一、目的
为了整理离线数仓开发的全流程,算是温故知新吧
离线数仓的数据源是Kafka和MySQL数据库,Kafka存业务数据,MySQL存维度数据
采集工具是Kettle和Flume,Flume采集Kafka数据,Kettle采集MySQL数据
离线数仓是Hive
目标数据库是ClickHouse
任务调度器是海豚
二、数据采集
(一)Flume采集Kafka数据
1、Flume配置文件
## agent a1
a1.sources = s1
a1.channels = c1
a1.sinks = k1
## configure source s1
a1.sources.s1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.s1.kafka.bootstrap.servers = 192.168.0.27:9092
a1.sources.s1.kafka.topics = topic_b_queue
a1.sources.s1.kafka.consumer.group.id = queue_group
a1.sources.s1.kafka.consumer.auto.offset.reset = latest
a1.sources.s1.batchSize = 1000
## configure channel c1
## a1.channels.c1.type = memory
## a1.channels.c1.capacity = 10000
## a1.channels.c1.transactionCapacity = 1000
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/data/flumeData/checkpoint/queue
a1.channels.c1.dataDirs = /home/data/flumeData/flumedata/queue
## configure sink k1
a1.sinks.k1.type = hdfs
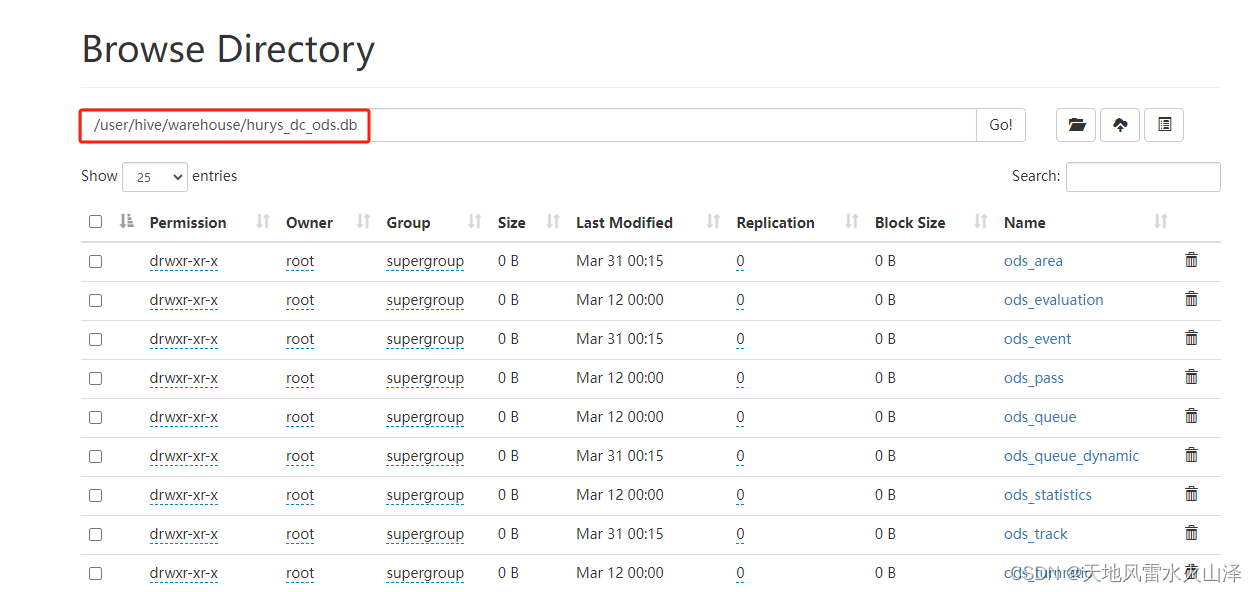
a1.sinks.k1.hdfs.path = hdfs://hurys23:8020/user/hive/warehouse/hurys_dc_ods.db/ods_queue/day=%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = queue
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
a1.sinks.k1.hdfs.rollSize = 1200000000
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 60
a1.sinks.k1.hdfs.minBlockReplicas = 1
a1.sinks.k1.hdfs.fileType = SequenceFile
a1.sinks.k1.hdfs.codeC = gzip
## Bind the source and sink to the channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1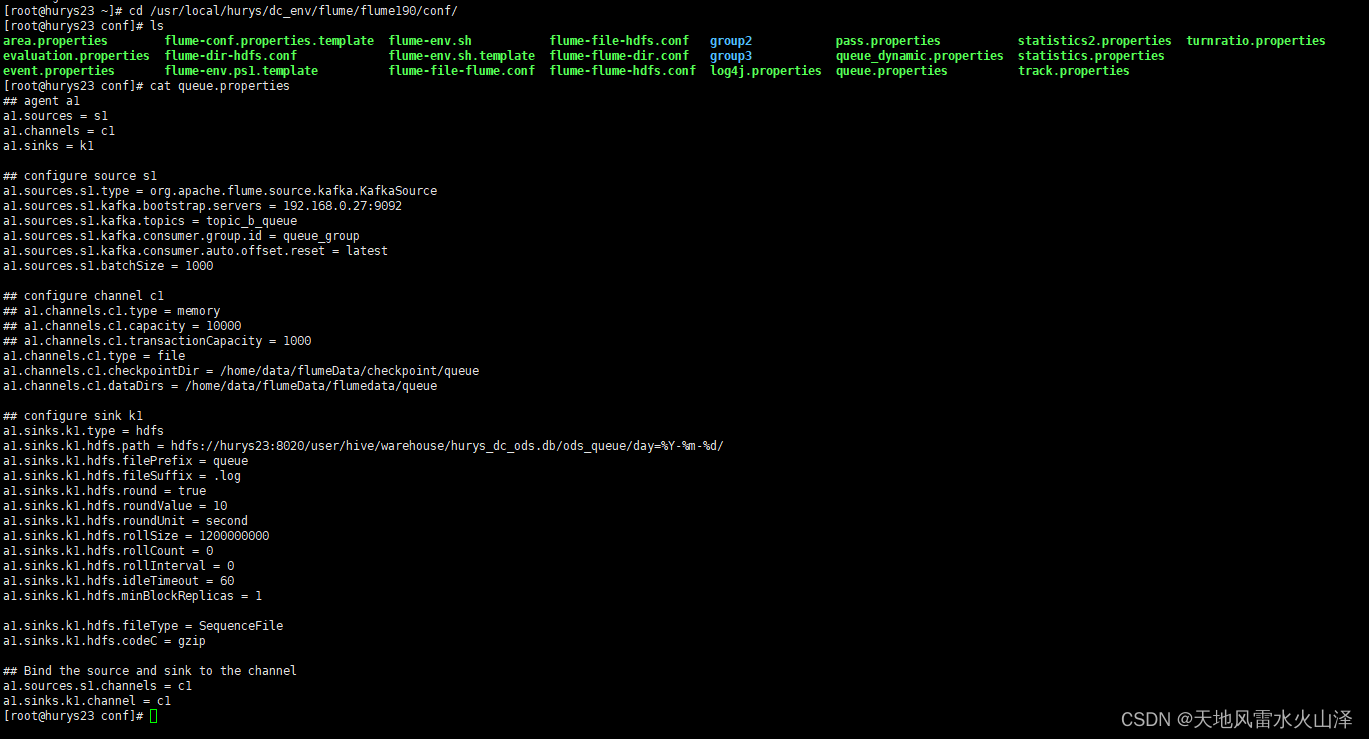
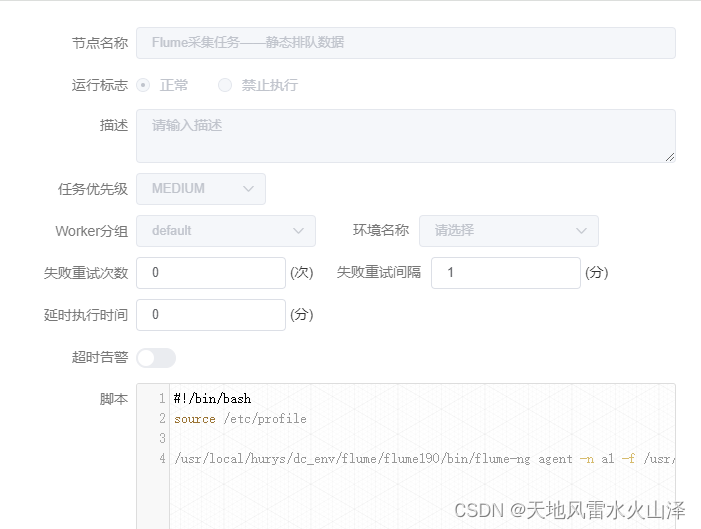
2、用海豚调度Flume任务
#!/bin/bash
source /etc/profile
/usr/local/hurys/dc_env/flume/flume190/bin/flume-ng agent -n a1 -f /usr/local/hurys/dc_env/flume/flume190/conf/queue.properties
3、目标路径
(二)Kettle采集MySQL维度数据
1、Kettle任务配置
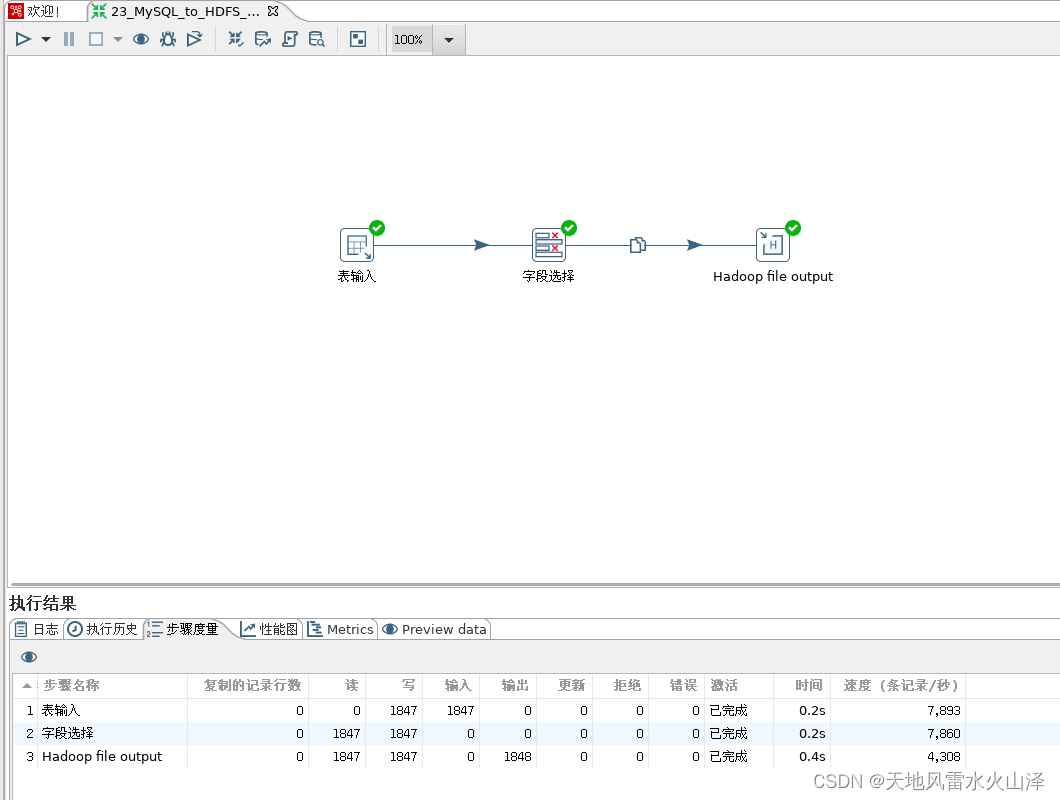
2、用海豚调度Kettle任务
#!/bin/bash
source /etc/profile
/usr/local/hurys/dc_env/kettle/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/mysql_to_hdfs/ -trans=23_MySQL_to_HDFS_tb_radar_lane level=Basic >>/home/log/kettle/23_MySQL_to_HDFS_tb_radar_lane_`date +%Y%m%d`.log

3、目标路径

三、ODS层
(一)业务数据表
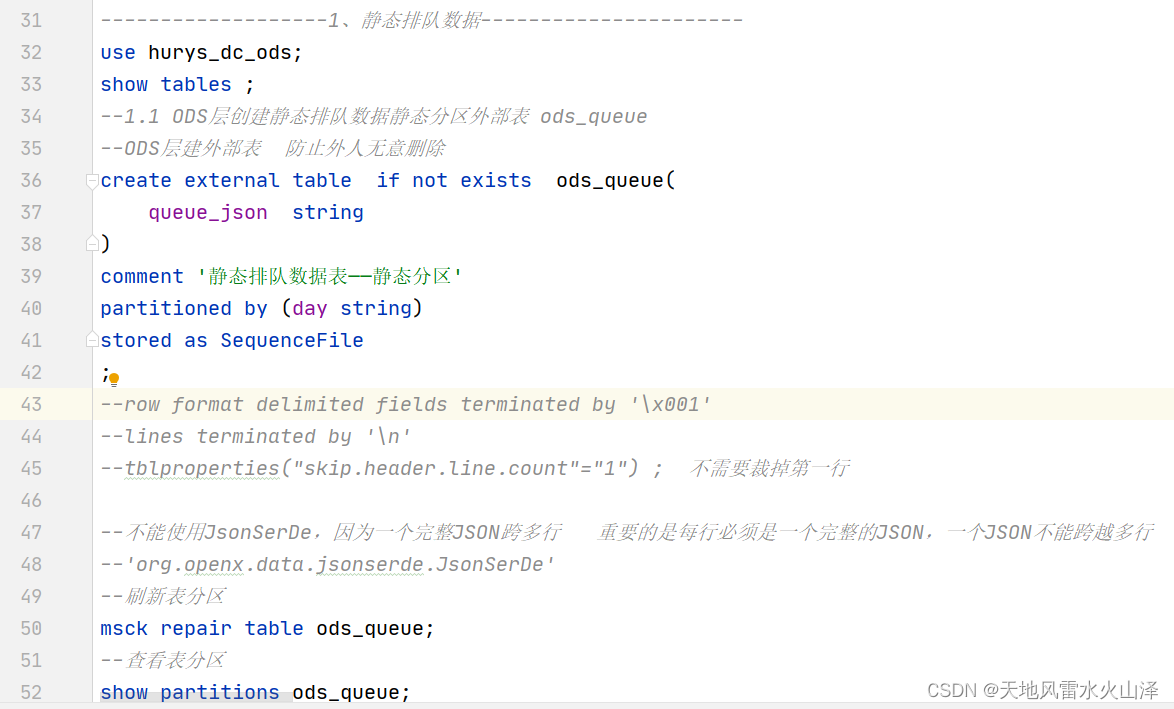
use hurys_dc_ods;create external table if not exists ods_queue(queue_json string ) comment '静态排队数据表——静态分区' partitioned by (day string) stored as SequenceFile ;
--刷新表分区 msck repair table ods_queue; --查看表分区 show partitions ods_queue; --查看表数据 select * from ods_queue;
(二)维度数据表
use hurys_dc_basic;create external table if not exists tb_device_scene(id int comment '主键id',device_no string comment '设备编号',scene_id string comment '场景编号'
)
comment '雷达场景表'
row format delimited fields terminated by ','
stored as textfile location '/data/tb_device_scene'
tblproperties("skip.header.line.count"="1") ;
--查看表数据
select * from hurys_dc_basic.tb_device_scene;

四、DWD层
(一)业务数据清洗
1、业务数据的JSON有多层
--1、静态排队数据内部表——动态分区 dwd_queue
create table if not exists dwd_queue(device_no string comment '设备编号',lane_num int comment '车道数量',create_time timestamp comment '创建时间',lane_no int comment '车道编号',lane_type int comment '车道类型 0:渠化1:来向2:出口3:去向4:左弯待转区5:直行待行区6:右转专用道99:未定义车道',queue_count int comment '排队车辆数',queue_len decimal(10,2) comment '排队长度(m)',queue_head decimal(10,2) comment '排队第一辆车距离停止线距离(m)',queue_tail decimal(10,2) comment '排队最后一辆车距离停止线距离(m)'
)
comment '静态排队数据表——动态分区'
partitioned by (day string)
stored as orc
;
--动态插入数据with t1 as(
selectget_json_object(queue_json,'$.deviceNo') device_no,get_json_object(queue_json,'$.createTime') create_time,get_json_object(queue_json,'$.laneNum') lane_num,get_json_object(queue_json,'$.queueList') queue_list
from hurys_dc_ods.ods_queue)
insert overwrite table hurys_dc_dwd.dwd_queue partition(day)
selectt1.device_no,t1.lane_num,substr(create_time,1,19) create_time ,get_json_object(list_json,'$.laneNo') lane_no,get_json_object(list_json,'$.laneType') lane_type,get_json_object(list_json,'$.queueCount') queue_count,cast(get_json_object(list_json,'$.queueLen') as decimal(10,2)) queue_len,cast(get_json_object(list_json,'$.queueHead') as decimal(10,2)) queue_head,cast(get_json_object(list_json,'$.queueTail') as decimal(10,2)) queue_tail,date(t1.create_time) day
from t1
lateral view explode(split(regexp_replace(regexp_replace(queue_list,'\\[|\\]','') , --将json数组两边的中括号去掉'\\}\\,\\{','\\}\\;\\{'), --将json数组元素之间的逗号换成分号'\\;') --以分号作为分隔符(split函数以分号作为分隔))list_queue as list_json
where device_no is not null and create_time is not null and get_json_object(list_json,'$.queueLen') between 0 and 500
and get_json_object(list_json,'$.queueHead') between 0 and 500 and get_json_object(list_json,'$.queueTail') between 0 and 500 and get_json_object(list_json,'$.queueCount') between 0 and 100
group by t1.device_no, t1.lane_num, substr(create_time,1,19), get_json_object(list_json,'$.laneNo'), get_json_object(list_json,'$.laneType'), get_json_object(list_json,'$.queueCount'), cast(get_json_object(list_json,'$.queueLen') as decimal(10,2)), cast(get_json_object(list_json,'$.queueHead') as decimal(10,2)), cast(get_json_object(list_json,'$.queueTail') as decimal(10,2)), date(t1.create_time)
;
--查看分区
show partitions dwd_queue;
--查看数据
select * from dwd_queue
where day='2024-03-11';
--删掉表分区
alter table hurys_dc_dwd.dwd_queue drop partition (day='2024-03-11');
2、业务数据的JSON只有一层
--2、转向比数据内部表——动态分区 dwd_turnratio create table if not exists dwd_turnratio(device_no string comment '设备编号',cycle int comment '转向比数据周期' ,create_time timestamp comment '创建时间',volume_sum int comment '指定时间段内通过路口的车辆总数',speed_avg decimal(10,2) comment '指定时间段内通过路口的所有车辆速度的平均值',volume_left int comment '指定时间段内通过路口的左转车辆总数',speed_left decimal(10,2) comment '指定时间段内通过路口的左转车辆速度的平均值',volume_straight int comment '指定时间段内通过路口的直行车辆总数',speed_straight decimal(10,2) comment '指定时间段内通过路口的直行车辆速度的平均值',volume_right int comment '指定时间段内通过路口的右转车辆总数',speed_right decimal(10,2) comment '指定时间段内通过路口的右转车辆速度的平均值',volume_turn int comment '指定时间段内通过路口的掉头车辆总数',speed_turn decimal(10,2) comment '指定时间段内通过路口的掉头车辆速度的平均值' ) comment '转向比数据表——动态分区' partitioned by (day string) --分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列。 stored as orc --表存储数据格式为orc ; --动态插入数据 --解析json字段、去重、非空、volumeSum>=0 --speed_avg、speed_left、speed_straight、speed_right、speed_turn 等字段保留两位小数 --0<=volume_sum<=1000、0<=speed_avg<=150、0<=volume_left<=1000、0<=speed_left<=100、0<=volume_straight<=1000 --0<=speed_straight<=150、0<=volume_right<=1000、0<=speed_right<=100、0<=volume_turn<=100、0<=speed_turn<=100 with t1 as( selectget_json_object(turnratio_json,'$.deviceNo') device_no,get_json_object(turnratio_json,'$.cycle') cycle,get_json_object(turnratio_json,'$.createTime') create_time,get_json_object(turnratio_json,'$.volumeSum') volume_sum,cast(get_json_object(turnratio_json,'$.speedAvg') as decimal(10,2)) speed_avg,get_json_object(turnratio_json,'$.volumeLeft') volume_left,cast(get_json_object(turnratio_json,'$.speedLeft') as decimal(10,2)) speed_left,get_json_object(turnratio_json,'$.volumeStraight') volume_straight,cast(get_json_object(turnratio_json,'$.speedStraight')as decimal(10,2)) speed_straight,get_json_object(turnratio_json,'$.volumeRight') volume_right,cast(get_json_object(turnratio_json,'$.speedRight') as decimal(10,2)) speed_right ,case when get_json_object(turnratio_json,'$.volumeTurn') is null then 0 else get_json_object(turnratio_json,'$.volumeTurn') end as volume_turn ,case when get_json_object(turnratio_json,'$.speedTurn') is null then 0 else cast(get_json_object(turnratio_json,'$.speedTurn')as decimal(10,2)) end as speed_turn from hurys_dc_ods.ods_turnratio) insert overwrite table hurys_dc_dwd.dwd_turnratio partition (day) selectt1.device_no,cycle,substr(create_time,1,19) create_time ,volume_sum,speed_avg,volume_left,speed_left,volume_straight,speed_straight ,volume_right,speed_right ,volume_turn,speed_turn,date(create_time) day from t1 where device_no is not null and volume_sum between 0 and 1000 and speed_avg between 0 and 150 and volume_left between 0 and 1000 and speed_left between 0 and 100 and volume_straight between 0 and 1000 and speed_straight between 0 and 150 and volume_right between 0 and 1000 and speed_right between 0 and 100 and volume_turn between 0 and 100 and speed_turn between 0 and 100 group by t1.device_no, cycle, substr(create_time,1,19), volume_sum, speed_avg, volume_left, speed_left, volume_straight, speed_straight, volume_right, speed_right, volume_turn, speed_turn, date(create_time) ; --查看分区 show partitions dwd_turnratio; --查看数据 select * from hurys_dc_dwd.dwd_turnratio where day='2024-03-11'; --删掉表分区 alter table hurys_dc_dwd.dwd_turnratio drop partition (day='2024-03-11');
(二)维度数据清洗
create table if not exists dwd_radar_lane(device_no string comment '雷达编号',lane_no string comment '车道编号',lane_id string comment '车道id',lane_direction string comment '行驶方向',lane_type int comment '车道类型 0渠化,1来向路段,2出口,3去向路段,4路口,5非路口路段,6其他',lane_length float comment '车道长度',lane_type_name string comment '车道类型名称' ) comment '雷达车道信息表' stored as orc ; --create table if not exists dwd_radar_lane stored as orc as --加载数据 insert overwrite table hurys_dc_dwd.dwd_radar_lane select device_no, lane_no, lane_id, lane_direction, lane_type,lane_length ,case when lane_type='0' then '渠化'when lane_type='1' then '来向路段'when lane_type='2' then '出口'when lane_type='3' then '去向路段'end as lane_type_name from hurys_dc_basic.tb_radar_lane where lane_length is not null group by device_no, lane_no, lane_id, lane_direction, lane_type, lane_length ; --查看表数据 select * from hurys_dc_dwd.dwd_radar_lane;
五、DWS层
create table if not exists dws_statistics_volume_1hour(device_no string comment '设备编号',scene_name string comment '场景名称',lane_no int comment '车道编号',lane_direction string comment '车道流向',section_no int comment '断面编号',device_direction string comment '雷达朝向',sum_volume_hour int comment '每小时总流量',start_time timestamp comment '开始时间' ) comment '统计数据流量表——动态分区——1小时周期' partitioned by (day string) stored as orc ; --动态加载数据 --两个一起 1m41s 、 convert.join=false 1m43s、 --注意字段顺序 查询语句中字段顺序与建表字段顺序一致 insert overwrite table hurys_dc_dws.dws_statistics_volume_1hour partition(day) selectdwd_st.device_no,dwd_sc.scene_name,dwd_st.lane_no,dwd_rl.lane_direction,dwd_st.section_no,dwd_rc.device_direction,sum(volume_sum) sum_volume_hour,concat(substr(create_time, 1, 14), '00:00') start_time,day from hurys_dc_dwd.dwd_statistics as dwd_stright join hurys_dc_dwd.dwd_radar_lane as dwd_rlon dwd_rl.device_no=dwd_st.device_no and dwd_rl.lane_no=dwd_st.lane_noright join hurys_dc_dwd.dwd_device_scene as dwd_dson dwd_ds.device_no=dwd_st.device_noright join hurys_dc_dwd.dwd_scene as dwd_scon dwd_sc.scene_id = dwd_ds.scene_idright join hurys_dc_dwd.dwd_radar_config as dwd_rcon dwd_rc.device_no=dwd_st.device_no where dwd_st.create_time is not null group by dwd_st.device_no, dwd_sc.scene_name, dwd_st.lane_no, dwd_rl.lane_direction, dwd_st.section_no, dwd_rc.device_direction, concat(substr(create_time, 1, 14), '00:00'), day ; --查看分区 show partitions dws_statistics_volume_1hour; --查看数据 select * from hurys_dc_dws.dws_statistics_volume_1hour where day='2024-02-29';
六、ADS层
这里的ADS层,其实就是用Kettle把Hive的DWS层结果数据同步到ClickHouse中,也是一个Kettle任务而已

这样用海豚进行调度每一层的任务,整个离线数仓流程就跑起来了
七、海豚调度任务(除了2个采集任务外)
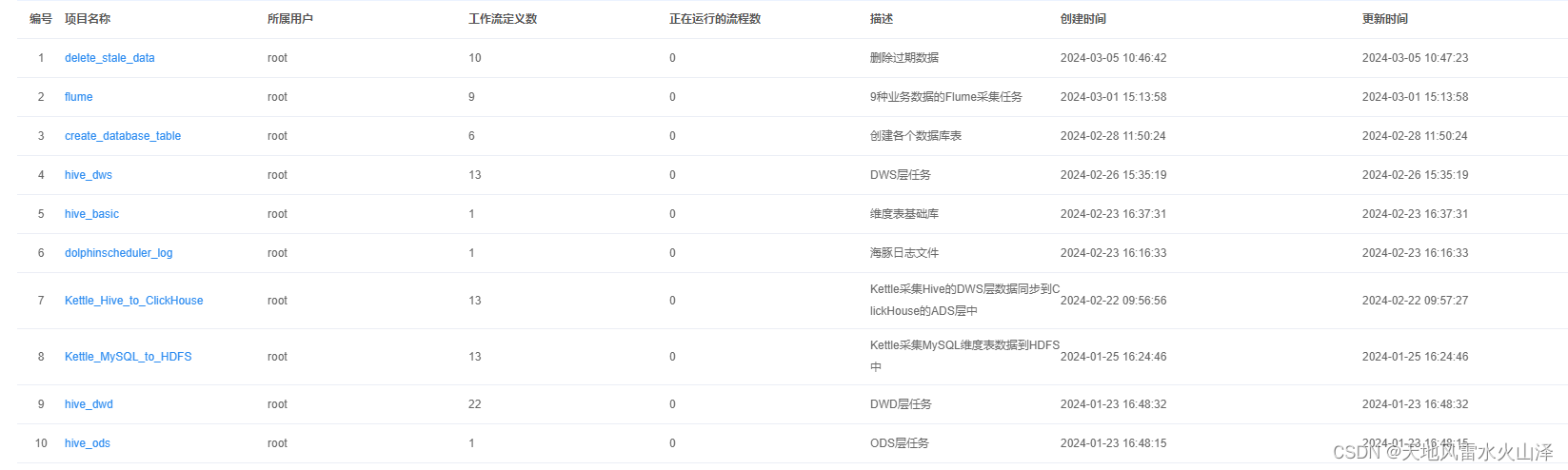
(一)delete_stale_data(根据删除策略删除ODS层原始数据)
#! /bin/bash
source /etc/profile
nowdate=`date --date='0 days ago' "+%Y%m%d"`
day_30_ago_date=`date -d "30 day ago " +%Y-%m-%d`
#静态排队数据
hadoop fs -test -e /user/hive/warehouse/hurys_dc_ods.db/ods_queue/day=${day_30_ago_date}
if [ $? -ne 0 ]; then
echo "文件不存在"
else
hdfs dfs -rm -r /user/hive/warehouse/hurys_dc_ods.db/ods_queue/day=${day_30_ago_date}
fi
#轨迹数据
hadoop fs -test -e /user/hive/warehouse/hurys_dc_ods.db/ods_track/day=${day_30_ago_date}
if [ $? -ne 0 ]; then
echo "文件不存在"
else
hdfs dfs -rm -r /user/hive/warehouse/hurys_dc_ods.db/ods_track/day=${day_30_ago_date}
fi
#动态排队数据
hadoop fs -test -e /user/hive/warehouse/hurys_dc_ods.db/ods_queue_dynamic/day=${day_30_ago_date}
if [ $? -ne 0 ]; then
echo "文件不存在"
else
hdfs dfs -rm -r /user/hive/warehouse/hurys_dc_ods.db/ods_queue_dynamic/day=${day_30_ago_date}
fi
#区域数据
hadoop fs -test -e /user/hive/warehouse/hurys_dc_ods.db/ods_area/day=${day_30_ago_date}
if [ $? -ne 0 ]; then
echo "文件不存在"
else
hdfs dfs -rm -r /user/hive/warehouse/hurys_dc_ods.db/ods_area/day=${day_30_ago_date}
fi
#事件数据
hadoop fs -test -e /user/hive/warehouse/hurys_dc_ods.db/ods_event/day=${day_30_ago_date}
if [ $? -ne 0 ]; then
echo "文件不存在"
else
hdfs dfs -rm -r /user/hive/warehouse/hurys_dc_ods.db/ods_event/day=${day_30_ago_date}
fi
#删除表分区
hive -e "
use hurys_dc_ods;
alter table hurys_dc_ods.ods_area drop partition (day='$day_30_ago_date');
alter table hurys_dc_ods.ods_event drop partition (day='$day_30_ago_date');
alter table hurys_dc_ods.ods_queue drop partition (day='$day_30_ago_date');
alter table hurys_dc_ods.ods_queue_dynamic drop partition (day='$day_30_ago_date');
alter table hurys_dc_ods.ods_track drop partition (day='$day_30_ago_date')
"
(二)flume(Flume采集Kafka业务数据)
(三)create_database_table(自动创建Hive和ClickHouse的库表)
1、创建Hive库表
#! /bin/bash
source /etc/profile
hive -e "
source 1_dws.sql
"
2、创建ClickHouse库表
#! /bin/bash
source /etc/profile
clickhouse-client --user default --password hurys@123 -d default --multiquery <1_ads.sql

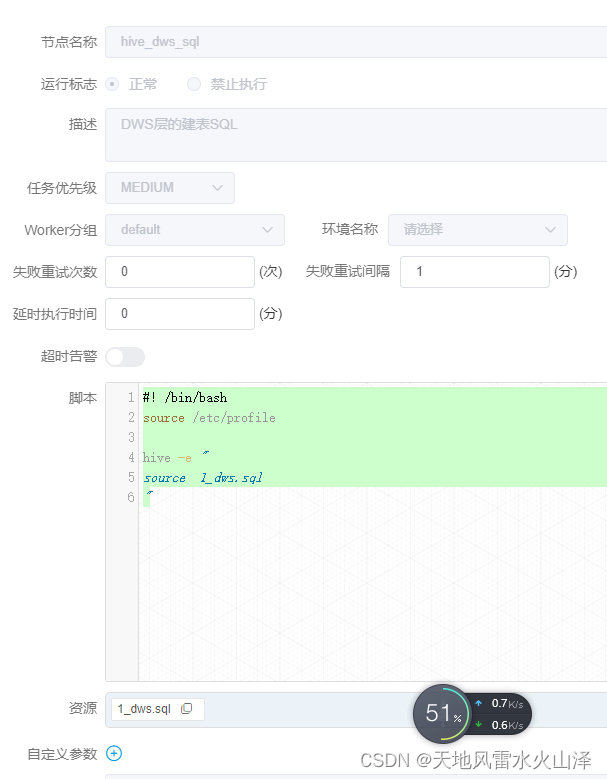
(四)hive_dws(DWS层任务)
#! /bin/bash
source /etc/profile
nowdate=`date --date='0 days ago' "+%Y%m%d"`
yesdate=`date -d yesterday +%Y-%m-%d`
hive -e "
use hurys_dc_dws;
set hive.vectorized.execution.enabled=false;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
set hive.exec.max.dynamic.partitions=2000;
insert overwrite table hurys_dc_dws.dws_statistics_volume_1hour partition(day='$yesdate')
select
dwd_st.device_no,
dwd_sc.scene_name,
dwd_st.lane_no,
dwd_rl.lane_direction,
dwd_st.section_no,
dwd_rc.device_direction,
sum(volume_sum) sum_volume_hour,
concat(substr(create_time, 1, 14), '00:00') start_time
from hurys_dc_dwd.dwd_statistics as dwd_st
right join hurys_dc_dwd.dwd_radar_lane as dwd_rl
on dwd_rl.device_no=dwd_st.device_no and dwd_rl.lane_no=dwd_st.lane_no
right join hurys_dc_dwd.dwd_device_scene as dwd_ds
on dwd_ds.device_no=dwd_st.device_no
right join hurys_dc_dwd.dwd_scene as dwd_sc
on dwd_sc.scene_id = dwd_ds.scene_id
right join hurys_dc_dwd.dwd_radar_config as dwd_rc
on dwd_rc.device_no=dwd_st.device_no
where dwd_st.create_time is not null and day= '$yesdate'
group by dwd_st.device_no, dwd_sc.scene_name, dwd_st.lane_no, dwd_rl.lane_direction, dwd_st.section_no, dwd_rc.device_direction, concat(substr(create_time, 1, 14), '00:00')
"
(五)hive_basic(维度表基础库)
#! /bin/bash
source /etc/profile
hive -e "
set hive.vectorized.execution.enabled=false;
use hurys_dc_basic
"

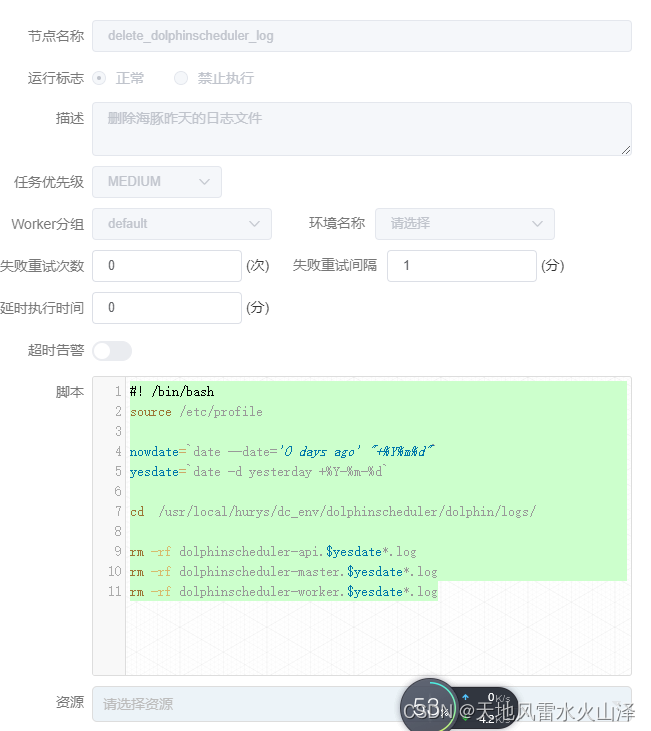
(六)dolphinscheduler_log(删除海豚日志文件)
#! /bin/bash
source /etc/profile
nowdate=`date --date='0 days ago' "+%Y%m%d"`
yesdate=`date -d yesterday +%Y-%m-%d`
cd /usr/local/hurys/dc_env/dolphinscheduler/dolphin/logs/
rm -rf dolphinscheduler-api.$yesdate*.log
rm -rf dolphinscheduler-master.$yesdate*.log
rm -rf dolphinscheduler-worker.$yesdate*.log
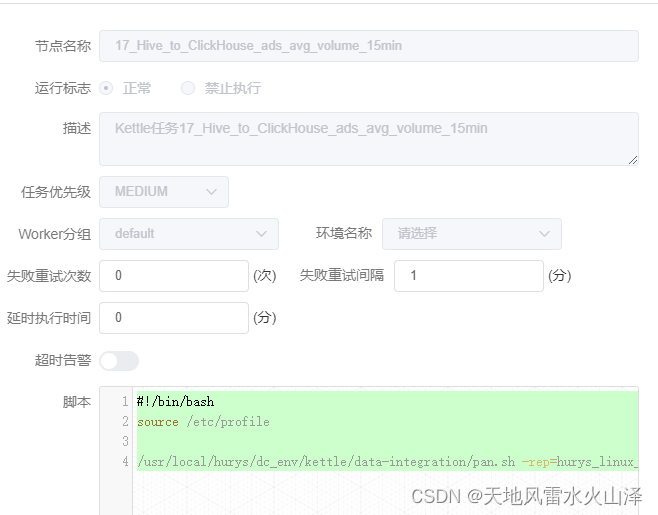
(七)Kettle_Hive_to_ClickHouse(Kettle采集Hive的DWS层数据同步到ClickHouse的ADS层中)
#!/bin/bash
source /etc/profile
/usr/local/hurys/dc_env/kettle/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/hive_to_clickhouse/ -trans=17_Hive_to_ClickHouse_ads_avg_volume_15min level=Basic >>/home/log/kettle/17_Hive_to_ClickHouse_ads_avg_volume_15min_`date +%Y%m%d`.log
(八)Kettle_MySQL_to_HDFS(Kettle采集MySQL维度表数据到HDFS中)
(九)hive_dwd(DWD层任务)
1、业务数据的JSON有多层
#! /bin/bash
source /etc/profile
nowdate=`date --date='0 days ago' "+%Y%m%d"`
yesdate=`date -d yesterday +%Y-%m-%d`
hive -e "
use hurys_dc_dwd;
set hive.vectorized.execution.enabled=false;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
set hive.exec.max.dynamic.partitions=1500;
with t1 as(
select
get_json_object(queue_json,'$.deviceNo') device_no,
get_json_object(queue_json,'$.createTime') create_time,
get_json_object(queue_json,'$.laneNum') lane_num,
get_json_object(queue_json,'$.queueList') queue_list
from hurys_dc_ods.ods_queue
where date(get_json_object(queue_json,'$.createTime')) = '$yesdate'
)
insert overwrite table hurys_dc_dwd.dwd_queue partition(day='$yesdate')
select
t1.device_no,
t1.lane_num,
substr(create_time,1,19) create_time ,
get_json_object(list_json,'$.laneNo') lane_no,
get_json_object(list_json,'$.laneType') lane_type,
get_json_object(list_json,'$.queueCount') queue_count,
cast(get_json_object(list_json,'$.queueLen') as decimal(10,2)) queue_len,
cast(get_json_object(list_json,'$.queueHead') as decimal(10,2)) queue_head,
cast(get_json_object(list_json,'$.queueTail') as decimal(10,2)) queue_tail
from t1
lateral view explode(split(regexp_replace(regexp_replace(queue_list,
'\\\\[|\\\\]','') , --将json数组两边的中括号去掉
'\\\\}\\\\,\\\\{','\\\\}\\\\;\\\\{'), --将json数组元素之间的逗号换成分号
'\\\\;') --以分号作为分隔符(split函数以分号作为分隔)
)list_queue as list_json
where device_no is not null and get_json_object(list_json,'$.queueLen') between 0 and 500 and get_json_object(list_json,'$.queueHead') between 0 and 500 and get_json_object(list_json,'$.queueTail') between 0 and 500 and get_json_object(list_json,'$.queueCount') between 0 and 100
group by t1.device_no, t1.lane_num, substr(create_time,1,19), get_json_object(list_json,'$.laneNo'), get_json_object(list_json,'$.laneType'), get_json_object(list_json,'$.queueCount'), cast(get_json_object(list_json,'$.queueLen') as decimal(10,2)), cast(get_json_object(list_json,'$.queueHead') as decimal(10,2)), cast(get_json_object(list_json,'$.queueTail') as decimal(10,2))
"
2、业务数据的JSON单层
#! /bin/bash
source /etc/profile
nowdate=`date --date='0 days ago' "+%Y%m%d"`
yesdate=`date -d yesterday +%Y-%m-%d`
hive -e "
use hurys_dc_dwd;
set hive.vectorized.execution.enabled=false;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
set hive.exec.max.dynamic.partitions=1500;
with t1 as(
select
get_json_object(turnratio_json,'$.deviceNo') device_no,
get_json_object(turnratio_json,'$.cycle') cycle,
get_json_object(turnratio_json,'$.createTime') create_time,
get_json_object(turnratio_json,'$.volumeSum') volume_sum,
cast(get_json_object(turnratio_json,'$.speedAvg') as decimal(10,2)) speed_avg,
get_json_object(turnratio_json,'$.volumeLeft') volume_left,
cast(get_json_object(turnratio_json,'$.speedLeft') as decimal(10,2)) speed_left,
get_json_object(turnratio_json,'$.volumeStraight') volume_straight,
cast(get_json_object(turnratio_json,'$.speedStraight')as decimal(10,2)) speed_straight,
get_json_object(turnratio_json,'$.volumeRight') volume_right,
cast(get_json_object(turnratio_json,'$.speedRight') as decimal(10,2)) speed_right ,
case when get_json_object(turnratio_json,'$.volumeTurn') is null then 0 else get_json_object(turnratio_json,'$.volumeTurn') end as volume_turn ,
case when get_json_object(turnratio_json,'$.speedTurn') is null then 0 else cast(get_json_object(turnratio_json,'$.speedTurn')as decimal(10,2)) end as speed_turn
from hurys_dc_ods.ods_turnratio
where date(get_json_object(turnratio_json,'$.createTime')) = '$yesdate'
)
insert overwrite table hurys_dc_dwd.dwd_turnratio partition (day='$yesdate')
select
t1.device_no,
cycle,
substr(create_time,1,19) create_time ,
volume_sum,
speed_avg,
volume_left,
speed_left,
volume_straight,
speed_straight ,
volume_right,
speed_right ,
volume_turn,
speed_turn
from t1
where device_no is not null and volume_sum between 0 and 1000 and speed_avg between 0 and 150 and volume_left between 0 and 1000 and speed_left between 0 and 100 and volume_straight between 0 and 1000 and speed_straight between 0 and 150 and volume_right between 0 and 1000 and speed_right between 0 and 100 and volume_turn between 0 and 100 and speed_turn between 0 and 100
group by t1.device_no, cycle, substr(create_time,1,19), volume_sum, speed_avg, volume_left, speed_left, volume_straight, speed_straight, volume_right, speed_right, volume_turn, speed_turn
"
3、维度数据
#! /bin/bash
source /etc/profile
hive -e "
use hurys_dc_dwd;
set hive.vectorized.execution.enabled=false;
insert overwrite table hurys_dc_dwd.dwd_holiday
select
day, holiday,year
from hurys_dc_basic.tb_holiday
group by day, holiday, year
"
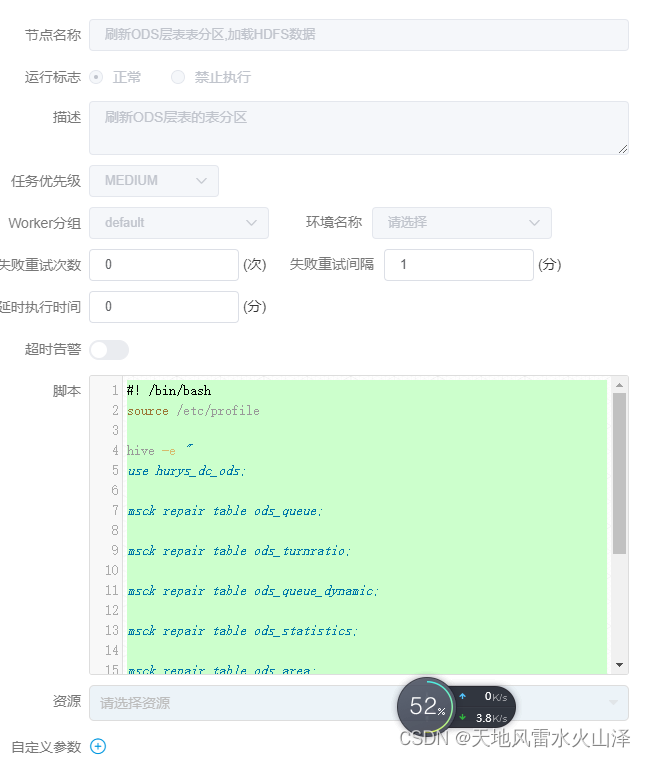
(十)hive_ods(ODS层任务)
#! /bin/bash
source /etc/profile
hive -e "
use hurys_dc_ods;
msck repair table ods_queue;
msck repair table ods_turnratio;
msck repair table ods_queue_dynamic;
msck repair table ods_statistics;
msck repair table ods_area;
msck repair table ods_pass;
msck repair table ods_track;
msck repair table ods_evaluation;
msck repair table ods_event;
"
目前,整个离线数仓的流程大致就是这样,有问题的后面再完善!