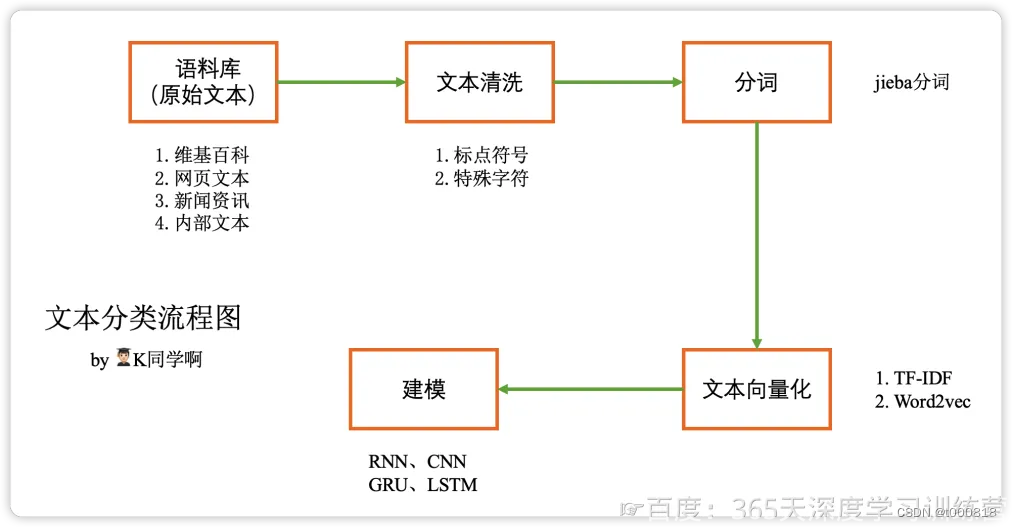
消息存储与同步策略
https://github.com/robinfoxnan/BirdTalkServer
思路:
- 私聊写扩散,以用户为中心,存储2次;
- 群聊读扩散,以群组为中心,存储一次;
- scylladb易于扩展,适合并发,但是并不适合搜索;如果需要针对聊天记录在服务端搜索的功能,可能还需要加上ES,以会话为中心存储一份;
存储的三级结构如下:
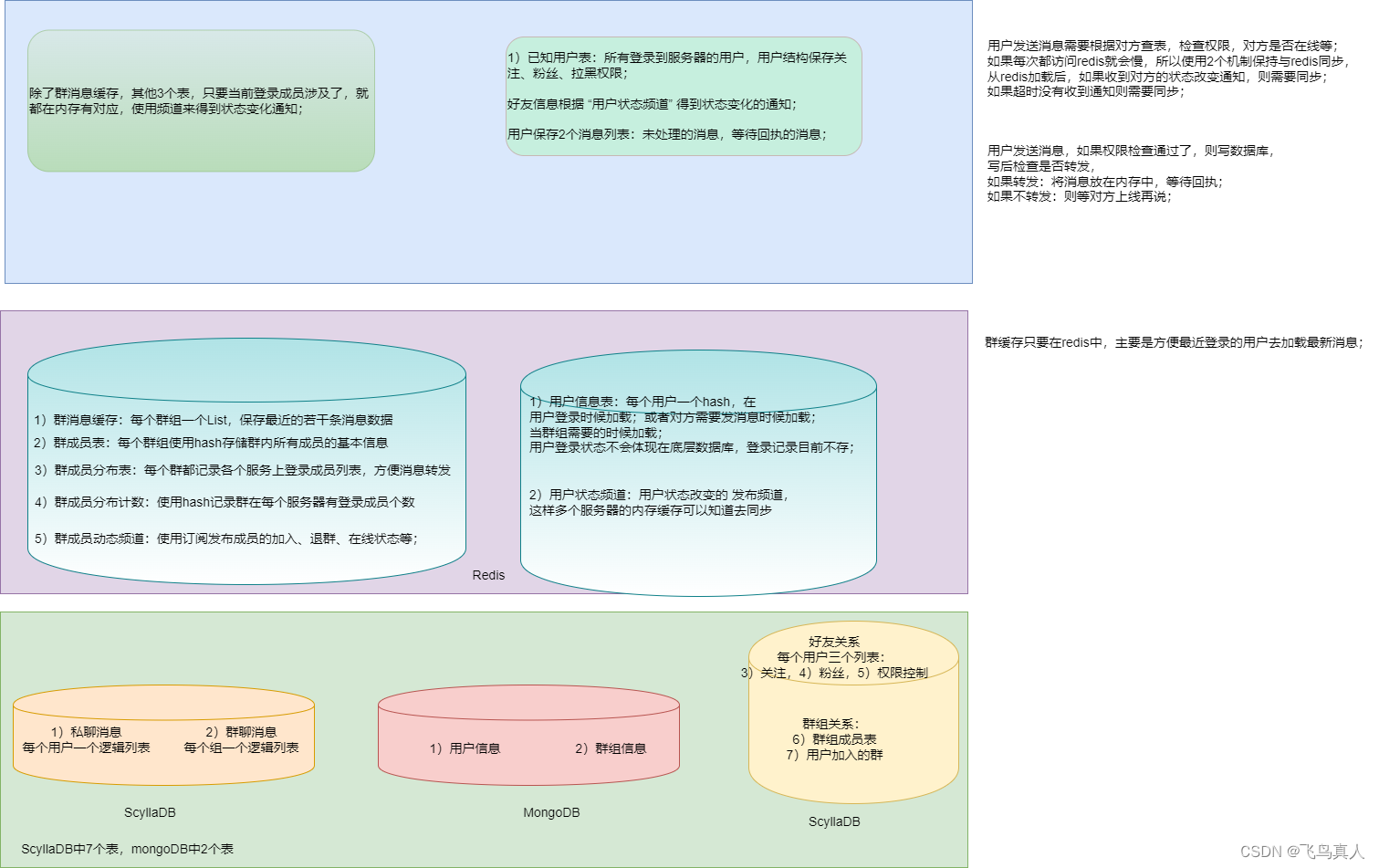
私聊
优点:以用户为中心比以会话为中心(tinode)的好处就是消息管理更加容易;每个用户的数据相对集中,可以快速的找到并一次性同步给客户;
缺点:数据需要存储2份;
群聊
优点:群聊使用读扩散,存储数据量少;
缺点:读扩散,如果用户反复离线与上线,需要读取离线数据,对scylladb压力比较大;
所有类型的IM系统都有一个共同的难点:如何同步数据,不丢消息?
同步机制
私聊和群聊在正常情况下如果所有用户在线,服务器也不重启,那么很容易保证实时转发不丢消息。
之所以会同步起来比较复杂就在于:
1)用户离线不定长时间后,上线时需要同步消息,而消息可能会非常的多(大群);
2)支持多终端登录,某个终端长久未使用,上线后也需要同步消息;
其实WX在多终端登录同步数据这一点上做的挺差的;多终端在线,某个终端时而离线,就会无法同步到所有的数据;而其他的一些系统就好多了,后加入群聊的也能看到之前的对话;多终端同步也好多了。
用户离线后重新登录,需要与服务器同步消息,需要保证尽量不丢包;这里需要有一个合适的同步机制。
基本策略:
登录后,根据本地保存的消息记录,对比时间差;如果离线时间不久,优先使用正向加载(私聊手机端);如果离线时间久,或者是群聊,优先使用倒序加载;(私聊的电脑端长期未登录也需要倒序加载)
同步流程:
用户登录就绪后,分为3类情况:
1)私聊:客户端比对最后接收消息时间,如果小于1天,则可以尝试正向加载消息,向服务器提供该条msgId,直到同步到消息列表末尾(一般情况下一天的私聊数据也不会超过1000条);如果时间较久,应该向服务申请反向加载数据到msgId为止;如果是老用户的新终端,也应该反向加载数据,并在用户界面提示用户按需加载;
2)群聊:新用户加入群聊后,以及离线后再次登录,都需要倒序加载数据;(这是因为群聊数据量可能非常庞大,而且用户也不需要从最开始的消息开始阅读,可以根据需要适当加载)
3)服务器假死:集群情况下,服务器由于负载大,没有即时上报心跳状态,造成其他服务器没有即时发送转发的消息;服务器恢复后发现此状态,应该按比例断开部分客户端链接;未断开的用户也应该要求客户端重新同步离线数据;
详见第2节部分。
1. ScyllaDb存储
这里使用了一个snow雪花算法生成唯一的消息ID,使用高42比特来保存毫秒时间戳,12比特作为流水号,所以每个毫秒最多支持4096个流水号;
那么这个ID就可以代表时间了,所以我们可以用它来排序,或者得到时间;
1.1 传输结构
// 聊天存储的基本信息
message MsgChat {int64 msgId = 1; // 消息的全网唯一标识,服务端使用雪花算法生成,因为客户端生成的不可靠int64 userId = 2; // 用于存储的clusterKey,因为一份消息要存储2次,要转发,需要有这个字段int64 fromId = 3; // 发送消息的用户 IDint64 toId = 4; // 接收消息的用户 ID(对方的用户 ID)int64 tm = 5; // 消息的时间戳string devId = 6; // 多设备登录时的设备 IDstring sendId = 7; // 用于确认消息的发送 IDChatMsgType msgType = 8; // 消息类型,建议使用枚举bytes data = 9; // 消息的内容,可以使用 bytes 存储二进制数据或文本数据MsgPriority priority = 10; // 消息的优先级,建议使用枚举int64 refMessageId = 11; // 引用的消息 ID,如果有的话ChatMsgStatus status = 12; // 消息状态,建议使用枚举int64 sendReply = 13; // 发送消息的回执状态int64 recvReply = 14; // 接收消息的回执状态int64 readReply = 15; // 已读状态的回执EncryptType encType = 16; // 加密类型ChatType chatType = 17; // p2p, group, systemint32 subMsgType = 18; // 传递给插件区分代码,插件都注册为整数类型,int64 keyPrint = 19; // 秘钥指纹
}
在传输过程中,私聊和群聊的消息是共用的;
服务为了保存到数据库需要进行格式转化:
1.2 私聊
私聊是写扩散,所以需要在表中对每个人都写一次,区别在于uid1和uid2交换一次,pk肯定也是需要交换的
type PChatDataStore struct {Pk int16 `db:"pk"`Uid1 int64 `db:"uid1"`Uid2 int64 `db:"uid2"`Id int64 `db:"id"`Usid int64 `db:"usid"`Tm int64 `db:"tm"`Tm1 int64 `db:"tm1"`Tm2 int64 `db:"tm2"`Io int8 `db:"io"` // 0=out, 1=inSt int8 `db:"st"` // 0=normal, 1=送达,2阅读,Ct int8 `db:"ct"` // 0=p2p_plain, 1=system, 2=p2_encrypted,Mt int8 `db:"mt"` // 0=text, 1=pic, 2=Print int64 `db:"pr"` // 秘钥哈希的低8字节作为指纹Ref int64 `db:"ref"` // 引用Draf []byte `db:"draf"`
}
对应的建表语句:
const cqlCreateTablePChat = `CREATE TABLE IF NOT EXISTS chatdata.pchat (pk smallint,uid1 bigint, uid2 bigint,id bigint,usid bigint,tm bigint,tm1 bigint,tm2 bigint,io tinyint,st tinyint,ct tinyint,mt tinyint,draf blob,pr varint,ref varint,PRIMARY KEY (pk, uid1, id))`
这里提供了如下几个函数:
// 写2次,首先是发方A,然后是收方B
func (me *Scylla) SavePChatData(msg *model.PChatDataStore, pk2 int) error// 对发送方设置回执,收方不需要设置,这里提供了收方的参数,是为了兼容,以后也许也保存
func (me *Scylla) SetPChatRecvReply(pk1, pk2, uid1, uid2, msgId, tm1 int64) error
func (me *Scylla) SetPChatReadReply(pk1, pk2, uid1, uid2, msgId, tm2 int64)
func (me *Scylla) SetPChatRecvReadReply(pk1, pk2, uid1, uid2, msgId, tm1, tm2 int64) error// 设置删除,不可逆
func (me *Scylla) SetPChatMsgDeleted(pk1, pk2, uid1, uid2, msgId int64) error// 正向查找,如果从头开始查找,那么设置为littleId = 0
func (me *Scylla) FindPChatMsg(pk, uid, littleId int64, pageSize uint) ([]model.PChatDataStore, error) // 正序查找,设置边界范围
func (me *Scylla) FindPChatMsgForwardBetween(pk, uid, littleId, bigId int64, pageSize uint) ([]model.PChatDataStore, error)// 从最新的数据向前倒序查若干条
func (me *Scylla) FindPChatMsgBackward(pk, uid, pageSize uint) ([]model.PChatDataStore, error)// 从某一点开始向之前的历史数据反向查找,即 所有小于bigId 的
func (me *Scylla) FindPChatMsgBackwardFrom(pk, uid, bigId int64, pageSize uint) ([]model.PChatDataStore, error)// 从当前最新开始向之前的历史数据反向查找,即 所有大于littlId 的
func (me *Scylla) FindPChatMsgBackwardTo(pk, uid, littleId int64, pageSize uint) ([]model.PChatDataStore, error)// 向之前的历史数据反向查找
func (me *Scylla) FindPChatMsgBackwardBetween(pk, uid, littleId, bigId int64, pageSize uint) ([]model.PChatDataStore, error)
1.3 群聊
type GChatDataStore struct {Pk int16 `db:"pk"`Gid int64 `db:"gid"`Uid int64 `db:"uid"`Id int64 `db:"id"`Usid int64 `db:"usid"`Tm int64 `db:"tm"`Res int8 `db:"res"` // 保留St int8 `db:"st"` // 0=normal, 1=送达,2阅读,Ct int8 `db:"ct"` // 0=普通,1=广播Mt int8 `db:"mt"` // 0=text, 1=pic, 2=Print int64 `db:"pr"` // 秘钥哈希的低8字节作为指纹Ref int64 `db:"ref"` // 引用Draf []byte `db:"draf"`
}去掉了uid2和tm2, tm3 群聊的消息不保存回执,多次读,每个用户都自己去读;
const cqlCreateTableGChat = `CREATE TABLE IF NOT EXISTS chatdata.gchat (pk smallint,gid bigint,uid bigint, id bigint,usid bigint,tm bigint,res tinyint,st tinyint,ct tinyint,mt tinyint,draf blob,pr varint,ref varint,PRIMARY KEY (pk, gid, id))`
相关函数如下:
// 保存
func (me *Scylla) SaveGChatData(msg *model.GChatDataStore) error// 设置删除,不可逆
func (me *Scylla) SetGChatMsgDeleted(pk, gid, msgId int64) error// 倒序,反向历史数据方向查找,从最新的数据开始向前加载
func (me *Scylla) FindGChatMsgBackwardTo(pk, gid, littleId int64, pageSize uint) ([]model.GChatDataStore, error)// 倒序,从bigId 向littleId方向去查找,限定一定的个数,如果无法覆盖边界,再来一次
func (me *Scylla) FindGChatMsgBackwardBetween(pk, gid, littleId, bigId int64, pageSize uint) ([]model.GChatDataStore, error)
消息的所有者,以及管理员可以设置删除消息,这里的删除等同于微信的撤回,而不是本地删除;
2. Redis缓存
2.1 群聊消息缓存
每个群组有一个list用于存储,左侧插入,默认1000条缓存,如果超过就会删除;
键名字类似:bsgmsg_1001
func (cli *RedisClient) GetGroupLatestMsg(gid, count int64) ([]string, error)
func (cli *RedisClient) GetGroupLatestMsgPage(gid, offset, count int64) ([]string, error)
func (cli *RedisClient) GetGroupLatestMsgCount(gid, count int64) (int64, error)
func (cli *RedisClient) PushGroupMsg(gid int64, msg string)
群聊用户离线后,重新上线后,先发所收到的最后一条消息的msgId,如果每个用户上线都搜索数据库,那么会非常耗费数据库资源,所以先从redis将最近的100条数据返回给用户;
这样就有了一个新的问题,用户如何知道中间缺失了部分消息?那么需要有一个节省流量与资源的同步方式:
**原则:**用户每次登录后主动请求加载离线数据,收到数据后回执,如果不请求数据,则不保证数据的完整性,在线时仅仅推送
1)用户登录准备好收发消息后,服务端首先设置状态;
2)用户需要同步群消息时,先发一个群消息同步请求,里面携带收到的最后的群消息msgId;
2)服务器加载最近的所有的消息(redis群缓存里的), 推送之后,需要推送一条待加载数据,通知前边还有数据需要同步;
用户端的群消息存储sqlite如下:
| 序号 | msg_id | 状态 |
|---|---|---|
| 100001 | ||
| 100003 | ||
| 100005 | ||
| 1000017 | 待加载 | |
| 1000018 | … | |
| 1000020 | … | |
| 1000025 | … | |
| 1000075 | … | |
| 1000086 | … |
比如,此次登录后,服务器推送了[1000086, 1000075, 1000025, 1000020, 1000018]数据后,尾号17的条目就是服务器发送的通知,这个编号完全可以从前一个msd_id = 1000018 减一得到,意思是从这里向前加载;
客户端需要插入这样的一条数据,下次从本地加载时,发现有这样一条数据,证明需要从这个位置向前加载,
界面上显示 ”待加载“的提示按钮,用户可以选择继续向前查看,客户端发送新的查询请求,
收到新加载的数据后,如果msg_id的范围越过了这条标记,那么这条标记就可以删除了。
这里存在一种异步竞争的情况,可能丢失消息:
| 登录后同步协程 | 发消息协程 |
|---|---|
| 1)检测到用户离线,不推送最新消息m | |
| 1) 用户结构建立后,标记在线 | |
| 2)加载离线数据,推送离线数据 | |
| 2) redis中插入m |
需要将流程改变一下:使用锁或者原子操作atomic来设置和读取用户的状态,
| 登录后同步协程 | 发消息协程 |
|---|---|
| 1)保存数据库,并在redis插入最新的消息m | |
| 2.1) 发现A不在线,未推送m | |
| 1) 用户结构建立后,标记在线 | |
| 2)加载离线数据,推送离线数据 | 2.2) 发现A在线,直接推送m |
这里就会有2种可能性,
2.2) 转发消息的协程发现用户在线,直接转发消息,此时会造成重复推送;
2.1) 转发协程虽然没有转发给用户,但是同步协程会加载离线数据;
这里队列中加载所有数据都需要收到用户确认回执后再删除;
然而这里还有一个问题,存入redis队列中的消息,是使用protobuf定义的结构序列化,或者使用model.GChatDataStore结构序列化为JSON保存好;从效率上说,应该是protobuf的版本更好;
2.2 私聊消息缓存
私聊消息在redis中不设置缓存,在每个用户的内存结构中使用循环队列保存,如果离线,则内存也不保存离线消息,只在离线的数据库中保存。
单机模式下,用户A的数据的加载可能是因为对方给A发送数据,所以即便缓存数据,(因为服务器可能重启过)也未必是所有的离线数据;
集群模式下,用户A和聊天的对象不一定在同一台服务器上,即便某台服务器内存缓存了A的离线数据,下次登录页未必一定在这台服务器登录,所以内存缓存没有意义;
而redis缓存中的user信息的hash表中可以保存一个用户最后收到的消息的msgId,那么从这个ID开始搜索就加载所有未同步的离线数据了;
那么,当每次用户提交接收回执的时候,需要记录最后一条回执的ID,为了减少redis的开销,可以每30秒执行一次redis同步;
但是,其实也不需要保存最后的ID,还是让用户根据msgId反向加载即可。