目录:sheng的学习笔记-AI目录-CSDN博客
需要学习卷机神经网络等知识,见ai目录
目录
基础知识:
人脸验证(face verification)
人脸识别(face recognition)
One-Shot学习(One-shot learning)
困难点:
编辑
传统的解决办法
解决方案-Similarity函数
Siamese 网络(Siamese network)
Triplet 损失
triplet训练集的选择
编辑
人脸验证与二分类(Face verification and binary classification)
提升部署效果的技巧
参考文章:
基础知识:
人脸验证(face verification)
如果你有一张输入图片,以及某人的ID或者是名字,这个系统要做的是,验证输入图片是否是这个人。有时候也被称作1对1问题,只需要弄明白这个人是否和他声称的身份相符
人脸识别(face recognition)

最大的难度就是,你提供了一个照片,ai程序如何通过一个照片,判断当前显示器捕捉的头像,和照片中的是否一个人,因为ai是给予海量数据训练出的模型,但目前仅有一个照片,用传统的ai模型,显然无法达到目的
One-Shot学习(One-shot learning)
困难点:

假设你的数据库里有4张你们公司的员工照片,实际上他们确实是我们deeplearning.ai的员工,分别是Kian,Danielle,Younes和Tian。现在假设有个人(编号1所示)来到办公室,并且她想通过带有人脸识别系统的栅门,现在系统需要做的就是,仅仅通过一张已有的Danielle照片,来识别前面这个人确实是她。相反,如果机器看到一个不在数据库里的人(编号2所示),机器应该能分辨出她不是数据库中四个人之一
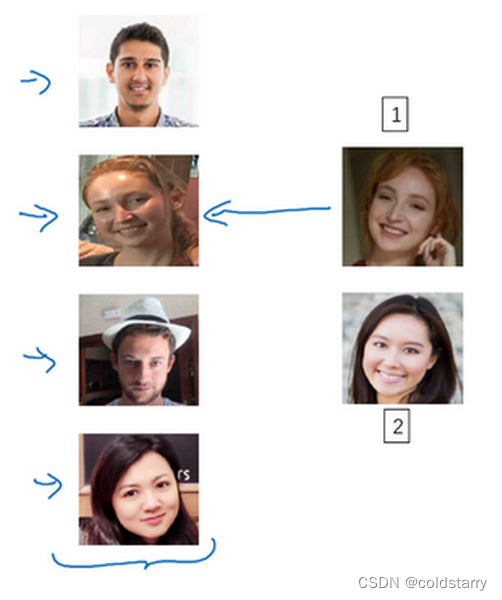
所以在一次学习问题中,只能通过一个样本进行学习,以能够认出同一个人。大多数人脸识别系统都需要解决这个问题,因为在你的数据库中每个雇员或者组员可能都只有一张照片。
传统的解决办法
有一种办法是,将人的照片放进卷积神经网络中,使用softmax单元来输出4种,或者说5种标签,分别对应这4个人,或者4个都不是,所以softmax里我们会有5种输出。但实际上这样效果并不好,因为如此小的训练集不足以去训练一个稳健的神经网络。
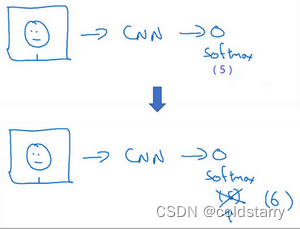
而且,假如有新人加入你的团队,你现在将会有5个组员需要识别,所以输出就变成了6种,这时你要重新训练你的神经网络吗?这听起来实在不像一个好办法。
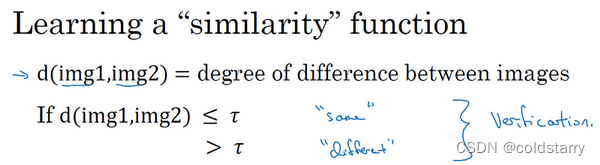
解决方案-Similarity函数


Siamese 网络(Siamese network)
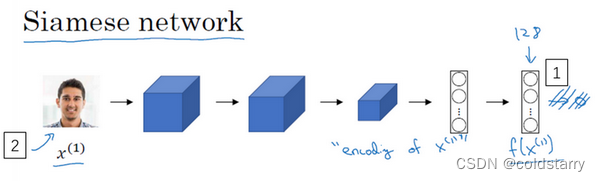
这是个常见的卷积网络,根据输入x,通过一些列卷积,池化和全连接层,最终得到这样的特征向量,有时这个会被送进softmax单元来做分类,但这次我们不这样做。
对于编号1和编号2 ,都会生成128维的向量f(x1)和f(x2)

对于两个不同的输入,运行相同的卷积神经网络,然后比较它们,这一般叫做Siamese网络架构
 x
x


Triplet 损失
要想通过学习神经网络的参数来得到优质的人脸图片编码,方法之一就是定义三元组损失函数然后应用梯度下降。

为了应用三元组损失函数,你需要比较成对的图像,比如这个图片,为了学习网络的参数,你需要同时看几幅图片,比如这对图片(编号1和编号2),你想要它们的编码相似,因为这是同一个人。然而假如是这对图片(编号3和编号4),你会想要它们的编码差异大一些,因为这是不同的人。
用三元组损失的术语来说,你要做的通常是看一个 Anchor 图片,你想让Anchor图片和Positive图片(Positive意味着是同一个人)的距离很接近。然而,当Anchor图片与Negative图片(Negative意味着是非同一个人)对比时,你会想让他们的距离离得更远一点


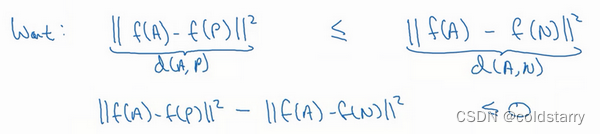





三元组损失函数的定义基于三张图片,假如三张图片A、P、N,即Anchor样本、Positive样本和Negative样本,其中Positive图片和Anchor图片是同一个人,但是Negative图片和Anchor不是同一个人。


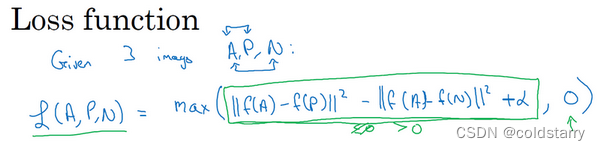


这是一个三元组定义的损失,整个网络的代价函数应该是训练集中这些单个三元组损失的总和。假如你有一个10000个图片的训练集,里面是1000个不同的人的照片,你要做的就是取这10000个图片,然后生成这样的三元组,然后训练你的学习算法,对这种代价函数用梯度下降,这个代价函数就是定义在你数据集里的这样的三元组图片上。
注意,为了定义三元组的数据集你需要成对的A和P,即同一个人的成对的图片,为了训练你的系统你确实需要一个数据集,里面有同一个人的多个照片。这是为什么在这个例子中,我说假设你有1000个不同的人的10000张照片,也许是这1000个人平均每个人10张照片,组成了你整个数据集。如果你只有每个人一张照片,那么根本没法训练这个系统。当然,训练完这个系统之后,你可以应用到你的一次学习问题上,对于你的人脸识别系统,可能你只有想要识别的某个人的一张照片。但对于训练集,你需要确保有同一个人的多个图片,至少是你训练集里的一部分人,这样就有成对的Anchor和Positive图片了
triplet训练集的选择

选择A和P的差异比较大的图片进行训练,看下面,虽然A和P是一个人,但照片风格差异比较大,逼迫网络对于相同人的识别敏感度增加
总结一下,训练这个三元组损失你需要取你的训练集,然后把它做成很多三元组,这就是一个三元组(编号1),有一个Anchor图片和Positive图片,这两个(Anchor和Positive)是同一个人,还有一张另一个人的Negative图片。这是另一组(编号2),其中Anchor和Positive图片是同一个人,但是Anchor和Negative不是同一个人,等等。

人脸验证与二分类(Face verification and binary classification)
Triplet loss是一个学习人脸识别卷积网络参数的好方法,还有其他学习参数的方法,让我们看看如何将人脸识别当成一个二分类问题。
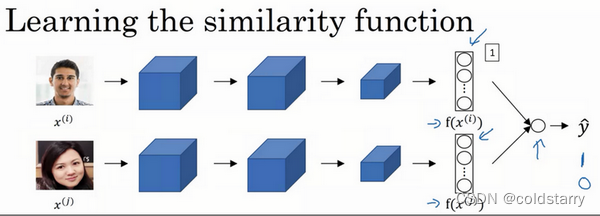
另一个训练神经网络的方法是选取一对神经网络,选取Siamese网络,使其同时计算这些嵌入,比如说128维的嵌入(编号1),或者更高维,然后将其输入到逻辑回归单元,然后进行预测,如果是相同的人,那么输出是1,若是不同的人,输出是0。这就把人脸识别问题转换为一个二分类问题,训练这种系统时可以替换Triplet loss的方法。



总结一下,把人脸验证当作一个监督学习,创建一个只有成对图片的训练集,不是三个一组,而是成对的图片,目标标签是1表示一对图片是一个人,目标标签是0表示图片中是不同的人。利用不同的成对图片,使用反向传播算法去训练神经网络,训练Siamese神经网络。

提升部署效果的技巧
一个计算技巧可以帮你显著提高部署效果,如果这是一张新图片(编号1),当员工走进门时,希望门可以自动为他们打开,这个(编号2)是在数据库中的图片,不需要每次都计算这些特征(编号6),不需要每次都计算这个嵌入,你可以提前计算好,那么当一个新员工走近时,你可以使用上方的卷积网络来计算这些编码(编号5),然后使用它,和预先计算好的编码进行比较,然后输出预测值。
因为不需要存储原始图像,如果你有一个很大的员工数据库,你不需要为每个员工每次都计算这些编码。这个预先计算的思想,可以节省大量的计算,这个预训练的工作可以用在Siamese网路结构中,将人脸识别当作一个二分类问题,也可以用在学习和使用Triplet loss函数上
参考文章:
吴恩达的神经网络教程