文章目录
- 前言
- 提出动机
- 模型猜想
- 模型提出
- 模型结构
- 模型参数
- 模型预训练
- 训练的目标
- 训练方式
- 训练参数
- 预训练数据集
- 预训练疑问点
- 模型微调
- 模型输入范式
- 模型训练
- 微调建议
- 微调疑问点
- 实验结果分析
前言
首先想感慨一波
- 这是当下最流行的大模型的的开篇之作,由OpenAI提出。
- 虽然【预训练+微调】的训练范式最初不是由GPT-1提出,但是基于transformer的【预训练+微调】是由GPT-1提出,这也是现在大模型所用的范式。
- 这篇论文出自18年,比google公司出的bert要早几个月,你去看bert的论文之后发现,其实bert的思路有大部分是来自GPT-1的。
细品一下,虽然当时这篇论文平平无奇,但是历史见证它的后劲很强大。下面会一一的记录一下我看了这篇论文后的理解。
提出动机
首先我们来回顾一下在自然语言任务中,尤其是自然语言理解任务中,大概有以下的几种任务包括:文本蕴含、问题回答、语义相似度评估和文档分类等。
那如何通过AI算法的手段去解决和完成这些NLI任务呢?
在传统的AI算法开发的过程中,一般是利用标注好的数据去训练一个模型,然后再将训练好的模型应用于具体的业务领域,下面就以NLP中的情感分类来举例子:
- 数据集构建: 构建情感分类数据集,
| 数据(feature) | 标签(label) |
|---|---|
| 你真的狗阿 | 负面 |
| 小明的表现还是很不错的 | 负面 |
| 。。。 | 。。。 |
- 模型构建: 构建一个深度学习或者机器学习的二分类模型,用来实现情感分类
- 模型训练:训练好后的模型就可以完成情感分类任务了。
但是以上的这种传统的做法还是存在着一些局限,如:
- 训练的数据集需要人为的标注,且数据集要足够大,这样就要求原始预料足够多,同时标注的人力也要足够大。
- 训练好后的模型只能完成单一的任务,且在这个单一任务上,未来要预测的数据的分布情况要和训练数据集的分布情况大致保持一致,如果不一致,模型效果就会变差,这很好理解,也就是说你训练的数据集是一种分布形式,那么模型学到的就是这种分布形式的规律,所以未来要预测的数据同样要符合这个规律,如果规律不一样,那么效果就不会太好。这就是风控领域的PSI技术原理。
- 训练好后的模型只能完成单一任务。如果这个模型是基于情感分类数据集来训练的,那么训练好后的模型就只能完成情感分类任务。
其实这就为现实的发展增加了不少的阻碍,最明显的地方在于有些领域的原始数据语料本身就特别少,那这种有监督式的训练就不能够sota了。
所以探索一种能够在少样本下sota的模型,变得有现实意义。
模型猜想
以上已经描述了监督学习在NLI任务上可能存在的阻碍,那到底该如何改善呢?该怎么做呢?作者最先想到的点子就是:
- 能不能在一些未标注且不缺分领域的海量数据上去训练得到一个模型,学习得到一些通用知识。这个模型具有一些基础的能力,诸如词的embedding表示能力等(预训练)。
- 然后在这个基础模型的基础上再利用少量的特有领域的标注数据对模型进行二次训练,这样就可以完成在特定领域的工作(微调)。
我们写过论文的都知道,既然你在论文中提出来了这个假设,自然肯定是能实现了哈哈,同样的作者提出的这种思想,在很多地方也找到了佐证。最典型的就是词向量的表示。
还记得以前的word2vec是如何工作的吗?先训练好word2vec,然后单词通过模型之后,就会得到词向量,有了词向量就可以做很多的事情,通常情况下,不会直接来使用这个词向量来完成具体的NLI任务,当然了它也完不成,一般情况是将词经过word2vec向量化表示,然后接着利用向量化后的特征来训练其他的模型来完成具体的NLI任务。这是不是有点验证了作者提出的猜想呢?
- word2vec的训练类似于作者提出的第一阶段的训练
- 二次训练其他的模型类似于作者提出的二次训练
此外还有一些例子也验证作者的猜想,诸如在GPT-1之前就有人提出了以LSTM作为基座,实现训练一个LSTM模型,然后在二次微调,去完成具体的NLI任务。
以上的两种工作模式被证明有一定的效果。
基于以上的种种,作者提出的这种两段式训练:预训练+微调。打开了未来的大门。
模型提出
接着,作者在论文中分析了,基于LSTM这种两段式的训练有一个问题:LSTM很难处理一些长文本信息,这是循环神经网络不可避免的问题,所以作者提出了一种新的模型,就是基于transformer的decoder模型架构。以这种架构来完成模型的预训练和微调。
模型结构
transformer结构
作者提出的GPT-1的结构其实就是基于transformer的解码器的简单的堆叠,那么我们先来看看transformer是怎么样的。
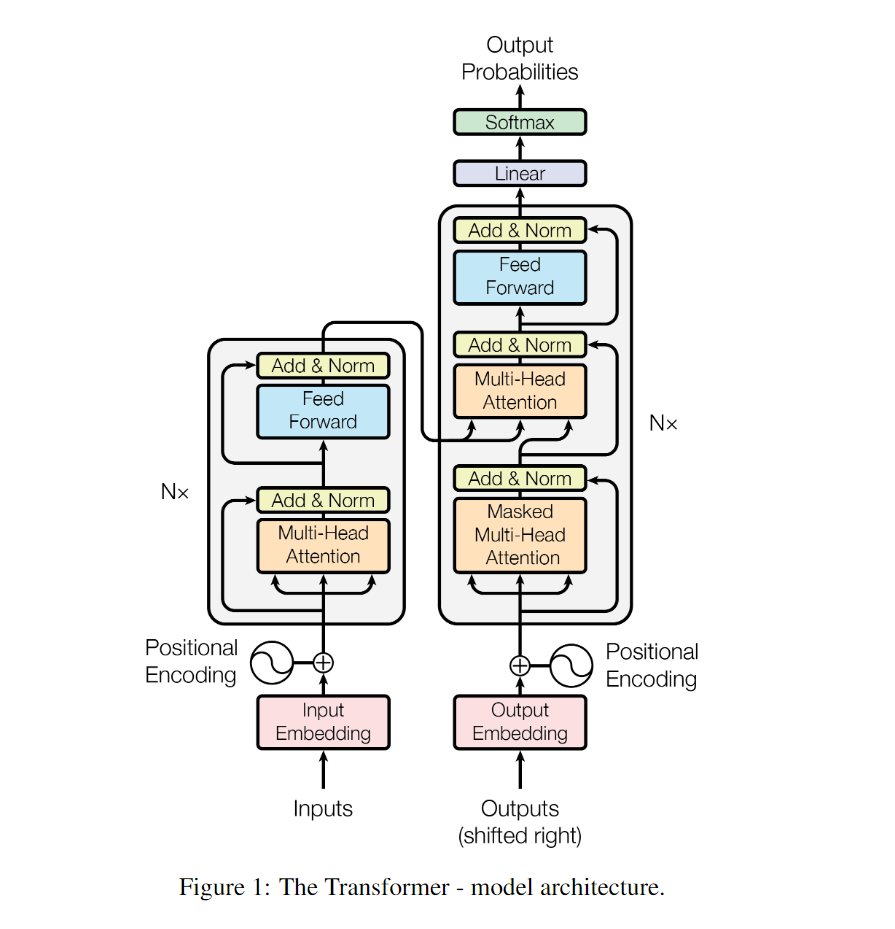
以上就是transformer的结构,左边是编码器,右边是解码器,解码器块和编码器块的差别其实就在于解码器块多了一个掩码机制(Masked Multi-Head Attention)。这个掩码机制会将要预测token的未来token进行掩码。避免信息穿越。具体关于transformer的内容,会在transformer论文中分享,这里只做最简单的介绍。
GPT-1结构
GPT-1的模型结构非常简单,其实就是基于transformer的decoder部分做了一个12层的堆叠,下面我先绘制一个GPT-1的结构图
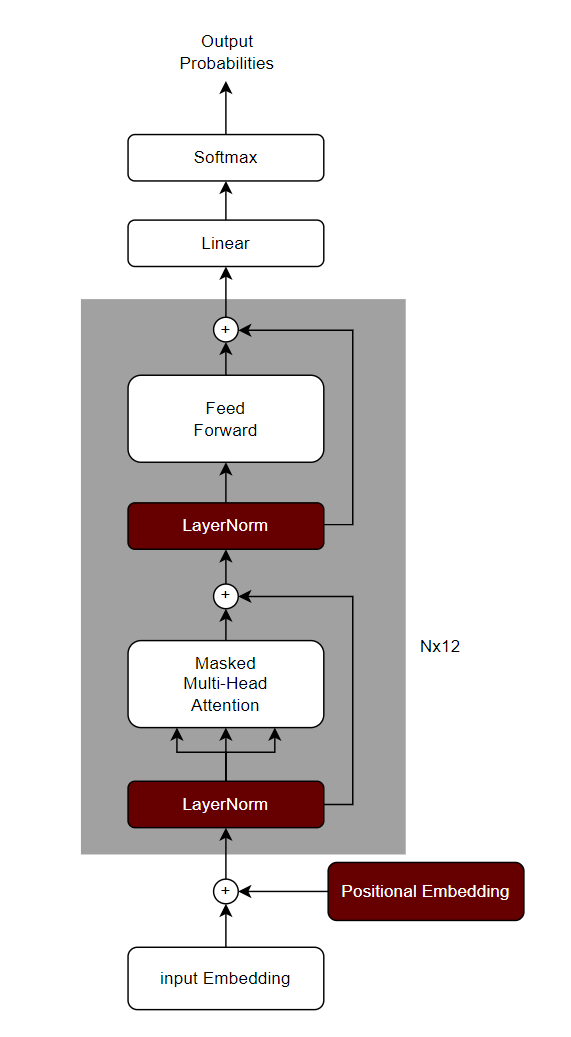
可以看出这就是基于transformer的decoder部分来设计的,但是还是有了一些简单的修改,具体一些在架构上显著的修改,我用红色的标注出来了。下面我大概描述一下。
- 位置编码(Positional Embedding)部分采用了和input Embeddingg一样的可学习的embedding模块,而不是transformer的正余弦计算原理。
- LayerNorm部分被提前了,原始的transformer部分,是先进行多头注意力计算,然后进行layerNorm,而在GPT-1这里则被提前了。
- 少了一个Mutil-Head Attention模块,只保留了Masked Mutil-Head Attention。
- 第三部分则是激活函数的变化,原始的transformer用的是relu,而GPT-1用的是GELU。
关于GPT-1的结构,以及和transformer的差别就是这么多,这也就可以理解为啥当初论文发出来之后响应没那么大,这放到现在的研究生论文中,可能也会被质疑创新不足吧哈哈。
模型参数
前面都介绍了模型的具体的结构了,下面就只需要说说结构里面具体的参数设定了
| 解码器块 | 12层 |
|---|---|
| 多头注意力 | 12头 |
| 词embedding | 768维 |
| 前馈神经网络隐藏层维度 | 3072维 |
有这些参数就可以具体确定这个模型了,如果不懂这些参数对应什么,强烈建议看看transformer的原理,后期我也会补一篇关于transformer论文的分析。
虽然我们已经有了模型,但是我们该如何训练呢?而训练很大程度是由训练目标决定的,比如我们的训练目标是二分类,那么我就知道模型该如何训练了。所以我们接下来就要知道预训练和微调阶段的各自训练目标是啥。
模型预训练
训练的目标
前面已经说了,作者看了很多论文之后,提出了这种预训练+微调的两段式训练范式。而在预训练阶段是通过在未标注数据上进行大量训练。而这里就有一个疑问了:
- 在未标记的语料上训练模型,到底该选择什么样的训练目标呢?到底是以情感分类为目标呢?还是以实体识别问分类目标呢?还是其他的NLI任务?
前面都说了,如果是以具体的任务为目标,那么这个数据是要人去标注的,根据作者的假设这显然是第二阶段要做的,那这个阶段该如何做呢?首先从数据上看,这个阶段有的都是一些未标注的大量文本数据;其次从之前所得到的启发来看,以往的这种两段式训练范式,在第一段中都是通过学习词的embedding表示,来捕获词或者短语级别的信息。诸如word2vec。所以作者受到启发,就是利用预训练来获得词的通用embedding表示,既然是学习词的通用embedding表示,那训练时候数据该如何组织呢?这些都是一些未标注的数据阿?作者这里采用的训练思想就是:预测下一个词的出现概率。利用出现的词来预测出现未出现的词,这就是训练的目标。
训练方式
这样所有的都解决了阿,所有的未标注的数据都可以用起来啦。我还是举一个例子吧,以:“你是一个打不死的码农”为例
| 特征(feature) | 标签(label) |
|---|---|
| 你 | 是 |
| 你是 | 一 |
| 你是一 | 个 |
| 你是一个 | 打 |
| 你是一个打 | 不 |
| 你是一个打不 | 死 |
| 。。。 | 。。。 |
将特征输入到模型,来预测标签,当然表格中的特征长度虽然是不一样的,但是实际情况下,是会把输入都padding到同一个长度的,这也就是下面要提的“最长文本输入”的概念。
训练参数
而在具体的训练中,有一些具体的细节参数还是需要留意的,下面我把主要的参数进行罗列
- 文本的字节编码用bpe:也就是说用bpe去对文本做token切分。
- 单词输入最长文本为512个token:这就是说一次输入的最长的文本只能是512,如果不够512,也会把它补齐padding到512,如果超过512,也会截断,只保留512个token。
- 单个batch为64个文本序列:如果把第1点输入的512看作一句话的长度,那么这里就是说一次输入到模型中为64句话。
- 优化器选择用adam
- 学习率最开始设置为2.5x10^-4,在前2000个step的时候学习率恒定不变,2000个step之后,学习率会动态减小,直到为0。
- 用到dropout的地方,丢弃概率参数为0.1
- 总共训练100个epoch
- 训练时采用L2正则。
预训练数据集
数据集这一块主要是用到了两个数据集
- booksCorpus:这是一些书籍数据。
- 1B Word Benchmark :这是一些连续文本内容。
现在,有了模型、有了优化目标、有了具体模型参数和训练参数、还有了数据。就可以做模型的预训练了,预训练结束后的模型,就会学到词的通用embedding表示啦。
预训练疑问点
在原始论文中,给出了一个计算的公式

从上面可以看得出来,最终自注意力块的输出之后还要和原始输入的词的embedding转置进行相乘,这就是我的疑问点所在。
以我对transformer的decoder的理解,以及在看了minGPT的实现之后,得到的结果时最后的这个We的转置其实本身就不是We,而是会额外的加入一个线性层进行学习。
注:minGPT工程是一个大神对GPT的实现。
模型微调
在预训练阶段,模型学到了如何利用出现的词来预测下一个词。按理来说要让他做具体的自然语言理解(NLI)任务是不太可能的,所以也就有了微调这一步,在微调阶段,模型只需要在少量的具体任务的标注数据,就可以达到sota。那对于每一个NLI任务具体该怎么做呢?
模型输入范式
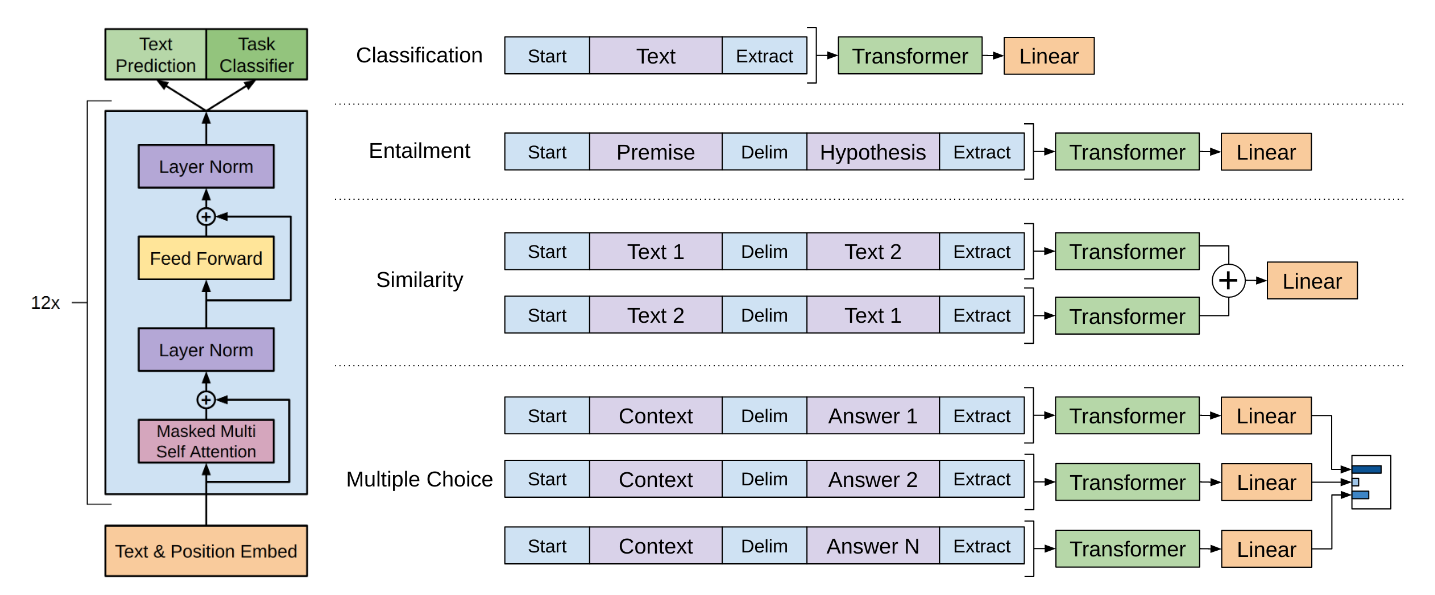
自然语言理解任务(NLI)其实是有很多种的,诸如:情感分析、文本蕴含、相似度计算、多项选择、摘要总结等。对于这么多的任务,输入部分是可大致总结为有两种输入的形式:
- 单文本输入:诸如情感分类这样的任务,其实就是单句话输入进去,判别情感类别。
- 多文本输入:诸如文本蕴含、多项选择,他们是多个连续文本的输入,然后做最终的目标计算。
所以针对这么多的NLI任务,GPT-1统一了输入的范式:
输入的序列(可以是单个或多个)以<s>开头。- 输入序列是多个时,序列质检用$符号做分隔。
输入序列的结尾用<e>作为结束。
以上就是关于输入的范式规定,下面我给出一张官方的图就一目了然了。
模型训练
在微调部分的训练,其实就是标准的有监督学习,自然要先计算loss,然后根据loss来进行反向BP优化参数。下面我会根据上图来挨个讲解不同NLI任务大概是如何训练的。
单句子分类任务

上图中的分类任务是单句子的二分类任务,诸如情感分类。
- 数据准备:
句子开头添加<s>,句子结尾添加<e> - 模型修改,在原有模型上添加二分类头
- 数据训练:数据输入到模型中,预测二分类,根据loss,反向BP更新模型参数
多句子分类任务

上图中的分类任务是多句子的二分类任务,诸如文本蕴含,就是预测一个句子是否含在另一个句子中。
- 数据准备:
句子开头添加<s>,句子结尾添加<e>,句子与句子之间用$分隔 - 模型修改:在原有模型上添加二分类头
- 数据训练:数据输入到模型中,预测二分类,根据loss,反向BP更新模型参数
相似度计算任务

这类任务其实也可以看作是一个二分类任务,以概率来表示他们的相似程度。
5. 数据准备:句子开头添加<s>,句子结尾添加<e>,句子与句子之间用$分隔
6. 在原有模型上添加二分类头
7. 数据训练:数据输入到模型中,预测二分类,根据loss,反向BP更新模型参数
注:在数据输入部分,由于是两段文本,所以谁在前都行,既然谁在前都行,官方的做法就是分别让每一句话都在前一次,然后分别输入到模型,最后将两次的结果进行相加,进行二分类的概率预测。
多项选择任务

多项选择原理上是一个多分类任务,所以同样是用概率来表示选谁,区别与之前的任务的地方在于别的是用sigmoid做二分类任务,而这里是用softmax做多分类任务。但是这里的softmax并不是直接在线性层上去叠加的。
- 数据准备:
句子开头添加<s>,句子结尾添加<e>,句子与句子之间用$分隔,分别将问题和答案做组合,多个选择就会有多组数据 - 在原有模型上添加二分类头(并不是直接添加多分类头)
- 数据训练:多组数据分别输入到模型中,预测二分类,最后根据多组的二分类输出结果做最终的softmax,再根据loss,反向BP更新模型参数。
注:这里最重要的就是在模型的设计上加入多分类头,诸如4选项的任务,并不是直接在输出添加一个输出维度为4的线性层,然后再softmax,而是添加了一个二分类头,每一个数据都分别进入模型,得到一个二分类的概率结果,然后再在这4个二分类结果上用softmax归一化,用最终的softmax结果计算loss。
微调建议
官方论文给出了关于一些微调时候训练参数的建议
- 学习率为6.25 x 10^-5
- 每个batch为32
- 训练3个epoch
微调疑问点
这个疑问点来自于微调阶段的loss的计算,在原始论文中,给出了一个公式
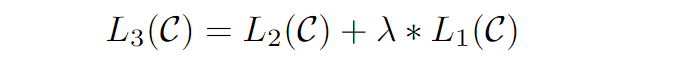
- L3为微调时计算的总的loss,
- L2表示微调时,具体任务的loss,如二分类任务,loss表示二分类结果和真实结果的差距
- L1表示文本生成的loss,也就是说你输入了一句话,这里时会计算文本生成的loss的,这也就是预训练阶段优化的依据,但是这里的这个文本生成的loss,并不会计算所有文本的loss,
而是只算开始符号<s>、结尾符号<e>和分隔符$的loss。
总的loss时L1和L2的相加。但是在minGPT中,以及现在流行的大模型中,其实都不这么做,都是只使用L2来计算loss,然后反向BP。包括在minGPT工程中,也是只用了L2。
这就是我的疑问点,大家可以留意。
实验结果分析
作者在很多的NLIL任务上做了多次的实验,得出了两个很重要的结论。
- 增加transformer的decoder层数,会对NLI的理解任务有提升。
- 零样本能力:预训练好后的模型本身不需要微调,就具有了一定的NLI解决能力。
从现在来看,以上的两个结果,指导着当下(2024)年大模型的发展,OpenAI牛逼。
关于GPT-1的讲解就到这,也强烈建议大家看一下论文:Improving Language Understanding by Generative Pre-Training
还有一个是文中提到的:minGPT,他是由一个国外的大佬开发的关于GPT的系列实现,通俗易懂,推荐阅读。