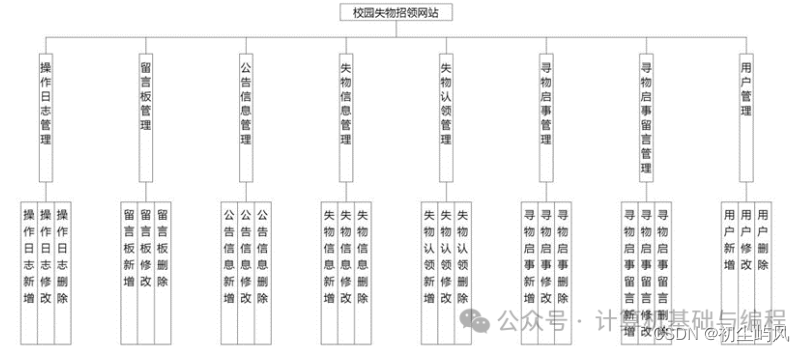
Stable Diffusion核心基础知识和网络结构解析
- 一. Stable Diffusion核心基础知识
- 1.1 Stable Diffusion模型工作流程
- 1. 文生图(txt2img)
- 2. 图生图
- 3. 图像优化模块
- 1.2 Stable Diffusion模型核心基础原理
- 1. 扩散模型的基本原理
- 2. 前向扩散过程详解
- 3. 反向扩散过程详解
- 4. 引入Latent思想
- 1.3 Stable Diffusion训练全过程
- 1. 训练过程简介
- 2. SD训练集加入噪声
- 3. SD训练中加噪与去噪
- 4. 语义信息对图片生成的控制
- 5. SD模型训练时的输入
- 二. SD模型核心网络结构解析
- 2.1 SD模型整体架构初识
- 2.2 VAE模型
- 1. Stable Diffusion中VAE的核心作用
- 2. Stable Diffusion中VAE的高阶作用
- 3. Stable Diffusion中VAE模型的完整结构图
- 4. Stable Diffusion中VAE的训练过程与损失函数
- 2.3 U-Net模型
- 1. Stable Diffusion中U-Net的核心作用
- 2. Stable Diffusion中U-Net模型的完整结构图
- 2.4 CLIP Text Encoder模型
- 1. CLIP模型介绍
- 2. CLIP在Stable Diffusion中的使用
一. Stable Diffusion核心基础知识
1.1 Stable Diffusion模型工作流程
1. 文生图(txt2img)
文生图任务是指将一段文本输入到SD模型中,经过一定的迭代次数,SD模型输出一张符合输入文本描述的图片。
步骤一: 使用CLIP Text Encode模型将输入的人类文本信息进行编码,生成与文本信息对应的Text Embeddings特征矩阵;
步骤二: 输入文本信息,再用random函数生成一个高斯噪声矩阵 作为Latent Feature(隐空间特征)的“替代” 输入到SD模型的 “图像优化模块” 中;
步骤三: 首先图像优化模块是由U-Net网络和Schedule算法 组成,将图像优化模块进行优化迭代后的Latent Feature输入到 图像解码器 (VAE Decoder) 中,将Latent Feature重建成像素级图。

2. 图生图
图生图任务在输入本文的基础上,再输入一张图片,SD模型将根据文本的提示,将输入图片进行重绘以更加符合文本的描述。
步骤一: 使用 CLIP Text Encode 模型将输入的人类文本信息进行编码,生成与文本信息对应的Text Embeddings特征矩阵;同时,将原图片通过图像编码器(VAE Encoder)生成Latent Feature(隐空间特征)
步骤二: 将上述信息输入到图像优化模块;
步骤三: 将图像优化模块进行优化迭代后的Latent Feature输入到 图像解码器 (VAE Decoder) 中,将Latent Feature重建成像素级图。

3. 图像优化模块
- 首先,“图像优化模块”是由一个U-Net网络和一个Schedule算法共同组成,U-Net网络负责预测噪声,不断优化生成过程,在预测噪声的同时不断注入文本语义信息。
- schedule算法对每次U-Net预测的噪声进行优化处理(动态调整预测的噪声,控制U-Net预测噪声的强度),从而统筹生成过程的进度。
- 在SD中,U-Net的迭代优化步数(Timesteps)大概是50或者100次,在这个过程中Latent Feature的质量不断的变好(纯噪声减少,图像语义信息增加,文本语义信息增加)。

总结:不管是文生图还是图生图,核心模型都是图像优化模块,图像优化模块的输入都是文字+图片,输出都是一张经过优化后的图片。只不过文生图任务中图像优化模块的输入是一张随机生成的噪声图。模型对文字的编码采用CLIP Text Encoder模型,对于图片的编码采用VAE Encoder。
1.2 Stable Diffusion模型核心基础原理
与GAN等生成式模型一致的是,SD模型同样学习拟合训练集分布,并能够生成与训练集分布相似的输出结果,但与GAN相比,SD模型训练过程更稳定,而且具备更强的泛化性能。这些都归功于扩散模型中核心的 前向扩散过程(Forward Diffusion Process) 和反向扩散过程(Reverse Diffusion Process)。
在前向扩散过程中,SD模型持续对一张图像添加高斯噪声直至变成随机噪声矩阵。而在反向扩散过程中,SD模型进行去噪声过程,将一个随机噪声矩阵逐渐去噪声直至生成一张图像。
- 前向扩散过程(Forward Diffusion Process)
图片中持续添加噪声 - 反向扩散过程(Reverse Diffusion Process)
持续去除图片中的噪声
1. 扩散模型的基本原理
在Stable Diffusion这个扩散模型中,无论是前向扩散过程还是反向扩散过程都是一个参数化的马尔可夫链(Markov chain),如下图所示:

2. 前向扩散过程详解
- 前向扩散过程,其实是一个不断加噪声的过程。
- 对于初始数据,我们设置K步的扩散步数,每一步增加一定的噪声,如果我们设置的K足够大,那么我们就能够将初始数据转化成随机噪音矩阵。
- 一般来说,扩散过程是固定的,由上节中提到的Schedule算法进行统筹控制。同时扩散过程也有一个重要的性质:我们可以基于初始数据 X 0 X_0 X0和任意的扩散步数 K i K_i Ki ,采样得到对应的数据 X i X_i Xi。
3. 反向扩散过程详解
- 反向扩散过程和前向扩散过程正好相反,是一个不断去噪的过程。将随机高斯噪声矩阵通过扩散模型的Inference过程,预测噪声并逐步去噪,最后生成一个有效图片。
- 其中每一步预测并去除的噪声分布,都需要扩散模型在训练中学习。
扩散模型的前向扩散过程和反向扩散过程,他们的目的都是服务于扩散模型的训练,训练目标也非常简单:扩散模型每次预测出的噪声和每次实际加入的噪声做回归,让扩散模型能够准确的预测出每次实际加入的真实噪声。
下面是SD反向扩散过程的完整图解:

4. 引入Latent思想
-
首先,我们已经知道了扩散模型会设置一个迭代次数,并不会像GAN网络那样一次输入一次输出,虽然这样输出效果会更好更稳定,但是会导致生成过程耗时的增加。
-
再者,Stable Diffusion出现之前的Diffusion模型虽然已经有非常强的生成能力与生成泛化性能,但缺点是不管是前向扩散过程还是反向扩散过程,都需要在完整像素级的图像上进行,当图像分辨率和Timesteps很大时,不管是训练还是前向推理,都非常的耗时。
-
而基于Latent的扩散模型可以将这些过程压缩在低维的Latent隐空间,这样一来大大降低了显存占用和计算复杂性,这是常规扩散模型和基于Latent的扩散模型之间的主要区别,也是SD模型火爆出圈的关键一招。
我们举个形象的例子理解一下,如果SD模型将输入数据压缩的倍数设为8,那么原本尺寸为 [ 3 , 512 , 512 ] [3, 512, 512] [3,512,512]
的数据就会进入 [ 3 , 64 , 64 ] [3, 64, 64] [3,64,64]的Latent隐空间中,显存和计算量直接缩小64倍,整体效率大大提升。
总结:
- SD模型是生成式模型,输入可以是图片,文本以及两者的结合,输出是生成的图片。
- SD模型属于扩散模型,扩散模型的整体逻辑的特点是过程分步化与可迭代,这给整个生成过程引入更多约束与优化提供了可能。
- SD模型是基于Latent的扩散模型,将输入数据压缩到Latent隐空间中,比起常规扩散模型,大幅提高计算效率的同时,降低了显存占用,成为了SD模型破圈的关键一招。
1.3 Stable Diffusion训练全过程
1. 训练过程简介
Stable Diffusion的整个训练过程在最高维度上可以看成是如何加噪声和如何去噪声的过程,并在针对噪声的“对抗与攻防”中学习到生成图片的能力。
- 从数据集中随机选择一个训练样本
- 从K个噪声量级随机抽样一个timestep t t t
- 将timestep t t t对应的高斯噪声添加到图片中
- 将加噪图片输入U-Net中预测噪声
- 计算真实噪声和预测噪声的L2损失
- 计算梯度并更新SD模型参数
2. SD训练集加入噪声
-
SD模型训练时,我们需要把加噪的数据集输入模型中,每一次迭代我们用random函数生成从强到弱各个强度的噪声,通常来说会生成0-1000一共1001种不同的噪声强度,通过Time Embedding嵌入到SD的训练过程中。
-
Time Embedding由Timesteps(时间步长)编码而来,引入Timesteps能够模拟一个随时间逐渐向图像加入噪声扰动的过程。每个Timestep代表一个噪声强度(较小的Timestep代表较弱的噪声扰动,而较大的Timestep代表较强的噪声扰动),通过多次增加噪声来逐渐改变干净图像的特征分布。
举个例子,可以帮助大家更好地理解SD训练时数据是如何加噪声的。
首先从数据集中选择一张干净样本,然后再用random函数生成0-3一共4种强度的噪声,然后每次迭代中随机一种强度的噪声,增加到干净图片上,完成图片的加噪流程。
3. SD训练中加噪与去噪
- 在训练过程中,我们首先对干净样本进行加噪处理,采用多次逐步增加噪声的方式,直至干净样本转变成为纯噪声。
- 接着,让SD模型学习去噪过程,最后抽象出一个高维函数,这个函数能在纯噪声中不断“优化”噪声,得到一个干净样本。
去噪过程是使用U-Net预测噪声,并结合Schedule算法实现逐步去噪。
加噪和去噪过程都是逐步进行的,我们假设进行 K K K步,那么每一步,SD都要去预测噪声.
那么怎么让网络知道目前处于 K K K的哪一步呢?本来SD模型其实需要K个噪声预测模型,这时我们可以增加一个Time Embedding(类似Positional embeddings)进行处理,通过将timestep编码进网络中,从而只需要训练一个共享的U-Net模型,就让网络知道现在处于哪一步。
总结:
SD训练的具体过程就是对每个加噪和去噪过程进行计算,从而优化SD模型参数,如下图所示分为四个步骤:
- 从训练集中选取一张加噪过的图片和噪声强度(timestep)
- 然后将其输入到U-Net中,让U-Net预测噪声(下图中的Unet Prediction),
- 接着再计算预测噪声与真实噪声的误差(loss),
- 最后通过反向传播更新U-Net的参数。
4. 语义信息对图片生成的控制
SD模型在生成图片时,需要输入prompt,那么这些语义信息是如何影响图片的生成呢?
答案非常简单:注意力机制。
在SD模型的训练中,每个训练样本都会对应一个标签,我们将对应标签通过CLIP Text Encoder输出Text Embeddings,并将Text Embeddings以Cross Attention的形式与U-Net结构耦合,使得每次输入的图片信息与文字信息进行融合训练。
5. SD模型训练时的输入
小结一下SD模型训练时的输入,一共有三个部分组成:图片,文本,噪声强度。其中图片和文本是固定的,而噪声强度在每一次训练参数更新时都会随机选择一个进行叠加。
二. SD模型核心网络结构解析
2.1 SD模型整体架构初识
Stable Diffusion模型整体上是一个End-to-End模型,主要由以下三个核心组件构成。
- VAE(变分自编码器,Variational Auto-Encoder),
- U-Net
- CLIP Text Encoder
 Stable Diffusion整体架构图
Stable Diffusion整体架构图
2.2 VAE模型
在Stable Diffusion中,VAE(变分自编码器,Variational Auto-Encoder)是基于Encoder-Decoder架构的生成模型。VAE的Encoder(编码器)结构能将输入图像转换为低维Latent特征,并作为U-Net的输入。VAE的Decoder(解码器)结构能将低维Latent特征重建还原成像素级图像。
1. Stable Diffusion中VAE的核心作用
总的来说,在Stable Diffusion中,VAE模型主要起到了图像压缩和图像重建的作用。
为什么VAE可以将图像压缩到一个非常小的Latent space(潜空间)后能再次对图像进行像素级重建呢?
因为虽然VAE对图像的压缩与重建过程是一个有损压缩与重建过程,但图像全图级特征关联并不是随机的,它们的分布具有很强的规律性:比如人脸的眼睛、鼻子、脸颊和嘴巴之间遵循特定的空间关系,又比如一只猫有四条腿,并且这是一个特定的生物结构特征。
2. Stable Diffusion中VAE的高阶作用
与此同时,VAE模型除了能进行图像压缩和图像重建的工作外,如果我们在SD系列模型中切换不同微调训练版本的VAE模型,能够发现生成图片的细节与整体颜色也会随之改变(更改生成图像的颜色表现,类似于色彩滤镜)。
3. Stable Diffusion中VAE模型的完整结构图

SD VAE模型中有三个基础组件:
- GSC组件:GroupNorm+Swish+Conv
- Downsample组件:Padding+Conv
- Upsample组件:Interpolate+Conv
-
同时SD VAE模型还有两个核心组件:ResNetBlock模块和SelfAttention模型,两个模块的结构如上图所示。
-
SD VAE Encoder部分包含了三个DownBlock模块、一个ResNetBlock模块以及一个MidBlock模块,将输入图像压缩到Latent空间,转换成为Gaussian Distribution。
-
而VAE Decoder部分正好相反,其输入Latent空间特征,并重建成为像素级图像作为输出。其包含了三个UpBlock模块、一个ResNetBlock模块以及一个MidBlock模块。
4. Stable Diffusion中VAE的训练过程与损失函数
在Stable Diffusion中,需要对VAE模型进行微调训练,主要采用了L1回归损失和感知损失(perceptual loss,Learned Perceptual Image Patch Similarity,LPIPS)作为损失函数,同时使用了基于patch的对抗训练策略。
2.3 U-Net模型
1. Stable Diffusion中U-Net的核心作用
在Stable Diffusion中,U-Net模型是一个关键核心部分,能够预测噪声残差,并结合Sampling method(调度算法:PNDM,DDIM,K-LMS等)对输入的特征矩阵进行重构,逐步将其从随机高斯噪声转化成图片的Latent Feature。
具体来说,在前向推理过程中,SD模型通过反复调用 U-Net,将预测出的噪声残差从原噪声矩阵中去除,得到逐步去噪后的图像Latent Feature,再通过VAE的Decoder结构将Latent Feature重建成像素级图像。
2. Stable Diffusion中U-Net模型的完整结构图
Stable Diffusion中的U-Net,在传统深度学习时代的Encoder-Decoder结构的基础上,增加了ResNetBlock(包含Time Embedding)模块,Spatial Transformer(SelfAttention + CrossAttention + FeedForward)模块以及CrossAttnDownBlock,CrossAttnUpBlock和CrossAttnMidBlock模块。

上图中包含Stable Diffusion U-Net的十四个基本模块:
1. GSC模块:Stable Diffusion U-Net中的最小组件之一,由GroupNorm+SiLU+Conv三者组成。
2. DownSample模块:Stable Diffusion U-Net中的下采样组件,使用了Conv(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))进行采下采样。
3. UpSample模块:Stable Diffusion U-Net中的上采样组件,由插值算法(nearest)+Conv组成。
4. ResNetBlock模块:借鉴ResNet模型的“残差结构”,让网络能够构建的更深的同时,将Time Embedding信息嵌入模型。
5. CrossAttention模块:将文本的语义信息与图像的语义信息进行Attention机制,增强输入文本Prompt对生成图片的控制。
6. SelfAttention模块:SelfAttention模块的整体结构与CrossAttention模块相同,这是输入全部都是图像信息,不再输入文本信息。
7. FeedForward模块:Attention机制中的经典模块,由GeGlU+Dropout+Linear组成。
8. BasicTransformer Block模块:由LayerNorm+SelfAttention+CrossAttention+FeedForward组成,是多重Attention机制的级联,并且也借鉴ResNet模型的“残差结构”。通过加深网络和多Attention机制,大幅增强模型的学习能力与图文的匹配能力。
9. Spatial Transformer模块:由GroupNorm+Conv+BasicTransformer Block+Conv构成,ResNet模型的“残差结构”依旧没有缺席。
10. DownBlock模块:由两个ResNetBlock模块组成。
11. UpBlock_X模块:由X个ResNetBlock模块和一个UpSample模块组成。
12. CrossAttnDownBlock_X模块:是Stable Diffusion U-Net中Encoder部分的主要模块,由X个(ResNetBlock模块+Spatial Transformer模块)+DownSample模块组成。
13. CrossAttnUpBlock_X模块:是Stable Diffusion U-Net中Decoder部分的主要模块,由X个(ResNetBlock模块+Spatial Transformer模块)+UpSample模块组成。
14. CrossAttnMidBlock模块:是Stable Diffusion U-Net中Encoder和ecoder连接的部分,由ResNetBlock+Spatial Transformer+ResNetBlock组成。
2.4 CLIP Text Encoder模型
1. CLIP模型介绍
CLIP模型是一个基于对比学习的多模态模型,主要包含Text Encoder和Image Encoder两个模型。
其中Text Encoder用来提取文本的特征,可以使用NLP中常用的text transformer模型作为Text Encoder;
而Image Encoder主要用来提取图像的特征,可以使用CNN/vision transformer模型(ResNet和ViT)作为Image Encoder。
与此同时,他直接使用4亿个图片与标签文本对数据集进行训练,来学习图片与本文内容的对应关系。
CLIP如何训练
CLIP在训练时,从训练集中随机取出一张图片和标签文本。CLIP模型的任务主要是通过Text Encoder和Image Encoder分别将标签文本和图片提取embedding向量,然后用余弦相似度(cosine similarity)来比较两个embedding向量的相似性,以判断随机抽取的标签文本和图片是否匹配,并进行梯度反向传播,不断进行优化训练。
2. CLIP在Stable Diffusion中的使用
在Stable Diffusion中主要使用了Text Encoder模型。CLIP Text Encoder模型将输入的文本Prompt进行编码,转换成Text Embeddings(文本的语义信息),通过U-Net网络中的CrossAttention模块嵌入Stable Diffusion中作为Condition,对生成图像的内容进行一定程度上的控制与引导。

特此感谢
https://zhuanlan.zhihu.com/p/632809634
https://blog.csdn.net/weixin_47748259/article/details/135502977
https://zhuanlan.zhihu.com/p/679152891