Netty核心原理剖析与RPC实践21-25
21 技巧篇:延迟任务处理神器之时间轮 HahedWheelTimer
Netty 中有很多场景依赖定时任务实现,比较典型的有客户端连接的超时控制、通信双方连接的心跳检测等场景。在学习 Netty Reactor 线程模型时,我们知道 NioEventLoop 不仅负责处理 I/O 事件,而且兼顾执行任务队列中的任务,其中就包括定时任务。为了实现高性能的定时任务调度,Netty 引入了时间轮算法驱动定时任务的执行。时间轮到底是什么呢?为什么 Netty 一定要用时间轮来处理定时任务呢?JDK 原生的实现方案不能满足要求吗?本节课我将一步步为你深入剖析时间轮的原理以及 Netty 中是如何实现时间轮算法的。
说明:本文参考的 Netty 源码版本为 4.1.42.Final。
定时任务的基础知识
首先,我们先了解下什么是定时任务?定时器有非常多的使用场景,大家在平时工作中应该经常遇到,例如生成月统计报表、财务对账、会员积分结算、邮件推送等,都是定时器的使用场景。定时器一般有三种表现形式:按固定周期定时执行、延迟一定时间后执行、指定某个时刻执行。
定时器的本质是设计一种数据结构,能够存储和调度任务集合,而且 deadline 越近的任务拥有更高的优先级。那么定时器如何知道一个任务是否到期了呢?定时器需要通过轮询的方式来实现,每隔一个时间片去检查任务是否到期。
所以定时器的内部结构一般需要一个任务队列和一个异步轮询线程,并且能够提供三种基本操作:
- Schedule 新增任务至任务集合;
- Cancel 取消某个任务;
- Run 执行到期的任务。
JDK 原生提供了三种常用的定时器实现方式,分别为 Timer、DelayedQueue 和 ScheduledThreadPoolExecutor。下面我们逐一对它们进行介绍。
Timer
Timer 属于 JDK 比较早期版本的实现,它可以实现固定周期的任务,以及延迟任务。Timer 会起动一个异步线程去执行到期的任务,任务可以只被调度执行一次,也可以周期性反复执行多次。我们先来看下 Timer 是如何使用的,示例代码如下。
Timer timer = new Timer();
timer.scheduleAtFixedRate(new TimerTask() {@Overridepublic void run() {// do something}
}, 10000, 1000); // 10s 后调度一个周期为 1s 的定时任务
可以看出,任务是由 TimerTask 类实现,TimerTask 是实现了 Runnable 接口的抽象类,Timer 负责调度和执行 TimerTask。接下来我们看下 Timer 的内部构造。
public class Timer {private final TaskQueue queue = new TaskQueue();private final TimerThread thread = new TimerThread(queue); public Timer(String name) {thread.setName(name);thread.start();}
}
TaskQueue 是由数组结构实现的小根堆,deadline 最近的任务位于堆顶端,queue[1] 始终是最优先被执行的任务。所以使用小根堆的数据结构,Run 操作时间复杂度 O(1),新增 Schedule 和取消 Cancel 操作的时间复杂度都是 O(logn)。
Timer 内部启动了一个 TimerThread 异步线程,不论有多少任务被加入数组,始终都是由 TimerThread 负责处理。TimerThread 会定时轮询 TaskQueue 中的任务,如果堆顶的任务的 deadline 已到,那么执行任务;如果是周期性任务,执行完成后重新计算下一次任务的 deadline,并再次放入小根堆;如果是单次执行的任务,执行结束后会从 TaskQueue 中删除。
DelayedQueue
DelayedQueue 是 JDK 中一种可以延迟获取对象的阻塞队列,其内部是采用优先级队列 PriorityQueue 存储对象。DelayQueue 中的每个对象都必须实现 Delayed 接口,并重写 compareTo 和 getDelay 方法。DelayedQueue 的使用方法如下:
public class DelayQueueTest {public static void main(String[] args) throws Exception {BlockingQueue<SampleTask> delayQueue = new DelayQueue<>();long now = System.currentTimeMillis();delayQueue.put(new SampleTask(now + 1000));delayQueue.put(new SampleTask(now + 2000));delayQueue.put(new SampleTask(now + 3000));for (int i = 0; i < 3; i++) {System.out.println(new Date(delayQueue.take().getTime()));}}static class SampleTask implements Delayed {long time;public SampleTask(long time) {this.time = time;}public long getTime() {return time;}@Overridepublic int compareTo(Delayed o) {return Long.compare(this.getDelay(TimeUnit.MILLISECONDS), o.getDelay(TimeUnit.MILLISECONDS));}@Overridepublic long getDelay(TimeUnit unit) {return unit.convert(time - System.currentTimeMillis(), TimeUnit.MILLISECONDS);}}
}
DelayQueue 提供了 put() 和 take() 的阻塞方法,可以向队列中添加对象和取出对象。对象被添加到 DelayQueue 后,会根据 compareTo() 方法进行优先级排序。getDelay() 方法用于计算消息延迟的剩余时间,只有 getDelay <=0 时,该对象才能从 DelayQueue 中取出。
DelayQueue 在日常开发中最常用的场景就是实现重试机制。例如,接口调用失败或者请求超时后,可以将当前请求对象放入 DelayQueue,通过一个异步线程 take() 取出对象然后继续进行重试。如果还是请求失败,继续放回 DelayQueue。为了限制重试的频率,可以设置重试的最大次数以及采用指数退避算法设置对象的 deadline,如 2s、4s、8s、16s ……以此类推。
相比于 Timer,DelayQueue 只实现了任务管理的功能,需要与异步线程配合使用。DelayQueue 使用优先级队列实现任务的优先级排序,新增 Schedule 和取消 Cancel 操作的时间复杂度也是 O(logn)。
ScheduledThreadPoolExecutor
上文中介绍的 Timer 其实目前并不推荐用户使用,它是存在不少设计缺陷的。
- Timer 是单线程模式。如果某个 TimerTask 执行时间很久,会影响其他任务的调度。
- Timer 的任务调度是基于系统绝对时间的,如果系统时间不正确,可能会出现问题。
- TimerTask 如果执行出现异常,Timer 并不会捕获,会导致线程终止,其他任务永远不会执行。
为了解决 Timer 的设计缺陷,JDK 提供了功能更加丰富的 ScheduledThreadPoolExecutor。ScheduledThreadPoolExecutor 提供了周期执行任务和延迟执行任务的特性,下面通过一个例子先看下 ScheduledThreadPoolExecutor 如何使用。
public class ScheduledExecutorServiceTest {public static void main(String[] args) {ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);executor.scheduleAtFixedRate(() -> System.out.println("Hello World"), 1000, 2000, TimeUnit.MILLISECONDS); // 1s 延迟后开始执行任务,每 2s 重复执行一次}
}
ScheduledThreadPoolExecutor 继承于 ThreadPoolExecutor,因此它具备线程池异步处理任务的能力。线程池主要负责管理创建和管理线程,并从自身的阻塞队列中不断获取任务执行。线程池有两个重要的角色,分别是任务和阻塞队列。ScheduledThreadPoolExecutor 在 ThreadPoolExecutor 的基础上,重新设计了任务 ScheduledFutureTask 和阻塞队列 DelayedWorkQueue。ScheduledFutureTask 继承于 FutureTask,并重写了 run() 方法,使其具备周期执行任务的能力。DelayedWorkQueue 内部是优先级队列,deadline 最近的任务在队列头部。对于周期执行的任务,在执行完会重新设置时间,并再次放入队列中。ScheduledThreadPoolExecutor 的实现原理可以用下图表示。
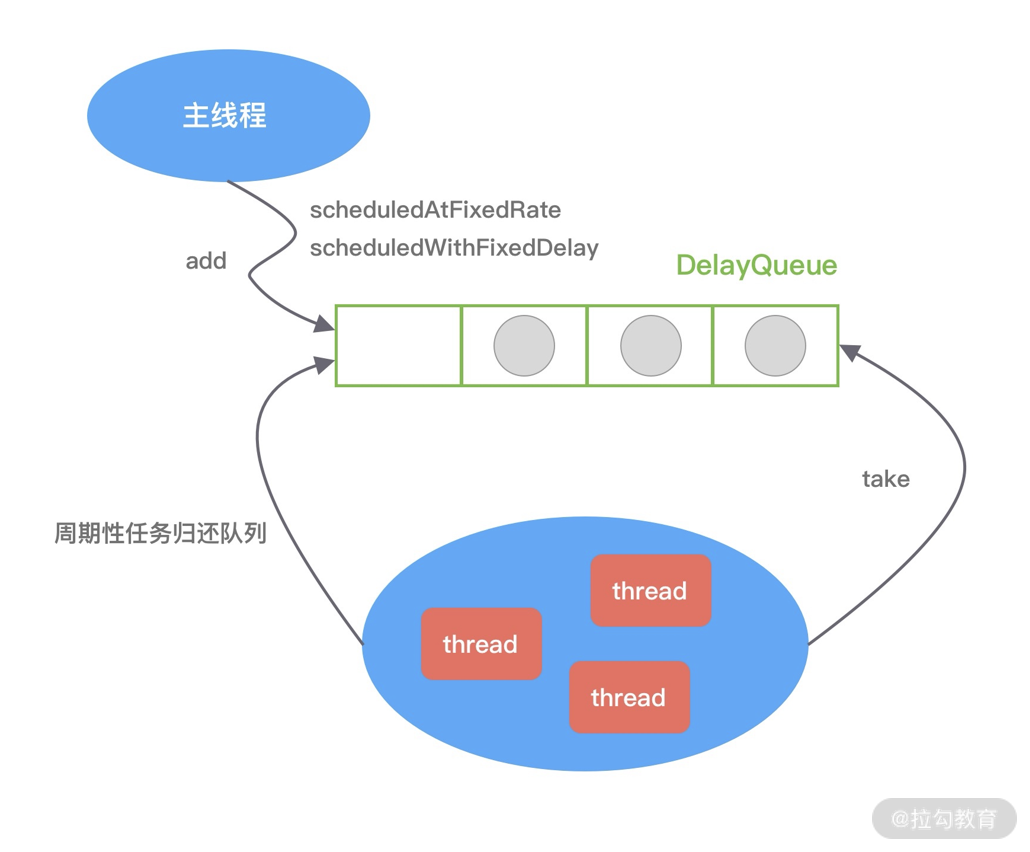
以上我们简单介绍了 JDK 三种实现定时器的方式。可以说它们的实现思路非常类似,都离不开任务、任务管理、任务调度三个角色。三种定时器新增和取消任务的时间复杂度都是 O(logn),面对海量任务插入和删除的场景,这三种定时器都会遇到比较严重的性能瓶颈。因此,对于性能要求较高的场景,我们一般都会采用时间轮算法。那么时间轮又是如何解决海量任务插入和删除的呢?我们继续向下分析。
时间轮原理分析
技术有时就源于生活,例如排队买票可以想到队列,公司的组织关系可以理解为树等,而时间轮算法的设计思想就来源于钟表。如下图所示,时间轮可以理解为一种环形结构,像钟表一样被分为多个 slot 槽位。每个 slot 代表一个时间段,每个 slot 中可以存放多个任务,使用的是链表结构保存该时间段到期的所有任务。时间轮通过一个时针随着时间一个个 slot 转动,并执行 slot 中的所有到期任务。
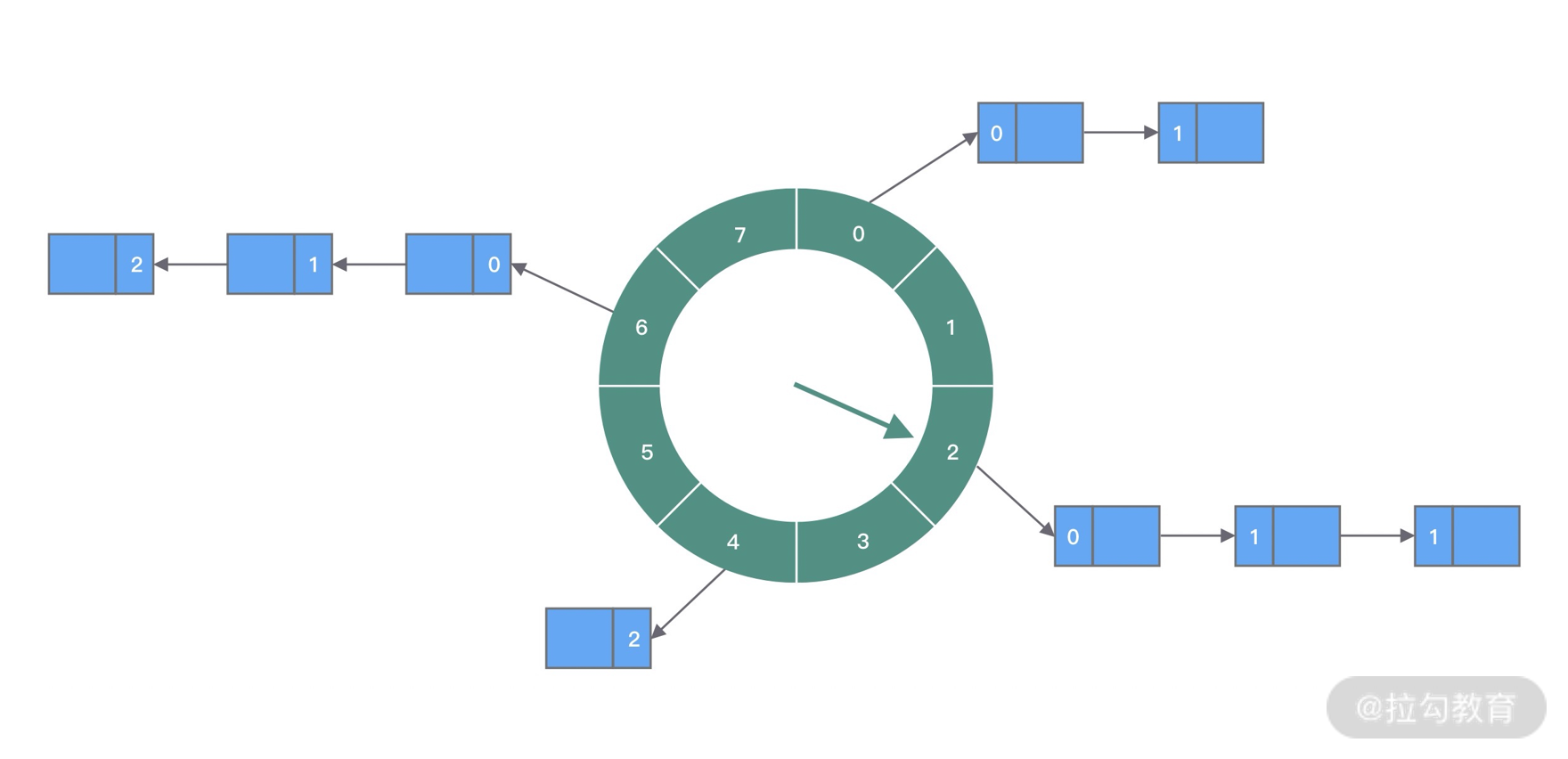
任务是如何添加到时间轮当中的呢?可以根据任务的到期时间进行取模,然后将任务分布到不同的 slot 中。如上图所示,时间轮被划分为 8 个 slot,每个 slot 代表 1s,当前时针指向 2。假如现在需要调度一个 3s 后执行的任务,应该加入 2+3=5 的 slot 中;如果需要调度一个 12s 以后的任务,需要等待时针完整走完一圈 round 零 4 个 slot,需要放入第 (2+12)%8=6 个 slot。
那么当时针走到第 6 个 slot 时,怎么区分每个任务是否需要立即执行,还是需要等待下一圈 round,甚至更久时间之后执行呢?所以我们需要把 round 信息保存在任务中。例如图中第 6 个 slot 的链表中包含 3 个任务,第一个任务 round=0,需要立即执行;第二个任务 round=1,需要等待 18=8s 后执行;第三个任务 round=2,需要等待 28=8s 后执行。所以当时针转动到对应 slot 时,只执行 round=0 的任务,slot 中其余任务的 round 应当减 1,等待下一个 round 之后执行。
上面介绍了时间轮算法的基本理论,可以看出时间轮有点类似 HashMap,如果多个任务如果对应同一个 slot,处理冲突的方法采用的是拉链法。在任务数量比较多的场景下,适当增加时间轮的 slot 数量,可以减少时针转动时遍历的任务个数。
时间轮定时器最大的优势就是,任务的新增和取消都是 O(1) 时间复杂度,而且只需要一个线程就可以驱动时间轮进行工作。HashedWheelTimer 是 Netty 中时间轮算法的实现类,下面我就结合 HashedWheelTimer 的源码详细分析时间轮算法的实现原理。
Netty HashedWheelTimer 源码解析
在开始学习 HashedWheelTimer 的源码之前,需要了解 HashedWheelTimer 接口定义以及相关组件,才能更好地使用 HashedWheelTimer。
接口定义
HashedWheelTimer 实现了接口 io.netty.util.Timer,Timer 接口是我们研究 HashedWheelTimer 一个很好的切入口。一起看下 Timer 接口的定义:
public interface Timer {Timeout newTimeout(TimerTask task, long delay, TimeUnit unit);Set<Timeout> stop();
}
Timer 接口提供了两个方法,分别是创建任务 newTimeout() 和停止所有未执行任务 stop()。从方法的定义可以看出,Timer 可以认为是上层的时间轮调度器,通过 newTimeout() 方法可以提交一个任务 TimerTask,并返回一个 Timeout。TimerTask 和 Timeout 是两个接口类,它们有什么作用呢?我们分别看下 TimerTask 和 Timeout 的接口定义:
public interface TimerTask {void run(Timeout timeout) throws Exception;
}
public interface Timeout {Timer timer();TimerTask task();boolean isExpired();boolean isCancelled();boolean cancel();
}
Timeout 持有 Timer 和 TimerTask 的引用,而且通过 Timeout 接口可以执行取消任务的操作。Timer、Timeout 和 TimerTask 之间的关系如下图所示:
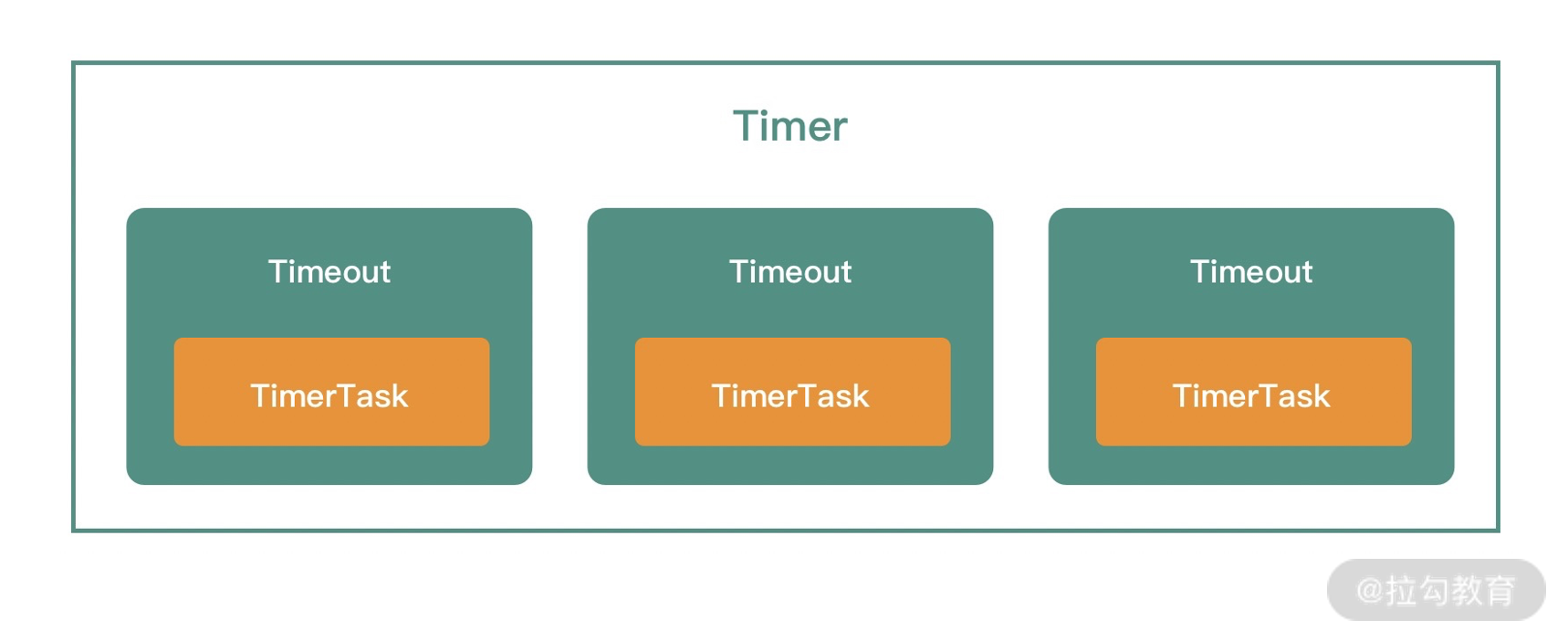
清楚 HashedWheelTimer 的接口定义以及相关组件的概念之后,接下来我们就可以开始使用它了。
快速上手
通过下面这个简单的例子,我们看下 HashedWheelTimer 是如何使用的。
public class HashedWheelTimerTest {public static void main(String[] args) {Timer timer = new HashedWheelTimer();Timeout timeout1 = timer.newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) {System.out.println("timeout1: " + new Date());}}, 10, TimeUnit.SECONDS);if (!timeout1.isExpired()) {timeout1.cancel();}timer.newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) throws InterruptedException {System.out.println("timeout2: " + new Date());Thread.sleep(5000);}}, 1, TimeUnit.SECONDS);timer.newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) {System.out.println("timeout3: " + new Date());}}, 3, TimeUnit.SECONDS);}
}
代码运行结果如下:
timeout2: Mon Nov 09 19:57:04 CST 2020
timeout3: Mon Nov 09 19:57:09 CST 2020
简单的几行代码,基本展示了 HashedWheelTimer 的大部分用法。示例中我们通过 newTimeout() 启动了三个 TimerTask,timeout1 由于被取消了,所以并没有执行。timeout2 和 timeout3 分别应该在 1s 和 3s 后执行。然而从结果输出看并不是,timeout2 和 timeout3 的打印时间相差了 5s,这是由于 timeout2 阻塞了 5s 造成的。由此可以看出,时间轮中的任务执行是串行的,当一个任务执行的时间过长,会影响后续任务的调度和执行,很可能产生任务堆积的情况。
至此,对 HashedWheelTimer 的基本使用方法已经有了初步了解,下面我们开始深入研究 HashedWheelTimer 的实现原理。
内部结构
我们先从 HashedWheelTimer 的构造函数看起,结合上文中介绍的时间轮算法,一起梳理出 HashedWheelTimer 的内部实现结构。
public HashedWheelTimer(ThreadFactory threadFactory,long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,long maxPendingTimeouts) {// 省略其他代码 wheel = createWheel(ticksPerWheel); // 创建时间轮的环形数组结构mask = wheel.length - 1; // 用于快速取模的掩码long duration = unit.toNanos(tickDuration); // 转换成纳秒处理// 省略其他代码workerThread = threadFactory.newThread(worker); // 创建工作线程leak = leakDetection || !workerThread.isDaemon() ? leakDetector.track(this) : null; // 是否开启内存泄漏检测this.maxPendingTimeouts = maxPendingTimeouts; // 最大允许等待任务数,HashedWheelTimer 中任务超出该阈值时会抛出异常// 如果 HashedWheelTimer 的实例数超过 64,会打印错误日志if (INSTANCE_COUNTER.incrementAndGet() > INSTANCE_COUNT_LIMIT &&WARNED_TOO_MANY_INSTANCES.compareAndSet(false, true)) {reportTooManyInstances();}
}
HashedWheelTimer 的构造函数清晰地列举出了几个核心属性:
- threadFactory,线程池,但是只创建了一个线程;
- tickDuration,时针每次 tick 的时间,相当于时针间隔多久走到下一个 slot;
- unit,表示 tickDuration 的时间单位;
- ticksPerWheel,时间轮上一共有多少个 slot,默认 512 个。分配的 slot 越多,占用的内存空间就越大;
- leakDetection,是否开启内存泄漏检测;
- maxPendingTimeouts,最大允许等待任务数。
下面我们看下 HashedWheelTimer 是如何创建出来的,我们直接跟进 createWheel() 方法的源码:
private static HashedWheelBucket[] createWheel(int ticksPerWheel) {// 省略其他代码ticksPerWheel = normalizeTicksPerWheel(ticksPerWheel);HashedWheelBucket[] wheel = new HashedWheelBucket[ticksPerWheel];for (int i = 0; i < wheel.length; i ++) {wheel[i] = new HashedWheelBucket();}return wheel;
}
private static int normalizeTicksPerWheel(int ticksPerWheel) {int normalizedTicksPerWheel = 1;while (normalizedTicksPerWheel < ticksPerWheel) {normalizedTicksPerWheel <<= 1;}return normalizedTicksPerWheel;
}
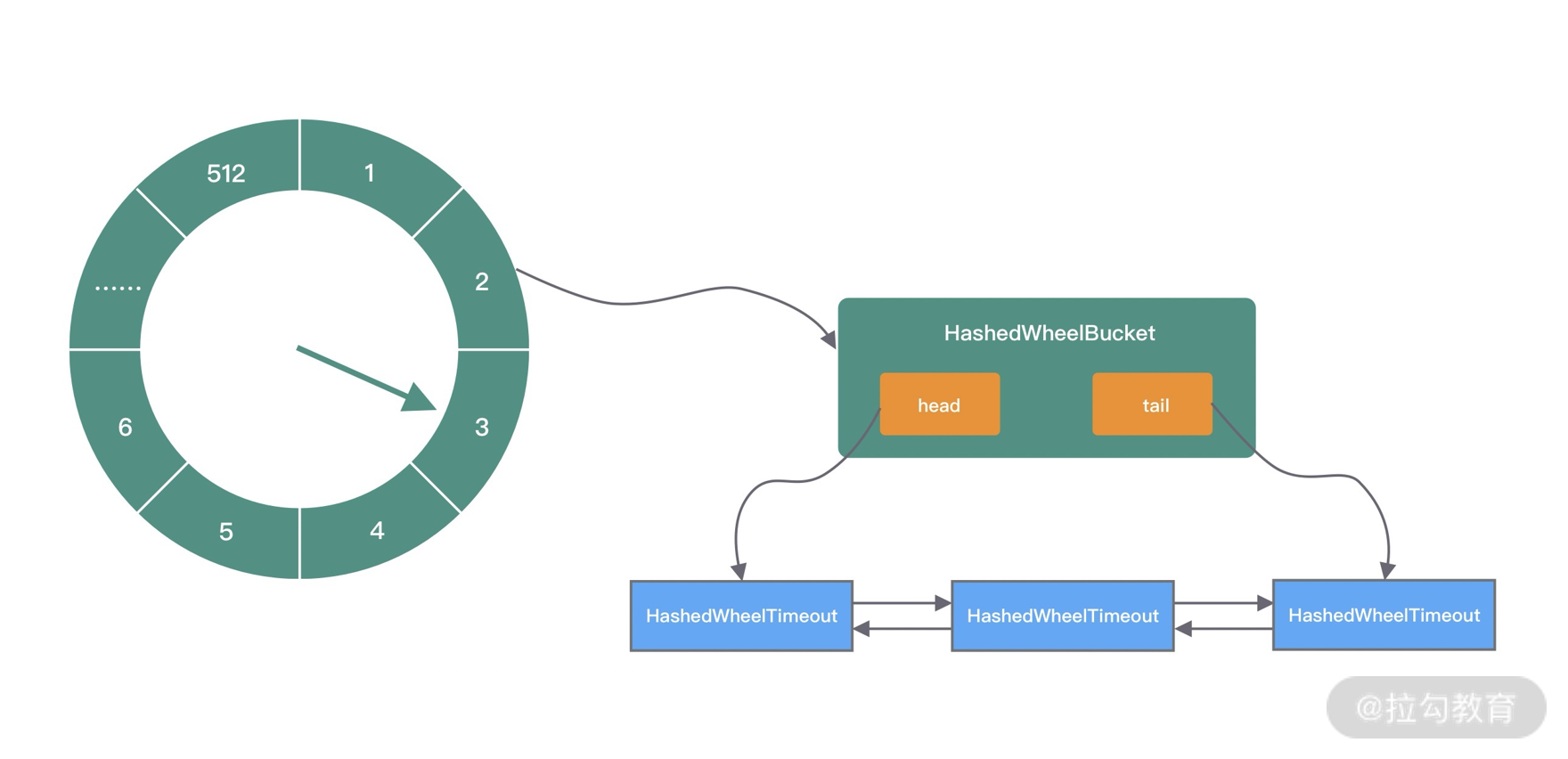
private static final class HashedWheelBucket {private HashedWheelTimeout head;private HashedWheelTimeout tail;// 省略其他代码
}
时间轮的创建就是为了创建 HashedWheelBucket 数组,每个 HashedWheelBucket 表示时间轮中一个 slot。从 HashedWheelBucket 的结构定义可以看出,HashedWheelBucket 内部是一个双向链表结构,双向链表的每个节点持有一个 HashedWheelTimeout 对象,HashedWheelTimeout 代表一个定时任务。每个 HashedWheelBucket 都包含双向链表 head 和 tail 两个 HashedWheelTimeout 节点,这样就可以实现不同方向进行链表遍历。关于 HashedWheelBucket 和 HashedWheelTimeout 的具体功能下文再继续介绍。
因为时间轮需要使用 & 做取模运算,所以数组的长度需要是 2 的次幂。normalizeTicksPerWheel() 方法的作用就是找到不小于 ticksPerWheel 的最小 2 次幂,这个方法实现的并不好,可以参考 JDK HashMap 扩容 tableSizeFor 的实现进行性能优化,如下所示。当然 normalizeTicksPerWheel() 只是在初始化的时候使用,所以并无影响。
static final int MAXIMUM_CAPACITY = 1 << 30;
private static int normalizeTicksPerWheel(int ticksPerWheel) {int n = ticksPerWheel - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashedWheelTimer 初始化的主要工作我们已经介绍完了,其内部结构与上文中介绍的时间轮算法类似,如下图所示。
接下来我们围绕定时器的三种基本操作,分析下 HashedWheelTimer 是如何实现添加任务、执行任务和取消任务的。
添加任务
HashedWheelTimer 初始化完成后,如何向 HashedWheelTimer 添加任务呢?我们自然想到 HashedWheelTimer 提供的 newTimeout() 方法。
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {// 省略其他代码long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {pendingTimeouts.decrementAndGet();throw new RejectedExecutionException("Number of pending timeouts ("+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "+ "timeouts (" + maxPendingTimeouts + ")");}start(); // 1. 如果 worker 线程没有启动,需要启动long deadline = System.nanoTime() + unit.toNanos(delay) - startTime; // 计算任务的 deadlineif (delay > 0 && deadline < 0) {deadline = Long.MAX_VALUE;}HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline); // 2. 创建定时任务timeouts.add(timeout); // 3. 添加任务到 Mpsc Queuereturn timeout;
}
private final Queue<HashedWheelTimeout> timeouts = PlatformDependent.newMpscQueue();
newTimeout() 方法主要做了三件事,分别为启动工作线程,创建定时任务,并把任务添加到 Mpsc Queue。HashedWheelTimer 的工作线程采用了懒启动的方式,不需要用户显示调用。这样做的好处是在时间轮中没有任务时,可以避免工作线程空转而造成性能损耗。先看下启动工作线程 start() 的源码:
public void start() {switch (WORKER_STATE_UPDATER.get(this)) {case WORKER_STATE_INIT:if (WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_INIT, WORKER_STATE_STARTED)) {workerThread.start();}break;case WORKER_STATE_STARTED:break;case WORKER_STATE_SHUTDOWN:throw new IllegalStateException("cannot be started once stopped");default:throw new Error("Invalid WorkerState");}while (startTime == 0) {try {startTimeInitialized.await();} catch (InterruptedException ignore) {}}
}
工作线程的启动之前,会通过 CAS 操作获取工作线程的状态,如果已经启动,则直接跳过。如果没有启动,再次通过 CAS 操作更改工作线程状态,然后启动工作线程。启动的过程是直接调用的 Thread#start() 方法,我们暂且先不关注工作线程具体做了什么,下文再继续分析。
回到 newTimeout() 的主流程,接下来的逻辑就非常简单了。根据用户传入的任务延迟时间,可以计算出任务的 deadline,然后创建定时任务 HashedWheelTimeout 对象,最终把 HashedWheelTimeout 添加到 Mpsc Queue 中。看到这里,你会不会有个疑问,为什么不是将 HashedWheelTimeout 直接添加到时间轮中呢?而是先添加到 Mpsc Queue?Mpsc Queue 可以理解为多生产者单消费者的线程安全队列,下节课我们会对 Mpsc Queue 详细分析,在这里就不做展开了。可以猜到 HashedWheelTimer 是想借助 Mpsc Queue 保证多线程向时间轮添加任务的线程安全性。
那么什么时候任务才会被加入时间轮并执行呢?此时还没有太多信息,接下来我们只能工作线程 Worker 里寻找问题的答案。
工作线程 Worker
工作线程 Worker 是时间轮的核心引擎,随着时针的转动,到期任务的处理都由 Worker 处理完成。下面我们定位到 Worker 的 run() 方法一探究竟。
private final class Worker implements Runnable {private final Set<Timeout> unprocessedTimeouts = new HashSet<Timeout>(); // 未处理任务列表private long tick;@Overridepublic void run() {startTime = System.nanoTime();if (startTime == 0) {startTime = 1;}startTimeInitialized.countDown();do {final long deadline = waitForNextTick(); // 1. 计算下次 tick 的时间, 然后sleep 到下次 tickif (deadline > 0) { // 可能因为溢出或者线程中断,造成 deadline <= 0int idx = (int) (tick & mask); // 2. 获取当前 tick 在 HashedWheelBucket 数组中对应的下标processCancelledTasks(); // 3. 移除被取消的任务HashedWheelBucket bucket =wheel[idx];transferTimeoutsToBuckets(); // 4. 从 Mpsc Queue 中取出任务加入对应的 slot 中bucket.expireTimeouts(deadline); // 5. 执行到期的任务tick++;}} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);// 时间轮退出后,取出 slot 中未执行且未被取消的任务,并加入未处理任务列表,以便 stop() 方法返回for (HashedWheelBucket bucket: wheel) {bucket.clearTimeouts(unprocessedTimeouts);}// 将还没来得及添加到 slot 中的任务取出,如果任务未取消则加入未处理任务列表,以便 stop() 方法返回for (;;) {HashedWheelTimeout timeout = timeouts.poll();if (timeout == null) {break;}if (!timeout.isCancelled()) {unprocessedTimeouts.add(timeout);}}processCancelledTasks();}
}
工作线程 Worker 的核心执行流程是代码中的 do-while 循环,只要 Worker 处于 STARTED 状态,就会执行 do-while 循环,我们把该过程拆分成为以下几个步骤,逐一分析。
- 通过 waitForNextTick() 方法计算出时针到下一次 tick 的时间间隔,然后 sleep 到下一次 tick。
- 通过位运算获取当前 tick 在 HashedWheelBucket 数组中对应的下标
- 移除被取消的任务。
- 从 Mpsc Queue 中取出任务加入对应的 HashedWheelBucket 中。
- 执行当前 HashedWheelBucket 中的到期任务。
首先看下 waitForNextTick() 方法是如何计算等待时间的,源码如下:
private long waitForNextTick() {long deadline = tickDuration * (tick + 1);for (;;) {final long currentTime = System.nanoTime() - startTime;long sleepTimeMs = (deadline - currentTime + 999999) / 1000000;if (sleepTimeMs <= 0) {if (currentTime == Long.MIN_VALUE) {return -Long.MAX_VALUE;} else {return currentTime;}}if (PlatformDependent.isWindows()) {sleepTimeMs = sleepTimeMs / 10 * 10;}try {Thread.sleep(sleepTimeMs);} catch (InterruptedException ignored) {if (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_SHUTDOWN) {return Long.MIN_VALUE;}}}
}
根据 tickDuration 可以推算出下一次 tick 的 deadline,deadline 减去当前时间就可以得到需要 sleep 的等待时间。所以 tickDuration 的值越小,时间的精准度也就越高,同时 Worker 的繁忙程度越高。如果 tickDuration 设置过小,为了防止系统会频繁地 sleep 再唤醒,会保证 Worker 至少 sleep 的时间为 1ms 以上。
Worker 从 sleep 状态唤醒后,接下来会执行第二步流程,通过按位与的操作计算出当前 tick 在 HashedWheelBucket 数组中对应的下标。按位与比普通的取模运算效率要快很多,前提是时间轮中的数组长度是 2 的次幂,掩码 mask 为 2 的次幂减 1,这样才能达到与取模一样的效果。
接下来 Worker 会调用 processCancelledTasks() 方法处理被取消的任务,所有取消的任务都会加入 cancelledTimeouts 队列中,Worker 会从队列中取出任务,然后将其从对应的 HashedWheelBucket 中删除,删除操作为基本的链表操作。processCancelledTasks() 的源码比较简单,我们在此就不展开了。
之前我们还留了一个疑问,Mpsc Queue 中的任务什么时候加入时间轮的呢?答案就在 transferTimeoutsToBuckets() 方法中。
private void transferTimeoutsToBuckets() {// 每次时针 tick 最多只处理 100000 个任务,以防阻塞 Worker 线程for (int i = 0; i < 100000; i++) {HashedWheelTimeout timeout = timeouts.poll();if (timeout == null) {break;}if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {continue;}long calculated = timeout.deadline / tickDuration; // 计算任务需要经过多少个 ticktimeout.remainingRounds = (calculated - tick) / wheel.length; // 计算任务需要在时间轮中经历的圈数 remainingRoundsfinal long ticks = Math.max(calculated, tick); // 如果任务在 timeouts 队列里已经过了执行时间, 那么会加入当前 HashedWheelBucket 中int stopIndex = (int) (ticks & mask);HashedWheelBucket bucket = wheel[stopIndex];bucket.addTimeout(timeout);}
}
transferTimeoutsToBuckets() 的主要工作就是从 Mpsc Queue 中取出任务,然后添加到时间轮对应的 HashedWheelBucket 中。每次时针 tick 最多只处理 100000 个任务,一方面避免取任务的操作耗时过长,另一方面为了防止执行太多任务造成 Worker 线程阻塞。
根据用户设置的任务 deadline,可以计算出任务需要经过多少次 tick 才能开始执行以及需要在时间轮中转动圈数 remainingRounds,remainingRounds 会记录在 HashedWheelTimeout 中,在执行任务的时候 remainingRounds 会被使用到。因为时间轮中的任务并不能够保证及时执行,假如有一个任务执行的时间特别长,那么任务在 timeouts 队列里已经过了执行时间,也没有关系,Worker 会将这些任务直接加入当前HashedWheelBucket 中,所以过期的任务并不会被遗漏。
任务被添加到时间轮之后,重新再回到 Worker#run() 的主流程,接下来就是执行当前 HashedWheelBucket 中的到期任务,跟进 HashedWheelBucket#expireTimeouts() 方法的源码:
public void expireTimeouts(long deadline) {HashedWheelTimeout timeout = head;while (timeout != null) {HashedWheelTimeout next = timeout.next;if (timeout.remainingRounds <= 0) {next = remove(timeout);if (timeout.deadline <= deadline) {timeout.expire(); // 执行任务} else {throw new IllegalStateException(String.format("timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));}} else if (timeout.isCancelled()) {next = remove(timeout);} else {timeout.remainingRounds --; // 未到执行时间,remainingRounds 减 1}timeout = next;}
}
执行任务的操作比较简单,就是从头开始遍历 HashedWheelBucket 中的双向链表。如果 remainingRounds <=0,则调用 expire() 方法执行任务,timeout.expire() 内部就是调用了 TimerTask 的 run() 方法。如果任务已经被取消,直接从链表中移除。否则表示任务的执行时间还没到,remainingRounds 减 1,等待下一圈即可。
至此,工作线程 Worker 的核心逻辑 do-while 循环我们已经讲完了。当时间轮退出后,Worker 还会执行一些后置的收尾工作。Worker 会从每个 HashedWheelBucket 取出未执行且未取消的任务,以及还来得及添加到 HashedWheelBucket 中的任务,然后加入未处理任务列表,以便 stop() 方法统一处理。
停止时间轮
回到 Timer 接口两个方法,newTimeout() 上文已经分析完了,接下来我们就以 stop() 方法为入口,看下时间轮停止都做了哪些工作。
@Override
public Set<Timeout> stop() {// Worker 线程无法停止时间轮if (Thread.currentThread() == workerThread) {throw new IllegalStateException(HashedWheelTimer.class.getSimpleName() +".stop() cannot be called from " +TimerTask.class.getSimpleName());}// 尝试通过 CAS 操作将工作线程的状态更新为 SHUTDOWN 状态if (!WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_STARTED, WORKER_STATE_SHUTDOWN)) {if (WORKER_STATE_UPDATER.getAndSet(this, WORKER_STATE_SHUTDOWN) != WORKER_STATE_SHUTDOWN) {INSTANCE_COUNTER.decrementAndGet();if (leak != null) {boolean closed = leak.close(this);assert closed;}return Collections.emptySet();}try {boolean interrupted = false;while (workerThread.isAlive()) {workerThread.interrupt(); // 中断 Worker 线程try {workerThread.join(100);} catch (InterruptedException ignored) {interrupted = true;}}if (interrupted) {Thread.currentThread().interrupt();}} finally {INSTANCE_COUNTER.decrementAndGet();if (leak != null) {boolean closed = leak.close(this);assert closed;}}return worker.unprocessedTimeouts(); // 返回未处理任务的列表
}
如果当前线程是 Worker 线程,它是不能发起停止时间轮的操作的,是为了防止有定时任务发起停止时间轮的恶意操作。停止时间轮主要做了三件事,首先尝试通过 CAS 操作将工作线程的状态更新为 SHUTDOWN 状态,然后中断工作线程 Worker,最后将未处理的任务列表返回给上层。
到此为止,HashedWheelTimer 的实现原理我们已经分析完了。再来回顾一下 HashedWheelTimer 的几个核心成员。
- HashedWheelTimeout,任务的封装类,包含任务的到期时间 deadline、需要经历的圈数 remainingRounds 等属性。
- HashedWheelBucket,相当于时间轮的每个 slot,内部采用双向链表保存了当前需要执行的 HashedWheelTimeout 列表。
- Worker,HashedWheelTimer 的核心工作引擎,负责处理定时任务。
时间轮进阶应用
Netty 中的时间轮是通过固定的时间间隔 tickDuration 进行推动的,如果长时间没有到期任务,那么会存在时间轮空推进的现象,从而造成一定的性能损耗。此外,如果任务的到期时间跨度很大,例如 A 任务 1s 后执行,B 任务 6 小时之后执行,也会造成空推进的问题。
那么上述问题有没有什么解决方案呢?在研究 Kafka 的时候,Kafka 也有时间轮的应用,它的实现思路与 Netty 是存在区别的。因为 Kafka 面对的应用场景是更加严苛的,可能会存在各种时间粒度的定时任务,那么 Kafka 是否有解决时间跨度问题呢?我们接下来就简单介绍下 Kafka 的优化思路。
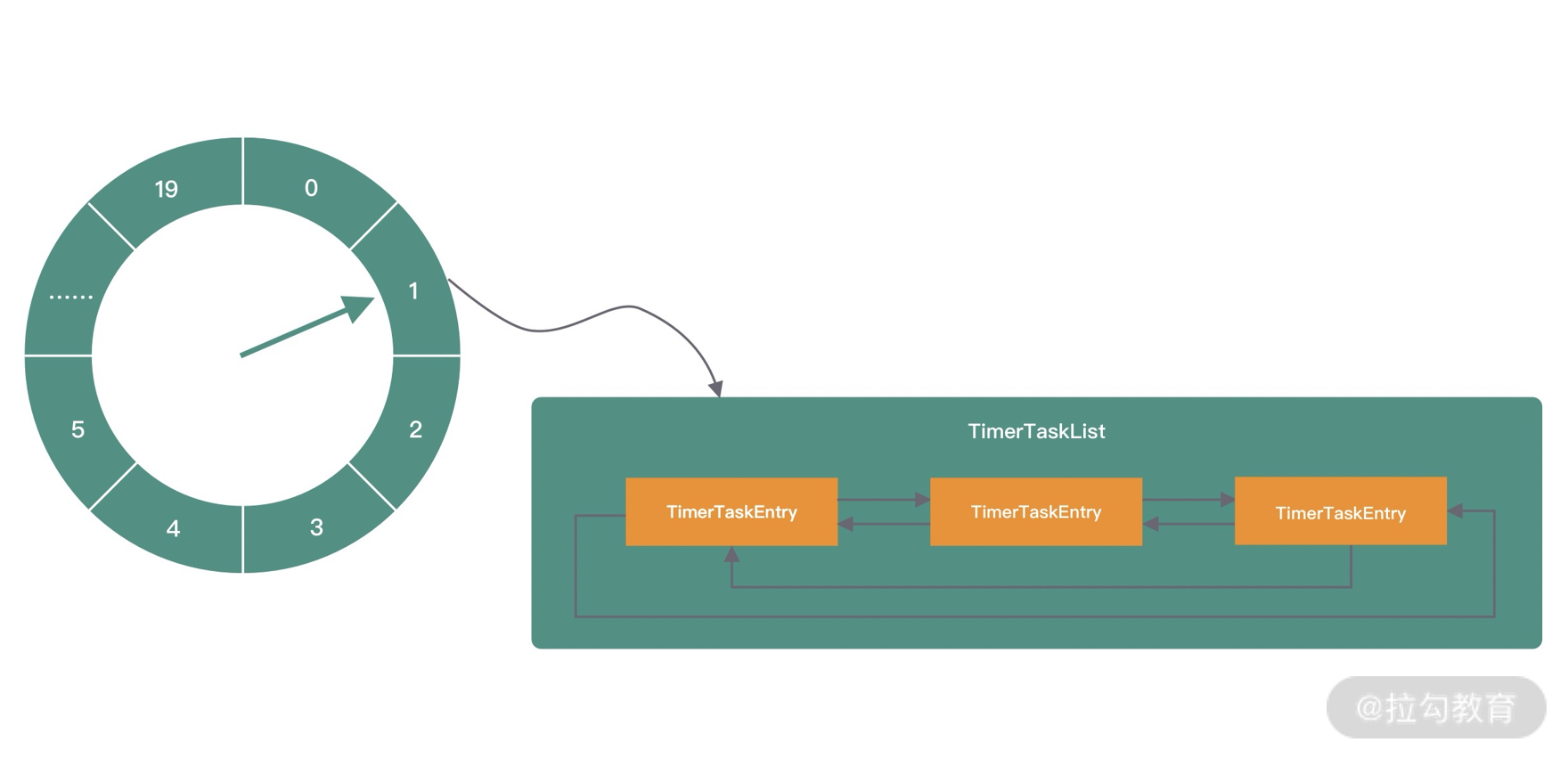
Kafka 时间轮的内部结构与 Netty 类似,如下图所示。Kafka 的时间轮也是采用环形数组存储定时任务,数组中的每个 slot 代表一个 Bucket,每个 Bucket 保存了定时任务列表 TimerTaskList,TimerTaskList 同样采用双向链表的结构实现,链表的每个节点代表真正的定时任务 TimerTaskEntry。
为了解决空推进的问题,Kafka 借助 JDK 的 DelayQueue 来负责推进时间轮。DelayQueue 保存了时间轮中的每个 Bucket,并且根据 Bucket 的到期时间进行排序,最近的到期时间被放在 DelayQueue 的队头。Kafka 中会有一个线程来读取 DelayQueue 中的任务列表,如果时间没有到,那么 DelayQueue 会一直处于阻塞状态,从而解决空推荐的问题。这时候你可能会问,DelayQueue 插入和删除的性能不是并不好吗?其实 Kafka 采用的是一种权衡的策略,把 DelayQueue 用在了合适的地方。DelayQueue 只存放了 Bucket,Bucket 的数量并不多,相比空推进带来的影响是利大于弊的。
为了解决任务时间跨度很大的问题,Kafka 引入了层级时间轮,如下图所示。当任务的 deadline 超出当前所在层的时间轮表示范围时,就会尝试将任务添加到上一层时间轮中,跟钟表的时针、分针、秒针的转动规则是同一个道理。
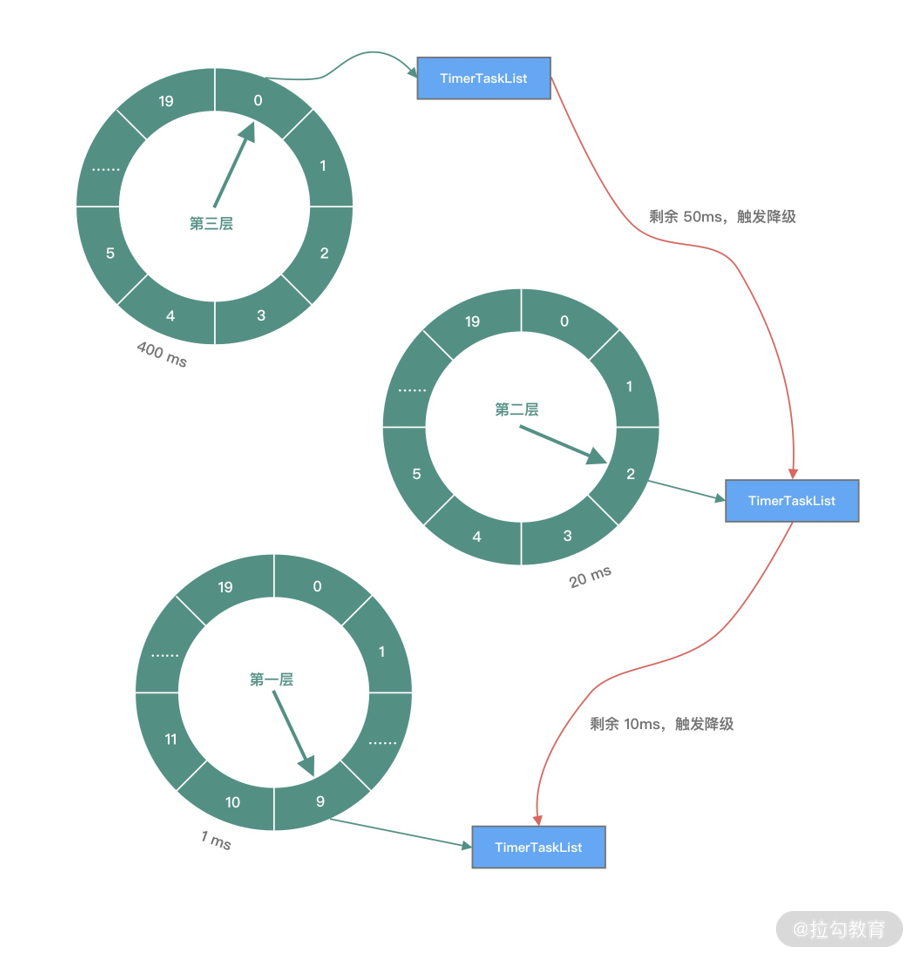
从图中可以看出,第一层时间轮每个时间格为 1ms,整个时间轮的跨度为 20ms;第二层时间轮每个时间格为 20ms,整个时间轮跨度为 400ms;第三层时间轮每个时间格为 400ms,整个时间轮跨度为 8000ms。每一层时间轮都有自己的指针,每层时间轮走完一圈后,上层时间轮也会相应推进一格。
假设现在有一个任务到期时间是 450ms 之后,应该放在第三层时间轮的第一格。随着时间的流逝,当指针指向该时间格时,发现任务到期时间还有 50ms,这里就涉及时间轮降级的操作,它会将任务重新提交到时间轮中。此时发现第一层时间轮整体跨度不够,需要放在第二层时间轮中第三格。当时间再经历 40ms 之后,该任务又会触发一次降级操作,放入到第一层时间轮,最后等到 10ms 后执行任务。
由此可见,Kafka 的层级时间轮的时间粒度更好控制,可以应对更加复杂的定时任务处理场景,适用的范围更广。
总结
HashedWheelTimer 的源码通俗易懂,其设计思想值得我们借鉴。在平时开发中如果有类似的任务处理机制,你可以尝试套用 HashedWheelTimer 的工作模式。
HashedWheelTimer 并不是十全十美的,使用的时候需要清楚它存在的问题:
- 如果长时间没有到期任务,那么会存在时间轮空推进的现象。
- 只适用于处理耗时较短的任务,由于 Worker 是单线程的,如果一个任务执行的时间过长,会造成 Worker 线程阻塞。
- 相比传统定时器的实现方式,内存占用较大。
22 技巧篇:高性能无锁队列 Mpc Queue
在前面的源码课程中,NioEventLoop 线程以及时间轮 HashedWheelTimer 的任务队列中都出现了 Mpsc Queue 的身影。这又是 Netty 使用的什么 “黑科技” 呢?为什么不使用 JDK 原生的队列呢?Mpsc Queue 应该在什么场景下使用呢?今天这节课就让我们一起再来长长知识吧!
JDK 原生并发队列
在介绍 Mpsc Queue 之前,我们先回顾下 JDK 原生队列的工作原理。JDK 并发队列按照实现方式可以分为阻塞队列和非阻塞队列两种类型,阻塞队列是基于锁实现的,非阻塞队列是基于 CAS 操作实现的。JDK 中包含多种阻塞和非阻塞的队列实现,如下图所示。
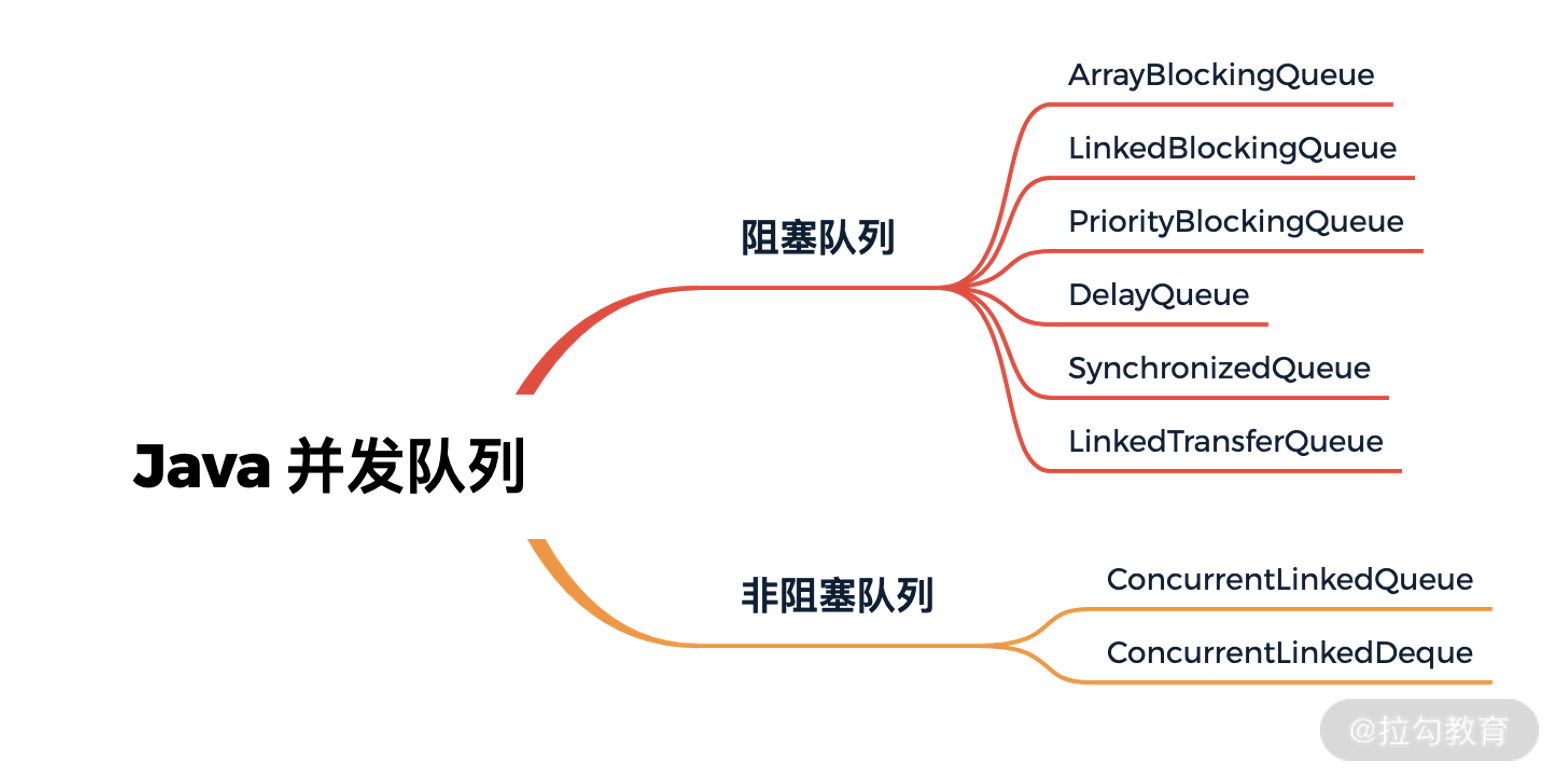
队列是一种 FIFO(先进先出)的数据结构,JDK 中定义了 java.util.Queue 的队列接口,与 List、Set 接口类似,java.util.Queue 也继承于 Collection 集合接口。此外,JDK 还提供了一种双端队列接口 java.util.Deque,我们最常用的 LinkedList 就是实现了 Deque 接口。下面我们简单说说上图中的每个队列的特点,并给出一些对比和总结。
阻塞队列
阻塞队列在队列为空或者队列满时,都会发生阻塞。阻塞队列自身是线程安全的,使用者无需关心线程安全问题,降低了多线程开发难度。阻塞队列主要分为以下几种:
- ArrayBlockingQueue:最基础且开发中最常用的阻塞队列,底层采用数组实现的有界队列,初始化需要指定队列的容量。ArrayBlockingQueue 是如何保证线程安全的呢?它内部是使用了一个重入锁 ReentrantLock,并搭配 notEmpty、notFull 两个条件变量 Condition 来控制并发访问。从队列读取数据时,如果队列为空,那么会阻塞等待,直到队列有数据了才会被唤醒。如果队列已经满了,也同样会进入阻塞状态,直到队列有空闲才会被唤醒。
- LinkedBlockingQueue:内部采用的数据结构是链表,队列的长度可以是有界或者无界的,初始化不需要指定队列长度,默认是 Integer.MAX_VALUE。LinkedBlockingQueue 内部使用了 takeLock、putLock两个重入锁 ReentrantLock,以及 notEmpty、notFull 两个条件变量 Condition 来控制并发访问。采用读锁和写锁的好处是可以避免读写时相互竞争锁的现象,所以相比于 ArrayBlockingQueue,LinkedBlockingQueue 的性能要更好。
- PriorityBlockingQueue:采用最小堆实现的优先级队列,队列中的元素按照优先级进行排列,每次出队都是返回优先级最高的元素。PriorityBlockingQueue 内部是使用了一个 ReentrantLock 以及一个条件变量 Condition notEmpty 来控制并发访问,不需要 notFull 是因为 PriorityBlockingQueue 是无界队列,所以每次 put 都不会发生阻塞。PriorityBlockingQueue 底层的最小堆是采用数组实现的,当元素个数大于等于最大容量时会触发扩容,在扩容时会先释放锁,保证其他元素可以正常出队,然后使用 CAS 操作确保只有一个线程可以执行扩容逻辑。
- DelayQueue,一种支持延迟获取元素的阻塞队列,常用于缓存、定时任务调度等场景。DelayQueue 内部是采用优先级队列 PriorityQueue 存储对象。DelayQueue 中的每个对象都必须实现 Delayed 接口,并重写 compareTo 和 getDelay 方法。向队列中存放元素的时候必须指定延迟时间,只有延迟时间已满的元素才能从队列中取出。
- SynchronizedQueue,又称无缓冲队列。比较特别的是 SynchronizedQueue 内部不会存储元素。与 ArrayBlockingQueue、LinkedBlockingQueue 不同,SynchronizedQueue 直接使用 CAS 操作控制线程的安全访问。其中 put 和 take 操作都是阻塞的,每一个 put 操作都必须阻塞等待一个 take 操作,反之亦然。所以 SynchronizedQueue 可以理解为生产者和消费者配对的场景,双方必须互相等待,直至配对成功。在 JDK 的线程池 Executors.newCachedThreadPool 中就存在 SynchronousQueue 的运用,对于新提交的任务,如果有空闲线程,将重复利用空闲线程处理任务,否则将新建线程进行处理。
- LinkedTransferQueue,一种特殊的无界阻塞队列,可以看作 LinkedBlockingQueues、SynchronousQueue(公平模式)、ConcurrentLinkedQueue 的合体。与 SynchronousQueue 不同的是,LinkedTransferQueue 内部可以存储实际的数据,当执行 put 操作时,如果有等待线程,那么直接将数据交给对方,否则放入队列中。与 LinkedBlockingQueues 相比,LinkedTransferQueue 使用 CAS 无锁操作进一步提升了性能。
非阻塞队列
说完阻塞队列,我们再来看下非阻塞队列。非阻塞队列不需要通过加锁的方式对线程阻塞,并发性能更好。JDK 中常用的非阻塞队列有以下几种:
- ConcurrentLinkedQueue,它是一个采用双向链表实现的无界并发非阻塞队列,它属于 LinkedQueue 的安全版本。ConcurrentLinkedQueue 内部采用 CAS 操作保证线程安全,这是非阻塞队列实现的基础,相比 ArrayBlockingQueue、LinkedBlockingQueue 具备较高的性能。
- ConcurrentLinkedDeque,也是一种采用双向链表结构的无界并发非阻塞队列。与 ConcurrentLinkedQueue 不同的是,ConcurrentLinkedDeque 属于双端队列,它同时支持 FIFO 和 FILO 两种模式,可以从队列的头部插入和删除数据,也可以从队列尾部插入和删除数据,适用于多生产者和多消费者的场景。
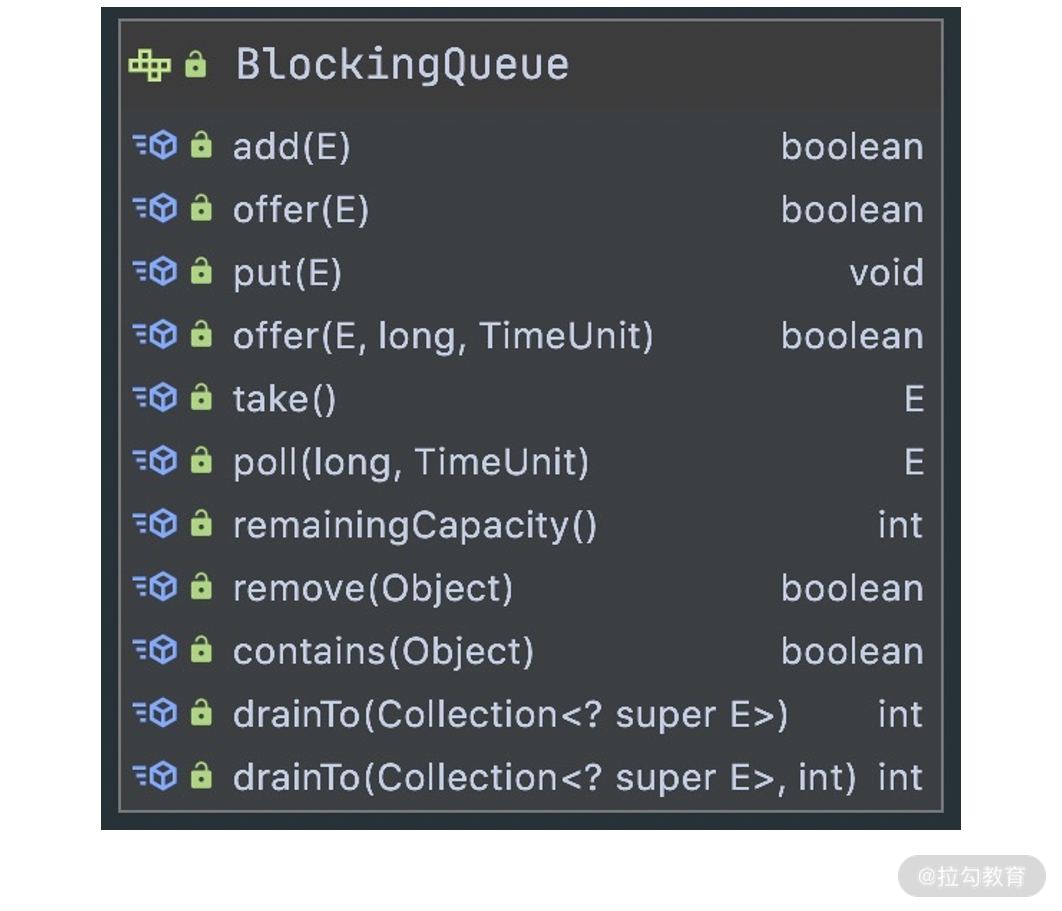
至此,常见的队列类型我们已经介绍完了。我们在平时开发中使用频率最高的是 BlockingQueue。实现一个阻塞队列需要具备哪些基本功能呢?下面看 BlockingQueue 的接口,如下图所示。
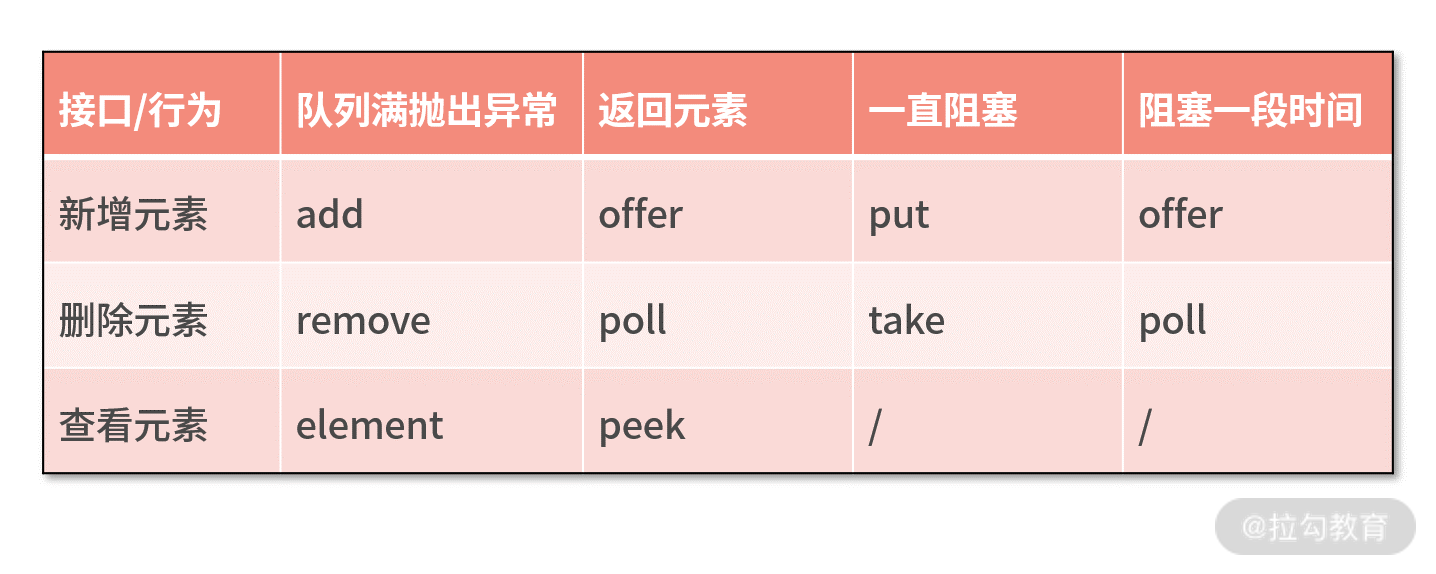
我们可以通过下面一张表格,对上述 BlockingQueue 接口的具体行为进行归类。
JDK 提供的并发队列已经能够满足我们大部分的需求,但是在大规模流量的高并发系统中,如果你对性能要求严苛,JDK 的非阻塞并发队列可选择面较少且性能并不够出色。如果你还是需要一个数组 + CAS 操作实现的无锁安全队列,有没有成熟的解决方案呢?Java 强大的生态总能给我们带来惊喜,一些第三方框架提供的高性能无锁队列已经可以满足我们的需求,其中非常出名的有 Disruptor 和 JCTools。
Disruptor 是 LMAX 公司开发的一款高性能无锁队列,我们平时常称它为 RingBuffer,其设计初衷是为了解决内存队列的延迟问题。Disruptor 内部采用环形数组和 CAS 操作实现,性能非常优越。为什么 Disruptor 的性能会比 JDK 原生的无锁队列要好呢?环形数组可以复用内存,减少分配内存和释放内存带来的性能损耗。而且数组可以设置长度为 2 的次幂,直接通过位运算加快数组下标的定位速度。此外,Disruptor 还解决了伪共享问题,对 CPU Cache 更加友好。Disruptor 已经开源,详细可查阅 Github 地址 https://github.com/LMAX-Exchange/disruptor。
JCTools 也是一个开源项目,Github 地址为 https://github.com/JCTools/JCTools。JCTools 是适用于 JVM 并发开发的工具,主要提供了一些 JDK 确实的并发数据结构,例如非阻塞 Map、非阻塞 Queue 等。其中非阻塞队列可以分为四种类型,可以根据不同的场景选择使用。
- Spsc 单生产者单消费者;
- Mpsc 多生产者单消费者;
- Spmc 单生产者多消费者;
- Mpmc 多生产者多消费者。
Netty 中直接引入了 JCTools 的 Mpsc Queue,相比于 JDK 原生的并发队列,Mpsc Queue 又有什么过人之处呢?接下来便开始我们今天要讨论的重点。
Mpsc Queue 基础知识
Mpsc 的全称是 Multi Producer Single Consumer,多生产者单消费者。Mpsc Queue 可以保证多个生产者同时访问队列是线程安全的,而且同一时刻只允许一个消费者从队列中读取数据。Netty Reactor 线程中任务队列 taskQueue 必须满足多个生产者可以同时提交任务,所以 JCTools 提供的 Mpsc Queue 非常适合 Netty Reactor 线程模型。
Mpsc Queue 有多种的实现类,例如 MpscArrayQueue、MpscUnboundedArrayQueue、MpscChunkedArrayQueue 等。我们先抛开一些提供特性功能的队列,聚焦在最基础的 MpscArrayQueue,回过头再学习其他类型的队列会事半功倍。
首先我们看下 MpscArrayQueue 的继承关系,会发现相当复杂,如下图所示。
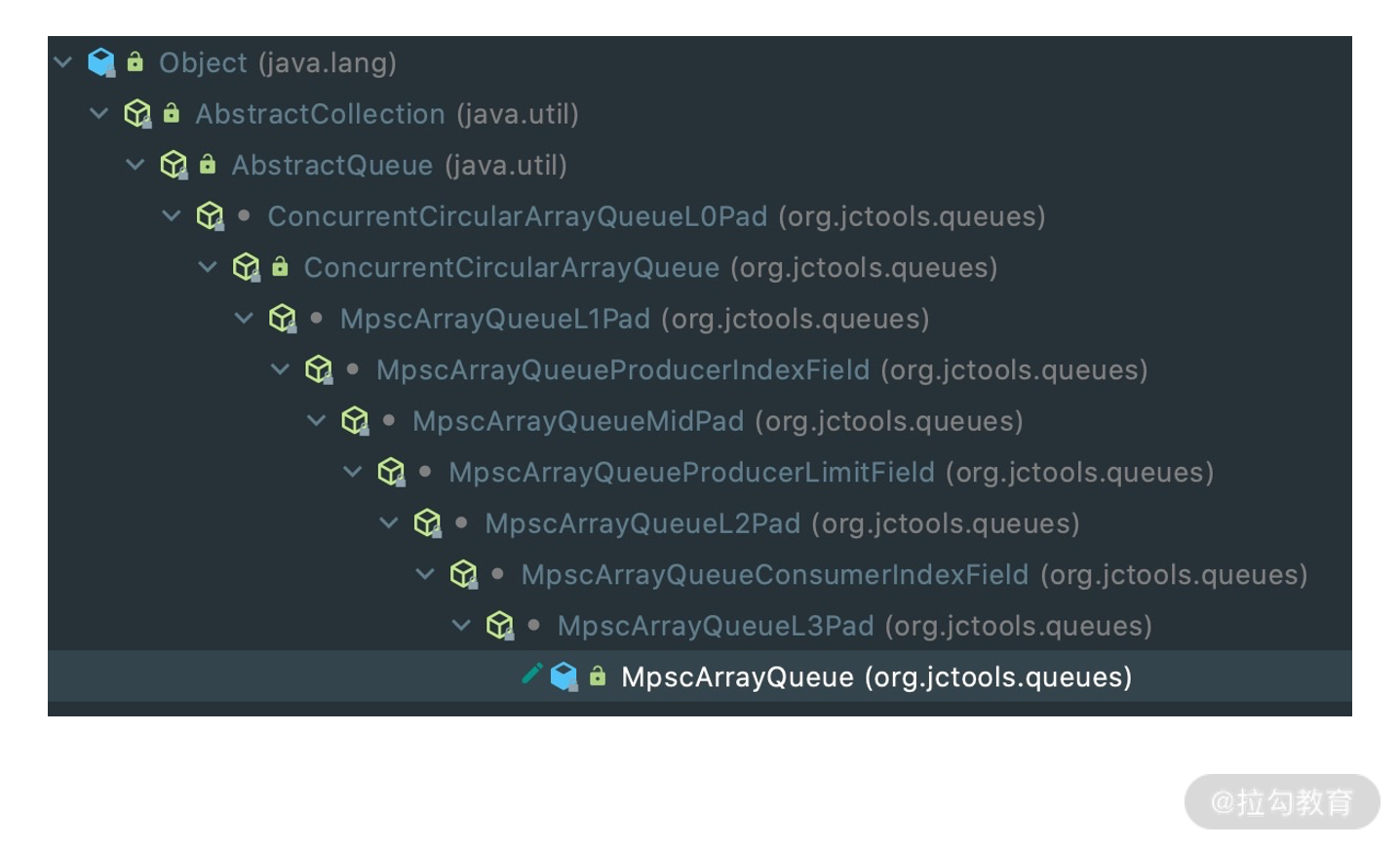
除了顶层 JDK 原生的 AbstractCollection、AbstractQueue,MpscArrayQueue 还继承了很多类似于 MpscXxxPad 以及 MpscXxxField 的类。我们可以发现一个很有意思的规律,每个有包含属性的类后面都会被 MpscXxxPad 类隔开。MpscXxxPad 到底起到什么作用呢?我们自顶向下,将所有类的字段合并在一起,看下 MpscArrayQueue 的整体结构。
// ConcurrentCircularArrayQueueL0Pad
long p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16, p17;
// ConcurrentCircularArrayQueue
protected final long mask;
protected final E[] buffer;
// MpmcArrayQueueL1Pad
long p00, p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16;
// MpmcArrayQueueProducerIndexField
private volatile long producerIndex;
// MpscArrayQueueMidPad
long p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16, p17;
// MpscArrayQueueProducerLimitField
private volatile long producerLimit;
// MpscArrayQueueL2Pad
long p00, p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16;
// MpscArrayQueueConsumerIndexField
protected long consumerIndex;
// MpscArrayQueueL3Pad
long p01, p02, p03, p04, p05, p06, p07;
long p10, p11, p12, p13, p14, p15, p16, p17;
可以看出,MpscXxxPad 类中使用了大量 long 类型的变量,其命名没有什么特殊的含义,只是起到填充的作用。如果你也读过 Disruptor 的源码,会发现 Disruptor 也使用了类似的填充方法。Mpsc Queue 和 Disruptor 之所以填充这些无意义的变量,是为了解决伪共享(false sharing)问题。
什么是伪共享呢?我们有必要补充这方面的基础知识。在计算机组成中,CPU 的运算速度比内存高出几个数量级,为了 CPU 能够更高效地与内存进行交互,在 CPU 和内存之间设计了多层缓存机制,如下图所示。
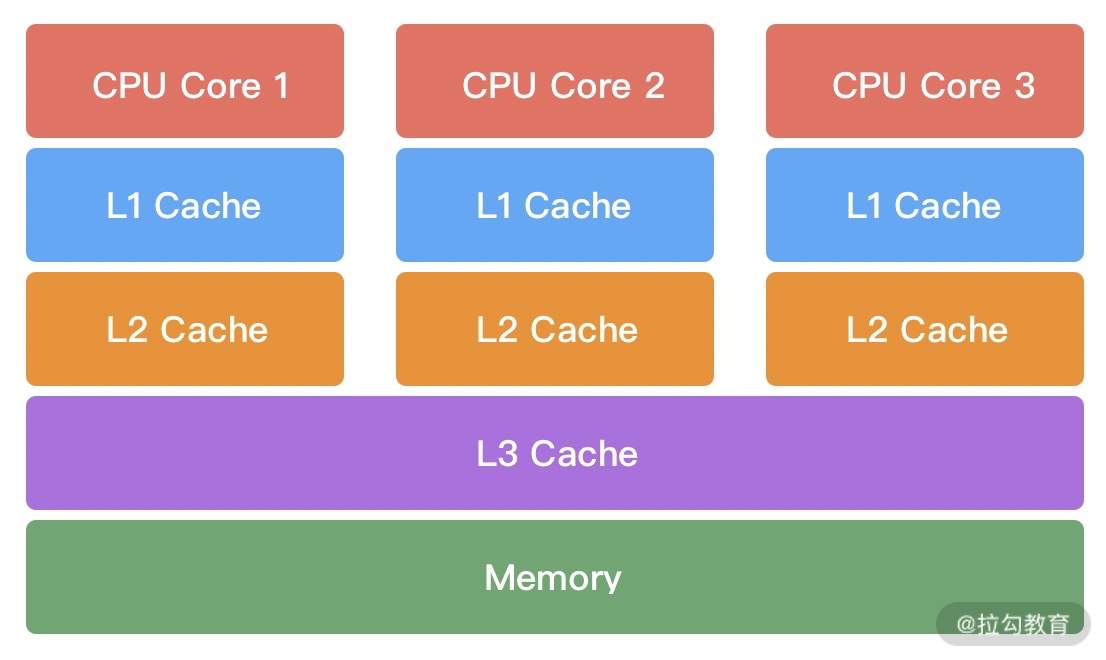
一般来说,CPU 会分为三级缓存,分别为L1 一级缓存、L2 二级缓存和L3 三级缓存。越靠近 CPU 的缓存,速度越快,但是缓存的容量也越小。所以从性能上来说,L1 > L2 > L3,容量方面 L1 < L2 < L3。CPU 读取数据时,首先会从 L1 查找,如果未命中则继续查找 L2,如果还未能命中则继续查找 L3,最后还没命中的话只能从内存中查找,读取完成后再将数据逐级放入缓存中。此外,多线程之间共享一份数据的时候,需要其中一个线程将数据写回主存,其他线程访问主存数据。
由此可见,引入多级缓存是为了能够让 CPU 利用率最大化。如果你在做频繁的 CPU 运算时,需要尽可能将数据保持在缓存中。那么 CPU 从内存中加载数据的时候,是如何提高缓存的利用率的呢?这就涉及缓存行(Cache Line)的概念,Cache Line 是 CPU 缓存可操作的最小单位,CPU 缓存由若干个 Cache Line 组成。Cache Line 的大小与 CPU 架构有关,在目前主流的 64 位架构下,Cache Line 的大小通常为 64 Byte。Java 中一个 long 类型是 8 Byte,所以一个 Cache Line 可以存储 8 个 long 类型变量。CPU 在加载内存数据时,会将相邻的数据一同读取到 Cache Line 中,因为相邻的数据未来被访问的可能性最大,这样就可以避免 CPU 频繁与内存进行交互了。
伪共享问题是如何发生的呢?它又会造成什么影响呢?我们使用下面这幅图进行讲解。
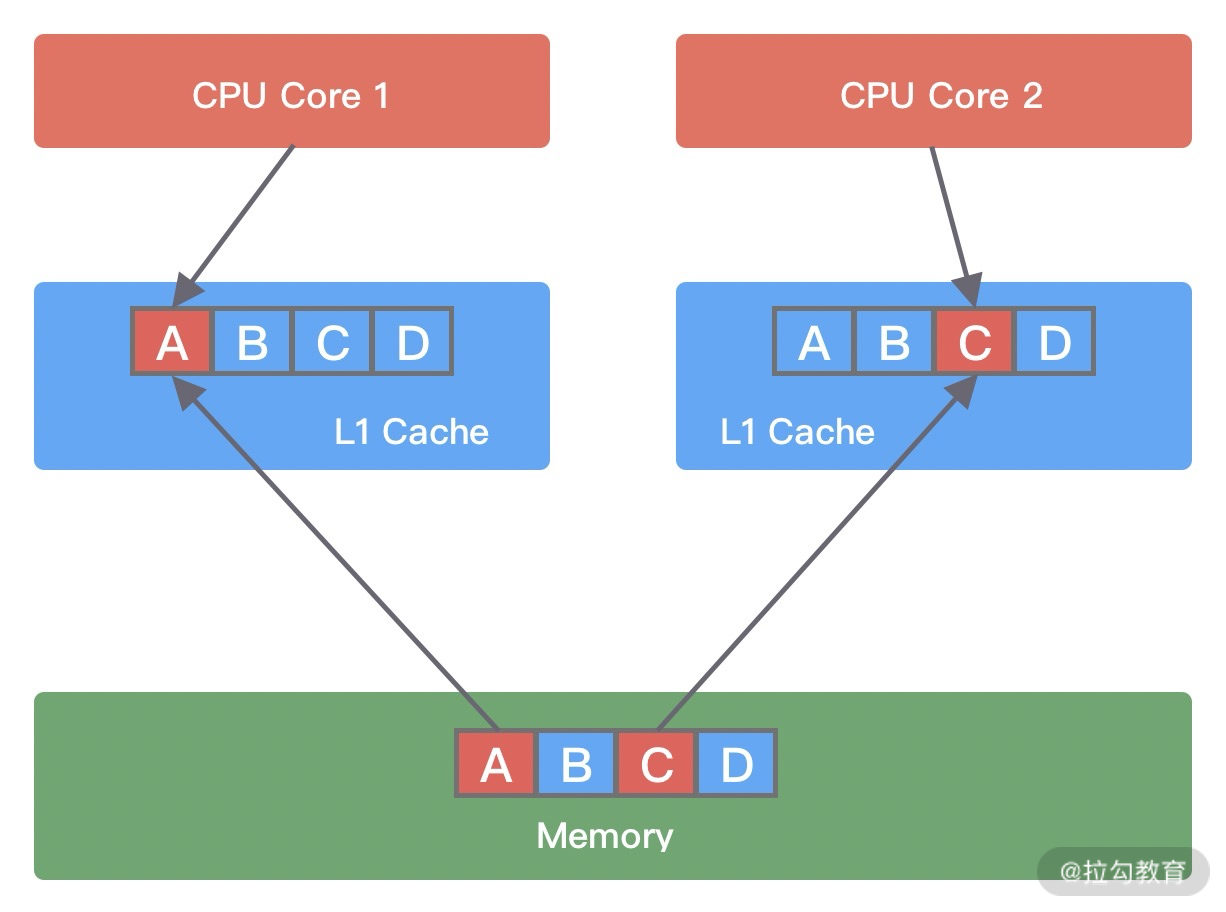
假设变量 A、B、C、D 被加载到同一个 Cache Line,它们会被高频地修改。当线程 1 在 CPU Core1 中中对变量 A 进行修改,修改完成后 CPU Core1 会通知其他 CPU Core 该缓存行已经失效。然后线程 2 在 CPU Core2 中对变量 C 进行修改时,发现 Cache line 已经失效,此时 CPU Core1 会将数据重新写回内存,CPU Core2 再从内存中读取数据加载到当前 Cache line 中。
由此可见,如果同一个 Cache line 被越多的线程修改,那么造成的写竞争就会越激烈,数据会频繁写入内存,导致性能浪费。题外话,多核处理器中,每个核的缓存行内容是如何保证一致的呢?有兴趣的同学可以深入学习下缓存一致性协议 MESI,具体可以参考 https://zh.wikipedia.org/wiki/MESI%E5%8D%8F%E8%AE%AE。
对于伪共享问题,我们应该如何解决呢?Disruptor 和 Mpsc Queue 都采取了空间换时间的策略,让不同线程共享的对象加载到不同的缓存行即可。下面我们通过一个简单的例子进行说明。
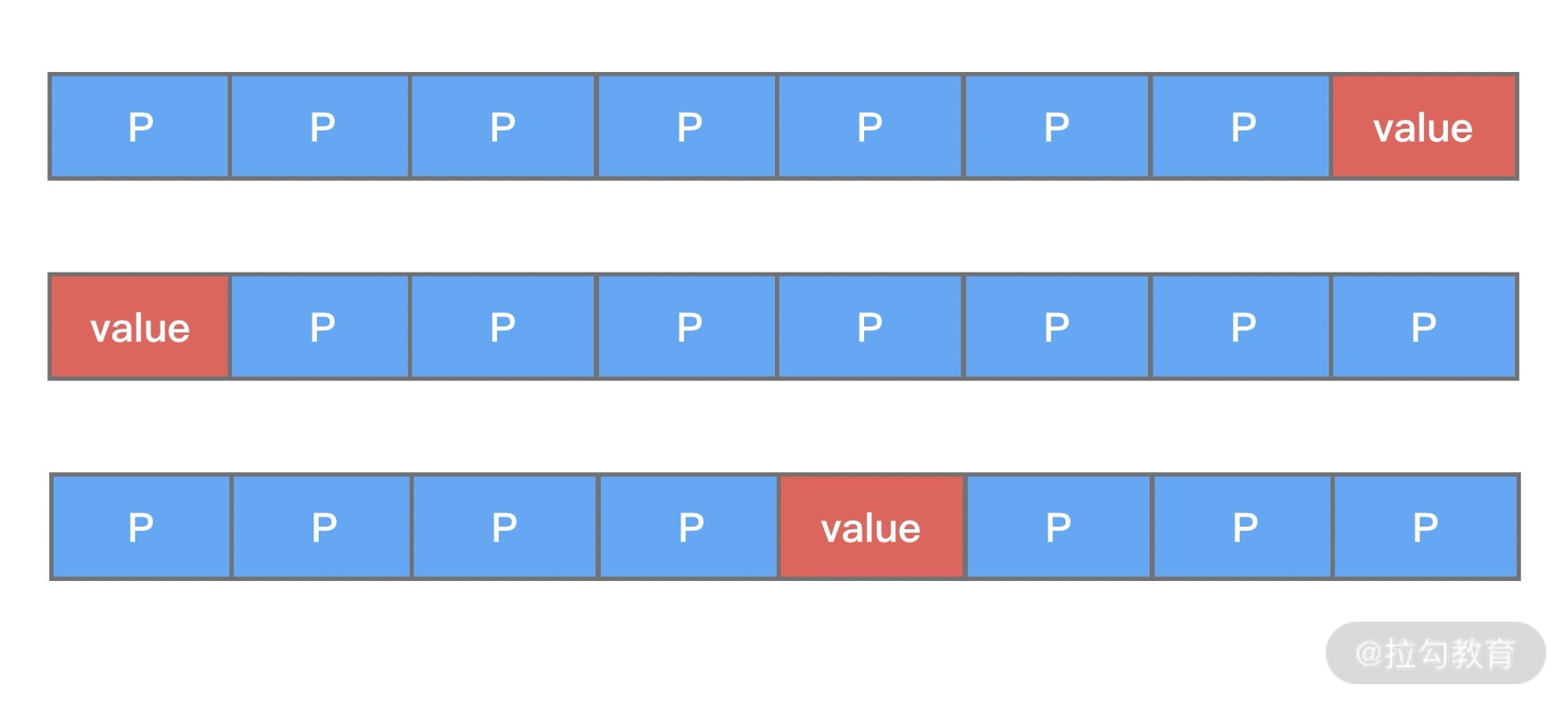
public class FalseSharingPadding {protected long p1, p2, p3, p4, p5, p6, p7;protected volatile long value = 0L;protected long p9, p10, p11, p12, p13, p14, p15;
}
从上述代码中可以看出,变量 value 前后都填充了 7 个 long 类型的变量。这样不论在什么情况下,都可以保证在多线程访问 value 变量时,value 与其他不相关的变量处于不同的 Cache Line,如下图所示。
伪共享问题一般是非常隐蔽的,在实际开发的过程中,并不是项目中所有地方都需要花费大量的精力去优化伪共享问题。CPU Cache 的填充本身也是比较珍贵的,我们应该把精力聚焦在一些高性能的数据结构设计上,把资源用在刀刃上,使系统性能收益最大化。
至此,我们知道 Mpsc Queue 为了解决伪共享问题填充了大量的 long 类型变量,造成源码不易阅读。因为变量填充只是为了提升 Mpsc Queue 的性能,与 Mpsc Queue 的主体功能无关。接下来我们先忽略填充变量,开始分析 Mpsc Queue 的基本实现原理。
Mpsc Queue 源码分析
在开始源码学习之前,我们同样先看看 MpscArrayQueue 如何使用,示例代码如下:
public class MpscArrayQueueTest {public static final MpscArrayQueue<String> MPSC_ARRAY_QUEUE = new MpscArrayQueue<>(2);public static void main(String[] args) {for (int i = 1; i <= 2; i++) {int index = i;new Thread(() -> MPSC_ARRAY_QUEUE.offer("data" + index), "thread" + index).start();}try {Thread.sleep(1000L);MPSC_ARRAY_QUEUE.add("data3"); // 入队操作,队列满则抛出异常} catch (Exception e) {e.printStackTrace();}System.out.println("队列大小:" + MPSC_ARRAY_QUEUE.size() + ", 队列容量:" + MPSC_ARRAY_QUEUE.capacity());System.out.println("出队:" + MPSC_ARRAY_QUEUE.remove()); // 出队操作,队列为空则抛出异常System.out.println("出队:" + MPSC_ARRAY_QUEUE.poll()); // 出队操作,队列为空则返回 NULL}
}
程序输出结果如下:
java.lang.IllegalStateException: Queue fullat java.util.AbstractQueue.add(AbstractQueue.java:98)at MpscArrayQueueTest.main(MpscArrayQueueTest.java:17)
队列大小:2, 队列容量:2
出队:data1
出队:data2
Disconnected from the target VM, address: '127.0.0.1:58005', transport: 'socket'
说到底 MpscArrayQueue 终究还是是个队列,基本用法与 ArrayBlockingQueue 都是类似的,都离不开队列的基本操作:入队 offer()**和**出队 poll()。下面我们就入队 offer() 和出队 poll() 两个最重要的操作分别进行详细的讲解。
入队 offer
首先我们先回顾下 MpscArrayQueue 的重要属性:
// ConcurrentCircularArrayQueue
protected final long mask; // 计算数组下标的掩码
protected final E[] buffer; // 存放队列数据的数组
// MpmcArrayQueueProducerIndexField
private volatile long producerIndex; // 生产者的索引
// MpscArrayQueueProducerLimitField
private volatile long producerLimit; // 生产者索引的最大值
// MpscArrayQueueConsumerIndexField
protected long consumerIndex; // 消费者索引
看到 mask 变量,你现在是不是条件反射想到队列中数组的容量大小肯定是 2 的次幂。因为 Mpsc 是多生产者单消费者队列,所以 producerIndex、producerLimit 都是用 volatile 进行修饰的,其中一个生产者线程的修改需要对其他生产者线程可见。队列入队和出队时会如何操作上述这些属性呢?其中生产者和消费者的索引变量又有什么作用呢?带着这些问题我们开始阅读源码。
首先跟进 offer() 方法的源码:
public boolean offer(E e) {if (null == e) {throw new NullPointerException();} else {long mask = this.mask;long producerLimit = this.lvProducerLimit(); // 获取生产者索引最大限制long pIndex;long offset;do {pIndex = this.lvProducerIndex(); // 获取生产者索引if (pIndex >= producerLimit) {offset = this.lvConsumerIndex(); // 获取消费者索引producerLimit = offset + mask + 1L;if (pIndex >= producerLimit) {return false; // 队列已满}this.soProducerLimit(producerLimit); // 更新 producerLimit}} while(!this.casProducerIndex(pIndex, pIndex + 1L)); // CAS 更新生产者索引,更新成功则退出,说明当前生产者已经占领索引值offset = calcElementOffset(pIndex, mask); // 计算生产者索引在数组中下标UnsafeRefArrayAccess.soElement(this.buffer, offset, e); // 向数组中放入数据return true;}
}
MpscArrayQueue 的 offer() 方法虽然比较简短,但是需要具备一些底层知识才能看得懂,先不用担心,我们一点点开始拆解。首先需要搞懂 producerIndex、producerLimit 以及 consumerIndex 之间的关系,这也是 MpscArrayQueue 中设计比较独特的地方。首先看下 lvProducerLimit() 方法的源码:
public MpscArrayQueueProducerLimitField(int capacity) {super(capacity);this.producerLimit = capacity;
}
protected final long lvProducerLimit() {return producerLimit;
}
在初始化状态,producerLimit 与队列的容量是相等的,对应到 MpscArrayQueueTest 代码示例中,producerLimit = capacity = 2,而 producerIndex = consumerIndex = 0。接下来 Thread1 和 Thread2 并发向 MpscArrayQueue 中存放数据,如下图所示。
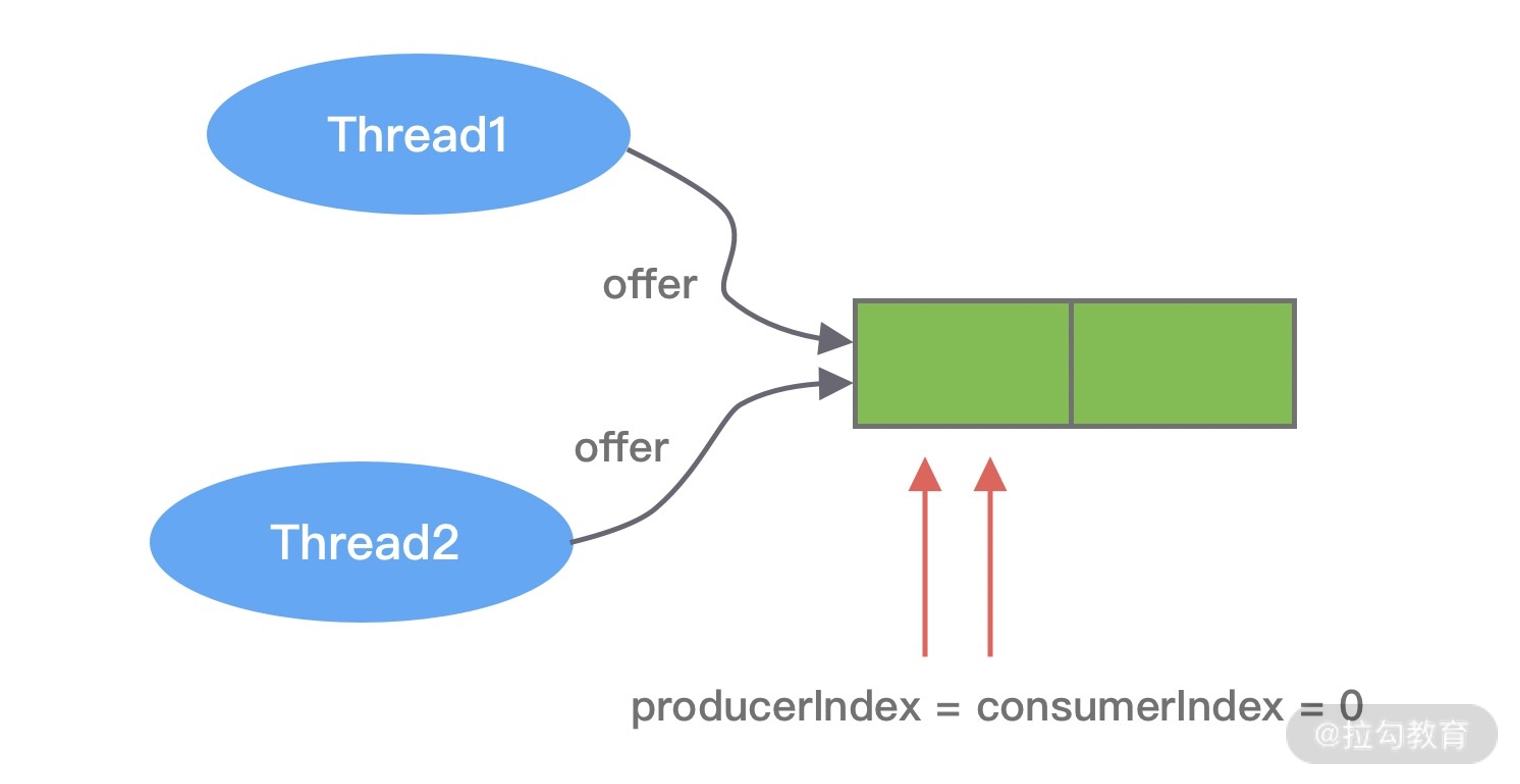
两个线程此时拿到的 producerIndex 都是 0,是小于 producerLimit 的。此时两个线程都会尝试使用 CAS 操作更新 producerIndex,其中必然有一个是成功的,另外一个是失败的。假设 Thread1 执行 CAS 操作成功,那么 Thread2 失败后就会重新更新 producerIndex。Thread1 更新后 producerIndex 的值为 1,由于 producerIndex 是 volatile 修饰的,更新后立刻对 Thread2 可见。这里有一点需要注意的是,当前线程更新后的值是被其他线程使用,当 Thread1 和 Thread2 都通过 CAS 抢占成功后,它们拿到的 pIndex 分别是 0 和 1。接下来就是根据 pIndex 进行位运算计算得到数组对应的下标,然后通过 UNSAFE.putOrderedObject() 方法将数据写入到数组中,源码如下所示。
public static <E> void soElement(E[] buffer, long offset, E e) {UnsafeAccess.UNSAFE.putOrderedObject(buffer, offset, e);
}
putOrderedObject() 和 putObject() 都可以用于更新对象的值,但是 putOrderedObject() 并不会立刻将数据更新到内存中,并把其他 Cache Line 置为失效。putOrderedObject() 使用的是 LazySet 延迟更新机制,所以性能方面 putOrderedObject() 要比 putObject() 高很多。
Java 中有四种类型的内存屏障,分别为 LoadLoad、StoreStore、LoadStore 和 StoreLoad。putOrderedObject() 使用了 StoreStore Barrier,对于 Store1,StoreStore,Store2 这样的操作序列,在 Store2 进行写入之前,会保证 Store1 的写操作对其他处理器可见。
LazySet 机制是有代价的,就是写操作结果有纳秒级的延迟,不会立刻被其他线程以及自身线程可见。因为在 Mpsc Queue 的使用场景中,多个生产者只负责写入数据,并没有写入之后立刻读取的需求,所以使用 LazySet 机制是没有问题的,只要 StoreStore Barrier 保证多线程写入的顺序即可。
至此,offer() 的核心操作我们已经讲完了。现在我们继续把目光聚焦在 do-while 循环内的逻辑,为什么需要两次 if(pIndex >= producerLimit) 判断呢?说明当生产者索引大于 producerLimit 阈值时,可能存在两种情况:producerLimit 缓存值过期了或者队列已经满了。所以此时我们需要读取最新的消费者索引 consumerIndex,之前读取过的数据位置都可以被重复使用,重新做一次 producerLimit 计算,然后再做一次 if(pIndex >= producerLimit) 判断,如果生产者索引还是大于 producerLimit 阈值,说明队列的真的满了。
因为生产者有多个线程,所以 MpscArrayQueue 采用了 UNSAFE.getLongVolatile() 方法保证获取消费者索引 consumerIndex 的准确性。getLongVolatile() 使用了 StoreLoad Barrier,对于 Store1,StoreLoad,Load2 的操作序列,在 Load2 以及后续的读取操作之前,都会保证 Store1 的写入操作对其他处理器可见。StoreLoad 是四种内存屏障开销最大的,现在你是不是可以体会到引入 producerLimit 的好处了呢?假设我们的消费速度和生产速度比较均衡的情况下,差不多走完一圈数组才需要获取一次消费者索引 consumerIndex,从而大幅度减少了 getLongVolatile() 操作的执行次数,性能提升是显著的。
学习完 MpscArrayQueue 的入队 offer() 方法后,再来看出队 poll() 就会容易很多,我们继续向下看。
出队 poll
poll() 方法的作用是移除队列的首个元素并返回,如果队列为空则返回 NULL。我们看下 poll() 源码是如何实现的。
public E poll() {long cIndex = this.lpConsumerIndex(); // 直接返回消费者索引 consumerIndexlong offset = this.calcElementOffset(cIndex); // 计算数组对应的偏移量E[] buffer = this.buffer;E e = UnsafeRefArrayAccess.lvElement(buffer, offset); // 取出数组中 offset 对应的元素if (null == e) {if (cIndex == this.lvProducerIndex()) { // 队列为空return null;}do {e = UnsafeRefArrayAccess.lvElement(buffer, offset); } while(e == null); // 等待生产者填充元素}UnsafeRefArrayAccess.spElement(buffer, offset, (Object)null); // 消费成功后将当前位置置为 NULLthis.soConsumerIndex(cIndex + 1L); // 更新 consumerIndex 到下一个位置return e;
}
因为只有一个消费者线程,所以整个 poll() 的过程没有 CAS 操作。poll() 方法核心思路是获取消费者索引 consumerIndex,然后根据 consumerIndex 计算得出数组对应的偏移量,然后将数组对应位置的元素取出并返回,最后将 consumerIndex 移动到环形数组下一个位置。
获取消费者索引以及计算数组对应的偏移量的逻辑与 offer() 类似,在这里就不赘述了。下面直接看下如何取出数组中 offset 对应的元素,跟进 lvElement() 方法的源码。
public static <E> E lvElement(E[] buffer, long offset) {return (E) UNSAFE.getObjectVolatile(buffer, offset);
}
获取数组元素的时候同样使用了 UNSAFE 系列方法,getObjectVolatile() 方法则使用的是 LoadLoad Barrier,对于 Load1,LoadLoad,Load2 操作序列,在 Load2 以及后续读取操作之前,会保证 Load1 的读取操作执行完毕,所以 getObjectVolatile() 方法可以保证每次读取数据都可以从内存中拿到最新值。
与 offer() 相反,poll() 比较关注队列为空的情况。当调用 lvElement() 方法获取到的元素为 NULL 时,有两种可能的情况:队列为空或者生产者填充的元素还没有对消费者可见。如果消费者索引 consumerIndex 等于生产者 producerIndex,说明队列为空。只要两者不相等,消费者需要等待生产者填充数据完毕。
当成功消费数组中的元素之后,需要把当前消费者索引 consumerIndex 的位置置为 NULL,然后把 consumerIndex 移动到数组下一个位置。逻辑比较简单,下面我们把 spElement() 和 soConsumerIndex() 方法放在一起看。
public static <E> void spElement(E[] buffer, long offset, E e) {UNSAFE.putObject(buffer, offset, e);
}
protected void soConsumerIndex(long newValue) {UNSAFE.putOrderedLong(this, C_INDEX_OFFSET, newValue);
}
最后的更新操作我们又看到了 UNSAFE put 系列方法的运用,其中 putObject() 不会使用任何内存屏障,它会直接更新对象对应偏移量的值。而 putOrderedLong 与 putOrderedObject() 是一样的,都使用了 StoreStore Barrier,也是延迟更新 LazySet 机制,我们就不再赘述了。
到此为止,MpscArrayQueue 入队和出队的核心源码已经分析完了。因为 JCTools 是服务于 JVM 的并发工具类,其中包含了很多黑科技的技巧,例如填充法解决伪共享问题、Unsafe 直接操作内存等,让我们对底层知识的掌握又更进一步。此外 JCTools 还提供了 MpscUnboundedArrayQueue、MpscChunkedArrayQueue 等其他具有特色功能的队列,有兴趣的话你可以课后自行研究,相信有了本节课的基础,再分析其他队列一定不会难倒你。
总结
MpscArrayQueue 还只是 Jctools 中的冰山一角,其中蕴藏着丰富的技术细节,我们对 MpscArrayQueue 的知识点做一个简单的总结。
- 通过大量填充 long 类型变量解决伪共享问题。
- 环形数组的容量设置为 2 的次幂,可以通过位运算快速定位到数组对应下标。
- 入队 offer() 操作中 producerLimit 的巧妙设计,大幅度减少了主动获取消费者索引 consumerIndex 的次数,性能提升显著。
- 入队和出队操作中都大量使用了 UNSAFE 系列方法,针对生产者和消费者的场景不同,使用的 UNSAFE 方法也是不一样的。Jctools 在底层操作的运用上也是有的放矢,把性能发挥到极致。
到此为止,我们源码解析的课程就告一段落了。Netty 还有很多黑科技等待我们去探索,希望通过前面 Netty 核心源码的学习,在今后深入研究 Netty 的道路上能够有所帮助。
23 架构设计:如何实现一个高性能分布式 RPC 框架
在前面的课程中,我们由浅入深地讲解了 Netty 的基础知识和实现原理,并对 Netty 的核心源码进行了剖析,相信你已经体会到了 Netty 的强大之处。本身学习一门技术是一个比较漫长的过程,恭喜你坚持了下来。纸上得来终觉浅,绝知此事要躬行。你是不是已经迫不及待想在项目中使用 Netty 了呢?接下来我会带着你完成一个相对完整的 RPC 框架原型,帮助你加深对 Netty 的理解,希望你能亲自动手跟我一起完成它。
我先来说说,为什么要选择 RPC 框架作为实战项目。RPC 框架是大型企业高频使用的一种中间件框架,用于解决分布式系统中服务之间的调用问题。RPC 框架设计很多重要的知识点,如线程模型、通信协议设计、同步/异步调用、负载均衡等,对于提高我们的技术综合能力有非常大的帮助。
我们实战课需要达到什么样的目标呢?市面上有较多出名的 RPC 框架,例如 Dubbo、Thrift、gRPC 等,RPC 框架本身是非常负责的,我们不可能面面俱到,而是抓住 RPC 框架的核心流程以及必备的组件,开发一个功能比较丰富的小型 RPC 框架。麻雀虽小,五脏俱全。
在正式开始 RPC 实战项目之前,我们先学习一下 RPC 的架构设计,这是项目前期规划非常重要的一步。
RPC 框架架构设计
RPC 又称远程过程调用(Remote Procedure Call),用于解决分布式系统中服务之间的调用问题。通俗地讲,就是开发者能够像调用本地方法一样调用远程的服务。下面我们通过一幅图来说说 RPC 框架的基本架构。
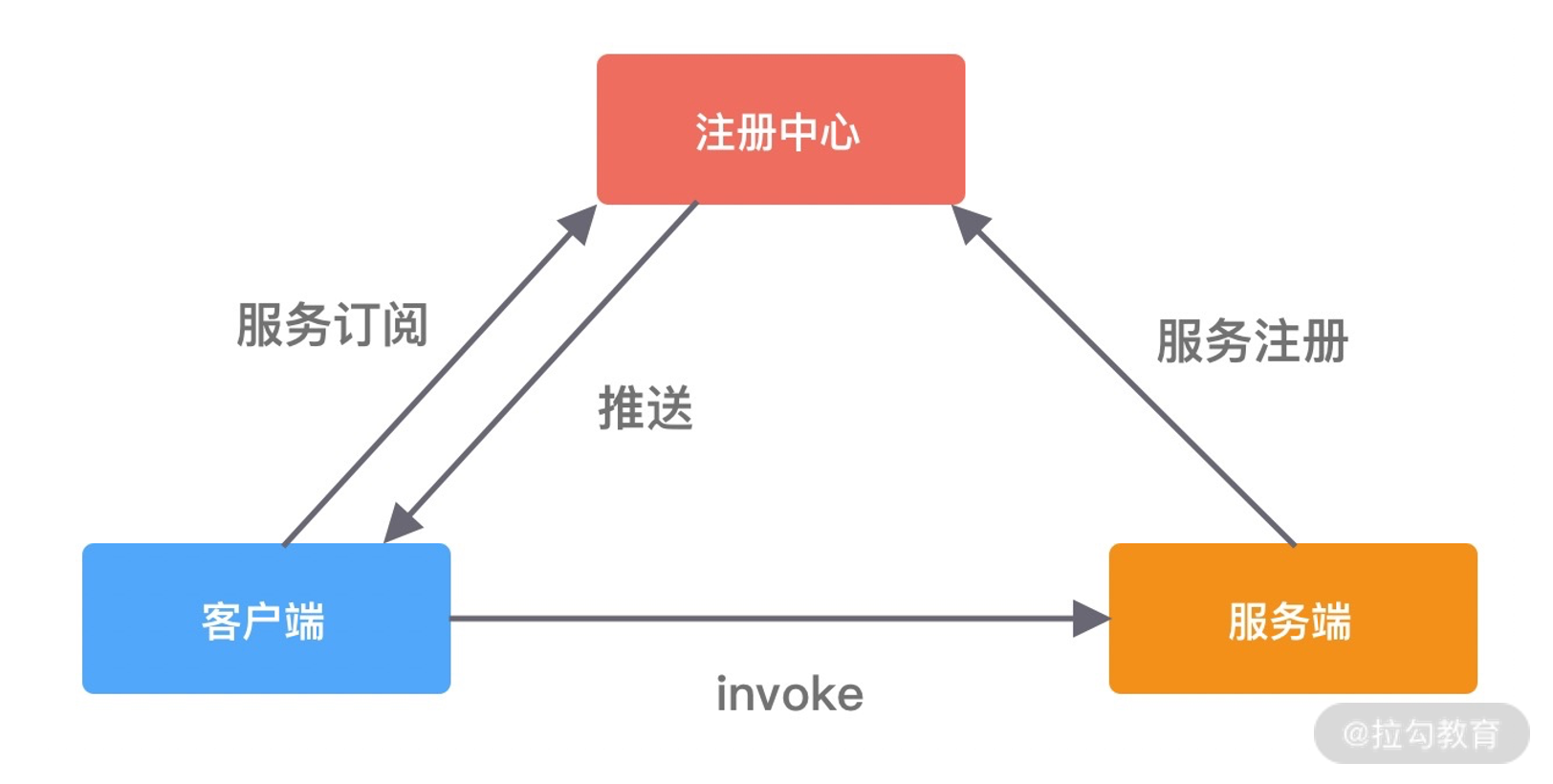
RPC 框架包含三个最重要的组件,分别是客户端、服务端和注册中心。在一次 RPC 调用流程中,这三个组件是这样交互的:
- 服务端在启动后,会将它提供的服务列表发布到注册中心,客户端向注册中心订阅服务地址;
- 客户端会通过本地代理模块 Proxy 调用服务端,Proxy 模块收到负责将方法、参数等数据转化成网络字节流;
- 客户端从服务列表中选取其中一个的服务地址,并将数据通过网络发送给服务端;
- 服务端接收到数据后进行解码,得到请求信息;
- 服务端根据解码后的请求信息调用对应的服务,然后将调用结果返回给客户端。
虽然 RPC 调用流程很容易理解,但是实现一个完整的 RPC 框架设计到很多内容,例如服务注册与发现、通信协议与序列化、负载均衡、动态代理等,下面我们一一进行初步地讲解。
服务注册与发现
在分布式系统中,不同服务之间应该如何通信呢?传统的方式可以通过 HTTP 请求调用、保存服务端的服务列表等,这样做需要开发者主动感知到服务端暴露的信息,系统之间耦合严重。为了更好地将客户端和服务端解耦,以及实现服务优雅上线和下线,于是注册中心就出现了。
在 RPC 框架中,主要是使用注册中心来实现服务注册和发现的功能。服务端节点上线后自行向注册中心注册服务列表,节点下线时需要从注册中心将节点元数据信息移除。客户端向服务端发起调用时,自己负责从注册中心获取服务端的服务列表,然后在通过负载均衡算法选择其中一个服务节点进行调用。以上是最简单直接的服务端和客户端的发布和订阅模式,不需要再借助任何中间服务器,性能损耗也是最小的。
现在思考一个问题,服务在下线时需要从注册中心移除元数据,那么注册中心怎么才能感知到服务下线呢?我们最先想到的方法就是节点主动通知的实现方式,当节点需要下线时,向注册中心发送下线请求,让注册中心移除自己的元数据信息。但是如果节点异常退出,例如断网、进程崩溃等,那么注册中心将会一直残留异常节点的元数据,从而可能造成服务调用出现问题。
为了避免上述问题,实现服务优雅下线比较好的方式是采用主动通知 + 心跳检测的方案。除了主动通知注册中心下线外,还需要增加节点与注册中心的心跳检测功能,这个过程也叫作探活。心跳检测可以由节点或者注册中心负责,例如注册中心可以向服务节点每 60s 发送一次心跳包,如果 3 次心跳包都没有收到请求结果,可以任务该服务节点已经下线。
由此可见,采用注册中心的好处是可以解耦客户端和服务端之间错综复杂的关系,并且能够实现对服务的动态管理。服务配置可以支持动态修改,然后将更新后的配置推送到客户端和服务端,无须重启任何服务。
通信协议与序列化
既然 RPC 是远程调用,必然离不开网络通信协议。客户端在向服务端发起调用之前,需要考虑采用何种方式将调用信息进行编码,并传输到服务端。因为 RPC 框架对性能有非常高的要求,所以通信协议应该越简单越好,这样可以减少编解码的性能损耗。RPC 框架可以基于不同的协议实现,大部分主流 RPC 框架会选择 TCP、HTTP 协议,出名的 gRPC 框架使用的则是 HTTP2。TCP、HTTP、HTTP2 都是稳定可靠的,但其实使用 UDP 协议也是可以的,具体看业务使用的场景。成熟的 RCP 框架能够支持多种协议,例如阿里开源的 Dubbo 框架被很多互联网公司广泛使用,其中可插拔的协议支持是 Dubbo 的一大特色,这样不仅可以给开发者提供多种不同的选择,而且为接入异构系统提供了便利。
客户端和服务端在通信过程中需要传输哪些数据呢?这些数据又该如何编解码呢?如果采用 TCP 协议,你需要将调用的接口、方法、请求参数、调用属性等信息序列化成二进制字节流传递给服务提供方,服务端接收到数据后,再把二进制字节流反序列化得到调用信息,然后利用反射的原理调用对应方法,最后将返回结果、返回码、异常信息等返回给客户端。所谓序列化和反序列化就是将对象转换成二进制流以及将二进制流再转换成对象的过程。因为网络通信依赖于字节流,而且这些请求信息都是不确定的,所以一般会选用通用且高效的序列化算法。比较常用的序列化算法有 FastJson、Kryo、Hessian、Protobuf 等,这些第三方序列化算法都比 Java 原生的序列化操作都更加高效。Dubbo 支持多种序列化算法,并定义了 Serialization 接口规范,所有序列化算法扩展都必须实现该接口,其中默认使用的是 Hessian 序列化算法。
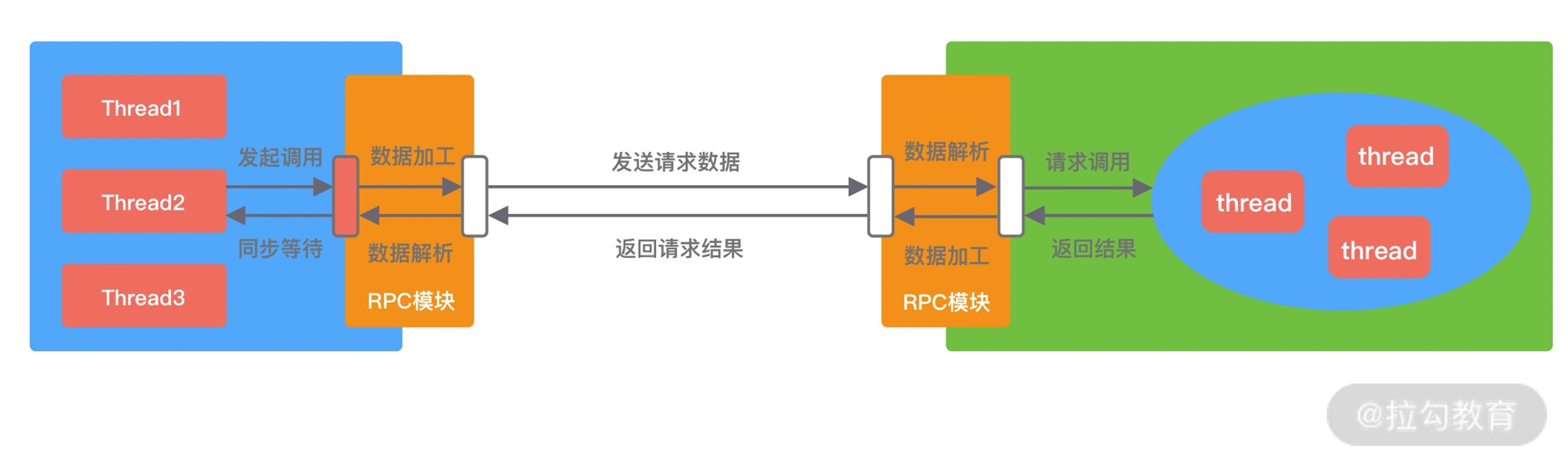
RPC 调用方式
成熟的 RPC 框架一般会提供四种调用方式,分别为同步 Sync、异步 Future、回调 Callback和单向 Oneway。RPC 框架的性能和吞吐量与合理使用调用方式是息息相关的,下面我们逐一介绍下四种调用方式的实现原理。
Sync 同步调用。客户端线程发起 RPC 调用后,当前线程会一直阻塞,直至服务端返回结果或者处理超时异常。Sync 同步调用一般是 RPC 框架默认的调用方式,为了保证系统可用性,客户端设置合理的超时时间是非常重要的。虽说 Sync 是同步调用,但是客户端线程和服务端线程并不是同一个线程,实际在 RPC 框架内部还是异步处理的。Sync 同步调用的过程如下图所示。
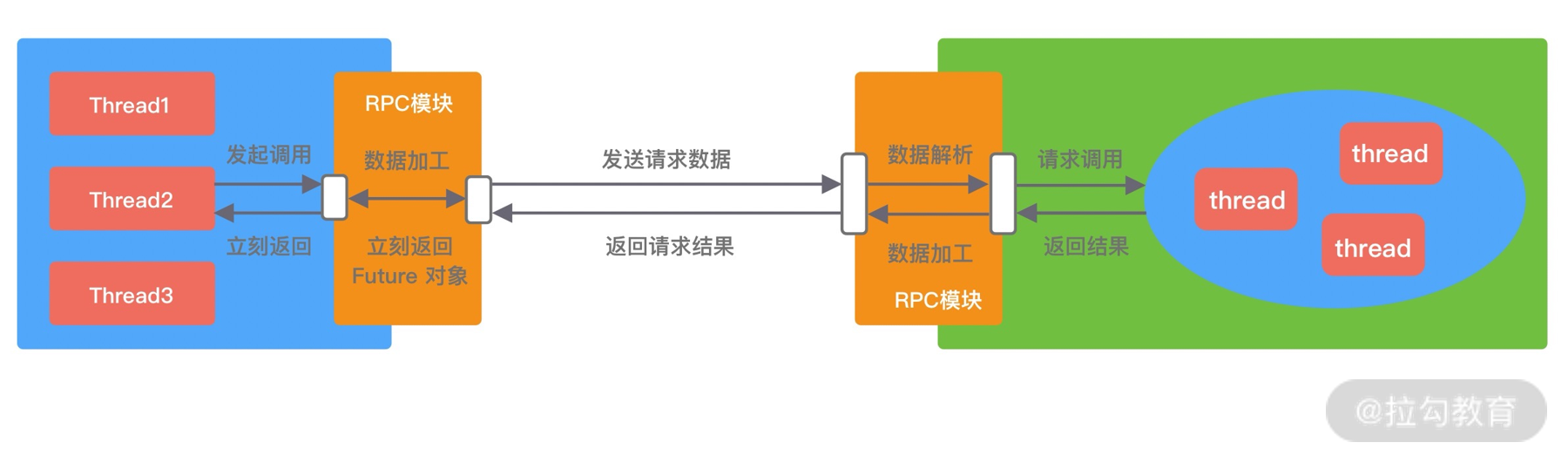
- Future 异步调用。客户端发起调用后不会再阻塞等待,而是拿到 RPC 框架返回的 Future 对象,调用结果会被服务端缓存,客户端自行决定后续何时获取返回结果。当客户端主动获取结果时,该过程是阻塞等待的。Future 异步调用过程如下图所示。
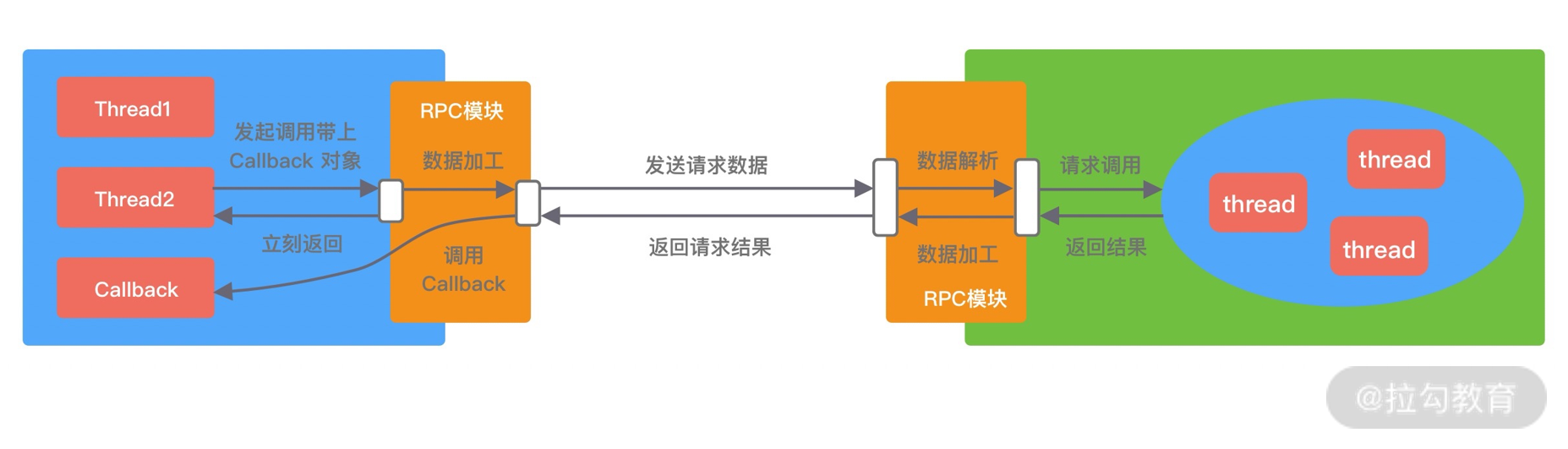
- Callback 回调调用。如下图所示,客户端发起调用时,将 Callback 对象传递给 RPC 框架,无须同步等待返回结果,直接返回。当获取到服务端响应结果或者超时异常后,再执行用户注册的 Callback 回调。所以 Callback 接口一般包含 onResponse 和 onException 两个方法,分别对应成功返回和异常返回两种情况。
- Oneway 单向调用。客户端发起请求之后直接返回,忽略返回结果。Oneway 方式是最简单的,具体调用过程如下图所示。
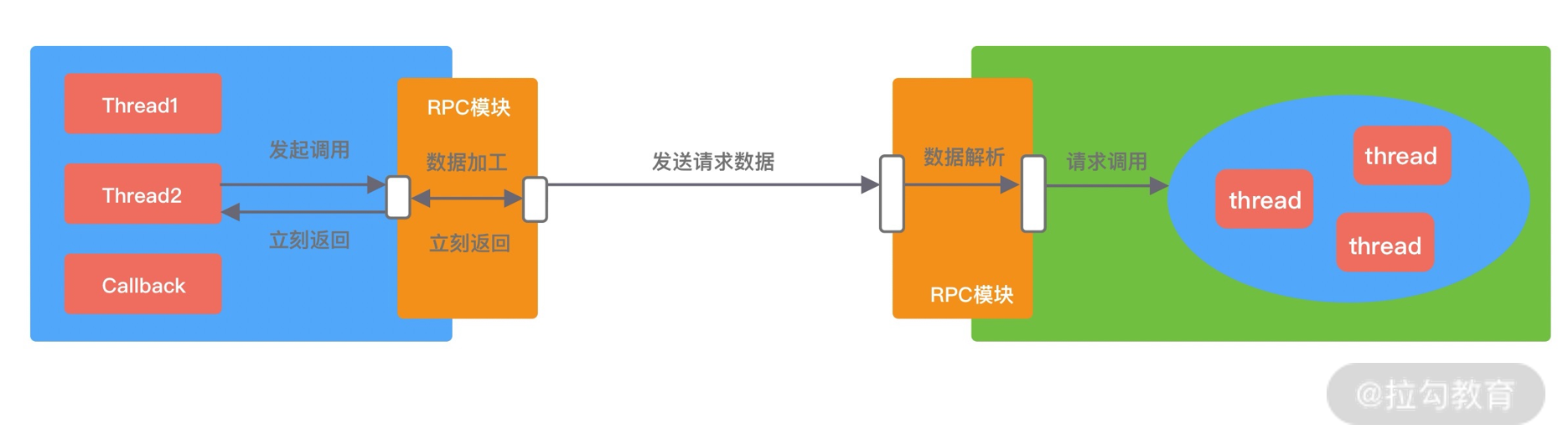
四种调用方式都各有优缺点,很难说异步方式一定会比同步方式效果好,在不用的业务场景可以按需选取更合适的调用方式。
线程模型
线程模型是 RPC 框架需要重点关注的部分,与我们之前介绍的 Netty Reactor 线程模型有什么区别和联系吗?
首先我们需要明确 I/O 线程和业务线程的区别,以 Dubbo 框架为例,Dubbo 使用 Netty 作为底层的网络通信框架,采用了我们熟悉的主从 Reactor 线程模型,其中 Boss 和 Worker 线程池就可以看作 I/O 线程。I/O 线程可以理解为主要负责处理网络数据,例如事件轮询、编解码、数据传输等。如果业务逻辑能够立即完成,也可以使用 I/O 线程进行处理,这样可以省去线程上下文切换的开销。如果业务逻辑耗时较多,例如包含查询数据库、复杂规则计算等耗时逻辑,那么 I/O 必须将这些请求分发到业务线程池中进行处理,以免阻塞 I/O 线程。
那么哪些请求需要在 I/O 线程中执行,哪些又需要在业务线程池中执行呢?Dubbo 框架的做法值得借鉴,它给用户提供了多种选择,它一共提供了 5 种分发策略,如下表格所示。

负载均衡
在分布式系统中,服务提供者和服务消费者都会有多台节点,如何保证服务提供者所有节点的负载均衡呢?客户端在发起调用之前,需要感知有多少服务端节点可用,然后从中选取一个进行调用。客户端需要拿到服务端节点的状态信息,并根据不同的策略实现负载均衡算法。负载均衡策略是影响 RPC 框架吞吐量很重要的一个因素,下面我们介绍几种最常用的负载均衡策略。
- Round-Robin 轮询。Round-Robin 是最简单有效的负载均衡策略,并没有考虑服务端节点的实际负载水平,而是依次轮询服务端节点。
- Weighted Round-Robin 权重轮询。对不同负载水平的服务端节点增加权重系数,这样可以通过权重系数降低性能较差或者配置较低的节点流量。权重系数可以根据服务端负载水平实时进行调整,使集群达到相对均衡的状态。
- Least Connections 最少连接数。客户端根据服务端节点当前的连接数进行负载均衡,客户端会选择连接数最少的一台服务器进行调用。Least Connections 策略只是服务端其中一种维度,我们可以演化出最少请求数、CPU 利用率最低等其他维度的负载均衡方案。
- Consistent Hash 一致性 Hash。目前主流推荐的负载均衡策略,Consistent Hash 是一种特殊的 Hash 算法,在服务端节点扩容或者下线时,尽可能保证客户端请求还是固定分配到同一台服务器节点。Consistent Hash 算法是采用哈希环来实现的,通过 Hash 函数将对象和服务器节点放置在哈希环上,一般来说服务器可以选择 IP + Port 进行 Hash,然后为对象选择对应的服务器节点,在哈希环中顺时针查找距离对象 Hash 值最近的服务器节点。
此外,负载均衡算法可以是多种多样的,客户端可以记录例如健康状态、连接数、内存、CPU、Load 等更加丰富的信息,根据综合因素进行更好地决策。
动态代理
RPC 框架怎么做到像调用本地接口一样调用远端服务呢?这必须依赖动态代理来实现。需要创建一个代理对象,在代理对象中完成数据报文编码,然后发起调用发送数据给服务提供方,以此屏蔽 RPC 框架的调用细节。因为代理类是在运行时生成的,所以代理类的生成速度、生成的字节码大小都会影响 RPC 框架整体的性能和资源消耗,所以需要慎重选择动态代理的实现方案。动态代理比较主流的实现方案有以下几种:JDK 动态代理、Cglib、Javassist、ASM、Byte Buddy,我们简单做一个对比和介绍。
- JDK 动态代理。在运行时可以动态创建代理类,但是 JDK 动态代理的功能比较局限,代理对象必须实现一个接口,否则抛出异常。因为代理类会继承 Proxy 类,然而 Java 是不支持多重继承的,只能通过接口实现多态。JDK 动态代理所生成的代理类是接口的实现类,不能代理接口中不存在的方法。JDK 动态代理是通过反射调用的形式代理类中的方法,比直接调用肯定是性能要慢的。
- Cglib 动态代理。Cglib 是基于 ASM 字节码生成框架实现的,通过字节码技术生成的代理类,所以代理类的类型是不受限制的。而且 Cglib 生成的代理类是继承于被代理类,所以可以提供更加灵活的功能。在代理方法方面,Cglib 是有优势的,它采用了 FastClass 机制,为代理类和被代理类各自创建一个 Class,这个 Class 会为代理类和被代理类的方法分配 index 索引,FastClass 就可以通过 index 直接定位要调用的方法,并直接调用,这是一种空间换时间的优化思路。
- Javassist 和 ASM。二者都是 Java 字节码操作框架,使用起来难度较大,需要开发者对 Class 文件结构以及 JVM 都有所了解,但是它们都比反射的性能要高。Byte Buddy 也是一个字节码生成和操作的类库,Byte Buddy 功能强大,相比于 Javassist 和 ASM,Byte Buddy 提供了更加便捷的 API,用于创建和修改 Java 类,无须理解字节码的格式,而且 Byte Buddy 更加轻量,性能更好。
至此,我们已经对实现 RPC 框架的几个核心要点做了一个大致的介绍,关于通信协议、负载均衡、动态代理在 RPC 框架中如何实现,我们后面会有专门的实践课对其进行详细介绍,本节课我们先有个大概的印象即可。
总结
如果你可以完成上述 RPC 框架的核心功能,那么一个简易的 RPC 框架的 MVP 原型就完成了,这也是我们实践课的目标。当然实现一个高性能高可靠的 RPC 框架并不容易,需要考虑的问题远不止如此,例如异常重试、服务级别线程池隔离、熔断限流、集群容错、优雅下线等等,在实践课最后我会为你讲解 RPC 框架进阶的拓展内容。
24 服务发布与订阅:搭建生产者和消费者的基础框架
从本节课开始,我们开始动手开发一个完整的 RPC 框架原型,通过整个实践课程的学习,你不仅可以熟悉 RPC 的实现原理,而且可以对之前 Netty 基础知识加深理解,同样在工作中也可以学以致用。
我会从服务发布与订阅、远程通信、服务治理、动态代理四个方面详细地介绍一个通用 RPC 框架的实现过程,相信你只要坚持完成本次实践课,之后你再独立完成工作中项目研发会变得更加容易。你是不是已经迫不及待地想动手了呢?让我们一起开始吧!
源码参考地址:mini-rpc
环境搭建
工欲善其事必先利其器,首先我们需要搭建我们的开发环境,这是每个程序员的必备技能。以下是我的本机环境清单,仅供参考。
- 操作系统:MacOS Big Sur,11.0.1。
- 集成开发工具:IntelliJ IDEA 2020.3,当然你也可以选择 eclipse。
- 项目技术栈:SpringBoot 2.1.12.RELEASE + JDK 1.8.0_221 + Netty 4.1.42.Final。
- 项目依赖管理工具:Maven 3.5.4,你可以独立安装 Maven 或者使用 IDEA 的集成版,独立安装的 Maven 需要配置 MAVEN_HOME 和 PATH 环境变量。
- 注册中心:Zookeeeper 3.4.14,需要特别注意 Zookeeeper 和 Apache Curator 一定要搭配使用,Zookeeper 3.4.x 版本,Apache Curator 只有 2.x.x 才能支持。
项目结构
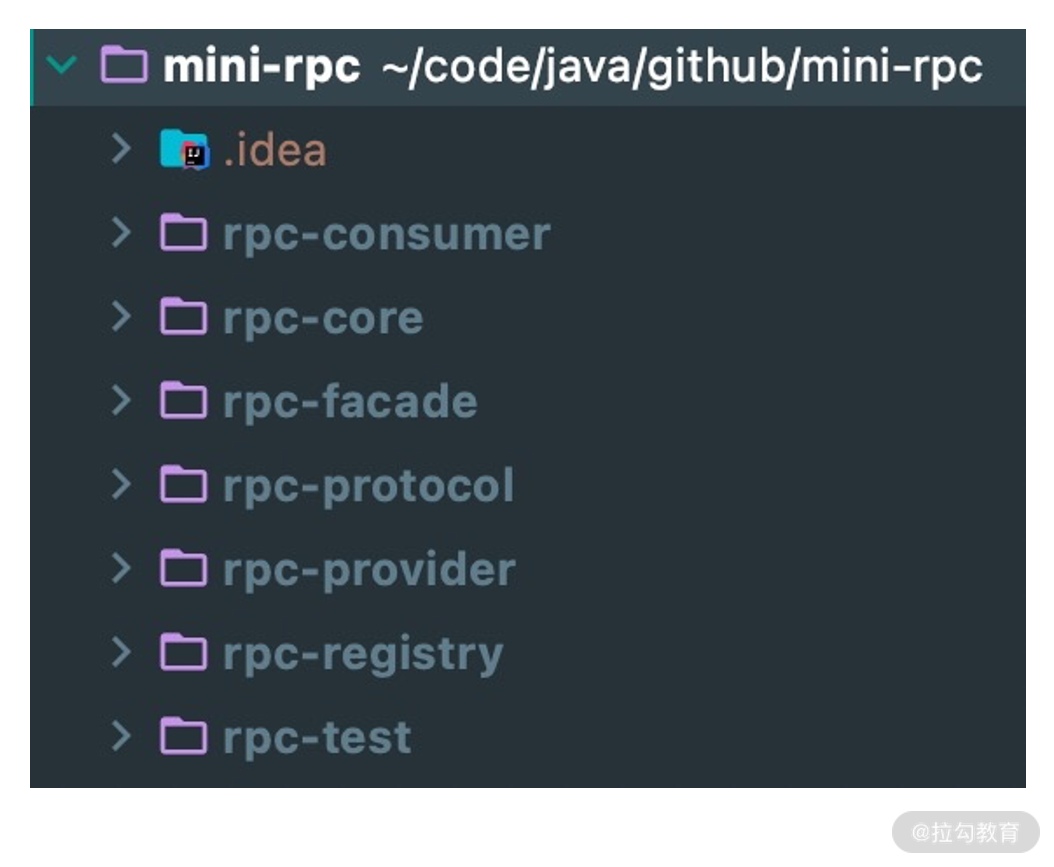
在动手开发项目之前,我们需要对项目结构有清晰的构思。根据上节课介绍的 RPC 框架设计架构,我们可以将项目结构划分为以下几个模块。
其中每个模块都是什么角色呢?下面我们一一进行介绍。
- rpc-provider,服务提供者。负责发布 RPC 服务,接收和处理 RPC 请求。
- rpc-consumer,服务消费者。使用动态代理发起 RPC 远程调用,帮助使用者来屏蔽底层网络通信的细节。
- rpc-registry,注册中心模块。提供服务注册、服务发现、负载均衡的基本功能。
- rpc-protocol,网络通信模块。包含 RPC 协议的编解码器、序列化和反序列化工具等。
- rpc-core,基础类库。提供通用的工具类以及模型定义,例如 RPC 请求和响应类、RPC 服务元数据类等。
- rpc-facade,RPC 服务接口。包含服务提供者需要对外暴露的接口,本模块主要用于模拟真实 RPC 调用的测试。
如下图所示,首先我们需要清楚各个模块之间的依赖关系,才能帮助我们更好地梳理 Maven 的 pom 定义。rpc-core 是最基础的类库,所以大部分模块都依赖它。rpc-consumer 用于发起 RPC 调用。rpc-provider 负责处理 RPC 请求,如果不知道远程服务的地址,那么一切都是空谈了,所以两者都需要依赖 rpc-registry 提供的服务发现和服务注册的能力。
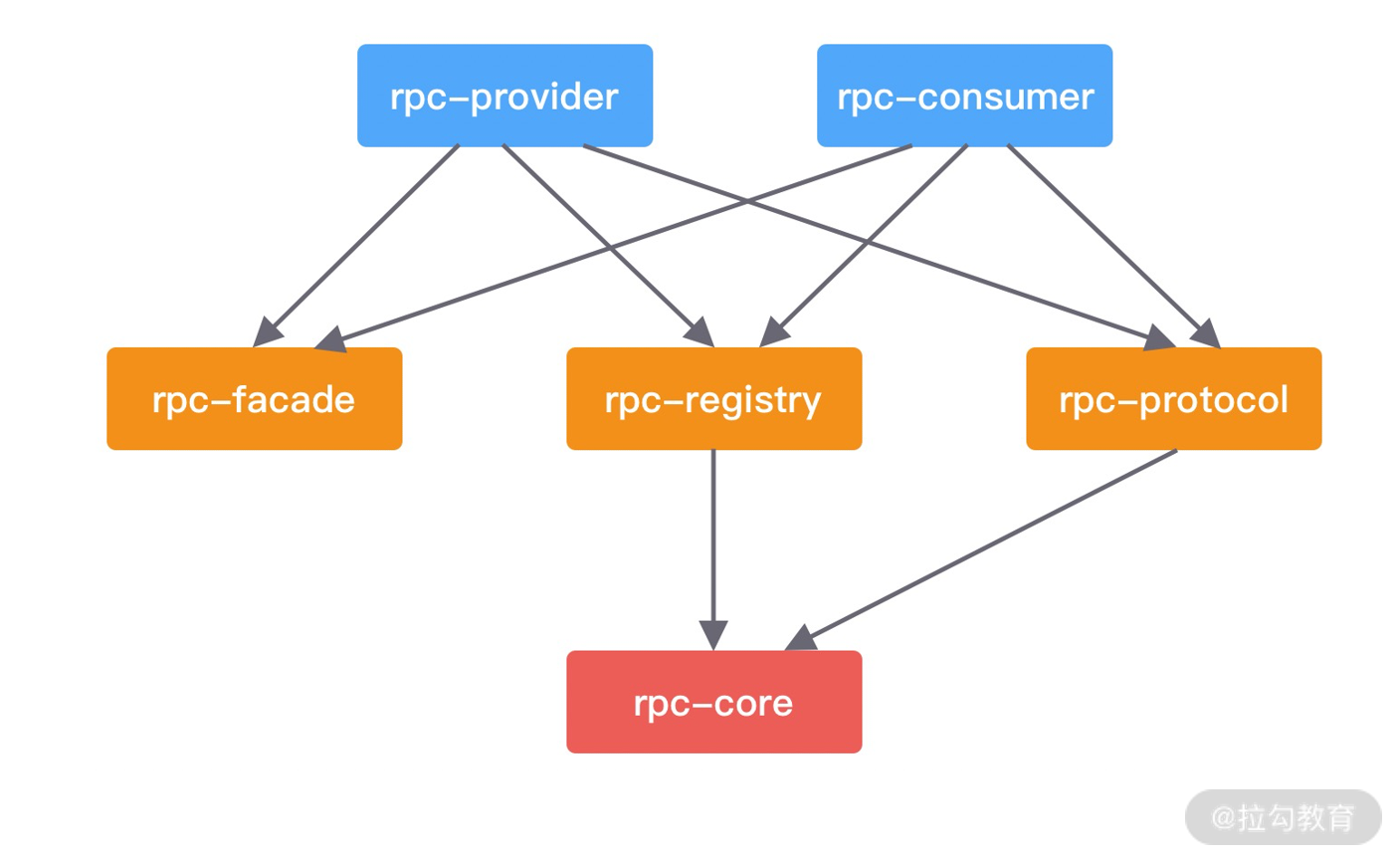
如何使用
我们不着急开始动手实现代码细节,而是考虑一个问题,最终实现的 RPC 框架应该让用户如何使用呢?这就跟我们学习一门技术一样,你不可能刚开始就直接陷入源码的细节,而是先熟悉它的基本使用方式,然后找到关键的切入点再深入研究实现原理,会起到事半功倍的效果。
首先我们看下 RPC 框架想要实现的效果,如下所示:
// rpc-facade # HelloFacade
public interface HelloFacade {String hello(String name);
}
// rpc-provider # HelloFacadeImpl
@RpcService(serviceInterface = HelloFacade.class, serviceVersion = "1.0.0")
public class HelloFacadeImpl implements HelloFacade {@Overridepublic String hello(String name) {return "hello" + name;}
}
// rpc-consumer # HelloController
@RestController
public class HelloController {@RpcReference(serviceVersion = "1.0.0", timeout = 3000)private HelloFacade helloFacade;@RequestMapping(value = "/hello", method = RequestMethod.GET)public String sayHello() {return helloFacade.hello("mini rpc");}
}
为了方便在本地模拟客户端和服务端,我会把 rpc-provider 和 rpc-consumer 两个模块能够做到独立启动。rpc-provider 通过 @RpcService 注解暴露 RPC 服务 HelloFacade,rpc-consumer 通过 @RpcReference 注解引用 HelloFacade 服务并发起调用,基本与我们常用的 RPC 框架使用方式保持一致。
梳理清楚项目结构和整体实现思路之后,下面我们从服务提供者开始入手开发。
服务提供者发布服务
服务提供者 rpc-provider 需要完成哪些事情呢?主要分为四个核心流程:
- 服务提供者启动服务,并暴露服务端口;
- 启动时扫描需要对外发布的服务,并将服务元数据信息发布到注册中心;
- 接收 RPC 请求,解码后得到请求消息;
- 提交请求至自定义线程池进行处理,并将处理结果写回客户端。
本节课我们先实现 rpc-provider 模块前面两个流程。
服务提供者启动
服务提供者启动的配置方式基本是固定模式,也是从引导器 Bootstrap 开始入手,你可以复习下基础课程《03 引导器作用:客户端和服务端启动都要做些什么?》。我们首先看下服务提供者的启动实现,代码如下所示:
private void startRpcServer() throws Exception {this.serverAddress = InetAddress.getLocalHost().getHostAddress();EventLoopGroup boss = new NioEventLoopGroup();EventLoopGroup worker = new NioEventLoopGroup();try {ServerBootstrap bootstrap = new ServerBootstrap();bootstrap.group(boss, worker).channel(NioServerSocketChannel.class).childHandler(new ChannelInitializer<SocketChannel>() {@Overrideprotected void initChannel(SocketChannel socketChannel) throws Exception {}}).childOption(ChannelOption.SO_KEEPALIVE, true);ChannelFuture channelFuture = bootstrap.bind(this.serverAddress, this.serverPort).sync();log.info("server addr {} started on port {}", this.serverAddress, this.serverPort);channelFuture.channel().closeFuture().sync();} finally {boss.shutdownGracefully();worker.shutdownGracefully();}
}
服务提供者采用的是主从 Reactor 线程模型,启动过程包括配置线程池、Channel 初始化、端口绑定三个步骤,我们暂时先不关注 Channel 初始化中自定义的业务处理器 Handler 是如何设计和实现的。
对于 RPC 框架而言,可扩展性是比较重要的一方面。接下来我们看下如何借助 Spring Boot 的能力将服务提供者启动所依赖的参数做成可配置化。
参数配置
服务提供者启动需要配置一些参数,我们不应该把这些参数固定在代码里,而是以命令行参数或者配置文件的方式进行输入。我们可以使用 Spring Boot 的 @ConfigurationProperties 注解很轻松地实现配置项的加载,并且可以把相同前缀类型的配置项自动封装成实体类。接下来我们为服务提供者提供参数映射的对象:
@Data
@ConfigurationProperties(prefix = "rpc")
public class RpcProperties {private int servicePort;private String registryAddr;private String registryType;
}
我们一共提取了三个参数,分别为服务暴露的端口 servicePort、注册中心的地址 registryAddr 和注册中心的类型 registryType。@ConfigurationProperties 注解最经典的使用方式就是通过 prefix 属性指定配置参数的前缀,默认会与全局配置文件 application.properties 或者 application.yml 中的参数进行一一绑定。如果你想自定义一个配置文件,可以通过 @PropertySource 注解指定配置文件的位置。下面我们在 rpc-provider 模块的 resources 目录下创建全局配置文件 application.properties,并配置以上三个参数:
rpc.servicePort=2781
rpc.registryType=ZOOKEEPER
rpc.registryAddr=127.0.0.1:2181
application.properties 配置文件中的属性必须和实体类的成员变量是一一对应的,可以采用以下常用的命名规则,例如驼峰命名 rpc.servicePort=2781;或者虚线 - 分割的方式 rpc.service-port=2781;以及大写加下划线的形式 RPC_Service_Port,建议在环境变量中使用。@ConfigurationProperties 注解还可以支持更多复杂结构的配置,并且可以 Validation 功能进行参数校验,如果你有兴趣可以课后再进行深入研究。
有了 RpcProperties 实体类,我们接下来应该如何使用呢?如果只配置 @ConfigurationProperties 注解,Spring 容器并不能获取配置文件的内容并映射为对象,这时 @EnableConfigurationProperties 注解就登场了。@EnableConfigurationProperties 注解的作用就是将声明 @ConfigurationProperties 注解的类注入为 Spring 容器中的 Bean。具体用法如下:
@Configuration
@EnableConfigurationProperties(RpcProperties.class)
public class RpcProviderAutoConfiguration {@Resourceprivate RpcProperties rpcProperties;@Beanpublic RpcProvider init() throws Exception {RegistryType type = RegistryType.valueOf(rpcProperties.getRegistryType());RegistryService serviceRegistry = RegistryFactory.getInstance(rpcProperties.getRegistryAddr(), type);return new RpcProvider(rpcProperties.getServicePort(), serviceRegistry);}
}
我们通过 @EnableConfigurationProperties 注解使得 RpcProperties 生效,并通过 @Configuration 和 @Bean 注解自定义了 RpcProvider 的生成方式。@Configuration 主要用于定义配置类,配置类内部可以包含多个 @Bean 注解的方法,可以替换传统 XML 的定义方式。被 @Bean 注解的方法会返回一个自定义的对象,@Bean 注解会将这个对象注册为 Bean 并装配到 Spring 容器中,@Bean 比 @Component 注解的自定义功能更强。
至此,我们服务提供者启动的准备工作就完成了,下面你需要添加 Spring Boot 的 main 方法,如下所示,然后尝试启动下 rpc-provider 模块吧。
@EnableConfigurationProperties
@SpringBootApplication
public class RpcProviderApplication {public static void main(String[] args) {SpringApplication.run(RpcProviderApplication.class, args);}
}
发布服务
在服务提供者启动时,我们需要思考一个核心问题,服务提供者需要将服务发布到注册中心,怎么知道哪些服务需要发布呢?服务提供者需要定义需要发布服务类型、服务版本等属性,主流的 RPC 框架都采用 XML 文件或者注解的方式进行定义。以注解的方式暴露服务现在最为常用,省去了很多烦琐的 XML 配置过程。例如 Dubbo 框架中使用 @Service 注解替代 dubbo:service 的定义方式,服务消费者则使用 @Reference 注解替代 dubbo:reference。接下来我们看看作为服务提供者,如何通过注解暴露服务,首先给出我们自定义的 @RpcService 注解定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Component
public @interface RpcService {Class<?> serviceInterface() default Object.class;String serviceVersion() default "1.0";
}
@RpcService 提供了两个必不可少的属性:服务类型 serviceInterface 和服务版本 serviceVersion,服务消费者必须指定完全一样的属性才能正确调用。有了 @RpcService 注解之后,我们就可以在服务实现类上使用它,@RpcService 注解本质上就是 @Component,可以将服务实现类注册成 Spring 容器所管理的 Bean,那么 serviceInterface、serviceVersion 的属性值怎么才能和 Bean 关联起来呢?这就需要我们就 Bean 的生命周期以及 Bean 的可扩展点有所了解。
Spring 的 BeanPostProcessor 接口给提供了对 Bean 进行再加工的扩展点,BeanPostProcessor 常用于处理自定义注解。自定义的 Bean 可以通过实现 BeanPostProcessor 接口,在 Bean 实例化的前后加入自定义的逻辑处理。如下所示,我们通过 RpcProvider 实现 BeanPostProcessor 接口,来实现对 声明 @RpcService 注解服务的自定义处理。
public class RpcProvider implements InitializingBean, BeanPostProcessor {// 省略其他代码private final Map<String, Object> rpcServiceMap = new HashMap<>();@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {RpcService rpcService = bean.getClass().getAnnotation(RpcService.class);if (rpcService != null) {String serviceName = rpcService.serviceInterface().getName();String serviceVersion = rpcService.serviceVersion();try {ServiceMeta serviceMeta = new ServiceMeta();serviceMeta.setServiceAddr(serverAddress);serviceMeta.setServicePort(serverPort);serviceMeta.setServiceName(serviceName);serviceMeta.setServiceVersion(serviceVersion);// TODO 发布服务元数据至注册中心rpcServiceMap.put(RpcServiceHelper.buildServiceKey(serviceMeta.getServiceName(), serviceMeta.getServiceVersion()), bean);} catch (Exception e) {log.error("failed to register service {}#{}", serviceName, serviceVersion, e);}}return bean;}
}
RpcProvider 重写了 BeanPostProcessor 接口的 postProcessAfterInitialization 方法,对所有初始化完成后的 Bean 进行扫描。如果 Bean 包含 @RpcService 注解,那么通过注解读取服务的元数据信息并构造出 ServiceMeta 对象,接下来准备将服务的元数据信息发布至注册中心,注册中心的实现我们先暂且跳过,后面会有单独一节课进行讲解注册中心的实现。此外,RpcProvider 还维护了一个 rpcServiceMap,存放服务初始化后所对应的 Bean,rpcServiceMap 起到了缓存的角色,在处理 RPC 请求时可以直接通过 rpcServiceMap 拿到对应的服务进行调用。
明白服务提供者如何处理 @RpcService 注解的原理之后,接下来再实现服务消费者就容易很多了。
服务消费者订阅服务
与服务提供者不同的是,服务消费者并不是一个常驻的服务,每次发起 RPC 调用时它才会去选择向哪个远端服务发送数据。所以服务消费者的实现要复杂一些,对于声明 @RpcReference 注解的成员变量,我们需要构造出一个可以真正进行 RPC 调用的 Bean,然后将它注册到 Spring 的容器中。
首先我们看下 @RpcReference 注解的定义,代码如下所示:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
@Autowired
public @interface RpcReference {String serviceVersion() default "1.0";String registryType() default "ZOOKEEPER";String registryAddress() default "127.0.0.1:2181";long timeout() default 5000;
}
@RpcReference 注解提供了服务版本 serviceVersion、注册中心类型 registryType、注册中心地址 registryAddress 和超时时间 timeout 四个属性,接下来我们需要使用这些属性构造出一个自定义的 Bean,并对该 Bean 执行的所有方法进行拦截。
Spring 的 FactoryBean 接口可以帮助我们实现自定义的 Bean,FactoryBean 是一种特种的工厂 Bean,通过 getObject() 方法返回对象,而并不是 FactoryBean 本身。
public class RpcReferenceBean implements FactoryBean<Object> {private Class<?> interfaceClass;private String serviceVersion;private String registryType;private String registryAddr;private long timeout;private Object object;@Overridepublic Object getObject() throws Exception {return object;}@Overridepublic Class<?> getObjectType() {return interfaceClass;}public void init() throws Exception {// TODO 生成动态代理对象并赋值给 object}public void setInterfaceClass(Class<?> interfaceClass) {this.interfaceClass = interfaceClass;}public void setServiceVersion(String serviceVersion) {this.serviceVersion = serviceVersion;}public void setRegistryType(String registryType) {this.registryType = registryType;}public void setRegistryAddr(String registryAddr) {this.registryAddr = registryAddr;}public void setTimeout(long timeout) {this.timeout = timeout;}
}
在 RpcReferenceBean 中 init() 方法被我标注了 TODO,此处需要实现动态代理对象,并通过代理对象完成 RPC 调用。对于使用者来说只是通过 @RpcReference 订阅了服务,并不感知底层调用的细节。对于如何实现 RPC 通信、服务寻址等,都是在动态代理类中完成的,在后面我们会有专门的一节课详细讲解动态代理的实现。
有了 @RpcReference 注解和 RpcReferenceBean 之后,我们可以使用 Spring 的扩展点 BeanFactoryPostProcessor 对 Bean 的定义进行修改。上文中服务提供者使用的是 BeanPostProcessor,BeanFactoryPostProcessor 和 BeanPostProcessor 都是 Spring 的核心扩展点,它们之间有什么区别呢?BeanFactoryPostProcessor 是 Spring 容器加载 Bean 的定义之后以及 Bean 实例化之前执行,所以 BeanFactoryPostProcessor 可以在 Bean 实例化之前获取 Bean 的配置元数据,并允许用户对其修改。而 BeanPostProcessor 是在 Bean 初始化前后执行,它并不能修改 Bean 的配置信息。
现在我们需要对声明 @RpcReference 注解的成员变量构造出 RpcReferenceBean,所以需要实现 BeanFactoryPostProcessor 修改 Bean 的定义,具体实现如下所示。
@Component
@Slf4j
public class RpcConsumerPostProcessor implements ApplicationContextAware, BeanClassLoaderAware, BeanFactoryPostProcessor {private ApplicationContext context;private ClassLoader classLoader;private final Map<String, BeanDefinition> rpcRefBeanDefinitions = new LinkedHashMap<>();@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.context = applicationContext;}@Overridepublic void setBeanClassLoader(ClassLoader classLoader) {this.classLoader = classLoader;}@Overridepublic void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {for (String beanDefinitionName : beanFactory.getBeanDefinitionNames()) {BeanDefinition beanDefinition = beanFactory.getBeanDefinition(beanDefinitionName);String beanClassName = beanDefinition.getBeanClassName();if (beanClassName != null) {Class<?> clazz = ClassUtils.resolveClassName(beanClassName, this.classLoader);ReflectionUtils.doWithFields(clazz, this::parseRpcReference);}}BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;this.rpcRefBeanDefinitions.forEach((beanName, beanDefinition) -> {if (context.containsBean(beanName)) {throw new IllegalArgumentException("spring context already has a bean named " + beanName);}registry.registerBeanDefinition(beanName, rpcRefBeanDefinitions.get(beanName));log.info("registered RpcReferenceBean {} success.", beanName);});}private void parseRpcReference(Field field) {RpcReference annotation = AnnotationUtils.getAnnotation(field, RpcReference.class);if (annotation != null) {BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition(RpcReferenceBean.class);builder.setInitMethodName(RpcConstants.INIT_METHOD_NAME);builder.addPropertyValue("interfaceClass", field.getType());builder.addPropertyValue("serviceVersion", annotation.serviceVersion());builder.addPropertyValue("registryType", annotation.registryType());builder.addPropertyValue("registryAddr", annotation.registryAddress());builder.addPropertyValue("timeout", annotation.timeout());BeanDefinition beanDefinition = builder.getBeanDefinition();rpcRefBeanDefinitions.put(field.getName(), beanDefinition);}}
}
RpcConsumerPostProcessor 类中重写了 BeanFactoryPostProcessor 的 postProcessBeanFactory 方法,从 beanFactory 中获取所有 Bean 的定义信息,然后分别对每个 Bean 的所有 field 进行检测。如果 field 被声明了 @RpcReference 注解,通过 BeanDefinitionBuilder 构造 RpcReferenceBean 的定义,并为 RpcReferenceBean 的成员变量赋值,包括服务类型 interfaceClass、服务版本 serviceVersion、注册中心类型 registryType、注册中心地址 registryAddr 以及超时时间 timeout。构造完 RpcReferenceBean 的定义之后,会将RpcReferenceBean 的 BeanDefinition 重新注册到 Spring 容器中。
至此,我们已经将服务提供者服务消费者的基本框架搭建出来了,并且着重介绍了服务提供者使用 @RpcService 注解是如何发布服务的,服务消费者相应需要一个能够注入服务接口的注解 @RpcReference,被 @RpcReference 修饰的成员变量都会被构造成 RpcReferenceBean,并为它生成动态代理类,后面我们再继续深入介绍。
总结
本节课我们介绍了服务发布与订阅的实现原理,搭建出了服务提供者和服务消费者的基本框架。可以看出,如果采用 Java 语言实现 RPC 框架核心的服务发布与订阅的核心逻辑,需要你具备较为扎实的 Spring 框架基础。了解 Spring 重要的扩展接口,可以帮助我们开发出更优雅的代码。
25 远程通信:通信协议设计以及编解码的实现
上节课我们搭建了服务提供者和服务消费者的基本框架,现在我们可以建立两个模块之间的通信机制了。本节课我们通过向 ChannelPipeline 添加自定义的业务处理器,来完成 RPC 框架的远程通信机制。需要实现的主要功能如下:
- 服务消费者实现协议编码,向服务提供者发送调用数据。
- 服务提供者收到数据后解码,然后向服务消费者发送响应数据,暂时忽略 RPC 请求是如何被调用的。
- 服务消费者收到响应数据后成功返回。
源码参考地址:mini-rpc
RPC 通信方案设计
结合本节课的目标,接下来我们对 RPC 请求调用和结果响应两个过程分别进行详细拆解分析。首先看下 RPC 请求调用的过程,如下图所示。
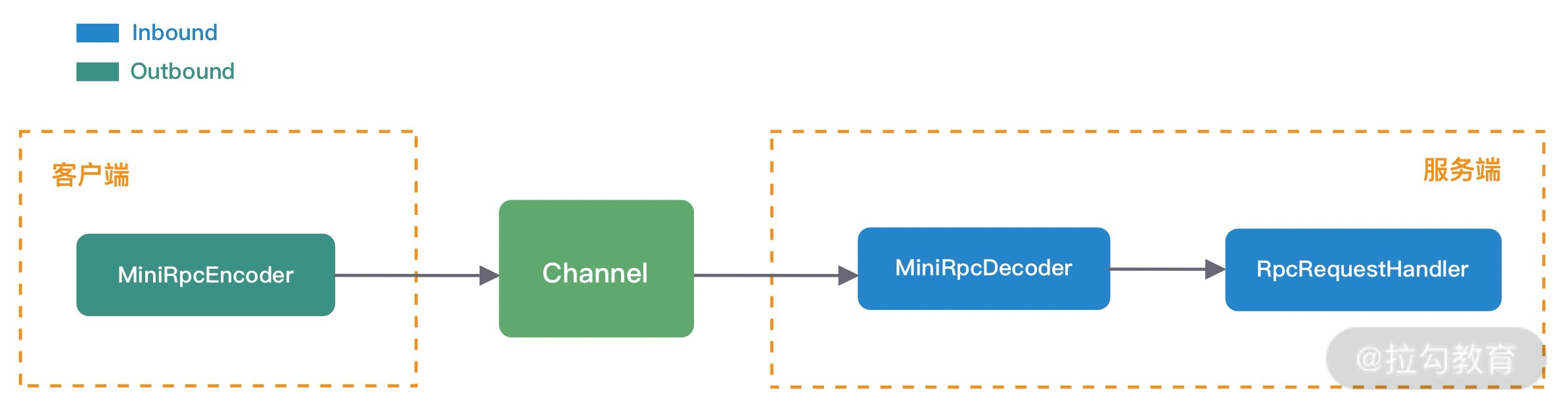
RPC 请求的过程对于服务消费者来说是出站操作,对于服务提供者来说是入站操作。数据发送前,服务消费者将 RPC 请求信息封装成 MiniRpcProtocol 对象,然后通过编码器 MiniRpcEncoder 进行二进制编码,最后直接向发送至远端即可。服务提供者收到请求数据后,将二进制数据交给解码器 MiniRpcDecoder,解码后再次生成 MiniRpcProtocol 对象,然后传递给 RpcRequestHandler 执行真正的 RPC 请求调用。
我们暂时忽略 RpcRequestHandler 是如何执行 RPC 请求调用的,接下来我们继续分析 RpcRequestHandler 处理成功后是如何向服务消费者返回响应结果的,如下图所示:
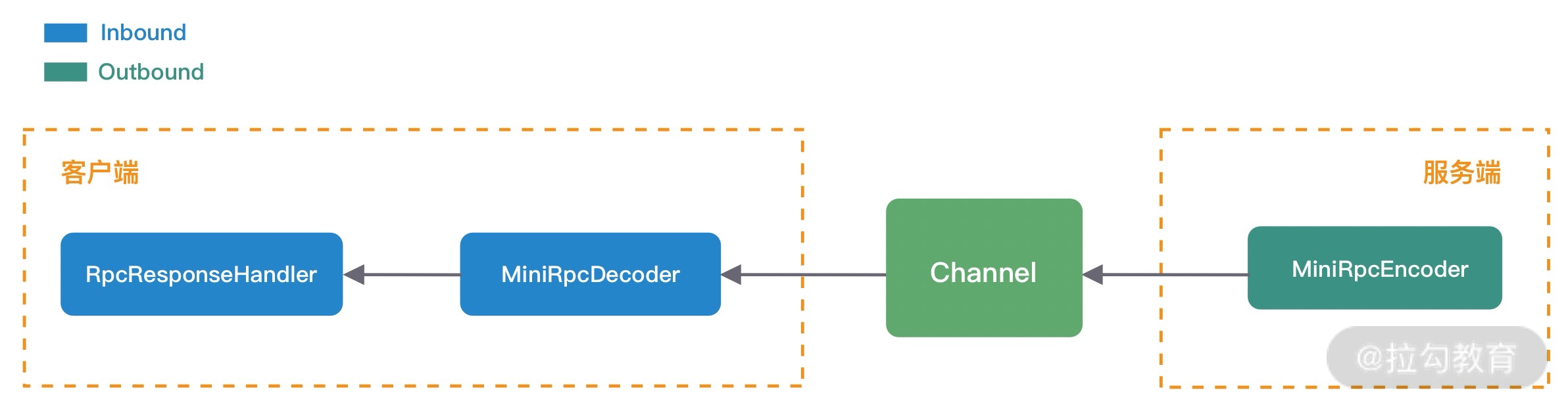
与 RPC 请求过程相反,是由服务提供者将响应结果封装成 MiniRpcProtocol 对象,然后通过 MiniRpcEncoder 编码发送给服务消费者。服务消费者对响应结果进行解码,因为 RPC 请求是高并发的,所以需要 RpcRequestHandler 根据响应结果找到对应的请求,最后将响应结果返回。
综合 RPC 请求调用和结果响应的处理过程来看,编码器 MiniRpcEncoder、解码器 MiniRpcDecoder 以及通信协议对象 MiniRpcProtocol 都可以设计成复用的,最终服务消费者和服务提供者的 ChannelPipeline 结构如下图所示。
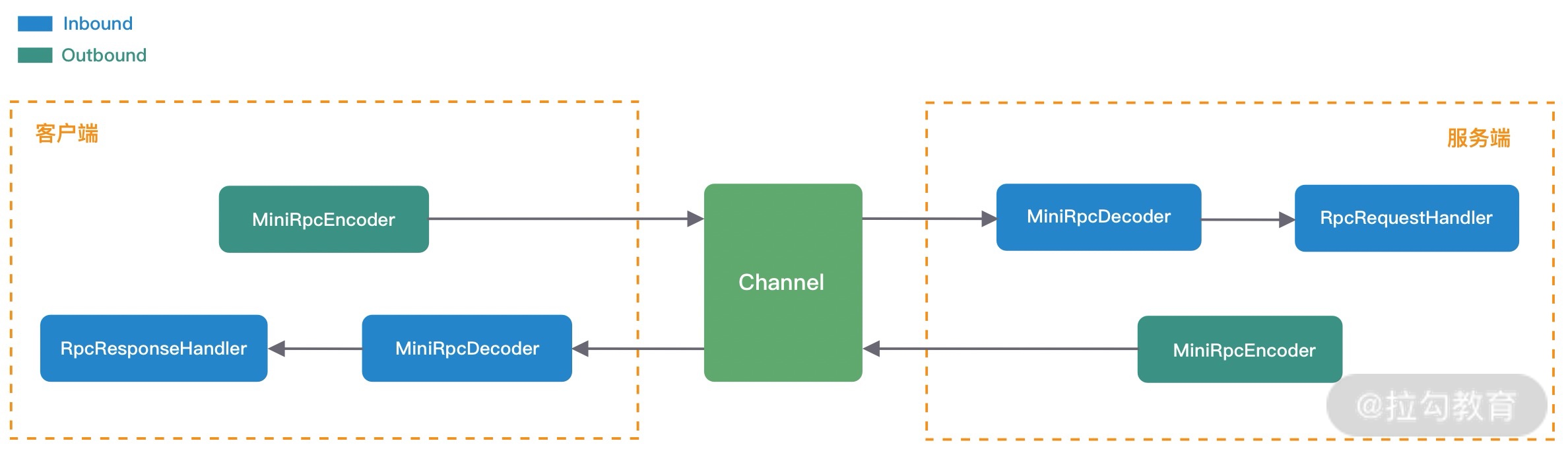
由此可见,在实现 Netty 网络通信模块时,先画图分析 ChannelHandler 的处理流程是非常有帮助的。
自定义 RPC 通信协议
协议是服务消费者和服务提供者之间通信的基础,主流的 RPC 框架都会自定义通信协议,相比于 HTTP、HTTPS、JSON 等通用的协议,自定义协议可以实现更好的性能、扩展性以及安全性。在《接头暗语:利用 Netty 如何实现自定义协议通信》课程中,我们学习了设计一个完备的通信协议需要考虑哪些因素,同时结合 RPC 请求调用与结果响应的场景,我们设计了一个简易版的 RPC 自定义协议,如下所示:
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 消息 ID 8byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
我们把协议分为协议头 Header 和协议体 Body 两个部分。协议头 Header 包含魔数、协议版本号、序列化算法、报文类型、状态、消息 ID、数据长度,协议体 Body 只包含数据内容部分,数据内容的长度是不固定的。RPC 请求和响应都可以使用该协议进行通信,对应协议实体类的定义如下所示:
@Data
public class MiniRpcProtocol<T> implements Serializable {private MsgHeader header; // 协议头private T body; // 协议体
}
@Data
public class MsgHeader implements Serializable {private short magic; // 魔数private byte version; // 协议版本号private byte serialization; // 序列化算法private byte msgType; // 报文类型private byte status; // 状态private long requestId; // 消息 IDprivate int msgLen; // 数据长度
}
在 RPC 请求调用的场景下,MiniRpcProtocol 中泛型 T 对应的 MiniRpcRequest 类型,MiniRpcRequest 主要包含 RPC 远程调用需要的必要参数,定义如下所示。
@Data
public class MiniRpcRequest implements Serializable {private String serviceVersion; // 服务版本private String className; // 服务接口名private String methodName; // 服务方法名private Object[] params; // 方法参数列表private Class<?>[] parameterTypes; // 方法参数类型列表
}
在 RPC 结果响应的场景下,MiniRpcProtocol 中泛型 T 对应的 MiniRpcResponse 类型,MiniRpcResponse 实体类的定义如下所示。此外,响应结果是否成功可以使用 MsgHeader 中的 status 字段表示,0 表示成功,非 0 表示失败。MiniRpcResponse 中 data 表示成功状态下返回的 RPC 请求结果,message 表示 RPC 请求调用失败的错误信息。
@Data
public class MiniRpcResponse implements Serializable {private Object data; // 请求结果private String message; // 错误信息
}
设计完 RPC 自定义协议之后,我们接下来再来解决 MiniRpcRequest 和 MiniRpcResponse 如何进行编码的问题。
序列化选型
MiniRpcRequest 和 MiniRpcResponse 实体类表示的协议体内容都是不确定具体长度的,所以我们一般会选用通用且高效的序列化算法将其转换成二进制数据,这样可以有效减少网络传输的带宽,提升 RPC 框架的整体性能。目前比较常用的序列化算法包括 Json、Kryo、Hessian、Protobuf 等,这些第三方序列化算法都比 Java 原生的序列化操作都更加高效。
首先我们定义了一个通用的序列化接口 RpcSerialization,所有序列化算法扩展都必须实现该接口,RpcSerialization 接口分别提供了序列化 serialize() 和反序列化 deserialize() 方法,如下所示:
public interface RpcSerialization {<T> byte[] serialize(T obj) throws IOException;<T> T deserialize(byte[] data, Class<T> clz) throws IOException;
}
接下来我们为 RpcSerialization 提供了 HessianSerialization 和 JsonSerialization 两种类型的实现类。以 HessianSerialization 为例,实现逻辑如下:
@Component
@Slf4j
public class HessianSerialization implements RpcSerialization {@Overridepublic <T> byte[] serialize(T object) {if (object == null) {throw new NullPointerException();}byte[] results;HessianSerializerOutput hessianOutput;try (ByteArrayOutputStream os = new ByteArrayOutputStream()) {hessianOutput = new HessianSerializerOutput(os);hessianOutput.writeObject(object);hessianOutput.flush();results = os.toByteArray();} catch (Exception e) {throw new SerializationException(e);}return results;}@SuppressWarnings("unchecked")@Overridepublic <T> T deserialize(byte[] bytes, Class<T> clz) {if (bytes == null) {throw new NullPointerException();}T result;try (ByteArrayInputStream is = new ByteArrayInputStream(bytes)) {HessianSerializerInput hessianInput = new HessianSerializerInput(is);result = (T) hessianInput.readObject(clz);} catch (Exception e) {throw new SerializationException(e);}return result;}
}
为了能够支持不同序列化算法,我们采用工厂模式来实现不同序列化算法之间的切换,使用相同的序列化接口指向不同的序列化算法。对于使用者来说只需要知道序列化算法的类型即可,不用关心底层序列化是如何实现的。具体实现如下:
public class SerializationFactory {public static RpcSerialization getRpcSerialization(byte serializationType) {SerializationTypeEnum typeEnum = SerializationTypeEnum.findByType(serializationType);switch (typeEnum) {case HESSIAN:return new HessianSerialization();case JSON:return new JsonSerialization();default:throw new IllegalArgumentException("serialization type is illegal, " + serializationType);}}
}
有了以上基础知识的储备,接下来我们就可以开始实现自定义的处理器了。
协议编码实现
在《接头暗语:利用 Netty 如何实现自定义协议通信》课程中,我们同样介绍了如何使用 Netty 实现自定义的通信协议。Netty 提供了两个最为常用的编解码抽象基类 MessageToByteEncoder 和 ByteToMessageDecoder,帮助我们很方便地扩展实现自定义协议。
我们接下来要完成的编码器 MiniRpcEncoder 需要继承 MessageToByteEncoder,并重写 encode() 方法,具体实现如下所示:
public class MiniRpcEncoder extends MessageToByteEncoder<MiniRpcProtocol<Object>> {@Overrideprotected void encode(ChannelHandlerContext ctx, MiniRpcProtocol<Object> msg, ByteBuf byteBuf) throws Exception {MsgHeader header = msg.getHeader();byteBuf.writeShort(header.getMagic());byteBuf.writeByte(header.getVersion());byteBuf.writeByte(header.getSerialization());byteBuf.writeByte(header.getMsgType());byteBuf.writeByte(header.getStatus());byteBuf.writeLong(header.getRequestId());RpcSerialization rpcSerialization = SerializationFactory.getRpcSerialization(header.getSerialization());byte[] data = rpcSerialization.serialize(msg.getBody());byteBuf.writeInt(data.length);byteBuf.writeBytes(data);}
}
编码逻辑比较简单,在服务消费者或者服务提供者调用 writeAndFlush() 将数据写给对方前,都已经封装成 MiniRpcRequest 或者 MiniRpcResponse,所以可以采用 MiniRpcProtocol<Object> 作为 MiniRpcEncoder 编码器能够支持的编码类型。
协议解码实现
解码器 MiniRpcDecoder 需要继承 ByteToMessageDecoder,并重写 decode() 方法,具体实现如下所示:
public class MiniRpcDecoder extends ByteToMessageDecoder {@Overridepublic final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {if (in.readableBytes() < ProtocolConstants.HEADER_TOTAL_LEN) {return;}in.markReaderIndex();short magic = in.readShort();if (magic != ProtocolConstants.MAGIC) {throw new IllegalArgumentException("magic number is illegal, " + magic);}byte version = in.readByte();byte serializeType = in.readByte();byte msgType = in.readByte();byte status = in.readByte();long requestId = in.readLong();int dataLength = in.readInt();if (in.readableBytes() < dataLength) {in.resetReaderIndex();return;}byte[] data = new byte[dataLength];in.readBytes(data);MsgType msgTypeEnum = MsgType.findByType(msgType);if (msgTypeEnum == null) {return;}MsgHeader header = new MsgHeader();header.setMagic(magic);header.setVersion(version);header.setSerialization(serializeType);header.setStatus(status);header.setRequestId(requestId);header.setMsgType(msgType);header.setMsgLen(dataLength);RpcSerialization rpcSerialization = SerializationFactory.getRpcSerialization(serializeType);switch (msgTypeEnum) {case REQUEST:MiniRpcRequest request = rpcSerialization.deserialize(data, MiniRpcRequest.class);if (request != null) {MiniRpcProtocol<MiniRpcRequest> protocol = new MiniRpcProtocol<>();protocol.setHeader(header);protocol.setBody(request);out.add(protocol);}case RESPONSE:MiniRpcResponse response = rpcSerialization.deserialize(data, MiniRpcResponse.class);if (response != null) {MiniRpcProtocol<MiniRpcResponse> protocol = new MiniRpcProtocol<>();protocol.setHeader(header);protocol.setBody(response);out.add(protocol);}case HEARTBEAT:// TODObreak;}}
}
解码器 MiniRpcDecoder 相比于编码器 MiniRpcEncoder 要复杂很多,MiniRpcDecoder 的目标是将字节流数据解码为消息对象,并传递给下一个 Inbound 处理器。整个 MiniRpcDecoder 解码过程有几个要点要特别注意:
- 只有当 ByteBuf 中内容大于协议头 Header 的固定的 18 字节时,才开始读取数据。
- 即使已经可以完整读取出协议头 Header,但是协议体 Body 有可能还未就绪。所以在刚开始读取数据时,需要使用 markReaderIndex() 方法标记读指针位置,当 ByteBuf 中可读字节长度小于协议体 Body 的长度时,再使用 resetReaderIndex() 还原读指针位置,说明现在 ByteBuf 中可读字节还不够一个完整的数据包。
- 根据不同的报文类型 MsgType,需要反序列化出不同的协议体对象。在 RPC 请求调用的场景下,服务提供者需要将协议体内容反序列化成 MiniRpcRequest 对象;在 RPC 结果响应的场景下,服务消费者需要将协议体内容反序列化成 MiniRpcResponse 对象。
请求处理与响应
在 RPC 请求调用的场景下,服务提供者的 MiniRpcDecoder 编码器将二进制数据解码成 MiniRpcProtocol<MiniRpcRequest> 对象后,再传递给 RpcRequestHandler 执行 RPC 请求调用。RpcRequestHandler 也是一个 Inbound 处理器,它并不需要承担解码工作,所以 RpcRequestHandler 直接继承 SimpleChannelInboundHandler 即可,然后重写 channelRead0() 方法,具体实现如下:
@Slf4j
public class RpcRequestHandler extends SimpleChannelInboundHandler<MiniRpcProtocol<MiniRpcRequest>> {private final Map<String, Object> rpcServiceMap;public RpcRequestHandler(Map<String, Object> rpcServiceMap) {this.rpcServiceMap = rpcServiceMap;}@Overrideprotected void channelRead0(ChannelHandlerContext ctx, MiniRpcProtocol<MiniRpcRequest> protocol) {RpcRequestProcessor.submitRequest(() -> {MiniRpcProtocol<MiniRpcResponse> resProtocol = new MiniRpcProtocol<>();MiniRpcResponse response = new MiniRpcResponse();MsgHeader header = protocol.getHeader();header.setMsgType((byte) MsgType.RESPONSE.getType());try {Object result = handle(protocol.getBody()); // TODO 调用 RPC 服务response.setData(result);header.setStatus((byte) MsgStatus.SUCCESS.getCode());resProtocol.setHeader(header);resProtocol.setBody(response);} catch (Throwable throwable) {header.setStatus((byte) MsgStatus.FAIL.getCode());response.setMessage(throwable.toString());log.error("process request {} error", header.getRequestId(), throwable);}ctx.writeAndFlush(resProtocol);});}
}
因为 RPC 请求调用是比较耗时的,所以比较推荐的做法是将 RPC 请求提交到自定义的业务线程池中执行。其中 handle() 方法是真正执行 RPC 调用的地方,你可以先留一个空的实现,在之后动态代理的课程中我们再完成它。根据 handle() 的执行情况,MiniRpcProtocol<MiniRpcResponse> 最终会被设置成功或者失败的状态,以及相应的请求结果或者错误信息,最终通过 writeAndFlush() 方法将数据写回服务消费者。
上文中我们已经分析了服务消费者入站操作,首先要经过 MiniRpcDecoder 解码器,根据报文类型 msgType 解码出 MiniRpcProtocol<MiniRpcResponse> 响应结果,然后传递给 RpcResponseHandler 处理器,RpcResponseHandler 负责响应不同线程的请求结果,具体实现如下:
public class RpcResponseHandler extends SimpleChannelInboundHandler<MiniRpcProtocol<MiniRpcResponse>> {@Overrideprotected void channelRead0(ChannelHandlerContext ctx, MiniRpcProtocol<MiniRpcResponse> msg) {long requestId = msg.getHeader().getRequestId();MiniRpcFuture<MiniRpcResponse> future = MiniRpcRequestHolder.REQUEST_MAP.remove(requestId);future.getPromise().setSuccess(msg.getBody());}
}
public class MiniRpcRequestHolder {public final static AtomicLong REQUEST_ID_GEN = new AtomicLong(0);public static final Map<Long, MiniRpcFuture<MiniRpcResponse>> REQUEST_MAP = new ConcurrentHashMap<>();
}
@Data
public class MiniRpcFuture<T> {private Promise<T> promise;private long timeout;public MiniRpcFuture(Promise<T> promise, long timeout) {this.promise = promise;this.timeout = timeout;}
}
服务消费者在发起调用时,维护了请求 requestId 和 MiniRpcFuture<MiniRpcResponse> 的映射关系,RpcResponseHandler 会根据请求的 requestId 找到对应发起调用的 MiniRpcFuture,然后为 MiniRpcFuture 设置响应结果。
我们采用 Netty 提供的 Promise 工具来实现 RPC 请求的同步等待,Promise 基于 JDK 的 Future 扩展了更多新的特性,帮助我们更好地以同步的方式进行异步编程。Promise 模式本质是一种异步编程模型,我们可以先拿到一个查看任务执行结果的凭证,不必等待任务执行完毕,当我们需要获取任务执行结果时,再使用凭证提供的相关接口进行获取。
至此,RPC 框架的通信模块我们已经实现完了。自定义协议、编解码、序列化/反序列化都是实现远程通信的必备基础知识,我们务必要熟练掌握。此外在《架构设计:如何实现一个高性能分布式 RPC 框架》课程中,我们介绍了 RPC 调用的多种方式,快开动你的大脑,想想其他方式应当如何实现呢?
总结
本节课我们通过 RPC 自定义协议的设计与实现,加深了对 Netty 自定义处理器 ChannelHandler 的理解。ChannelPipeline 和 ChannelHandler 是我们在项目开发过程中打交道最多的组件,在设计之初一定要梳理清楚 Inbound 和 Outbound 处理的传递顺序,以及数据模型之间是如何转换的。