本文将结合典型实战案例,分析常见的造成卡顿等性能问题的原因。从系统工程师的总体角度来看 ,造成卡顿等性能问题的原因总体上大致分为三个大类:一类是流程执行异常;二是系统负载异常;三是编译问题引起。
1 流程执行异常
在这篇文章,Android卡顿掉帧问题分析之原理篇-CSDN博客,我们以滑动场景为例完整的分析了Android应用上帧显示的全流程(默认开启硬件绘制加速条件下)。下面我们用一张图来看看这个流程上可能引起卡顿、反应延迟等性能问题的点。
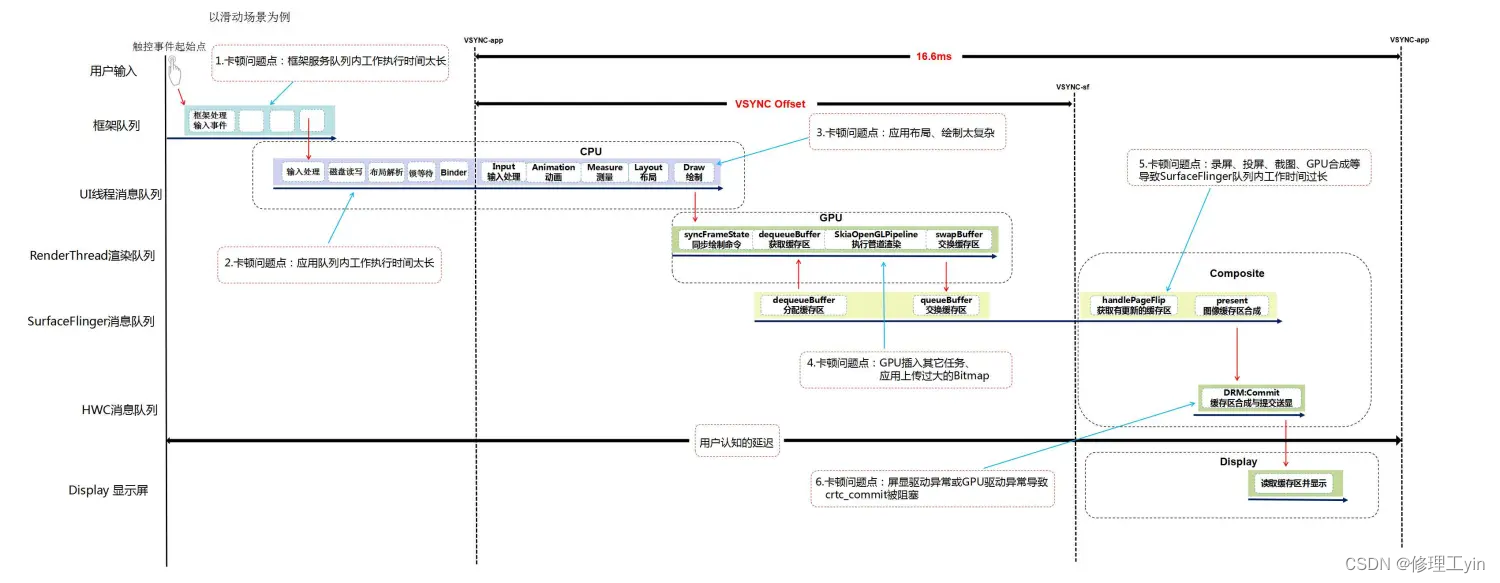
从上图可以看出,在Android应用上帧显示的各个流程上都可能出现问题导致出现卡顿、反应延迟等性能问题。下面我们分类来分析一下各个流程上可能的引起卡顿等性能问题的点。
1.1 system_server引起应用卡顿
一、理论分析
框架system_server进程内部的各个核心服务AMS、WMS、PKMS等,都有各自的对象锁和工作线程,各个服务运行时相互之间存在交互,可能出现某个线程持锁执行耗时操作而其它线程陷入长时间锁等待的情况。某些情况下当系统框架负载过重或流程出现异常情况下,其工作线程之间相互等锁的现象会非常严重。如果此时应用App的UI线程中有Binder请求,而系统框架内部处理请求的实现又恰好需要持锁,就可能间接导致应用App的UI线程阻塞在Binder请求,而引起App应用的卡顿问题。
二、典型案例分析
问题描述:设备刚开机时,桌面左右滑动出现卡顿。
问题分析:结合Systrace工具分析问题原因如下:

从以上问题Systrace的分析可以看出,出现桌面滑动卡顿的原因是:
桌面应用的UI线程(tid:4927)中通过Binder请求访问框架PKMS服务的getActivityInfo接口查询Activity的相关信息时出现长时间阻塞;
而框架PKMS服务中处理此Binder请求的线程(tid:5271)逻辑需要持锁执行,而当前此锁对象的“锁池”中至少已经有7个线程都已经在等待这把锁,所以此线程进入锁对象的“锁池”中阻塞等待锁释;
而此时持有该锁的线程为框架的android.bg工作线程(tid:2608),此线程中正持锁执行IO写磁盘等耗时操作,且线程的优先级较低,在刚开机阶段系统整体负载比较重的场景下,抢不到CPU执行时间片而长时间处于Runnable状态,导致运行时间较长
三、优化思路
针对此类system_server内部的各种锁等待或流程异常导致的性能问题。Google在历年的Android版本上也在不断针对优化,通过优化流程尽量的减少流程中不必要的持锁或减小持锁范围。例如在Android P上推出的LockFreeAnimation无锁窗口动画,就实现了无需持有WMS锁播放窗口动画,从而极大减少窗口动画卡顿的概率;Android 12上在 PackageManager 中,引入只读快照减少了 92% 的锁争用。另外各大手机厂商也会在自家的ROM系统上针对这种情况对框架作出持续的优化,通过分析持锁等待的关系,找到问题源头的当前持锁线程,利用一些空间换时间的缓存方案或优化CPU、IO等资源的调度与分配,减少线程的持锁的时长,从而改善其它线程锁等待的时长。
1.2 Input事件处理引起卡顿
一、理论分析
从前面Android卡顿掉帧问题分析之原理篇文章中的分析我们知道,屏幕驱动上报的Input事件要经过框架的InputReader和InputDispatcher线程的读取与分发,然后通过Socket发送到应用进程中,再经过界面View控件树的层层分发后消费处理。这个过程中任意一个流程出现阻塞就能造成用户的触控操作得不到及时的响应,出现用户感知的系统反应延迟或卡顿现象。
二、典型案例分析
问题描述:微博应用界面手势滑动退出时,界面卡住几秒钟才有反应。
问题分析:结合Systrace工具分析问题原因如下:
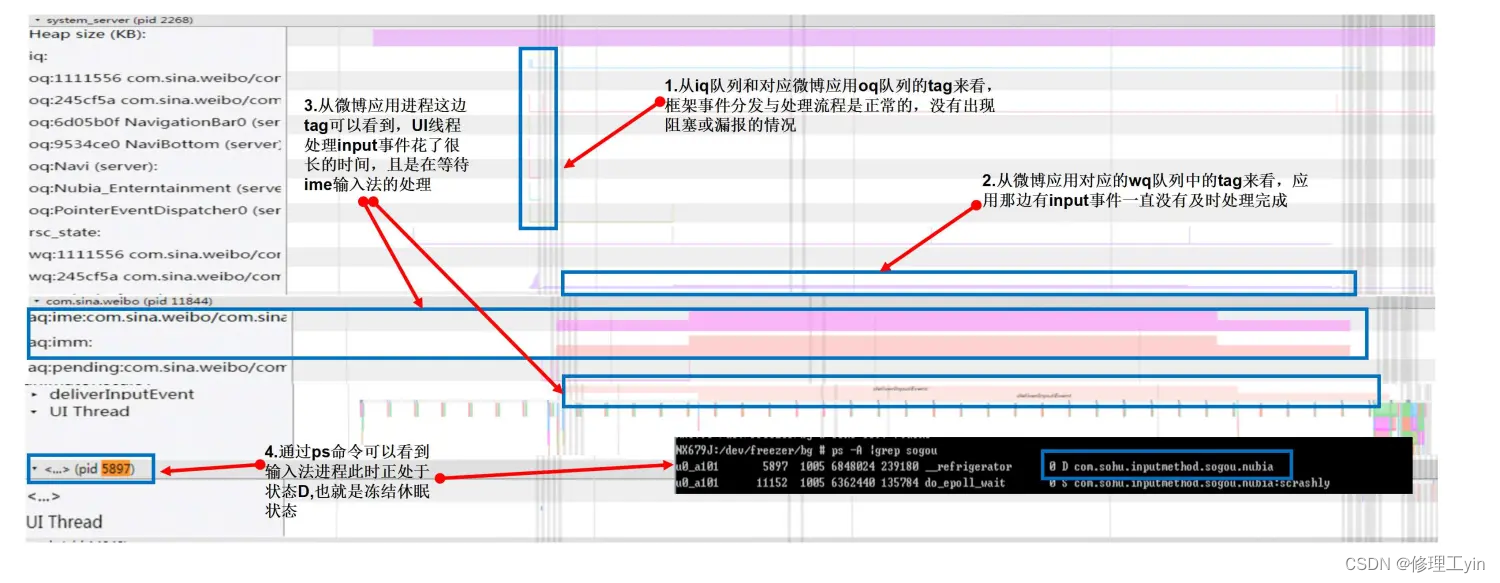
从以上问题Systrace的分析可以看出,退出应用界面时出现卡住几秒的原因:
- 首先看
Systrace上system_server进程中标识Input事件分发的"iq"和“oq”队列的信息,可以看到框架InputDispatcher对事件的分发处理没有出现阻塞或漏报等异常情况; - 从微博应用对应的
“wq”队列可以看到,应用进程一直有没有完成处理消费的Input事件,说明问题在微博应用进程侧; - 看
Systrace上微博应用侧的信息,可以看到应用UI线程很长一段的deliverInputEvent的tag(大概持续2.5秒左右),且“aq:ime”队列中显示有持续很长一段时间的事件处理逻辑。说明应该是在应用进程UI线程中判断Input事件类型为返回键的Key事件,所以先交给输入法应用进行处理,但是输入法进程一直没有完成处理,导致应用UI线程一直处于等待状态无法及时处理此Input事件,说明问题出现在输入法应用侧; - 然后我们用
ps命令查看当前输入法进程信息,发现输入法进程(pid:5897)当前的状态为“D”,说明处于进程“冻结”的休眠状态,结合Systrace上显示的输入法进程的主线程信息显示,发现其确实是一直处于Sleeping状态。所以此问题出现的原因就是因为输入法进程被异常“冻结”导致的。和负责维护进程“冻结”功能的同事沟通并分析日志后发现,问题的原因是用户安装并设置了新的输入法应用,进程“冻结”模块没有成功识别,将其认定为普通后台进程所以进行了“冻结”从而导致了异常。
到此还剩一个疑问就是为什么输入法进程都被“冻结”而休眠了,应用UI线程在等待2.5秒后还是能继续往下处理Input事件,并成功退出应用Activity界面呢?原因就是应用UI线程进入等待输入法处理Input事件时会设置一个超时,这个时长就是2.5秒,如果超时后输入法进程还是没有处理完,就会强行结束等待的逻辑,由应用UI线程继续往下处理Input事件。相关源码如下所示:
/*frameworks/base/core/java/android/view/inputmethod/InputMethodManager.java*/
...
/**
* Timeout in milliseconds for delivering a key to an IME.
*/
static final long INPUT_METHOD_NOT_RESPONDING_TIMEOUT = 2500;
...
// Must be called on the main looper
int sendInputEventOnMainLooperLocked(PendingEvent p) {if (mCurChannel != null) {...if (mCurSender.sendInputEvent(seq, event)) {...Message msg = mH.obtainMessage(MSG_TIMEOUT_INPUT_EVENT, seq, 0, p);msg.setAsynchronous(true);mH.sendMessageDelayed(msg, INPUT_METHOD_NOT_RESPONDING_TIMEOUT);//1.处理Input事件时设置一个2500ms的超时检查return DISPATCH_IN_PROGRESS;}...}return DISPATCH_NOT_HANDLED;
}
...
case MSG_TIMEOUT_INPUT_EVENT: {finishedInputEvent(msg.arg1, false, true);// 2.时间到之后如果输入法还是没有完成Input事件处理,则强行结束输入法对事件的处理逻辑return;
}
...三、优化思路
对用户触控事件的响应速度直接关系到用户对交互设备性能体验的感知,所以一直以来都是系统性能优化工作的重中之重。多年来谷歌,包括SOC厂商都有针对系统Input事件的处理流程作出优化,以提升触控响应速度。例如高通基线上在2018年左右就有一笔提交,优化应用进程侧的Input事件处理流程,大概思路就是识别应用UI线程中收到第一个ACTION_DOWN的Touch事件后,调用sendMessageAtFrontOfQueue接口在应用UI线程的消息队列的最前面插入一帧doFrame绘制任务,这样界面不用等待下一个Vsync的信号的到来就能直接上帧显示,从而减少整个Input触控事件的响应延迟。从Systrace上表现如下图所示:

国内各大手机厂商也有各自的优化方案。比如硬件上采用触控采样率更高的屏幕,屏幕触控采样率达到240HZ甚至480HZ。再比如监控到触控事件后提升CPU主频,提升触控事件处理相关线程和渲染线程的优先级等方式,从而优化事件触控响应速度。而对于应用APP开发者来说,需要做的就是避免在Input触控事件的分发处理流程中执行耗时操作,以免引起触控延迟或卡顿等性能问题。
1.3 应用UI线程耗时引起卡顿
一、理论分析
这部分逻辑主要由应用APP开发者控制。根据前文Android卡顿掉帧问题分析之原理篇中的分析可知,UI线程耗时过长必然会导致Vsync周期内应用上帧出现超时。特别是屏幕高刷时代的到来,留给应用UI线程处理上帧任务的时长越来越短。例如120HZ的高刷屏幕配上,一个Vsync信号周期已经缩短到8ms左右。这要求应用APP开发者能写出更加高性能质量的代码。应用UI线程耗时引起的卡顿往往涉及的因素比较多,下面列举一些常见原因:
UI线程消息队列中存在除doFrame绘制任务外的其它耗时任务,导致Vsync信号到来后,无法及时触发UI线程执行doFrame绘制上帧任务,而导致掉帧。例如界面布局XML文件的inflate解析,如果界面布局文件比较复杂,就会有大量的IO与反射等耗时操作。又或者UI线程中有decodeBitmap解析大图片的耗时操作。UI帧的doFrame绘制任务处理耗时过长导致掉帧。最常见的问题就是应用界面布局存在过度绘制,导致measure/layout/draw任务的计算复杂度成倍上升。再比如应用界面布局中的部分View控件层面如果关闭了硬件绘制加速,就会触发View#buildDrawingCache的耗时操作,从而导致整个draw动作耗时过长而引起掉帧。UI线程存在大量的阻塞等待导致上帧超时。UI线程陷入阻塞等待,常见的原因就是跨进程的Binder调用阻塞和进程内的同步锁竞争等待。还有一类情况就是频繁的GC内存回收引起(一般为进程内存抖动或内存泄露引起)。
二、典型案例分析
问题描述:三方应用书旗小说界面上下滑动严重掉帧卡顿。
问题分析:结合Systrace工具分析问题原因如下:
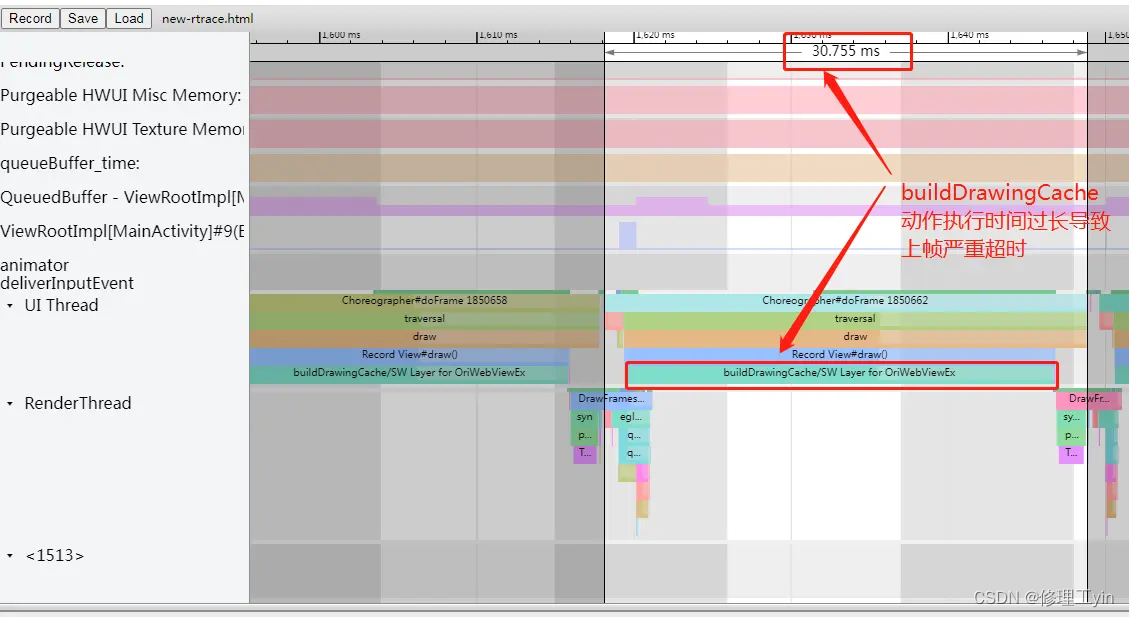
从Systrace上可以看到,应用UI线程上帧的doFrame流程中主要耗时点在buildDrawingCache的流程上。下面我们结合源码来看看什么情况下draw流程中会出现buildDrawingCache的动作:
/*frameworks/base/core/java/android/view/View.java*/
...
public RenderNode updateDisplayListIfDirty() {...if (layerType == LAYER_TYPE_SOFTWARE) { //判断View的layerType为LAYER_TYPE_SOFTWARE,也就是关闭了硬件绘制加速,执行buildDrawingCachebuildDrawingCache(true);...}else{...draw(canvas); //走硬件绘制加速的流程...}....
}
...从代码可以看出当判断某个View空间的layerType为LAYER_TYPE_SOFTWARE,也就是关闭了硬件绘制加速的情况下,就会触发走到buildDrawingCache的耗时逻辑中。所以此问题就是由于书旗小说应用的界面布局中一个名为OriWebViewEx 的View控件关闭了硬件绘制加速导致。
问题描述:Twitter应用界面上下滑动严重掉帧卡顿。
问题分析:结合Systrace工具分析问题原因如下:
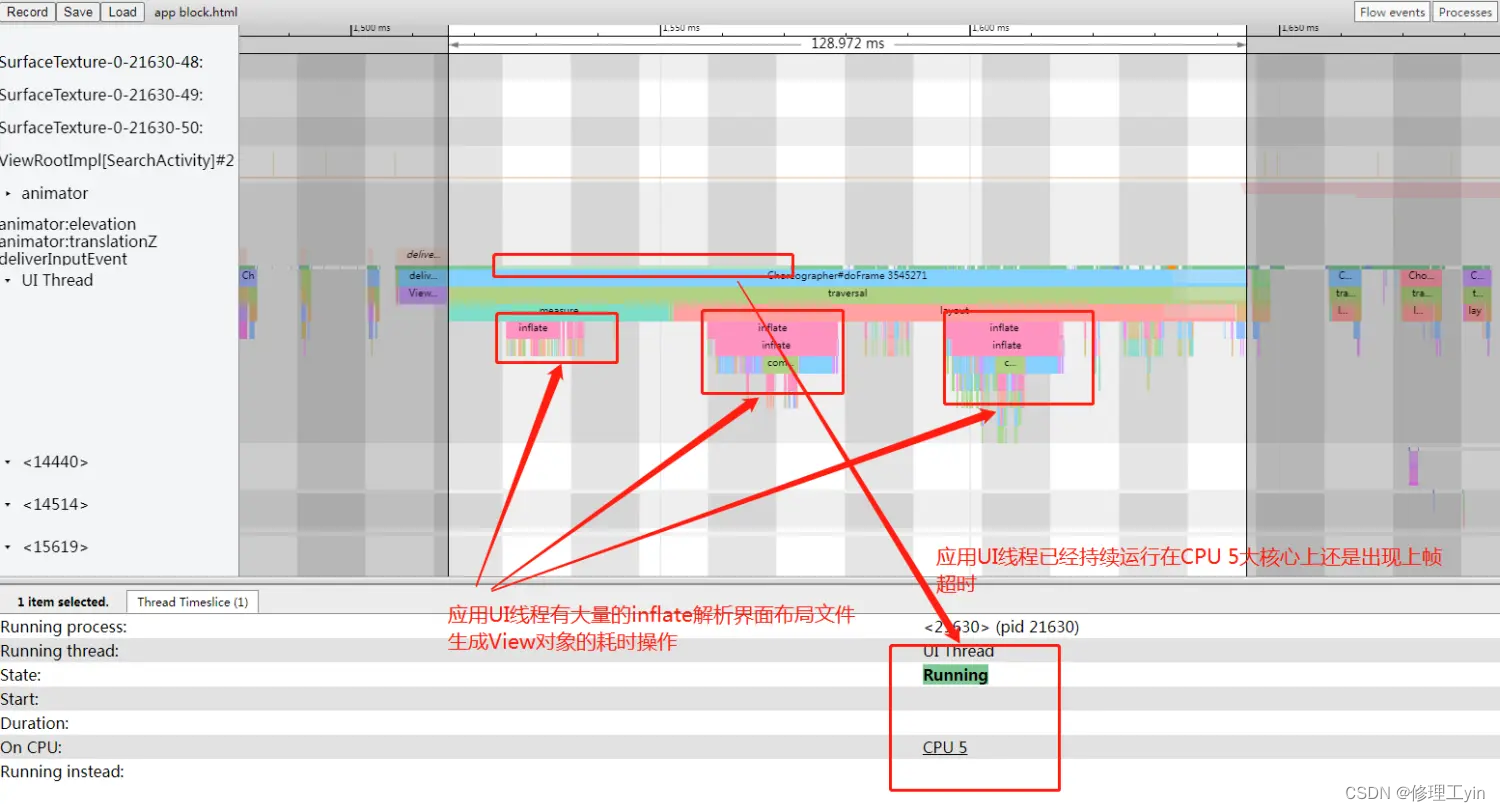
从Systrace上可以看到,三方应用Twitter出现掉帧的主要原因是:其UI线程中存在大量耗时的inflate解析xml布局文件的操作,且出现问题时UI线程已经持续Running到CPU 5大核心上但是还是出现严重的上帧超时。
三、优化思路
针对应用UI线程耗时引起卡顿的问题,原则就是尽量减轻UI线程的负担。针对不同的引起问题原因,常见的优化思路大致如下:
- 异步处理:各种耗时操作尽量放到子线程异步处理。比如使用
View的异步线程inflate方案;decodeBitmap加载图片的耗时操作移到子线程统一处理等。 -
逻辑优化:必须要在主线程执行的逻辑应尽量优化,减少计算频次,避免重复计算。比如采用约束布局解决嵌套过多的问题,避免过度绘制;优化应用的内存占用,避免内存泄露、内存抖动等问题,从而减少
GC触发的次数;优化内部代码逻辑,尽量减少主线程陷入同步锁竞争等待的状态;原则上不要主动去关闭硬件绘制加速。 -
流程复用:能复用的逻辑尽量复用,以避免多次调用产生的性能开销。比如
ListView的Adapter中实现View的复用,减少View的inflate执行次数。另外UI线程中Binder请求框架查询一些系统信息,能够一次查完就不要分多次执行。且查询结果应尽量缓存在内存中实现复用,避免多次反复的查询造成主线程频繁陷入Binder阻塞等待。
1.4 SurfaceFlinger耗时引起卡顿
一、理论分析
前文的分析可以知道,SurfaceFlinger在Android系统的整个图形显示系统中是起到一个承上、启下的作用,负责收集不同应用进程Surface的绘制缓存数据进行的合成,然后发送到显示设备。所以,如果SurfaceFlinger的处理流程上出现耗时或阻塞,必然会导致整个应用的上帧显示的流程出现超时而掉帧。特别是随着屏幕高刷时代的到来,Vsync周期不断缩短,留给SurfaceFlinger处理的时间也越来越短,对SurfaceFlinger的性能提出了更高的要求。这也是谷歌、SOC厂商包括各大手机厂商做系统性能优化的重点。
二、典型案例分析
问题描述:设置120HZ高刷模式下,手机录屏、投屏场景下出现帧率下降。
问题分析:结合Systrace工具分析问题原因如下:
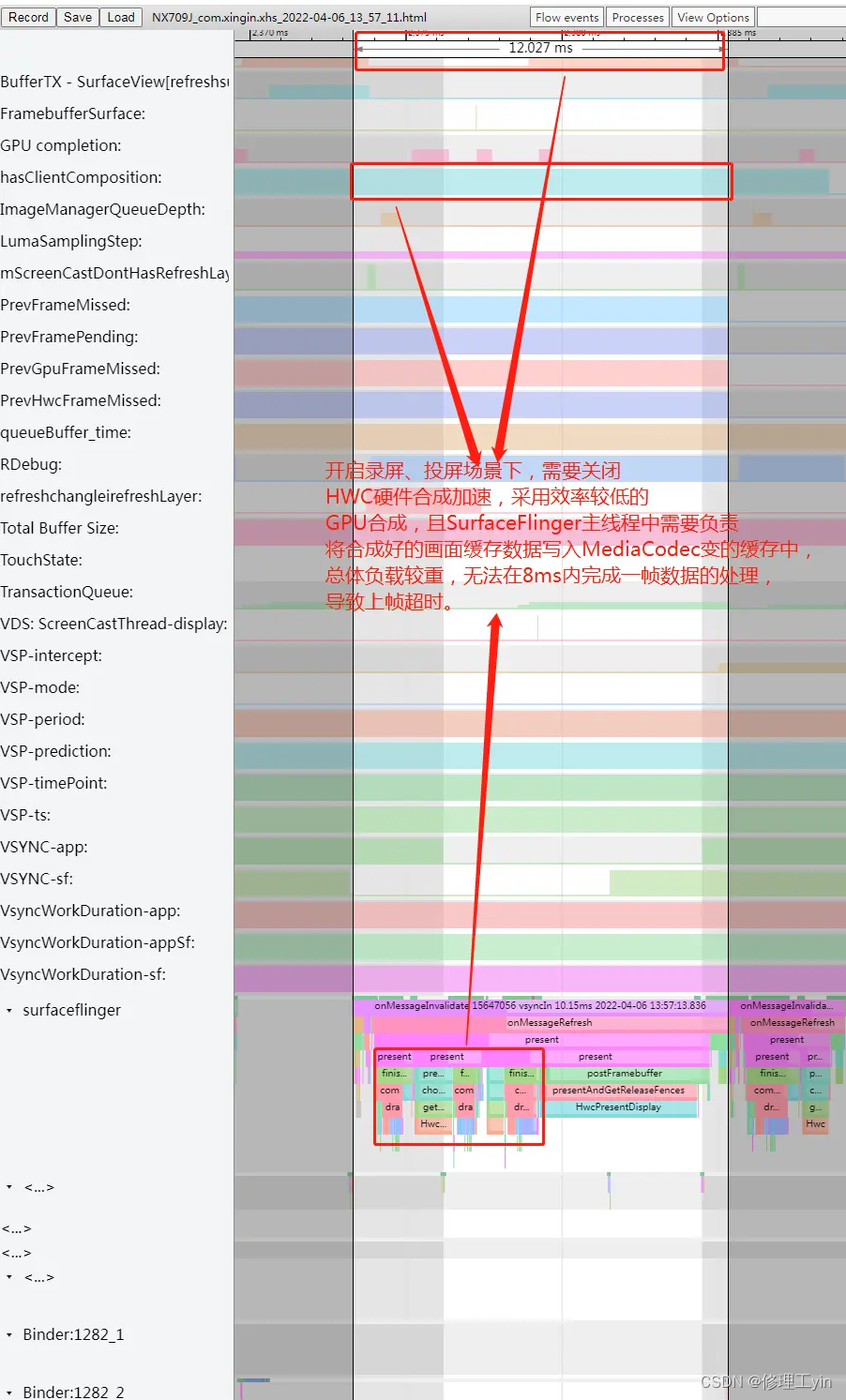
从Systrace上可以看到,开启录屏或投屏后,部分Layer需要采用效率更低的GPU合成方式(主要是因为高通平台HWC不支持回写),SurfaceFlinger的主线程中需要实现drawLayers的动作,还需要将图层数据写入到MediaCodec缓存中,总体负载较高,导致在8ms(120HZ高刷模式下)内无法完成一帧数据的处理而出现帧率下降的问题。
三、优化思路
针对SurfaceFlinger引起的性能卡顿问题,常见的优化思路有:
- 谷歌通过
cpuset的配置,默认场景下SurfaceFlinger只能使用4个CPU小核心运行;部分厂商会在投屏或录屏等负载比较重的场景下放开这个限制,让SurfaceFlinger进程能跑到CPU大核心上。 - 部分厂商在开启录屏的情况下,会锁定屏幕刷新率最高不超过
60HZ,以减轻SurfaceFlinger进程的压力。 Android 12上,谷歌就将各个应用对应的BufferQueue的管理工作移动到应用进程侧处理,以减轻SurfaceFlinger进程的负载。
2 系统负载异常
CPU、GPU、内存、磁盘等都是系统内各个进程任务的运行所必需的公共系统资源。这就涉及到一个复杂的资源调度与分配的问题,实现将系统资源与各个不同进程的需求进行合理的匹配,以保证进程任务能够流畅的运行。这就涉及到两个问题:
- 这些系统公共资源是否充足。比如当进程需要时,当前
CPU核心的运行主频算力是否足够高,系统剩余内存是否足够大,磁盘的读写速度是否足够快。 - 这些系统资源的分配是否合理。比如当前优先级更高的前台应用进程相对于后台进程是否能获得更多的
CPU调度运行时间片和I/O带宽等资源,以保证界面的流畅运行。
从软件的角度出发,每个应用任务进程都希望自己获得无限的CPU算力、无限的内存资源分配等能力,以保证其能够流畅的运行。但是从硬件的角度出发,各种系统的公共资源配置都是有限的,不可能无限的提供给每个任务进程,且在移动设备上还要考量功耗与发热的问题,需要限制各种系统资源的供给。所以如何协调这种供需关系之间的矛盾,将宝贵的系统资源合理的分配给当前最需要的任务进程,以最小的资源开销保证系统的流畅运行,就是考验操作系统的设计者和性能优化工程师的功力的问题,弄不好就可能出现应用任务进程的运行受限于系统运行资源的分配而出现各种性能问题。
2.1 CPU调度引起卡顿
一、理论分析
CPU算力资源绝对是系统内最重要的公共资源之一,每个应用程序的正常运行都需要CPU的调度执行。目前的主流移动设备搭载的CPU基本上都是采用多核心架构设计,按照算力的大小设置有多颗CPU运算核心(以高通的骁龙8 gen 1处理器为例,其拥有8颗CPU运算核心,包含四个小核、三个中核和一个大核,算力依次递增,功耗也逐渐增大)。

且Linux操作系统内核中会有相应的scheduler和governor调度器,来管理每颗CPU核心上当前运行的任务的排程,以及每颗CPU核心当前运行的主频(每颗CPU核心都有一个运行主频参数可以支持在一定的范围内动态调节,主频越高算力越强,相应的功耗也就越大)、节能状态等参数,以达到最佳的性能与功耗的平衡。但是很多时候由于CPU运行核心上的任务排布不合理,或运行主频过低导致的算力过低,无法满足应用进程的需求,就可能导致应用出现卡顿掉帧等性能问题。常见的一些原因如下:
- 后台应用进程任务持续运行抢占
CPU运行资源,或者处于功耗管控直接关核,导致前台应用的UI线程任务无法及时的获得CPU运行算力执行,长时间处于Runnable状态,而出现上帧超时掉帧问题; - 某些时候出于功耗与发热的考量,将
CPU的运行主频压的过低,导致算力不足。应用的上帧线程上的任务需要Running很长一段时间,而出现上帧超时掉帧。
二、典型案例分析
问题描述:腾讯视频应用中观看视频时,播放弹幕卡顿。
问题分析:结合Systrace工具分析问题原因如下:
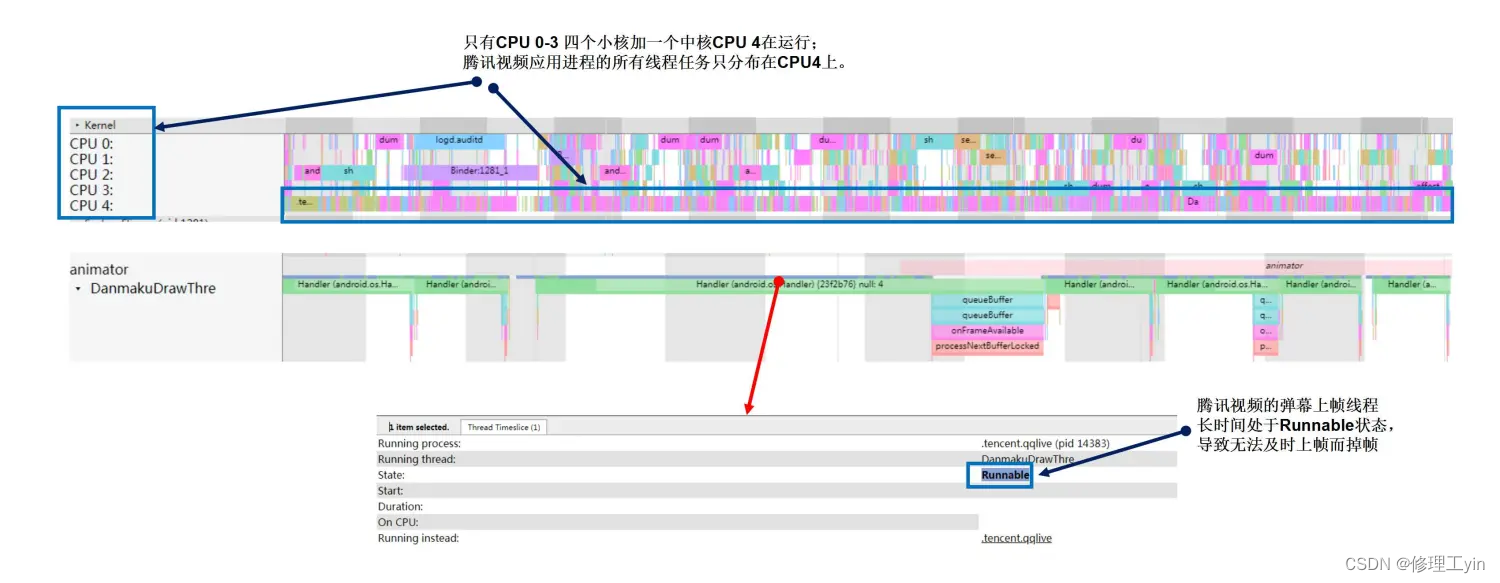
从Systrace上可以看到:腾讯视频播放视频时出现掉帧卡顿的原因,是因为其负责弹幕上帧的线程无法获得CPU运行资源,而长时间处于Runnable状态,导致上帧出现严重超时。
进一步分析原因发现存在两个问题:一个就是看CPU Trace信息发现此时只有CPU 0-3四个小核心和一个CPU 4一个中核心在运行,而算力更强的CPU 5-7都处于关闭状态,导致系统总体算力受限;另一个问题就是前台应用腾讯视频进程内的所有线程运行任务都只分配到CPU 4上运行,其它几个小核心处于空闲状态也没有使用,导致腾讯视频应用的运行严重受限。
最终经过分析找到问题的根本原因就是:一、关闭算力更强的CPU 5-7的原因,是系统组为了降低用户全屏看视频场景下的功耗而故意为之;二、腾讯视频只能运行在CPU 4上的原因,是因为该项目使用的是高通最新的SM8450平台,该平台采用ARM V9架构设计,32位的应用只能使用CPU4-6三个中核运行,而应用商店提供的腾讯视频刚好就是32位的版本。
至此问题水落石出,后面解决问题思路就是:一方面推动应用商店上架腾讯视频64位版本;二是系统组那边需要针对32位的应用前台全屏看视频的场景下的CPU配置做出调整,不再全部关闭CPU 5-7三个算力较强的核心。
问题描述:桌面界面左右滑动出现卡顿掉帧。
问题分析:结合Systrace工具分析问题原因如下:
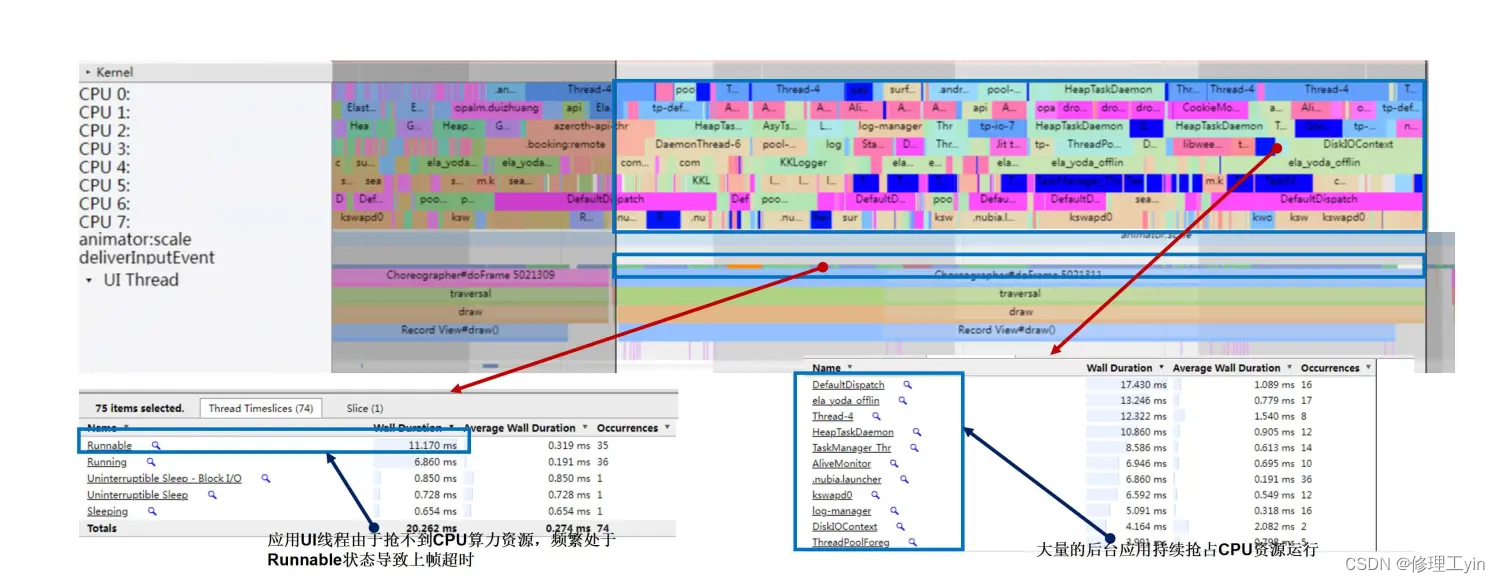
从Systrace上可以看到:前台应用桌面出现掉帧的原因是其UI线程抢不到CPU运算资源而长时间处于Runnable状态。而此时,CPU上分布有大量后台应用的任务持续运行。出现这个问题的原因是国内部分应用存在很多进程保活机制,会在后台持续运行,并想方设法提升其进程的优先级。所以在系统关闭了相关针对性的管控后就会出现问题。
三、优化思路
针对CPU调度问题引起的性能卡顿问题,常见的优化思路有:
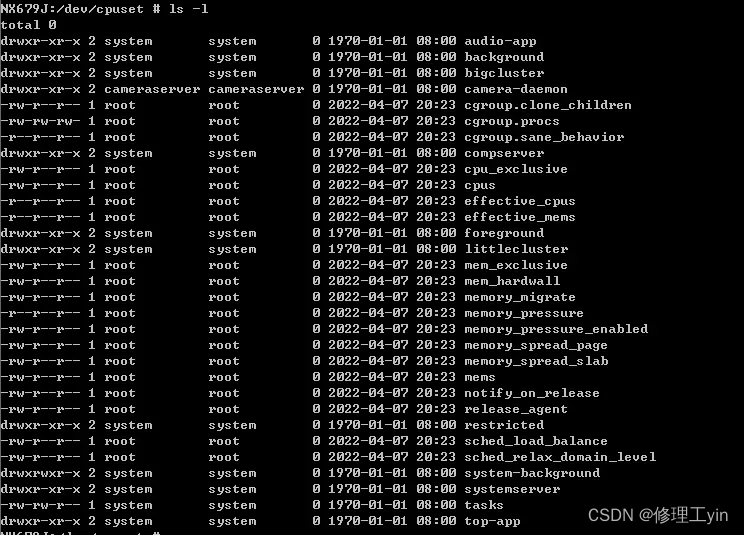
1. 基于cgroup的进程资源隔离。Android系统上继承了linux的cgroup机制,以控制进程的资源占用,让重要的进程获得更多的系统资源。涉及的系统资源如下图所示:

其中cpuset(可以实现限制进程只能运行在指定的CPU核心上)、cpuctl(可以实现控制前后台进程的CPU用量)和freezer(可以实现控制进程处于冻结休眠状态,完全放弃CPU执行权)就是对进程CPU资源的控制。后面的top-app标识当前进程所属的资源分组。cgroup机制中会将不同的运行进程分成不同的资源组,比如前台应用属于top-app组,后台应用属于background组。不同的组可以支持配置不同的资源使用权限(比如通过cpuset的配置,background组中的进程被限制只能运行在cpu 0-3三个小核心上,而处于top-app组中的进程可以使用所有的cpu核心资源)。以cpuset为例,如下图所示:
![]()
通过这种限制后台不重要的进程的CPU资源占用,从而让前台重要的应用进程获得更多的CPU资源(至于进程的前后台优先级定义,主要是由框架AMS服务来管理维护,通过写进程的oom_score_adj值来标识)。国内各大手机厂商的系统性能优化的策略中,有很大一部分工作都是依赖于cgroup机制来实现的,通过对系统资源精细的定义划分,和应用进程优先级与功能场景的精准识别,来实现对资源的合理分配,达到性能与功耗的最佳平衡。
2. 基于场景识别的CPU调度策略配置。主要工作包括:
- 对
CPU基础配置影响各核的性能输出:包括CPU Frequency运行主频调节、排程器大核小核工作分配策略upmigrate/downmigrate/sched_boost的调节(根据CPU各核心的任务负载,对线程任务进行大小核分布的迁移调整),以上都是通过Soc厂商提供的Perf服务接口设置参数,去写相关的设备节点实现,以高通平台为例相关节点如下图所示:

还有温控策略的配置调整(出于功耗与发热的考量,移动设备上温控机制thermal-engine服务,会根据遍布设备内部的各个温度传感器读取的温度值,按照一定的温度阈值对CPU运行主频进行限制,以防止设备过热);
- 对场景的定义识别与策略配置:比如定义应用冷启动场景,在框架进行识别,并动态将
CPU主频进行拉升一段时间,以提升应用打开速度;定义视频播放的场景,在框架进行识别,然后对CPU主频进行限频,在保证播放流畅的前提下,尽量降低功耗和发热;这块也属于国内各大手机厂商的系统性能优化的核心工作。如何实现精确的场景定义与识别,精准控制CPU的性能输出,用最小的功耗,保证应用界面的流畅运行,就是对厂商功力的考验。
3. 对三方应用后台相互唤醒和进程保活机制的限制,防止其在后台持续运行抢占CPU算力资源。这块也是国内各大手机厂商系统优化的重点工作之一。
2.2 GPU调度引起卡顿
一、理论分析
GPU算力资源是继CPU算力外,系统内另一个重要的公共资源,从前文Android应用上帧显示的流程分析可知,应用对每一帧画面的渲染处理都离不开GPU算力的支撑。和CPU类似,设备的GPU也有自己的运行主频(运行主频越高,算力越强,同时发热也就越大),且支持在一定的范围内调节,以实现功耗和性能的最佳平衡。以高通SM8450平台所搭载的型号为Adreno 730的GPU为例,其参数信息如下图所示:
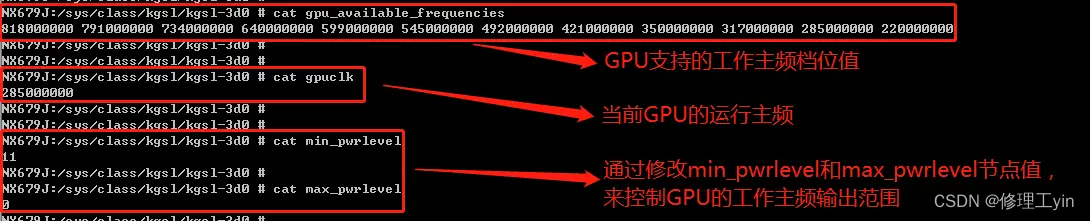
从上图可以看到,GPU支持在一定的范围内动态调节运行主频,Soc厂商和国内的手机厂商会根据任务负载和使用场景,动态调节GPU的工作频率以实现功耗与性能的最佳平衡。但是如果调节不合理,就可能引起性能问题,常见的一些原因如下:
- 部分大型游戏应用(如原神)需要大量的
GPU算力进行游戏画面的实时渲染处理,如果系统的GPU运行主频算力没有及时的跟上来,无法满足应用对GPU算力的需求就会导致游戏应用上帧时出现阻塞超时而掉帧; - 部分应用在后台利用
GPU做一些图像处理的并行计算,抢占了系统的GPU算力资源;就可能导致前台应用绘制上帧时,由于GPU算力不足,使其渲染线程陷入长时间阻塞等待GPU渲染完成的Fence信号的状态,最终出现上帧超时卡顿的问题。
二、典型案例分析
问题描述:三方应用UC浏览器界面滑动卡顿。
问题分析:结合Systrace工具分析问题原因如下:
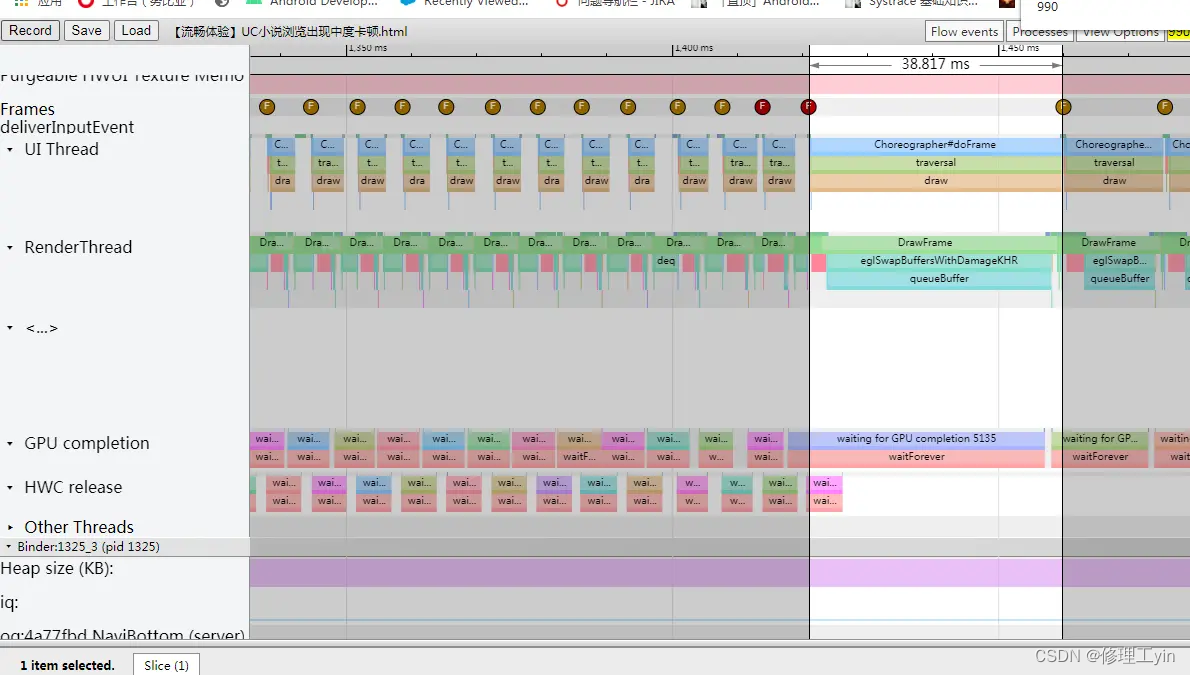
从上图的Systrace可以看出,UC浏览器出现上帧超时的主要原因是,其RenderThread渲染线程长时间阻塞在queueBuffer上帧的流程上,而queueBuffer阻塞在SurfaceFlinger进程那边的Binder响应,而SurfaceFlinger进程中又需要等待GPU那边完成画面渲染处理的fence信号的(从应用进程侧的waiting for GPU completion的systrace tag也能看出)。如下简化代码所示:
/*frameworks/native/libs/gui/BufferQueueProducer.cpp*/
status_t BufferQueueProducer::queueBuffer(int slot,const QueueBufferInput &input, QueueBufferOutput *output) {ATRACE_CALL();...// Wait without lock heldif (connectedApi == NATIVE_WINDOW_API_EGL) {// Waiting here allows for two full buffers to be queued but not a// third. In the event that frames take varying time, this makes a// small trade-off in favor of latency rather than throughput.lastQueuedFence->waitForever("Throttling EGL Production"); // 等待GPU fence信号}return NO_ERROR;
} 也就是说,问题出在系统的GPU算力资源比较紧张。后来分析应用掉帧的同一时间段系统的其它运行进程的systrace表现,发现系统的图库应用正在执行一些Bitmap图像处理的动作。再结合日志分析后与负责图库的同事沟通,最终找到问题的根本原因所在:图库应用中有一个事物分类相册的功能,当时正在后台使用GPU进行照片图像的特征识别与处理的逻辑,抢占了系统GPU算力资源,从而导致前台UC浏览器应用的渲染线程阻塞在等待GPU的fence信号的流程而出现掉帧。
三、优化思路
针对GPU调度问题引起的性能卡顿问题,常见的优化思路有:
- 基于场景的
GPU调度策略配置。这块主要是结合前台应用场景的需求,动态调节GPU的运行主频等参数,以最小的功耗满足应用的性能需求。这块考验各大手机厂商的调教水平,也是厂商进行游戏优化调教的重点工作之一。 - 后台应用进程抢占
GPU算力资源的管控。主要是限制后台应用的运行,防止其出现抢占GPU算力资源的行为,以保证前台应用的流畅运行。
2.3 低内存引起卡顿
一、理论分析
内存也绝对算的上是一个重要的系统公共资源,系统内任何进程的正常运行都需要消耗一定的内存资源。一般来讲设备的RAM硬件物理内存的大小是固定且有限的(4G、8G或12G等),而系统内运行的所有进程都需要共享这些有限内存资源。如何用有限的内存资源去满足系统各个应用进程无限的需求,这就涉及到一个系统内存管理的逻辑。这是一个复杂的问题,几乎贯穿了整个Android系统的各个层级。从Linux内核到Art虚拟机,再到Framework框架,甚至到APP应用,都会有各自的内存管理的策略。关于Android系统的内存管理的详细逻辑,由于篇幅所限本文就不详细展开。我们以systemui应用进程为例,来看看一个普通应用进程的内存占用分布:

合理的内存的分配与管理无论对系统和应用来讲都至关重要。因为内存问题既能引发稳定性问题,也能引发卡顿性能问题。下面我们分别来分析一下:
1. 内存引起的稳定性问题:
- 因为系统总的内存资源是有限的,为了防止单个应用进程无限制的占用内存资源,
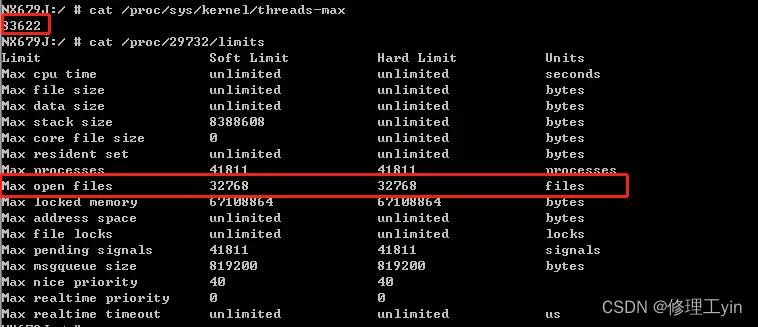
Android系统设计了很多机制来遏制这种情况的产生。比如在虚拟机层面,谷歌设计对每个应用进程占用的Dalvik Heap的内存大小做出了限制,超过一定的阈值(记录在dalvik.vm.heapgrowthlimit的property中,一般为256M),就会触发OutOfMemeory的异常,导致应用进程崩溃。此外Android系统还引入了lmkd低内存守护机制,当系统总的可用内存低于一定的阈值,就会按照进程优先级,将占用内存比较大的应用进程杀掉。 32位的应用虚拟内存的寻址空间最大为4G,当应用进程的虚拟内存占用超过4G时,就无法继续为其分配内存,产生OOM类型的报错,出现应用崩溃或黑屏等问题。- 另外
Android系统基于Linux内核,也绩承了Linux系统对应用进程的相关限制。如果应用进程中开启的线程过多(每创建一个空线程也会有一定的内存开销),超过/proc/sys/kernel/threads-max中定义的上限,也会报出OOM异常导致应用进程崩溃;再比如应用进程中打开的文件句柄过多,超过/proc/pid/limits节点中的定义上限,也会报出OOM异常导致应用进程崩溃。如下图所示:
2. 内存引起的性能性问题:
-
当应用出现内存抖动或内存泄露的问题时,就会导致虚拟机的
GC频繁工作,甚至触发stop-the-world事件,造成应用的UI线程出现挂起阻塞,最终导致上帧出现超时而掉帧。 -
当后台活跃运行的应用进程过多时,会造成系统总体的剩余内存偏低。此时主要有两个问题可能会造成应用的卡顿:
a、当内存
zone处于低水位时,内核会频繁唤醒kswapd的线程起来执行内存回收的动作;另外内核PSI内存压力信号也会频繁唤醒lmkd进程,进行扫描和杀进程。这些动作都会占用CPU运行资源,导致前台应用UI线程由于抢不到运行CPU资源而出现长时间处于Runnable的问题;b、当系统内存不足时,
kswapd的线程被唤醒进行内存回收,会将page cache内存页中已经缓存的磁盘文件信息进行大量释放,导致应用进程中的一些IO读文件操作(比如view读文件,读配置文件、读odex文件等),由于page cache无法命中,触发缺页中断,陷入内核态阻塞等待,一直等到readahead机制从磁盘中将文件内容全部读取出来才能释放返回。当大量进程在进行IO操作时,又进一步加重底层IO的阻塞时长。最终导致前台应用的UI线程长时间处于Uninterruptible Sleep - Block I/O的状态而出现上帧超时卡顿问题。
二、典型案例分析
问题描述:在三方应用唯品会的首页界面上下滑动严重掉帧卡顿。
问题分析:结合Systrace工具分析问题原因如下:
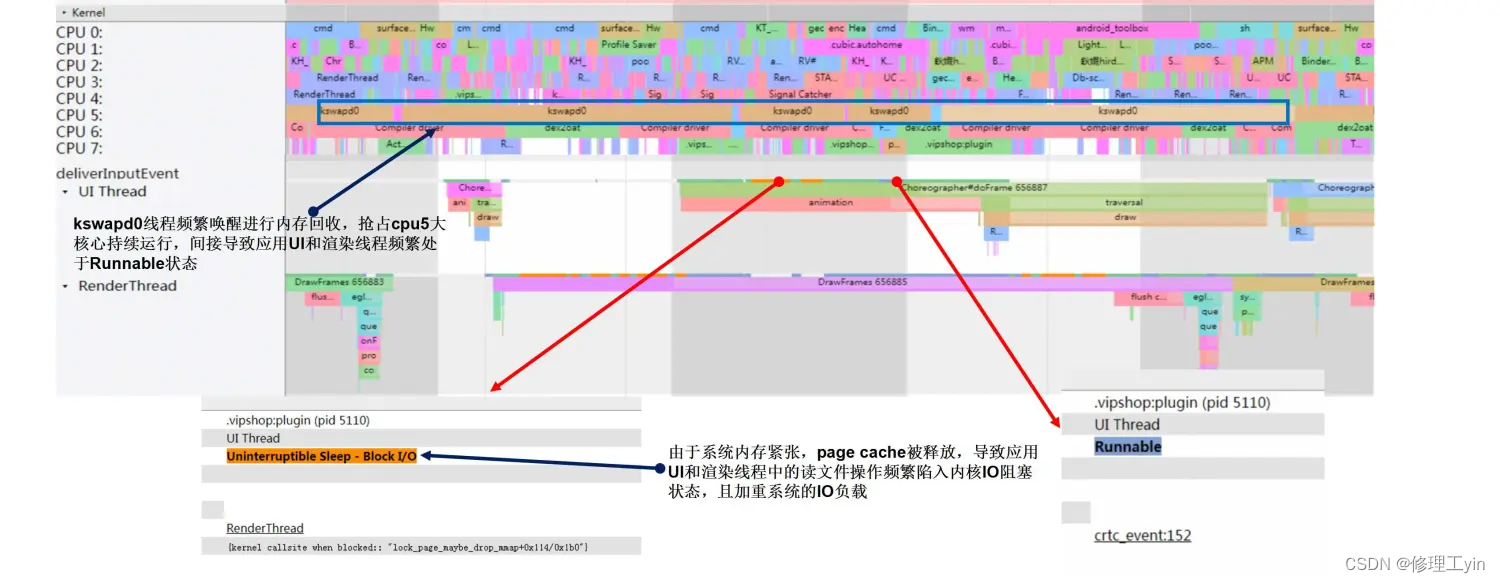
从Systrace上可以看到,唯品会应用出现掉帧卡顿的主要原因如下:
- 系统内存紧张,频繁唤醒
kswapd0线程进行内存回收操作,其持续抢占CPU 5大核心运行,导致应用的UI线程和RenderThread渲染线程频繁出现抢不到CPU资源得不到执行,而处于Runnable的状态,从而导致应用上帧超时而掉帧; - 系统内存紧张时,
page cache磁盘文件缓存被内存回收,导致应用的UI线程和RenderThread渲染线程中的一些IO读文件操作无法命中page cache缓存而频繁陷入内核Uninterruptible Sleep - Block I/O的状态,导致应用上帧超时而掉帧。
三、优化思路
针对内存问题引起的性能卡顿问题,常见的优化思路有:
1. 在应用进程侧:作为应用开发者:
-
需要解决应用自身的内存泄漏问题,避免频繁的内存分配回收出现的内存抖动现象;
-
并尽量优化应用的内存占用,包括优化图片加载占用、采用内存更高效的数据结构(如
ArrayMap)、采用对象池和图片复用等内存复用机制、功能比较复杂的应用采用多进程方案、尽量优化应用APK包体积大小、监听onTrimMemory事件并及时释放内存中的不必要缓存等; -
尽量不要做一些应用进程保活的机制,以免增加系统总体的内存负担;
-
将应用升级适配到64位版本,以免陷入虚拟内存耗尽而进程崩溃的局面。
使用Android Studio自带的Profile分析工具进行内存分析与优化,具体用法可以参考这篇文章:https://www.jianshu.com/p/72b213fa6a26。
2. 在系统总体层面:这部分内容主要属于谷歌和手机厂商的工作,常见的一些针对性优化手段有:
-
调整
lowmemorykiller的杀进程的门限值,让其提前介入清理掉一些低优先级的进程而释放内存,以免系统陷入低内存状态; -
适当提高
extra_free_kbytes值,让kswapd线程能提前介入进行内存回收,以免系统陷入低内存状态; -
框架中设计后台应用查杀功能,定期清理后台低优先级应用进程,并限制三方应用的后台保活机制,从而释放内存,以免系统陷入低内存状态;
-
通过
cpuset配置限制kswapd不让其使用部分CPU大核,从而让出CPU资源给前台应用的UI和渲染线程使用; -
配置和启动
ZRAM和app compaction后台内存压缩机制,从而减少应用进程后台的内存占用,腾出更多的系统可用内存; -
优化系统的磁盘
IO性能,采用UFS3.1等性能更强的存储器,以减轻系统出现内存低的情况时,出现IO阻塞的时长。
2.4 磁盘I/O引起卡顿
一、理论分析
磁盘是现代计算机系统实现数据持久化存储的核心硬件模块。也是继CPU和内存外系统内另一个重要的公共资源。Android系统内应用程序的运行一般都会伴随有大量的磁盘I/O读写的操作,比如读写数据库、加载XML布局文件、读取配置文件等。但是相对于CPU和内存相比,磁盘的读写访问速度是比较慢的,很容易成为CPU运行的瓶颈,导致系统被拖累。当应用进程的线程中发生直接I/O磁盘读写时,就会导致线程进入Uninterrupt Sleep-Block I/O阻塞状态,如下图所示:

在开始分析磁盘I/O读写的瓶颈引起性能问题原因之前,我们先借用一张简化图来总体看看Linux系统的I/O栈:

从上图可以看出,整个Linux 下的 I/O栈大致有三个层次:
- 文件系统层,以
write为例,内核拷贝了write参数指定的用户态数据到文件系统Cache中,并适时向下层同步。 - 块层,管理块设备的
I/O队列,对I/O请求进行合并、排序。 - 设备层,通过
DMA与内存直接交互,完成数据和具体存储设备之间的交互。
可能存在的性能瓶颈问题如下:
- 为了优化文件读写的性能,减少磁盘的
I/O操作,Linux内核系统提供了页缓存(Page Cache)技术,以页为单位将磁盘上的文件内容缓存在内存中,从而提供了接近于内存读写速度的文件顺序读写速度,也就是Buffered I/O。但是当系统剩余内存不足时,系统会回收Page Cache页缓存内存,导致文件读写操作直接落到磁盘上,从而极大降低I/O性能。这也就前一小节中分析的低内存导致的性能卡顿问题。 - 上层所有的
I/O请求都会放入队列中进行合并排队处理,这样就可能引发不同应用进程之间的资源抢占问题。比如后台进程存在大量读写磁盘的操作请求,占用系统的I/O资源,这就会导致前台应用的I/O请求出现在队列中阻塞排队等待的现象,最终导致掉帧卡顿问题。 - 文件系统的性能瓶颈。比如针对
NAND闪存特性设计的f2fs文件系统,相比于ext4文件系统,能够提升小文件的随机读写性能,并能减少碎片化的问题。再比如Android 11上引入的Fuse文件系统,增加I/O读写的开销,导致sdcard路径下的部分路径文件的I/O读写性能下降。 - 闪存的读写性能瓶颈。一个就是闪存硬件的读写性能差异,比如
UFS 3.0相对于UFS 2.1来讲顺序读取速度快90%,顺序写入速度更是提升160%;另外一个问题就是闪存重复写入,需要先进行擦除操作,这样随着时间的推移,磁盘碎片变多,剩余空间少,一个内存页的写入会引起整个磁盘块的迁移,造成耗时操作,也就是早期Android手机给人形成“越用越卡”的印象的原因之一。
二、优化思路
针对I/O磁盘性能的瓶颈,总体优化思路从两个角度来看:
1. 从手机厂商角度:
- 采用更大的内存硬件配置,并从总体上优化系统的内存占用。以防止出现系统低内存状态下,
Page Cache页缓存被回收后,应用直接写磁盘而导致的I/O阻塞卡顿问题; -
启用
Linux的cgroup机制对I/O资源的进程隔离机制blkio,将进程按照优先级进行分组(分为前台进程、后台进程、甚至可以根据需求进行更详细的自定义划分),以分配不同的I/O带宽资源,从而解决后台应用进程抢占前台应用I/O资源造成的卡顿的问题; - 采用
f2fs文件系统,替换ext4文件系统,以提升文件系统的性能;可以针对部分系统文件管理类的应用不走默认的fuse路径,而是走f2fs,以提升其读写性能表现; - 采用读写性能更强的闪存器件,比如
UFS 3.1; - 启用
fstrim磁盘碎片整理功能,在息屏、充电等条件下触发磁盘碎片整理的动作,从而减少磁盘碎片,提升磁盘读写性能;系统手机管家模块可以引导用户定期进行垃圾文件的清理,以保证磁盘有充足的剩余空间; -
基于
mmap内存映射机制,将系统运行常访问的文件Lock锁定到内存缓存中,以提升文件读写的性能,减少真正发生I/O磁盘读写的概率,减轻系统的I/O负载。Android系统框架中的PinnerService服务主要职责就是这个,如下图所示:
2. 从应用开发者角度:
- 选择合适的文件读写操作。对读写速度有较高的要求,并允许低概率的数据丢失问题,就采用系统默认的基于
Page Cache的缓存I/O;对文件读写的速度要求不高,但是需要严格的保证数据不会丢失就使用Direct I/O;如果需要对同一块区域进行频繁读写的情况,对读写性能要求极高,可以采用mmap内存映射机制实现读写文件,比如腾讯开源的用于改善原生SharePreferences机制性能的存储工具MMKV就是这个原理实现的。 I/O方式的选择。一个是对于阻塞I/O操作尽量放入子线程执行,以免阻塞UI线程;二是适当采用异步I/O减少读取文件的耗时,提升CPU整体利用率,比如Okio就支持异步I/O操作。- 优化数据结构,建立内存缓存,尽量减少不必要的
I/O;
3 编译引起卡顿性能问题
编译引起的性能问题主要分为两类:一类是代码的解释执行耗时,运行时VerifyClass执行耗时等引发卡顿;二类是编译本身引起的卡顿问题,比如dex2oat编译抢占CPU算力资源,进程中的Jit编译线程抢占CPU算力资源。
3.1 代码解释执行耗时
一、理论分析
Art虚拟机有两种代码执行模式:quick code 模式和 Interpreter 模式。对于dex字节码文件采用的是Interpreter解释执行的模式,每次执行代码,虚拟机需要将代码转换成机器指令集,然后交给CPU去执行,所以执行效率比较低(早期Android系统被诟病性能差的原因之一)。而对于经过编译(AOT的dex2oat编译或JIT运行时及时编译,都需要消耗一定的磁盘空间存储编译出来的机器码文件)后生成的ELF格式机器码文件(如.oat格式文件、.art格式文件),采用quick code模式,直接执行arm 汇编指令,执行效率较高。为了做到性能、磁盘空间占用以及应用安装速度之间的最佳平衡,从Android 7.0 开始,采用AOT+JIT+解释执行的混合模式,其特点如下:
- 应用在安装的时候
dex中大部分函数代码不会被编译。 App运行时,dex文件先通过解析器被直接执行,热点函数会被识别并被JIT编译后存储在jit code cache中并生成profile文件以记录热点函数的信息。- 手机进入
IDLE(空闲) 或者Charging(充电) 状态的时候,系统会扫描App目录下的profile文件并执行AOT过程进行编译。
所以ART虚拟机在执行一个函数过程中会在 Interpreter 解释器模式和quick code模式切换,具体切换规则如下图所示:
从上图可以看出,有些时候应用部分代码还是按照Interpreter 模式执行,运行效率较低,从而产生一些性能问题。
二、典型案例分析
问题描述:淘宝等三方应用冷启动速度慢于同平台竞品机型。
问题分析:结合Systrace工具分析问题原因如下:
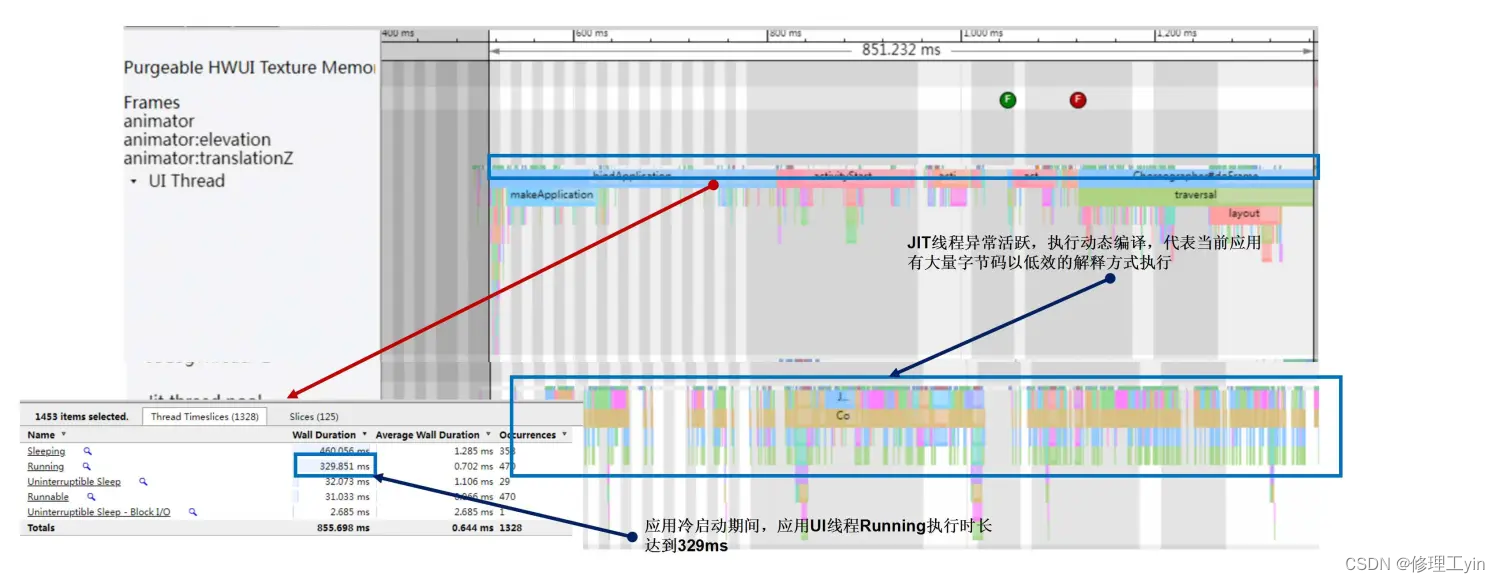

从与竞品机器的对比Systrace分析可以看到:同一个应用,且在两台手机CPU型号和运行主频一致的情况下,竞品机器上应用冷启动期间,UI线程的Running时长更短,且Jit工作线程上的热点代码编译任务明显少很多。从而可以推断出,问题原因在于竞品机器上的应用代码大部分是以机器码直接执行,而我们是以字节码解释执行,所以效率更低,运行时间更长。为什么会出现这个差异呢?后来对比日志分析发现,原因是竞品机上应用第一次安装打开后一段时间后,系统会触发一次speed-profile模式的dex2oat编译,会根据应用运行期间JIT搜集到的热点函数信息保存后生成的Profile描述文件进行编译,从而将应用启动期间的大部分代码函数编译成了机器码.oat文件,后续再启动应用时即可直接以quick code 模式执行机器码,所以执行效率更高。
三、优化思路
针对代码解释执行造成的性能问题,大致优化思路是尽量让应用代码以机器码形式运行,部分有效的手段有:
- 部分手机厂商,在手机预置的应用商店中下载的三方应用,除了
APK文件外,还会包含保存有应用热点函数信息的Profile描述文件,这样在应用dex2oat安装时,选择speed-profile模式,就会根据Profile描述文件,将应用的大部分热点函数直接编译成机器码,从而极大的提升应用的性能表现。 - 在手机息屏充电,进入
Idle状态后,通过JobScheduler机制,启动后台服务,扫描App目录下的profile文件并执行AOT过程进行编译,以达到手机越用越快的效果。
3.2 编译本身耗时
一、理论分析
在dex2oat进程编译应用的过程中,系统会启动很多线程,消耗大量的CPU算力资源。可能会导致前台应用由于抢不到CPU算力资源,其UI线程长时间处于Runnable状态而卡顿。另外应用进程内部,Jit工作线程动态编译时持续运行,如果负载较重,持续跑到CPU大核上,也会造成CPU算力资源抢占。
二、典型案例分析
问题描述:抖音应用界面严重卡顿。
问题分析:结合Systrace工具分析问题原因如下:
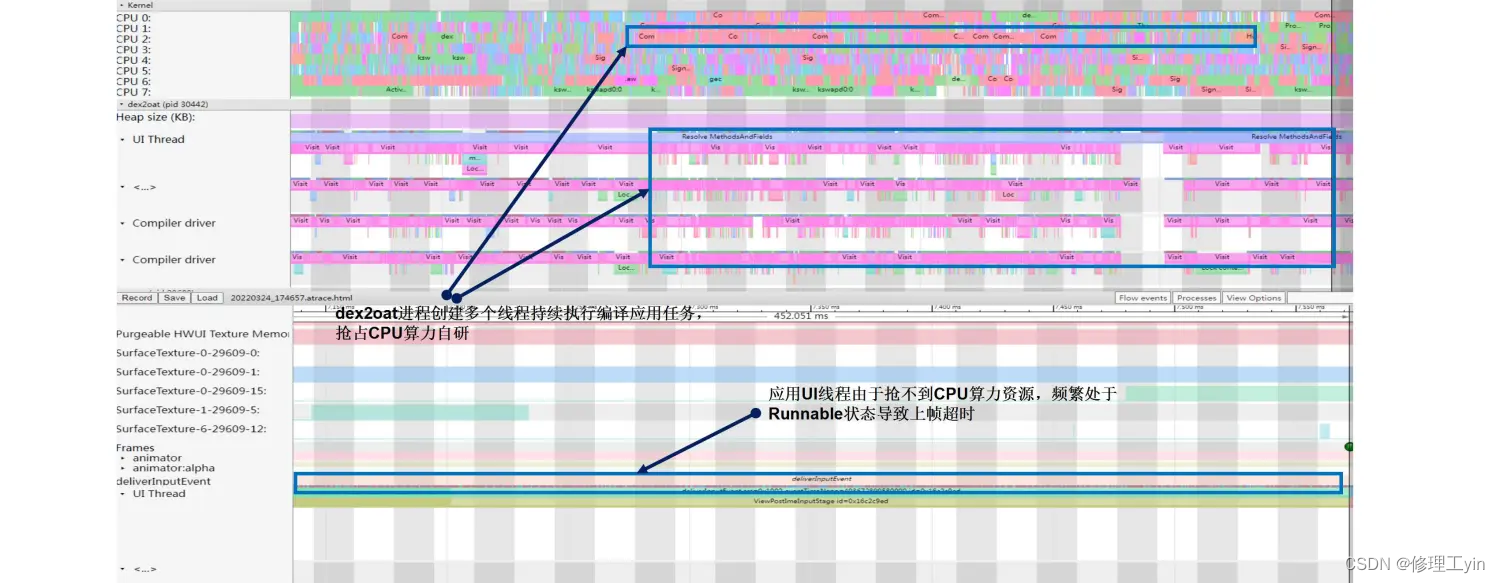
从上图可以看出:抖音应用界面卡顿的原因是因为其UI线程抢不到CPU算力资源而长时间处于Runnbale状态,而导致这个问题的很大一部分原因就是此时后台dex2oat进程创建多个线程持续执行应用编译动作抢占CPU算力资源。
三、优化思路
针对编译本身耗时引起的性能问题,部分有效的手段有:
- 通过
cpuset配置,限制dex2oat进程和Jit工作线程对CPU的使用,使其不抢占CPU大核心算力资源,并设置参数限制其创建的线程数。 dex2oat编译应用的动作尽量放在设备息屏,设备处于Idle状态下进行,以免影响前台用户的操作;- 限制三方应用在后台触发执行
dex2oat编译动作(从Android 10开始,谷歌官方通过Selinux权限的管控,禁止了三方应用触发dex2oat的权限);






![[flask]异常抛出和捕获异常](https://img-blog.csdnimg.cn/direct/b52f1ea9c6344737bec4786a080362be.png)