一、框架目录结构
- 1)tools目录用来放公共方法存储,如发送接口以及读取测试数据的方法,响应断言 数据库断言 前置sql等方法;
- 2)datas目录用例存储接口用例的测试数据,我是用excel来存储的数据,文件数据 图片数据等;
- 3)testcases目录用来存放测试用例,一个python文件对应一个接口模块的测试用例,不同接口分别别多个不同的python文件;
- 4)outputs里有reports和logs,report目录用来存放测试报告,报告是HTML格式的;logs是存放框架日志的;
- 5)run.py是用来执行所有接口用例的入口文件;
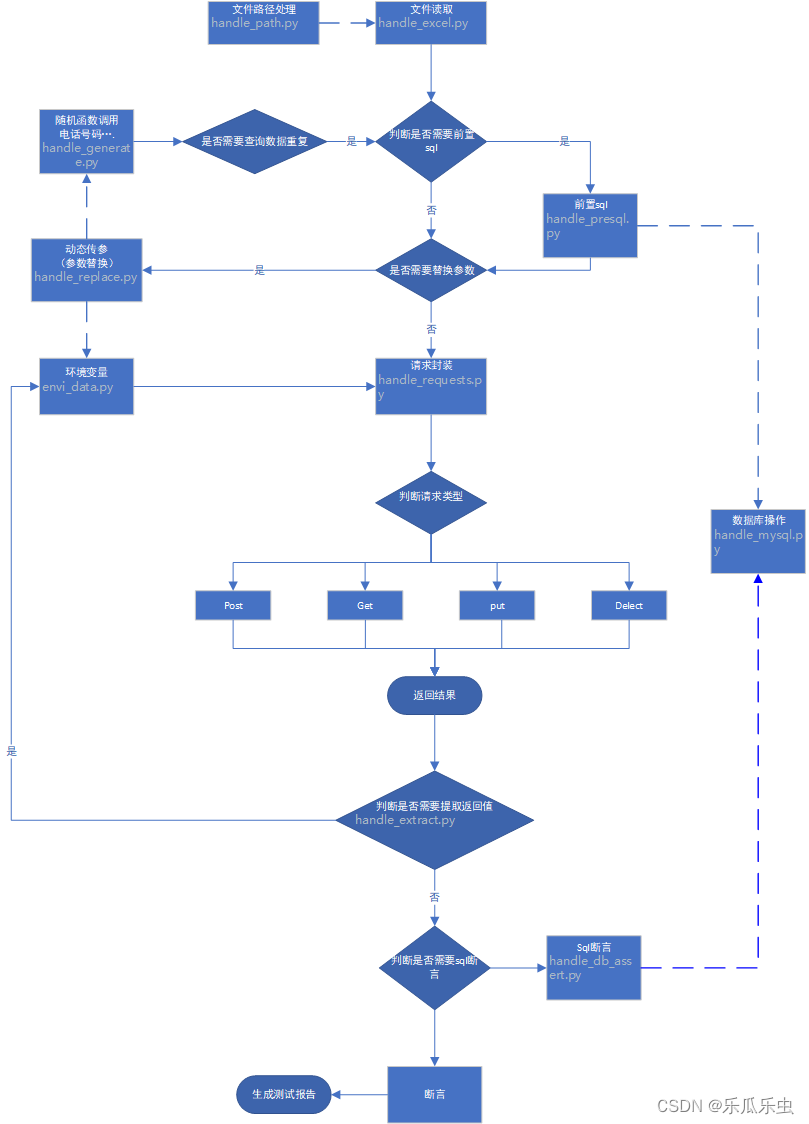
二、框架结构代码图解
三、各文件内容详解
tools扩展封装类详解
handle_path.py :文件路径处理
from pathlib import Pathlog_path = Path(__file__).absolute().parent.parent/"outputs"/"logs"/"mytest.log"# excel表格的路径处理
exc_path = Path(__file__).absolute().parent.parent /"datas" / "testcase_mall.xlsx"# 上传文件 路径
pic_path = Path(__file__).absolute().parent.parent /"datas"handle_excel.py:读取excel文件内容
from pathlib import Path
from openpyxl import load_workbookdef read_data(exc_path,sheetname):"""这是读取excel表格函数:param exc_path: 用例文件的路径:param sheetname: 用例表单的名字:return:"""wb = load_workbook(exc_path)sh = wb[sheetname]cases = list(sh.values) # 所有的用例的列表 [(第一行-title),(第二行用例),(),()]title = cases[0] # 得到标题行list_case = []for case in cases[1:]:data = dict(zip(title,case)) # 第一条用例的字典list_case.append(data) # 每一条用例追加到列表里。return list_caseif __name__ == '__main__':exc_path = Path(__file__).absolute().parent.parent /"datas" / "testcase_mall.xlsx"print(read_data(exc_path, "登录"))envi_data.py:存储环境变量
# 这个类就是为了存储环境变量 实现环境变量的共享的
class EnviData:passhandle_replace.py
检查excel读取的内容是否需要替换变量,
需要替换变量,先提取需要替换的变量名,
再查通过需要替换的变量名在环境变量中查询对应的值
替换变量的值并返回。
"""
1、def封装
2、参数化
3、返回值: 最终要拿到替换后的字符串 --- 头部 参数 要用于发送接口测试的
4、加上日志: 但凡你想确认数据结果的地方 都可以加上日志
5、因为有些接口不需要做数据提取,所以判空处理:
6、异常捕获: 因为有可能环境变量里没有这个属性名 和属性值"""
import reimport allure
from loguru import logger
from tools.envi_data import EnviData
from tools.handle_generate import GenData@allure.step("替换占位符变量")
def replace_mark(str_data):while True:if str_data is None:returnresult = re.search("#(.*?)#",str_data)if result is None: # 如果没有占位符 就是None 跳出循环breakmark = result.group() # 结果是 #prodId# --要被替换的子字符串| #gen_unregister_phone()#logger.info(f"要被替换的子字符串:{mark}")if "()" in mark:fun_name = result.group(1) # 第一个分组的值 结果是 gen_unregister_phone()logger.info(f"要提取环境变量的函数名:{fun_name}")# 通过eval拖引号之后,不可以直接GenData().gen_unregister_name(),要导包gen_data = eval(f'GenData().{fun_name}') # 接口函数的返回值结果-生成的数据logger.info(f"生成的随机的数据是:{gen_data}")# 1、存数据到环境变量里 -- 类属性的名字 函数名去掉()var_name = fun_name.strip("()") # 结果是 gen_unregister_phonesetattr(EnviData,var_name,gen_data) # 属性名:gen_unregister_phone 属性值: gen_datalogger.info(f"环境变量的属性值:{EnviData.__dict__}")# 2、完成第一条的参数的替换 用刚刚生成的数据替换str_data = str_data.replace(mark,str(gen_data))logger.info(f"替换完成后的字符串是:{str_data}")else:var_name = result.group(1) # 第一个分组的值 结果是 prodIdlogger.info(f"要提取环境变量的属性名:{var_name}")try:var_value = getattr(EnviData,var_name) # 结果 : 7717--int类型except AttributeError as e:logger.error(f"环境变量里不存在这个属性:{var_name}")raise elogger.info(f"要提取环境变量的属性值:{var_value}")str_data = str_data.replace(mark,str(var_value))logger.info(f"替换完成后的字符串是:{str_data}")return str_dataif __name__ == '__main__':# str_data = '{"basketId": 0, "count": 1, "prodId": #prodId#, "shopId": 1, "skuId": #skuId#}'str_data = '{"mobile": "#gen_unregister_phone()#"}'replace_mark(str_data)
handle_mysql.py:数据库的连接封装
import pymysql
from pymysql.cursors import DictCursor
from loguru import loggerclass HandleMysql:def __init__(self,user,password,database,port,host):"""定义了两个实例属性: conn cursor ,可以用于后续实例方法共享。"""self.conn = pymysql.connect(user=user,password=password,database=database,port=port,host=host,charset="utf8mb4",cursorclass=DictCursor)self.cursor = self.conn.cursor()def query_data(self,query_sql,match_num=1,size=None):""":param query_sql: 查询sql语句:param match_num: 用户获取条数 match_num=1,fetchone;match_num=2,fetchmany,match_num=-1,fetchall:param size:当match_num=2,size是查询的条数,传参。:return: 返回查询结果数据"""try:result = self.cursor.execute(query_sql) # 结果条数 >0 才有获取详细数据必要logger.info(f"数据库的查询结果条数为:{result}")if result > 0:if match_num==1:data = self.cursor.fetchone()logger.info(f"查询结果数据为:{data}")return dataelif match_num == 2:data = self.cursor.fetchmany(size = size)logger.info(f"查询结果数据为:{data}")return dataelif match_num == -1:data = self.cursor.fetchall()logger.info(f"查询结果数据为:{data}")return datalogger.warning("请传入1,2,-1的match_num")logger.info("数据库没有查询结果!")except:logger.error("数据库操作异常!")finally:self.cursor.close()self.conn.close()if __name__ == '__main__':my_db = {"user": "lemon_auto","password": "lemon!@123","database": "yami_shops","port": 3306,"host": "mall.lemonban.com"}sql = "select mobile_code from tz_sms_log where user_phone='13645321122' order by rec_date desc limit 1;"result = HandleMysql(**my_db).query_data(sql)print(result)
handle_requests.py :请求模块封装
请求模块:将处理好的数据通过requests模块发送请求,在发送请求之前判断是否含有前置sql,有就调用前置sql函数并进行参数替换检查和参数替换操作。
"""
方法优化:
1、日志加上2、测试用例方法里调用夹具 获取返回值。
- 更新requests-api,需要做token处理:- 设置一个默认参数:token = None- 如果接口需要鉴权,测试用例里调用夹具,得到token,requests_api传递token参数;--requests 更新头部- 如果接口不需要鉴权: token不传 None。 不会做更新头部的操作。"""import jsonimport allure
import requests
from tools.handle_path import pic_path
from loguru import logger
from tools.handle_extract import extract_response
from tools.handle_replace import replace_mark
from tools.handle_presql import pre_sql@allure.step("发送接口请求")
def requests_api(casedata,token=None):method = casedata["请求方法"]url = casedata["接口地址"]headers = casedata["请求头"]params = casedata["请求参数"]presql = casedata["前置SQL"]# 在执行前置SQL之前,替换占位符数据presql = replace_mark(presql)# 在数据替换之前调用前置SQL方法:调用完成后,把结果放到环境变量里pre_sql(presql)# 在发送请求之前完成头部和参数的替换--调用替换的函数==结果是字符串headers = replace_mark(headers)params = replace_mark(params)url = replace_mark(url) # 替换掉url地址里的占位符# 反序列操作: 结合判空处理,if headers is not None:headers = json.loads(headers)if token is not None: # 这是做接口如果需要鉴权,传进来token 更新头部信息。headers["Authorization"] = token # 字典新增 / 修改if params is not None:params = json.loads(params)logger.info("---------------------------请求消息-----------------------------------")logger.info(f"请求方法是{method}")logger.info(f"请求地址是{url}")logger.info(f"请求头部是{headers}")logger.info(f"请求参数是{params}")#接口请求可能是get post put等各种请求方法 分支判断if method.lower() == "get":resp = requests.request(method=method, url=url, params=params,headers=headers)elif method.lower() == "post":if headers is None:logger.info("头部为空,检查excel表格里头部信息!")return# post请求:content-type的类型有关系。需要对每一种类型做处理 分支判断if headers["Content-Type"] == "application/json":resp = requests.request(method=method, url=url, json=params, headers=headers)if headers["Content-Type"] == "application/x-www-form-urlencoded":resp = requests.request(method=method, url=url, data=params, headers=headers)if headers["Content-Type"] == "multipart/form-data":# 发送请求的时候不能带上 'Content-Type': 'multipart/form-data' 删除之后才发送接口请求。headers.pop("Content-Type") # 字典删除元素filename = params["filename"] # 文件名字 值file_obj = {"file": (filename, open(pic_path/filename, "rb"))} # 文件参数logger.info(f"文件接口的参数是:{file_obj}")logger.info(f"文件接口的头部是:{headers}")resp = requests.request(method=method, url=url,headers=headers,files=file_obj)elif method.lower() == "put":resp = requests.request(method=method, url=url, json=params, headers=headers)logger.info("------------------------------响应消息-----------------------------")logger.info(f"接口响应状态码是:{resp.status_code}")logger.info(f"接口响应体是:{resp.text}")# 提取响应结果的数据-- 调用提取数据的函数extract_response(resp,casedata["提取响应字段"])return resphandle_extract.py :提取响应结果
提取响应结果:通过excel文件读取的内容判断是否需要提取响应结果,并提取响应结果到环境变量
"""
1、def封装
2、参数化
3、返回值: 因为数据都存在环境变量 所以不需要返回值
4、加上日志: 但凡你想确认数据结果的地方 都可以加上日志
5、因为有些接口不需要做数据提取,所以判空处理:注册接口,要二次修改 extract提取的方法。加一个判断分支:思路如下 {"check_code":"text"}* 1、针对键值对的值做判断,是$开头的就是jsonpath* 2、v如果是text 就是直接获取响应文本。* 3、结果都是存在环境变量里的。
"""import jsonimport allure
from jsonpath import jsonpath
from loguru import logger
from tools.envi_data import EnviData@allure.step("提取响应结果")
def extract_response(response,extract_data):# 因为有些接口不需要做数据提取,所以判空处理:if extract_data is None:logger.info("这条用例不需要做响应结果的数据提取!")return# 第一步: 反序列化 -字典logger.info("-----------------响应结果提取开始------------------------------")extract_data = json.loads(extract_data)logger.info(f"提取的响应结果的表达式是:{extract_data}")for k,v in extract_data.items(): # k 是access_token | check_code 变量名字,v是$..access_token | text# 因为响应结果有可能是json格式 也有可能是文本格式: 所以,这里要做判断分支:if v.startswith("$"):# 使用jsonpath表达式 提取login响应结果里的值value = jsonpath(response.json(),v)[0] # 是access_token的具体值elif v == "text": # 如果是文本 用响应消息获取文本value = response.text# 存起来到环境变量里去setattr(EnviData,k,value)logger.info(f"提取并设置环境变量之后的类属性是:{EnviData.__dict__}")handle_response_assert.py: 断言封装
断言封装
先判断excel文件读取的数据是否需要断言,
提取预期结果-----》读取的数据进行序列化操作
将预期结果和实际结果进行比对
"""
函数优化:
1、加日志: 方便做跟踪
2、异常捕获: 断言成功或者失败的结果 记录日志 / 断言失败 ; 异常抛出
3、因为有些用例的步骤可能不需要做断言 这个预期结果字段空的 --None 判空处理。
"""
import jsonimport allure
from jsonpath import jsonpath
from loguru import logger@allure.step("响应结果断言步骤")
def response_assert(expected_data,login_resp):"""这是做响应断言的函数:param expected_data: 从excel表格里读取的预期结果表达式:param login_resp:登录的响应消息:return:"""# 这是判断处理 --不需要断言if expected_data is None:logger.info("这条用例不需要做断言!!")return# 第一步: 反序列化操作: 转化为字典logger.info("----------------------断言开始-----------------------------")expected = json.loads(expected_data)logger.info(f"json反序列之后的期望结果是:{expected}")# 第二步: 取到期望结果键值对: key 是jsonpath 表示式,value是断言的预期结果for k,v in expected.items():if k.startswith("$"):# k是 "$..nickName",v 是lemon_pytry:actual_result = jsonpath(login_resp.json(),k)[0]except Exception as e:logger.error("接口执行失败,响应数据提取失败")raise elogger.info(f"执行结果是:{actual_result}")try:assert actual_result == vlogger.info("断言通过!")except Exception as e:logger.error("断言失败!")raise eelif k == 'text':actual_result = login_resp.textlogger.info(f"执行结果是:{actual_result}")try:assert actual_result == vlogger.info("断言通过!")except Exception as e:logger.error("断言失败!")raise ehandle_db_assert.py:数据库断言
判断excel读取的内容是否需要数据库断言
调用数据库handle_mysql.py函数进行操作并进行比对
"""
1、def封装
2、参数化
3、返回值: 数据库断言不需要返回值
4、加上日志: 但凡你想确认数据结果的地方 都可以加上日志
5、因为有些接口不需要做数据提取,所以判空处理:
6、异常捕获: 因为断言失败要加日志 记录 并raise错误 使测试用例失败"""
import jsonimport allurefrom tools.handle_replace import replace_mark
from tools.handle_mysql import HandleMysql
from datas.db_data import my_db
from loguru import logger@allure.step("数据库结果断言步骤")
def database_assert(assert_data):if assert_data is None: # 判空处理returnlogger.info("--------------------数据库断言开始----------------------------")# 第一步:先读取数据出来-- 反序列化 转化字典assert_data = json.loads(assert_data)logger.info(f"数据库断言的表达式:{assert_data}")# 第二步: 得到key【sql】 和value【预期数据库查询结果】for k,v in assert_data.items(): # k是sql语句,v是数据库预期结果# 第三步: sql里有占位符,先替换-调用replace方法k = replace_mark(k)logger.info(f"数据库查询sql是{k}")# 第四步: 调用数据库封装的方法 执行查询语句 得到数据库查询结果sql_result = HandleMysql(**my_db).query_data(k) # 数据库的查询结果:{'count(*)': 1}| {'status': 2}# 第五步: 把预期结果和查询结果 断言for i in sql_result.values(): # i是数据库查询结果字典的values 1 2这个数据 ==执行结果logger.info(f"数据库断言的实际结果是{i}")logger.info(f"数据库断言的预期结果是{v}")try:assert i == vlogger.info("数据库断言成功!")except AssertionError as e:logger.error("数据库断言失败!")raise ehandle_generate.py :随机生成用户名和手机号
随机生成用户名和手机号,并调用数据库检查生成的数据是否存在系统中
(在变量替换中会检查对应字段是够含有随机生成函数并调用函数进行赋值)
"""
用户名有长度要求: 4-16位长度的用户名因为这些生成数据的方法可能需要后续进行扩展: 生成其他的数据。
所以可以把这些方法都当到一个类里。 统一管理。思考:这个函数应该在哪里执行呢?
思路:
1、执行第一个接口的时候,需要替换掉参数里的占位符位置-- 调用函数并执行函数的结果"""from faker import Faker
from tools.handle_mysql import HandleMysql
from datas.db_data import my_dbclass GenData:def gen_unregister_phone(self):fk = Faker(locale="zh_CN")while True:# 第一步:调用faker类生成手机号码phone_number = fk.phone_number()# 第二步:把生成的数据去数据库里确认是否真的不重复sql = f'select * from tz_user where user_mobile = "{phone_number}"'sql_result = HandleMysql(**my_db).query_data(sql)if sql_result is not None: # 如果数据里有这个号码 继续生成 循环continueelse: # 如果数据里没有这个号码 得到号码 跳出循环return phone_numberdef gen_unregister_name(self):fk = Faker(locale="zh_CN")while True:# 第一步:调用faker类生成用户名username = fk.user_name()# 第二步:把生成的数据去数据库里确认是否真的不重复sql = f'select * from tz_user where user_name = "{username}"'sql_result = HandleMysql(**my_db).query_data(sql)if sql_result is not None or (len(username) < 4 or len(username) > 16): # 如果数据里有这个号码 继续生成 循环continueelse: # 如果数据里没有这个号码 得到号码 跳出循环return usernameif __name__ == '__main__':print(GenData().gen_unregister_phone())print('GenData().gen_unregister_name()')result = eval('GenData().gen_unregister_name()')print(result)dates:测试数据
存放测试数据与输入数据
测试数据excel文件目录如下:

注册调用随机函数写法如下:
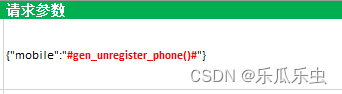
直接调用handle_generate.py文件下的对应模块
上传接口

testcase:测试用例
test_07_cart.py 测试用例文件名必须按照pytest框架的规范来命名。
"""
调用夹具,得到token;
发送请求的方法 里没有使用token 地方。
"""
import jsonimport pytest
import requests
from tools.handle_response_assert import response_assert
from tools.handle_excel import read_data
from tools.handle_path import exc_path
from tools.handle_requests import requests_api
from tools.handle_db_assert import database_assert
import allure# 第一步: handle_excel读取测试用例的数据 --列表嵌套字典,每个字典是一个用例
all_cases = read_data(exc_path,"购物车")# 第二步: pytest测试用例方法
@pytest.mark.p1
@allure.suite("购物车模块")
@allure.title("{data[用例标题]}") # 使用测试用例的excel的用例标题描述每一条用例 更直观
@pytest.mark.parametrize("data",all_cases)
def test_cart_case(data): # 调用夹具resp = requests_api(data)expected = data["预期结果"] # 从excel读取预期结果db_assert = data["数据库断言"]response_assert(expected,resp)# 数据库断言database_assert(db_assert)
其他文件
conftest.py
"""
执行一个接口执行之前 先要执行另外一个接口 获取数据【token】 给到下一个使用:
- pytest的夹具
- yield 返回值
- conftest 共享定义夹具 获取token"""
import pytest
import requests
from jsonpath import jsonpath@pytest.fixture()
def login_fixture():url_login = "http://shop.lemonban.com:8107/login"param = {"principal": "lemon_py", "credentials": "12345678", "appType": 3, "loginType": 0}resp = requests.request("post",url=url_login,json=param)access_token = jsonpath(resp.json(), "$..access_token")[0] # jsonpath 提取数据token_type = jsonpath(resp.json(), "$..token_type")[0]token = token_type+access_tokenyield token # 夹具的返回值pytest.ini :用例优先级
通过excel文件中的优先级来执行用例
[pytest]
markers=p1p2p3high
run.py
from tools.handle_path import log_path# 存储日志文件代码
import pytest
from loguru import logger
from tools.handle_path import log_pathlogger.add(sink=log_path,encoding="UTF8",level="INFO",rotation="10MB",retention= 20)# pytest.main(["-v","--alluredir=outputs/allure_report","--clean-alluredir"])
pytest.main(["-v","-m p1","--alluredir=outputs/allure_report", "--clean-alluredir"])