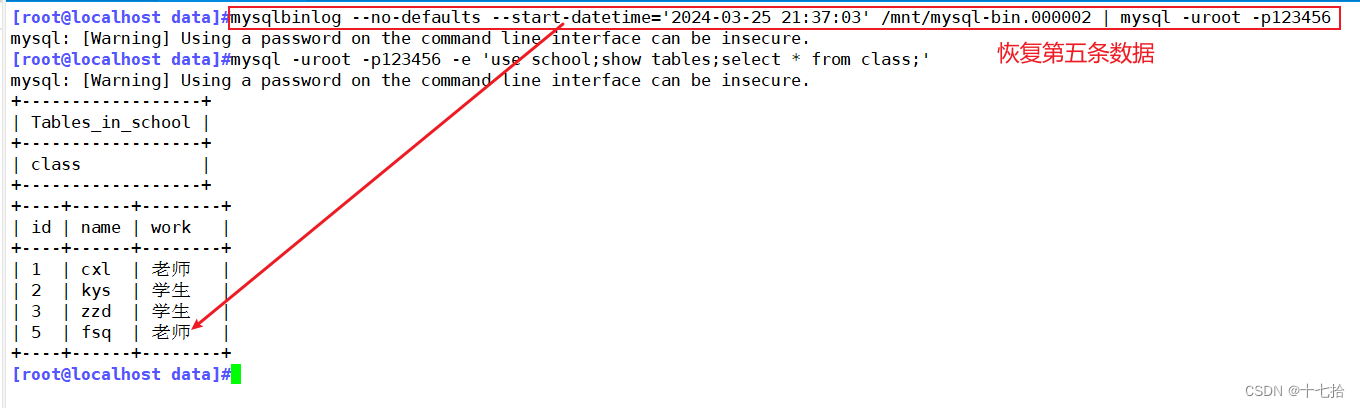
注:
- 如果恢复某条SQL语之前的所有数据,就stop在这个语句的位置节点或者时间点
- 如果恢复某条SQL语句以及之后的所有数据,就从这个语句的位置节点或者时间点start
五、总结
1、物理冷备份
- 关闭Mysqld服务
- 使用tar命令进行打包data目录
- 恢复直接解压即可
2、逻辑热备份
mysqldump -u 用户名 -p 密码 --database 备份库1,库2 > xxx.sql #备份多个数据库mysqldump -u 用户名 -p 密码 --all-database > xxx.sql #备份所有数据库mysql -u 用户名 -p 密码 库1,库2 表1,表2 > xxx.sql #备份多库多表3、完全恢复
mysql -u 用户名 -p 密码 < xxx.sql #恢复整个库mysql -u 用户名 -p 密码 库名 < xxx.sql #恢复指定数据库中的表4、增量备份
- 要先开启二进制日志,设置二进制格式为MIXED
- 进行一次完全备份,可每周备份一次,通过crontable -e 进行编辑
- mysqladmin -uroot -p flush-logs 刷新二进制日志文件,分割出新的二进制日志文件,由于刷新之前的数据都会记录在老的二进制文件里
- 可通过mysqlbinlog --no-defaults --base64-output=decode-rows -v 二进制文件名称 ,可查看日志内容
- 可通过mysqlbinlog --no-defaults 二进制日志文件名|mysql -u 用户名 -p 密码 ,来恢复丢失的数据库
位置恢复——position
- start:--start-position :恢复某条SQL语之后的所有数据
- stop:--stop-position :恢复某条SQL语之前的所有数据
- start、stop:--start-position --stop-position :恢复某条SQL语和某条SQL语之间的所有数据
时间恢复——datetime
- start:--start-datetime:恢复某条SQL语之后的所有数据
- stop:--stop-datetime :恢复某条SQL语之前的所有数据
- start、stop:--start-datetime --stop-datetime:恢复某条SQL语和某条SQL语之间的所有数据

![[flask]cookie的基本使用/](https://img-blog.csdnimg.cn/direct/53d9e47e4b91420187a59faa2ba89a8d.png)
![[音视频学习笔记]八、FFMpeg结构体分析 -上一个项目用到的数据结构简单解析:AVFrame、AVFormatContext、AVCodecContext](https://img-blog.csdn.net/20130914204051125?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvbGVpeGlhb2h1YTEwMjA=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)