HDFS
NameNode
安全模式(safemode)
-
当NameNode被重启的时候,自动进入安全模式
-
在安全模式中,NameNode首先会触发edits_inprogress文件的滚动。滚动完成之后,更新fsimage文件
-
更新完成之后,NameNode会将fsimage文件中的元数据加载到内存中。加载完成之后,NameNode等待DataNode的心跳
-
如果NameNode没有收到DataNode的心跳,那么此时NameNode就会认为这个DataNode已经lost,那么此时NameNode会将这个DataNode上的数据备份到其他的节点上来保证副本数量;如果NameNode收到了DataNode的心跳,那么会对这个DataNode上的Block存储情况进行校验。如果校验成功,那么NameNode自动退出安全模式;如果校验失败,那么NameNode会试图恢复这个DataNode上的数据(每个DataNode的全部数据都会在其他DataNode上有备份),恢复完成之后,会重新校验;校验成功之后,才会退出安全模式
-
在安全模式下,HDFS只提供读(下载)操作,不提供写(上传)操作
-
如果在合理的时间内,HDFS依然没有退出安全模式,那么说明数据已经产生了不可逆的损坏或者丢失(这个数据的所有副本都损坏或者丢失)
-
安全模式的命令
命令 解释 hdfs dfsadmin -safemode enter进入安全模式 hdfs dfsadmin -safemode leave退出安全模式 hdfs dfsadmin -safemode get获取安全模式的状态
DataNode
- DataNode是HDFS的从进程,负责存储数据。DataNode会将数据以Block形式落地到本地的磁盘上
- Block在磁盘上的存储位置由
dfs.datanode.data.dir属性来决定的,默认值是file://${hadoop.tmp.dir}/dfs/data,由hadoop.tmp.dir属性来决定 - DataNode会为每一个Block生成一个.meta文件,.meta文件实际上是这个Block的校验文件
- DataNode会通过心跳向NameNode注册信息
- DataNode的状态:预服役、服役、预退役、退役
SecondaryNameNode
-
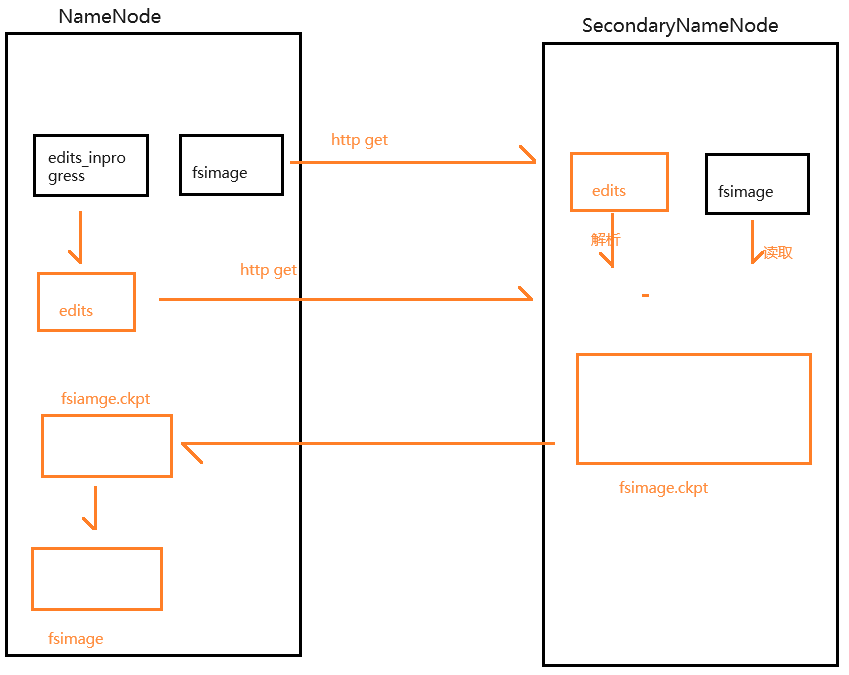
SecondaryNameNode不是NameNode的备份,而是辅助进程,用于辅助NameNode完成edits_inprogress文件的滚动和fsimage文件的更新
- 如果HDFS集群中存在SecondaryNameNode,那么fsimage文件的更新是由SecondaryNameNode来完成
- 如果HDFS集群中不存在SecondaryNameNode,那么fsimage文件的更新是由NameNode自己来完成
-
因此,SecondaryNameNode不是必须的进程。实际过程中,NameNode和SecondaryNameNode不是在同一个节点上
-
fsimage文件的更新过程
-
由于HDFS集群的限制,HDFS集群支持两种模式
- 1个NameNode+1个SecondayNameNode+n个DataNode
- n个NameNode+n个DataNode
考虑到NameNode作为核心节点,必须对NameNode来进行备份。所以实际过程中,采用上述的第二种结构
机架感知策略
-
在HDFS集群中,机架指的是逻辑机架。默认情况下,机架感知策略是不开启的
-
逻辑机架:通过一个映射(map)来定义主机和机架之间的关联。将主机名或者IP作为键,将机架作为值,只要值相同,就表示不同的服务器是位于相同的机架上的
# hadoop01~hadoop03都是属于机架r1,hadoop04~05都是属于机架r2 rack = {"hadoop01":"r1","hadoop02":"r1","hadoop03":"r1","hadoop04":"r2","hadoop05":"r2" } -
如果需要开启机架感知策略,那么需要在
hadoop-site.xml文件中配置<property><name>net.topology.script.file.name</name><value>脚本的路径</value> </property>实际过程中,一般是通过shell或者python来定义脚本文件
-
理论上而言,可以将同一个物理机架上的节点配置到不同的逻辑机架上,也可以将不同物理机架上的节点配置到同一个逻辑机架上
副本放置策略
- HDFS为了保证数据的可靠性,默认采用的是多副本策略。默认情况下,每一个Block对应了3个副本。副本数量可以通过
dfs.replication属性来调节 - 在HDFS中,如果不开启机架感知策略,副本是放在相对空闲的节点上;如果开启了机架感知策略,那么对应的会开启副本放置策略
- 第一个副本:如果是集群内部上传,谁上传就放在谁身上;如果是集群外部上传,谁空闲就放在谁身上
- 第二个副本:放在和第一个副本相同机架的不同节点上
- 第三个副本:放在和第二个副本不同机架的节点上
- 更多副本:谁空闲放在谁身上
命令和操作
启动命令
| 命令 | 解释 |
|---|---|
start-dfs.sh | 启动HDFS |
stop-dfs.sh | 关闭HDFS |
hdfs --daemon start namenode | 启动NameNode |
hdfs --daemon start datanode | 启动DataNode |
hdfs --daemon start secondarynamenode | 启动SecondaryNameNode |
hdfs --daemon stop namenode | 关闭NameNode |
hdfs --daemon stop datanode | 关闭DataNode |
hdfs --daemon stop secondarynamenode | 关闭SecondaryNameNode |
基本命令
| 命令 | 解释 |
|---|---|
hadoop fs -put a.txt / 或者 hadoop fs -copyFromLocal a.txt / (过时) | 将a.txt上传到HDFS的根目录下 |
hadoop fs -ls / | 查看子文件和子目录 |
hadoop fs -ls -R / | 递归查看 |
hadoop fs -cat /a.txt | 查看文件内容 |
hadoop fs -appendToFile b.txt /a.txt | 将本地的b.txt的内容追加到HDFS的a.txt中 |
hadoop fs -checksum /a.txt | 计算校验和(就是获取这个文件的md5计算结果) |
hadoop fs -chown tom /a.txt | 更改文件所属用户 |
hadoop fs -chmod 777 /a.txt | 更改文件的权限 |
hadoop fs -chgrp test /a.txt | 更改文件的用户组 |
hadoop fs -copyToLocal /a.txt /opt/test.txt或者 hadoop fs -get /a.txt /opt/test.txt | 下载文件 |
hadoop fs -cp /a.txt /b.txt | 复制文件 |
hadoop fs -mv /a.txt /test.txt | 剪切或者重命名文件 |
hadoop fs -df / | 查看HDFS的容量 |
hadoop fs -du /b.txt | 查看文件的大小 |
hadoop fs -setrep 3 /b.txt(上传文件时指定副本数量,这个参数优先级高于默认的副本数量) | 指定副本数量 |
回收站机制
-
在HDFS中,回收站机制默认是不开启的,即删除命令会立即生效,无法撤销
-
如果需要开启回收站机制,那么需要在
core-site.xml文件中做配置<!-- 指定文件在回收站中临时的存放时间 --> <!-- 单位默认是min --> <!-- 如果不指定,默认情况下值为0,即删除要立即生效 --> <!-- 如果超过指定时间,没有将文件从回收站中移出来,那么这个文件就会被清理掉 --> <property><name>fs.trash.interval</name><value>1440</value> </property> -
回收站的默认路径是:
/user/${user.name}/.Trash/Current/ -
如果需要将文件从回收站中挪出来,那么使用
hadoop fs -mv命令即可
流程
删除流程
- 客户端发起RPC请求到NameNode,请求删除指定文件
- NameNode收到请求之后,会进行校验
- 校验是否有写入权限 -
AccessControlException - 校验是否有指定文件 -
FileNotFoundException
- 校验是否有写入权限 -
- 如果校验失败,那么会报错;如果校验成功,那么NameNode修改元数据;修改完元数据之后,NameNode会给客户端返回一个ACK信号表示删除成功!注意,此时文件并没有真正从HDFS上移除,仅仅是修改了元数据!
- NameNode会等待DataNode的心跳,收到DataNode的心跳之后,会在心跳响应中要求DataNode删除对应的Block
- DataNode收到心跳响应之后,才回去磁盘上删除这个文件对应的Block。注意,此时,文件才真正从HDFS上移除!
写入(上传)流程
-
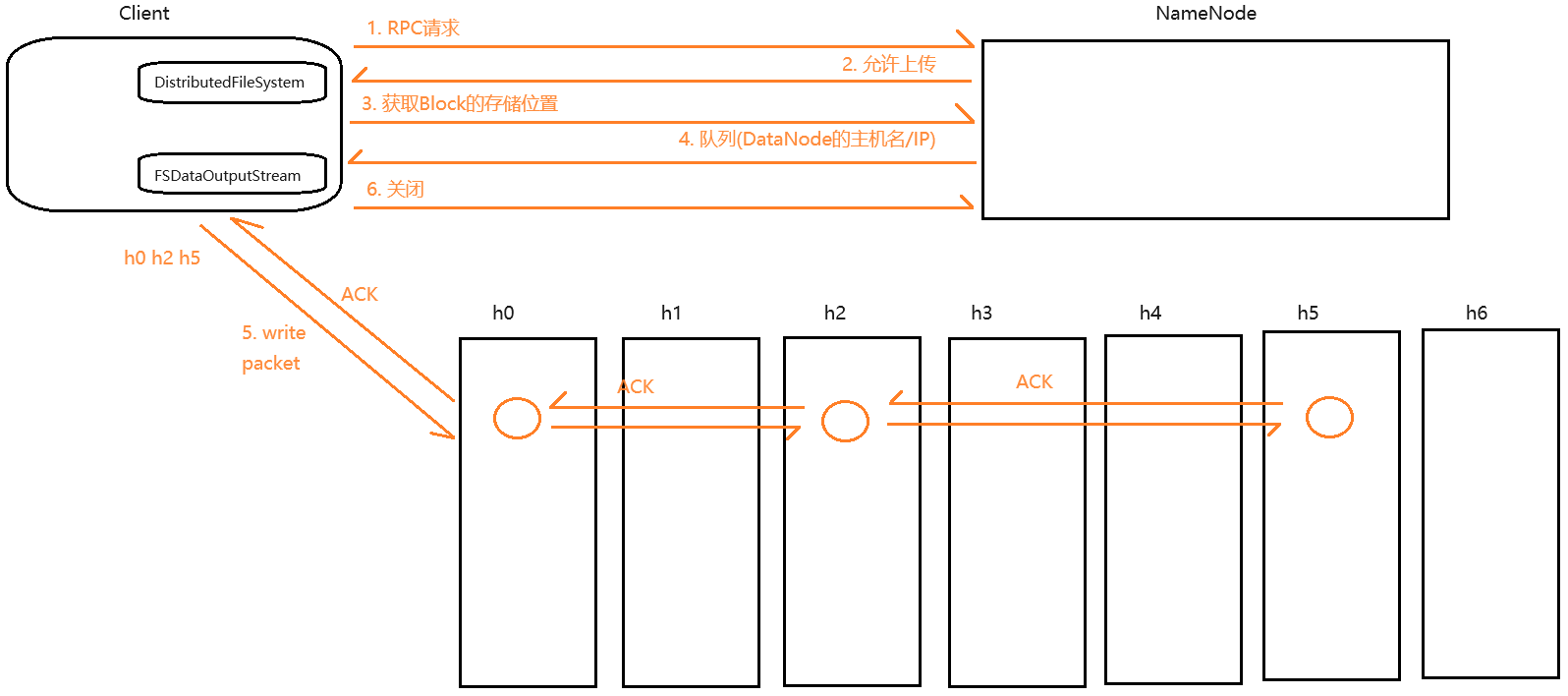
客户端通过
DistributedFileSystem向NameNode发送RPC请求,请求上传指定文件 -
NameNode收到请求之后,会进行校验
- 校验是否有写入权限 -
AccessControlException - 校验是否有同名文件 -
FileAlreadyExistException
- 校验是否有写入权限 -
-
如果校验失败,那么直接报错;如果校验成功,NameNode会给客户端返回一个信号表示允许上传
-
客户端在收到信号之后,会再次给NameNode发送请求,请求获取第一个Block的存储地址
-
NameNode收到请求之后,会查询元数据,根据副本放置策略,将这个Block的存储位置放入队列中返回给客户端。存储位置其实就是DataNode的主机名/IP,默认情况下,返回的是3个地址(副本数量默认为3)
-
客户端收到队列之后,会从队列中将地址全部取出,取出之后,会从中选择一个较近(网络拓扑距离的远近)的节点,通过
FSDataOutputStream来请求建立pipeline(管道),来写入当前Block的第一个副本;第一个副本写完之后,这个副本所在的节点会通过pipeline将这个Block的第二个副本写入;第二个副本写完之后,这个副本所在的节点会通过管道来写入下一个节点 -
当这个Block的最后一个副本写完之后,会给上一个副本所在的节点返回一个ACK信号表示成功;上一个副本所在的节点收到ACK之后,会继续往前返回ACK,直到返回给客户端
-
当客户端收到ACK之后,会再次给NameNode发送请求,请求获取下一个Block的存储位置,重复5.6.7三个步骤,直到所有的Block全部写完
-
当所有的Block全部写完之后,客户端会给NameNode发送一个结束信号(关流)。NameNode收到信号之后,会关闭文件。文件一旦关闭就不能修改!
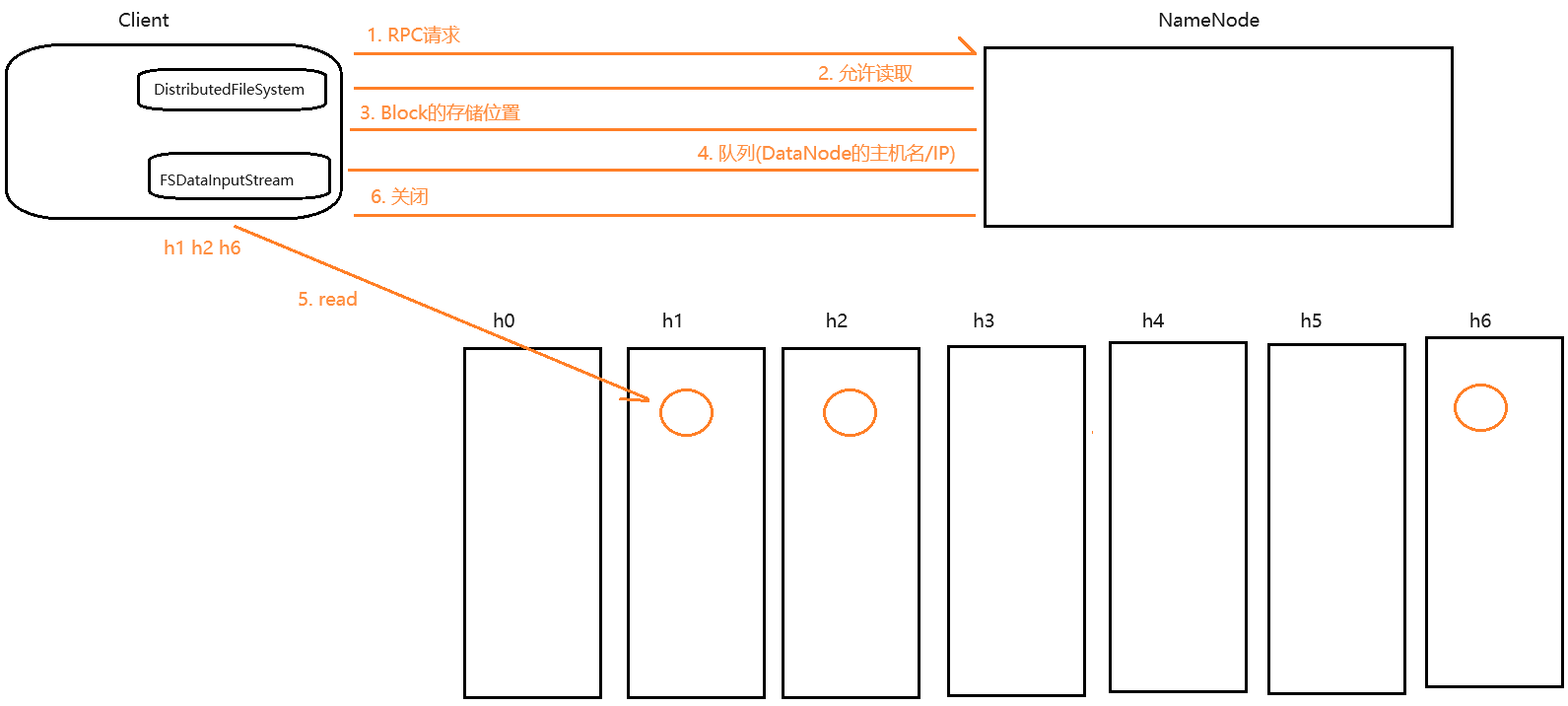
读取(下载)流程
-
客户端通过
DistributedFileSystem向NameNode发送RPC请求,请求读取指定文件 -
NameNode收到请求之后,会进行校验
- 校验是否有读取权限 -
AccessControlException - 校验是否有指定文件 -
FileNotFoundException
- 校验是否有读取权限 -
-
如果校验失败,则直接报错;如果校验成功, 那么NameNode会给客户端返回一个信号表示允许读取
-
客户端收到信号之后,会再次给NameNode发送请求,请求获取第一个Block的存储位置
-
NameNode收到请求之后,会查询元数据,将这个Block的存储位置以及Block的校验信息放入队列中返回给客户端
-
客户端收到队列之后,会将地址从队列中全部取出,从中选择一个较近(网络拓扑距离较近)的节点,通过
FSDataInputStream来读取这个Block -
读取完成之后,客户端会对这个Block进行一次checkSum校验。如果校验失败,那么客户端会从剩余的地址中重新选取地址重新读取重新校验;如果校验成功,那么客户端会再次给NameNode发送请求,请求获取下一个Block的位置,重复5.6.7,直到所有的Block全部读取完毕
-
当所有的Block都读取完之后,客户端会给NameNode发送一个结束信号
特点
- 支持超大文件。HDFS会对文件进行切块处理,所以集群规模越大,能够存储的文件就越大
- 能够快速的应对和检测故障。HDFS通过心跳来管理DataNode,通过心跳可以确定DataNode的状态以及Block的状态
- 高容错性。HDFS对文件进行备份,从而保证不会因为一个节点宕机就产生数据丢失
- 可以在相对廉价的机器上来进行横向扩展
- 不支持低延迟数据访问。HDFS的设计初衷就是为了存储超大文件,因此考虑的是数据的吞吐量而不是响应速度
- 不建议存储小文件。每一个小文件对应的会产生一条元数据,小文件多了,就意味着元数据会增多,那么会导致内存占用变大,同时会导致查询效率降低
- 简化的一致性模型。HDFS支持一次写入多次读取,不支持修改但是支持追加写入
- 不支持事务或者支持弱事务。这就意味着在HDFS中,即使数据写错也不能修改
- 存储的超大文件允许小部分数据出错。HDFS通常是TB级的日志级别,然后对其数据分析。其中几MB的数据出错并不会影响最终的分析结果。
补充
RPC
- RPC(Remote Procedure Call),远程过程调用,指的是允许程序员在一个节点上远程调用另一个节点上的程序或者功能,而不需要显式的实现这个功能
- RPC是Nelson在1990年的论文中提出的理论,现在RPC已经成为了分布式中最重要的通讯方式
- 存储的超大文件允许小部分数据出错。HDFS通常是TB级的日志级别,然后对其数据分析。其中几MB的数据出错并不会影响最终的分析结果。
补充
RPC
- RPC(Remote Procedure Call),远程过程调用,指的是允许程序员在一个节点上远程调用另一个节点上的程序或者功能,而不需要显式的实现这个功能
- RPC是Nelson在1990年的论文中提出的理论,现在RPC已经成为了分布式中最重要的通讯方式
- stub(存根):保证两端能够调用的函数是相同的,在Java中通常使用接口来实现