一文读懂时序数据库 IoTDB。
01
为什么需要时序数据库
解释时序数据库前,先了解一下何谓时序数据。
时序数据,也称为时间序列数据,是指按时间顺序记录的同一统计指标的数据集合。这类数据的来源主要是能源、工程、交通等工业物联网强关联行业的机器设备和传感器,如汽车的车速、发动机转速,发电风车的功率、电压、电流等。
时序数据的典型特征包括:
• 测点多:在工业领域,设备数量可达百万级别,数据测点可达亿级,并随业务增长动态增加。
• 采样频率高:在部分振动状态监控场景下,采样频次可达 1kHz。
• 存储成本高:数据的月增量可达 10TB 以上,并需长期存储海量历史数据。
顾名思义,时序数据库是专门用于管理时序数据的数据库类型。时序数据库近些年之所以受到越来越多的关注,主要原因便是物联网设备和数据量的爆炸式增长。通过对历史数据以及新产生的时序数据进行管理和分析,时序数据库能够助力工业企业实现数字化转型、工业 4.0 升级,进而达到降低成本、提高效率、提升产品质量等目的。
02
IoTDB 诞生的价值
IoTDB 是一款国产自研的物联网原生时序数据库,其技术发源于清华大学,目前已历经 13 年的发展。IoTDB 的诞生,主要是为了解决工业物联网时序数据管理的实时性、压缩比、分布式部署等多方面痛点。
开源版 IoTDB 是 Apache 基金会时序数据领域第一个 Top-Level 项目,其核心团队成立了天谋科技(北京)有限公司(以下简称“天谋科技”),专注 IoTDB 产品的打磨。
IoTDB 提供数据采集工具,可对接多类协议,底层为纯自研列式存储文件系统 TsFile,在此基础上设计存储、查询计算、流处理、分析引擎,以及系统管理模块与多种应用工具,并支持对接大数据生态,与单机版、分布式版、双活版等多类形态部署。
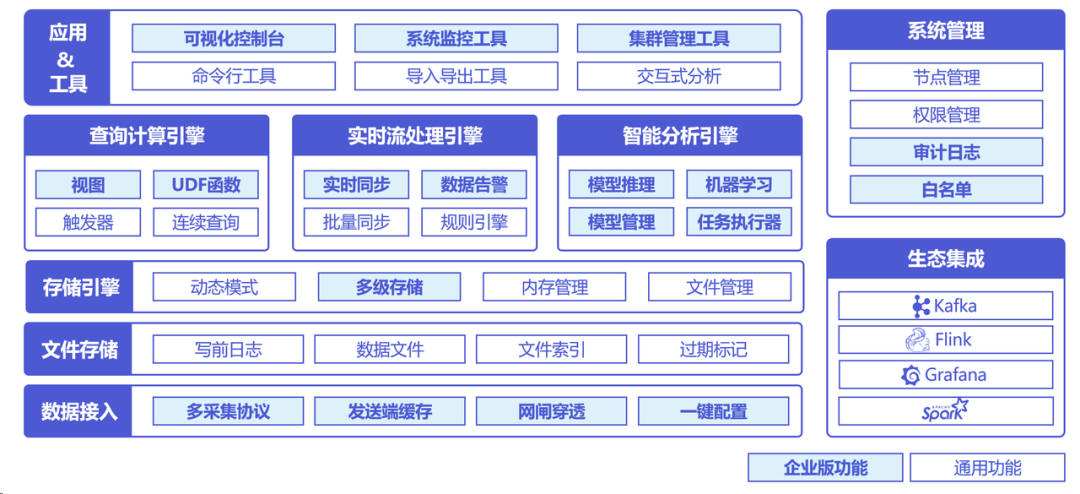
通过多项自研技术创新成果,IoTDB 在不依赖第三方系统的情况下,可以实现高吞吐、高压缩、高可用的性能表现,并建立了物联网场景时序数据横向与纵向解决方案。
横向解决方案以 IoTDB 为时序数据系统内核,通过其优异的存、读、写能力,上游对接多类采集协议,下游对接多类数据分析处理平台,可支持时序数据单平台采集、存储、计算、管理、应用全流程。
纵向解决方案可将 IoTDB 部署于多个平台,实现跨厂、跨车间应用,IoTDB 强大的数据同步能力与简便的数据同步机制,可支持跨平台端(可为设备侧/车间侧)、边(可为厂侧)、云(可为集团侧)数据协同。

03
IoTDB 七大功能特性
IoTDB 能够实现稳定、高效、易用的时序数据管理方案,在国际数据库基准测试性能排行榜 benchANT 中,IoTDB 的读、写、压缩指标均排名第一。其功能特性可简单归结为“管得好、接得住、存得下、处理强、实时性、智能性、协同性”七个词。
一、管得好:基于业务,便捷建模
对于一款时序数据库而言,面对海量的时序数据,首先需要在最底层,也就是数据建模层面,确保这些时序数据能够被很好地管理。
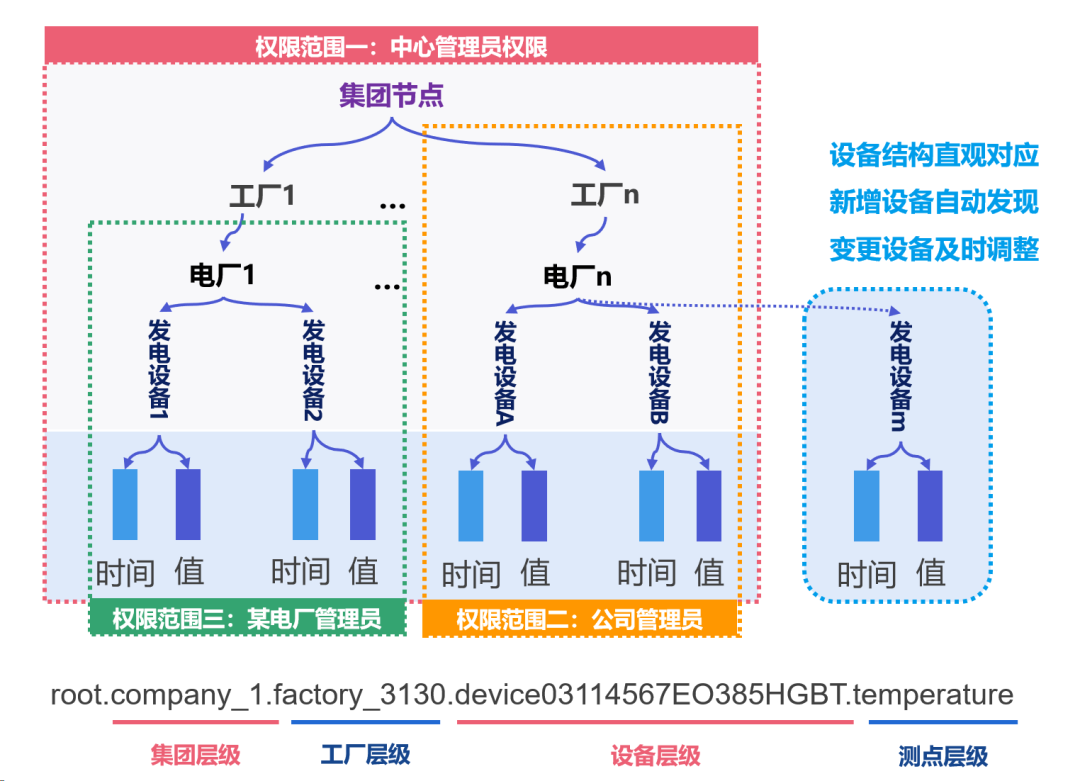
从 OT 视角而言,物联网场景中产线、设备产生的 BOM 数据是按照层级,彼此关联起来的。比如集团下可能有很多工厂,工厂中有很多产线,产线中有很多设备,最终这些设备再产生数据。
因此,IoTDB 实现了树形时序数据模型,能够直观地与 BOM 数据进行对应。同时对于需要新增或变更的设备,也能够做到自动化同步,这就有效地降低了时序数据管理与运维的成本。
同时,IoTDB 自研的基于 PBTree 的元数据管理模型,可以实现亿级的时间序列管理规模,并降低数据冗余,能够通过高效的元数据存储提高 IoTDB 管理的数据质量。
最后,在树形模型基础上,IoTDB 可以对序列级的权限进行更好的控制,比如可以为集团级、工厂级、产线级数据设置不同的权限范围,进而达到多层级数据高效管理的目的。
二、接得住:高频数据、乱序数据高写入
底层数据建模确定后,IoTDB 在物联网时序数据生命周期的多个环节也都能够解决一些常见难题。
第一个环节自然是时序数据的写入,该环节第一个难题在于高频数据的写入。针对前面提到的振动场景 1kHz 的采集频率,传统时序数据库一般因为采用行式数据写入,所以只能支持到秒级数据接入。
而 IoTDB 可通过底层文件 TsFile 支持的列式数据写入,达到毫秒级的数据接入,相比竞品有 10 倍的性能优势。
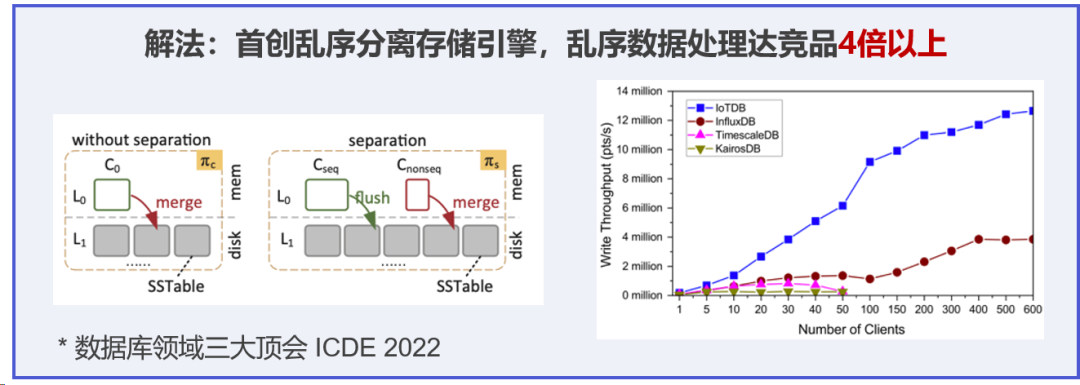
第二个难题是乱序数据的写入。乱序数据可以简单理解为“早产生的数据后到了,晚产生的数据先到了”。在实际场景中,因为弱网环境导致的断网、延迟等问题,数据无法保序到达,产生乱序数据的情况非常常见。以天谋科技接触到的某电厂客户为例,其数据存在 50% 以上的乱序数据,延迟时长在 0 到 300 分钟不等。
针对这一问题,IoTDB 首创了乱序分离存储引擎,用独有的顺乱序判断的机制,将顺序数据与乱序数据分开,并通过多种空间合并的方法,去消除乱序数据。IoTDB 的乱序数据处理效率可以达到竞品的 4 倍以上。
三、存得下:首创标准文件格式 TsFile
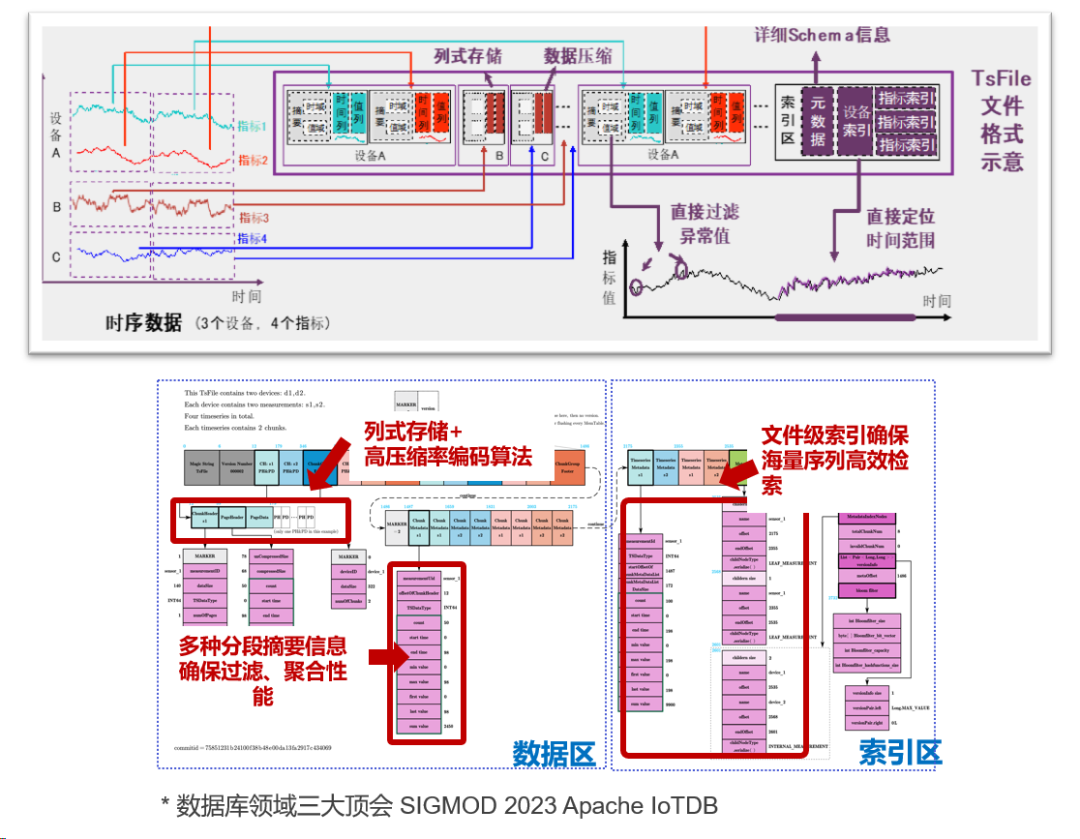
时序数据存储方面一直面临着一个难题:海量数据导致存储成本高昂,而 IoTDB 通过自研的时序数据标准文件格式 TsFile 解决了这一难题。
TsFile 结合列式存储、编码算法、分段摘要信息、文件级索引等架构,相比通用的文件格式,对时序数据的压缩比可以提升 20% 以上,达到无损压缩 10 倍以上、无损压缩 100 倍以上的压缩比。
另外,TsFile 架构针对时序数据特性的优化,也使得 IoTDB 有效提升了时序数据的写入与查询效率。相比竞品,IoTDB 的写入吞吐量提升了 2-3 倍,查询吞吐量则提升了 2-10 倍。
值得一提的是,继 IoTDB 之后,TsFile 已经被 Apache 基金会通过成为时序数据领域第二个 Top-Level 项目,这就意味着其不但能够与 IoTDB 共同使用,还可以作为单独文件格式进行使用。
四、处理强:支持时序特性查询分析
解决了写入、存储问题,下一步自然便是运用数据。时序数据因为强时间属性,在查询时用户很可能有一些特殊的、强关联时间的需求。常见场景包括在数据密集情况下,想清晰地知道数据的走势、最新值;想以时间为维度,查询一段时间内的数据情况等等。
这些特性的交互式查询 IoTDB 都是支持的,比如针对上述的场景,IoTDB 可提供降采样查询、最新点查询和时间分段查询。
降采样查询可以去掉原始高频数据不必要的细节,还原数据的基本趋势;最新点查询通过缓存每个设备的最新值,实现毫秒级响应;时序分段查询可以根据数据的变化阈值、中断间隔等等维度进行多样的分段查询。
再进一步,IoTDB 还提供一套 UDF(用户自定义函数)体系,提供超过 70 种内置函数,可满足数据修复、数据图像、异常检测等时序数据计算需求。如果用户还有在这套体系之外的计算需求,也可自行在 IoTDB 中编辑、保存常用的 UDF 函数。
查询、计算双管齐下,IoTDB 希望帮助用户最大化地开发时序数据的价值。

五、智能化:AINode 拥抱机器学习
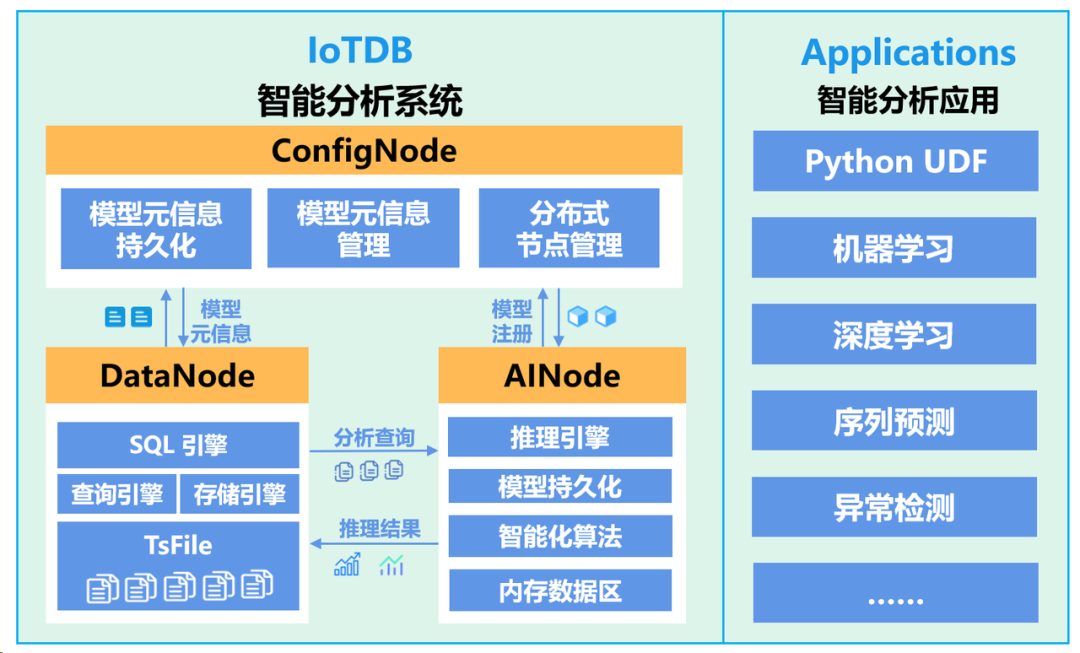
如今我们正迎来智能时代,IoTDB 自然要拥抱 AI。为了更好地让 IoTDB 实现智能化分析,IoTDB 团队在 2023 年为 IoTDB 集群引入了智能分析节点 AINode。
AINode 通过与集群管理节点(ConfigNode)、数据节点(DataNode)的交互,可以为用户提供模型注册、管理、推理的能力,结果可直接在 IoTDB 返回。同时也涵盖了时序数据适用的多类算法和自研模型,能够实现序列预测、异常预测等时序分析场景需要的深度学习功能。
IoTDB 支持让时序数据与机器学习、模型分析领域的技术成果更好地结合,为用户提供更深入、多样的数据分析方法。
六、实时性:内置实时流处理功能
在时序数据的基础场景之外,IoTDB 团队在 2023 年加入了实时流处理功能,可不间断地处理数据,并及时发现异常或分析趋势。
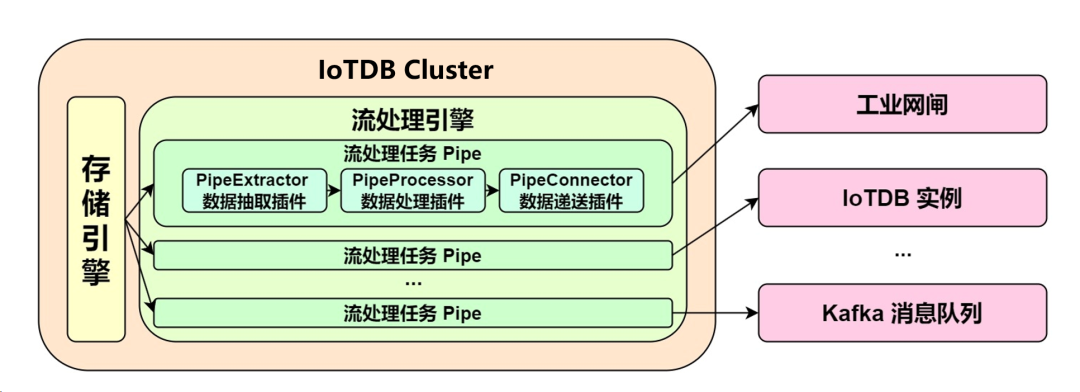
IoTDB 中,一个流处理任务(Pipe)包含抽取(Extract)、处理(Process)、发送(Connect)三个子任务,三个子任务可由三种独立插件进行实现,并允许用户自定义配置三个子任务的处理逻辑和具体属性,通过组合不同的子任务内核,实现灵活的数据 ETL 能力。
利用流处理框架,可以在 IoTDB 搭建完整、灵活的数据链路,实现毫秒级的低延迟响应,满足端边云数据同步、双活集群部署、网闸穿透、实时告警、数据订阅、异地灾备、读写负载分库等场景需求。
七、云边协同:文件+引擎,全面数据协同
工业物联网应用场景中,产生数据的设备可能来自于多个厂站,数据经常需要汇总至省域或集团进行分析,所以时序数据库需要多终端、多环境、多平台部署。
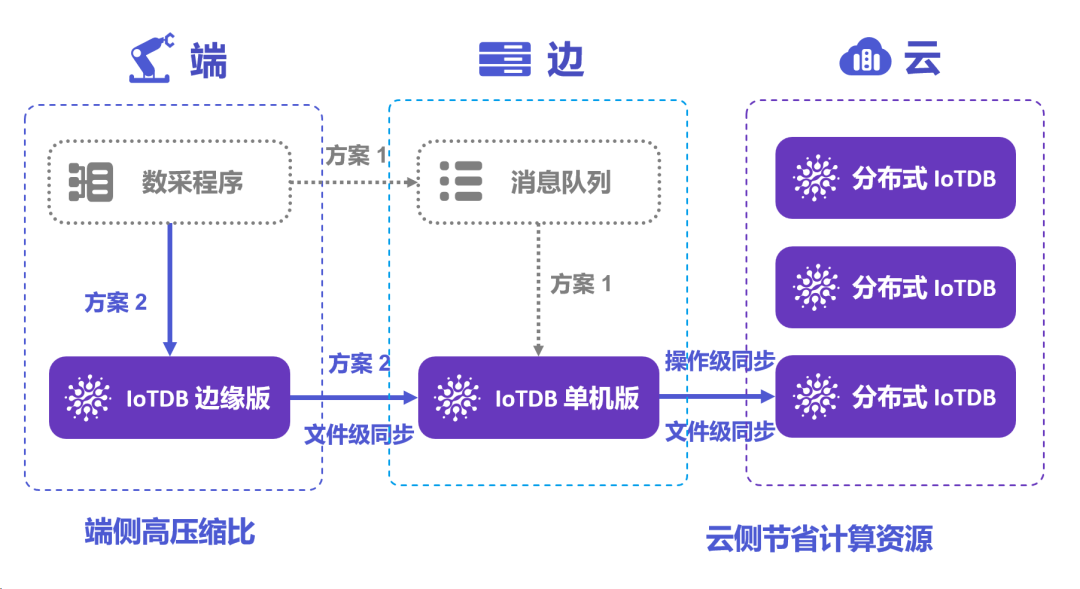
IoTDB 的数据同步便解决了这一问题。该方案基于可插拔的 TsFile 文件,并支持操作级、文件级的多种传输模式,与跨网闸传输、加密传输。同一个文件类型可在端、边、云侧进行协同传输,同步方案的易用性得以保障;传输模式多样则保障数据传输的实时性、吞吐量、安全性。
同时,IoTDB 的数据同步支持数据在边侧进行必要的数据清洗与计算操作,再向云侧进行同步,能够最大化地利用边侧的算力资源,同时节省云侧算力资源。
此外,企业因为业务扩张,往往也经常需要扩展数据库部署规模。IoTDB 的分布式架构具备高扩展性,可以达到秒级扩容、无需迁移数据、灵活调整。
除上述功能外,IoTDB 的类 SQL 语言、多语言 SDK、API 接口等功能支持,能够面向不同的业务需求实现二次开发,有效降低了开发人员的学习成本。IoTDB 也支持与多类大数据系统进行生态集成,实现时序数据管理解决方案的全生命周期覆盖。
为进一步提升 IoTDB 的使用体验,天谋科技还研发了一系列配套工具,包括集群管理工具 IoTDB-OpsKit、系统监控面板、可视化控制台 Workbench、组态软件等等。这些服务数据库运维人员与业务人员的工具易于交互,能让所有数据库功能被看到,所有数据细节被分析。

04
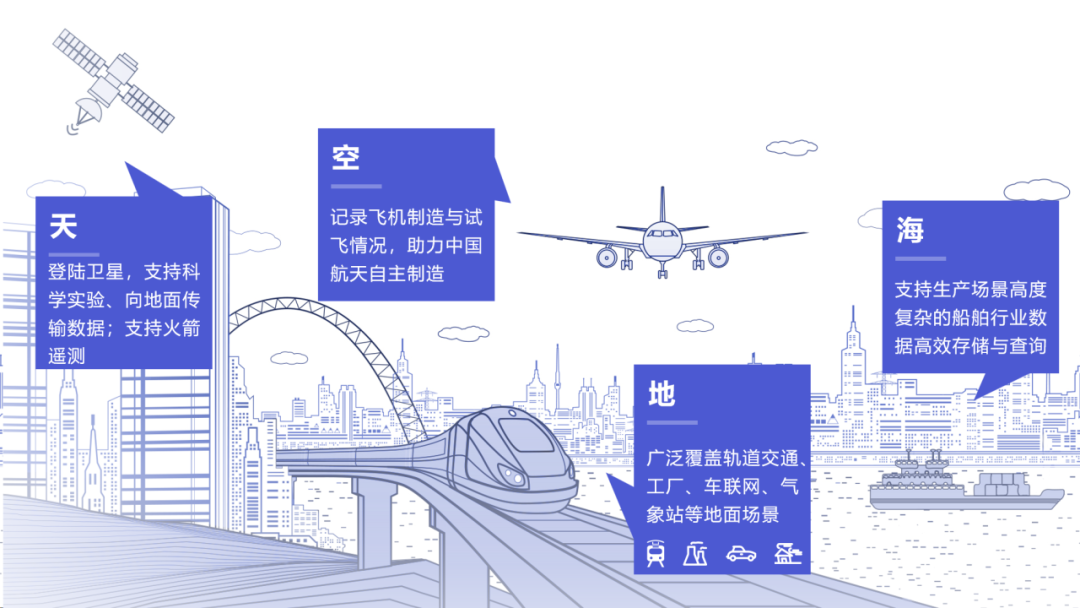
IoTDB 广泛应用于 “天、空、地、海”
目前,天谋科技构建的 IoTDB 解决方案在业内得到了广泛应用,覆盖“天、空、地、海”各个层面。
IoTDB 落地的主要行业与应用效果有:
• 电力:已有案例可支持千万级设备并发,管理百亿级累计数据,并支持设备端侧、现场边缘侧与中心云侧的端边云数据协同传输,与电力行业特性的跨网闸数据传输。
• 储能:已有案例可达到毫秒级数据写入、毫秒级查询响应、超 90 倍压缩比,并实现大字段数据自动挂载、多字段、多路径、多关键词复杂查询等功能。
• 钢铁:已有案例可用少量服务器管理集团全量数据,涉及装备数百万,时间序列达千万,并加速了数据的加工、抽取、备份过程,性能提升 1 个量级。
• 太空:IoTDB 于北邮一号卫星边缘侧成功部署,实现低 CPU 使用率及内存占用,与不定期关机场景下数据的自动保存与恢复,有效支持星-地数据协同。
• 飞机制造:已有案例压缩率可达 10 倍,空间占用缩减为 30%,预计节省百万存储成本,并协助实现异地工厂端与云中心侧的分布式数据互通和统一管理,与应用层、产线层、设备层多个应用系统的数据存储与调用。
• 轨道交通:已有城轨案例管理列车数能力增加 1 倍,采样时间提升 60%,需要服务器数降为 1/9,月数据增量压缩后大小下降 95%,实现日增 4140 亿数据点管理。
• 车联网:已有案例管理约 1.5 亿时间序列,稳定支持千万级写入数据与单车时间范围查询、单车全时间序列最新点查询结果毫秒级返回。
• 先进制造:已有案例压缩比达 10 倍以上,支持多种查询方式与多点位同时查询的需求,针对流程长、工艺复杂、精度高、数据量大的制造场景,支撑对核心指标进行实时分析。
目前,应用 IoTDB 的工业企业已经超过 1000 家,其中包括国家电网、中核集团、中航成飞、中国中车、中国气象局等国内企业,和博世力士乐、德国宝马、西门子、日本小松等海外企业。
此外,IoTDB 还被集成应用于华为、阿里、海尔、东方国信、用友等多个工业互联网平台中。
05
做能用、好用、管用的国产时序数据库
过去 13 年里,IoTDB 打破了海量时序数据管理的瓶颈,将最初的技术思考转化为一个成熟的项目,实现了多项自研技术突破,也将产品体系商业化。
这期间,天谋科技扮演着不可或缺的的角色,让 IoTDB 技术创新不止停留在科研、论文,而是真正在多个行业落地,帮助用户挖掘时序数据的价值,并根据用户反馈确定下一步的研发方向。
未来,随着物联网的发展以及时序数据管理的场景扩展,IoTDB 会迎来更多的机会。天谋科技将坚定“做一款国产自研的,能用、好用、管用的时序数据库”的信念,不断迭代、优化,切实满足用户需求,让 IoTDB 成为物联网领域的强力基建。