HeZaoCha-CSDN博客
序章—软工版
- 一、环境介绍
- 1. VMware Workstation Pro
- 2. CentOS
- 3. Java
- 4. Hadoop
- 5. HBase
- 6. MySQL
- 7. Hive
- 二、系统安装
- 1. 虚拟网络编辑器
- 2. 操作系统安装
- 三、结尾
先说说哥们写这系列博客的原因,本来学完咱也没想着再管部署这部分问题的说,毕竟
Linux 的发行版太多了,有的可能不存在一些儿个问题,而且系统配置上的不同也导致了这边不一定会存在有大家可能存在的问题,但是刚好俺女朋友刚好这学期开了这门课,由于各种各样的原因,深思熟虑之下,最终还是决定写这么几篇博客来帮助一下各位上课的伙伴们(尽量不要让我帮各位兄弟姐妹干啦,最近配环境配麻了)。
这边咱先叠个甲,不定期更新,不一定适配所有人;要是这些博客无法解决您的问题,哥们大可以通过博客评论或者私信或者联系老师或者联系朋友联系到我,我还是很乐意帮助大家解决问题的;若是各位兄弟姐妹有认识我的,觉得这些博客能够帮上一点小忙的,然后小生又有幸认识到各位家人的,能否有空请我喝一杯奶茶,请我吃顿外卖,在下感激不尽。
一、环境介绍
下面进入正文,我们采用 VMware Workstation,如果有使用 Mac 的朋友们,可以参考一下macOS 安装Hadoop教程—单机—伪分布式配置_厦大数据库实验室博客 (xmu.edu.cn)这篇推文,咱这就不过多赘述了,办法总比困难多嘛;如果各位家里有条件想要自定义装机的,可以稍微参照一下这篇,然后后续可以进行自定义选配,当然咱这叠个甲,要是不会弄的话,还是不要头铁的好,小生是过来人。下面会有大家可能用到的一些软件的一点点介绍,如果大家觉得没用可以跳过,有兴趣的朋友可以自己看一下。
1. VMware Workstation Pro
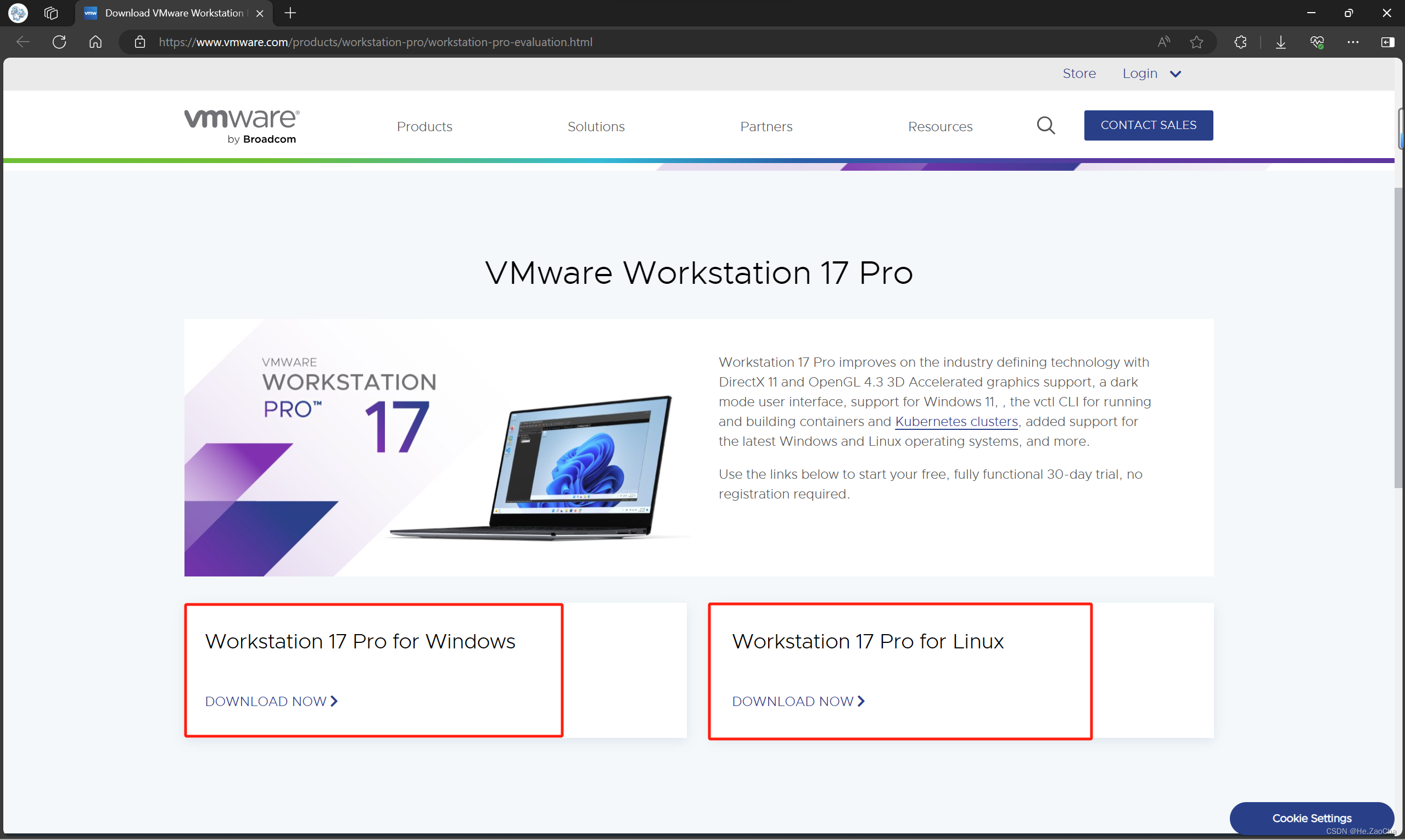
VMware 版本多少其实不是很影响,我这边是 17,大家上课应该是 15,但差别是不大的,17 可向下兼容,15 不可向上兼容,各位可以使用老师的安装包,也可以使用小生下方的连接进行下载。
VMware 版本:VMware® Workstation 17 Pro
下载链接:这里的版本是指各位电脑本身的系统,不是要安装的
CentOS的系统(各位,我说清楚了嘛,不清楚可以再问问是吧)。
- Windows 版:Workstation 17 Pro for Windows
- Linux 版:Workstation 17 Pro for Linux
官网链接:Download VMware Workstation Pro
2. CentOS
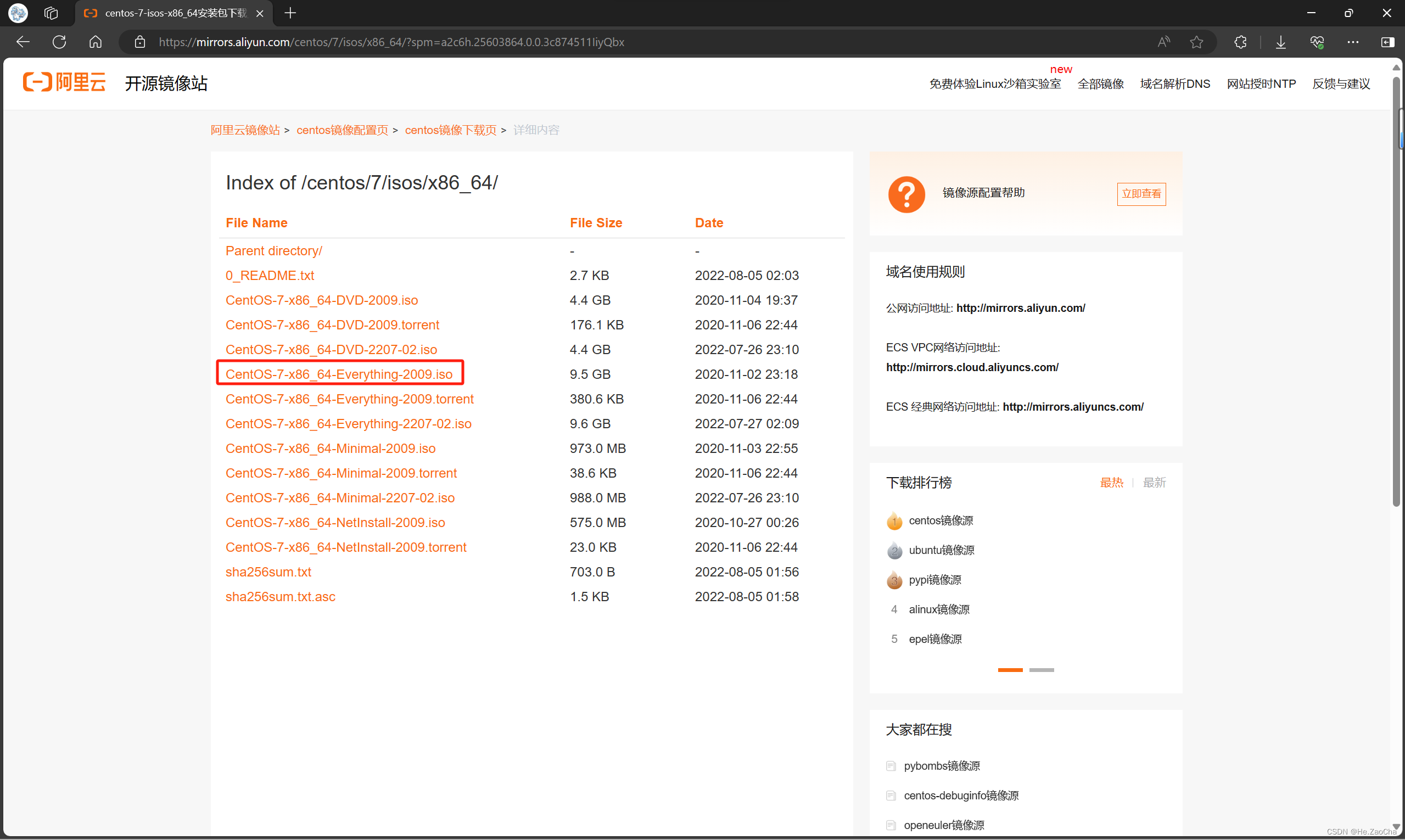
镜像本来想采用的是 CentOS—7—x86_64—Minimal—2009.iso,后面发现老师选用的版本有图形化界面,故不得不采用 CentOS—7—x86_64—Everything—2009.iso,为了更加适配大家的学习,故小生选择了后者。这俩大概的差别就是,前者是最小化安装,优点是整张碟占用空间小,总占 1G,缺点是需要自定义下载配置的地方太多,图形化界面需要自己下载,不能在安装系统的时候带上,如果大家有兴趣可以去点这儿第一篇——大数据环境部署前置条件看看小生用该 Minimal 镜像配置的博客,当然当年写的没那么全面,希望大家多多包涵;后者是全部都合在一起,在安装的时候可以自定义选配,缺点是整张碟太大了,总占 9G。
当然这俩差别在各位的学习使用中我认为问题不大,后续安装会进行一定的选择,有兴趣的朋友们可以自行了解,这里不展开,但是 CentOS 7 生命周期快到了,准备不维护了,在 2024 年年中就会停止维护了,不建议深入学习了,当个跳板可以。
小生认为,以后是 Ubuntu 的天下了,但小生头铁,偏爱 Debian,有兴趣的朋友,真的建议学一学,以后真的没有人会在 Windows 进行开发了,千万不要觉得学前端设计学的好就好了,也不要觉得后端会写代码就好了,小生还是希望大家多了解一些东西,能力全面的人是任何公司都爱的。
别的不多说,如果大家考研,这点东西都不会,复试的老师是不会让大家过的,小生言尽于此,衷心希望大家考研过过过!!!
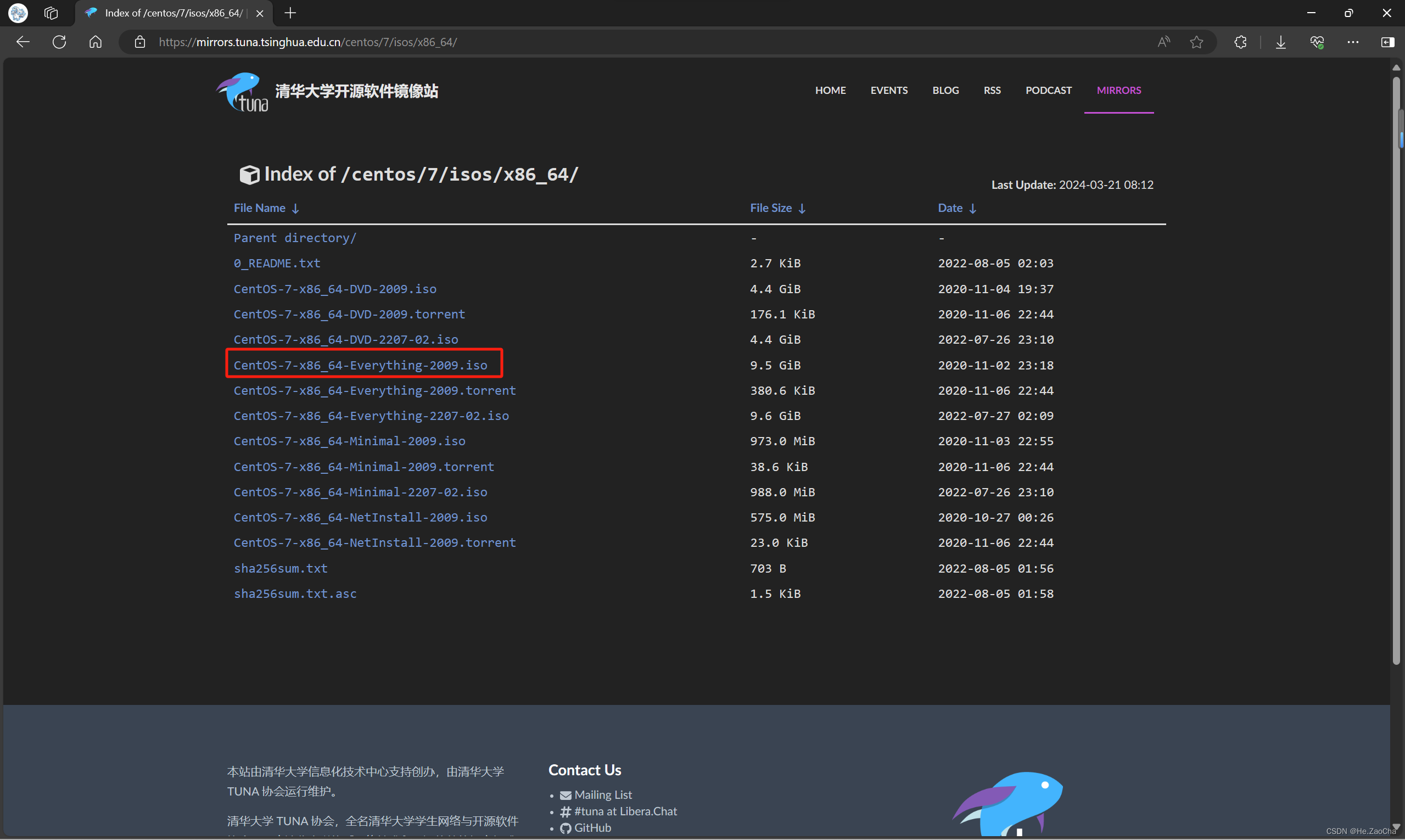
镜像选择:CentOS—7—x86_64—Everything—2009.iso
下载链接:
- 阿里源: CentOS—7—x86_64—Everything—2009.iso (aliyun.com)
- 清华源:CentOS—7—x86_64—Everything—2009.iso (tsinghua.edu.cn)
官网链接:
阿里开源镜像站:centos—7—isos—x86_64安装包下载_开源镜像站—阿里云 (aliyun.com)
清华开源镜像站:Index of /centos/7/isos/x86_64/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
3. Java
jdk 这里采用甲骨文公司的 Java 8,当然这个版本问题在我看来其实不会太影响,想用 Java 11、Java 17、Java 21 在理论上也可以的,但是建议各位为了后续的学习不出问题,尽量选择 LTS(长期支持) 版,短期支持版像18、19、20 虽然也不是不能用,但毕竟维护时间太短了,不建议大家使用,当然各位肯定比我更清楚,毕竟小生主 Python 开发,Java 学的也不怎样,这边我们选择下载的是 jdk—8u401—linux—x64.tar.gz,没有太大的说法,其实因为大家学的是 CentOS,下载 jdk—8u401—linux—x64.rpm,看起来会更省心一些,还不用自己添加环境变量,简直是省大事情,插个眼,要是小生时间足够,就两个都会给大家写一下,纯作了解。最后说一下,不用太担心老师给的是 jdk—8u162—linux—x64.tar.gz,这个会不会有问题之类的,在我看来,一点问题没有,所以大家不用担心,这个方法是通用的,小生也会尽量给大家用通用的办法去写的,所以大家不用担心,当然如果要跟着小生下载的,可以看看下面,然后下载的时候需要注册一个甲骨文的账户,嫌麻烦的话,建议大家还是用老师的包。
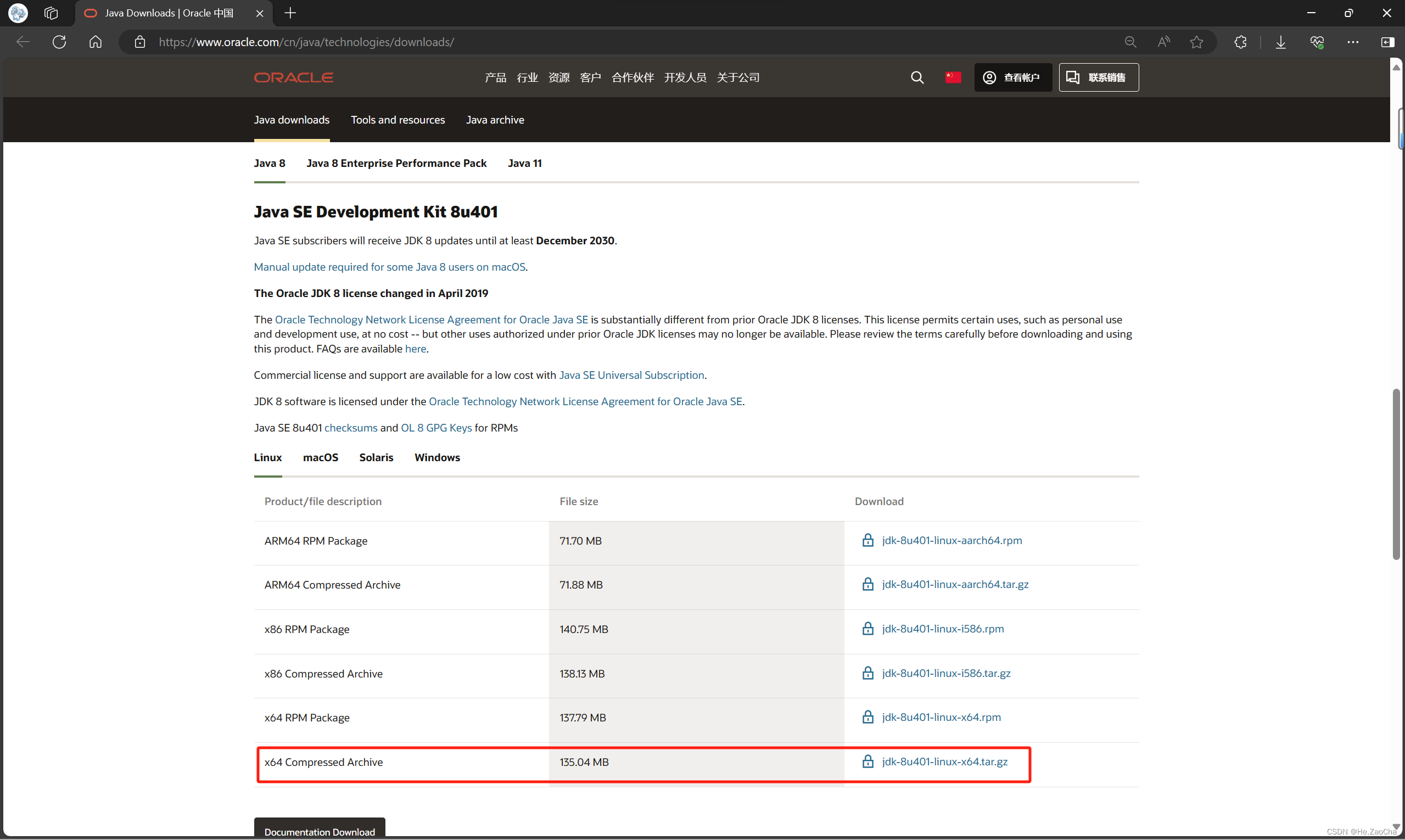
Java 安装包选择:jdk—8u401—linux—x64.tar.gz
下载链接:Java Downloads | Oracle 中国
4. Hadoop
Hadoop 小生选用的是 hadoop—3.3.6 的版本,在小生看来,Hadoop 3以上的版本基本都没有太大的差别,可能会有一点不同的地方,但是总结大差不差;有兴趣深入学习的可以点这儿Hadoop – Apache Hadoop 3.1.3找到老师发的 hadoop—3.1.3 的官方文档进行学习,后续配置也会根据官方文档给出的配置文档范例进行配置;如果是跟小生使用 3.3.6 的版本,则可以点这儿Hadoop – Apache Hadoop 3.3.6找到官网文档;如果还需要其他版本的文档,可以点这儿Index of /docs (apache.org)找到。
Hadoop 的配置涉及到三种模式,单机模式、伪分布模式、完全分布模式,单机和伪分布模式只需要一台机器开一台或多台虚拟机即可实现,而完全分布模式则是需要真实拥有多台机器进行连接;其中小生认为伪分布模式与完全分布模式差别不算是特别大,这里小生推荐大家跟着老师参考这篇:Hadoop安装教程—伪分布式配置—CentOS6.4/Hadoop2.6.0—厦大数据库实验室博客 (xmu.edu.cn)博客进行学习,当然小生并不是说照抄就可以了,这篇博客只有参考作用,喜欢自定义的有兴趣的同学可以自行深入摸索。
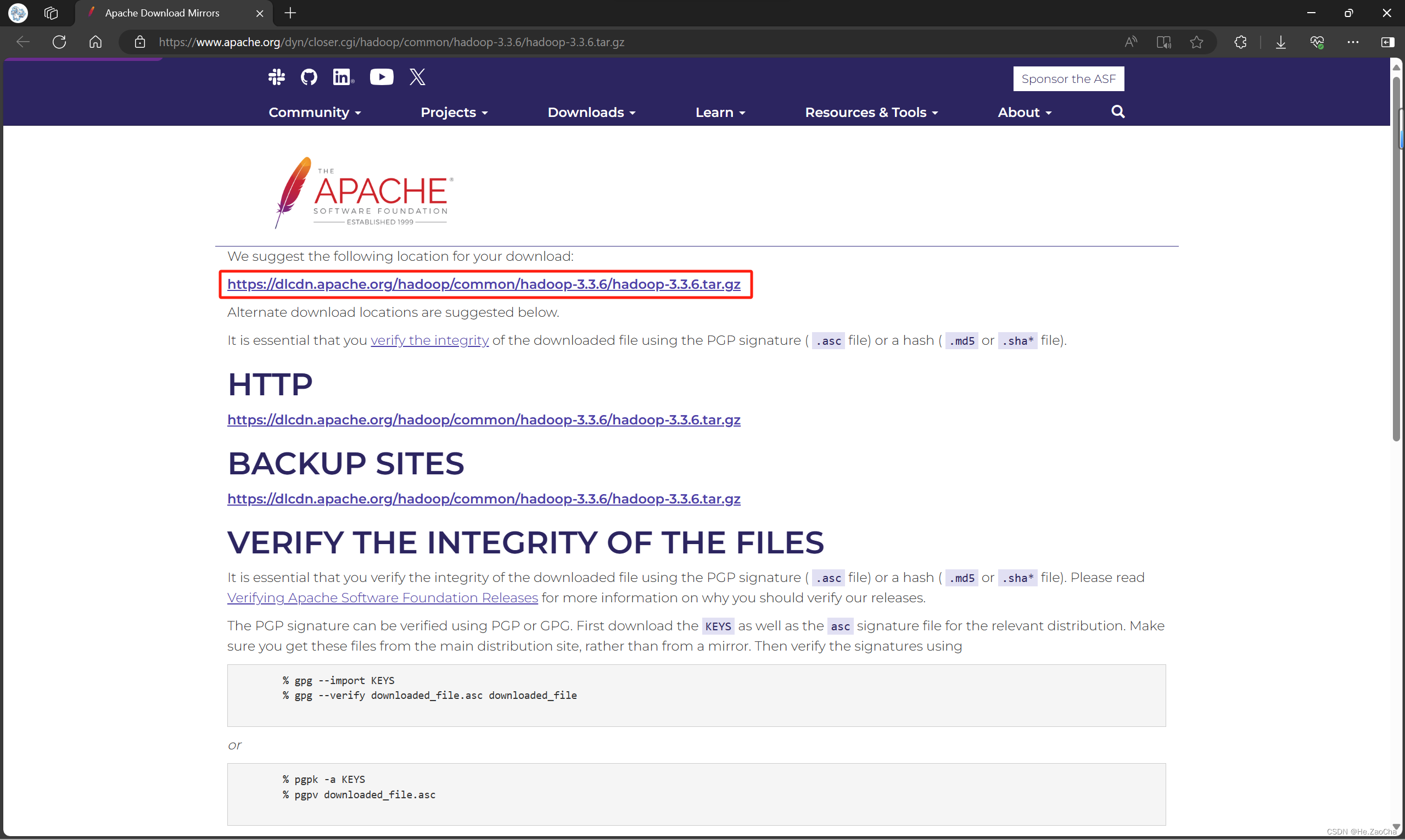
Hadoop 安装包选择:hadoop—3.3.6.tar.gz
下载链接:hadoop—3.3.6.tar.gz
5. HBase
HBase 咱这选择的是 hbase—2.4.17,课程时间不长,所以咱这也不知道各位选取的是哪一个版本,但理论上是 2.1.x ~ 2.4.x 的版本;问题不大,大概的都差不多,但是 HBase 依赖于 Hadoop ,所以会有一定的版本对应关系,下面是一些版本的对应关系,但不一定涵盖完全,所以如果各位有想法深入了解,可以点这儿Apache HBase ™ Reference Guide查看官方文档进行学习。
✓:代表经过测试,功能齐全
✕:已知功能不全,或者存在CVE,因此我们在较新的次要版本中放弃支持
— :不适配
| HBase—2.0.x | HBase—2.1.x | HBase—2.2.x | HBase—2.3.x | HBase—2.4.x | HBase—2.5.x | |
|---|---|---|---|---|---|---|
| Hadoop—3.1.3 | ✕ | ✓ | ✓ | ✓ | ✓ | ✕ |
| Hadoop—3.3.6 | — | — | — | ✓ | ✓ | ✓ |
根据上表,我们就很清楚我们会用到的版本依赖关系。当然,HBase 不止依赖 Hadoop,还会有 jdk 的版本依赖,请看下表:
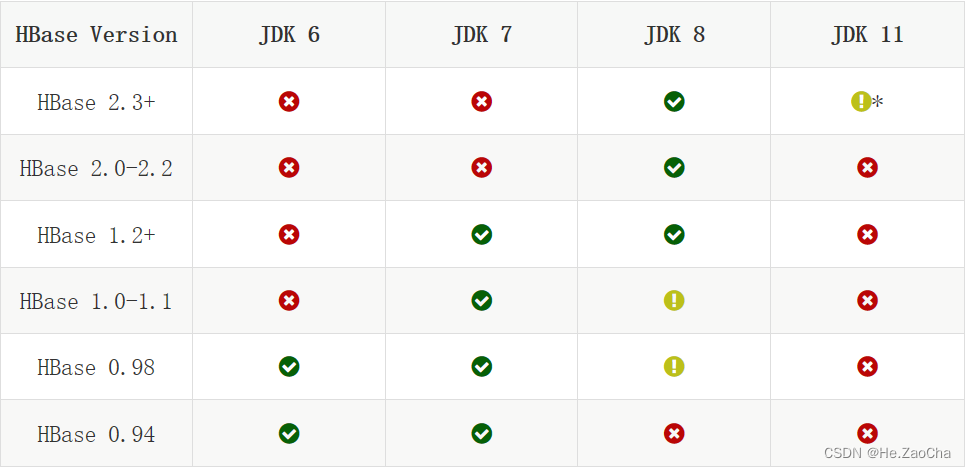
当然,大家所使用的 jdk8 肯定是没有问题的,所以放心好了,这个当做了解而已。下面附上链接,当然用老师的也可以,作为探索,我就不用老师的版本了,其实都一样的,不用担心兼容问题,有问题私信小生,小生再帮大家解决。
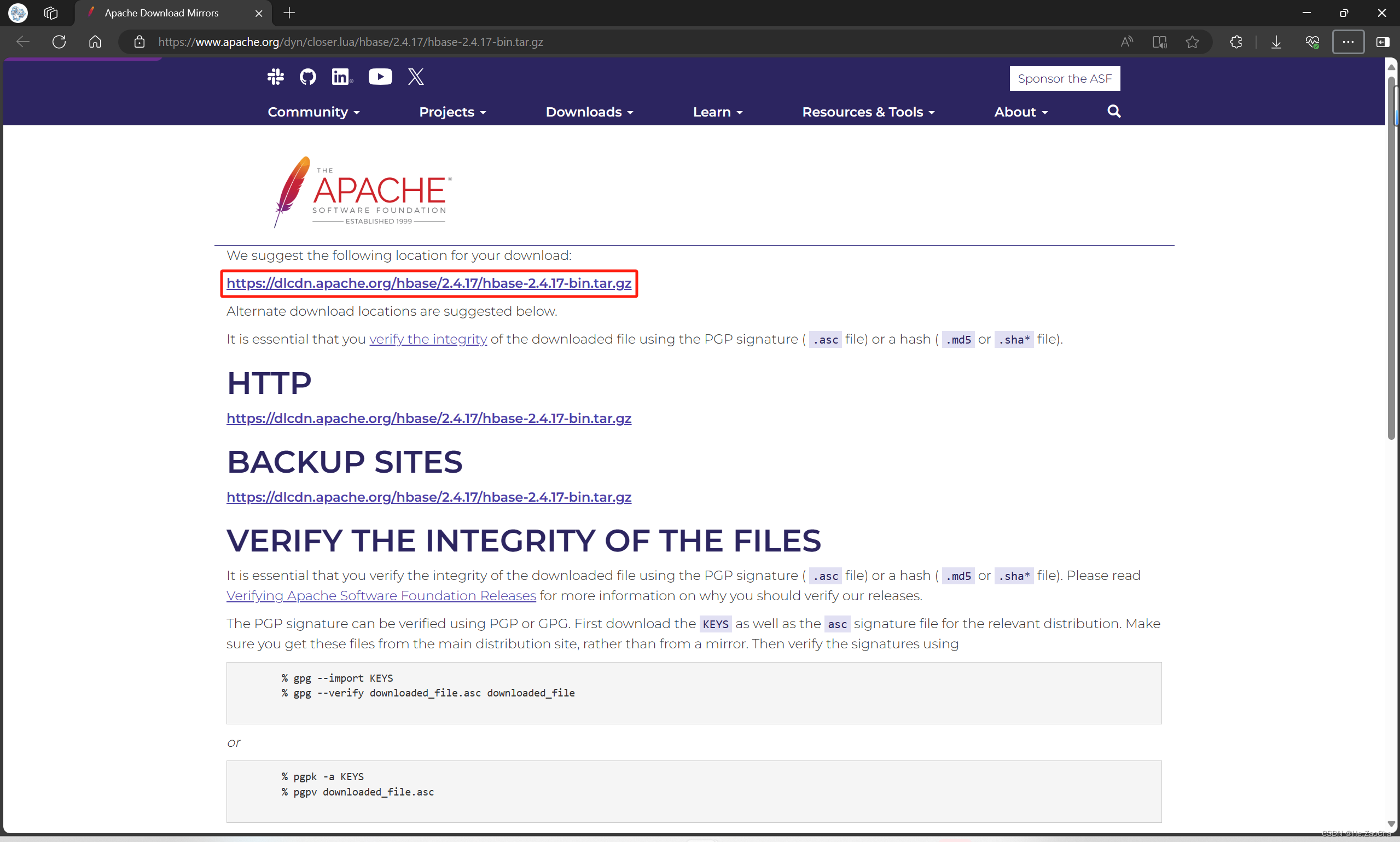
HBase 安装包选择:hbase-2.4.17-bin.tar.gz
下载链接:hbase-2.4.17-bin.tar.gz
6. MySQL
本来应该是用不到 Mysql 的,但是由于 Hive 只是一个架构,需要建设在实体的数据库上边,而 HBase 各位同学后续也不会真正接触,所以这边需要将 Hive 架设到 MySQL 数据库上。这里选择安装的是 MySQL 8,各位同学如果想安装 MySQL 5 版的也可以参考 MySQL 8 的安装方式。MySQL 文档众多,这里就不一一列举了,想要查看的可以点击MySQL :: MySQL Documentation查看官方文档。
MySQL 没有特别的依赖说明,安装方式也很简单,鉴于大家在先前的学习中已经有过接触,这里也不过多赘述。为了大家的方便,我们就不选择在线安装的方式了,我们直接下载所有的离线包进行安装,为了简便一些,我们选择全部组件都进行安装,如果有想要了解各个组件的作用进行适当的选装的朋友们,可以自行查阅官方文档内容进行选择。
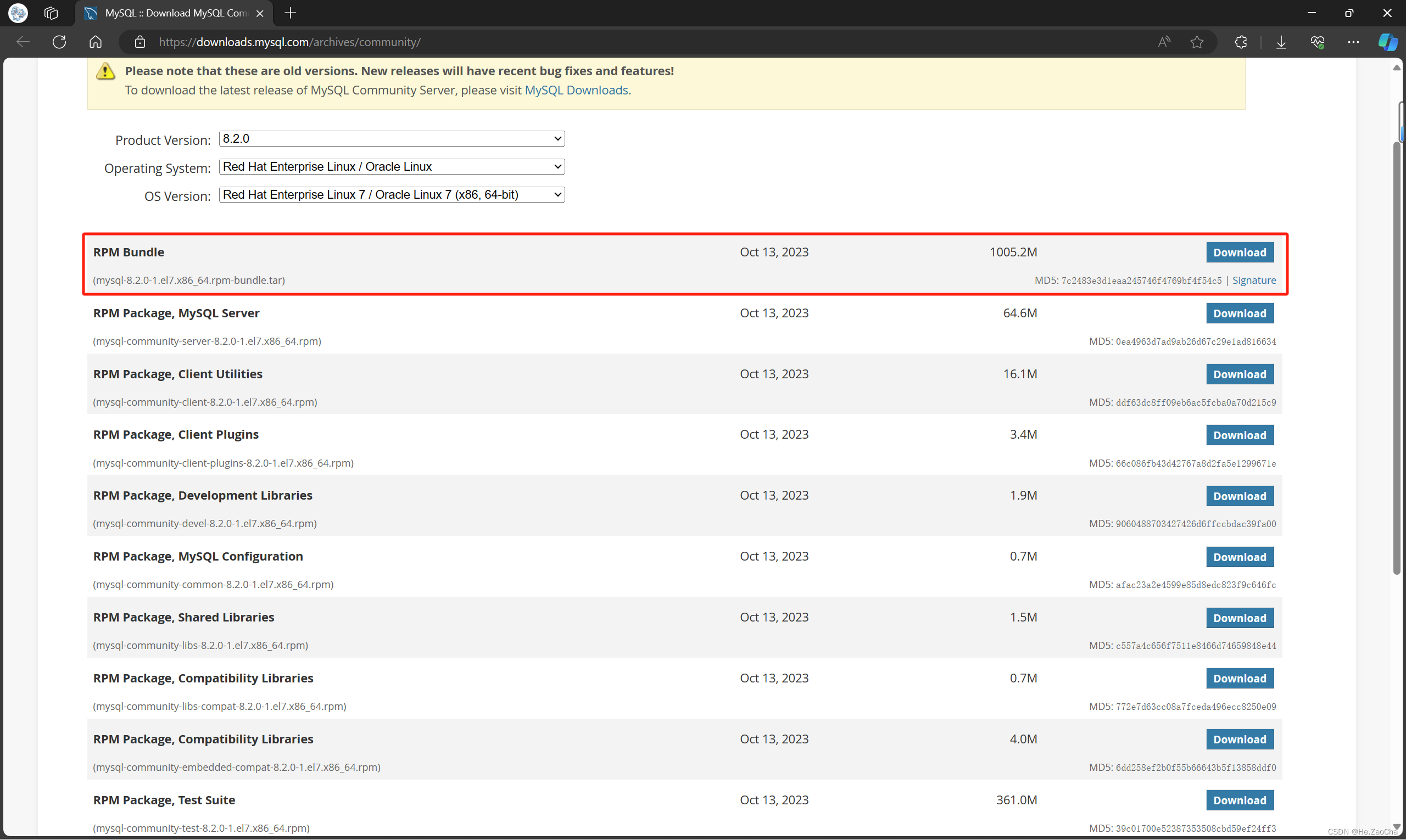
MySQL 安装包选择:mysql-8.2.0-1.el7.x86_64.rpm-bundle.tar
下载链接:mysql-8.2.0-1.el7 .x86_64.rpm-bundle.tar
7. Hive
Hive 这边,我选用的是 Hive-3.1.3,Hive 与 Hadoop 也有一定的依赖关系,各位可以通过下载并解压缩包来安装Hive的稳定版本,也可以下载源代码并使用 Maven(0.13版及更高版本)或 Ant(0.12版及更早版本)构建Hive,鉴于大家并不是特别需要懂源码编译安装,所以这边选择稳定版本的安装就可以,如果有想深入了解安装配置等的可以选择点这儿Home - Apache Hive - Apache Software Foundation查看 Hive 的文档。
以下是一定的依赖关系说明:
- Java 版本选择:Java 1.7(首选)
注意:Hive 1.2版本以上需要Java 1.7或更高版本。Hive版本0.14到1.1可以与Java 1.6兼容,但更喜欢1.7。强烈建议用户开始迁移到Java 1.8(参见HIVE-8607)。- Hadoop 版本选择:Hadoop 2.x(首选),1.x(不受Hive 2.0.0以上版本支持)。
Hive 0.13之前的版本也支持Hadoop 0.20.x、0.23.x。- Hive通常用于生产Linux和Windows环境。Mac是一种常用的开发环境。本文档中的说明适用于Linux和Mac。在Windows上使用它需要稍微不同的步骤。
| Hive 3.0.0 | Hive 3.1.x | Hive 4.0.0-alpha-1 | Hive release 4.0.0-alpha-2 | |
|---|---|---|---|---|
| Hadoop 3.x.y | ✓ | ✓ | ✓ | ✕ |
上面的依赖关系仅仅是列出了有限的一部分,邮箱深入了解的可以自行学习,这里就不一一列举了。
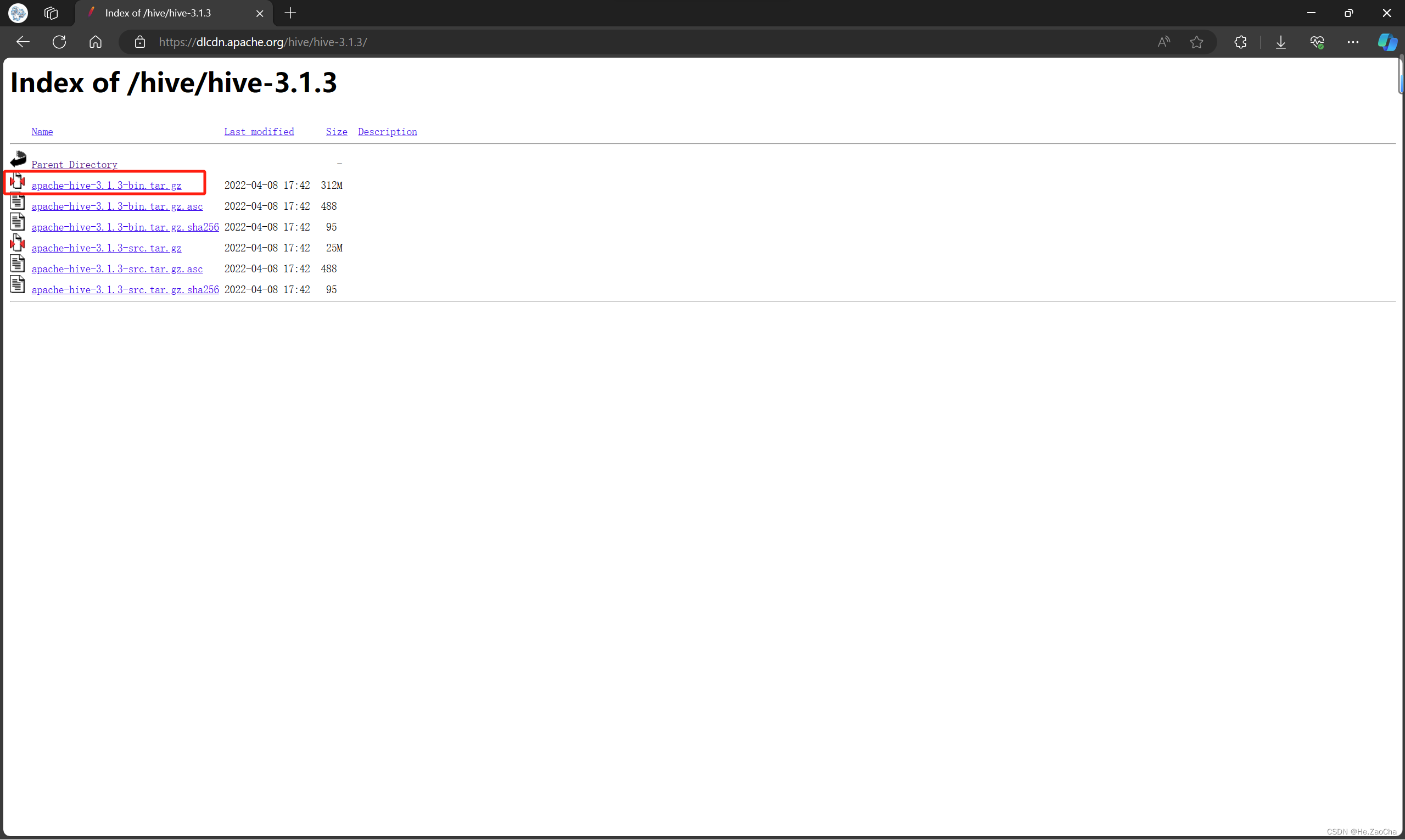
Hive 安装包选择:apache-hive-3.1.3-bin.tar.gz
下载链接:apache-hive-3.1.3-bin.tar.gz
二、系统安装
安装 VMware 的部分,在下就不在这里过多赘述了,大家根据提示下载安装好即可,当然安装完后也可能会有其他问题,在这部分我尽量对目前我已知的问题进行一些说明,希望能帮助大家解决一些简单的配置上的问题。
1. 虚拟网络编辑器
用于 Workstation Pro 提供桥接模式网络连接、网络地址转换 (NAT)、仅主机模式网络连接和自定义网络连接选项,用于为虚拟机配置虚拟网络连接。在安装 Workstation Pro 时,已在主机系统中安装用于所有网络连接配置的软件,想深入了解的可以到VMware Workstation Pro 文档查看官方文档。
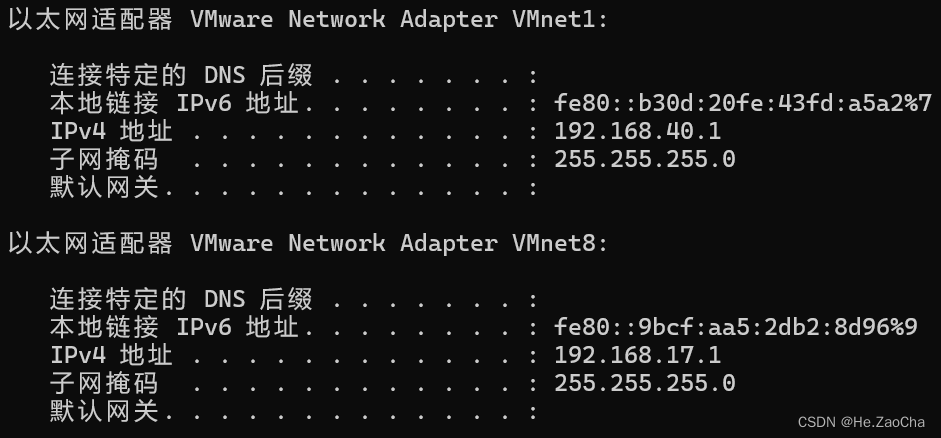
提到这个部件是因为在 Workstation Pro 的网络配置中会有三种模式,桥接模式、NAT模式和仅主机模式,这三种模式都有一定的区别,他们将会在系统创建两个以太网适配器(如下图所示),如果大家计算机网络还有印象,应该知道以太网适配器是计算机中的硬件设备,也称为网络接口卡(Network Interface Card,NIC)。它的主要作用是使计算机能够连接到局域网(LAN)或广域网(WAN),并通过以太网协议进行通信。简单来说,如果没有它,那么计算机之间将不能进行通信,就是断网了。
其中我们可能会用到的是桥接模式和NAT模式,通过下表,大家可以了解一下它们的作用:
| 选项 | 说明 |
|---|---|
| 桥接模式 | 通过使用主机系统上的网络适配器将虚拟机连接到网络。虚拟机在网络中具有唯一标识,与主机系统相分离,且与主机系统无关。 |
| NAT | 虚拟机和主机系统共享一个网络标识,此标识在外部网络中不可见。当虚拟机发送请求以访问网络资源时,它会充当网络资源,就像请求来自主机系统一样。 |
这个我们不详细说明,大家稍微有点了解即可,有兴趣的同学可以自行学习。
写这么多,只是希望大家能确保这两个以太网适配器存在且可用,否则将无法进行后续的学习和操作!!!
- 打开 VMware Workstation,请大家点击
编辑(E) --> 虚拟网络编辑器(N)
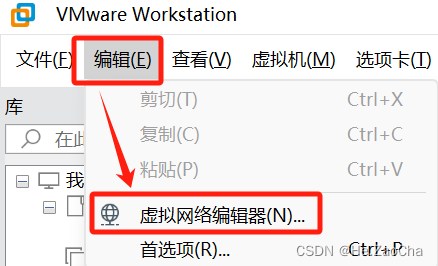
-
打开后,请大家点击
更改设置(C)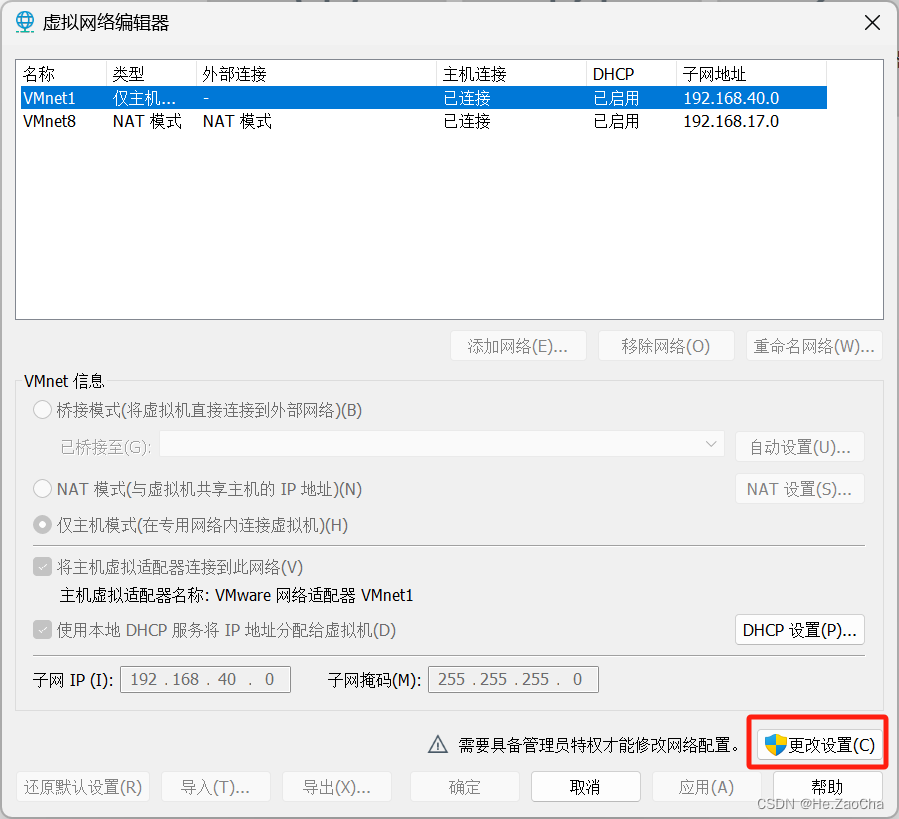
-
然后可以看见出现了三种网络模式的选项,我们需要分别点击
VMnet1和VMnet8,并且确保下方红色框中的内容已被勾选,这样可以确保上述提到的两个以太网适配器存在且可用。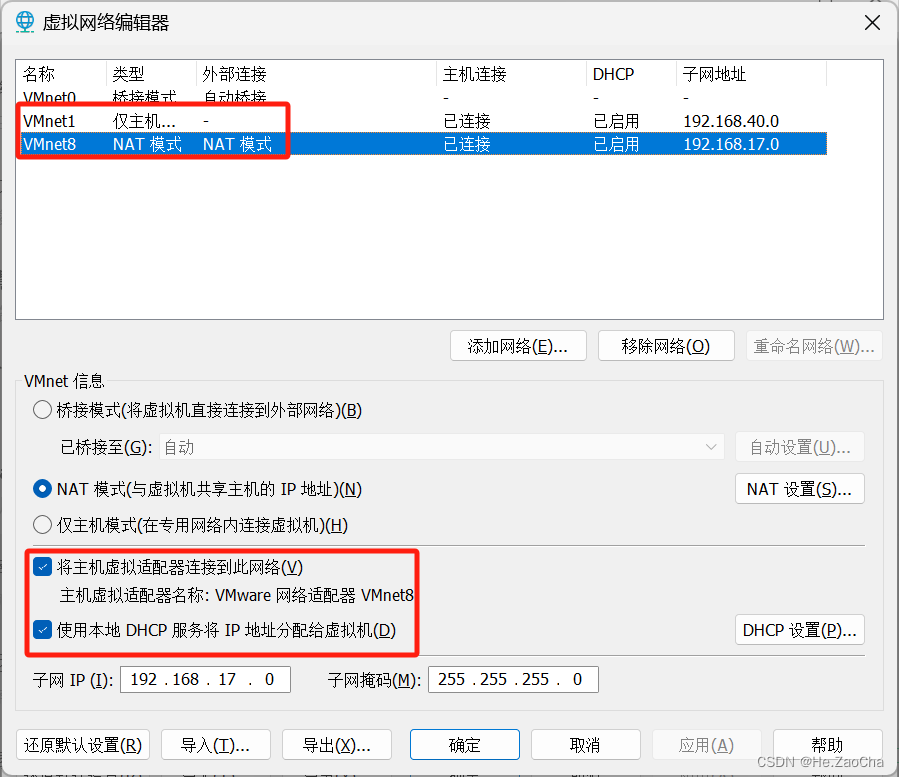
2. 操作系统安装
这部分将会给大家讲解操作系统安装的一些细节,纯属个人见解,只能保证大家能顺利渡过这门课程,不能保证大家工作生活自定义的时候不会产生冲突,这里先叠个甲。
-
打开 VMware Workstation,点击
创建新的虚拟机,或者使用快捷键Ctrl + N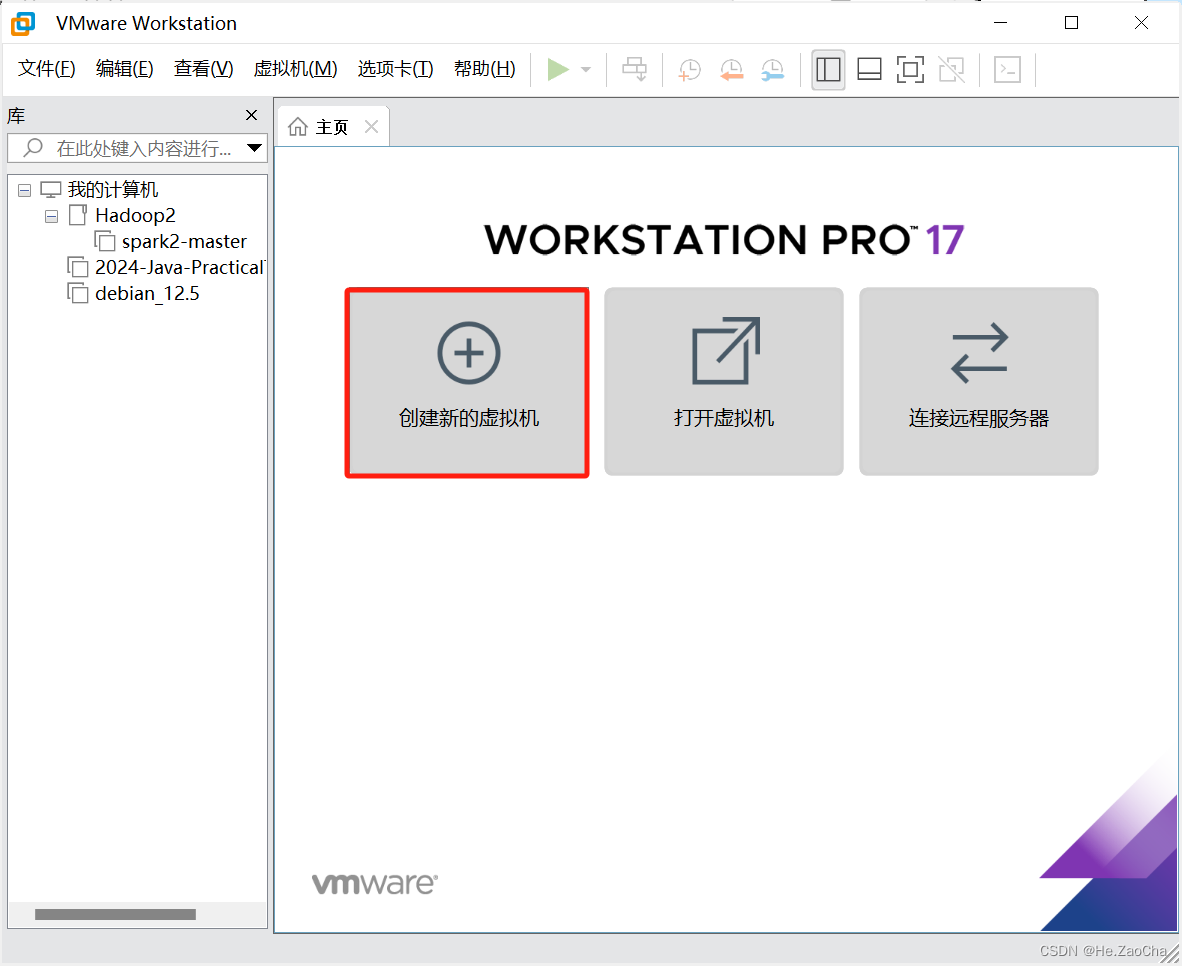
-
为了保证我们见到的东西都差不多,所以请大家选择
自定义(高级)(C) --> 下一步(N)>,选择典型(推荐)(T)会让大家省很多事情,但是为了保证大家以后售后简单一些,这边还是选择自定义安装。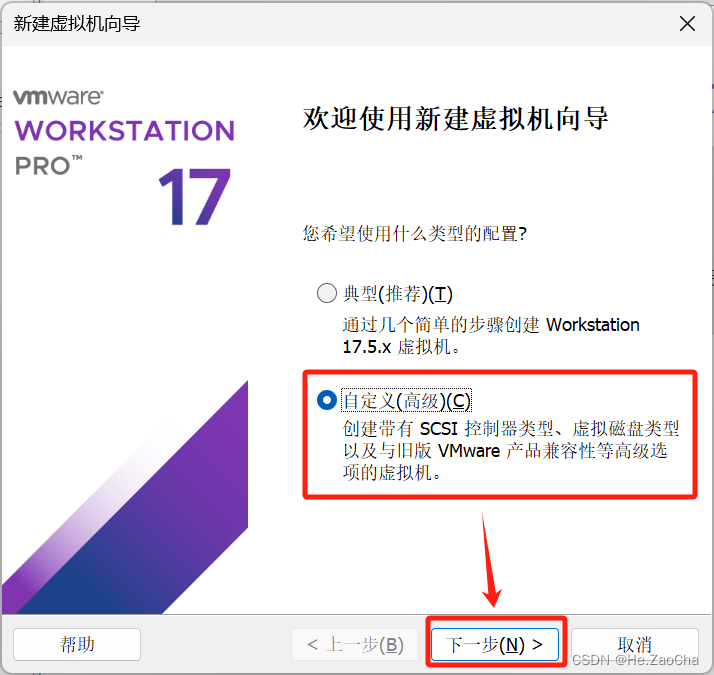
-
硬件的兼容性大家可以不用管,无论是 15 还是 17 都不重要,反正虚拟机只在你的电脑上运行,又不用拿到别人那里,所以没有关系的,如果需要移动虚拟机到其他电脑上,可以根据两台电脑中 VMware Workstation 的版本,选择较低版本的进行兼容,左边的
兼容产品栏会显示可兼容的版本号(注意选择较低的版本进行兼容)。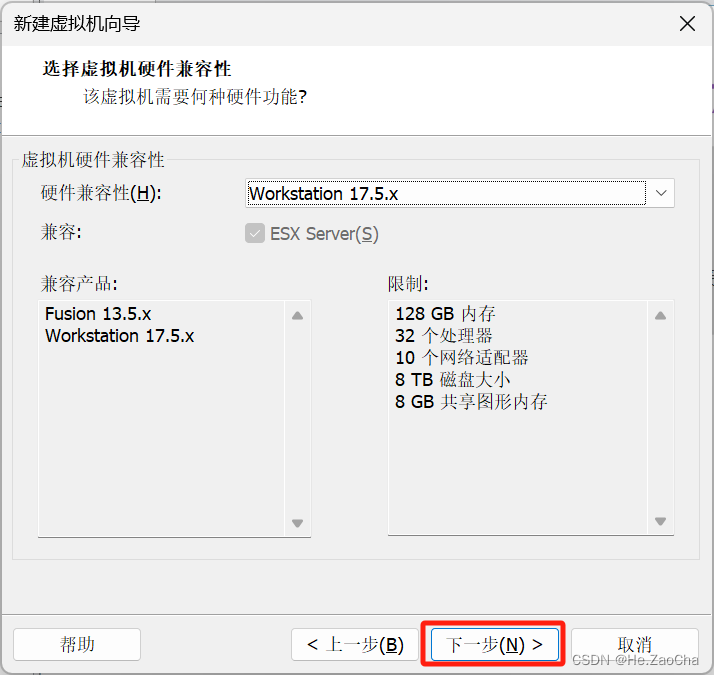
-
接下来各位的各种出现的顺序不能保证,我只能根据我这边的顺序给大家写,大家如果发现图对不上,可以往下面翻一翻,会有一样的;如果没有,又拿不定主意的可以私信我或者私信老师或者查找搜索引擎寻找一定的办法。这里需要大家选择
稍后安装操作系统(S),如果大家打开了变成驱动光盘了,请选择第一个安装程序光盘(D),也不是说打开了不能选择其他两种方式安装,大家自己看着来就好,然后就可以点击下一步(N)>。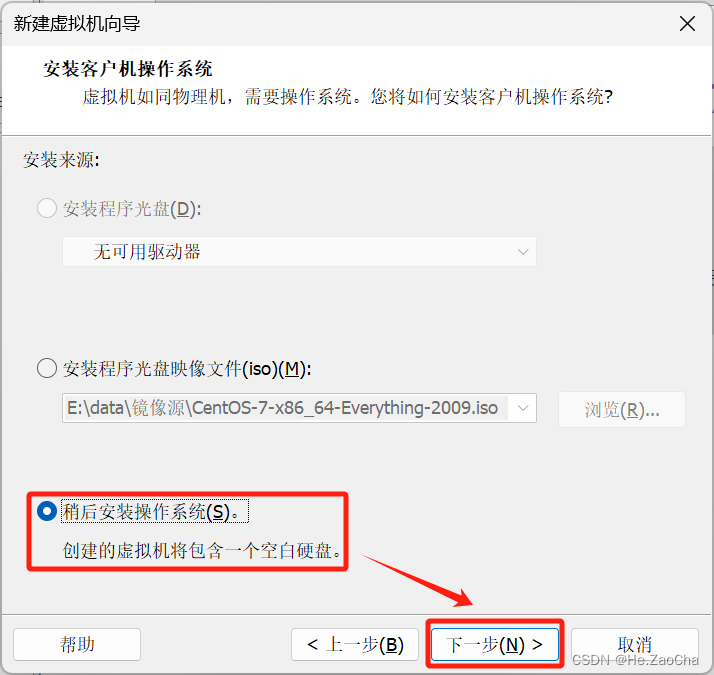
-
到这里我们需要选择操作系统,
CentOS 7是 Linux 的其中一个发行版,也就是俗称的分支,所以这里我们选择Linux(L),在版本上,我们选择是CentOS 7 64 位,现在的个人 PC 机器的芯片架构一般都是X86_64,所以我们选择的是 64 位的操作系统,具体可以到系统配置中查看自己的 CPU 是多少位的,现在已经很少见 32 位的了,最后点击下一步(N)>。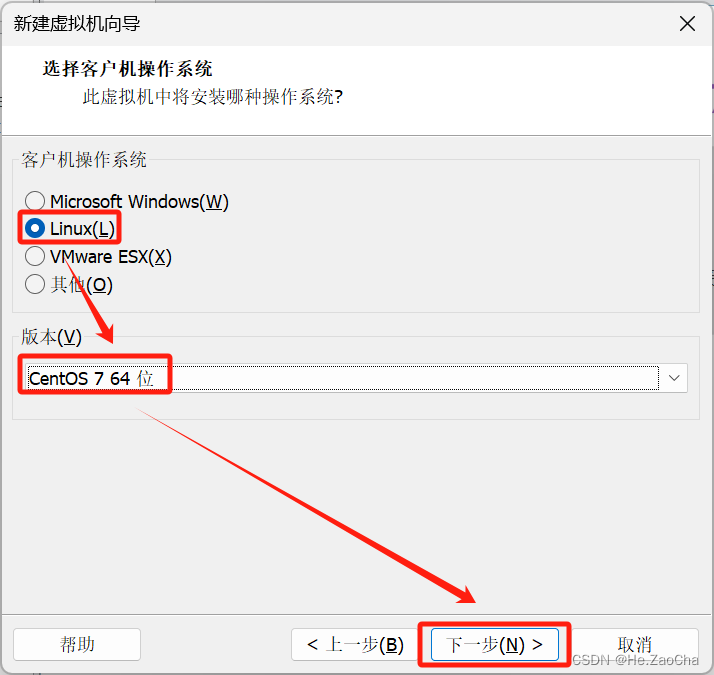
-
这部分是为你的虚拟机命名以及选择虚拟机文件存储在计算机中的位置,名称并不是虚拟机里面的主机名,而是一个标记的名称,只要自己能够认出来即可;再次提醒!!!不是虚拟机的主机名,只是一个普通的名称而已,都选择好之后就可以点击
下一步(N)>。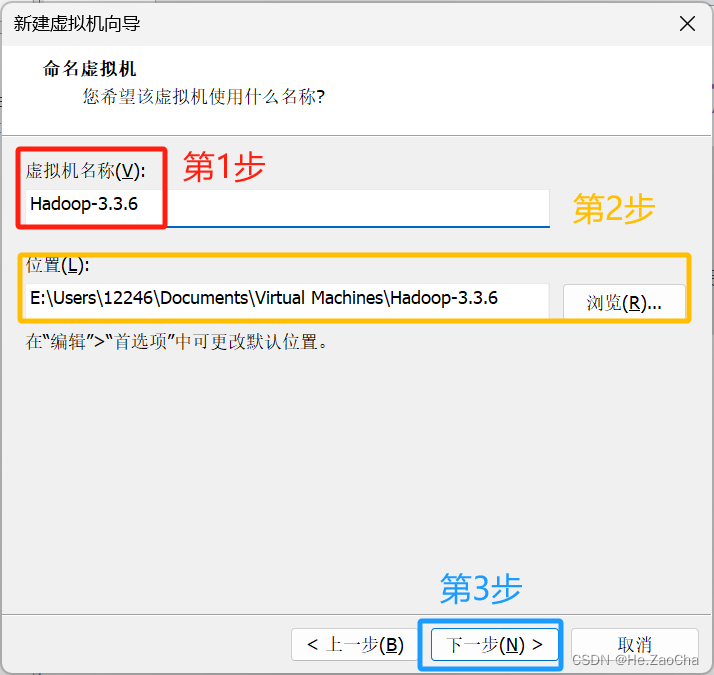
-
这部分需要选择分配给虚拟机的处理器个数以及每个处理器中的内核个数;这部分我想了好一会,还是决定给大家讲清楚一些,这里我们尽量简单一些,只关注最后的数字,也就是
处理器的内核总数,计算方式就是 处理器的数量 × 每个处理器的内核数量 = 处理器的内核总数 处理器的数量 × 每个处理器的内核数量 = 处理器的内核总数 处理器的数量×每个处理器的内核数量=处理器的内核总数;这里各位在安装的时候尽量保证处理器的内核总数不要超过 本机 C P U 内核总数的 2 3 本机 CPU 内核总数的 \frac{2}{3} 本机CPU内核总数的32即可;这里以Windows 11 为例,使用快捷键Win + i打开控制面板,找到系统 --> 系统信息,在设备规格中我们可以找到处理器型号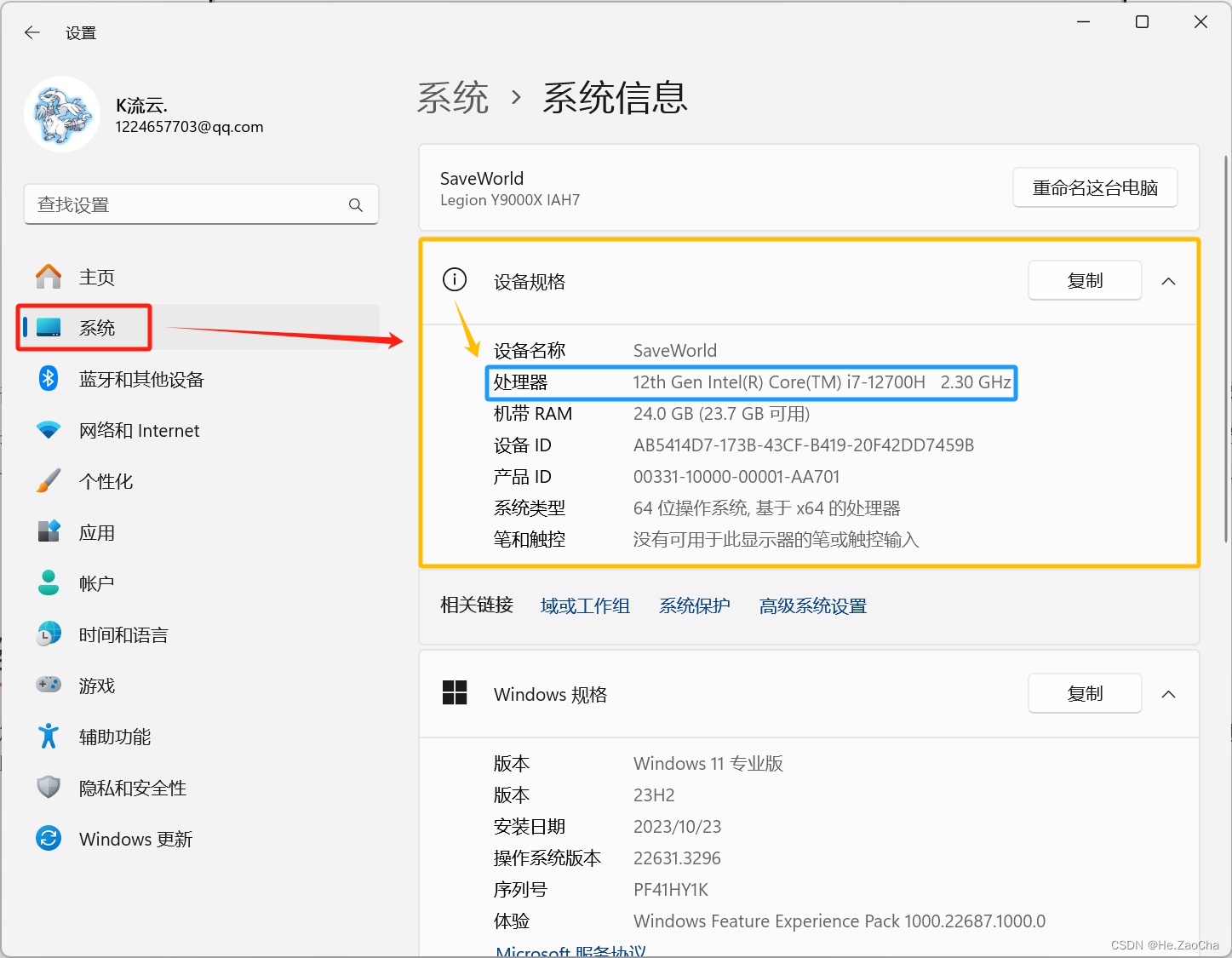
然后需要复制处理器的型号并且上网处理器的信息,这里可以清楚找到 CPU 的内核总数
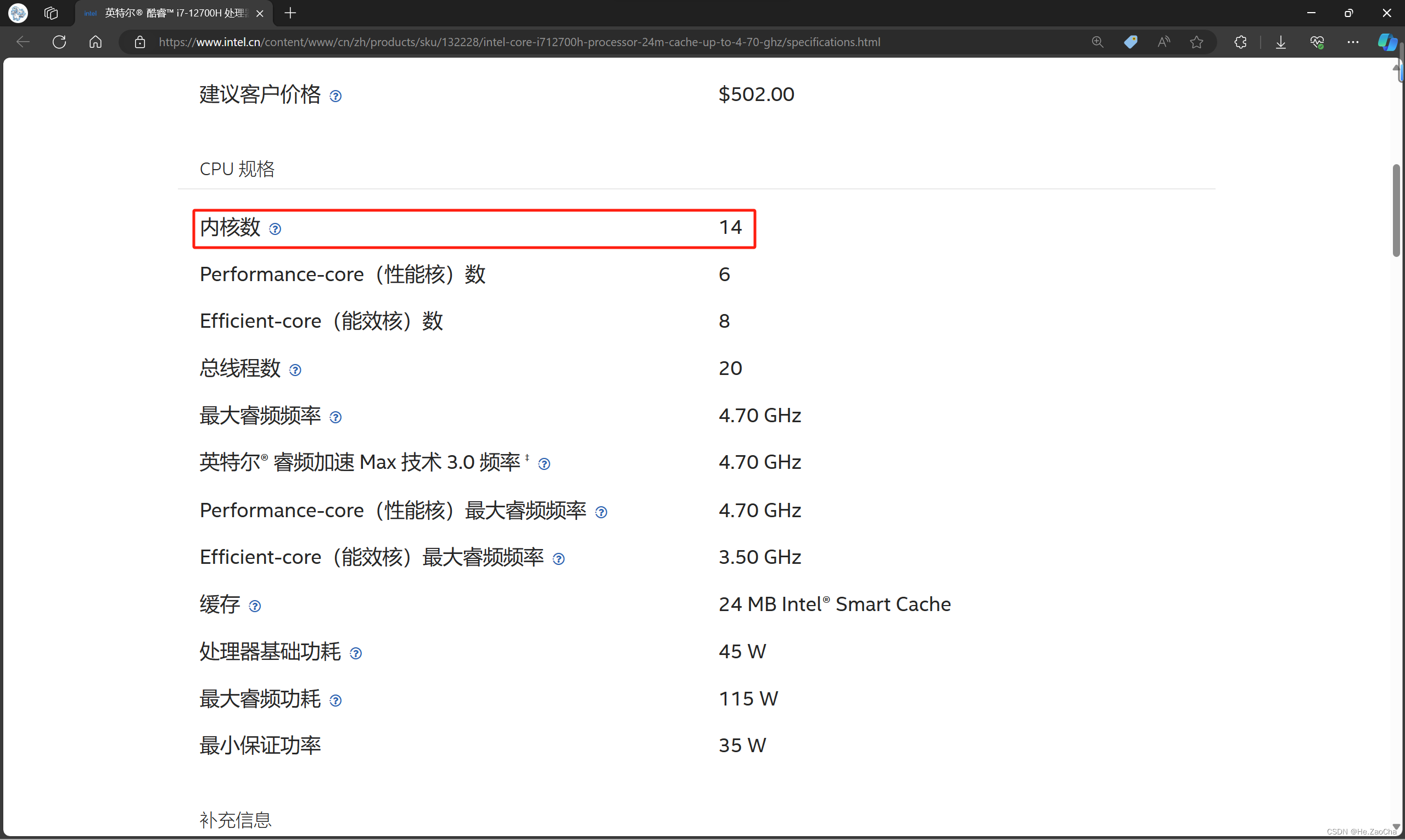
然后各位只要大概设置一下数量,尽量不要超出 本机 C P U 内核总数的 2 3 本机 CPU 内核总数的 \frac{2}{3} 本机CPU内核总数的32,这样减少对本机运行时产生的影响,因为大家并不需要学习并使用所有大数据的组件,所以大概估算下来,内核大概 3~4 个即可流畅运行本课程所有内容,当然不是说 1 个不行,1 个核心也可以,时间上慢一点而已,不会说产生什么问题,所以大家可以完全放心;选配完后请大家点击
下一步(N)>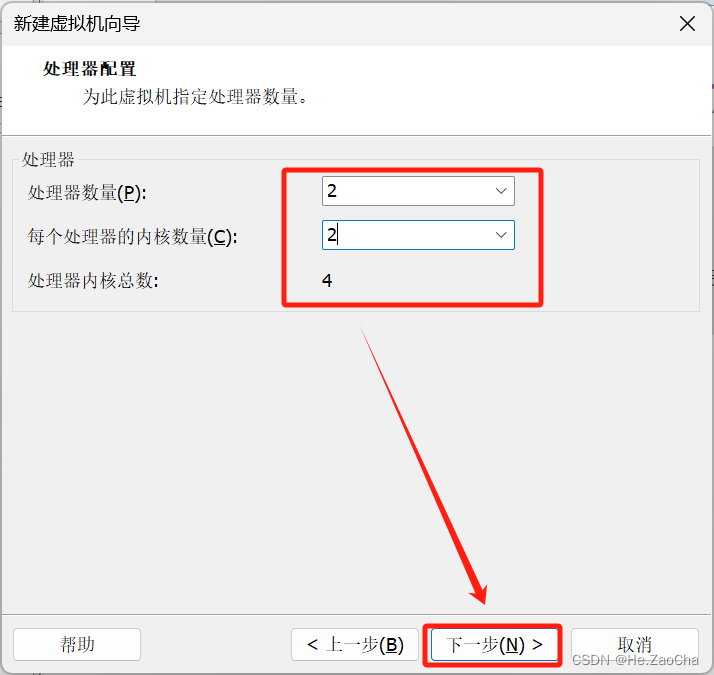
-
这部分大家需要选择分配给虚拟机的内存,VMware 会根据大家的电脑配置给大家推荐内存量,请大家不要超过最大推荐的内存量,否则将会影响本机的运行;选择上,建议大家尽量 1 个内核分配 1G,这样能更好的保证运行的流畅度;当然,如果大家不安装图形化界面,则可以 2 个内核分配 1G 内存;当然以上纯属个人见解,大家根据实际情况进行选配;选配可以点击左侧红色框内的数字进行快速选择,也可以在黄色方框输入内存值,选配好后请点击下方蓝色方框进入
下一步(N)>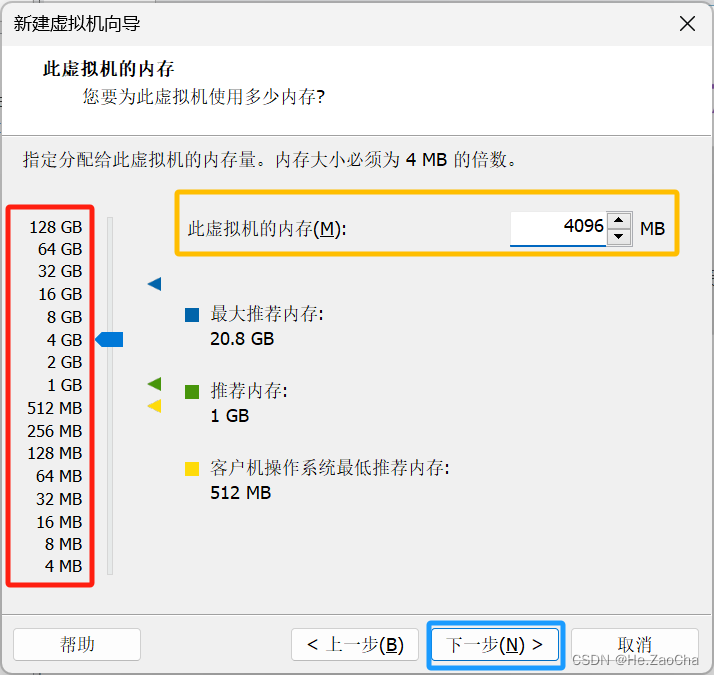
-
这部分涉及的是网络类型,大家做的是单机模式,也就是只需要一台虚拟机即可,为了方便,请大家选择
使用网络地址转换(NAT)(E),当然选择桥接火鹤仅主机不是不可以,只是没那么方便,后续可能在售后方面会有一定的问题存在,如果大家使用了桥接模式遇到了一定的问题,也可以私信我、私信老师或者上网查询;仅主机模式出问题的家人们请不要找到小生,小生对仅主机模式网络无能为力,建议多烦烦老师,谢谢各位;选配好后即可点击下一步(N)>进入下一个配置的选择。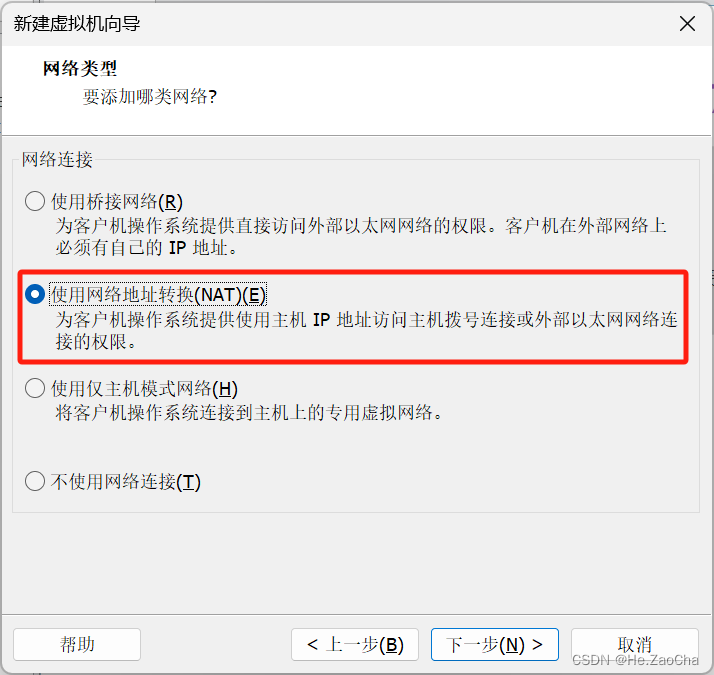
-
这部分是I/O控制器的选择,默认就好,不多说了,推荐什么选什么,这个不会有太大的影响,当然大家对客制化感兴趣,也可以深入了解;选好后请点击
下一步(N)>。
-
这部分是磁盘类型的选择,我的建议是,推荐就很好,也不会太大的影响,当然各位有兴趣对硬件进行了解,也是可以去查询然后再进行安装选配的,但是毕竟是虚拟机,跟真正装机天差地别,所以没必要现在纠结这个;选好后请各位点击
下一步(N)>
-
这部分我们需要选择已有磁盘或者创建一个新的磁盘,不建议使用物理磁盘,会有一定的风险;如果需要使用现有磁盘,则需要选择已有的虚拟机磁盘文件进行导入,但是我们是新建的虚拟机,所以我们选择创建新虚拟磁盘,选择好后请各位点击
下一步(N)>。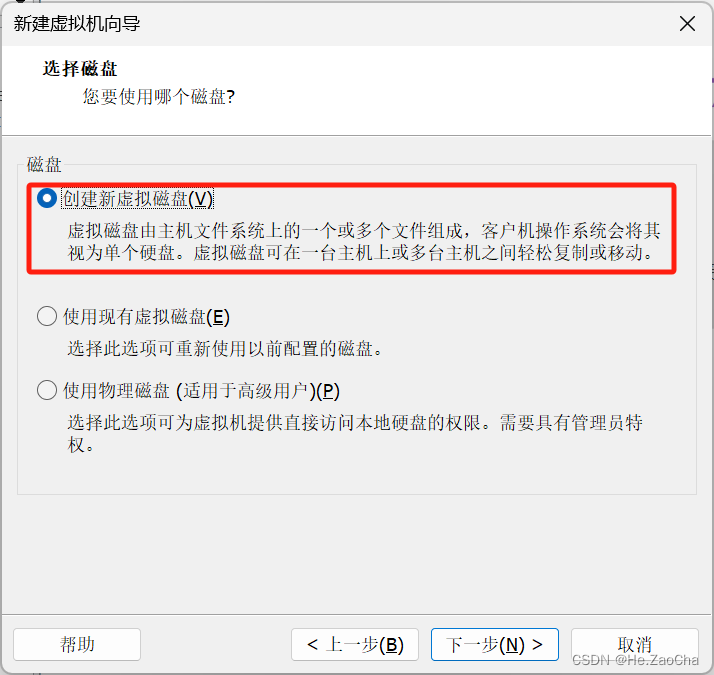
-
这部分我们需要为虚拟机分配存储大小,请各位根据需要使用的软件大小进行调整,一般建议是 20G,如果需要完成本课程,在我看来大概需要 30~40G,左右的内存容量,大家可以适当进行调整,不够再加也是可以的,不一定非得刚开始就固定好;然后根据提示,如果大家需要移动虚拟机,则请大家尽量选择拆分成多个文件,如果不需要移动虚拟机到其他电脑上使用,则请大家尽量选择存储为单个文件,可以提升一定的性能,如果大家还记得操作系统一些知识,应该就很好解释这一部分。
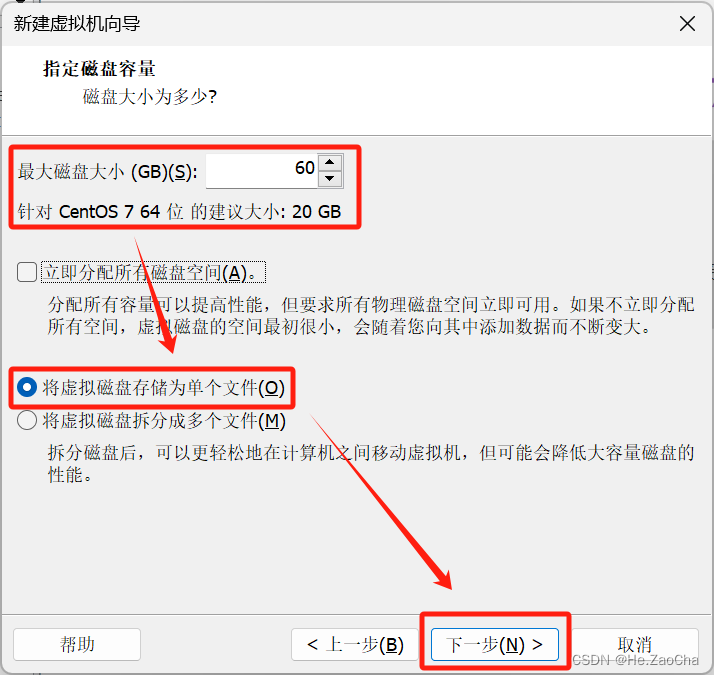
-
这部分需要我们指定磁盘文件存储到哪一个虚拟磁盘中,该虚拟磁盘在 VMware Workstation 中是
.vmdk的形式进行存储,并且大家并不是特别熟悉,所以这里我们选择默认即可,然后点击下一步(N)>
-
看到下图的界面说明我们的虚拟机选配已经完成了,大家根据自己电脑进行适当的选配即可,不一定要抄作业,我的说法是,没必要。最后我们还有一步,还记得上面我们还没选择光盘映像吗?这里我们需要点击
自定义硬件(C)...,在里面进行光盘映像文件的选择。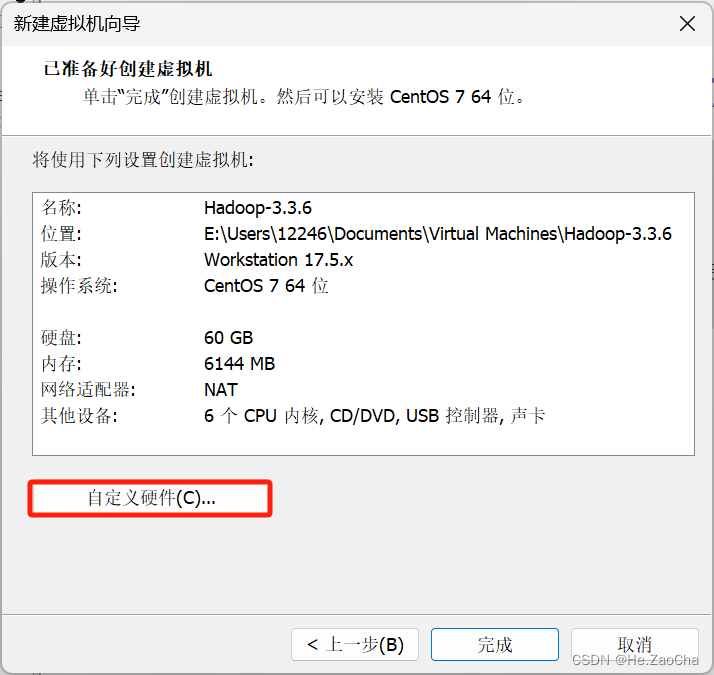
-
这里我们需要点击左边栏目中的
新 CD/DVD (IDE);然后将设备状态中的启动时连接(O)进行勾选(默认已经是勾选状态了),因为我们需要通过该功能进行安装操作,待后续安装完毕后我们可以将其关闭;最后需要再连接板块中选择使用 ISO 映像文件(M):并且点击浏览(B)...进行光盘映像的选择,最后点击关闭即可。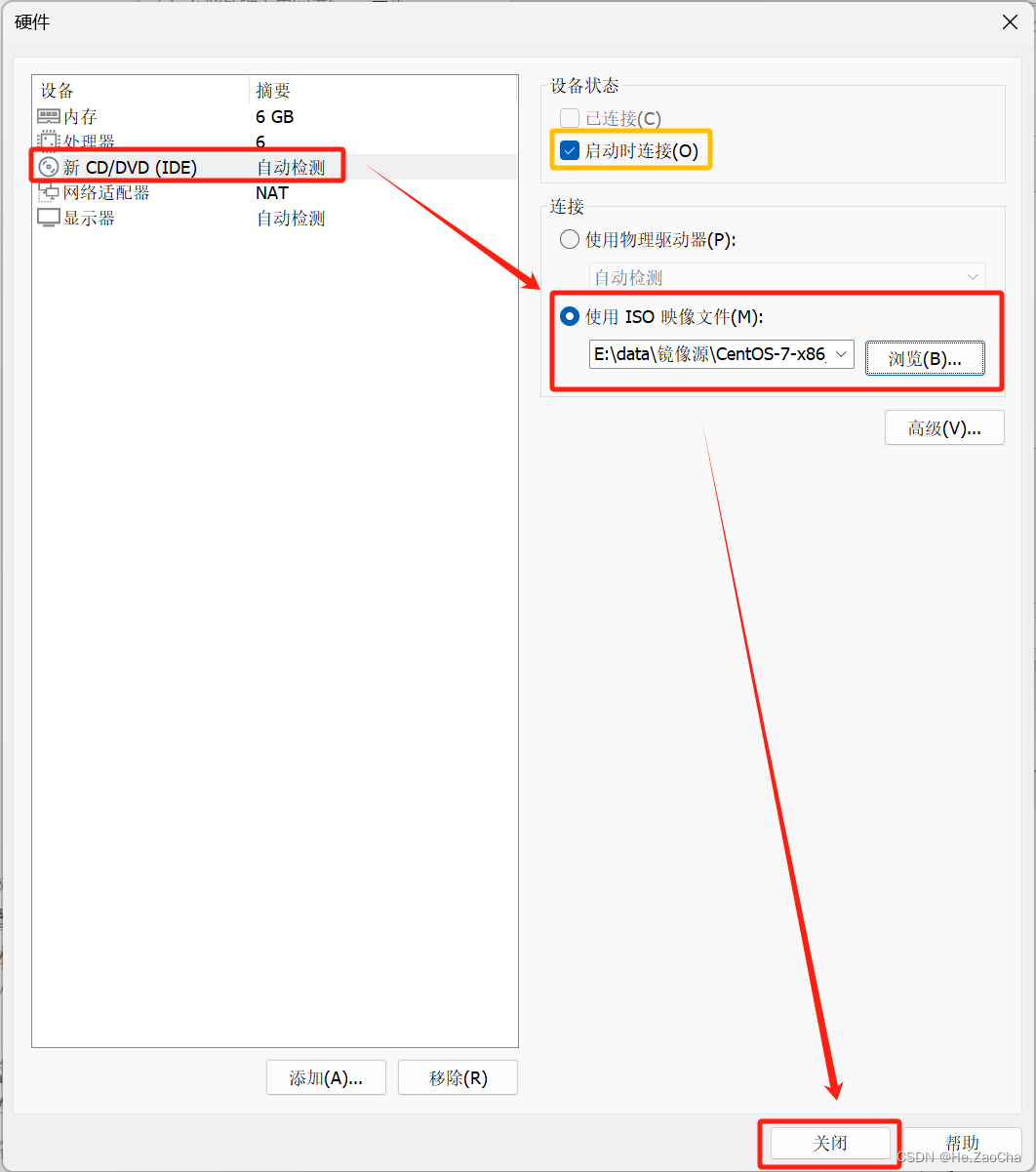
-
这部分中的其他设备跟我上面那张图是有点区别的,因为我把那几个我觉得没必要的东西给删掉了,如果大家需要使用这几种虚拟设备,请不要像我一样删了,如果不太明白,就请保留即可,最后点击
完成即可完成虚拟机的创建。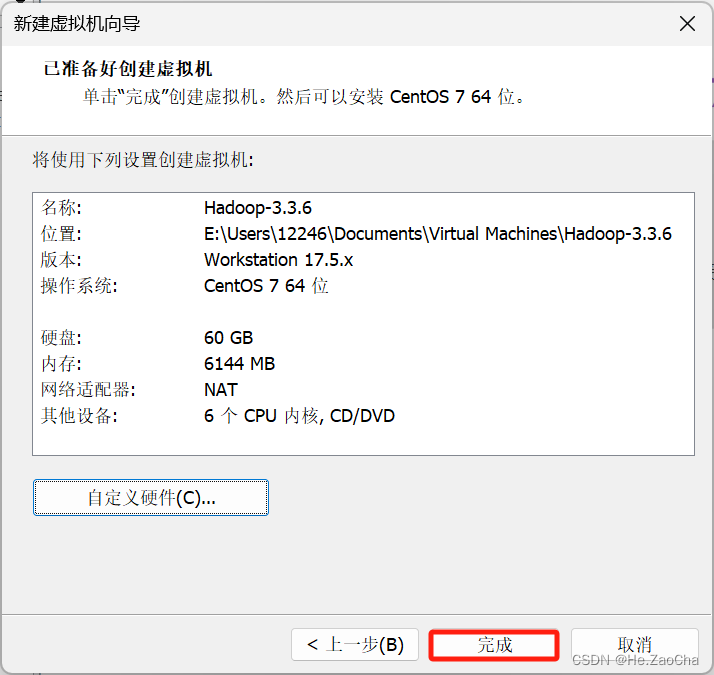
-
如果没有开创建完毕自动开启,请在主页面手动点击
开启虚拟机进行开启。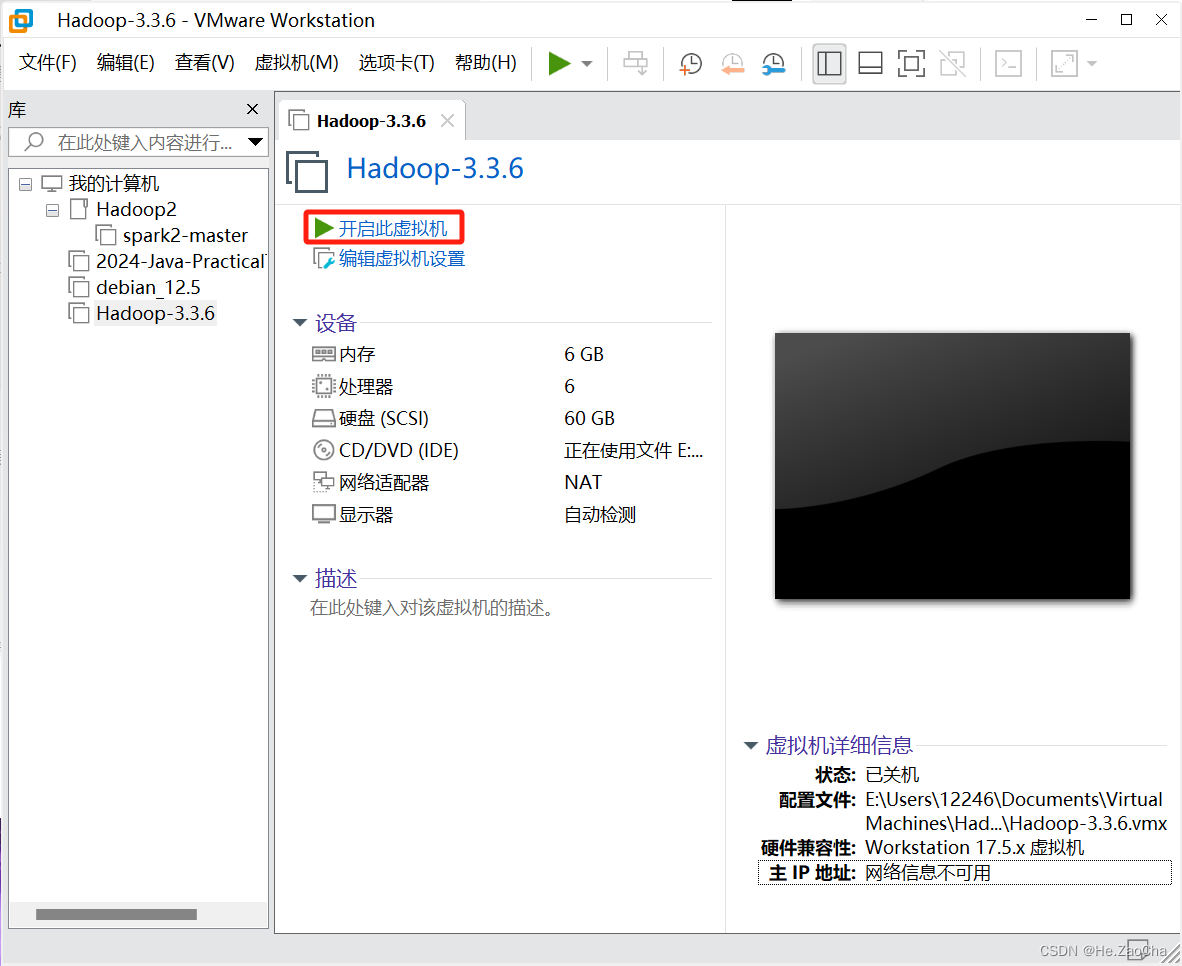
-
打开后,会自动读取光盘映像,然后会看见如下的界面,可能大家显示的不一定有那么清楚,因为 VMware 默认的是
BIOS启动,所以请大家尽量点击一下键盘↑键,会有一点变化,当然如果时间足够的话,选择第二种启动方式也是可以的,然后需要再键盘上按Enter键进入安装界面。
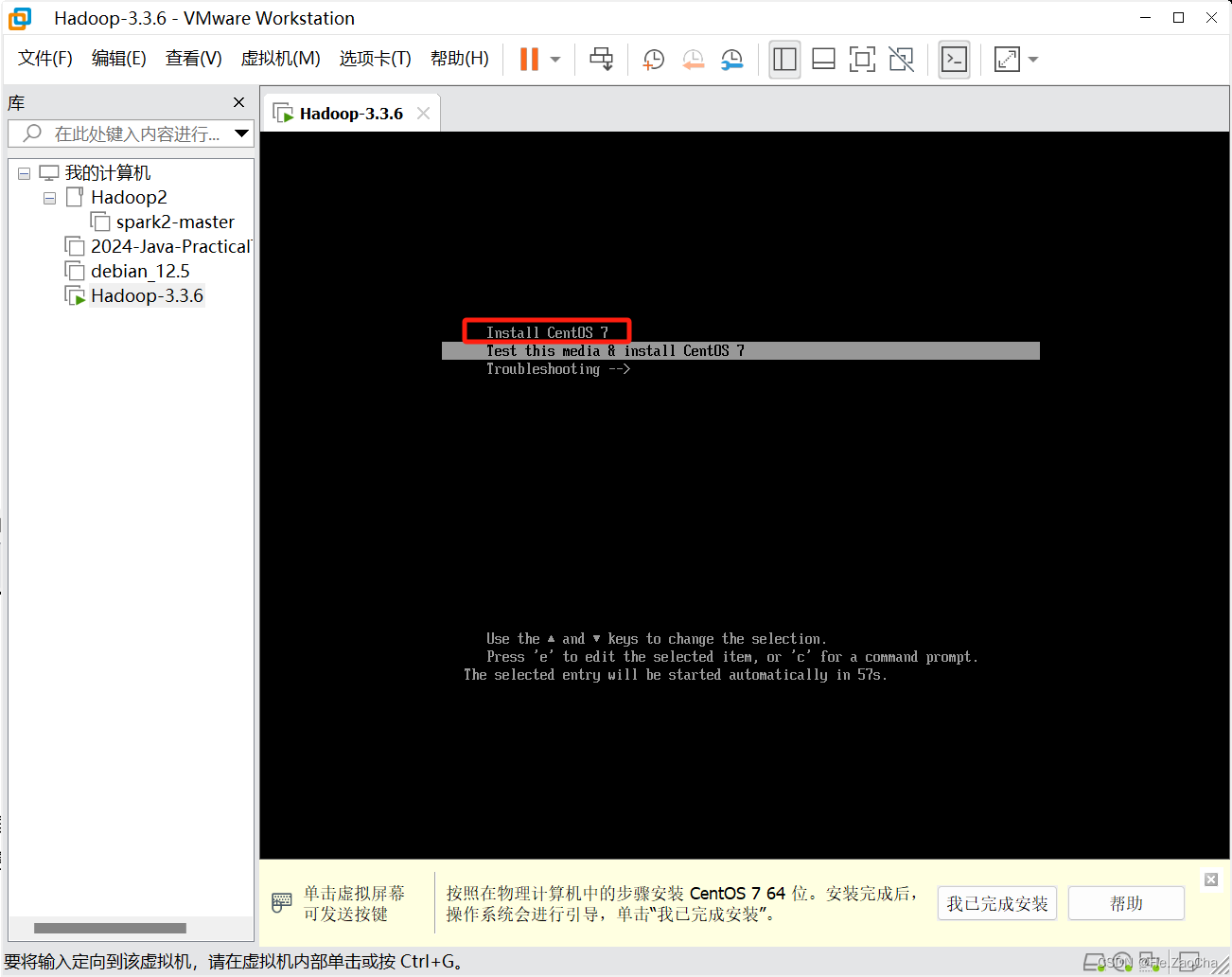
-
进入安装界面后,需要选择系统语言,这里我选择美式英文,当然大家选择中文也是可以的,但建议尽量选择英文,因为英文会更合适系统一些,中文可能会在某些时候产生乱码,为避免问题的产生,我采用的是美式英文,选择好后,点击下方蓝蓝的按钮
continue,进入下一步。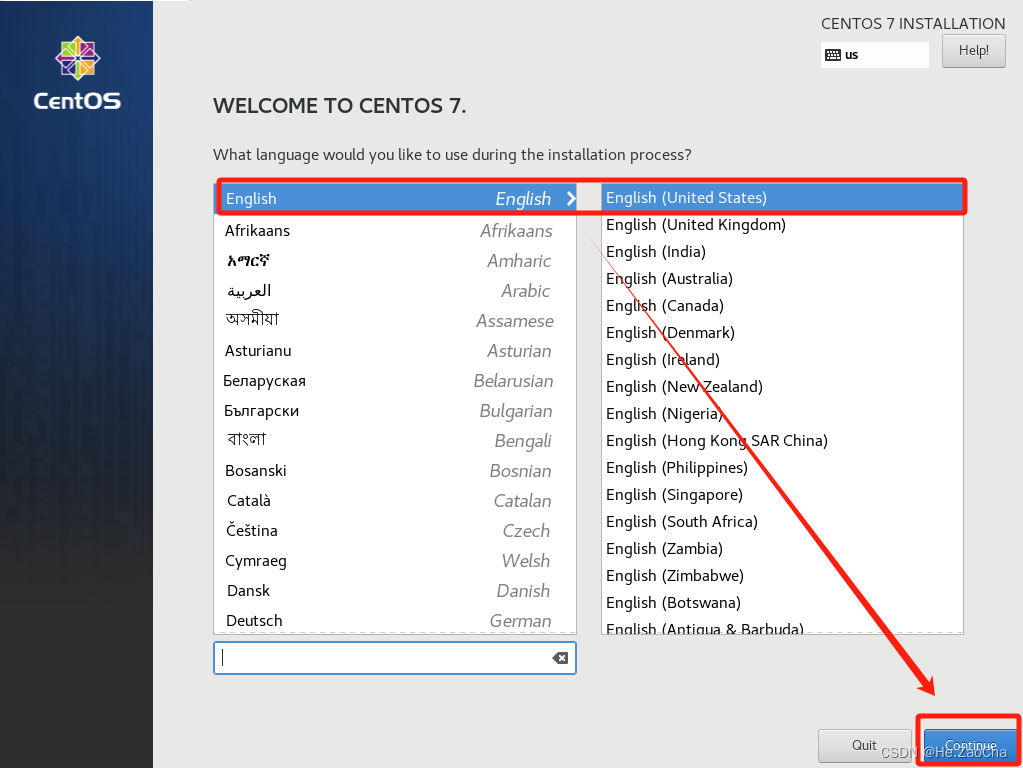
-
这部分需要配置的有点多,这边我们先从网络和主机名开始,请根据下图选择
NETWORK & HOST NAME,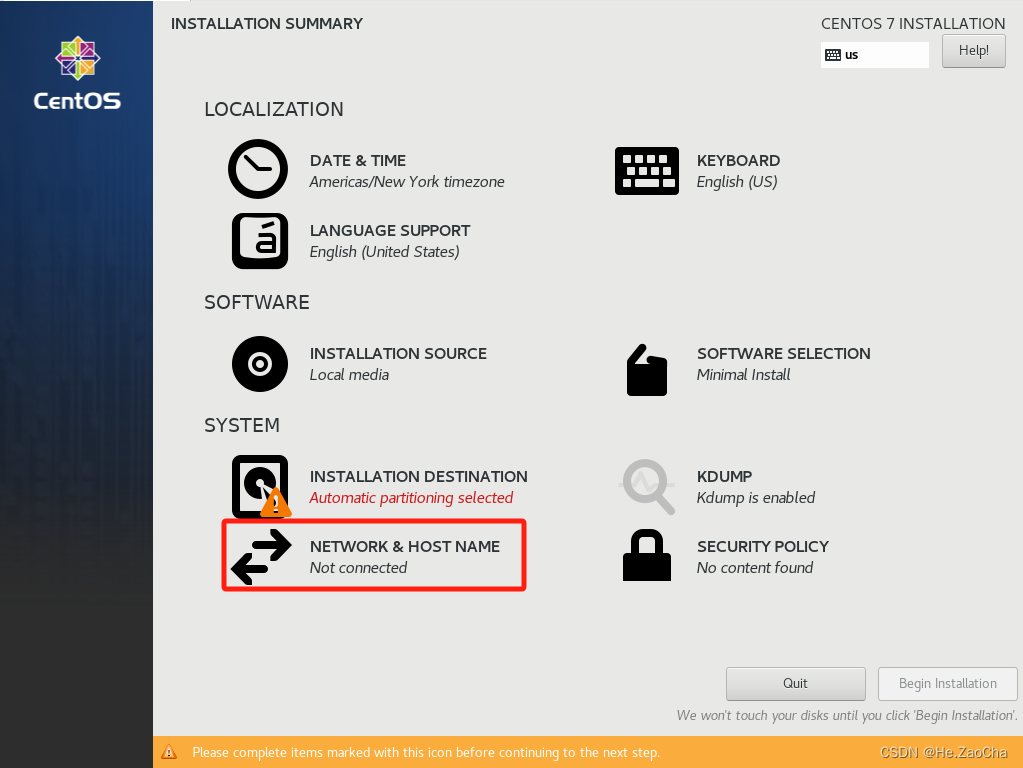
-
进入之后我们需要根据下图,打开网卡的开关,然后修改下面的主机名称,当然,主机名称也可以不改,这个映像并不是特别大,这里我改成了
Hadoop,跟课程贴合,这个大家想改什么改什么,没有讲究;完成后即可点击完成配置;不过这里插个眼,需要大家记一下下面蓝色方框的东西,最主要的是第一行的IP Address,这是虚拟机的 IP 地址,待会配置网卡文件的时候会用上,当然这个没有硬性要求,到时候改个网关一样的 ip 也是一样的。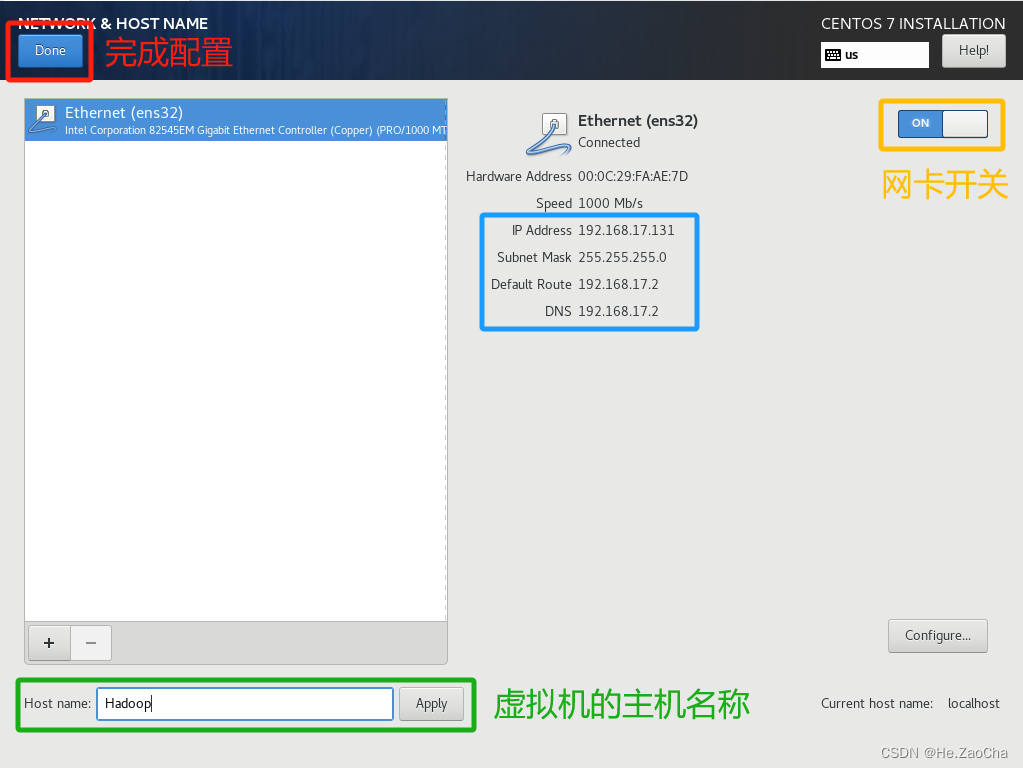
-
接下来我们点击
DATE & TIME,调整时区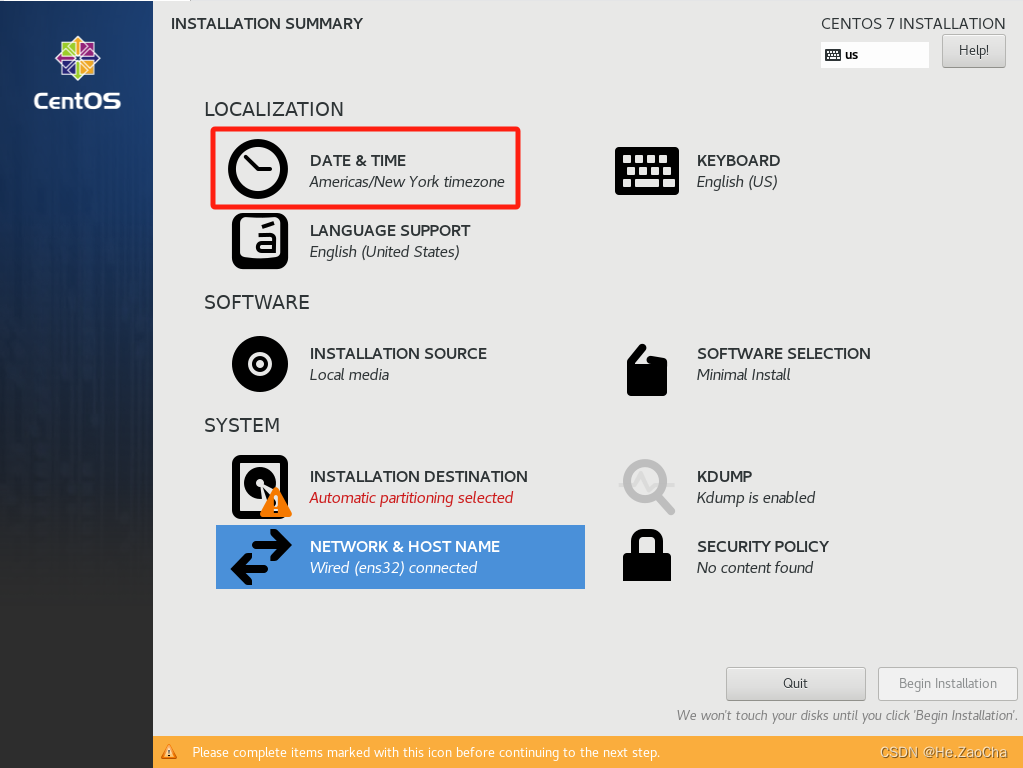
-
可以看见有一幅世界地图,比起韩国的世界地图我直呼内行;如图点击标记地方,只要上面红色框中
Region改变成Asia,也就是亚洲,City改变成Shanghai,如果上面网卡设置一切正常的话,这里的Network Time选项应该是ON的才对,配置好后,点击Done退出该设置。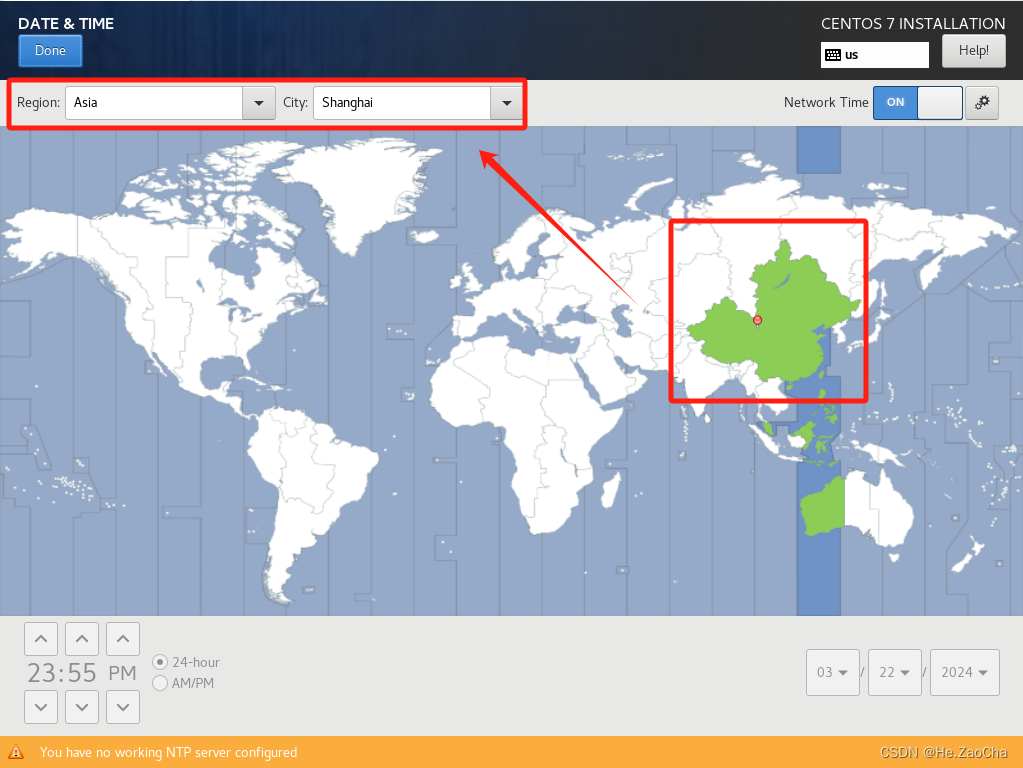
-
接下来开始选配软件,大家软件工程的朋友们应该对软件的了解稍微会深那么一点点的吧…开个玩笑嘿嘿;点击
SOFTWARE SELECTION,进入软件选配界面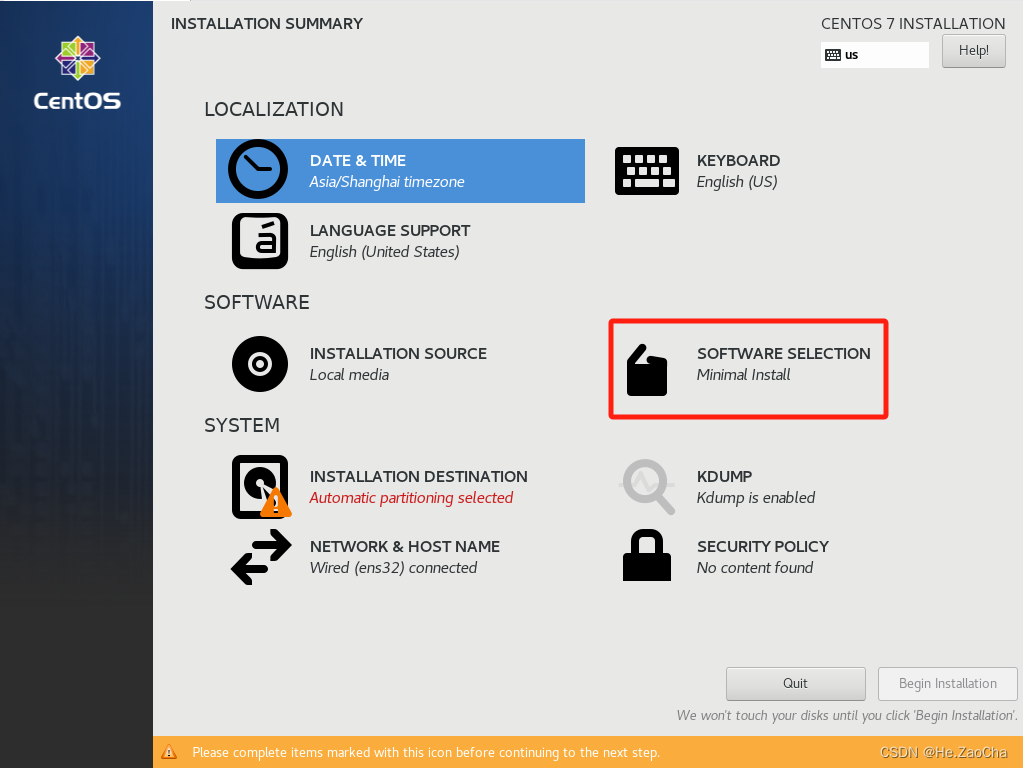
-
接下来各位应该选择的是图形化界面,这边建议选择下图的
GNOME Desktop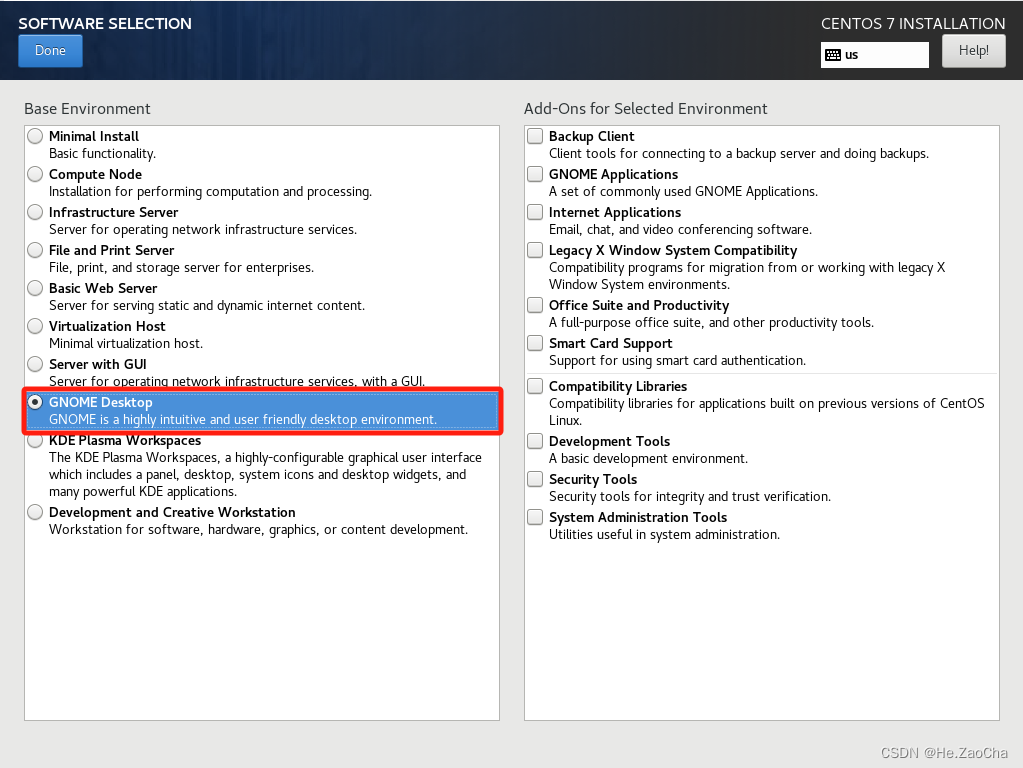
然后这边给出翻译,右边的至少请大家勾选
开发工具,勾选GNOME应用程序,要是全部勾选也可以,看大家的需求来选择吧,选择好后点击Done,退出软件的选配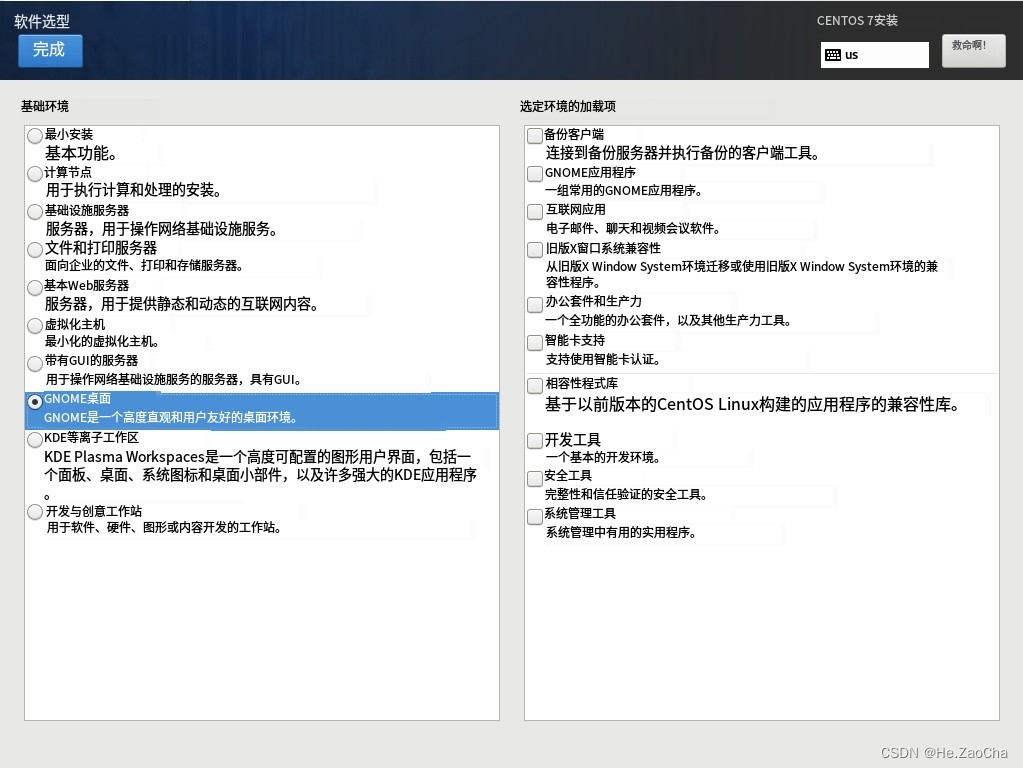
-
下面还需要选配最后一个
INSTALLATION DESTINATION,进行分区的配置。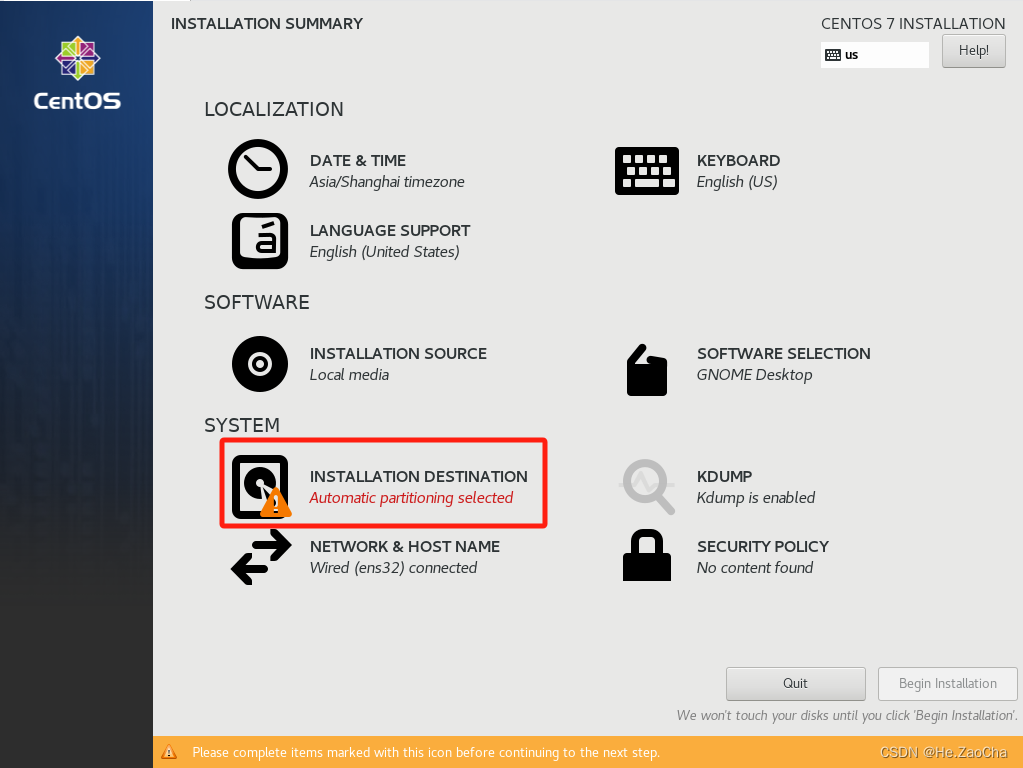
-
这个进去就可以直接点击
Done退出了,如果大家后续想自定义分区的话,可以后面再进行配置,这里我就不跟大家过多赘述了。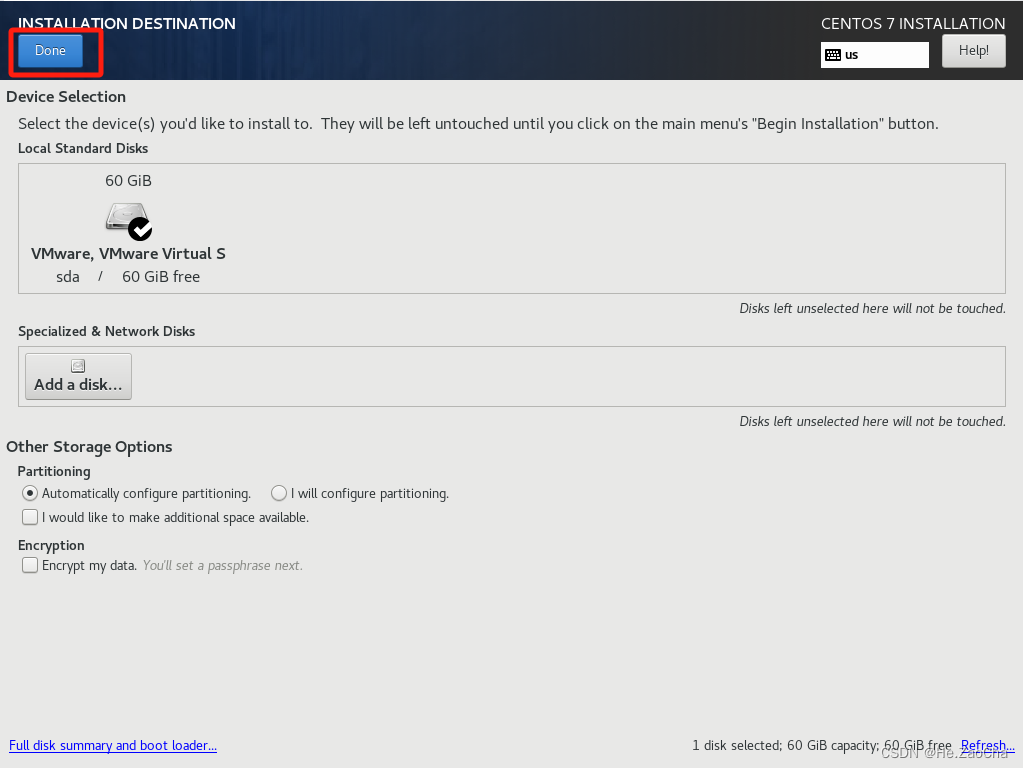
-
搞完这个应该就没有黄色的感叹号了,然后就可以点击下面蓝色的按键
Begin Installation,开始安装了。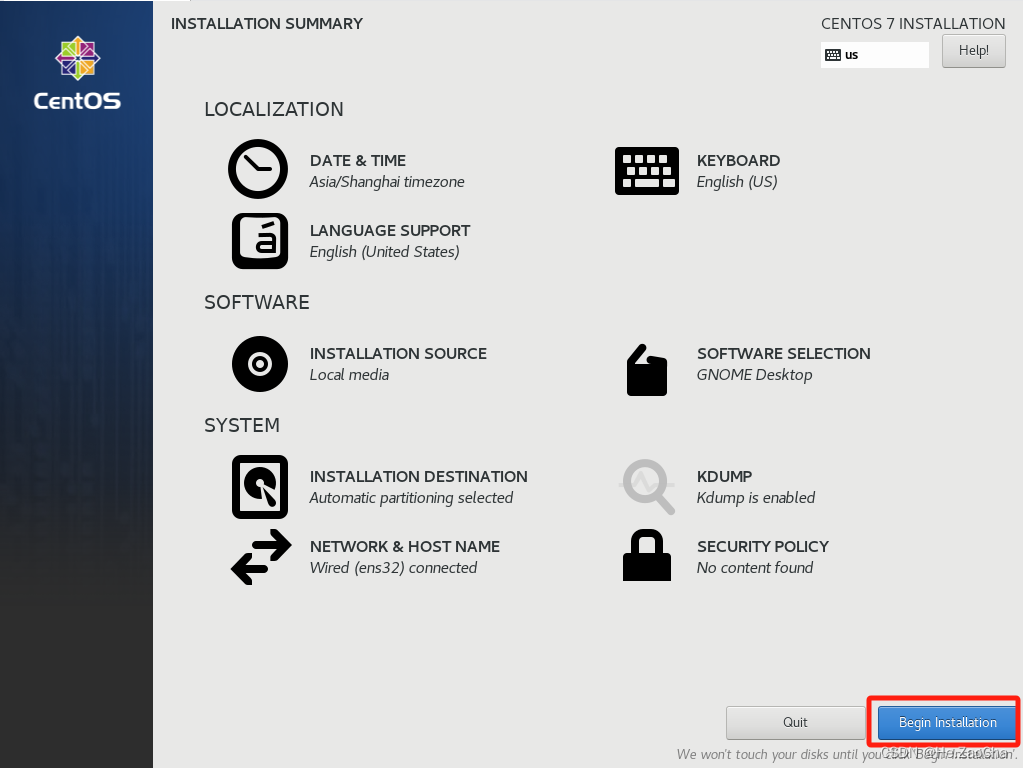
-
看下图,我们先给
root用户设置密码,点击ROOT PASSWORD进入设置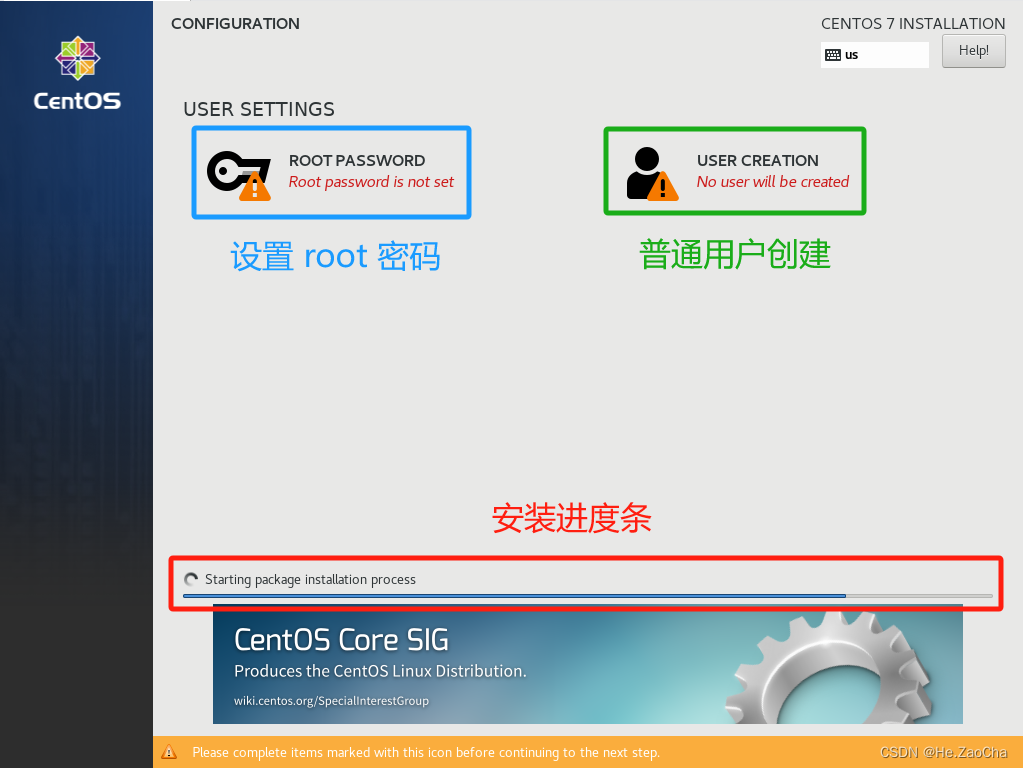
-
输入密码,并且确认密码正确,然后就可以点击
Done退出了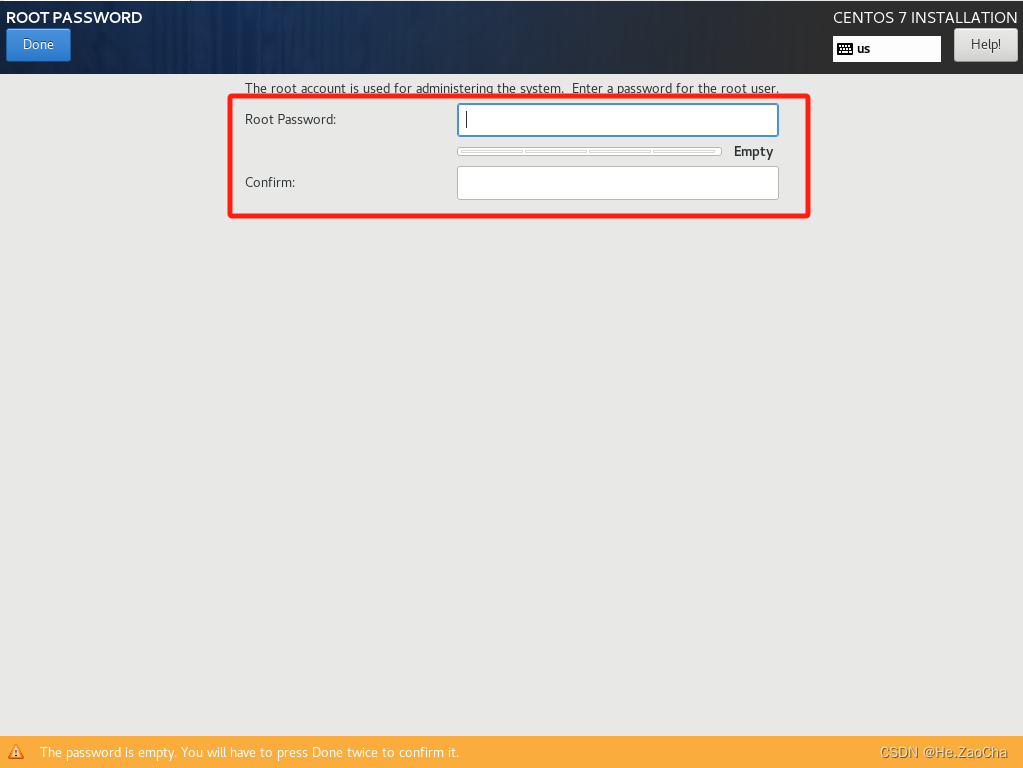
-
然后我们再点击
USER CREATION创建一个新的普通用户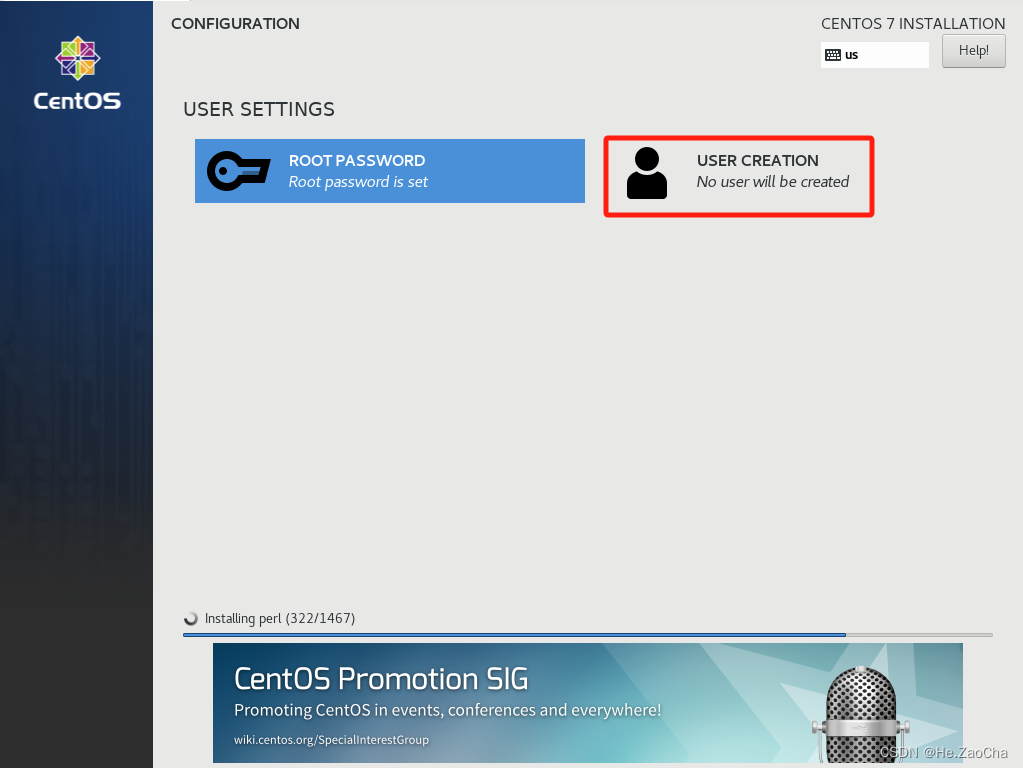
-
这里的用户名设置也没什么讲究,其实用不用
hadoop当做用户名都对后续操作没有影响,因为这个并不是特定的,哪怕是另外名字的账户也是可以进行实验的,所以后面没必要再重新创建一个用户,所以大家看着来就好,这里我就设置一个我熟悉的用户名哈,各位自己也整一个熟悉的就可以了;然后下图红色方框和蓝色方框的建议大家勾选上,sudo这个指令还是很有用的,密码登录也是,虽然我们到时候也需要配置免密登录,但是没密码的用户其实没那么安全,我是不建议的,当然头铁的兄弟们另算哈;配置完后就可以点击Done退出了。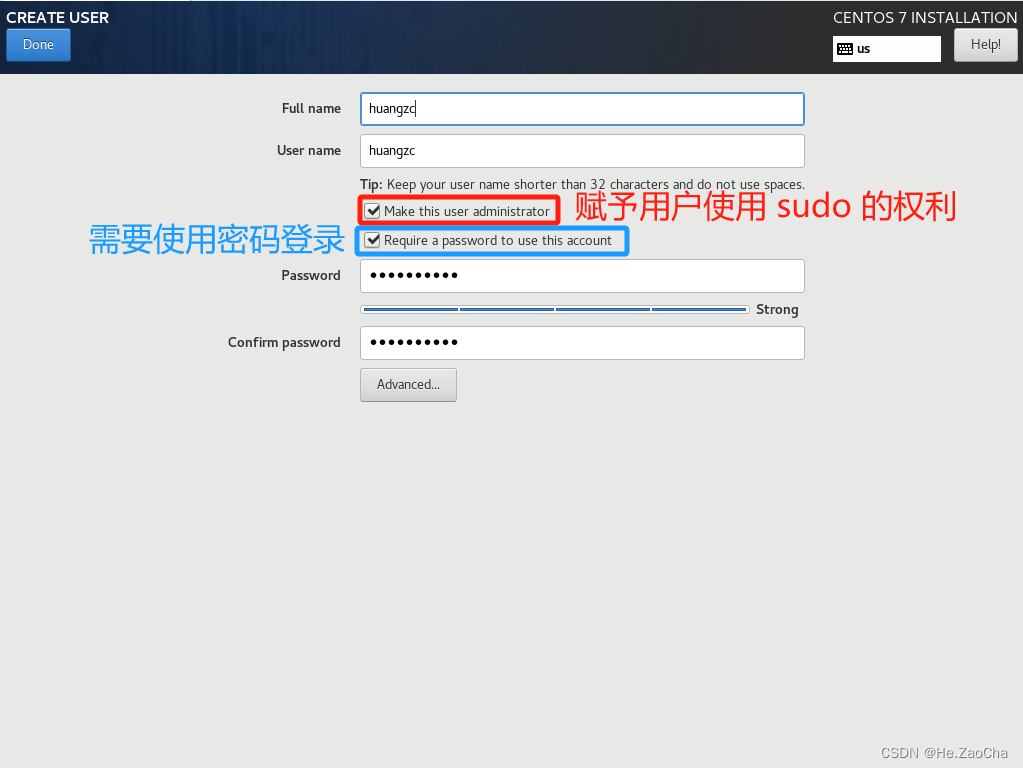
-
然后就是漫长的等待时间了,等待安装完毕后,即可点击下面的蓝色按钮
Restart,进行系统重启即可。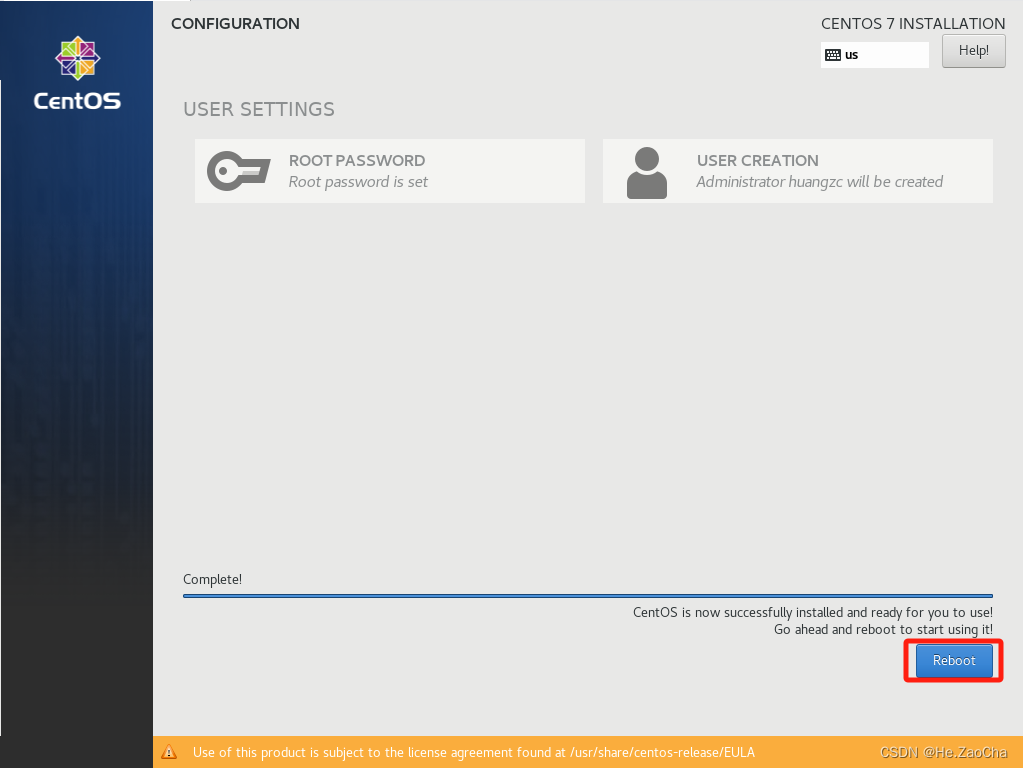
-
重启之后会有一个授权认证,需要点进去
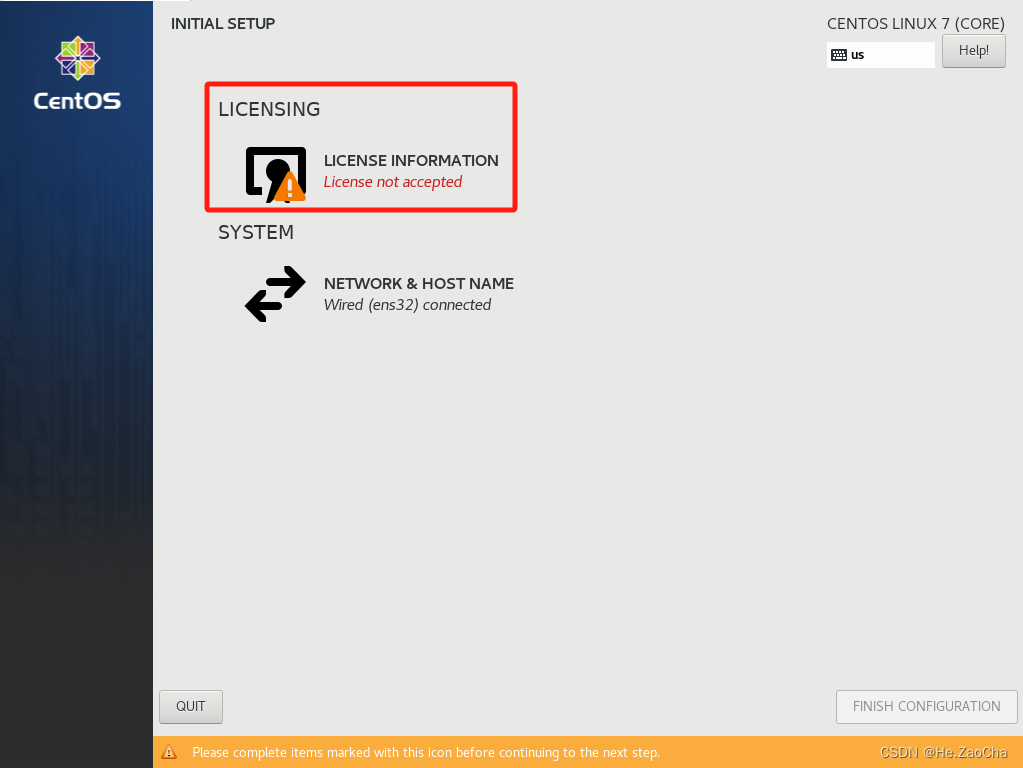
-
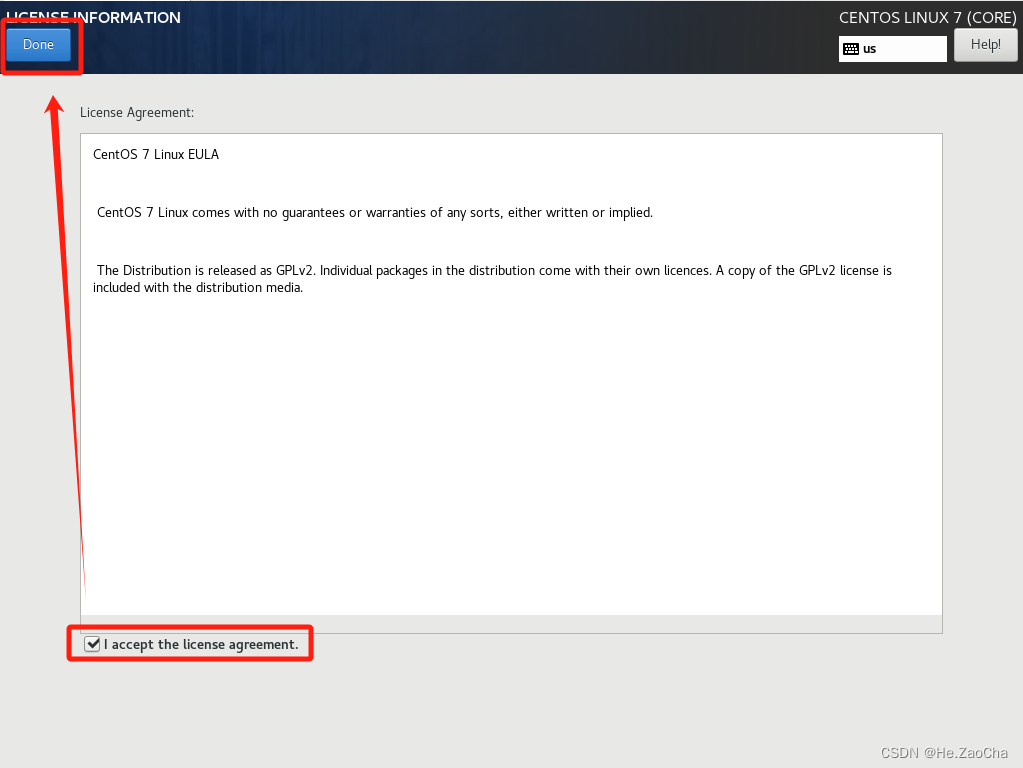
然后勾选上下面的那个同意协议的方框,然后就可以退出了
-
如果网络配置没有问题的话,就会像下面一样,显示
connected,然后我们点击FINISH CONFIGURATION,完成配置即可。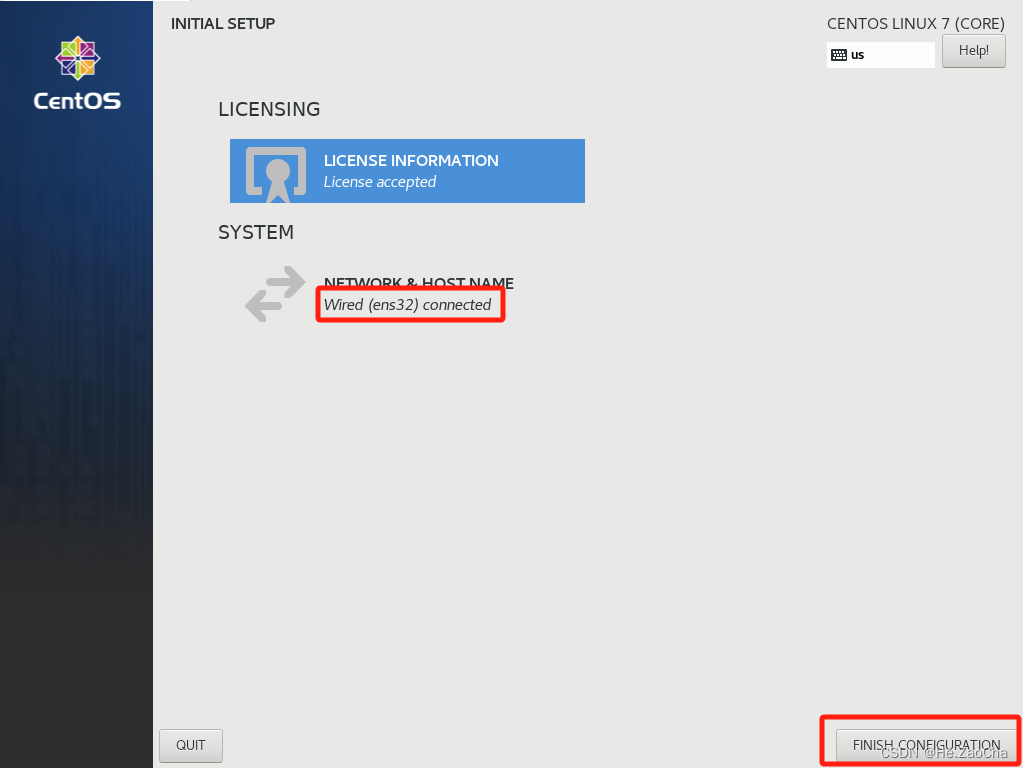
-
然后系统将会出现登录界面(如下图),到这儿就和
Windows差不多像了,也说明我们安装完成了。
三、结尾
这一篇主要给软工的兄弟姐妹介绍一下本门课程需要的一些组件和下载的方式,以及系统的安装,可能大家已经安装好了,也可能有些覆盖不到的地方,也请大家多多包涵;还是希望这篇文章能够帮助到大家一些地方的。如果大家学习过程中有什么问题可以一起交流,能联系到我的话,在下也很乐意为大家排忧解难。