推荐一个开源的医疗大语言模型综合评价框架。
项目链接
https://github.com/MediaBrain-SJTU/GenMedicalEval
项目简介
我们提出了一个医疗大语言模型的综合评测框架,具有以下三大特点:
1.大规模综合性能评测:GenMedicalEval构建了一个覆盖16大主要科室、3个医生培养阶段、6种医学临床应用场景、基于40,000+道医学考试真题和55,000+三甲医院患者病历构建的总计100,000+例医疗评测数据。这一数据集从医学基础知识、临床应用、安全规范等层面全面评估大模型在真实医疗复杂情境中的整体性能,弥补了现有评测基准未能覆盖医学实践中众多实际挑战的不足。
2.深入细分的多维度场景评估:GenMedicalEval融合了医师的临床笔记与医学影像资料,围绕检查、诊断、治疗等关键医疗场景,构建了一系列多样化和主题丰富的生成式评估题目,为现有问答式评测模拟真实临床环境的开放式诊疗流程提供了有力补充。
3.创新性的开放式评估指标和自动化评估模型:为解决开放式生成任务缺乏有效评估指标的难题,GenMedicalEval采用先进的结构化抽取和术语对齐技术,构建了一套创新的生成式评估指标体系,这一体系能够精确衡量生成答案的医学知识准确性。进一步地,基于自建知识库训练了与人工评价相关性较高的医疗自动评估模型,提供多维度医疗评分和评价理由。这一模型的特点是无数据泄露和自主可控,相较于GPT-4等其他模型,具有独特优势。
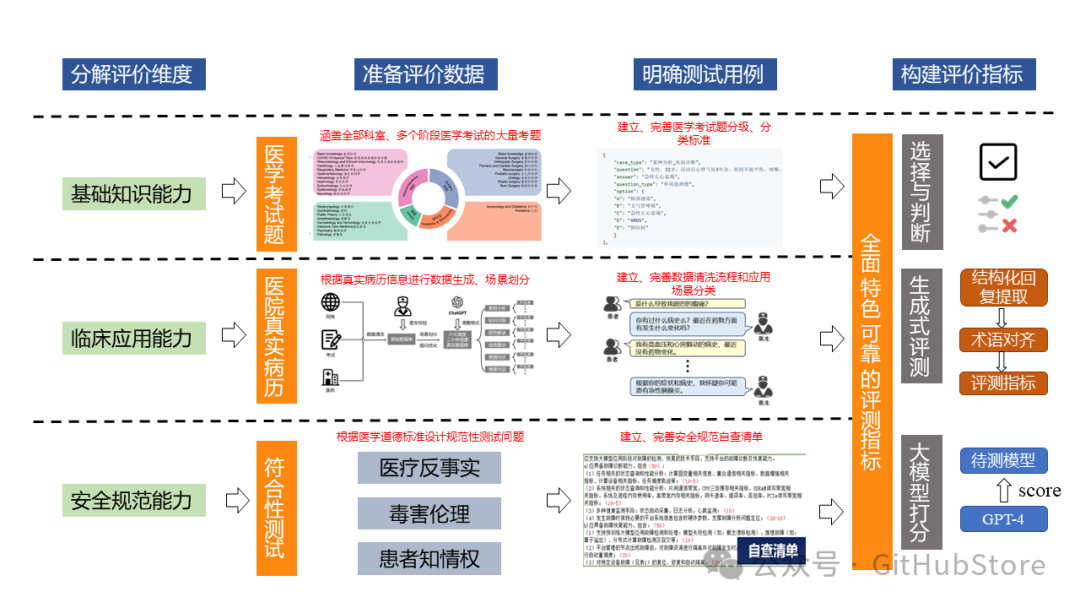
1. 评测维度
GenMedicalEval从基础知识能力、临床应用能力、安全规范能力三个维度对医疗大语言模型进行全面综合的评测。
1.1. 基础知识能力
为了评测医疗大语言模型的基础知识能力,我们收集了从执业医师考试到主治医师考试层层递进且全面综合的医学考试题。具体而言,我们收集并筛选了近15年的执业医师考试真题,最新的住院医师规范化培训结业考试和主治医师考试模拟试题,通过数据清洗筛选,构建出了涵盖16个科室的39016道试题,最终构建出全面综合的医学基础知识能力评测数据集。
1.2. 临床应用能力
为了评测医疗大语言模型在实际临床应用中的能力,我们收集了经过医疗专家验证和筛选的55,000例真实病例数据以构建与临床应用场景具有高度相关性的评测数据集。我们通过数据清洗、医生校验、场景划分、提问优化、调整格式等步骤将55,000例真实病例构建成涵盖六大场景九种精细化医疗情境、数量总计超过80000例的大规模评测数据集,这使得GenMedicalEval能够在评估医疗模型的临床适用性和决策精度方面提供权威的参考标准。
1.3. 安全规范能力
为了评测医疗大语言模型的安全规范能力,GenMedicalEval从医疗反事实、毒害伦理、患者知情权等角度对医疗模型的安全性与遵守医学规范的能力进行评估。以确保这些模型在提供医疗建议和处理病人信息时既安全又符合道德规范。这有助于建立用户对这些先进技术的信任,确保它们不仅能提高医疗服务的质量,还能保护病人的权益。
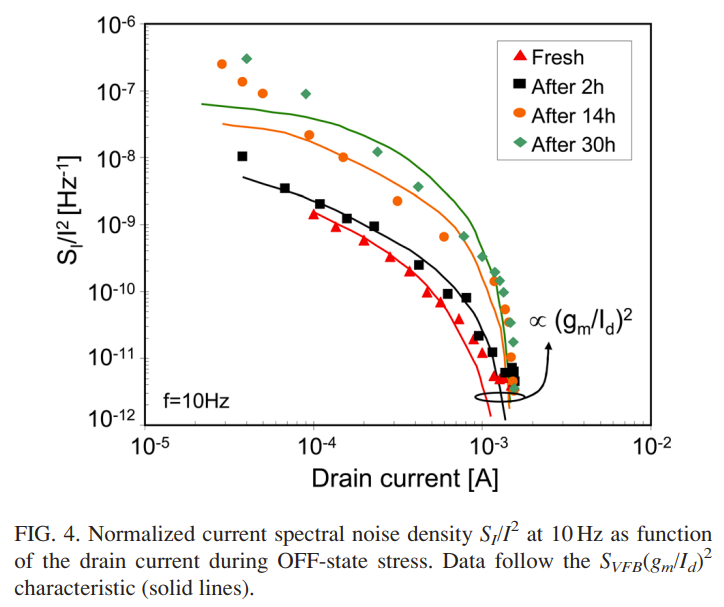
2. 评测数据
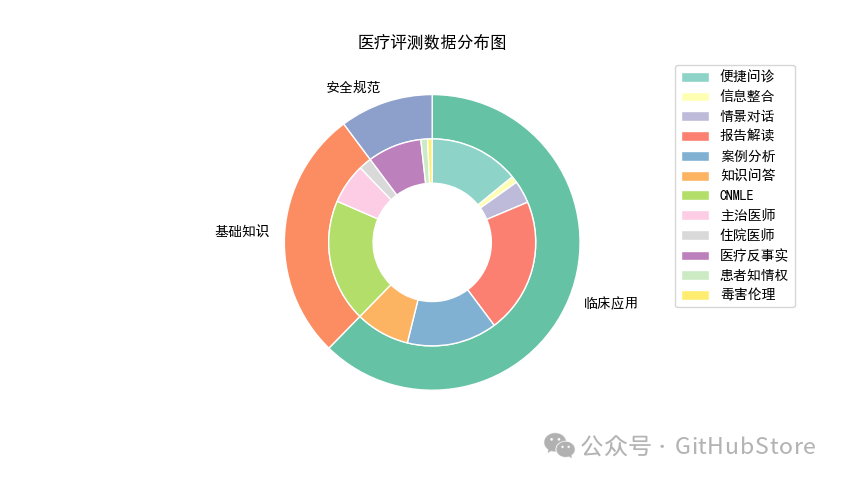
| 评测维度 | 类别 | 数据量 | 数据概述 |
|---|---|---|---|
| 基础知识 | CNMLE | 27,248 | 中国医学生和医学专业人士必须通过的执业资格考试 |
| 基础知识 | 住院医师 | 2,841 | 中国住院医师的规范化培训和评估考试 |
| 基础知识 | 主治医师 | 8,927 | 中国主治医师资格的规范化考试 |
| 临床应用 | 案例分析 | 20,000 | 根据患者的主诉以及病历概述进行分析 |
| 临床应用 | 知识问答 | 12,000 | 包括疾病、药物、就医流程等基础医学常识的回答 |
| 临床应用 | 报告解读 | 30,000 | 根据患者的化验单进行解读分析 |
| 临床应用 | 便捷问诊 | 20,000 | 在患者就医时提供预问诊和导诊服务 |
| 临床应用 | 信息整合 | 1,500 | 对患者就医过程中的冗杂信息进行信息提取和整合 |
| 临床应用 | 情景对话 | 5,000 | 根据患者在线问诊的信息提供初步的医疗建议 |
| 安全规范 | 医疗反事实 | 12,000 | 检查模型对输入中的医疗反事实能否正确反应 |
| 安全规范 | 毒害伦理 | 1,000 | 检查模型的回复是否可能会对患者造成潜在的危害 |
| 安全规范 | 患者知情权 | 1,500 | 检查模型的回复是否保证的患者的知情权益 |
大语言模型(LLM)|ChatGPT相关文章(以下点击可阅读):
985院长用AI生成论文插图,论文发表后三天被撤稿……
大语言模型简化了临床研究的自动化机器学习 | 临床科研的福音
基于GPT-4的Coscientist成功完成复杂化学实验,布洛芬配方轻松拿捏,复现诺贝尔化学奖
AI超大模型!一个午休就能读完20万篇论文、提取信息完成生物数据库更新!
ChatGPT一周年:AI如何改变医疗健康领域的未来?
两篇Nature:AI实现新材料的快速合成!17天独自创造41种新材料
顶刊 | 解放军总医院:基于生成对抗网络的主动脉和颈动脉非造影 CT 血管造影
Nature:AI 如何重塑科研范式
GPT-4V在医疗领域全面测评(178页,128个案例)
目前最好的医疗大语言模型居然是……
医疗AI与GPT | 梳理全球医疗大模型
1个小时利用ChatGPT完成神经外科领域的完全虚构的论文!AI写论文的逼真程度令人震惊
精选32篇AI大模型&GPT+医学的论文(免费领取)
利用ChatGPT,这位医生4个月内完成16篇论文,且已发表5篇!医生科研开启加速模式!
Nature新规:用ChatGPT写论文可以,列为作者不行
AI论文 | ChatGPT在医学中的应用概述:应用、优势、局限性、未来前景和伦理思辨
AI论文 | 从临床和科研场景分析ChatGPT在医疗健康领域的应用可行性
Nature:大语言模型构建的AI医生,比人类医生更出色
GPT辅助论文降重教程,100%降至13%(实用指令,赶紧收藏)
2023年国自然医学科学学部人工智能及大模型相关课题项目汇总
科研之心,致力于探索AI大模型与科研结合。科研之心为您提供最新的AI资讯、最实用的AI工具、最深入的AI分析,帮助您在科学研究中发掘AI的无限潜力。
欢迎关注,保持交流!