音频编程时游戏开发中最容易忽略,学习资源又是很少的环节。接下来,你将和我探索人耳的工作机制。
what is sound?
我们可以解释电视机是如何通过眼睛传递视觉信息的,但却往往无法对听觉信息做出类似的解释。
对声音的科学研究被称为声学,美国国家标准学会将其定义为 "关于声音的科学,包括对声音的产生,传播和影响。生物和心理影响。大多数与人类相关的声音物理特性都可以通过声波方程模拟为弹性介质中的波。但也有一些有趣的例外情况,如长号和超音速飞机,这两种飞机对空气的压缩足以产生显著的非线性。
与所有波现象一样,声音可以通过衍射、干涉、反射和折射等方式相互作用。考虑到声速(约 340 米/秒)和人类能听到的频率(稍后详述),墙壁、椅子和杯子等日常物品都能产生所有这些相互作用。这些相互作用的数量和复杂性使得精确模拟音频传输比模拟人类感知频率的光更为困难。
全面解释物理声学远远超出了本章的范围。 但我将为有兴趣了解更多信息的读者提供一段历史和参考资料。
对声音物理学的最早书面探索可以追溯到希腊人。毕达哥拉斯和亚里士多德都花了大量时间从物理和音乐的角度研究和撰写有关振动弦性质的文章。文艺复兴为我们对声音物理学的理解带来了许多进步。物理声学的现代参考书目有《物理声学基础》和《理论声学》。
直到十九世纪,亥姆霍兹等人的著作《论音调感觉作为音乐理论的生理基础》才出版了第一部将声音作为一种生理和心理现象进行研究的详尽著作。二十世纪,人们对耳朵的功能和大脑对声音的感知有了极大的了解。这一研究领域被称为心理声学,它直接造就了现代科技的奇迹,如 mpeg 音频压缩和当今令人惊叹的助听器。
声学中最重要的一个概念就是频率。频率的定义是重复现象在一定周期内重复的次数;在音频中,频率的单位是赫兹,用来衡量每秒的重复次数。频率之所以特别有用,是因为任何带限信号都可以通过傅立叶变换分解为一定数量的纯音(正弦波)。在分析或修改信号时,将信号视为可线性分离的简单部分的有限总和,而不是复杂的整体,是非常有用的。您的听觉也是这样认为的:耳朵最重要的行为就是分离频率。
How Do We Hear Audio?
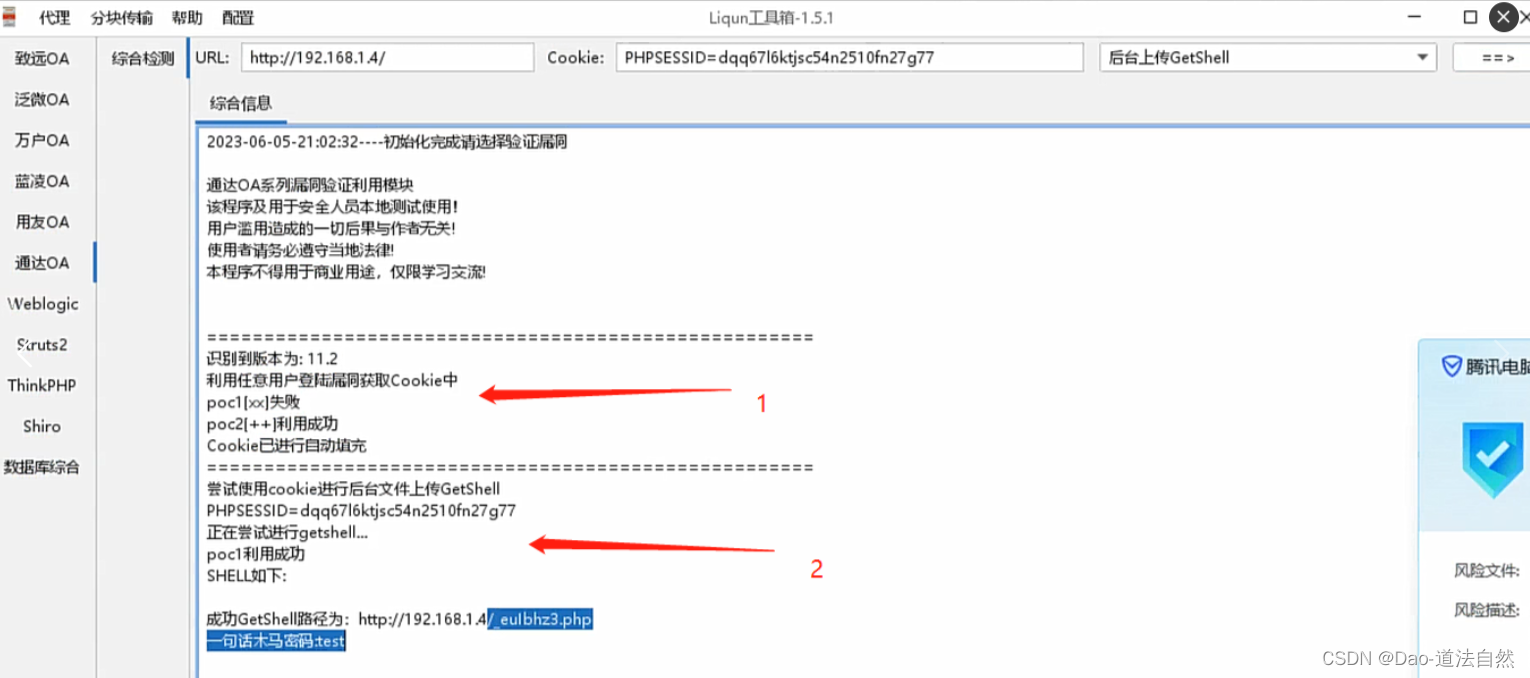
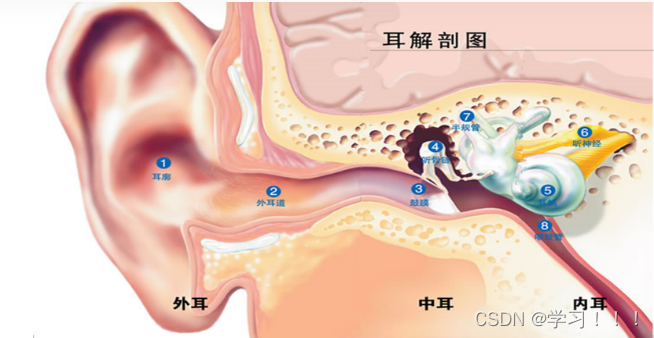
声音无处不在。无论我们走到哪里,都会被振动的空气所包围。这些声波与我们的头部和耳廓(耳朵从头部伸出的部分)相互作用,并被导入耳道。在耳道中,电波会使鼓膜(一层薄薄的膜)产生与空气压力成比例的位移。这层膜将压力振动传导到一组骨骼,这些骨骼就像杠杆一样将振动传递并放大到耳蜗。
耳蜗是一个复杂的器官,是一个自适应降噪压频探测器。它的外形是一个卷起的圆锥体,内部的毛细胞沿长度方向排列。耳蜗的尺寸就像一种滤波器,在锥体上的每一点都有不同的频率响应。这种频率响应差异导致耳蜗长度方向上每一点的振动都不同(音调映射)。沿着耳蜗长度方向存在着成千上万个毛细胞,它们通过将振动传导到毛囊来充当信号检测器,从而将物理振动转换成神经系统中的电脉冲。这些信号在耳蜗和大脑中经过处理,形成我们对声音的感知。图 显示了人耳各部分的示意图。
《听觉心理学导论》是一本关于这一主题的极好的入门参考书,它以更深的深度涵盖了本节中介绍的大部分内容。我认为,无论是否从事音频技术工作,这本书都是必读书。更深入的书籍是同名的《心理声学》。
Dynamic Range
我们的听力有一个惊人的事实,那就是耳朵的动态范围。人类听力的范围约为 120 分贝(dB)。分贝是一个对数单位,用来表示两个数值的比值。当用于测量声压级时,比率中的参考电平是人类能听到的最安静的声音。耳朵实现这一目标的主要方式是通过骨头将信号从鼓膜传输到耳蜗。它们能够动态地重新配置,根据传入的信号实时调整增益。
Spatial Hearing(空间听力)
人类能够辨别声音的方向,主要是由于头部和耳朵的几何形状。大脑用于辨别方向的两个物理线索是耳际时差(ITD)和头部相关传递函数(HRTF)。
声音的移动速度很慢,以至于你的大脑可以测量出声音波到达一侧耳朵与到达另一侧耳朵之间的时间延迟。 声音波到达一侧耳朵与到达另一侧耳朵之间的时间差。这个时间差称为 ITD。如果声音在人的正前方,延迟时间为零,因为声波会同时击中两只耳朵。当声音向一侧移动时,这一延迟会随着声音到两耳距离的变化而变化。这是大脑对声音相对于头部前方的角度的主要提示。
头部和耳廓的结构就像一个滤波器,可根据信号的角度改变频率响应。例如,如果声音通过耳廓传播,高频率的功率就会减弱。我们可以通过为每只耳朵定义一个滤波器来模拟这些效果,该滤波器的频率响应因声音与耳朵的入射角度不同而不同。这种基于角度的滤波器就是 HRTF。大脑通过分析信号的频率响应来推断方向信息。这是一种学习行为,因为每个人耳朵的具体形状会影响 HRTF,因此不同个体的 HRTF 会有很大差异。
提供给大脑的信息不足以让大脑分辨出所有传入声音的角度。这种模糊性形成了一个锥形,被恰当地称为 "混淆锥"。大脑会利用其他感官的输入(例如,将声源与视觉输入相匹配)和上下文知识(例如,直升机很少在人的脚下)来帮助缩小声音的实际方向。
《 Spatial Hearing 》一书对此进行了详尽的评述。
Reflections
我们周围的环境主要通过反射与我们的声音环境相互作用。当声波与表面相互作用时,表面会反射声波。在频率较高、表面光滑的情况下,反射的原理与镜面反射很相似。反射包含大量有关周围环境的信息。反射的结构是大脑了解听者与声音之间距离的主要线索。它还能让我们估计周围环境的大小。
反射还会干扰更重要的信号,因此耳朵会忽略某些反射。当一个声音后面紧跟着另一个声音时,大脑只会使用第一个声音来判断声音的方向。这就是所谓的 "优先效应"。
Time and Sensory Fusion (时间与感官的融合)
人类对时间的感知是非直觉性的。例如,有文献记载,一个刺激会改变对先前接收到的刺激的感知,这显然违反了我们的因果关系概念。在所谓的 "感觉融合 "方面,已经进行了大量有趣且与游戏极其相关的研究。这是一项关于两个刺激需要接近到什么程度,大脑才会认为它们是同一物理原因的一部分的研究。例如,两个音频脉冲的距离有多近,大脑仍能将它们区分为不同的声音(约 5 毫秒);声音与某人说话的视频在时间上的距离有多远,听者才会不再将声音和音频视为一体(唇音同步)。这个特殊的例子显示了心理声学中常见的复杂性,因为唇音同步的时间并不对称。如果音频领先于视觉,而不是相反,您就会发现同步偏离的时间间隔要短得多。不同人群的灌注感差异很大,最准确和最不准确的人之间可能相差五倍之多。音乐家和其他受过正规音频训练的人往往比普通人的阈值低得多。我过于简化的唇音同步经验法则是将音频保持在视频的 50 毫秒以内。音频轶事》中 "可感知的听觉延迟 "一章: 数字音频的工具、技巧和技术》11 中的 "可感知的听觉延迟 "一章对与感觉融合有关的研究进行了出色的概述,任何从事交互式音频工作的人都应该熟悉这些研究。
Frequency
听觉的第一近似值是窗口时间频率转换器。窗口式的意思是它只关注一小部分时间。耳朵可以精确地检测到大约 20 赫兹到最多 20 千赫兹的频率。间距类似于指数,因此耳朵的精确度(以赫兹为单位)会随着音调的增加而降低。为了更接近耳朵的音高空间,人们开发了许多单位,如 Mel、Bark 和 ERB。
Masking
我们听觉最引人注目的能力之一,就是能够根据同一信号的时频内容过滤掉信号中的频率内容。概括地说,就是响亮的声音会让较安静的声音听不见。具体细节相当复杂,超出了本文的讨论范围。掩蔽模型是有损音频压缩算法(如 mpeg)用来减少存储音频信息量的方法,因为耳朵会移除的任何信号都无需保留在压缩音频中。
为了说明这种复杂性的特点,我将举两个掩蔽行为的例子。首先,较小的宽带声音可以掩盖较大的纯音声音(频率掩蔽)。这在游戏中很常见,因为枪声和爆炸声是非常常见的声音。这些声音的频带极宽,这意味着它们在几乎所有可感知的频率上都有威力。正因为如此,它们能非常有效地掩盖局部频率较高的声音。根据我的经验,一种几乎听不见的宽带声音(通常是爆炸声)会导致其他各种声音变得听不见,这种情况很常见。仅仅移除大的爆炸噪音就会使其他声音变得嘈杂,而且由于其他声音不再被掩盖,往往会使整个场景显得更加响亮。
另一个例子是,一个声音在另一个声音之后出现,会导致在时间上先出现的声音听不见(时间掩蔽)。在 100 毫秒左右的感知中,因果关系是一个模糊的量。
HOW IS AUDIO REPRESENTED,PROCESSED, AND REPRODUCED?(音频是如何表现、处理和再现的?)
一维物理属性可以用来表示某一时刻的空气压力。如果该属性随时间变化,它可以表示音频。常见的例子包括电压(最常见的模拟信号)、电流(动态麦克风)、光透射率(胶片)、磁定向(磁带)和物理位移(唱片)。所选的属性随时间变化以表示随时间变化的压力。在存储介质中,时间通常用长度来表示(磁带、光学、唱片)。在许多声音模拟中,时间是由时间本身来表示的(例如,通过电缆的电压)。
大部分源音频都是通过麦克风录制的物理声音。麦克风将气压转化为其中一种压力模拟信号(电压和电流是最常见的两种)。扬声器将电流或电压(几乎总是电流)转换为气压。
在游戏中(以及在所有数字音频处理中),处理声音的通用表示法是脉冲编码调制,或称 PCM。这种表示法由一串整数组成,以等间隔的时间表示声压。
与所有近似方法一样,数字表示法并不完美。由于我们是用固定大小的整数来捕捉连续量,因此量化会造成信息损失。用于表示压力的整数的比特大小称为(bit depth)比特深度。最常用的位深度是 16 位。以固定速率采样也会造成信息损失,但具体情况难以量化。
尼奎斯特-香农采样定理是了解采样如何影响信号的最有力工具之一。这一理论略显简单,它指出,对于带限信号,需要以其最高频率的两倍以上的速率进行采样,才能正确重建信号。奈奎斯特以上的高频成分会反射到采样信号带宽内的频率上,这种现象被称为混叠。从音频角度来看,混叠听起来很不自然,一般应避免。 许多书籍中都有这方面的内容。我最喜欢的一本书是《 数字信号处理的理论与应用》。
几乎所有音频数字信号处理 (DSP) 都是通过对这些整数序列进行基本运算(+、-、∗)来完成的。这也是一个涵盖广泛的巨大课题。我强烈推荐 Julius O. Smith III 的音频 DSP 系列丛书,这套书既有在线版,也有印刷版。
CONCLUSION
听觉是一种复杂的感觉,有时并不直观。要想在视频游戏音频技术和艺术上取得成功,就必须了解其特殊性。要掌握与游戏编程相关的音频知识,需要具备物理学、心理学和信号处理等领域的大量知识。
1. American Standards Association. 1960. Acoustical terminology SI, 1–1960.New York: American Standards Association.
2. Blackstock, David T. 2000. Fundamentals of Physical Acoustics. New York: John Wiley & Sons.
3. Morse, Philip McCord, and K. Uno Ingard. 1968. Theoretical Acoustics.Princeton: Princeton University Press.
4. Helmholtz, Hermann L.F., and Alexander J. Ellis. 2009. On the Sensations of Tone as a Physiological Basis for the Theory of Music. Cambridge: Cambridge University Press.
5. Smith, Julius O. 2007. Mathematics of the Discrete Fourier Transform (DFT): With Audio Applications. W3K.
6. Brockmann, Chittka L. A diagram of the anatomy of the human ear. https://commons.wikimedia.org/wiki/File:Anatomy_of_the_Human_Ear_en.svg licensed under Creative Commons Attribution 2.5 Generic license.
7. Moore, Brian C.J. 2012. An Introduction to the Psychology of Hearing. Leiden,The Netherlands: Brill.