PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。
第48讲:PG高可用实现
内容1:keepalived简介
内容2:Keepalived安装与配置
内容3:Keepalived&流复制实现高可用
内容4:主备切换技巧
PostgreSQL技术大讲堂 第48讲:PG高可用实现,
往期视频和文档,联系 ”CUUG“客服
keepalived简介
Keepalived是一个用C编写的路由软件。
keepalive起初专门为lvs负载均衡软件设计的,用来管理监控lvs集群系统中各个服务节点的状态,后来又加入了可以实现高可用的vrrp功能。
该项目的主要目标是为Linux系统和基于Linux的基础架构提供简单而强大的负载平衡和高可用性设施。 负载平衡框架依赖于众所周知且广泛使用的Linux虚拟服务器(IPVS)内核模块,提供Layer4负载均衡。
keepalived完全遵守VRRP协议,包括竞选机制等等,此外,Keepalived为VRRP有限状态机实现了一组挂钩,提供低级和高速协议交互。为了提供最快的网络故障检测,Keepalived实现了BFD协议。VRRP状态转换可以考虑BFD提示来驱动快速状态转换。Keepalived框架可以单独使用,也可以一起使用,以提供灵活的基础架构。
这个协议起先应用于网络,网络在设计的时候必须考虑到冗余容灾,包括线路冗余,设备冗余等,防止网络存在单点故障,那在路由器或三层交换机处实现冗余就显得尤为重要,在网络里面有个协议就是来做这事的,这个协议就是VRRP协议,Keepalived就是巧用VRRP协议来实现高可用性(HA)的。
其用IP组播的方式,实现服务节点间的通信, 通过一种竞选机制来将路由任务交给某台VRRP路由器. 工作时主节点广播发送VRRP协议报文, 备节点接收报文, 若一段时间(默认3个报文发送时间)备节点接收不到主节点发送的报文, 就会启动接管程序接管主节点的资源. 备节点可以有多个, 通过优先级竞选。
Keepalived组件进程

keepalived是模块化设计,不同模块复杂不同的功能,下面是keepalived的组件。
Control Plane:
Keepalived配置通过keepalived.conf文件完成。编译器设计用于解析。解析器使用关键字树层次结构来使用特定处理程序映射每个配置关键字。中央多级递归函数读取配置文件并遍历关键字树。在解析期间,配置文件被转换为内部存储器表示。
调度程序 - I / O多路复用器:
所有事件都安排在同一个进程中。Keepalived是一个单一的过程。
Keepalived是一种网络路由软件,它对I / O非常封闭。这里使用的设计是一个中央选择(...),负责安排所有内部任务。不使用POSIX线程库。该框架提供了自己的线程抽象,针对网络目的进行了优化。
Memory Mngt(内存管理):
该框架提供对一些通用内存管理功能的访问,例如分配,重新分配,发布......这个框架可以用于两种模式:normal_mode和debug_mode。
使用debug_mode时,它提供了一种消除和跟踪内存泄漏的强大方法。这个低级env通过跟踪分配内存并释放来提供缓冲区欠载保护。使用的所有缓冲区都是固定长度的,以防止最终的缓冲区溢出。
Core components(核心组件):
是keepalived的核心,复杂主进程的启动和维护,全局配置文件的加载解析等。
该框架定义了所有代码中使用的一些通用和全局库。这些库是:html解析,链接列表,计时器,向量,字符串格式化,缓冲区转储,网络工具,守护程序管理,pid处理,低级TCP层4。这里的目标是将代码分解为最大限度,以尽可能地代码重复以增加模块性。
WatchDog:
该框架提供子进程监控(VRRP和健康检查)。每个子进程都接受与其自己的监视器unix域套接字的连接。父进程向此子unix域套接字发送“hello”消息。Hello消息使用父端的I / O多路复用器发送,并使用子端的I / O多路复用器接收/处理。如果父检测到损坏的管道,则在子项仍然存活时使用sysV信号进行测试并重新启动它。
Checkers:
这是主要的Keepalived功能之一,Checkers负责realserver healthchecking。
包括了各种健康检查方式,以及对应的配置的解析包括LVS的配置解析
检查器测试如果realserver处于活动状态,则此测试以二进制决策结束:从LVS拓扑中删除或添加realserver。内部检查器设计是实时网络软件,它使用完全多线程的FSM设计(有限状态机)。此检查器堆栈提供符合layer4到layer5 / 7测试结果的LVS拓扑操作。它在由父进程监视的独立进程中运行。
IPVS包装器:
借助于Checkers实现后端lvs主机的健康状态检测。
此框架用于将规则发送到内核IPVS代码。它提供Keepalived内部数据表示和IPVS rule_user表示之间的转换。它使用IPVS libipvs来保持与IPVS代码的通用集成。来自LinuxVirtualServer.org OpenSource Project的Wensong提供的Linux内核代码。
IPVS:
为lvs生成ipvs规则的组件,是内核级别的。
System call:
在VRRP框架中,它提供了在协议状态转换期间启动额外脚本的能力。系统调用完成分叉进程,以便不会影响全局调度计时器。
keepalived相关进程
keepalived启动后会有三个进程
PID
111 Keepalived <-- Parent process monitoring children
112 \_ Keepalived <-- VRRP child
113 \_ Keepalived <-- Healthchecking child
父进程:内存管理,子进程管理等等
子进程:VRRP子进程
子进程:healthchecker子进程
两个子进程都被系统WatchDog看管,两个子进程各自负责自己的事。
healthchecker子进程负责检查各自服务器的健康程度,例如HTTP,LVS等等,如果healthchecker子进程检查到MASTER上服务不可用了,就会通知本机上的兄弟VRRP子进程,让他删除通告,并且去掉虚拟IP,转换为BACKUP状态。
keepalived脑裂问题
根据上述工作原理知道, 备节点接收不到报文时, 如两者间的网络不通了, 备节点就会启动接管程序接管主节点的资源, 对外提供服务, 表现形式就是备节点上出现了虚拟IP, 此时主节点也是持有虚拟IP的.
只要有虚拟IP存在, 就不可能完全规避这个问题. 也就是没有虚拟IP了, 就没有脑裂了, 那么节点又如何向外提供服务呢?
推荐自己写脚本
写一个while循环,每轮ping网关,累计连续失败的次数,当连续失败达到一定次数则运行service keepalived stop关闭keepalived服务。
如果发现又能够ping通网关,再重启keepalived服务。最后在脚本开头再加上脚本是否已经运行的判断逻辑,将该脚本加到crontab里面。
keepalived脑裂原因
一般来说脑裂问题有以下这几种原因:
高可用服务器对之间心跳线链路发生故障,导致无法正常通信
心跳线坏了(包括断了,老化)、
网卡及相关驱动坏了,IP配置及冲突问题(网卡直连)
心跳线之间的设备故障(网卡及交换机)、
仲裁的机器出现问题(才用仲裁的方案)
高可用服务器上开启了iptables防火墙,阻止了心跳传消息输
高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
其他服务配置不当的原因,如心跳方式不同,心跳广播冲突,软件bug等
提示keepalive配置里同一VRRP实例如果virtual_router_id两端参数配置不一致,也会导致脑裂问题
keepalived脑裂方案
在实际生产环境中,我们从以下方面防止脑裂:
同时使用串行电缆和以太网电缆连接、同时使用两条心跳线路,这样一条线路断了,另外一条还是好的,依然能传送心跳消息;
当检查脑裂时强行关闭一个心跳节点(这个功能需要特殊设备支持,如stonith、fence)相当于备节点接收不到心跳消息,通过单独的线路发送关机命令关闭主节点的电源;
做好对脑裂的监控报警;
利用服务注册机制避免脑裂发生。
常见解决方案:
如果开启防火墙,一定要让心跳消息通过,一般通过允许IP段的形式解决
可以拉一条以太网网线或者串口线作为主备节点心跳线路的冗余
开发检测程序通过监控软件检测脑裂
Keepalived优缺点
keepalived与zookeeper都可以用来实现高可用,高可用一般跟负载均衡会一起考虑,所以通常也会考虑到相应的负载均衡能力。
以下是Keepalived与Zookeeper的对比:
Keepalived:
优点:简单,基本不需要业务层面做任何事情,就可以实现高可用,主备容灾。而且容灾的宕机时间也比较短。
缺点:也是简单,因为VRRP、主备切换都没有什么复杂的逻辑,所以无法应对某些特殊场景,比如主备通信链路出问题,会导致脑裂。同时,keepalived也不容易做负载均衡。
zookeeper:
优点:可以支持高可用,负载均衡。本身是个分布式的服务。
缺点:跟业务结合的比较紧密。需要在业务代码中写好ZK使用的逻辑,比如注册名字。拉取名字对应的服务地址等。
keepalived配置文件
keepalived有三类配置区域
注意:不是三种配置文件,是一个配置文件里面三种不同类别的配置区域
全局配置(Global Configuration)
VRRPD配置
LVS配置
全局定义(global definition)配置范例:
! Configuration File for keepalived
global_defs {
router_id pg_xc1 #主备机必须不一样
script_user postgres #如果是涉及到pg数据库的相关操作,则需要选择pg用户
enable_script_security
}
vrrp_script check_pg_alived {
script “/etc/keepalived/check_pg.sh“ #检查pg数据库状态的脚本,主要靠这个判断是否进行主备切换
interval 5
weight 30 #很重要,判断主备切换的权重
fall 3 # require 3 failures for KO
}
VRRPD配置范例:
vrrp_instance VI_1 {
state BACKUP #BACKUP 必须大写
nopreempt #no preempt为非抢占模式
interface enp0s8 #vip使用的网络接口
virtual_router_id 10 #主备必须一样
priority 80 #设置节点的优先级,跟weight值组合使用,决定选择哪个为主
advert_int 1
authentication {
auth_type PASS
auth_pass abcdefgh
}
VRRPD配置范例(续):
track_script {
check_pg_alived
}
virtual_ipaddress {
192.168.18.100 #vip
}
notify_master “/etc/keepalived/failover.sh“ #当节点成为master时,执行的脚本
notify_fault “/etc/keepalived/fault.sh“ #节点出现故障,执行的脚本
}
Keepalived脚本编写
1、脚本要放在/etc/keepalived目录下,否则无法切换,可能是基于安全的原因。
2、脚本的权限很重要,权限太多执行不成功,一般为755
监控脚本check_pg.sh,对主从PG 进行状态监控。
#!/bin/bash
export PGDATABASE=postgres
export PGPORT=1922
export PGUSER=postgres
export PGHOME=/usr/local/pg12.2
export PATH=$PGHOME/bin:$PATH:$HOME/bin
PGMIP=127.0.0.1
LOGFILE=/etc/keepalived/log/pg_status.log
SQL1='SELECT pg_is_in_recovery from pg_is_in_recovery();'
SQL2='update sr_delay set sr_date = now() where id =1;'
SQL3='SELECT 1;'
db_role=`echo $SQL1 | $PGHOME/bin/psql -d $PGDATABASE -U $PGUSER -At -w`
if [ $db_role == 't' ];
then
echo -e `date +"%F %T"` "Attention1:the current database is standby DB!" >> $LOGFILE
exit 0
fi
# 备库不检查存活,主库更新状态
echo $SQL3 | psql -p $PGPORT -d $PGDATABASE -U $PGUSER -At -w
if [ $? -eq 0 ] ;
then
echo $SQL2 | psql -p $PGPORT -d $PGDATABASE -U $PGUSER -At -w
echo -e `date +"%F %T"` "Success: update the master sr_delay successed!" >> $LOGFILE
exit 0
else
echo -e `date +"%F %T"` "Error:Is the server is running?" >> $LOGFILE
exit 1
fi
切换脚本failover.sh,主库宕机后,keepalived调用执行切换脚本。
#!/bin/bash
export PGPORT=1922
export PGUSER=postgres
export PG_OS_USER=postgres
export PGDATA=/usr/local/pg12.2/data
export PGDBNAME=postgres
export LANG=zh_CN.UTF-8
export PGPATH=/usr/local/pg12.2/bin
export PATH=$PATH:$PGPATH
PGMIP=127.0.0.1
LOGFILE=/etc/keepalived/log/failover.log
# master-to-slave delay
sr_allowed_delay_time=10
SQL1='select pg_is_in_recovery from pg_is_in_recovery();'
SQL2="select sr_date as delay_time from sr_delay where now()-sr_date < interval '60';"
db_role=`echo $SQL1 | psql -At -p $PGPORT -U $PGUSER -d $PGDBNAME -w`
db_sr_delaytime=`echo $SQL2 | psql -p $PGPORT -d $PGDBNAME -U $PGUSER -At -w`
SWITCH_COMMAND='pg_ctl promote -D $PGDATA'
# slave switchover to master if delay large than specical second
if [ $db_role == f ];then
echo -e `date +"%F %T"` "Attention:The current postgreSQL DB is master database,cannot switched!" >> $LOGFILE
exit 0
fi
if [ $db_sr_delaytime -gt 0 ];then
echo -e `date +"%F %T"` "Attention:The current master database is health,the standby DB cannot switched!" >> $LOGFILE
exit 0
fi
echo $db_sr_delaytime
if [ -z $db_sr_delaytime ];then
echo -e `date +"%F %T"` "Attention:The current database is statndby,ready to switch master database!" >> $LOGFILE
pg_ctl promote -D $PGDATA
sed -i 's/primary_conninfo/#primary_conninfo/' $PGDATA/postgresql.auto.conf
pg_ctl restart -D $PGDATA
elif [ $? eq 0 ];then
echo -e `date +"%F %T"` "success:The current standby database successed to switched the primary PG database !" >> $LOGFILE
exit 0
else
echo -e `date +"%F %T"` "Error: the standby database failed to switch the primary PG database !,pelease checked it!" >> $LOGFILE
exit 1
fi
脚本fault.sh,keepalived 进入错误状态时执行的脚本。
#!/bin/bash
LOGGFILE=/etc/keepalived/log/pg_db_fault.log
PGPORT=1922
PGMIP=10.10.10.111
echo -e `date +"%F %T"` "Error:Because of the priamry DB happend some unknown problem,So turn off the PostgreSQL Database!" >> $LOGFILE
PGPID="`netstat -anp|grep $PGPORT |awk '{printf $7}'|cut -d/ -f1`"
service keepalived stop
kill -9 $PGPID
if [ $? eq 0 ];then
echo -e `date +"%F %T"` "Error:Because of the priamry DB happend some unknown problem,So turn off the PostgreSQL Database!" >> $LOGFILE
service keepalived stop
exit 1
fi
Keepalived配置文件(备)
备库配置:
1、把master的keepalived.conf文件和scripts目录复制到备机。
2、修改keepalived.conf的router_id为pg_xc2,priority为80即可。
keepalived启动及状态查看
1、MASTER启动keepalived 服务器
# service keepalived start
2、MASTER查看keepalived 状态
# service keepalived status
3、查看后台日志
# tail -f /var/log/messages
4、查看虚拟ip(ifconfig看不到虚拟IP):
# ip addr
Keepalived主备切换
1、把主库给停掉
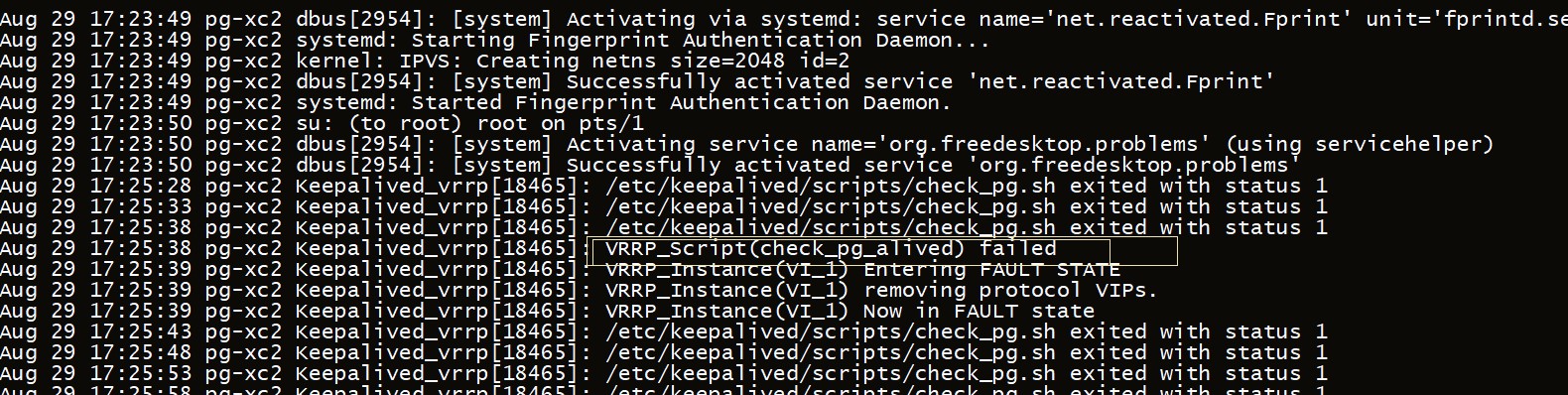
在原来的主节点可以看到报错信息/var/log/message
2、此时第三方主机通过vip连接到的是新的主库数据库(说明vip和备库切换到主库成功)。
3、备库切换到主库,需要额外操作完成所有切换(或者在切换脚本实现)
3.1、修改postgresql.auto.conf中的内容,屏蔽掉之前当作备库时的配置,否则还是名义上的备库。
3.2、重启实例
pg_ctl restart
4、原主库变成备库需要手动下面的操作(需要手动操作)
4.1、编辑standby.signal文件
primary_conninfo = 'host=pg-xc2 port=1922 user=repl password=repl options=''-c wal_sender_timeout=5000'''
restore_command = 'cp /home/postgres/arch/%f %p'
archive_cleanup_command = 'pg_archivecleanup /home/postgres/arch %r'
standby_mode = on
4.2、编辑postgresql.auto.conf
primary_conninfo = 'host=pg-xc2 port=1922 user=repl password=repl options=''-c wal_sender_timeout=5000'''
restore_command = 'cp /home/postgres/arch/%f %p'
archive_cleanup_command = 'pg_archivecleanup /home/postgres/arch %r'
standby_mode = on
4.3、启动数据库
$ pg_ctl start
4.4、查看状态,并且通过第三方通过vip登录时,此时登录的是主库。
select * from pg_is_in_recovery();
Keepalived主备竞选规则
Keepalived的主备角色是可以改变的,其改变策略是:
1、如果weight值设置为正整数,当主库的vrrp_script脚本执行成功,其权值为priority+weight,而备库的权值为priority+weight的值。那么此时主库的和大于备库的和。
2、如果weight值设置为正整数,当主库的vrrp_script脚本执行失败,其权值为priority设置的值;而备库的权值为priority+weight,如果其和大于主库的priority,则备库会变成主库。
注意weight设置的值必须要大于主备priority之间的差。比如:主库priority设为100,备库priority设为80,weight则要设置大于100-80=20的差。
通过观察/var/log/messages可以看到权值的变化。
keepalived切换模式
keepalived工作模式分为抢占和非抢占模式:
抢占模式:
通过优先级(priority)来决定谁是master,优先级高的为master,拥有虚拟IP。
这种模式有一个问题就是当原主节点从故障中恢复后会重新获得master角色抢占虚拟IP,这在有些场景可能会有问题(例如需要数据同步的场景,恢复后需要先同步数据)。
抢占模式配置:preempt
非抢占模式:
发生故障才切换(比如keepalived进程中断),否则不切换。切换测试时先停止主库,再关闭keepalived进程。
非抢占模式配置:no preempt
切换模式选择规则
如果是要实现主库和vip都在同一台主机的目标,那么应该选择非抢占模式,这样子虽然主库中断,只要keepalived进程还在,则不会发生主库切换和vip切换。虽然切换响应时间受到影响,但是保证通过VIP都能够连接主库上。
如果是抢占模式,会出现以下情况:
1、A是主库(拥有vip),B是备库
2、A主库关闭,B变成主库(抢到vip) #此时没有问题。
3、A备库启动(根据抢占模式,抢到vip),B还是主库(但是vip被抢占) #此时通过vip就会访问到备库。
4、如果一定要提高数据库故障切换响应时间,可以配置为抢占模式,但是当备库(原来的主库)启动前,得降低该主机的优先级模式。也就是保证主库所在的优先级要高,vip不会被抢占。