scrapy爬虫框架
- 一、scrapy的概念作用和工作流程
- 1、scrapy的概念
- 2、scrapy框架的作用
- 3、scrapy的工作流程(重点)
- 3.1 回顾之前的爬虫流程
- 3.2 改写上述流程
- 3.3 scrapy的流程
- 3.4 scrapy的三个内置对象
- 3.5 scrapy中每个模块的具体作用
- 二、scrapy的入门使用
- 1、安装scrapy
- 2、scrapy项目开发流程
- 3、创建项目
- 4、创建爬虫
- 5、完善爬虫
- 5.1 在/spiders/itcast.py中修改内容
- 5.2 定位元素以及提取数据、属性值的方法
- 5.3 response响应对象的常用属性
- 6、保存数据
- 6.1 在pipelines.py文件中定义对数据的操作
- 6.2 在settings.py配置启用管道
- 7、运行scrapy
- 三、scrapy数据建模与请求
- 1、数据建模
- 1.1 为什么要建模
- 1.2 如何建模
- 1.3 如何使用模板类
- 2、翻页请求的思路
- 3、构造Request对象,并发送请求
- 3.1 实现方法
- 3.2 网易招聘爬虫案例
- 3.3 代码实现
- 3.4 scrapy.Request的更多参数
- 4、meta参数的使用
- 四、scrapy模拟登录
- 1、模拟登录的方法
- 1.1 requests的模拟登录
- 1.2 selenium的模拟登录
- 1.3 scrapy的模拟登录
- 2、scrapy携带cookies直接获取需要登录后的页面
- 2.1 实现:重构scrapy的start_requests方法
- 2.2 携带cookies登录GitHub
- 3、scrapy.Request发送post请求
- 3.1 发送post请求
- 3.1.1 思路分析
- 3.1.1 代码实现
- 五、scrapy管道的使用
- 1、pipeline 中常用的方法
- 2、管道文件的修改
- 3、开启管道
- 4、pipeline使用注意点
- 六、scrapy中间件的使用
- 1、scrapy中间件的分类和作用
- 1.1 scrapy中间件的分类
- 1.2 scrapy中间件的作用
- 2、下载中间件的使用方法
- 3、定义实现随机User-Agent的下载中间件
- 3.1 在settings.py中添加UA列表
- 3.2 在middleware.py中完善代码
- 3.3 在settings中设置开启自定义的下载中间件,设置方法同管道
- 4、代理IP的使用
- 4.1 思路分析
- 4.2 具体实现
- 4.3 检测代理IP是否可用
- 5、在中间件中使用selenium
- 七、scrapy_redis的概念、作用及流程
- 1、分布式是什么
- 2、scrapy_redis的概念
- 3、scrapy_redis的作用
- 4、scrapy_redis的工作流程
- 4.1 回顾scrapy流程
- 4.2 scrapy_redis的流程
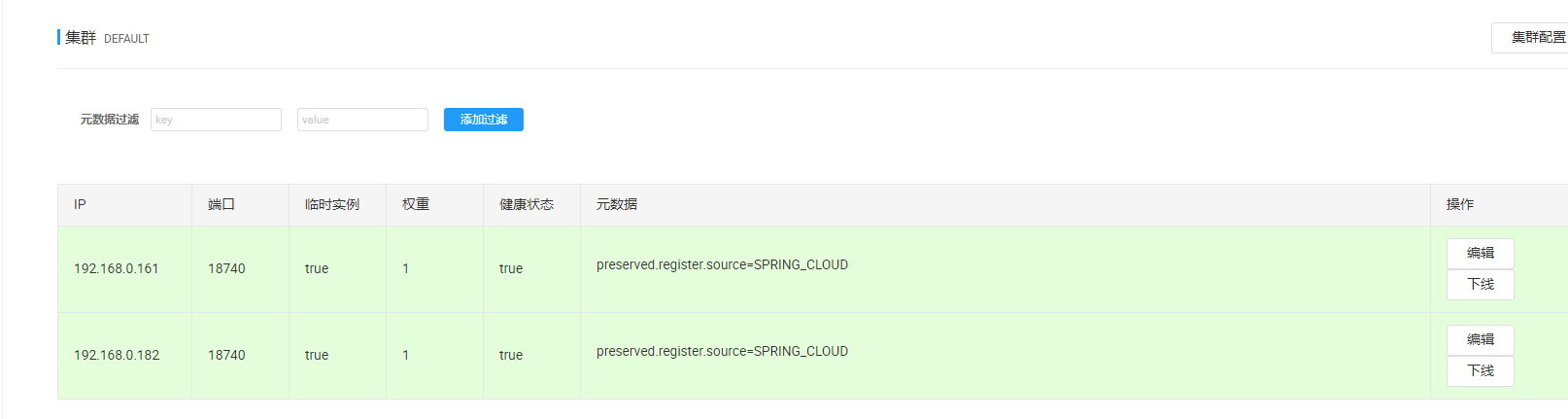
一、scrapy的概念作用和工作流程
1、scrapy的概念
scrapy是一个python编写的开源网络爬虫框架。它是一个被设计用于爬虫网络数据、提取结构性数据的框架。
scrapy使用了twisted异步网络框架,可以加快我们的下载速度。
scrapy文档地址:https://scrapy-chs.readthedocs.io/zh-cn/0.24/intro/overview.html
2、scrapy框架的作用
少量的代码,就能够快速的抓取
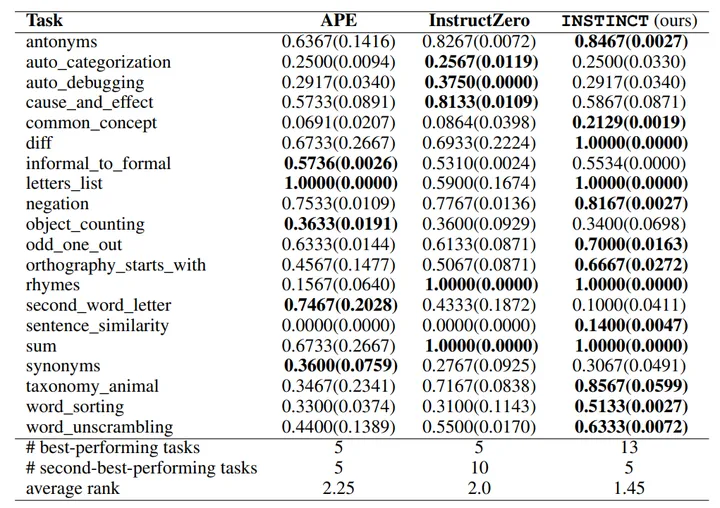
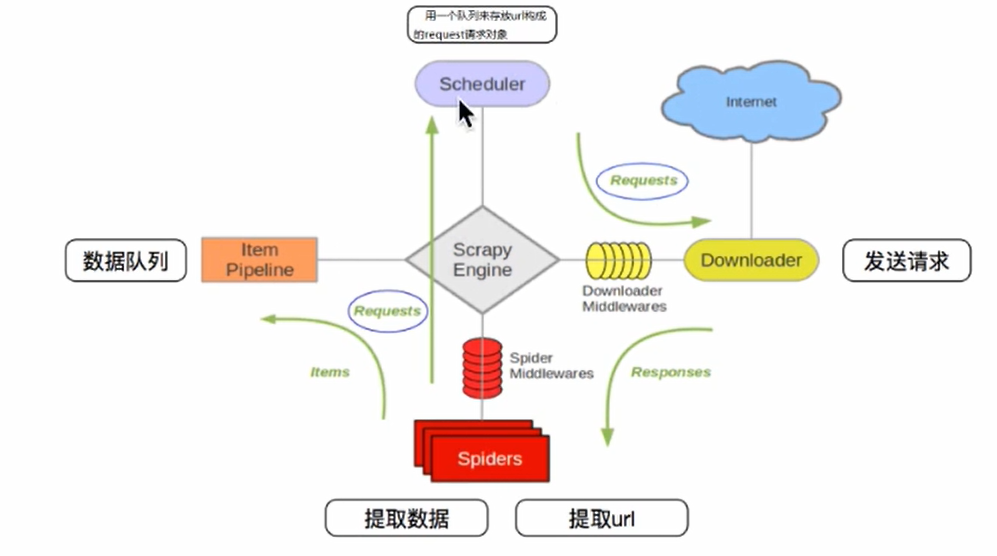
3、scrapy的工作流程(重点)
3.1 回顾之前的爬虫流程
3.2 改写上述流程
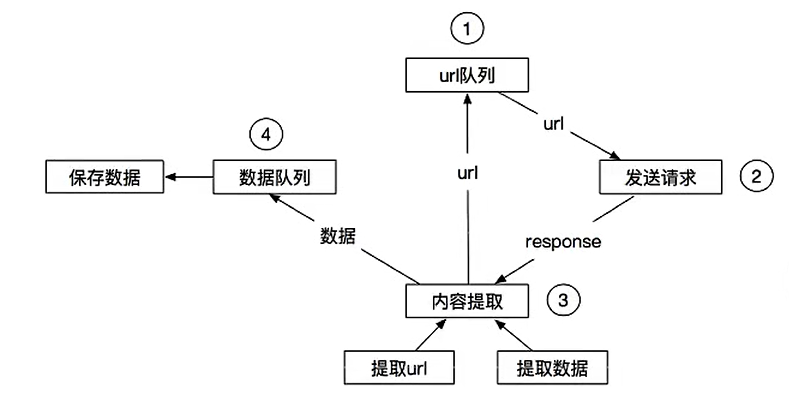
3.3 scrapy的流程
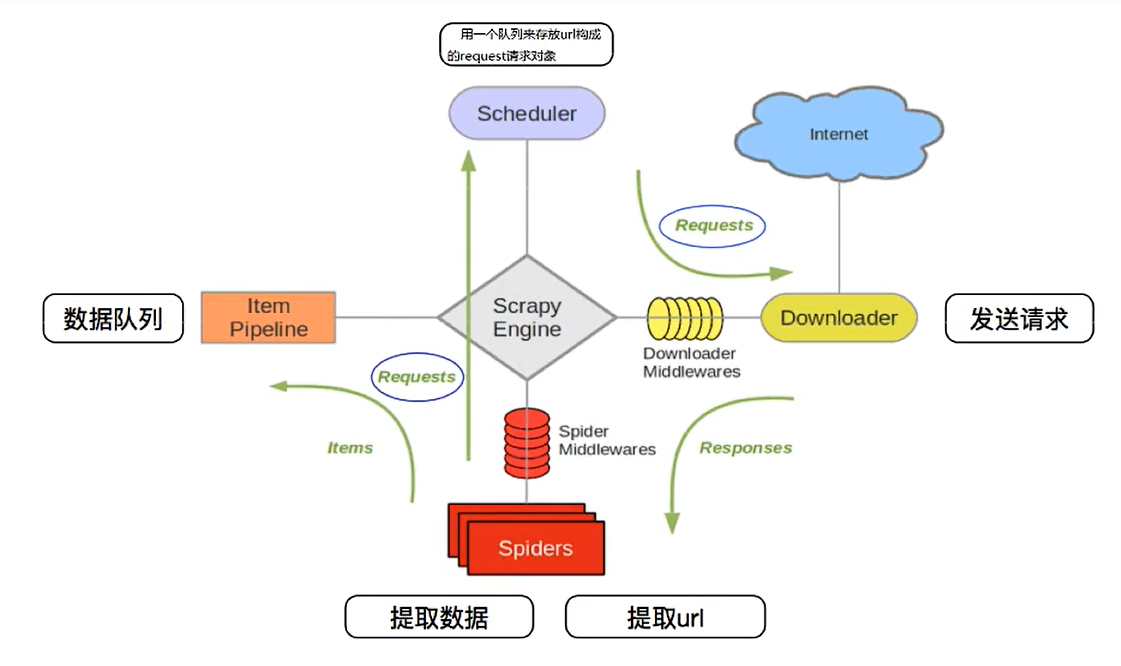
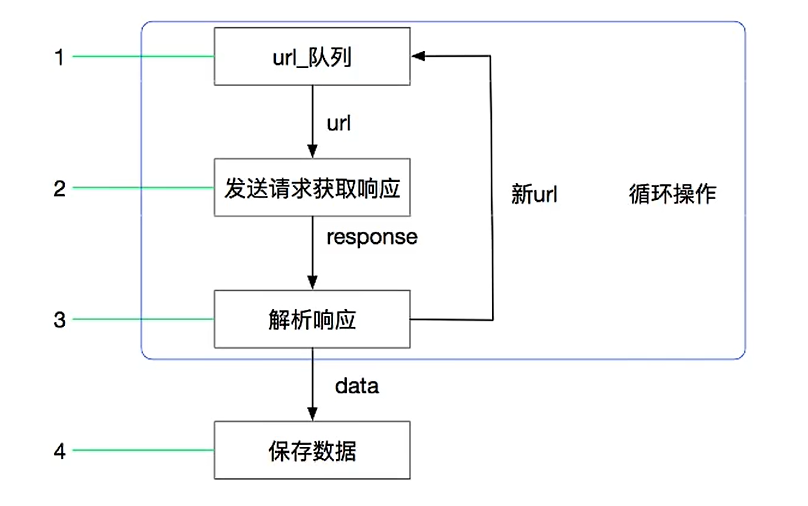
其流程可以描述为:
- 爬虫中的起始url构造成request对象→爬虫中间件→引擎→调度器
- 调度器把request→引擎→下载中间件→下载器
- 下载器发送请求,获取response响应→下载中间件→引擎→爬虫中间件→爬虫
- 爬虫提取url地址,组装成request对象→爬虫中间件→引擎→调度器,重复步骤2
- 爬虫提取数据→引擎→管道处理和保存数据
注意:
- 图中中文是为了方便理解后加上去
- 图中绿色线条表示数据的传递
- 注意图中中间件的位置,决定了其作用
- 注意其中引擎的位置,所有模块之间相互独立,只和引擎进行交互
3.4 scrapy的三个内置对象
- request请求对象:由url、method、post_data、headers等构成
- response响应对象:由url、body、status、headers等构成
- item数据对象:本质是个字典
3.5 scrapy中每个模块的具体作用
| 模块 | 作用 | 其他 |
|---|---|---|
| Scrapy Engine(引擎) | 总指挥:负责数据和信号在不同模块之间的传递 | scrapy已经实现 |
| Scheduler(调度器) | 一个队列,存放引擎发过来的request请求 | scrapy已经实现 |
| Downloader(下载器) | 下载引擎发过来的request请求,并返回给引擎 | scrapy已经实现 |
| Spider(爬虫) | 处理引擎发来的response,提取数据,提取url,并交给引擎 | 需要手写 |
| Item Pipeline(管道) | 处理引擎传过来的数据,比如存储 | 需要手写 |
| Downloader Middlewares(下载中间件) | 可以自定义的下载扩展,比如设置代理 | 一般不用手写 |
| Spider Middlewares(爬虫中间件) | 可以自定义request请求和进行response过滤 | 一般不用手写 |
注意:
- 爬虫中间件和下载中间件只是运行逻辑的位置不同,作用是重复的:如替换UA等。
二、scrapy的入门使用
1、安装scrapy
命令:sudo apt-get install scrapy 或者 pip/pip3 install scrapy
2、scrapy项目开发流程
- 创建项目:
scrapy startproject mySpider - 生成爬虫:
scrapy genspider itcast itcast.cn - 提取数据:根据网站结构在spider中实现数据采集相关内容
- 保存数据:使用pipeline进行数据后续处理和保存
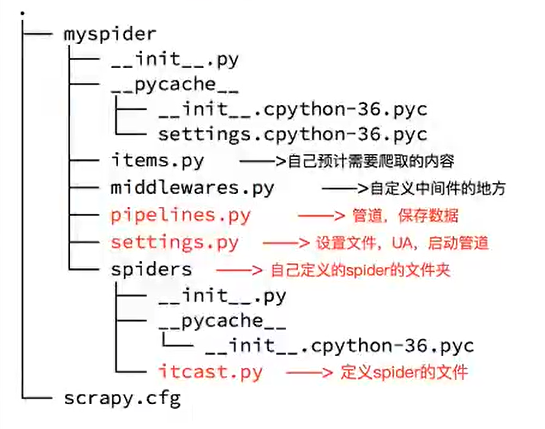
3、创建项目
创建scrapy项目的命令:scrapy startproject <项目名称>
示例:scrapy startproject myspider
生成的目录和文件结果如下:

4、创建爬虫
在项目路径下执行如下命令:scrapy genspider <爬虫名字> <允许爬取的域名>
爬虫名字:作为爬虫运行时的参数
允许爬取的域名:设置爬虫的爬取范围,设置之后用于过滤要爬取的url,如果爬取的url与允许的域不同则会被过滤掉。
示例:
cd myspider
scrapy genspider itcast itcast.cn
生成的目录和文件结果如下:
5、完善爬虫
在上一步生成出来的爬虫文件中编写指定网站的数据采集操作,实现数据提取
5.1 在/spiders/itcast.py中修改内容
import scrapyclass ItcastSpider(scrapy.Spider): # 继承scrapy.Spidername = 'itcast' # 爬虫名字allowed_domains = ['itcast.cn'] # 允许爬取的范围start_urls = ['https://www.itheima.com/teacher.html#ajavaee'] # 开始爬取的url地址# 数据提取的方法,接收下载中间件传过来的responsedef parse(self, response):# 获取所有老师节点node_list = response.xpath('//div[@class="li_txt"]')# 遍历老师节点列表for node in node_list:temp = {}# xpath方法返回的是选择器对象列表,extract()用于从选择器对象中提取数据temp['name'] = node.xpath('./h3/text()')[0].extract()temp['title'] = node.xpath('./h4/text()')[0].extract()temp['desc'] = node.xpath('./p/text()')[0].extract()yield temp
注意:
- scrapy.Spider爬虫类中必须有名为parse的解析
- 如果网站结构层次比较复杂,也可以自定义其他解析函数
- 在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内,但是start_urls中的url地址不受这个限制
- 启动爬虫时要注意启动的位置,在项目路径下启动
- parse()函数中使用yield返回数据,注意解析函数中的yield能够传递的对象只能是:BaseItem,Request,dict,None
5.2 定位元素以及提取数据、属性值的方法
解析并获取scrapy爬虫中的数据:利用xpath规则字符串进行定位和提取
- response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
- 额外方法extract():返回一个包含有字符串的列表
- 额外方法extract_first():返回列表中的第一个字符串,列表为空则返回None
5.3 response响应对象的常用属性
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
- response.headers:响应头
- response.request.headers:当前响应的请求头
- response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码
6、保存数据
利用管道pipeline来处理(保存)数据
6.1 在pipelines.py文件中定义对数据的操作
- 定义一个管道类
- 重写管道类的process_item方法
- process_item方法处理完item之后必须返回给引擎
import jsonclass MyspiderPipeline:def __init__(self):self.file = open('itcast.json', 'w')def process_item(self, item, spider):# 将字典数据序列化json_data = json.dumps(item, ensure_ascii=False) + ',\n'# 将数据写入文件self.file.write(json_data)# 默认使用完管道之后需要将数据返回给引擎return itemdef __del__(self):self.file.close()6.2 在settings.py配置启用管道
ITEM_PIPELINES = {'myspider.pipelines.MyspiderPipeline': 300,
}
配置项中键为使用的管道类,管道类使用.进行分割,第一个为项目目录,第二个为文件,第三个为定义的管道类。
配置项中值为管道的使用顺序,设置的数值越小越优先执行,该值一般设置为1000以内。
7、运行scrapy
命令:在项目目录下执行scrapy crawl <爬虫名字>
示例:scrapy crawl itcast
三、scrapy数据建模与请求
1、数据建模
通常在做项目的过程中,在items.py中进行数据建模
1.1 为什么要建模
- 定义item,即提前规划好哪些字段需要抓,防止手误;定义好之后,在运行过程中,系统会自动检查
- 配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字典代替
- 使用scrapy的一些特定组件需要Item做支持,如scrapy的ImagesPipeline管道类。
1.2 如何建模
在items.py文件中定义要提取的字段:
class MyspiderItem(scrapy.Item):# define the fields for your item here like:name = scrapy.Field() # 讲师的名字title = scrapy.Field() # 讲师的职称desc = scrapy.Field() # 讲师的介绍
1.3 如何使用模板类
模板类定义以后需要在爬虫中导入并且实例化,之后的使用方法和使用字典相同
itcast.py:
import scrapy
from myspider.items import MyspiderItemclass ItcastSpider(scrapy.Spider): # 继承scrapy.Spidername = 'itcast' # 爬虫名字allowed_domains = ['itcast.cn'] # 允许爬取的范围start_urls = ['https://www.itheima.com/teacher.html#ajavaee'] # 开始爬取的url地址# 数据提取的方法,接收下载中间件传过来的responsedef parse(self, response):# 获取所有老师节点node_list = response.xpath('//div[@class="li_txt"]')# 遍历老师节点列表for node in node_list:item = MyspiderItem() # 实例化后直接使用# xpath方法返回的是选择器对象列表,extract()用于从选择器对象中提取数据item['name'] = node.xpath('./h3/text()')[0].extract()item['title'] = node.xpath('./h4/text()')[0].extract()item['desc'] = node.xpath('./p/text()')[0].extract()yield item注意:
from myspider.items import MyspiderItem这一行代码中注意item的正确导入路径,忽略pycharm标记的错误- python中的导入路径要诀:从哪里开始运行,就从哪里开始导入
2、翻页请求的思路
对于要提取如下图中所有页面上的数据该怎么办?

requests模块是如何实现翻页请求的:
- 找到下一页的url地址
- 调用requests.get(url)
scrapy实现翻页的思路:
- 找到下一页的url地址
- 构造url地址的请求对象,传递给引擎
3、构造Request对象,并发送请求
3.1 实现方法
- 确定url地址
- 构造请求,scrapy.Request(url, callback)
- callback:指定解析函数名称,表示该请求返回的响应使用哪一个函数进行解析
- 把请求交给引擎:yield scrapy.Request(url, callback)
3.2 网易招聘爬虫案例
- 通过爬取网易社会招聘的页面的招聘信息,学习如何实现翻页请求
- 地址:https://hr.163.com/job-list.html
思路分析:
- 获取首页的数据
- 寻找下一页的地址,进行翻页,获取数据
注意:
-
可以在settings中设置ROBOTS协议
# False表示忽略网站的robots.txt协议,默认为True ROBOTSTXT_OBEY = False -
可以在settings中设置User-Agent:
# scrapy发送的每一个请求的默认UA都是设置的这个User-Agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
3.3 代码实现
-
网易社会招聘网站是一个JSON数据渲染的动态网页,网页源码中并不包含数据,所以不能使用xpath进行解析;对网站进行分析,找到请求页面动态加载JSON数据的请求,如下图所示:
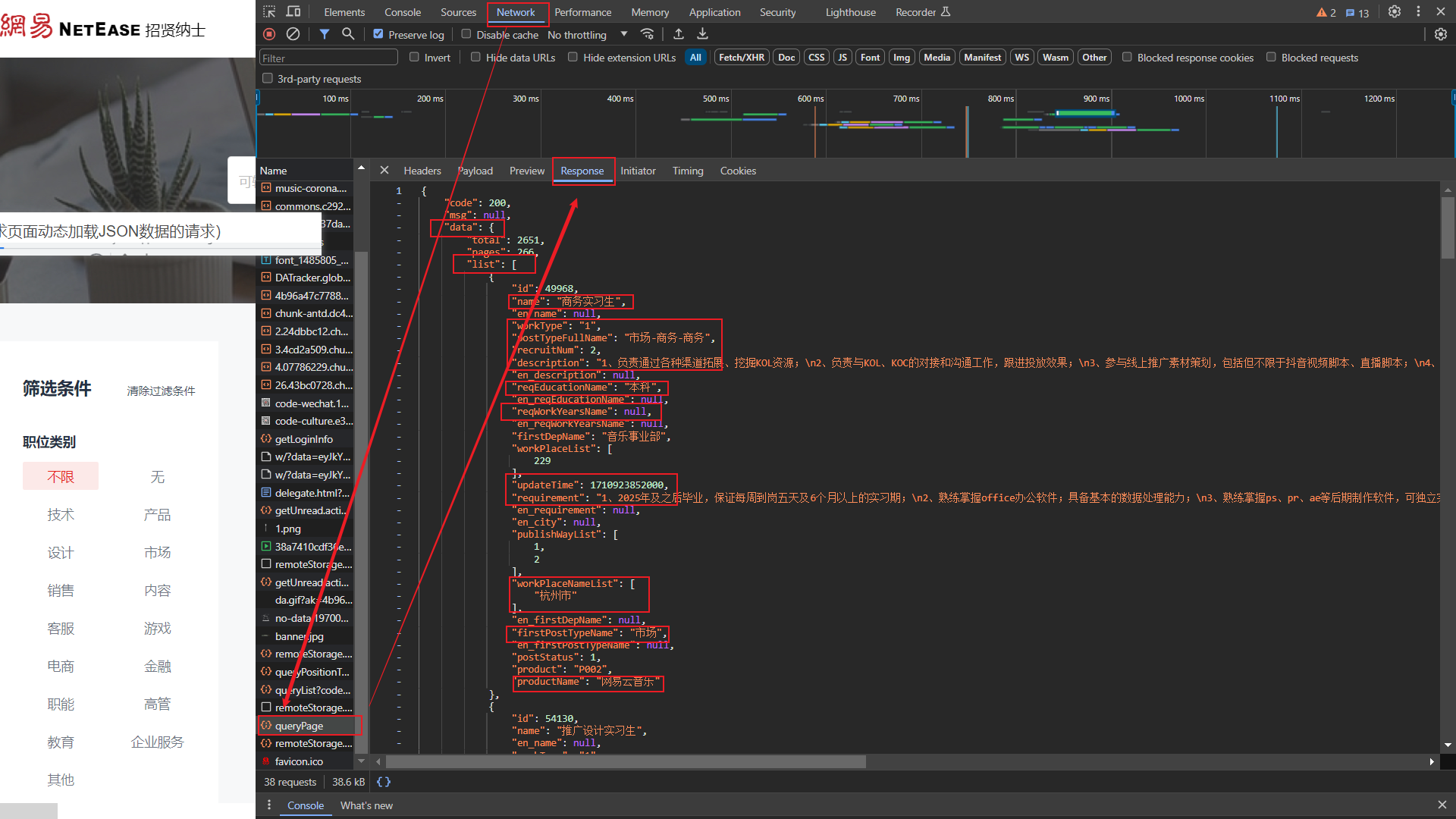
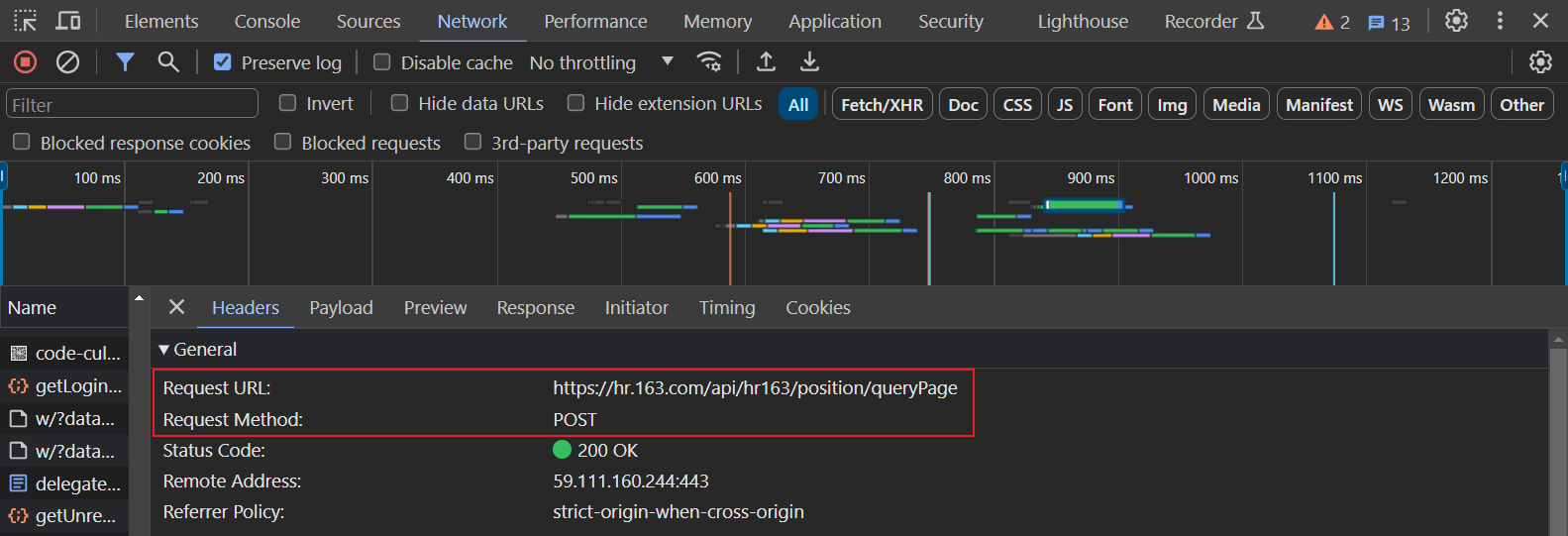
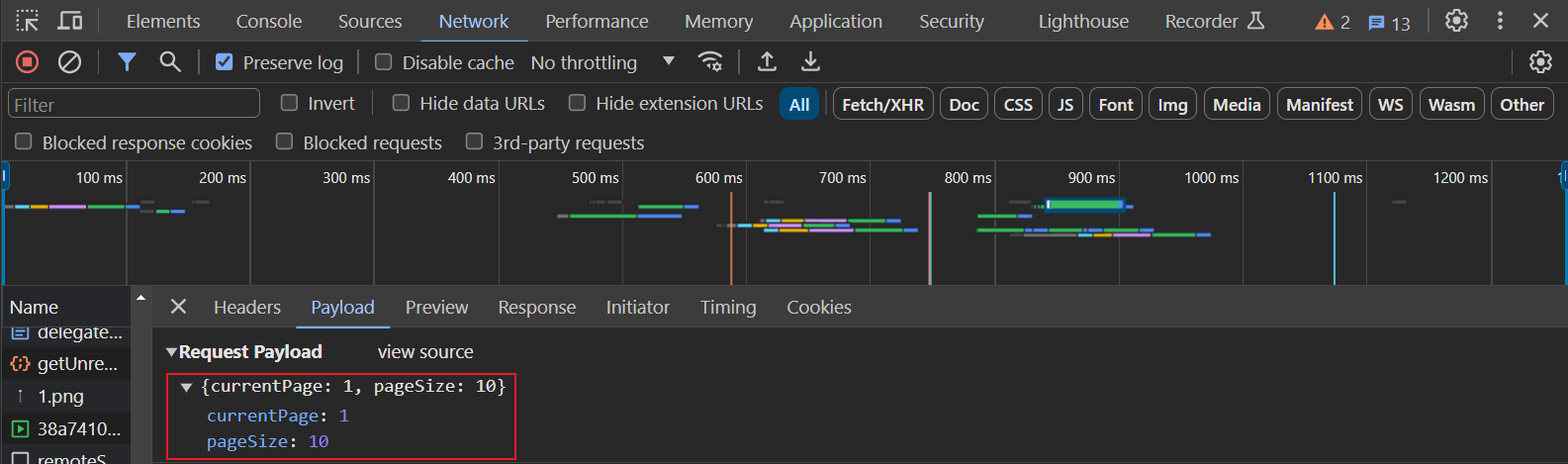
图中包含了每个职位的相关信息,此时的start_url地址发生了变化,需要进行更改,请求的方式为POST请求,相关的参数如下:
-
该网站存在翻页,需要进行模拟翻页请求
-
将爬取到的数据存储到JSON文件中
-
代码如下:
items.py:# Define here the models for your scraped items import scrapyclass WangyiItem(scrapy.Item):name = scrapy.Field() # 职位名称workType = scrapy.Field() # 工作性质workPlaceNameList = scrapy.Field() # 工作地点productName = scrapy.Field() # 所属产品firstPostTypeName = scrapy.Field() # 职位类别recruitNum = scrapy.Field() # 招聘人数reqEducationName = scrapy.Field() # 学历reqWorkYearsName = scrapy.Field() # 工作经验description = scrapy.Field() # 职位描述requirement = scrapy.Field() # 职位要求updateTime = scrapy.Field() # 更新时间job.py:
import jsonimport scrapyfrom wangyi.items import WangyiItem from datetime import datetimenext_page = 1 # 用来控制翻页的变量class JobSpider(scrapy.Spider):name = 'job'allowed_domains = ['hr.163.com']# start_urls = ['https://hr.163.com/job-list.html']start_urls = ['https://hr.163.com/api/hr163/position/queryPage']def start_requests(self):url = self.start_urls[0]# 起始url参数payload = {"currentPage": "1","pageSize": "10"}# 构建post请求yield scrapy.Request(url=url,body=json.dumps(payload),method='POST',callback=self.parse,headers={'Content-Type': 'application/json;charset=utf-8'})def parse(self, response):dic = response.json()job_list = dic['data']['list']item = WangyiItem()for job in job_list:item['name'] = job['name'].replace(u'\xa0', u' ')item['workType'] = job['workType']item['workPlaceNameList'] = str(job['workPlaceNameList']).replace('[', '').replace(']', '').replace("'", '')item['productName'] = job['productName']item['firstPostTypeName'] = job['firstPostTypeName']item['recruitNum'] = job['recruitNum']item['reqEducationName'] = job['reqEducationName']item['reqWorkYearsName'] = job['reqWorkYearsName']item['description'] = job['description'].replace('\t', '').replace('\n', '').replace('\\', '/')\.replace(u'\xa0', u' ')item['requirement'] = job['requirement'].replace('\t', '').replace('\n', '').replace(u'\xa0', u' ')item['updateTime'] = datetime.utcfromtimestamp(job['updateTime'] / 1000).strftime('%Y-%m-%d')yield item# 模拟翻页page_stutas = dic['data']['lastPage'] # 根据返回的数据来判断是否是最后一页,true为最后一页global next_pagenext_page = next_page + 1if not page_stutas:print("正在爬取第{}页···········".format(next_page))payload = {"currentPage": "{}".format(next_page),"pageSize": "10"}url = self.start_urls[0]yield scrapy.Request(url=url,body=json.dumps(payload),method='POST',callback=self.parse,headers={'Content-Type': 'application/json;charset=utf-8'})pipelines.py:
# Define your item pipelines here import jsonclass WangyiPipeline:def __init__(self):self.file = open('wangyi.json', 'w', encoding='utf-8')def process_item(self, item, spider):# 将item对象强转为字典,该操作只能在scrapy中使用item = dict(item)# 将字典数据序列化json_data = json.dumps(item, ensure_ascii=False) + ',\n'# 将数据写入文件self.file.write(json_data)# 默认使用完管道之后需要将数据返回给引擎return itemdef __del__(self):self.file.close() -
最终结果:
3.4 scrapy.Request的更多参数
scrapy.Request(url[, callback, method="GET", headers, body, cookies, meta, dont_filter=False])
参数解释:
- 中括号里的参数为可选参数
- callback:表示当前的url的响应交给哪个函数去处理
- meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
- dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求;对需要重复请求的url地址可以把它设置成True,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
- method:指定POST或GET请求
- header:接收一个字典,其中不包括cookie
- cookies:接收一个字典,专门放置cookie
- body:接收json字符串,为POST的数据,发送payload_post请求时使用
4、meta参数的使用
meta的作用:meta可以实现数据在不同解析函数中的传递
在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self, response):...yield scrapy.Request(url = detail_url,callback = self.parse_detail,meta = {"item": item})def parse_detail(self, response):# 获取之前传入的itemitem = response.meta["item"]
注意:
- meta参数是一个字典
- meta字典中有一个固定的键proxy,表示代理IP
四、scrapy模拟登录
1、模拟登录的方法
1.1 requests的模拟登录
- 直接携带cookies请求页面
- 找url地址,发送post请求存储cookies
1.2 selenium的模拟登录
- 找到对应的input标签,输入文本点击登录
1.3 scrapy的模拟登录
- 直接携带cookies
- 找url地址,发送post请求存储cookie
2、scrapy携带cookies直接获取需要登录后的页面
应用场景
- cookie过期时间很长,常用于一些不规范的网站
- 能在cookie过期前把所有的数据拿到
- 配合其他程序使用,比如其使用selenium把登录之后的cookie获取保存到本地,scrapy发送请求之前先读取本地cookie
2.1 实现:重构scrapy的start_requests方法
scrapy中start_url是通过start_request来进行处理的,其实现代码如下:
def start_requests(self):cls = self.__class__if not self.start_urls and hasattr(self, 'start_url'):raise AttributeError("Crawling could not start: 'start_urls' not found ""or empty (but found 'start_url' attribute instead, ""did you miss an 's'?)")if method_is_overridden(cls, Spider, 'make_requests_from_url'):warnings.warn("Spider.make_requests_from_url method is deprecated; it ""won't be called in future Scrapy releases. Please ""override Spider.start_requests method instead "f"(see {cls.__module__}.{cls.__name__}).",)for url in self.start_urls:yield self.make_requests_from_url(url)else:for url in self.start_urls:yield Request(url, dont_filter=True)
所以对应的,如果start_url地址中的url是需要登录后才能访问的url地址,则需要重写start_request方法并在其中手动添加上cookie
2.2 携带cookies登录GitHub
import scrapyclass Git1Spider(scrapy.Spider):name = 'git1'allowed_domains = ['github.com']start_urls = ['https://github.com/yixinchd']def start_requests(self):url = self.start_urls[0]temp = '_octo=GH1.1.1704635908.1695371613; preferred_color_mode=dark; tz=Asia%2FShanghai; _device_id=e0e107d487355d28e612363acb5a1896; has_recent_activity=1; saved_user_sessions=102498110%3AVR4xKz7HlrvOYXtBGIYS5ymlBh60jLTs5ZluskQ1quEy_SHy; user_session=VR4xKz7HlrvOYXtBGIYS5ymlBh60jLTs5ZluskQ1quEy_SHy; __Host-user_session_same_site=VR4xKz7HlrvOYXtBGIYS5ymlBh60jLTs5ZluskQ1quEy_SHy; tz=Asia%2FShanghai; color_mode=%7B%22color_mode%22%3A%22light%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light_high_contrast%22%2C%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A%22dark%22%7D%7D; logged_in=yes; dotcom_user=yixinchd; _gh_sess=qO24Aua93K95viiLT3FeWsEqiAZRqjuIA%2BBJMmnRsaEKwiXYC8MJZF1nXni%2Fvt0bLRxwXadmjsHsbIuFTfLx6EwdGuQVjAdC0b88nq7w%2Bo7eOZYspcKxyqn5QoHYOiKFkPG8up6y7jwLwWgdZawMWndiK3OvlHO4rYccMttUcRUgmWY%2Fqlc1y8PgGDbuphe0aUY2agmZjxsm4DUmOCOZrnQybBXefybehb8Y5yql5A%2BWKNYES1dIDd9wToPmjYhf%2Fg0Y3rn0Vd%2Fi%2FIW%2Fj%2BfDCpv3BB4NY2zBBR3B3LSrRzYMNvOQFBM1SsL2vaoQSRg5kt6OpQfpkZZ7LZLZn0dmBoGNOrV66efLO4cSq8VXoUqPafbz%2B%2BFGx6NbgR0bFBkSDuHuTf%2FqFKb0io6d2LqcASJgIU6aOqSR2TDPsdob25leBzErM1mVwTN7sTq36CD5Fypr%2Fyuj8Ofu6HA%2FJ7oDss1UUAl%2Bh5G8C8I%2F1zcZKEkr5mlyL4LbZdteBqLfBE2PQp%2B1l%2BdZBLKkTbBrUTc%2BB1IFupsDIocOh5gx0%2BszdegRieG3RNn%2BfuqaxOsbRbWGNI%2F7pVgdswp%2F67PI6NT6SbnXwDRccZO63f8k3hAc26Az%2B5JmXf%2B5XWkgcf8hGWUL3eWJAOn7HXjUp7bCERsD%2BxEZH%2FRQDv8EozZKpGi3AWyL4uJYfondySe6kOARef0Vr%2Fe0AoFBakLmrEkvv7nI9BpbYDCj5zuV1ItPkDxPy%2BpOPzFbbZGEOx8dkKQenNFj0LzG1VSUGa5ZyYxwXdTu%2FwxouF4mgi%2Bp1c0Jl60BYuidKo0izfVH3giU4VZG6wzDi1QU66UapA5UzsixdTJJL8gQ0uPst1NUdvocY%2FToIyGwntGoPR3NYlCm9Jx2uE2WaKCJ1S8ahcyX5sV95t4ioEm%2FSrsuwrjBSbohk2mB%2B81xAPR4qBDURwpVwXSXt0LYvl5CIJUL%2BUnZd17%2BvvOTwpfY0e5uS3u2vOUVwgdD9dI2ZU3MFqURgjHjz15gSfSqZdb64Q%3D%3D--Fdopx2y%2BDKwpM9rj--Yn7THwpkvt8r67w5NaoDFQ%3D%3D'cookies = {data.split('=')[0]: data.split('=')[-1] for data in temp.split('; ')}yield scrapy.Request(url=url,callback=self.parse,cookies=cookies)def parse(self, response):print(response.xpath('/html/head/title/text()').extract_first())注意:
- scrapy中cookie不能放在headers中,在构造请求的时候有专门的cookies参数,能够接收字典形式的cookie
- 在setting中设置Robots协议、User_Agent
3、scrapy.Request发送post请求
可以通过scrapy.Request()指定method、body参数来发送post请求,但通常使用scrapy.FormRequest()来发送post请求
3.1 发送post请求
注意:scrapy.FormRequest()能够发送表单和ajax请求
3.1.1 思路分析
- 找到post的url地址:点击登录按钮进行抓包,然后定位url地址为
- 找到请求体的规律:分析post请求的请求体,其中包含的参数均在前一次的响应中
- 是否登录成功:通过请求个人主页,观察是否包含用户名
3.1.1 代码实现
import scrapyclass LoginSpider(scrapy.Spider):name = 'login'allowed_domains = ['github.com']start_urls = ['https://github.com/login']def parse(self, response):# 从登录页面响应中解析出post数据token = response.xpath('//input[@name="authenticity_token"]/@value').extract_first()post_data = {'commit': 'Sign in','authenticity_token': token,'login': '**************','password': '**************','webauthn-conditional': 'undefined'}print(post_data)# 针对登录url发送post请求yield scrapy.FormRequest(url='https://github.com/session',callback=self.after_login,formdata=post_data)def after_login(self, response):yield scrapy.Request(url='https://github.com/yixinchd',callback=self.check_login)def check_login(self, response):print(response.xpath('/html/head/title/text()').extract_first())注意:
- 在settings.py中通过设置COOKIES_DEBUG = True能够在终端看到cookie的传递过程

五、scrapy管道的使用
1、pipeline 中常用的方法
process_item(self, item, spider):- 管道类中必须有的函数
- 实现对item数据的处理
- 必须return item
open_spider(self, spider):在爬虫开启的时候仅执行一次close_spider(self, spider):在爬虫关闭的时候仅执行一次
2、管道文件的修改
3、开启管道
在settings.py设置开启pipeline
注意:在settings中能够开启多个管道,为什么需要开启多个?
- 不同的pipeline可以处理不同爬虫的数据,通过spider.name属性来区分
- 不同的pipeline能够对一个或多个爬虫进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
- 同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
4、pipeline使用注意点
- 使用之前需要在settings中开启
- pipeline在settings中,键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
- 有多个pipeline的时候,process_item方法必须return item,否则后一个pipeline取到的数据为None值
- pipeline中process_item的方法必须有,否则item没有办法接收和处理
- process_item方法接收item和spider,其中spider表示当前传递item过来的spider
- open_spider(spider):能够在爬虫开启的时候执行一次
- close_spider(spider):能够在爬虫关闭的时候执行一次
- 上述两个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立数据库连接,在爬虫关闭的时候断开数据库的连接
六、scrapy中间件的使用
1、scrapy中间件的分类和作用
1.1 scrapy中间件的分类
根据scrapy运行流程中所在位置不同分为:
- 下载中间件
- 爬虫中间件
1.2 scrapy中间件的作用
预处理request和response对象
- 对header以及cookie进行更换和处理
- 使用代理ip等
- 对请求进行定制化操作
在scrapy默认的情况下,两种中间件都在middlewares.py文件中,爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
2、下载中间件的使用方法
Downloader Middlewares默认的方法:
- process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象通过引擎交给调度器,此时不通过其他权重低的process_request方法
- process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Response对象:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
- 返回Request对象:通过引擎交给调度器继续请求,此时将不通过其他权重低的process_request方法
- 在settings.py中配置开启中间件,权重值越小越优先执行
3、定义实现随机User-Agent的下载中间件
3.1 在settings.py中添加UA列表
USER_AGENT_LIST = ["Mozilla/5.0 (Windows; U; Windows 98) AppleWebKit/532.16.1 (KHTML, like Gecko) Version/4.0.3 Safari/532.16.1","Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.0 (KHTML, like Gecko) Chrome/59.0.863.0 Safari/535.0","Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3 like Mac OS X; kl-GL) AppleWebKit/534.50.7 (KHTML, like Gecko) Version/4.0.5 Mobile/8B113 Safari/6534.50.7","Mozilla/5.0 (X11; Linux x86_64; rv:1.9.5.20) Gecko/7048-11-15 20:21:34 Firefox/11.0","Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10_8_0) AppleWebKit/531.1 (KHTML, like Gecko) Chrome/54.0.878.0 Safari/531.1","Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10_11_4; rv:1.9.6.20) Gecko/5511-07-04 09:40:02 Firefox/3.6.20","Mozilla/5.0 (compatible; MSIE 6.0; Windows NT 6.1; Trident/3.1)","Mozilla/5.0 (compatible; MSIE 6.0; Windows NT 5.0; Trident/3.0)","Mozilla/5.0 (Linux; Android 9) AppleWebKit/533.2 (KHTML, like Gecko) Chrome/23.0.863.0 Safari/533.2","Mozilla/5.0 (Windows; U; Windows NT 10.0) AppleWebKit/531.7.2 (KHTML, like Gecko) Version/4.1 Safari/531.7.2","Mozilla/5.0 (compatible; MSIE 5.0; Windows 95; Trident/5.0)","Mozilla/5.0 (iPad; CPU iPad OS 4_2_1 like Mac OS X) AppleWebKit/536.0 (KHTML, like Gecko) CriOS/36.0.810.0 Mobile/82Q614 Safari/536.0","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/3.1)","Mozilla/5.0 (iPad; CPU iPad OS 3_1_3 like Mac OS X) AppleWebKit/533.0 (KHTML, like Gecko) FxiOS/14.9o6822.0 Mobile/83W885 Safari/533.0","Mozilla/5.0 (Macintosh; PPC Mac OS X 10_10_0; rv:1.9.6.20) Gecko/5731-02-10 20:23:15 Firefox/6.0","Mozilla/5.0 (compatible; MSIE 8.0; Windows CE; Trident/3.0)","Opera/8.62.(Windows NT 6.2; zh-HK) Presto/2.9.168 Version/12.00","Mozilla/5.0 (Windows 98) AppleWebKit/536.1 (KHTML, like Gecko) Chrome/13.0.827.0 Safari/536.1","Opera/9.98.(Windows NT 6.1; pa-PK) Presto/2.9.188 Version/12.00"
]
3.2 在middleware.py中完善代码
import random
from douban.settings import USER_AGENT_LIST# 定义一个中间件类
class RandomUserAgent(object):def process_request(self, request, spider):ua = random.choice(USER_AGENT_LIST)request.headers['User-Agent'] = uaclass CheckUA:def process_response(self, request, response, spider):print(request.headers['User-Agent'])return response
3.3 在settings中设置开启自定义的下载中间件,设置方法同管道
DOWNLOADER_MIDDLEWARES = {'douban.middlewares.RandomUserAgent': 543,'douban.middlewares.CheckUA': 600,
}
4、代理IP的使用
4.1 思路分析
- 代理添加的位置:request.meta中增加proxy字段
- 获取一个代理IP,赋值给
request.meta['proxy']- 代理池中随机选择代理IP
- 代理IP的webapi发送请求获取一个代理IP
4.2 具体实现
class RandomProxy(object):def process_request(self, request, spider):proxy = random.choice(PROXY_LIST)print(proxy)if 'user_passwd' in proxy:# 对账号密码进行编码b64_up = base64.b64encode(proxy['user_passwd'].encode())# 设置认证request.headers['Proxy-Authorization'] = 'Basic' + b64_up.decode()# 设置代理request.meta['proxy'] = proxy['ip_port']else:# 设置代理request.meta['proxy'] = proxy['ip_port']
4.3 检测代理IP是否可用
在使用了代理IP的情况下,可以在下载中间件的process_response()方法中处理代理IP的使用情况,如果该代理IP不能使用可以替换其他代理IP
class ProxyMiddleware(object):......def process_response(self, request, response, spider):if response.status != '200':request.dont_filter = True # 重新发送的请求对象能够再次进入队列return request
在settings.py中开启该中间件
5、在中间件中使用selenium
七、scrapy_redis的概念、作用及流程
1、分布式是什么
分布式就是不同的节点(服务器,IP不同)共同完成一个任务
2、scrapy_redis的概念
scrapy_redis是scrapy框架的基于redis的分布式组件
3、scrapy_redis的作用
scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
通过持久化请求队列和请求的指纹集合来实现:
- 断点续爬
- 分布式快速抓取
4、scrapy_redis的工作流程
4.1 回顾scrapy流程
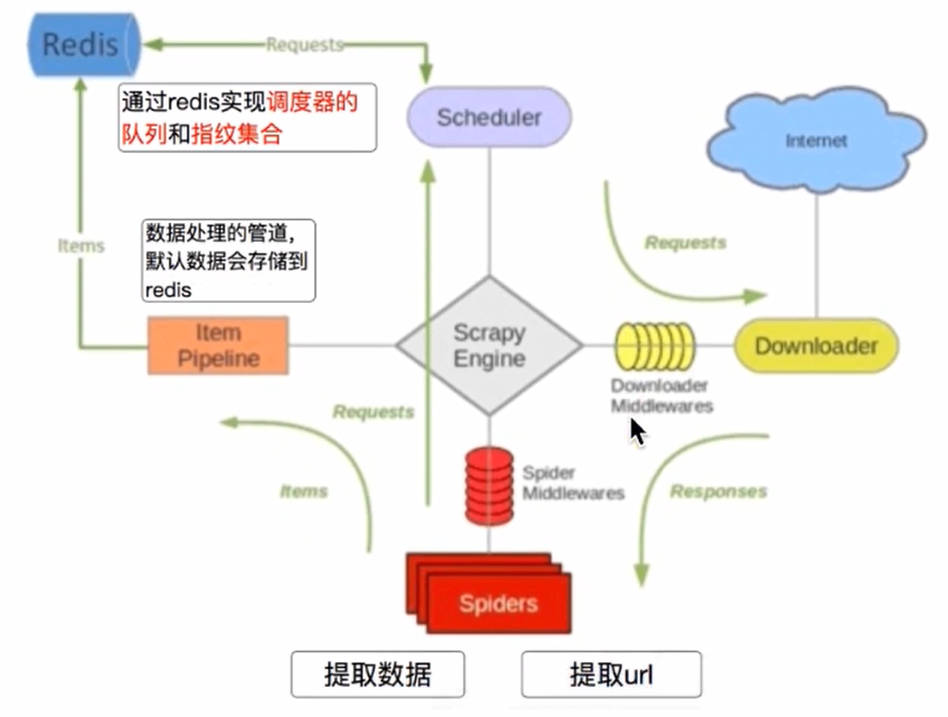
4.2 scrapy_redis的流程
- 在scrapy_redis中,所有待抓取的request对象和去重的request对象指纹都存在所有的服务器共用的redis中
- 所有服务器中scrapy进程共用同一个redis中的request对象的队列
- 所有的request对象存入redis前,都会通过该redis中的request指纹集合进行判断,之前是否已经存入过
- 在默认情况下所有的数据会保存在redis中
八、scrapy_redis原理分析并实现断点续爬以及分布式爬虫
未完待续