文章目录
- MySQL高级语句
- older by 排序
- 区间判断查询
- 或与且(or 与and)
- 嵌套查询(多条件)
- 查询不重复记录distinct
- count 计数
- 限制结果条目limit
- 别名as
- 常用通配符
- 嵌套查询(子查询)
- 同表
- 不同表
- 嵌套查询还能用于删除
- 嵌套查询还可以用于修改表格
- 视图
- 内连接 左连接 右连接
- 内连接
- 左连接
- 右连接
- 结语
MySQL高级语句
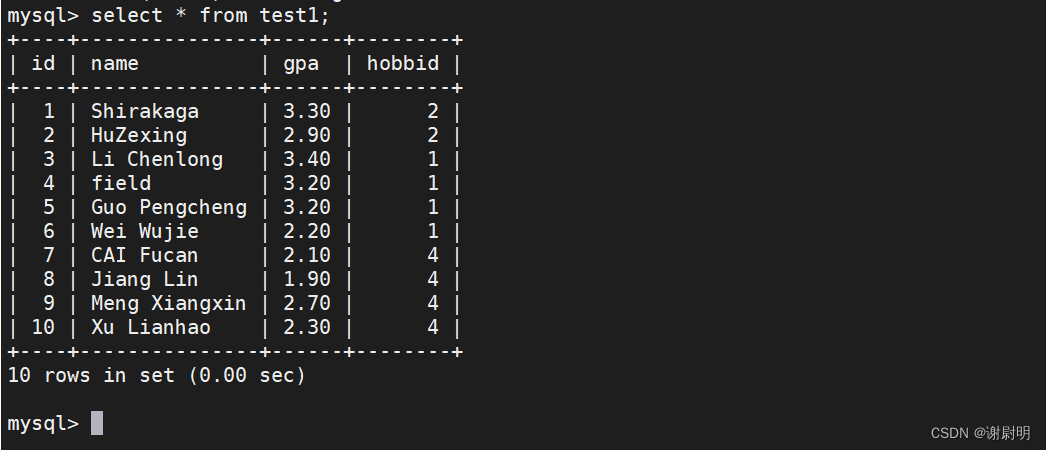
1构建测试用表
create table test1 (id int primary key,name char(30) not null,gpa decimal(3,2),hobbid int(2));
insert into test1 values(1,'baijiahe',3.3,2);
insert into test1 values(2,)'Hu Zexing',2.9,2);
....
older by 排序
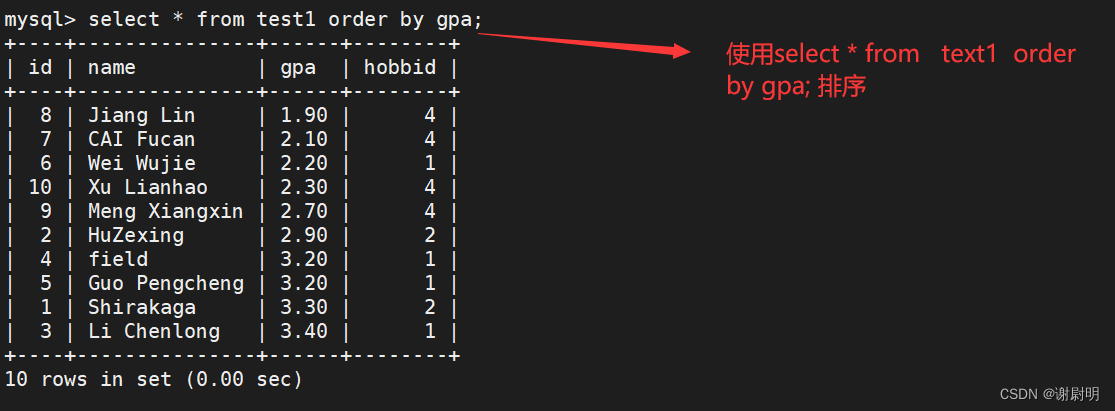
1.order by 排序默认升序
select * from test1 order by gpa;
2.添加desc 选线可以降序排序
select * from test1 order by gpa desc;
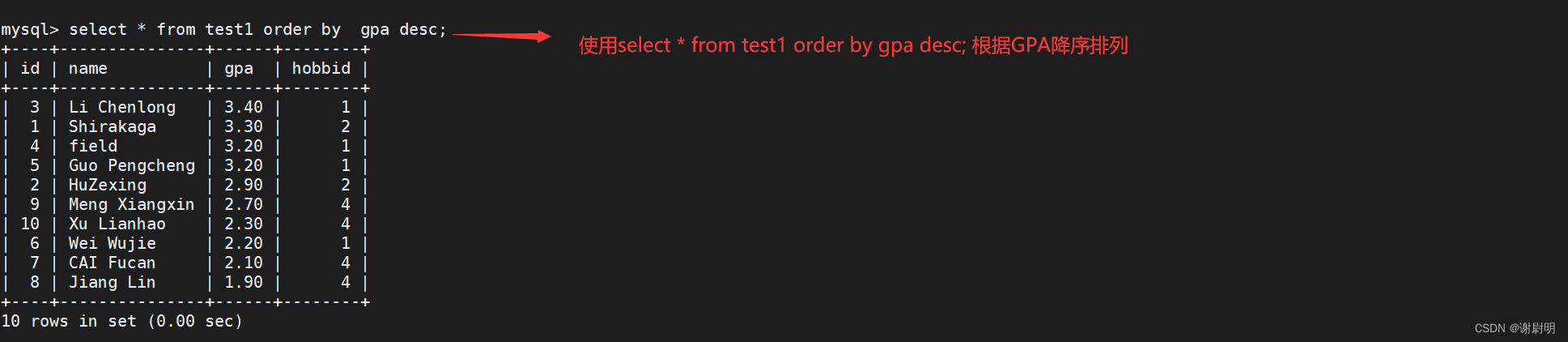
3.order by 还可以使用where来过滤数据
select * from test1 where hobbid=4 order by gpa desc;

4.order by 还可以多个数值一起排序
select * from test order by gpa,hobbid,id desc;
上面表示按绩点(gpa)排名,分数相同的按照hobbid来序排序hobbid相同按照 id降序排序
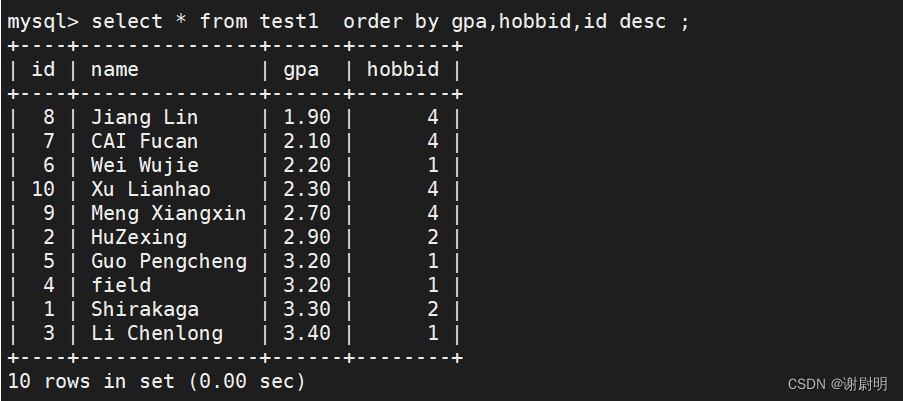
select * from test order by gpa desc,hobbid desc,id desc;

区间判断查询
查询GPA大于2.7的数据
select * from test1 where gpa>2.7;

或与且(or 与and)
查询GPA>2.7或者id=7的数据
select * from test1 where gpa>2.7 or id=7;

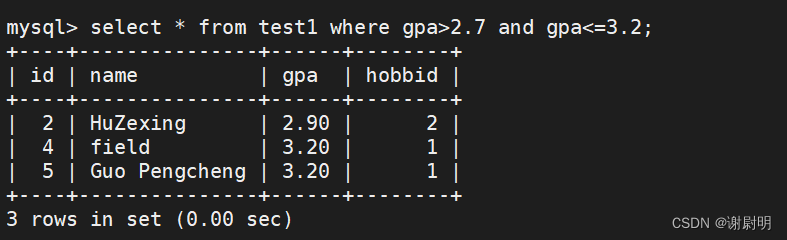
查询GPA>2.7且GPA<=3.2的数据
select * from test1 where gpa>2.7 and gpa<=3.2;
嵌套查询(多条件)
查找gpa>2.4且(id大于4或者hobbid=2)的数据
select * from test1 where gpa>2.4 and(id>4 or hobbid=2);

查询不重复记录distinct
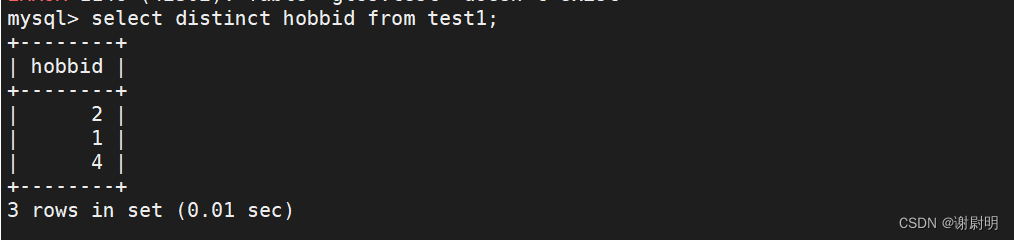
select distinct hobbid from test;
查询test表格中 hobbid项中不重复的数据
count 计数
统计一个有多少数据(包括空行),count(主键名)则不包括空行
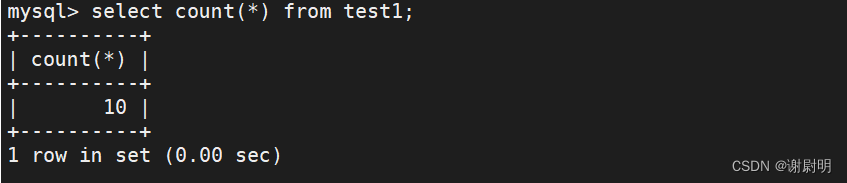
select count(*) from test1;
统计表中hobbid不同的个数
select count(distinct hobbid) from test1;

限制结果条目limit
注:本文忽略第0行
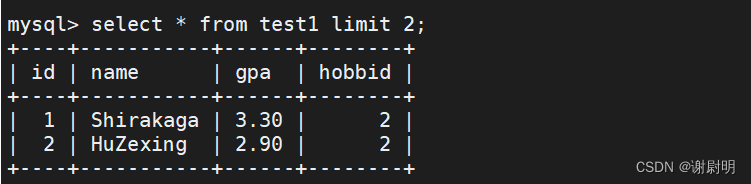
显示表至第二行
select * from test1 limit 2;
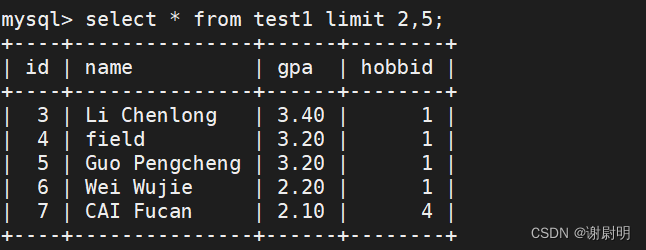
从第二行开始显示,至第五行
select * from test1 limit 2,5
查询前五
select * from test1 order by gpa desc limit 1,5;

别名as
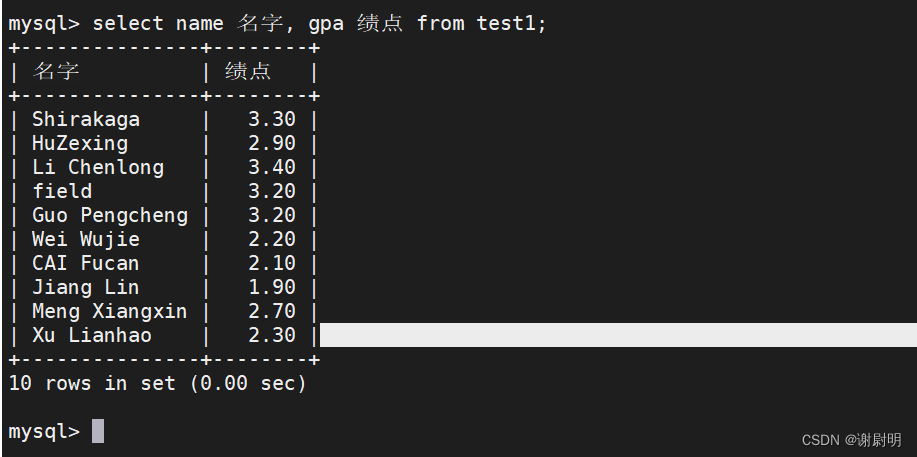
使用别名显示
select name 名字, gpa 绩点 from test1;
创建表别名
create table t1 as select * from test1;

用别名查询
select name,gpa from t1;

常用通配符
1.% - 通配符,匹配任何数量的字符。
2._ - 通配符,匹配任何单个字符。
例如
mysql> SELECT * FROM t1 AS t WHERE t.name LIKE 'w%';

SELECT * FROM test1 WHERE gpa LIKE '3___';
嵌套查询(子查询)
创建一个新表,用作实验
create table money(id int primary key,money decimal(15,2));
insert into money values (1,3000);
insert into money values (2,5000);
insert into money values (3,1300);
insert into money values (4,6000);
insert into money values (5,2800);
insert into money values (6,2300);
insert into money values (7,3300);
insert into money values (8,9200);
insert into money values (10,3154);
insert into money values (11,31575);
insert into money values (12,8547);
insert into money values (13,8745);
insert into money values (14,900);
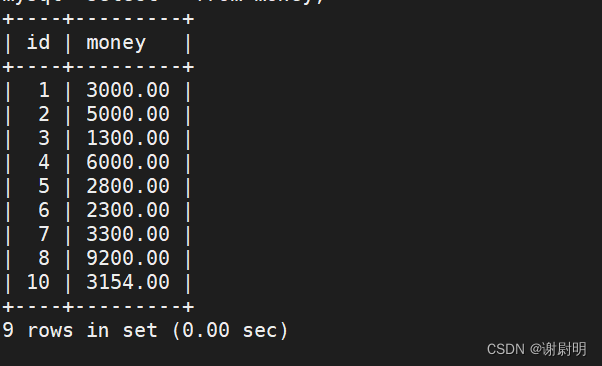
同表
select id,gpa from test1 where id in (select id from test1 where gpa=>2.7)
上面这个SQL语句含义是,首先运行括号内的SQL语句,输出运行结果到达括号外的SQL语句,最为条件运行。
可以理解为上个SQL语句效果相当于SELECT id, gpa FROM test1 WHERE id=1 OR id=2 OR id=3 OR id=4 OR id=5 OR id=9;
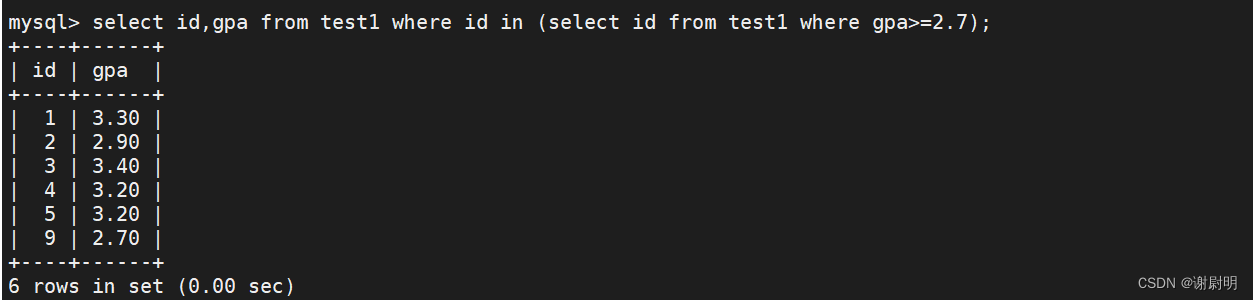

不同表
select id,money from money where id in (select id from test1);

上面这个SQL语句含义是,首先运行括号内的SQL语句,输出运行结果到达括号外的SQL语句,最为条件运行。
可以理解为上个SQL语句效果相当于select id,money from money where id=6 or id=7 or id=8 or id=9 or id=10;
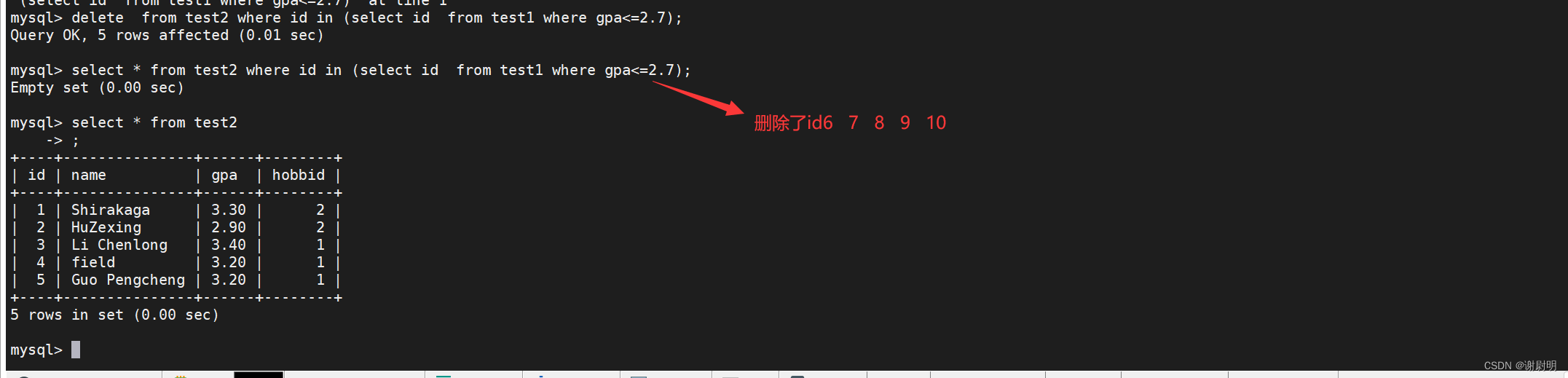
嵌套查询还能用于删除
创建一个测试用的表test2
用select查询是否是要删除的值
是直接将select换成delete就可以删除了
create table test2 (select * from test1);
select * from text2 where id in (select id from test1 where gpa<=2.7);
delete * from text2 where id in (select id from test1 where gpa<=2.7);
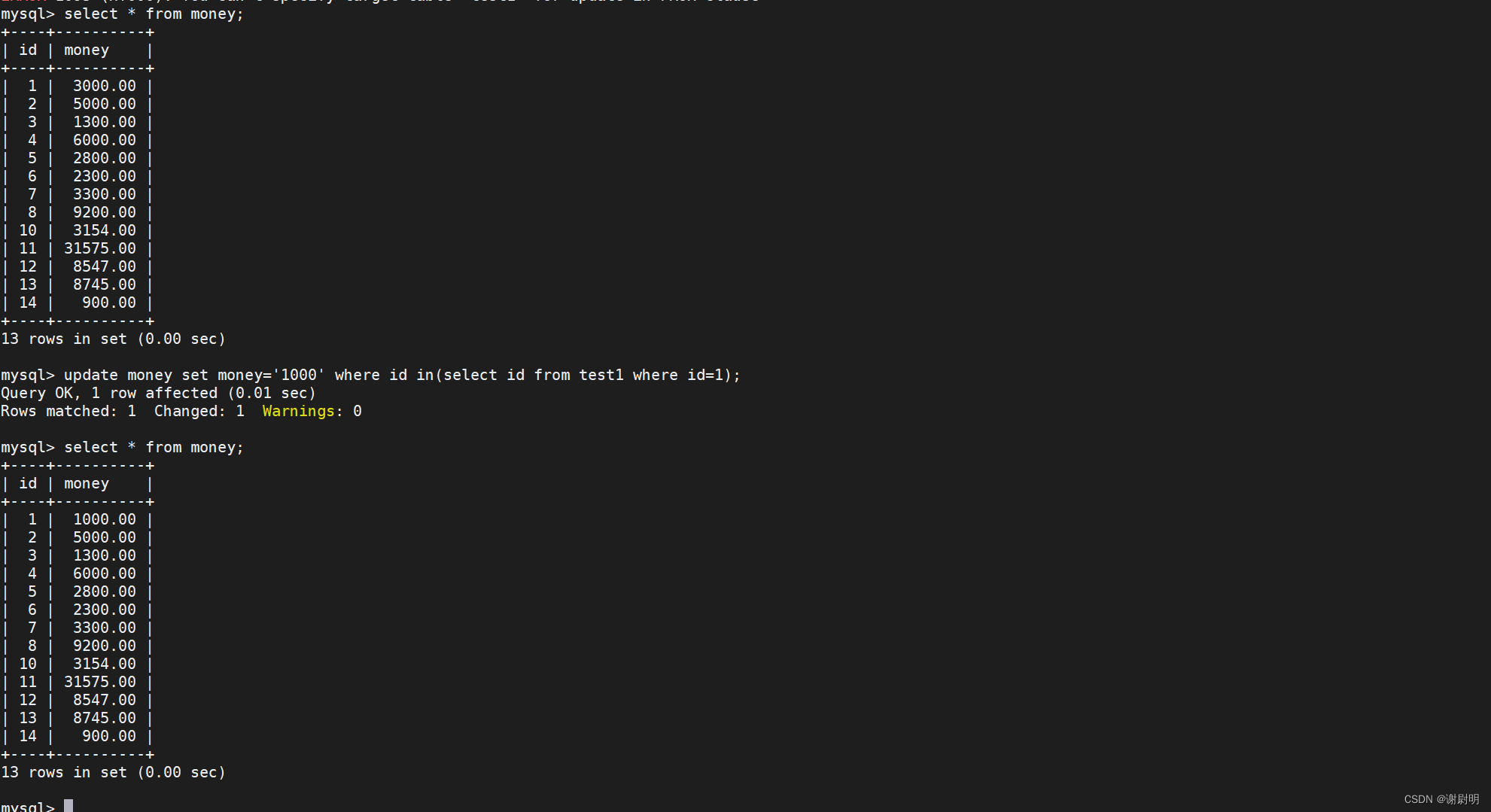
嵌套查询还可以用于修改表格
将money表的id=1的用户money数改为1000
update money set money='1000' where id in(select id from test1 where id=1);
子查询,别名as
当运行
select id from (select id,name from test1);

会报错
原因为:
select * from 表名 此为标准格式,而以上的查询语句,“表名"的位置其实是一个完整结果集,mysql并不能直接识别,而此时给与结果集设置一个别名,以”select a.id from a“的方式查询将此结果集视为一张"表”,就可以正常查询数据了,如下:
select a.id from (select id,name from test) a;
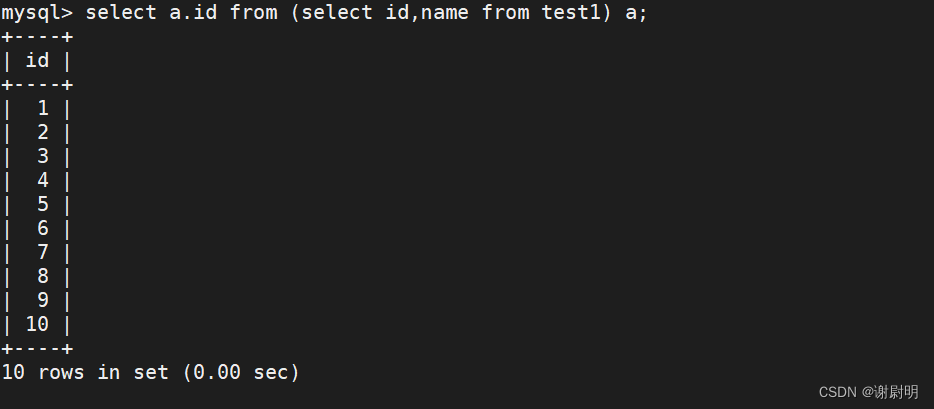
相当于
select test.id,name from test;
select 表.字段,字段 from 表;
在MySQL中,视图(View)是一种虚拟表,它由一个SQL查询定义,但并不存储数据。视图的本质是一条SQL查询语句,它的结果集看起来像是一张表。视图可以用来简化复杂的SQL操作,提供数据的安全性和独立性,以及为用户提供一个更加直观的数据表示。
视图
在MySQL中,视图(View)是一种虚拟表,它由一个SQL查询定义,但并不存储数据。视图的本质是一条SQL查询语句,它的结果集看起来像是一张表。视图可以用来简化复杂的SQL操作,提供数据的安全性和独立性,以及为用户提供一个更加直观的数据表示。
CREATE VIEW 试图名 AS SELECT 字段1, 字段2, ... FROM 表名 WHERE 判断句;
create view test_view as select name,gpa from test1 where id<=10;
使用视图
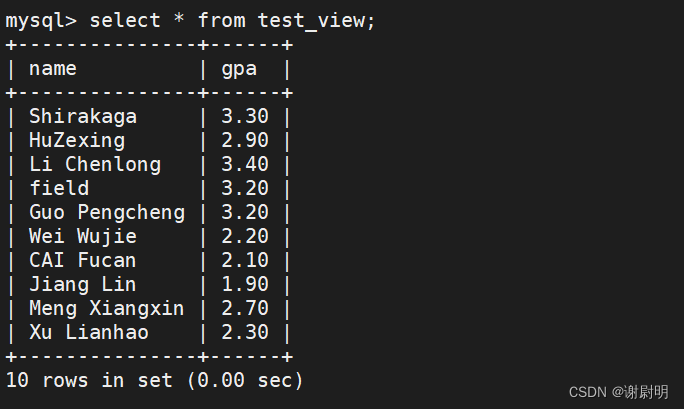
select * from test_view;
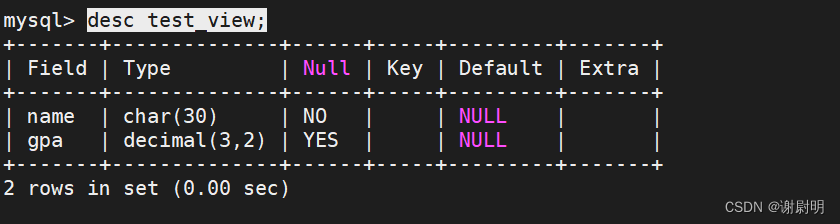
查看视图与源表结构
desc test_view;
修改视图
update test_view set gpa=3.9 where name=Shirakanga ;
将视图的Shirakanga的gpa改成3.9原表也会自动修改

内连接 左连接 右连接
内连接
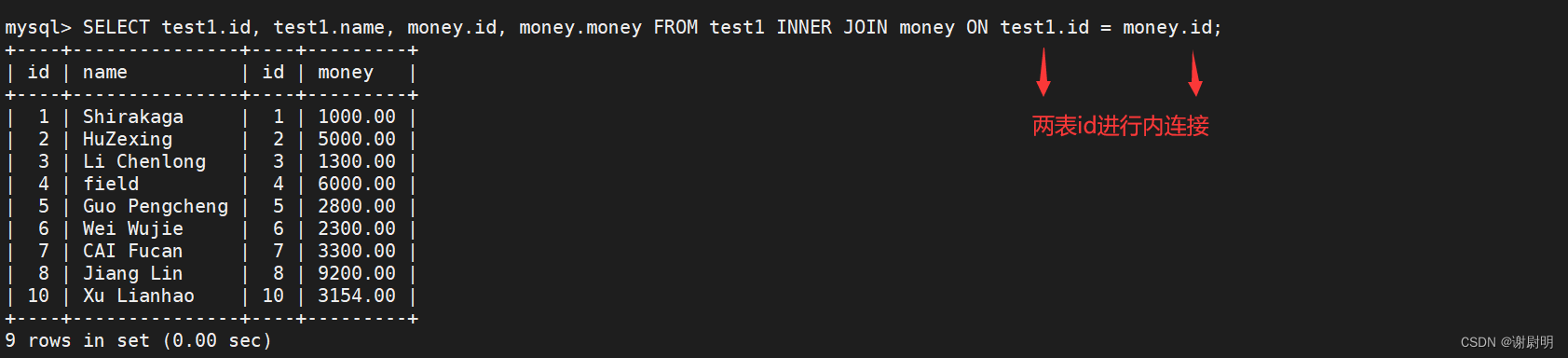
内连接是SQL中的一种连接查询,用于合并两个或多个表中具有匹配值的行。只有当连接条件在两个表中都匹配时,内连接才会返回这些行,内连接只返回两个表中都有匹配的记录的结果集。
SELECT test1.id, test1.name, money.id, money.money FROM test1 INNER JOIN money ON test1.id = money.id;
左连接
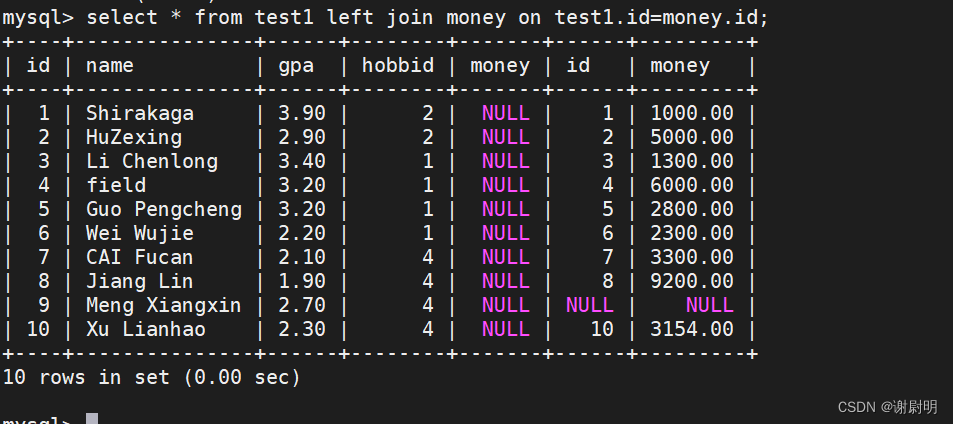
左连接是一种SQL连接操作,它返回左表(LEFT JOIN子句之前的表)的所有记录,即使右表中没有匹配的记录。如果右表中有匹配的记录,则左连接还会返回右表中的匹配记录。如果右表中没有匹配的记录,则结果集中右表的部分将包含NULL。
select * from test1 left join money on test1.id=money.id;
右连接
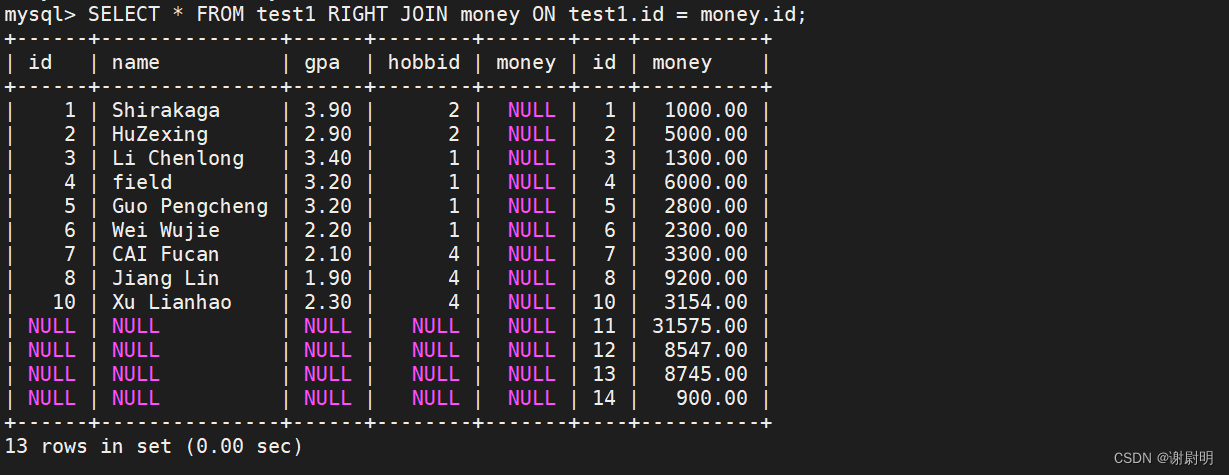
右连接(Right Join)是一种SQL连接操作,它返回右表(RIGHT JOIN子句之后的表)的所有记录,即使左表中没有匹配的记录。如果左表中有匹配的记录,则右连接还会返回左表中的匹配记录。如果左表中没有匹配的记录,则结果集中左表的部分将包含NULL。
SELECT * FROM test1 RIGHT JOIN money ON test1.id = money.id;
结语
- ORDER BY 排序:
- 升序排序:
ORDER BY column_name - 降序排序:
ORDER BY column_name DESC - 多条件排序:
ORDER BY column1, column2 DESC
- 升序排序:
- 区间判断查询:
- 查询满足特定条件的数据:
WHERE column_name BETWEEN value1 AND value2
- 查询满足特定条件的数据:
- 或与且(OR 与 AND):
- 组合多个条件进行查询:
WHERE column_name = 'value' OR column_name2 = 'value2' - 组合多个条件进行查询:
WHERE column_name = 'value' AND column_name2 = 'value2'
- 组合多个条件进行查询:
- 查询不重复记录(DISTINCT):
- 去除重复记录:
SELECT DISTINCT column_name FROM table_name
- 去除重复记录:
- COUNT 计数:
- 统计记录数:
SELECT COUNT(*) FROM table_name
- 统计记录数:
- 限制结果条目(LIMIT):
- 限制结果数量:
LIMIT offset, limit_number
- 限制结果数量:
- 别名(AS):
- 为列设置别名:
SELECT column_name AS alias_name FROM table_name - 为表设置别名:
SELECT * FROM table_name AS alias_name
- 为列设置别名:
- 常用通配符:
%:匹配任何数量的字符。_:匹配任何单个字符。