文章目录
- 简介
- ES文档操作
- 创建索引
- 查看索引
- 创建映射字段
- 查看映射关系
- 字段属性详解
- type
- index
- store
- 字段映射设置流程
- 新增数据
- 新增会随机生成id
- 新增自定义id
- 智能判断
- 修改数据
- 删除数据
- 查询
- 基本查询
- 查询所有(match_all)
- 匹配查询
- 多字段查询
- 词条匹配
- 多词条精确匹配
- 结果过滤
- 直接指定该字段
- 指定includes和excludes
- 高级查询
- 布尔组合(多条件查询)
- 范围查询
- 模糊查询(fuzzy)
- 排序
- 单字段排序(sort)
- 多字段查询
- 聚合(aggregations)
- 桶(bucket)类似于数据库中的分组group_by
简介
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图、线状图、饼图等。
在开始之前,需要启动Kibana和Elasticsearch
ES的访问地址:http://ip:9200
Kibana的访问地址:http://ip:5601
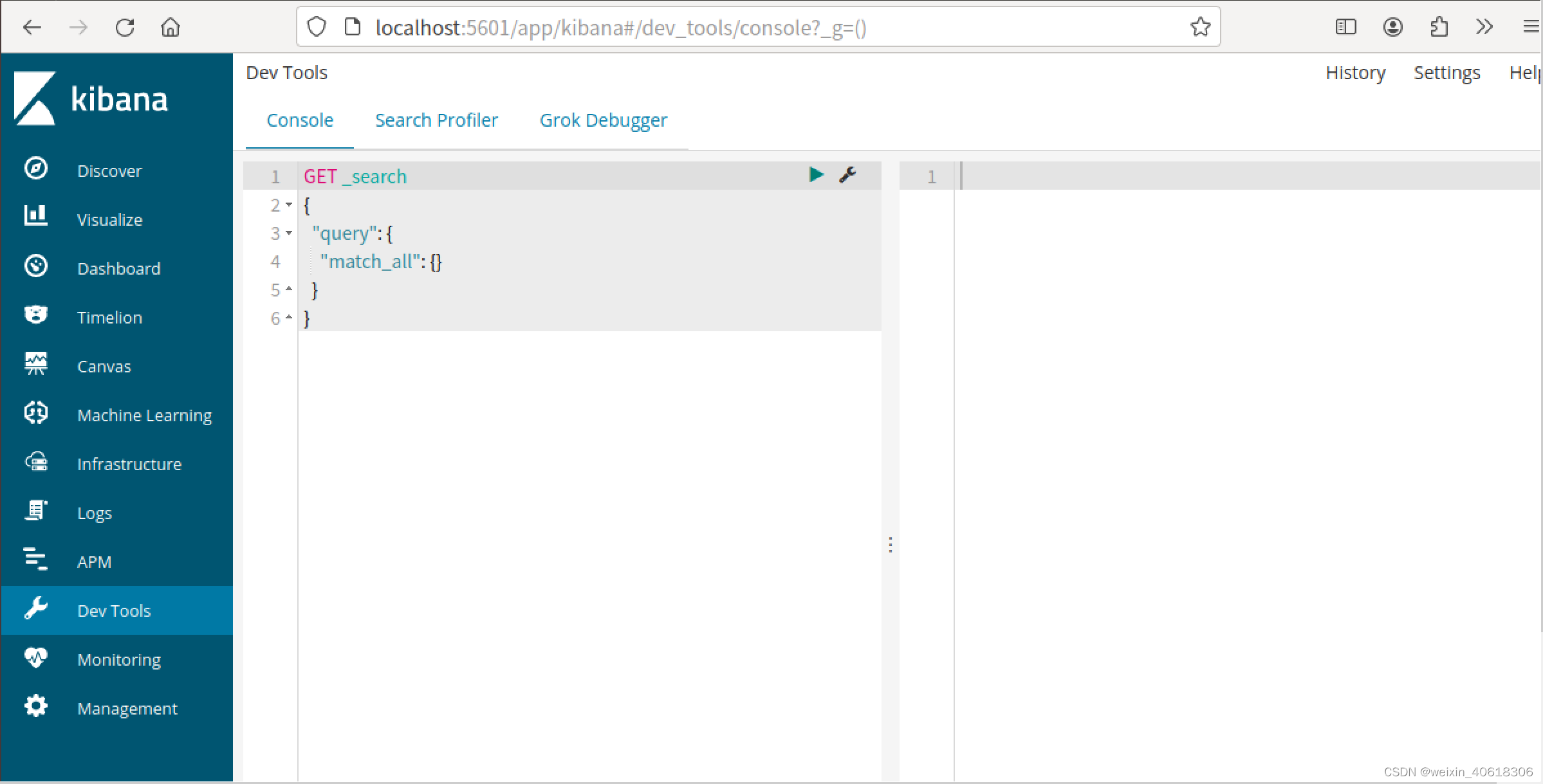
操作步骤:进入到Kibana后,点击左侧的Dev Tools
ES文档操作
ES是面向文档的,存储文档的同时对其进行索引使其能够被搜索到。
创建索引
Elasticsearch采用Rest API风格,因此其API就是一次HTTP请求,可以使用任何工具发起http请求创建索引的请求格式。由于遵循REST风格,可以很直观的想到操作名。
- POST新增
- GET查询
- DELETE删除
- PUT修改
在这里使用Kibana简化操作
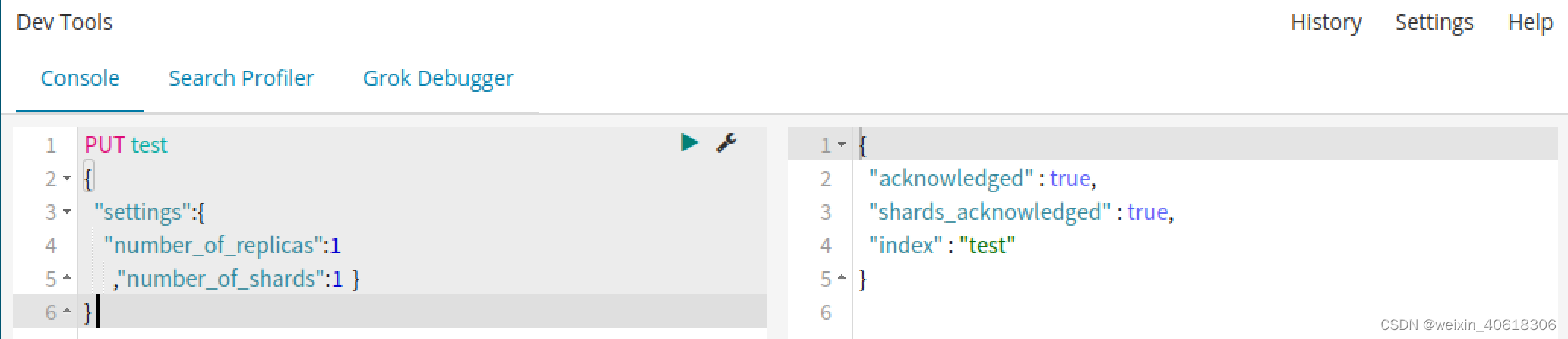
number_of_replicas:设置索引库分片副本数量
number_of_shards:设置索引库分片数量
查看索引
- 查看某一个特定索引库
GET 索引库名
- 查看所有的索引库
GET *
- 删除索引
DELETE 索引库名
- 映射配置
索引有了,接下来就是添加数据,但是在添加数据之前必须定义映射。 映射就是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等。只有配置清楚,Elasticsearch才会帮我们进行索引库的创建。
创建映射字段
请求方式依然是PUT
PUT /索引库名/_mapping/类型名称
{"properties": {"字段名": {"type": "类型","index": true,"store": true,"analyzer": "分词器"}}
}
- 类型名称:就是type的概念,类似于数据库中不同表字段名;任意填写,可以指定很多属性。
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false(会自动生成一个_source备份)
- analyzer:分词器,这里的ik_max_word即使用ik分词器
发起请求示例
PUT test/_mapping/goods
{"properties":{"title":{"type":"text","analyzer":"ik_max_word"},"images":{"type":"keyword","index":false},"price":{"type":"float"}}
}
字符串类型一共有两种,text代表进行分词,下面要加上分词器,这里使用的ik分词器中ik_max_word代表按照最大程度划分。
keyword不进行分词。
【问题】
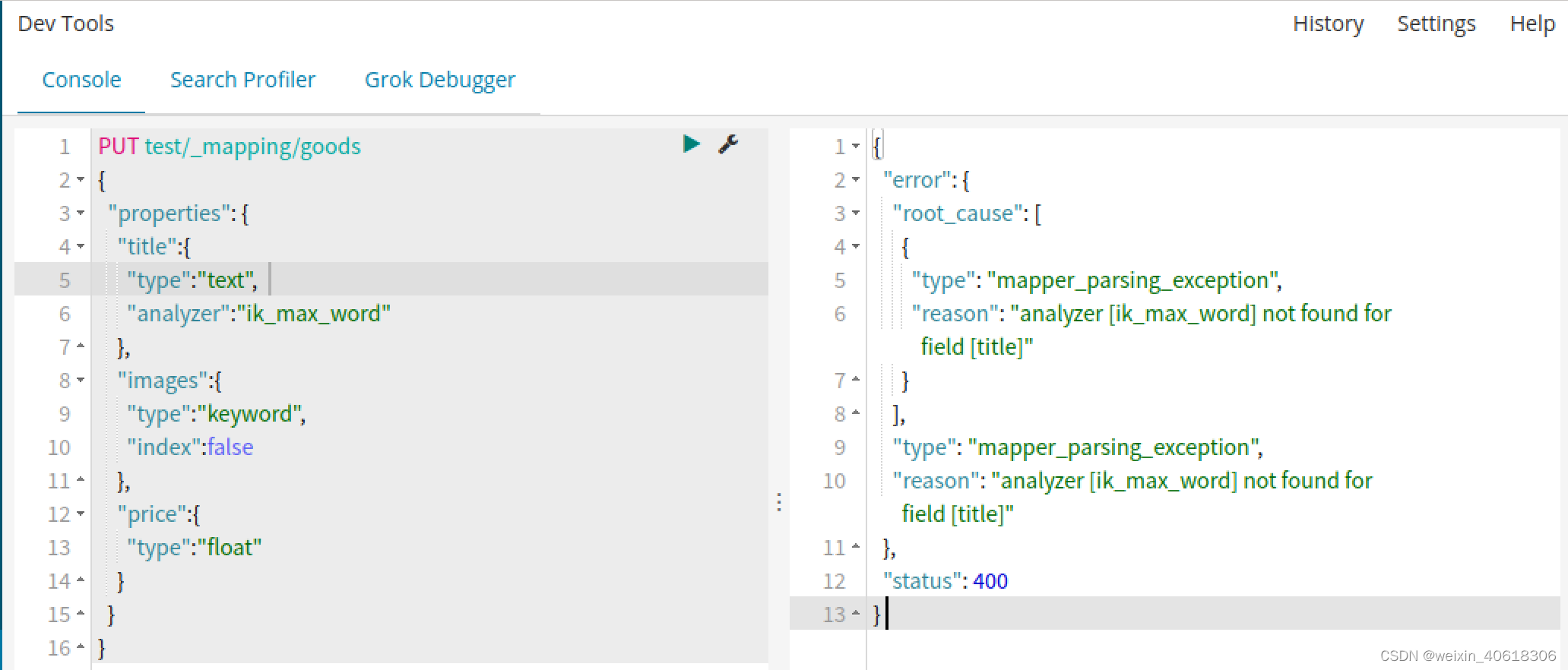
- elasticsearch创建索引时遇到
analyzer[ik_max_word] not found for field[title]
【原因】
IK分词器插件未安装
查看映射关系
GET /索引库名/_mapping
字段属性详解
type
Elasticsearch中支持的数据类型非常丰富:
下面我们介绍几个关键的:
String类型,又分两种:
- text:可分词,不可参与聚合
- keyword:不可分词,数据作为完整字段进行匹配,可以参与聚合
Numberical:数值类型,分两类 - 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
需要指定一个精度因子,比如说10或者100,elasticseach会把真实值乘以这个因子存储,取出时再还原。
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
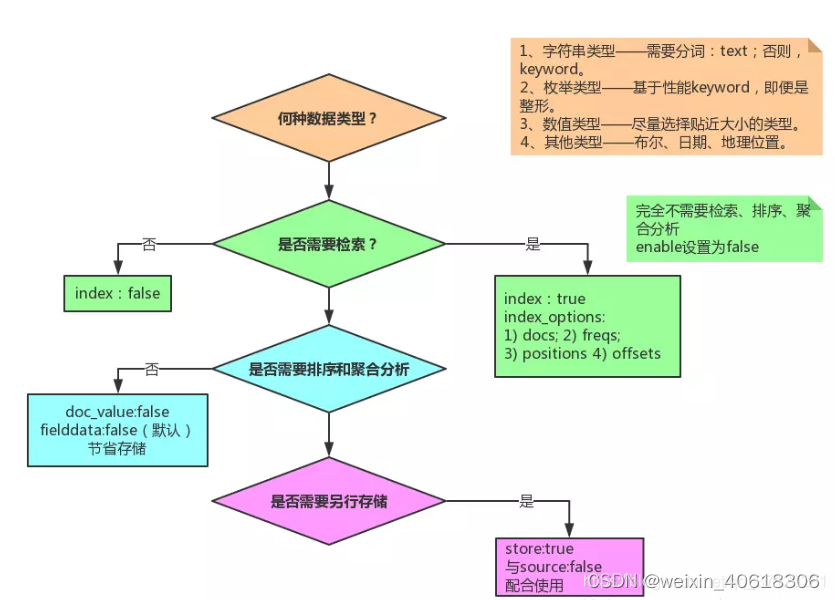
index
index影响字段的索引情况
- true:字段会被索引,则可以用来进行搜索,默认值就是true
- false: 字段不会索引,不能用来搜索
** index的默认值就是true,也就是说不进行任何配置,所有字段都会被索引。**
但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。
store
是否将数据进行额外存储。
在学习lucene和solr时,我们知道如果一个字段的store的值设置为false,那么在文档列表中就不会有这个字段的值,用户的搜索结果中不会显示出来。
但是在elasticsearch中,即使store设置为false,也可以搜索到结果,
原因是Elasticsearch在创建文档索引时,会将文档中的原始数据备份,保存在一个交_source的属性中,而且我们可以通过过滤_source来选择哪些要显示,哪些不显示。
而如果设置store为true,就会在_source以外额外存储一份数据,比较多余,因此一般我们都会将store设置为false,事实上,store的默认值就是false。
字段映射设置流程
新增数据
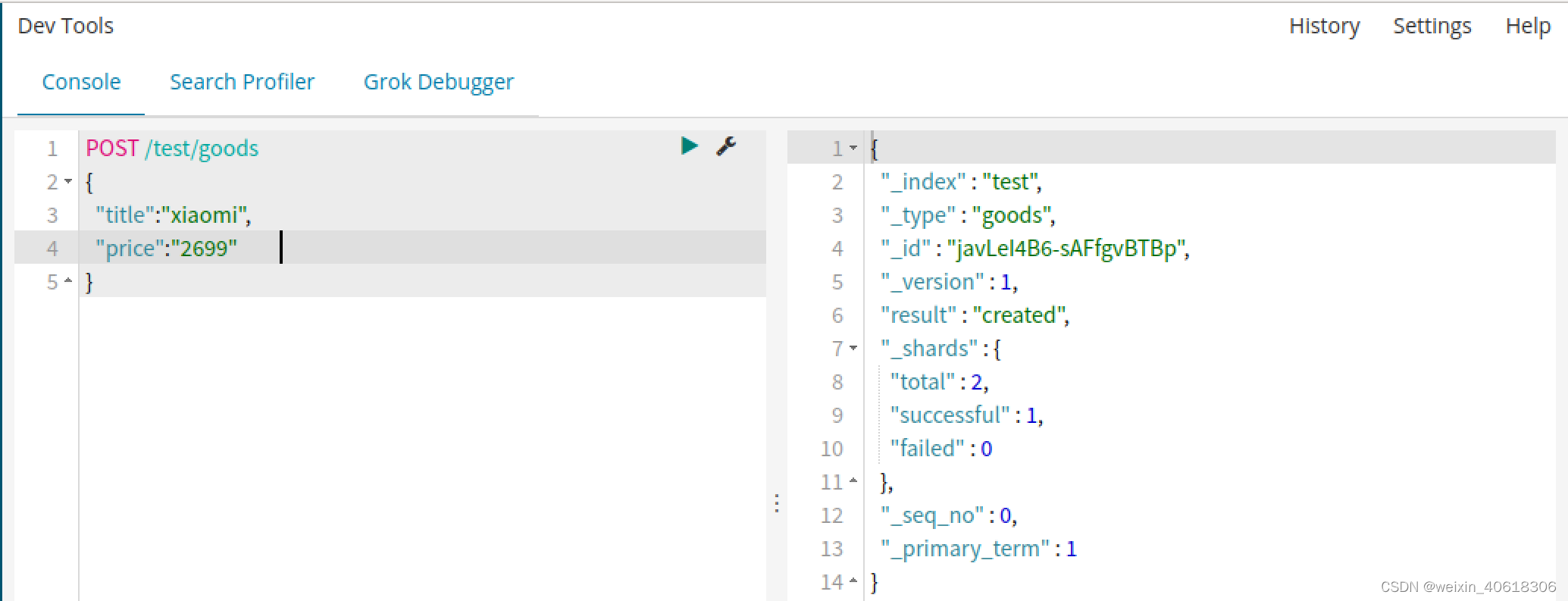
新增会随机生成id
POST /索引库/类型名
{“key”:"value"
}
新增自定义id
如果我们想要自己新增的时候指定id,可以这么做
POST /索引库/类型/id值
{
}
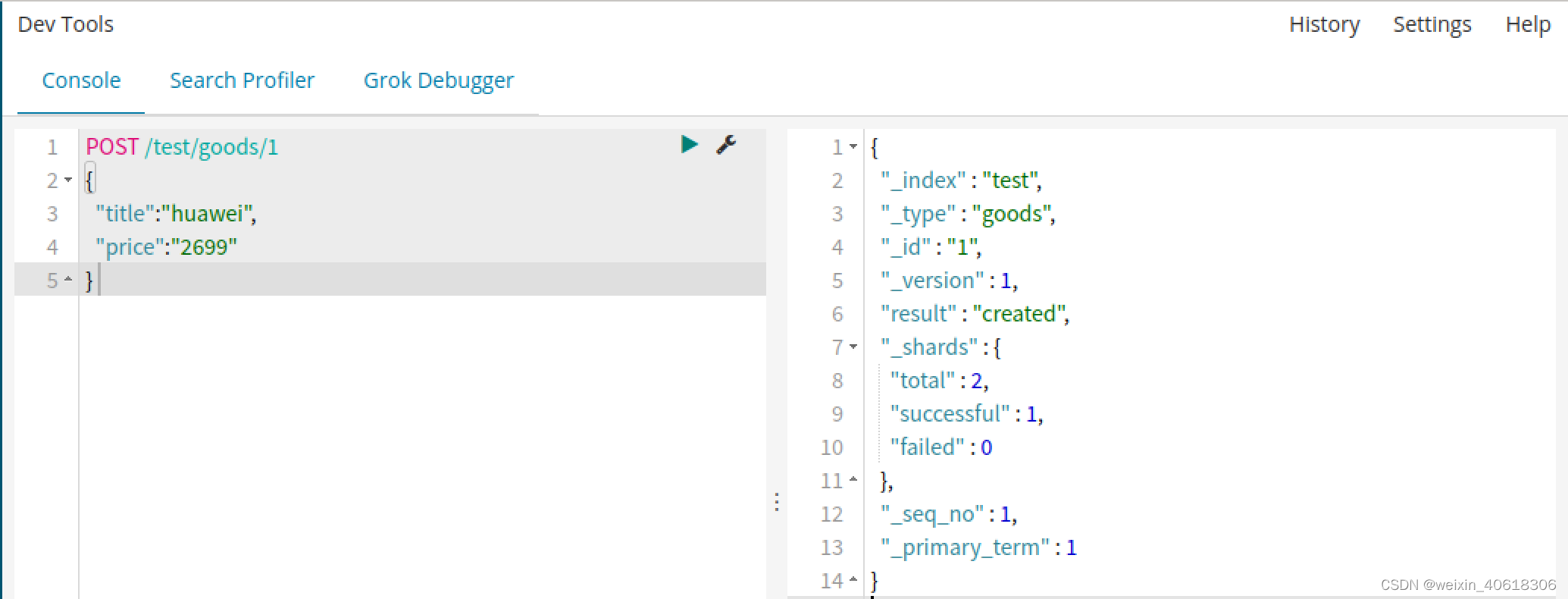
智能判断
在学习Solr时我们发现,我们在新增数据时,只能使用提前配置好映射属性的字段,否则就会报错。不过在Elasticsearch中并没有这样的规定。
事实上Elasticsearch非常智能,你不需要给索引库设置任何mapping映射,它也可以根据你输入的数据来判断类型,动态添加数据映射。
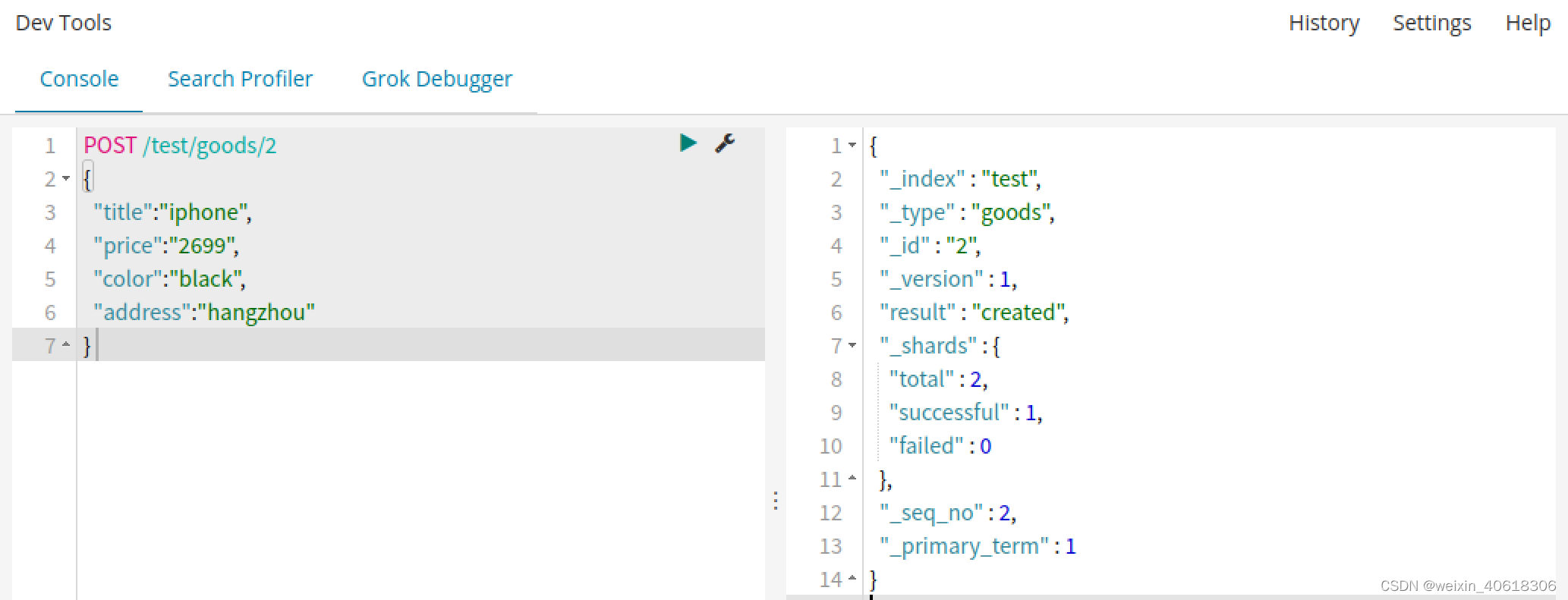
相对上个例子来说,我这里新增了color和address两个字段。再看下索引库的映射关系。
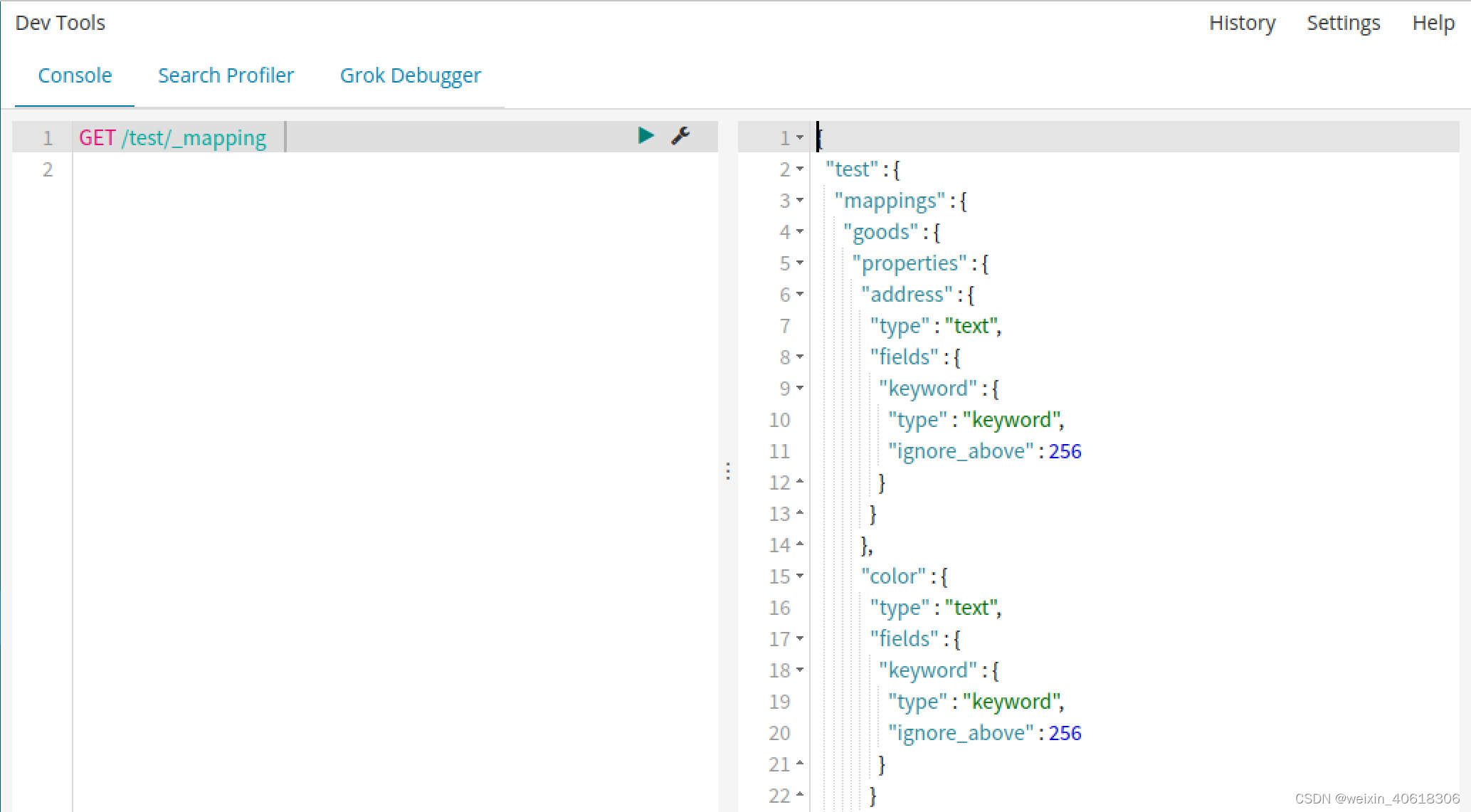
color和address都被成功映射了。
修改数据
把刚才新增的请求方式改为PUT,就是修改数据操作不过修改操作必须要指定id。
- id对应文档存在,则修改
- id对应文档不存在,则新增
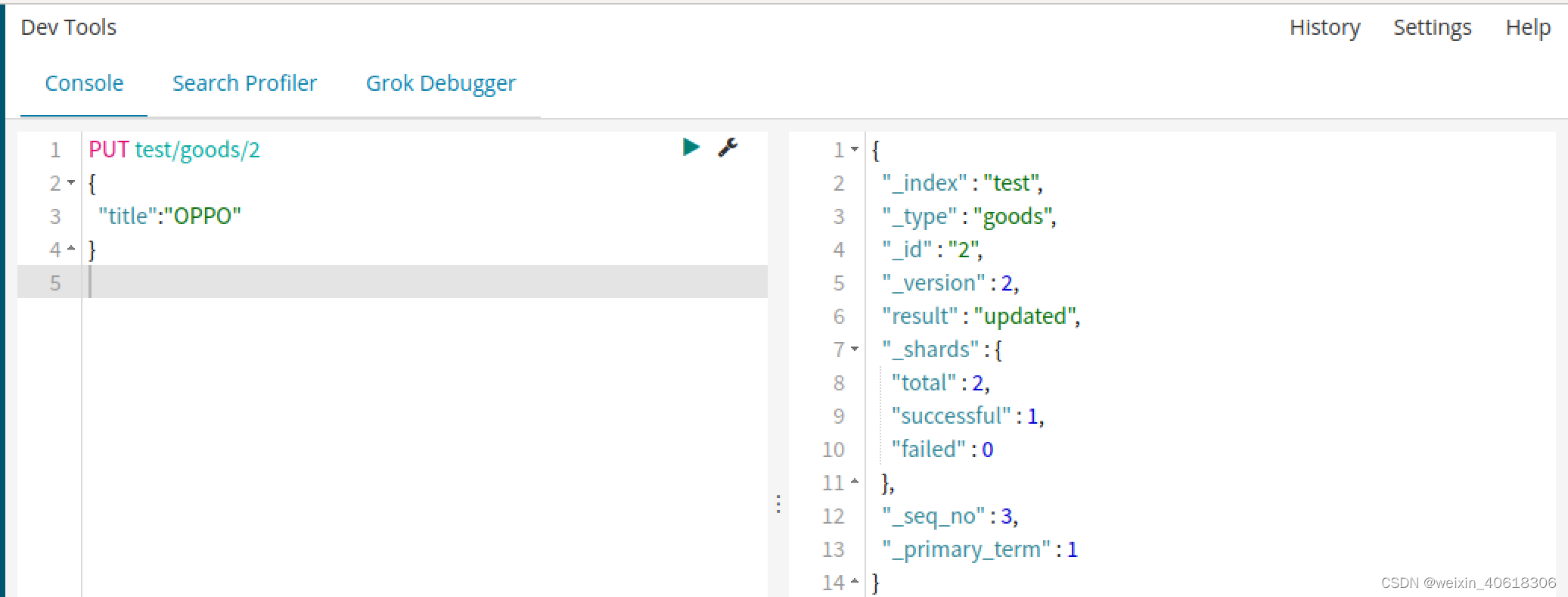
注意:如果只修改了一个字段,那么原有的其他字段都会消失,只保留当前的这次修改,相当于覆盖
删除数据
DELETE test/goods/2
查询
- 基本查询
- _source过滤
- 结果过滤
- 高级查询
- 排序
基本查询
不能设置查询多个条件,如果需要请用后面的高级bool查询
GET /索引库名/_search
{"query":{“查询类型”:{“查询条件”:“查询条件值”}}
}
这里的query代表一个查询对象,里面可以有不同的查询属性
- 查询类型:match_all,match,term,range等等
- 查询条件:查询条件会根据类型的不同,写法也有差异,后面根据示例进行详细讲解。
查询所有(match_all)
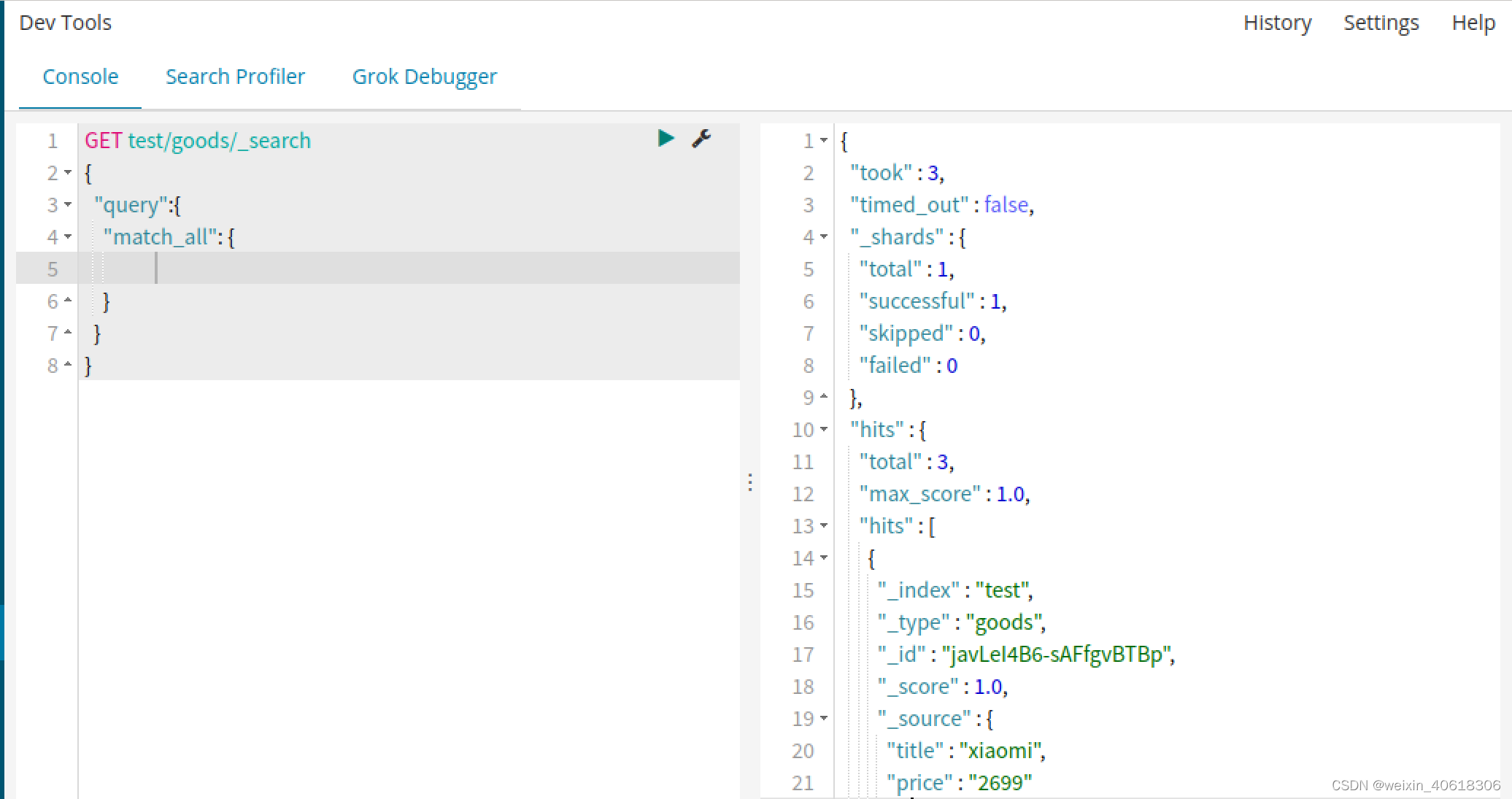
hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息。
- _index:索引库
- _type:文档类型
- _id:文档id
- _score:文档得分
- _source:文档的源数据
匹配查询
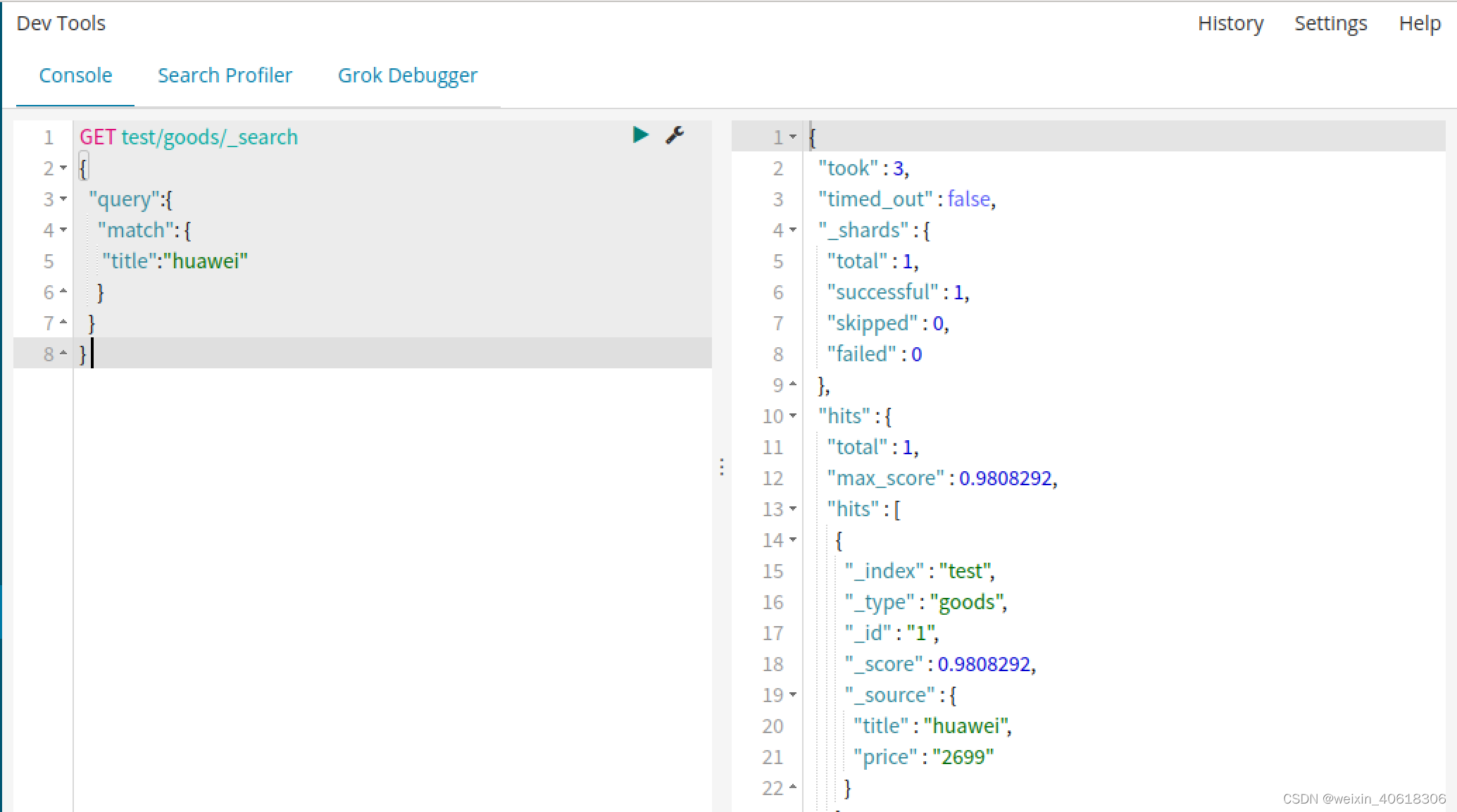
多字段查询
multi_match与match类似,不同的是它可以在多个字段中查询
GET /test/_search
{"query":{"multi_match": {"query": "小米","fields": [ "title", "subTitle" ]}}
在本例中,我们会在title和subtitle字段中查询小米这个词。
词条匹配
term查询被用于精确值匹配
这些精确值可能是数字、时间、布尔或者那些未分词的字符串(keyword)
GET /test/_search
{"query":{"term":{"price":2699.00}}
}多词条精确匹配
terms查询和term查询一样,但它允许你指定多值进行匹配,如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件。
GET /test/_search
{"query":{"terms":{"price":[2699.00,2899.00,3899.00]}}
}
结果过滤
默认情况下,elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。如果我们只想获取其中的部分字段,我们可以添加_source的过滤。
直接指定该字段
GET /heima/_search
{"_source": ["title","price"],"query": {"term": {"price": 2699}}
}
指定includes和excludes
我们也可以通过下面的方法来实现过滤
- includes:来指定想要显示的字段
- excludes:来指定不想显示的字段
GET /test/_search{"_source": {"includes":["title","price"]},"query": {"term": {"price": 2699}}}与下面的结果将是一样的:GET /test/_search{"_source": {"excludes": ["images"]},"query": {"term": {"price": 2699}}}
高级查询
布尔组合(多条件查询)
GET test/goods/_search
{"query": {"bool": {"must": [{"match": {"title": "小米电视"}}],"must_not": [{"match": {"title": "电视"}}]}}
}
查询bool里面结果全为true的情况。
范围查询
range查询找出那些落在指定区间内的数字或者时间,range允许以下操作符。
| 操作符 | 说明 |
|---|---|
| gt | 大于 |
| gte | 大于等于 |
| lt | 小于 |
| lte | 小于等于 |
| 示例: |
GET test/goods/_search
{"query": {"range": {"price": {"gte": 3000,"lte": 9909}}}
}
模糊查询(fuzzy)
fuzzy查询是term查询的模糊等价,它允许用户搜索词条与实际词条的拼写出现偏差,但是偏差的距离不得超过2.
GET /test/_search{"query": {"fuzzy": {"title": "appla"}}}
根据上面的示例,能够查询到apple的结果。我们也可以通过fuzziness来指定允许的编辑距离。
GET /test/_search{"query": {"fuzzy": {"title": {"value":"appla","fuzziness":1}}}}
排序
单字段排序(sort)
sort可以让我们按照不同的字段进行排序,并且通过order指定排序的方式。
示例
GET /test/_search
{"query": {"match": {"title": "小米手机"}},"sort": [{"price": {"order": "desc"}}]
}
sort是对查询后做的,不属于查询和过滤的条件,因此在query查询对象外面。
多字段查询
假定我们想要结合使用price和_score(得分)进行查询,并且匹配的结果首先按照价格排序,然后按照相关性得分排序。
GET test/goods/_search
{"query": {"bool": {"must": [{"match": {"title": "小米"}}]}},"sort": [{"price": {"order": "desc"}},{"_score": {"order": "desc"}}]
}
聚合(aggregations)
聚合可以让我们及其方便的实现对数据的统计分析
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量。
桶(bucket)类似于数据库中的分组group_by
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中被称为一个桶。Elasticsearch中提供的划分桶的方式有很多:
- Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组。
- Histogram Aggregation:根据数值阶梯分组,与日期类似;
- Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组;
- Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按照阶段分组。
- …