不是新文章哈,就是最近要看下思维链(chain of thought,CoT)这块,然后做点review。
文章链接(2022年):https://arxiv.org/pdf/2210.09261.pdf
GitHub链接:GitHub - suzgunmirac/BIG-Bench-Hard: Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
大家都知道出了大语言模型以后呢,最重要的一件事情就是做测评,因为只有测评过关才能对外说我这个模型多么多么厉害,在所有公认测评任务里排第一。Big Bench则是一个有着非常多样任务(24个task)的测试数据集(GitHub - google/BIG-bench: Beyond the Imitation Game collaborative benchmark for measuring and extrapolating the capabilities of language models),GitHub上面是这么介绍的:
The Beyond the Imitation Game Benchmark (BIG-bench) is a collaborative benchmark intended to probe large language models and extrapolate their future capabilities.
Big Bench的论文链接:https://arxiv.org/abs/2206.04615
今天的这个论文主要讲的是,研究人员发现,当使用chain-of-thought prompting的时候,大语言模型PaLM和CodeX在一些Big Bench的任务上是可以有一定的效果提升的。所谓思维链,就是思考步骤或者体现一定逻辑性的思考步骤,文章给出了两个示例分别是answer only 和CoT prompting:
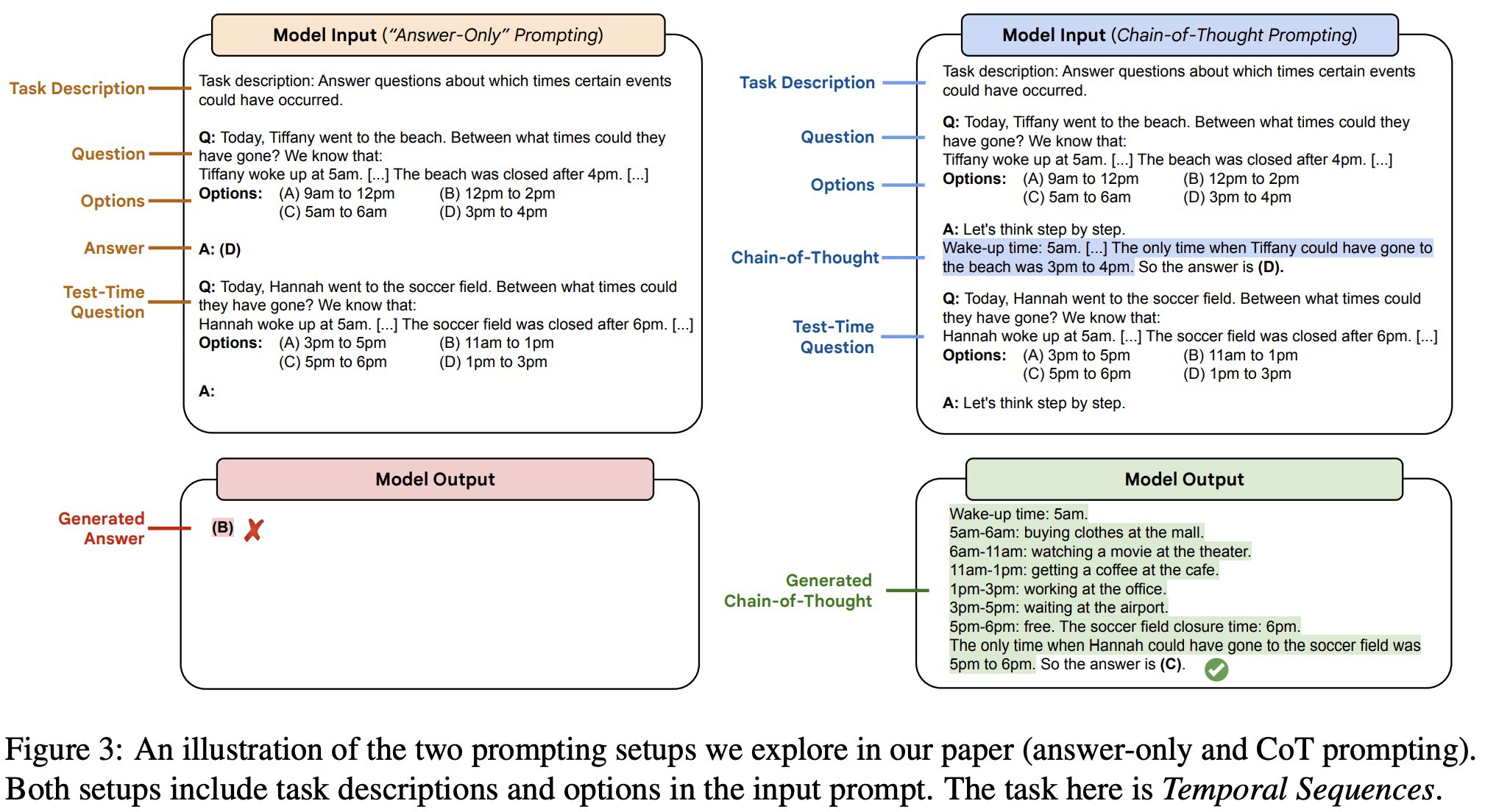
可以看到在进行模型输入的时候,任务描述、问题、选项以及测试问题的描述都是一模一样的,唯一不同的在于Answer的形式。在CoT中,Answer都以“Let's think step by step”作为开头,在示例数据的 answer中,还给出了step by step的逻辑,以及最终答案。在做测试的时候,作者们比较了few-shot prompting以及带着CoT的few-shot prompting。结果肯定是CoT在多个任务上比answer only(AO)好:
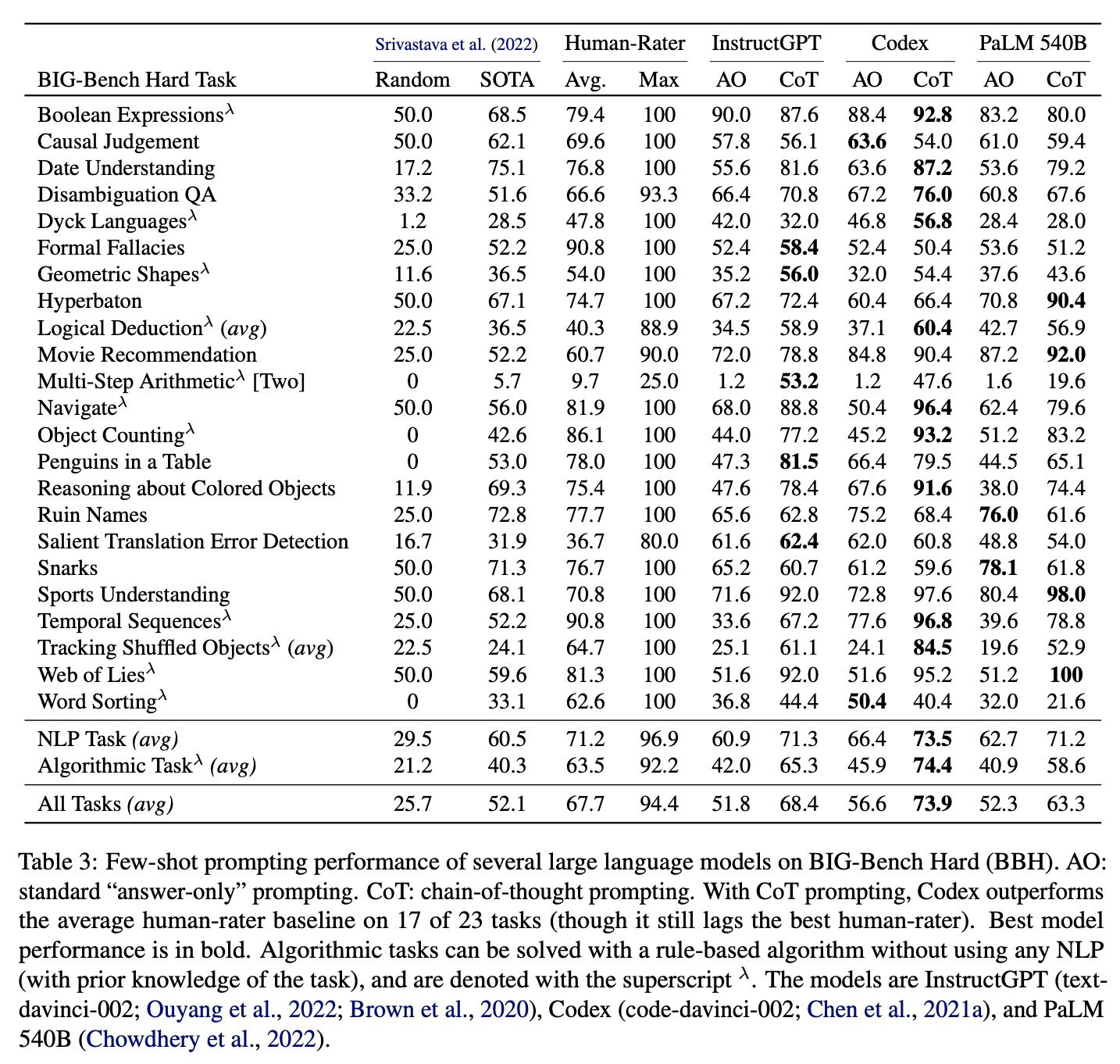
不过这边文章,我觉得耗费精力和人力的是CoT该怎么写!!!看起来作者可是一条一条把思维链写了一遍的,要不然怎么做测评呢!并且作者在所有的CoT注释前都加了一句话let’s think step-by-step!
We manually write CoT exemplars for BBH
We prepend “let’s think step-by-step” (Kojima et al., 2022) to all CoT annotations in the few-shot exemplars.
好的,读完了这篇文章,知道CoT有效了。就是在具体任务上怎么写是个问题。所以大家一定要去看这篇文章的Github!!!里面有不同任务写CoT的例子。