唠唠叨:我不想误人子弟,我这篇算是搬运工,加上自己的理解做点总结,所以还请大家科学上网去看这篇:https://aws.amazon.com/cn/blogs/mobile/what-happens-when-you-type-a-url-into-your-browser/
是这六个步骤:
- 您在浏览器中输入 URL 并按 Enter 键
- 浏览器查找域的 IP 地址
- 浏览器发起与服务器的TCP连接
- 浏览器向服务器发送HTTP请求
- 服务器处理请求并发回响应
- 浏览器渲染内容
小知识:
网站和服务器:网站是文件的集合,通常是HTML、CSS、JavaScript和图像,它们告诉浏览器如何显示网站、图像和数据。它们需要可供任何人随时随地的访问,因此将它们托管在家里的计算机上不具有可扩展性或可靠性。连接到互联网的强大外部计算机(称为服务器)存储这些文件。
IP地址:当您浏览器指向http://www.baidu.com这样的URL时,我的浏览器就必须找出Internet上的哪台服务器正在托管该站点。通过查找域www.baidu.com来查找地址来实现此目的。
互联网上的每台设备(服务器、手机、智能冰箱)都有一个唯一的地址,称为 IP 地址。 IP 地址包含四个编号部分:203.0.113.0
但这样的数字很难记住!这就是域名的用武之地。www.baidu.com比 203.0.113.0 更容易记住,对吧?想象一下,如果手机上没有联系人应用程序,则必须记住联系人的所有电话号码。您的通讯录应用程序可让您按姓名查找电话号码。
我们在互联网上也做同样的事情。域名系统或 DNS,就像我们手机上的通讯录应用程序。 DNS 帮助我们的浏览器(和我们)找到互联网上的服务器。我们可以进行 DNS 查找,根据域名 jennapederson.dev 查找服务器的 IP 地址。您可以在此处阅读有关 DNS 的更多信息。
现在您已经了解了不同的部分以及它们之间的相互关系,接下来让我们看看该过程的每个步骤以及当您键入 URL 时浏览器如何与服务器通信。无论您是输入 URL 还是单击当前页面中的链接 URL,过程都是相同的。
从输入 url 到页面的画面展示的过程。
输入url
关于浏览器的通讯协议:
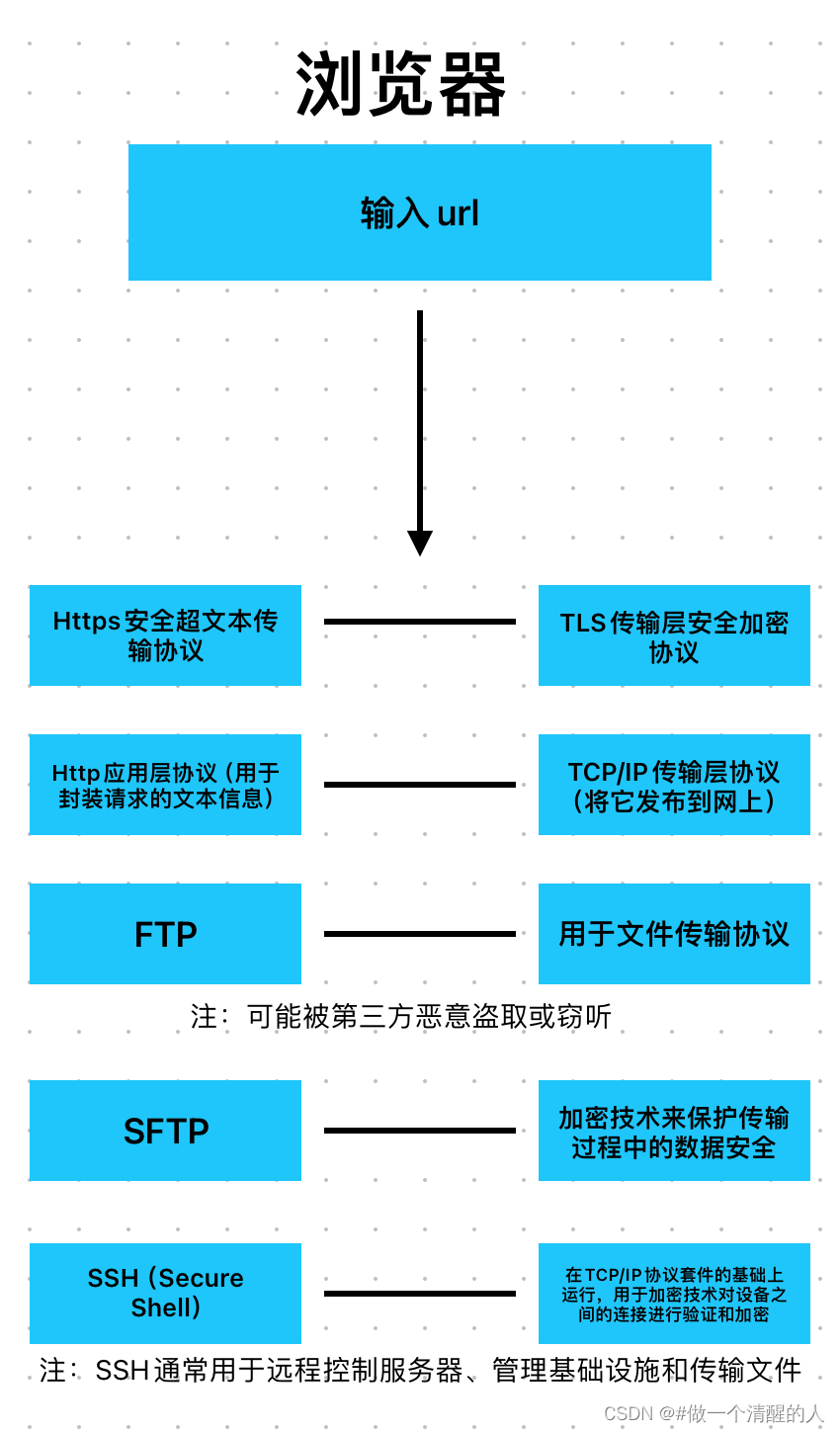

查找域的IP地址
在浏览器中输入URL并Enter键后,浏览器需要确定要连接到 Internet 上的哪个服务器。为此,它需要使用您输入的域查找托管网站的服务器的 IP 地址。它使用 DNS 查找来完成此操作。超出了本文的范围。您可以在此处阅读有关 DNS 如何工作的更多信息,浏览器会先进入缓存查找。
由于 DNS 很复杂并且必须非常快,因此 DNS 数据缓存在浏览器之间的不同层以及 Internet 上的各个位置。浏览器会先检查自身的以下缓存
- 浏览器缓存:检查浏览器缓存。浏览器会在固定的时间之内维护之前访问的网站DNS记录存储库
- os缓存:如果它不在浏览器缓存中,则浏览器将对底层计算机操作系统进行系统调用(即Windows上的gethostname)来获取记录,因为os还维护DNS记录的缓存。
- 路由缓存:如果它不在我的计算机上,浏览器将与维护其自己的DNS记录缓存的路由器进行通信。
- 或互联网服务提供商 (ISP) 上的 DNS 服务器缓存。
注:DNS查找信息通畅混存在查询计算机本地或进程DNS基础设施中,这可以跳过DNS查找过程中的步骤并使其更快。然而,当没有缓存任何内容时,查询就会传输到Internet并有DNS递归解析器(即ISP)接收。
浏览器发起与服务器的TCP的连接
使用公共互联网路由基础设施,来自客户端浏览器请求的数据包通过路由器、ISP、互联网交换机来切换 ISP 或网络,所有这些都使用传输控制协议(通常称为 TCP)来查找具有要连接的 IP 地址。但这是一种非常迂回的方式,而且效率不高。
相反,许多网站使用内容交付网络(CDN)来缓存更靠近浏览器的静态和动态内容。CDN 是一个全球分布式缓存服务器网络,可通过使内容更接近用户来提高网站或应用程序(源)的性能。
客户端浏览器请求可以搭乘 AWS 全球网络,而不是依赖公共互联网路由基础设施并遭受额外的跃点、重新传递和数据包丢失。该请求会智能地通过性能最佳的位置进行路由,以将内容传送到您的浏览器。
一旦浏览器在 Internet 上找到服务器,它就会与服务器建立 TCP 连接,如果使用 HTTPS,则会发生 TLS 握手以确保通信安全。 TCP 和 TLS 是极其重要的主题。
一旦浏览器与服务器建立了连接,下一步就是发送 HTTP 请求以获取资源或页面。
浏览器向服务器发送HTTP请求
现在浏览器已连接到服务器,它遵循 HTTP(s) 协议的通信规则。首先浏览器向服务器发送 HTTP 请求以请求页面内容。 HTTP 请求包含请求行、标头(或有关请求的元数据)和正文。请求行包含服务器可用来确定客户端(在本例中为您的浏览器)想要执行的操作的信息。
请求行包含以下内容:
请求方法,是 GET、POST、PUT、PATCH、DELETE 或一些其他 HTTP 动词之一
路径,指向所请求的资源
要通信的 HTTP 版本
URL 请求的请求行如下所示:
GET /hello-world HTTP/1.1
请求行告诉服务器您想要获取 处的资源/hello-world并与之通信HTTP/1.1。
请记住,HTTP 动词表达了您的请求的语义意图。您还可以使用 POST、PUT 或 PATCH 方法将数据发送到服务器进行存储,以创建新数据或更新请求路径上的现有数据。 DELETE 方法将删除给定路径上的资源。但是,重要的是要知道服务器不必支持所有动词。服务器可以用200 OK状态响应 DELETE 方法,但不对资源执行任何操作。
请求的下一部分是请求标头。标头从客户端传递额外信息,帮助路由请求,指示发出请求的客户端类型(用户代理),并可用于支持 A/B 测试、蓝/绿部署和金丝雀部署。
请求的最后一部分是正文。对于像我们这样的 GET 请求,主体(通常)是空的。对于操作资源的请求(例如 POST、PUT 或 PATCH),正文将包含来自客户端的要创建或更新的数据。
请求正文可以采用不同的格式,服务器根据请求标头理解该格式Content-Type。
一旦服务器收到客户端的请求,服务器就会处理该请求并发回响应。
浏览器处理请求并发回响应
服务器接受请求并根据请求行、标头和正文中的信息决定如何处理请求。对于请求,GET /hello-world/ HTTP/1.1服务器获取此路径上的内容,构造响应并将其发送回客户端。响应包含以下内容:
- 状态行,告诉客户端请求的状态
- 响应头,告诉浏览器如何处理响应
- 该路径中请求的资源,可以是 HTML、CSS、Javascript 或图像文件等内容,也可以是数据
状态行包含 HTTP 版本以及请求状态的数字和文本表示形式。响应如下所示:
HTTP/1.1 200 OK
Date: Tue, 25 May 2021 19:40:59 GMT
Server: Apache
X-Frame-Options: SAMEORIGIN
X-Powered-By: Express
Cache-Control: max-age=0, no-cache
Content-Type: text/html; charset=utf-8
Vary: Accept-Encoding
X-Mod-Pagespeed: 1.13.35.2-0
Content-Encoding: br
Keep-Alive: timeout=1, max=100
Connection: Keep-Alive
Transfer-Encoding: chunked<!DOCTYPE html>
<html lang="en">
<head>THE REST OF THE HTML浏览器渲染内容
一旦浏览器收到服务器的响应,它就会检查响应标头以获取有关如何呈现资源的信息。上面的标Content-Type头告诉浏览器它在响应正文中收到了 HTML 资源。幸运的是,浏览器知道如何处理 HTML!
第一个 GET 请求返回 HTML,即页面的结构。但是,如果您使用浏览器的开发工具检查页面(或任何网页)的 HTML,您将看到它引用其他 Javascript、CSS、图像资源并请求其他数据,以便按设计呈现网页。
当浏览器解析和渲染 HTML 时,它会发出额外的请求来获取 Javascript、CSS、图像和数据。它可以并行完成大部分工作,但并非总是如此,这是另一篇文章的故事。
学习:https://aws.amazon.com/cn/blogs/mobile/what-happens-when-you-type-a-url-into-your-browser/


![[数据结构]排序](https://img-blog.csdnimg.cn/direct/4e2be02c5f9a4590885da734d4f569a7.png)