原文出处:
[2401.09417] Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model (arxiv.org)
原文笔记:
What:
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
我们提出了 Vision Mamba (Vim),Vim是一种基于纯SSM的方法,并以序列方式对图像进行建模,它结合了双向 SSM 用于数据相关的全局视觉上下文建模和位置嵌入以进行位置感知视觉理解。以前的工作要么将SSM应用于特定的视觉应用程序,要么通过将SSM与卷积或注意力相结合来构建混合架构。与之不同的是,我们建立了一个纯ssm的模型,该模型可以作为通用的视觉主干。
它的效果与VIT持平甚至更好
他的计算效率更高,内存占用更低
(他的双向SSM比较创新,至于位置编码操作和图片打成patch的操作根VIT和Swin-Transformer都比较像)
Why:
1、Mamba作为长序列建模的基础模型在NLP领域取得了成功,然而尚未探索一个通用的基于纯SSM的骨干网来处理视觉数据,如图像和视频。
2、Transformers 中的自注意力机制在处理远程视觉依赖关系(例如处理高分辨率图像)时在速度和内存使用方面提出了挑战。
3、以前的工作要么将SSM应用于特定的视觉应用程序,要么通过将SSM与卷积或注意力相结合来构建混合架构。与之不同的是,我们建立了一个纯ssm的模型,该模型可以作为通用的视觉主干。
Challenge:
由于视觉数据的位置敏感性和全局上下文对视觉理解的要求
Mamba用在视觉领域存在两个挑战
1、单向建模
2、缺乏位置感知
Idea:
1、使用双向状态空间模型来处理视觉数据,用于数据依赖的全局视觉上下文建模
2、使用位置嵌入来辅助模型对视觉数据的位置感知视觉识别
Model:
原文翻译:
Abstract
最近,具有高效硬件感知设计的状态空间模型 (SSM),即 Mamba 深度学习模型,在长序列建模方面显示出巨大潜力。同时,纯粹基于SSM构建高效通用的视觉骨干是一个吸引人的方向。然而,由于视觉数据的位置敏感性和全局上下文对视觉理解的要求,表示视觉数据对SSMs具有挑战性。在本文中,我们表明,不需要依赖自注意力进行视觉表示学习,并提出了一种新的具有双向 Mamba 块 (Vim) 的通用视觉主干,它使用位置嵌入标记图像序列并使用双向状态空间模型压缩视觉表示。在 ImageNet 分类、COCO 对象检测和 ADE20k 语义分割任务上,与 DeiT 等成熟的视觉转换器相比,Vim 实现了更高的性能,同时也证明了显著提高了计算和内存效率。例如,Vim比DeiT快2.8倍,在执行批处理推理时节省了86.8%的GPU内存,在分辨率为1248×1248的图像中提取特征。结果表明,Vim能够克服计算和内存约束,对高分辨率图像执行Transformer风格的理解,成为视觉基础模型的下一代骨干的巨大潜力。
1. Introduction
最近的研究进展导致人们对状态空间模型 (SSM) 的兴趣激增。现代SSM起源于经典的卡尔曼滤波模型[29],擅长捕捉长期依赖关系,并从并行训练中受益。提出了一些基于SSM的方法,如线性状态空间层(LSSL)[21]、结构化状态空间序列模型(S4)[20]、对角状态空间(DSS)[23]和S4D[22],用于处理各种任务和模式的序列数据,特别是在建模远程依赖方面。由于卷积计算和近似线性计算,它们在处理长序列方面是有效的。2-D SSM[2]、SGConvNeXt[36]和ConvSSM[51]将SSM与CNN或Transformer架构相结合来处理2-D数据。最近的工作 Mamba [19] 将时变参数合并到 SSM 中,并提出了一种硬件感知算法来实现非常有效的训练和推理。Mamba 的卓越性能表明它是 Transformer 在语言建模中的有前途的替代方案。然而,尚未探索一个通用的基于纯SSM的骨干网来处理视觉数据,如图像和视频。
Video Transformers(ViTs)在视觉表示学习方面取得了巨大的成功,在大规模自我监督预训练和下游任务的高性能方面表现出色。与卷积神经网络相比,核心优势在于ViT可以通过自我注意为每个图像补丁提供数据/补丁相关的全局上下文。这与对所有位置使用相同的参数(即卷积滤波器)的卷积网络不同。另一个优点是通过将图像视为没有 2D 归纳偏差的补丁序列来进行模态不可知建模,这使得它成为多模态应用程序的首选架构 [3, 35, 39]。同时,Transformers 中的自注意力机制在处理远程视觉依赖关系(例如处理高分辨率图像)时在速度和内存使用方面提出了挑战。
受 Mamba 在语言建模方面的成功启发,将这种成功从语言转移到视觉对我们来说很有吸引力,即使用先进的 SSM 方法设计通用且高效的视觉主干。然而,Mamba 存在两个挑战,即单向建模和缺乏位置感知。为了应对这些挑战,我们提出了视觉曼巴(Vim)模型,该模型结合了用于数据依赖的全局视觉上下文建模的双向ssm和用于位置感知视觉识别的位置嵌入。我们首先将输入图像分割成小块,并将它们线性投影为 Vim 的向量。图像块被视为 Vim 块中的序列数据,它使用所提出的双向选择性状态空间有效地压缩视觉表示。此外,Vim 块中的位置嵌入提供了对空间信息的认识,这使得 Vim 在密集预测任务中更加健壮。在这个阶段,我们使用 ImageNet 数据集在监督图像分类任务上训练 Vim 模型,然后使用预训练的 Vim 作为主干,为下游密集预测任务执行顺序视觉表示学习,即语义分割、对象检测和实例分割。与 Transformers 一样,Vim 可以在大规模无监督视觉数据上进行预训练,以实现更好的视觉表示。由于 Mamba 的更好效率,可以以更低的计算成本实现 Vim 的大规模预训练。
与其他基于SSM的视觉任务模型相比,Vim是一种基于纯SSM的方法,并以序列方式对图像进行建模,这对于通用和高效的主干更有前途。由于位置感知的双向压缩建模,Vim 是第一个基于纯 SSM 的模型来处理密集预测任务。与最令人信服的基于 Transformer 的模型(即 DeiT [59])相比,Vim 在 ImageNet 分类上取得了卓越的性能。此外,Vim 在高分辨率图像的 GPU 内存和推理时间方面更有效。在内存和速度方面的效率使 Vim 能够直接执行顺序视觉表示学习,而不依赖于 2D 先验(例如 ViTDet [37] 中的 2D 局部窗口)进行高分辨率视觉理解任务,同时实现比 DeiT 更高的精度。
我们的主要贡献可以概括如下:
• 我们提出了 Vision Mamba (Vim),它结合了双向 SSM 用于数据相关的全局视觉上下文建模和位置嵌入以进行位置感知视觉理解。
• 无需注意力机制,所提出的 Vim 与 ViT 具有相同的建模能力,而它只有次二次时间计算和线性内存复杂度。具体来说,Vim比DeiT快2.8倍,在执行批处理推理时节省了86.8%的GPU内存,在分辨率为1248×1248的图像中提取特征。
•我们对ImageNet分类和密集预测下游任务进行了广泛的实验。结果表明,与已建立的高度优化的普通视觉转换器(即 DeiT)相比,Vim 取得了更好的性能。
2. Related Work
通用视觉主干的架构。在早期的时代,ConvNet[33]作为计算机视觉事实上的标准网络设计。许多卷积神经架构[24,25,32,49,50,55-57,62,71]被提出作为各种视觉任务的视觉主干。开创性的工作 Vision Transformer (ViT) [13] 改变了景观。它将图像视为一系列扁平的 2D patch,并直接应用纯 Transformer 架构。ViT在图像分类及其缩放能力方面的惊人结果鼓励了许多后续工作[15,58,60,61]。一项研究侧重于通过将 2D 卷积先验引入 ViT [8, 12, 14, 68] 的混合架构设计。PVT[65]提出了一种金字塔结构变压器。Swin Transformer[41]在移位窗口内应用自我注意。另一项工作侧重于改进具有更先进的设置的传统 2D ConvNets [40, 66]。ConvNeXt [42] 回顾了设计空间并提出了纯 ConvNets,它可以作为 ViT 及其变体进行扩展。RepLKNet[11]建议扩大现有ConvNets的内核大小,带来改进。
虽然这些占主导地位的后续作品通过引入2D先验,在ImageNet[9]和各种下游任务[38,73]上表现出了更优越的性能和效率,但随着大规模视觉预训练[1,5,16]和多模态应用[3,28,34,35,39,48]的兴起,vanilla Transformer-style模型重新回到了计算机视觉的中心舞台。它具有建模容量大、多模态表示统一、便于自监督学习等优点,是首选的体系结构。然而,由于Transformer的二次复杂度,可视令牌的数量有限。有大量的作品[6,7,10,31,47,54,64]来解决这个长期存在的突出挑战,但很少有人关注视觉应用。最近,LongViT[67]通过扩展注意为计算病理学应用构建了一个高效的Transformer架构。LongViT的线性计算复杂度使其能够对极长的视觉序列进行编码。在这项工作中,我们从Mamba[19]中汲取灵感,探索在不使用注意力的情况下构建纯ssm模型作为通用视觉主干,同时保留ViT的顺序性、模态不可知建模优点。
用于长序列建模的状态空间模型。[20]提出了一种结构化状态空间序列(S4)模型,这是cnn或transformer的一种新颖替代方案,用于建模远程依赖关系。序列长度线性缩放的前景值得进一步探索。[52]通过在S4层中引入MIMO SSM和高效并行扫描,提出了一种新的S5层。[17]设计了一个新的SSM层H3,几乎填补了SSM和Transformer在语言建模方面的性能差距。[45]通过引入更多的门控单元,在S4上构建门控状态空间层,以提高表现力。最近,[19]提出了一种依赖于数据的SSM层,并构建了一个通用语言模型主干Mamba,在大规模真实数据上,它在各种尺寸上都优于transformer,并且序列长度呈线性缩放。在这项工作中,我们探索将曼巴的成功转移到视觉上,即纯粹在SSM上建立一个通用的视觉骨干,而不需要注意力机制。
用于可视化应用程序的状态空间模型。[26]使用1D S4来处理视频分类的长时间依赖关系。[46]进一步扩展了1D S4以处理包括2D图像和3D视频在内的多维数据。[27]结合S4和自关注的优势构建TranS4mer模型,实现了最先进的电影场景检测性能。[63]为S4引入了一种新的选择性机制,极大地提高了S4在长格式视频理解方面的性能,并且内存占用更低。[72]用更具可扩展性的基于ssm的主干取代了注意力机制,以在可承受的计算下生成高分辨率图像并处理细粒度表示。[44]提出了一种混合CNN-SSM架构U-Mamba来处理生物医学图像分割中的远程依赖关系。上述工作要么将SSM应用于特定的视觉应用程序,要么通过将SSM与卷积或注意力相结合来构建混合架构。与之不同的是,我们建立了一个纯ssm的模型,该模型可以作为通用的视觉主干。
3. Method
Vision Mamba (Vim)的目标是将高级状态空间模型(SSM),即Mamba[19]引入到计算机视觉中。本节首先描述 SSM 的预备知识。然后是 Vim 的概述。然后我们详细介绍 Vim 块如何处理输入标记序列并继续说明 Vim 的架构细节。本节最后分析了所提出的 Vim 的效率。
3.1. Preliminaries
基于 SSM 的模型,即结构化状态空间模型 (S4) 和 Mamba 受到连续系统的启发,该系统通过隐藏状态 h(t) ∈ RN 映射 1-D 函数或序列x(t) ∈ R 7 → y(t)∈R。该系统使用 A ∈ RN×N 作为演化参数,B ∈ RN×1, C ∈ R1×N 作为投影参数。

S4 和 Mamba 是连续系统的离散版本,其中包括一个时间尺度参数 Δ 将连续参数 A、B 转换为离散参数 A拔、B拔。常用的变换方法是零阶保持 (ZOH),定义如下:

在对 A、B 的离散化之后,等式 (1) 的离散版本使用步长 Δ 可以重写为:

最后,模型通过全局卷积计算输出

式中,M为输入序列x的长度,K∈R^m为结构化卷积核。
3.2. Vision Mamba

所提出的Vim的概述如图2所示。标准Mamba是为1-D序列设计的。为了处理视觉任务,我们首先将2D图像∈R^H×W×C变换为展开的2D patch Xp∈R^j (P^2·C),其中(H, W)为输入图像的大小,C为通道数,P为图像patch的大小。接下来,我们将xp线性投影到大小为D的向量上,并添加位置嵌入Epos∈R^(J+1)×D,如下所示:
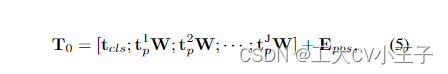
(位置编码个数比patch个数加一是因为T0多了一个tcls的token)
(这个t应该是把x的H,W,C合并成一个维度之后的向量,就是把patch展平后的向量,就像Swin-Transformer一开始对图片做Embedding的那样)
其中 tjp 是 t 的第 j 个补丁,W ∈ R^(P^2·C)×D 是可学习的投影矩阵。受ViT[13]和BERT[30]的启发,我们还使用类标记来表示整个patch序列,记为tcls。然后,我们将令牌序列 (Tl−1) 发送到 Vim 编码器的第 l 层,得到输出 Tl。最后,我们对输出类标记 T0L 进行归一化并将其馈送到多层感知器 (MLP) 头以获得最终预测 ^p,如下所示:

(从公式可以看出,这个Vim中应该是用到了残差连接)
其中 Vim 是所提出的视觉 mamba 块,L 是层数,Norm 是归一化层。
3.3. Vim Block
原始的 Mamba 块是为 1D 序列设计的,不适合需要空间感知理解的视觉任务。在本节中,我们将介绍 Vim 块,它结合了视觉任务的双向序列建模。Vim 块如图 2 所示。具体来说,我们展示了 Algo 中 Vim 块的操作。21. 输入标记序列 Tl-1 首先由归一化层归一化。接下来,我们将归一化序列线性投影到维度为 E 的 x 和 z。然后,我们从前向和后向处理 x。对于每个方向,我们首先将 1-D 卷积应用于 x 并获得 x′o。然后,我们分别将 x′o 线性投影到 Bo、Co、Δo。然后使用 Δo 分别变换 Ao拔、Bo拔。最后,我们通过SSM计算yforward和ybackward,yforward和ybackward由z进行门控处理,并将它们加在一起(其实又走了个线性层和残差连接)得到输出标记序列Tl

(这个伪代码其实和图二那个流程图说的事是一模一样的)
3.4. Architecture Details
总之,我们架构的超参数如下:
L:块的数量,
D:隐藏状态维度,
E:扩展状态维度,
N:SSM维度。
在 ViT [13] 和 DeiT [60] 之后,我们首先使用 16×16 内核大小投影层来获得非重叠补丁嵌入的一维序列。随后,我们直接堆叠 L Vim 块。默认情况下,我们将块的数量 L 设置为 24,SSM 维度 N 设置为 16。为了与 DeiT 系列的模型大小保持一致,我们将隐藏状态维度 D 设置为 192,并将状态维度 E 扩展到 384 用于Tiny尺寸变体。对于Small尺寸变体,我们将 D 设置为 384,E 设置为 768。
3.5. Efficiency Analysis
传统的基于SSM的方法利用快速傅里叶变换来提高卷积运算,如式(4)所示。对于依赖于数据的方法,例如 Mamba,Algo 第 11 行的 SSM 操作。21 不再等同于卷积。为了解决这个问题,Mamba 和提议的 Vim 选择一种现代硬件友好的方法来确保效率。这种优化的关键思想是避免现代硬件加速器 (GPU) 的 IO 绑定和内存绑定。
IO效率。高带宽内存 (HBM) 和 SRAM 是 GPU 的两个重要组件。其中,SRAM具有更大的带宽,HBM具有更大的内存大小。使用 HBM 的 Vim 的 SSM 操作的标准实现需要 O(BMEN) 的顺序的内存 IO 数量。受 Mamba 的启发,Vim 首先从慢速 HBM 到快速 SRAM 的 O(BME + EN) 字节内存 (Δo, Ao, Bo, Co) 读取。然后,Vim 在 SRAM 中得到大小为 (B, M, E, N) 的离散 Ao,Bo。最后,Vim 在 SRAM 中执行 SSM 操作,并将大小为 (B, M, E) 的输出写入 HBM。这种方法可以帮助将 IO 从 O(BMEN) 减少到 O(BME + EN)。
内存效率。为了避免内存不足问题并在处理长序列时实现较低的内存使用,Vim 选择与 Mamba 相同的重新计算方法。对于大小为 (B, M, E, N) 的中间状态来计算梯度,Vim 在网络后向传递处重新计算它们。对于激活函数和卷积输出等中间激活,Vim 还重新计算它们以优化 GPU 内存需求,因为激活值占用大量内存,但重新计算速度很快。
计算效率。Vim块中的SSM(Algo.2中的第11行)和Transformer中的自我注意都自适应地提供全局上下文起着关键作用。给定一个视觉序列 T ∈ R1×M×D 和默认设置 E = 2D,全局自注意力和 SSM 的计算复杂度为:

其中自注意力是序列长度 M 的二次方,SSM 与序列长度 M 成线性关系(N 是固定参数,默认设置为 16)。计算效率使得 Vim 对具有大序列长度的十亿像素应用程序具有可扩展性。
4. Experiment

略





![Linux repo基本用法: 搭建自己的repo仓库[服务端]](https://img-blog.csdnimg.cn/direct/4ff0eb8bf537489dbb519f8e33bb06bb.png#pic_center)