ACM上的一篇综述,讨论Transformer在CV上的应用。
摘要:
Among their salient benefits,Transformers enable modeling long dependencies between inputsequence elements and support parallel processing of sequence as compared to recurrent networks e.g.,Long short-term memory(LSTM).
与循环网络(如 LSTM)相比,Transformer 可以建模输入序列元素之间的长期依赖关系,并支持序列的并行处理。
Furthermore,the straightforward design of Transformers allows processing multiple modalities(e.g.,images,videos,text and speech)using similar processing blocks and demonstrates excellent scalability to very large capacity networks and hugedatasets.
Transformer 的直观设计允许使用类似的处理模块处理多种模态(例如图像、视频、文本和语音),并且展现出对非常大容量网络和大规模数据集的良好可扩展性。
1.简介
The profound impact of Transformer models has become more clear with their scalability to very large capacity mod-els
Transformer 模型的深远影响在于它们能够扩展到非常大容量的模型,比如 BERT-large 和 GPT-3,以及最新的 Switch transformer。
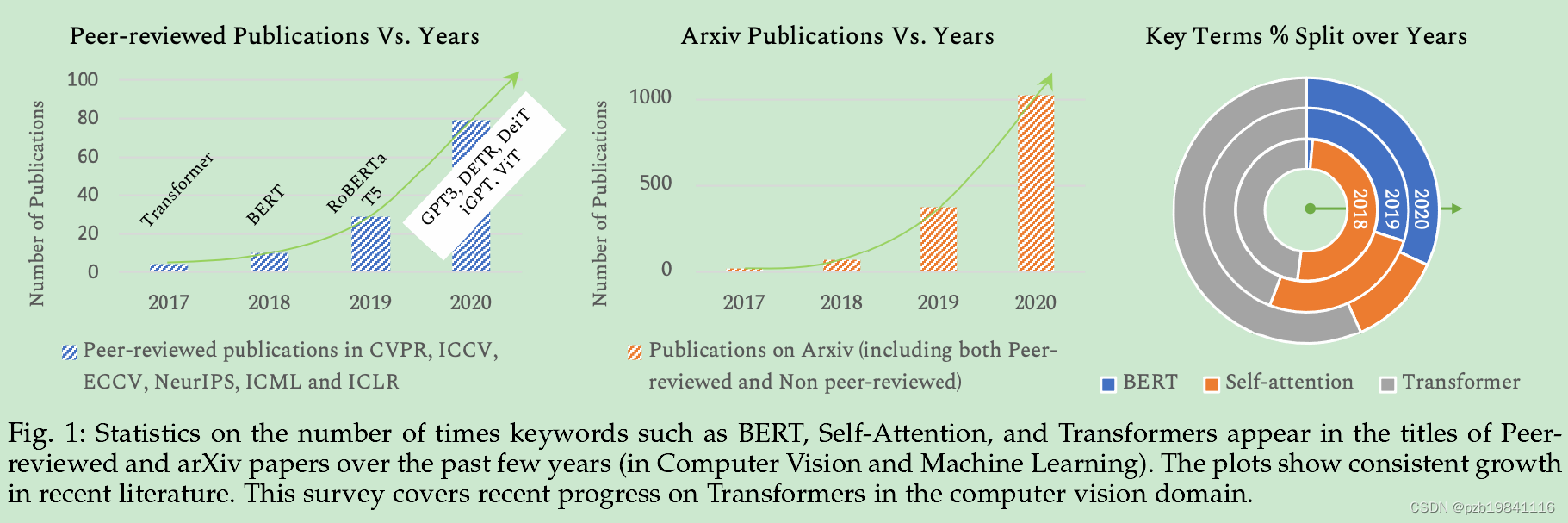
As a result,Transformer mod-els and their variants have been successfully used for imagerecognition[11],[12],object detection[13],[14],segmenta-tion[15],image super-resolution[16],video understanding[17],[18],image generation[19],text-image synthesis[20]and visual question answering[21],[22],among severalother use cases[23]–[26].
Transformer 模型及其变体已成功应用于图像识别、目标检测、分割、图像超分辨率、视频理解、图像生成、文本-图像合成和视觉问答等领域。
Al-though attention models have been extensively used inboth feed-forward and recurrent networks[27],[28],Trans-formers are based solely on the attention mechanism andhave a unique implementation(i.e.,multi-head attention)optimized for parallelization.
Transformer 基于注意力机制,独特的多头注意力实现优化了并行性,与其他模型如硬注意力相比,Transformer 具有很好的可扩展性,不需要先验知识即可处理问题结构。
Since Transformers assume minimal priorknowledge about the structure of the problem as comparedto their convolutional and recurrent counterparts[30]–[32],they are typically pre-trained using pretext tasks on large-scale(unlabelled)datasets[1],[3].
Transformer 通常通过在大规模(未标记)数据集上的预训练来学习表征,然后在监督下游任务中进行微调,以获得良好的结果,避免了昂贵的手动标注成本。
2.基础
The first one is self-attention,which allows capturing‘long-term’dependencies between sequence elements as com-pared to conventional recurrent models that find it chal-lenging to encode such relationships.
自注意力机制(self-attention)允许捕获序列元素之间的“长期”依赖关系,相比于传统的循环模型,传统的循环模型往往难以编码这种关系。
The second keyidea is that of pre-training1on a large(un)labelled corpus ina(self)supervised manner,and subsequently fine-tuning tothe target task with a small labeled dataset[3],[7],[38].
在大规模(未)标记语料库上进行自(监督)预训练,并随后使用小规模标记数据集对目标任务进行微调,是 Transformer 模型发展的第二个关键思想。
2.1 Transformer中的自注意力
The self-attentionmechanism is an integral component of Transformers, which explicitly models the interactions between all entities of asequence for structured prediction tasks.
自注意力机制是 Transformer 的核心组成部分,用于显式地建模序列中所有实体之间的交互,适用于结构化预测任务。
This is doneby defining three learnable weight matrices to transformQueries(WQ∈Rd×dq),Keys(WK∈Rd×dk)and Values(WV∈Rd×dv),where dq=dk
自注意力机制通过定义三个可学习的权重矩阵来实现,分别用于转换查询(Queries)、键(Keys)和值(Values),其中查询和键的维度相同,值的维度可以不同。

For a given entity in the sequence,the self-attention basi-cally computes the dot-product of the query with all keys,which is then normalized using softmax operator to get theattention scores.
自注意力机制对于给定序列中的每个实体,基本上是计算查询(query)与所有键(keys)的点积,然后使用 softmax 运算进行归一化,以获得注意力分数。
For the Transformer model[1]which is trained to predict the next entity of the sequence,the self-attention blocks used in the decoder are masked toprevent attending to the subsequent future entities.
对于 Transformer 模型中的解码器,在训练过程中,用于预测序列下一个实体的自注意力块会被掩码,以防止关注未来的实体。
This issimply done by an element-wise multiplication operation with a mask M∈Rn×n,where M is an upper-triangular matrix.
这是通过与一个掩码矩阵相乘的元素级乘法操作完成的,掩码矩阵 M 是一个上三角矩阵。
Hadamard product
Hadamard 乘积(Hadamard product),也称为元素级乘积或者逐元素乘积,是指两个相同大小的矩阵(或者向量)中对应元素相乘得到的新矩阵(或者向量)。
Basically,while pre-dicting an entity in the sequence,the attention scores of thefuture entities are set to zero in masked self-attention.
在掩码的自注意力机制中,预测序列中的实体时,未来实体的注意力分数被设为零。
In order to encapsulate multiplecomplex relationships amongst different elements in thesequence,the multi-head attention comprises multiple self-attention blocks(h=8 in the original Transformer model[1]).Each block has its own set of learnable weight ma-trices{WQi,WKi,WVi},where i=0···(h−1).
多头注意力机制包含多个自注意力块,用于捕捉序列中不同元素之间的多个复杂关系。每个注意力块有自己的一组可学习的权重矩阵,用于计算查询、键和值。
The main difference of self-attention with convolution operation is that the filters are dynamically calculated in-stead of static filters(that stay the same for any input)as in the case of convolution.
自注意力与卷积操作的主要区别在于,自注意力中的滤波器是动态计算的,而不是静态的,因此具有更大的灵活性。
self-attention is invariant to permutations and changes in the number of input points.As a result,it can easily operate on irregular inputs as op-posed to standard convolution that requires grid structure.
自注意力不受排列的影响,也不受输入点数量的改变影响,因此可以轻松处理不规则的输入,而卷积则需要网格结构。
In fact,self-attention provides the capability to learn the global aswell as local features,and provide expressivity to adaptivelylearn kernel weights as well as the receptive field(similar todeformable convolutions[42]).
自注意力能够学习全局和局部特征,并提供适应性学习核权重和感受野的能力,类似于可变形卷积。
2.2 自监督预训练
self-supervised learning has been very effectivelyused in the pre-training stage.The self-supervision basedpre-training stage training has played a crucial role in un-leashing the scalability and generalization of Transformernetworks,
预训练阶段通常采用自监督学习,利用大量非标记数据来训练模型,这种方法在 Transformer 网络的可扩展性和泛化性方面发挥了关键作用。
the basicidea of SSL is to fill in the blanks,i.e.,try to predict theoccluded data in images,future or past frames in temporalvideo sequences or predict a pretext task
自监督学习的预训练阶段利用各种预训练任务,例如填空任务、预测未来或过去帧、对比学习等,以生成有意义的数据表示。
Self-supervised learning provides a promising learningparadigm since it enables learning from a vast amount ofreadily available non-annotated data.
自监督学习提供了一种有前景的学习范式,因为它能够从大量可用的非注释数据中进行学习。
The pseudo-labels for the pretext task are automati-cally generated(without requiring any expensive manual annotations)based on data attributes and task definition. Therefore,the pretext task definition is a critical choice in SSL.
预训练阶段的自监督学习使模型能够自动生成伪标签,而无需昂贵的手动注释,因此自监督任务的选择是至关重要的。
existing SSL methods basedupon their pretext tasks into (a)generative approaches whichsynthesize images or videos(given conditional inputs),(b)context-based methods which exploit the relationships be-tween image patches or video frames,and(c)cross-modalmethods which leverage from multiple data modalities.
根据预训练任务的不同,自监督学习方法可以分为生成型方法、基于上下文的方法和跨模态方法,它们分别针对不同的数据属性和任务定义。
2.3 Transformer模型
with each block having two sub-layers:amulti-head self-attention network,and a simple position-wise fully connected feed-forward network.
每个块包含两个子层,分别是多头自注意力网络和简单的位置感知的全连接前馈网络。
Positional encodings are added to the input sequence to capture the relative position of each word in the sequence.
Transformer 模型的编码器接收一个语言中的单词序列作为输入,并通过位置编码捕捉每个单词在序列中的相对位置。
Being an auto-regressive model,the decoder ofthe Transformer[1] uses previous predictions to output thenext word in the sequence.
Transformer 模型的解码器使用先前的预测来输出句子中的下一个单词,同时接收来自编码器的输入以及先前的输出。

2.4 双向表征
Bidirectional Encoder Representations fromTransformers(BERT)[3]proposed to jointly encode the rightand left context of a word in a sentence,thus improvingthe learned feature representations for textual data in anself-supervised manner.
双向编码器表示( Bidirectional Encoder Representations from Transformers,BERT ) [ 3 ]提出对句子中单词的左右上下文进行联合编码,以自监督的方式改进文本数据的学习特征表示。
Masked Language Model(MLM)-Afixed percentage(15%)of words in a sentence are randomlymasked and the model is trained to predict these maskedwords using cross-entropy loss.
MLM 任务中,句子中的一定比例的单词会被随机屏蔽,模型要预测这些被屏蔽的单词,从而学习双向上下文信息。
Next Sentence Prediction(NSP)-Given a pairof sentences,the model predicts a binary label i.e.,whetherthe pair is valid from the original document or not.Thetraining data for this can easily be generated from anymonolingual text corpus.
NSP 任务中,模型需要预测一对句子的二进制标签,即原始文档中这对句子是否有效。训练数据可以从任何单语文本语料库中轻松生成,模型通过此任务能够捕捉句子之间的关系,这在许多语言建模任务中至关重要。
NSP enables the model to capture sentence-to-sentencerelationships which are crucial in many language modelingtasks such as Question Answering and Natural LanguageInference.
NSP使模型能够捕获在许多语言建模任务(如问答和自然语言推理)中至关重要的句子间关系。
3.CV中的自注意力与Transformer
We broadly categorize vision models with self-attentioninto two categories:the models which use single-head self-attention(Sec.3.1),and the models which employ multi-head self-attention based Transformer modules into theirarchitectures(Sec.3.2).
视觉模型可以广泛分为两类,一类使用单头自注意力机制,另一类使用基于多头自注意力机制的Transformer模块。
single-head self-attention based frameworks,which generally apply global or local self-attention withinCNN architectures,or utilize matrix factorization to enhancedesign efficiency and use vectorized attention models.
单头自注意力机制的框架通常在CNN架构中应用全局或局部自注意力,或者利用矩阵分解增强设计效率,并使用矢量化注意力模型。

3.1 单头自注意力机制
3.1.1 CNN中的自注意力机制
This way,the non-local operation isable to capture interactions between any two positions inthe feature map regardless of the distance between them.
这样,非局部操作能够捕获特征图中任意两个位置之间的交互作用,无论它们之间的距离有多远。
Videos classification is an example of a task where long-range interactions between pixels exist both in space andtime.
在视频分类任务中,像素之间存在空间和时间上的长距离交互作用。
Although the self-attention allows us to model full-image contextual information,it is both memory and com-pute intensive.
自注意力允许我们建模全图像的上下文信息,但它既消耗内存又计算密集。

Another shortcoming of the convolutional operatorcomes from the fact that after training,it applies fixedweights regardless of any changes to the visual input.
卷积操作的另一个缺点是,在训练之后,它应用固定权重,不管视觉输入是否发生变化。
self-attention as an alternative to convolutional operators.
自注意力被探索作为卷积操作的替代方法。
3.1.2 单独使用自注意力
On the other hand,global attention[1]which attend toall spatial locations of the input can be computationallyintensive and is preferred on down-sampled small images,image patches[11]or augmenting the convolutional featuresspace[79].
全局注意力虽然能够关注输入的所有空间位置,但计算成本高,通常适用于降采样的小图像、图像块或增强卷积特征空间。
3.2 多头自注意力(Transformer)
Vision Transformer(ViTs)[11]adapts the architecture of[1](see Fig.3),which cascades multiple Transformer layers
Vision Transformer(ViTs)采用了多个Transformer层级的架构,而不是像第3.1节中讨论的将自注意力作为CNN启发架构中的组件插入。
Below,we discuss these methods by categorizingthem into:uniform scale ViTs having single-scale featuresthrough all layers(Sec.3.2.1),multi-scale ViTs that learnhierarchical features which are more suitable for denseprediction tasks(Sec.3.2.2),and hybrid designs havingconvolution operations within ViTs(Sec.3.2.3).
这些方法可以分为三类:统一规模的ViTs在所有层中都具有单一规模特征,多尺度的ViTs学习适用于密集预测任务的分层特征,以及在ViTs内部具有卷积操作的混合设计。
3.2.1 统一尺度的视觉Transformer
The original Vision Transformer[11]model belongs to thisfamily,where the multi-head self-attention is applied to aconsistent scale in the input image where the spatial scale ismaintained through the network hierarchy.
最初的Vision Transformer模型属于这个家族,其中多头自注意力被应用于输入图像中的一致尺度,通过网络层次结构来保持空间尺度。
Vision Transformer(ViT)[11](Fig.6)is the first workto showcase how Transformers can‘altogether’replacestandard convolutions in deep neural networks on large-scale image datasets.
Vision Transformer(ViT)是第一个展示了Transformer如何完全取代标准卷积在大规模图像数据集上的深度神经网络的工作。
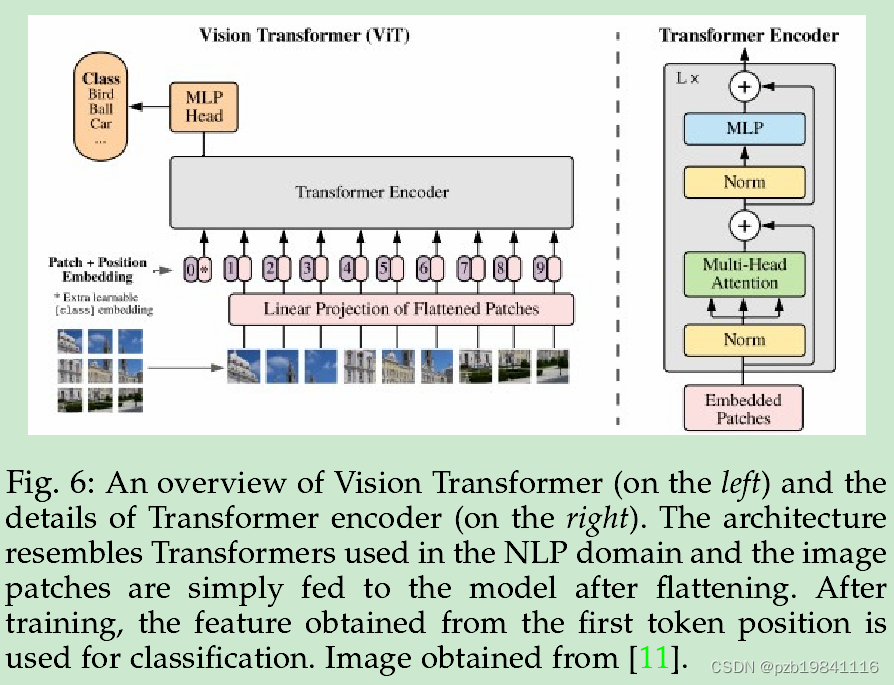
Besides using augmentation and regularizationprocedures common in CNNs,the main contribution ofDeiT[12]is a novel native distillation approach for Trans-formers which uses a CNN as a teacher model(RegNetY-16GF[86])to train the Transformer model.
除了使用CNN中常见的数据增强和正则化程序外,DeiT的主要贡献是一种新颖的原生蒸馏方法,用于Transformer,它使用CNN作为教师模型来训练Transformer模型。
3.2.2 多尺度视觉Transformer
In standard ViTs,the number of the tokens and token featuredimension are kept fixed throughout different blocks ofthe network.
多阶段分层设计的ViTs逐渐减少了标记数量,同时逐步增加了标记特征维度,
These architectures mostly sparsify tokens by merg-ing neighboring tokens and projecting them to a higherdimensional feature space.
这些架构通常通过合并相邻标记并将它们投影到更高维度的特征空间来稀疏化标记。
Some of them are hybrid designs(with both convolution and self-attentionoperations,see Sec.3.2.3),while others only employ pureself-attention based design(discussed next).
这些架构中的一些是混合设计(同时使用卷积和自注意力操作),而其他一些仅采用纯自注意力设计。
Pyramid ViT(PVT)[93]is the first hierarchical designfor ViT,and proposes a progressive shrinking pyramidand spatial-reduction attention.
具有多阶段分层架构的ViTs通过不同方式来捕获局部和全局关系,如渐进收缩金字塔、空间缩减注意力、交叉尺度嵌入模块等。
3.2.3 与卷积混合的ViT
Convolutions do an excellent job at capturing low-level localfeatures in images,and have been explored in multiple hy-brid ViT designs,specially at the beginning to“patchify andtokenize”an input image.
卷积在捕获图像的低层局部特征方面表现出色,因此在多种混合ViT设计中得到了探索,特别是在开始时将输入图像“划分成补丁并标记化”。
3.2.4 自监督视觉Transformer
Contrastive learning based self-supervised approaches,which have gained significant success for CNN based visiontasks,have also been investigated for ViTs.
基于对比学习的自监督方法在基于CNN的视觉任务中取得了显著的成功,也被研究用于ViTs中。
3.3 用于目标检测的Transformer
Transformers based modules have been used for objectdetection in the following manner:(a)Transformer back-bones for feature extraction,with a R-CNN based headfor detection(see Sec.3.2.2),(b)CNN backbone for visualfeatures and a Transformer based decoder for object detec-tion[13],[14],[122],[123](see Sec.3.3.1,and(c)a purelytransformer based design for end-to-end object detection[124](see Sec.3.3.2).
目标检测中使用基于Transformer的模块有以下几种方式:- (a) 使用Transformer骨干进行特征提取,并配合一个基于R-CNN的头部进行检测。- (b) 使用CNN骨干提取视觉特征,并使用基于Transformer的解码器进行对象检测。- (c) 采用纯Transformer设计进行端到端的对象检测。
3.3.1 用CNN做骨干网络的检测Transformer
Detection Transformer(DETR)[13]treats object detectionas a set prediction task i.e.,given a set of image features,the objective is to predict the set of object bounding boxes.
Detection Transformer(DETR)将目标检测视为一个集合预测任务,即在给定一组图像特征的情况下,目标是预测一组物体边界框。
The Transformer model enables the prediction of a set ofobjects(in a single shot)and also allows modeling theirrelationships.
DETR采用了Transformer模型,使得可以在一次预测中预测一组对象,并且允许对它们的关系进行建模
bipartite matching between predictions and ground-truthboxes.
DETR使用一种集合损失函数,允许预测与地面真实框之间的二部匹配。
The main advantage of DETR is that it removesthe dependence on hand-crafted modules and operations,such as the RPN(region proposal network)and NMS(non-maximal suppression)commonly used in object detection[125]–[129].
DETR的主要优点在于它消除了对手工设计的模块和操作的依赖,例如在对象检测中常用的RPN(区域提议网络)和NMS(非极大值抑制)。

The DETR[13]model successfully combines convolu-tional networks with Transformers[1]to remove hand-crafted design requirements and achieves an end-to-endtrainable object detection pipeline.
DETR模型成功地将卷积网络与Transformer相结合,实现了端到端可训练的对象检测流水线。
3.3.2 用纯Transformer做检测
You Only Look at One Sequence(YOLOS)[124]is a sim-ple,attention-only architecture directly built upon the ViT
You Only Look at One Sequence(YOLOS)是一个简单的基于注意力机制的架构,直接建立在ViT之上。
It replaces the class-token in ViT with multiplelearnable object query tokens,and the bipartite matchingloss is used for object detection similar to[13].
YOLOS将ViT中的类标记替换为多个可学习的对象查询标记,并使用二部匹配损失进行对象检测,类似于DETR。
We note that it isfeasible to combine other recent ViTs with transformer baseddetection heads as well to create pure ViT based designs[124],and we hope to see more such efforts in future.
可以将其他最近的ViTs与基于Transformer的检测头部结合起来,创建纯ViT的设计,希望未来能看到更多类似的尝试。
3.4 用于分割的Transformer
Self-attention can be leveraged for dense prediction taskslike image segmentation that requires modeling rich interac-tions between pixels.
自注意力可以用于密集预测任务,如图像分割,需要建模像素之间的丰富交互。
To tackle these issues,Wang et al.[133]propose the position-sensitive axial-attention where the 2Dself-attention mechanism is reformulated as two 1D axial-attention layers,applied to height-axis and width-axis se-quentially(see Fig.8).
Axial self-attention将2D自注意机制重新构建为两个1D轴向自注意层,分别应用于高度轴和宽度轴,从而实现了计算效率,并使模型能够捕获全图像的上下文信息。

Segmentation Transformer(SETR)[134]has a ViT encoder,and two decoder designs basedupon progressive upsampling,and multi-level feature ag-gregation.SegFormer[101]has a hierarchical pyramid ViT[93](without position encoding)as an encoder,and a simpleMLP based decoder with upsampling operation to get thesegmentation mask.
Segmenter使用ViT编码器提取图像特征,并采用Mask Transformer模块进行解码,预测分割掩码,同时提出了基线线性解码器,将补丁嵌入投影到分类空间,从而生成粗糙的补丁级标签。
3.5 用于图像与场景生成的Transformer
Their approachmodels the joint distribution of the image pixels by factor-izing it as a product of pixel-wise conditional distributions.
他们的方法通过将图像像素的联合分布因子化为像素级条件分布的乘积来建模图像像素的联合分布。

Inspired by the success of GPT model[5]in the lan-guage domain,image GPT(iGPT)[143]demonstrated thatsuch models can be directly used for image generationtasks,and to learn strong features for downstream visiontasks(e.g.,image classification).
Image GPT(iGPT)直接在图像领域使用了类似于GPT模型在语言领域的成功经验,展示了这种模型可以直接用于图像生成任务,并学习用于下游视觉任务的强特征。
TransGAN[145]builds a strong GAN model,free of any convolutionoperation,with both generator and discriminator basedupon the Transformer model[1].
TransGAN是一种基于Transformer模型而不是卷积操作的强大GAN模型,包括生成器和判别器。
Ramesh etal.[20]recently proposed DALL·E which is a Transformermodel capable of generating high-fidelity images from agiven text description.DALL·E model has 12 billion param-eters and it is trained on a large set of text-image pairs takenfrom the internet.Before training,images are first resizedto 256×256 resolution,and subsequently compressed toa 32×32 grid of latent codes using a pre-trained discretevariational autoencoder[162],[163].
DALL·E是一个Transformer模型,能够从给定的文本描述生成高保真度的图像。它采用了12亿个参数,并通过预先训练的离散变分自动编码器将图像压缩到32x32的潜在编码网格中。

3.6 低级别视觉处理的Transformer
numerous Transformer-based meth-ods have been proposed for low-level vision tasks,includingimage super-resolution[16],[19],[164],denoising[19],[165],deraining[19],[165],and colorization[24].
人们提出了大量基于Transformer的方法,用于低级视觉任务,包括图像超分辨率、去噪、去雨、和着色等。
Image restorationrequires pixel-to-pixel correspondence from the input to theoutput images.One major goal of restoration algorithmsis to preserve desired fine image details(such as edgesand texture)in the restored images.
图像恢复需要在输入和输出图像之间进行像素级对应。恢复算法的一个主要目标是在恢复图像中保留所需的精细图像细节(如边缘和纹理)。
3.6.1 用于图像处理任务的Transformer
In contrast,algorithms for low-level vision tasks such as image denoising,super-resolution,and deraining are directly trained on task-specific data,thereby suffer from these limitations:(i)small number of im-ages available in task-specific datasets(e.g.,the commonlyused DIV2K dataset for image super-resolution containsonly 2000 images),(ii)the model trained for one imageprocessing task does not adapt well to other related tasks.
低级视觉任务(如图像去噪、超分辨率和去雨)的算法直接在任务特定数据上进行训练,因此受到以下限制:任务特定数据集中图像数量有限;训练用于一个图像处理任务的模型不太适用于其他相关任务。
It is capable of performing various imagerestoration tasks such as super-resolution,denoising,andderaining.The overall architecture of IPT consists of multi-heads and multi-tails to deal with different tasks separately,and a shared encoder-decoder Transformer body.
IPT能够执行各种图像恢复任务,如超分辨率、去噪和去雨。IPT的总体架构包括多头和多尾,以分别处理不同的任务,并且具有共享的编码器-解码器Transformer主体。
During training,each task-specific head takes asinput a degraded image and generates visual features.Thesefeature maps are divided into small crops and subsequentlyflattened before feeding them to the Transformer encoder(whose architecture is the same as[1]).
在训练过程中,每个特定任务的头部接受退化图像作为输入,并生成视觉特征。这些特征图被划分为小的裁剪图,然后被送入Transformer编码器。
The outputs of the encoder along with the task-specific embeddings are givenas input to the Transformer decoder.The features from thedecoder output are reshaped and passed to the multi-tailthat yields restored images.
编码器的输出连同任务特定的嵌入被输入到Transformer解码器。解码器输出的特征被重塑并传递给多尾,产生恢复的图像。
3.6.2 用于超分辨率重构的Transformer
While the SR methods[167],[170]–[173]that are based on pixel-wise loss functions(e.g.,L1,MSE,etc.)yield impressive results in terms of image fi-delity metrics such as PSNR and SSIM,they struggle torecover fine texture details and often produce images thatare overly-smooth and perceptually less pleasant.
基于像素级损失函数(如L1、MSE等)的SR方法在图像保真度指标(如PSNR和SSIM)方面取得了令人印象深刻的结果,但它们难以恢复精细纹理细节,通常产生过度平滑和感知上不愉悦的图像。
The above mentioned SR approaches follow two distinct(butconflicting)research directions:one maximizing the recon-struction accuracy and the other maximizing the perceptual quality,but never both.
上述SR方法遵循两个不同(但相互冲突)的研究方向:一个最大化重建精度,另一个最大化感知质量,但从未兼顾两者。
The texture Transformer module of TTSR method(see Fig.11)consists of four core components:
TTSR方法的纹理Transformer模块包括四个核心组件:(1)可学习的纹理提取器;(2)相关性嵌入;(3)硬注意力;(4)软注意力。

3.6.3 用于着色的Transformer
Given a grayscale image,colorization seeks to produce thecorresponding colorized sample.It is a one-to-many task asfor a given grayscale input,there exist many possibilitiesin the colorized output space.
色彩化旨在为灰度图像生成相应的彩色样本,是一种一对多的任务,因为对于给定的灰度输入,存在着许多可能的彩色化输出空间。
Colorization Trans-former[24]is a probabilistic model based on conditionalattention mechanism[179].It divides the image colorizationtask into three sub-problems and proposes to solve eachtask sequentially by a different Transformer network.
色彩化Transformer是一种基于条件注意力机制的概率模型,将图像色彩化任务分为三个子问题,并提出通过不同的Transformer网络依次解决每个任务。
first train a Transformer network to map a low-resolution grey-scale image to a 3-bit low-resolution col-ored image.
首先训练一个Transformer网络,将低分辨率的灰度图像映射到3位低分辨率的彩色图像。
The 3-bit low-resolution colored imageis then upsampled to an 8-bit RGB sample by anotherTransformer network in the second stage of training.
通过另一个Transformer网络将3位低分辨率彩色图像上采样为8位RGB样本,
Transformer is trained to increase the spatialresolution of the 8-bit RGB sample produced by the second-stage Transformer.
通过第三个阶段的Transformer训练,将第二阶段Transformer生成的8位RGB样本的空间分辨率增加。
These layers capture the interaction between each pixel of an input image while being computation-ally less costly.
这些层捕捉输入图像每个像素之间的交互作用,同时计算成本较低。
3.7 用于多模型任务的Transformer
Sev-eral works in this direction target effective vision-languagepre-training(VLP)on large-scale multi-modal datasets tolearn generic representations that effectively encode cross-modality relationships(e.g.,grounding semantic attributesof a person in a given image).
在这个方向上的几项工作旨在在大规模多模态数据集上进行有效的视觉语言预训练(VLP),以学习能够有效编码跨模态关系的通用表示形式
several of these modelsstill use CNNs as vision backbone to extract visual featureswhile Transformers are used mainly used to encode textfollowed by the fusion of language and visual features.
这些模型中的几个仍然使用CNN作为视觉主干来提取视觉特征,而Transformer主要用于编码文本,然后融合语言和视觉特征。
The single-stream designs feed the multi-modal inputs to a single Transformerwhile the multi-stream designs first use independent Trans-formers for each modality and later learn cross-modal repre-sentations using another Transformer(see Fig.12).

3.7.1 多流Transformer
ViLBERTdeveloped a two-stream architecture where each stream is dedicated to model the vision or language inputs(Fig.12-h).
ViLBERT采用了双流架构,其中每个流专用于建模视觉或语言输入,其架构是一系列Transformer块,类似于BERT模型。
The pre-training phase oper-ates in a self-supervised manner,i.e.,pretext tasks are cre-ated without manual labeling on the large-scale unlabelled dataset.
预训练阶段以自监督方式进行,即在大规模未标记数据集上创建预文本任务,例如预测文本和图像输入是否相关,以及预测图像区域和文本输入的语义。
For the first time in the literature,they propose tolearn an end-to-end multi-modal bidirectional Transformermodel called PEMT on audio-visual data from unlabeled videos.
他们首次提出了一种名为PEMT的端到端多模态双向Transformer模型,用于从未标记视频的音频-视觉数据中学习。
short-term(e.g.,1-3 seconds)video dynamicsare encoded using CNNs,followed by a modality-specificTransformer(audio/visual)to model long-term dependen-cies(e.g.,30 seconds).A multi-modal Transformer is then applied to the modality-specific Transformer outputs to ex-change information across visual-linguistic domains.
PEMT使用CNN对短期视频动态进行编码,然后使用模态特定的Transformer来建模长期依赖关系,并通过多模态Transformer交换信息。
CLIP[195]is a contrastive approach to learn image rep-resentations from text,with a learning objective which max-imizes similarity of correct text-image pairs embeddings ina large batch size.
CLIP[195]是一种对比学习方法,通过最大化大批量图像-文本对的相似性来学习文本中的图像表示,展示了出色的零样本迁移能力。

3.7.2 单流Transformer
Different from two-stream networks like ViLBERT[181]and LXMERT[21],VisualBERT[63]uses a single stack ofTransformers to model both the domains(images and text).
VisualBERT[63]使用单个Transformer堆栈来建模图像和文本两个领域,与ViLBERT和LXMERT不同,它不是使用两个流网络。
The input sequence of text(e.g.,caption)and the visualfeatures corresponding to the object proposals are fed tothe Transformer that automatically discovers relations be-tween the two domains.
VisualBERT首先应用于任务无关的预训练,使用两个目标来预测缺失的文本标记和区分给定图像的真假标题。
The Unified Vision-Language Pre-training(VLP)[197]model uses a single Transformer network for both encod-ing and decoding stages.
统一VLP模型采用了共享编码和解码阶段的单个Transformer网络,以更好地在预训练期间共享跨任务信息。
Universal image-text representation(UNITER)[43]per-forms pre-training on four large-scale visual-linguisticdatasets(MS-COCO[75],Visual Genome[200],ConceptualCaptions[196]and SBU Captions[201]).
Universal image-text representation(UNITER)[43]在四个大规模视觉-语言数据集上进行预训练,并设计了预训练任务来强调学习视觉和语言领域之间的关系。
To address this problem,Object-Semantics AlignedPre-Training(Oscar)[44]first uses an object detector toobtain object tags(labels),which are then subsequently usedas a mechanism to align relevant visual features with thesemantic information(Fig.12-b).
Object-Semantics Aligned Pre-Training(Oscar)[44]使用对象检测器获取对象标签,并使用这些标签来将相关的视觉特征与语义信息对齐。
3.7.3 用于视觉描述的Transformer
The visual and text features are then separately linearly projected to a shared space,concatenated and fed toa transformer model(with an architecture similar to DETR)to predict the bounding boxes for objects corresponding to the queries in the grounding text.
MDETR将视觉和文本特征分别线性投影到一个共享空间,然后连接起来,输入到一个Transformer模型(类似于DETR),以预测与文本中的查询对应的对象的边界框。
Visual Groundingwith Transformer[206]has an encoder-decoder architecture,where visual tokens(features extracted from a pretrainedCNN model)and text tokens(parsed through an RNNmodule)are processed in parallel with two distinct branchesin the encoder,with cross-modality attention to generatetext-guided visual features.The decoder then computesattention between the text queries and visual features andpredicts query-specific bounding boxes.
Visual Grounding with Transformer[206]具有编码器-解码器架构,其中视觉标记(从预训练的CNN模型中提取的特征)和文本标记(通过RNN模块解析)在编码器的两个不同分支中并行处理,具有跨模态注意力,以生成文本引导的视觉特征。解码器然后计算文本查询和视觉特征之间的注意力,并预测查询特定的边界框。
3.8 视频理解
3.8.1 视频与语言模型的联合
The VideoBERT[17]model leverages Transformer networksand the strength of self-supervised learning to learn effec-tive multi-modal representations.
VideoBERT[17]利用Transformer网络和自监督学习的优势来学习有效的多模态表示。
VideoBERT uses the prediction of masked visual and linguistic tokens as a pretext task(Fig.12-c).This allows modeling high-level se-mantics and long-range temporal dependencies,importantfor video understanding tasks.
VideoBERT使用掩码视觉和语言标记的预训练任务,以建模高级语义和长期时间依赖性,这对于视频理解任务至关重要。
The video+text model uses a visual-linguisticalignment task to learn cross-modality relationships.Thedefinition of this pre-text task is simple,given the latentstate of the[cls]token,the task is to predict whether thesentence is temporally aligned with the sequence of visual tokens.
视频+文本模型使用视觉-语言对齐任务来学习跨模态关系。该预训练任务的定义很简单,即在[cls]标记的潜在状态的情况下,任务是预测句子是否与视觉标记序列在时间上对齐。
3.8.2 视频动作识别
Neimark et al.[211]propose Video Transformer Network(VTN)that first ob-tains frame-wise features using 2D CNN and apply a Trans-former encoder(Longformer[103])on top to learn temporalrelationships.
Neimark等人提出了Video Transformer Network(VTN),该网络首先使用2D CNN获取逐帧特征,然后在顶部应用Transformer编码器(Longformer)来学习时间关系。
The classification token is passed through afully connected layer to recognize actions or events.Theadvantage of using Transformer encoder on top of spatialfeatures is two fold:(a)it allows processing a complete videoin a single pass,and(b)considerably improves training andinference efficiency by avoiding the expensive 3D convolu-tions.
在VTN中,分类标记通过全连接层传递,以识别动作或事件。将Transformer编码器应用于空间特征的优势有两个:(a)它允许在单次传递中处理完整的视频,(b)通过避免昂贵的3D卷积,大大提高了训练和推理效率。
Multiscale Vision Transformers(MViT)[219]build afeature hierarchy by progressively expanding the channelcapacity and reducing the spatio-temporal resolution invideos.They introduce multi-head pooling attention togradually change the visual resolution in their pyramidstructure.
Multiscale Vision Transformers(MViT)通过逐渐扩展通道容量和降低视频的时空分辨率来构建特征层次结构。他们引入了多头池化注意力,逐步改变金字塔结构中的视觉分辨率。

First,the spatio-temporal tokens are extracted and then efficient factorisedversions of self-attention are applied to encode relationshipsbetween tokens.However,they require initialization withimage-pretrained models to effectively learn the ViT models.
ViViT首先提取时空标记,然后应用有效的分解版本的自注意力来编码标记之间的关系。然而,它们需要使用图像预训练模型进行初始化,以有效地学习ViT模型。
3.8.3 视频实物分割
An encoder and a decoder Transformer is used similar to DETR toframe the instance segmentation problem as a sequence tosequence prediction task.
与DETR类似,VisTR使用编码器和解码器Transformer将实例分割问题框架为一个序列到序列的预测任务。
3.9 少样本学习中的Transformer
Trans-former models have been used to learn set-to-set mappingson this support set[26]or learn the spatial relationshipsbetween a given input query and support set samples[25].
Transformer模型已被用于在这个支持集上学习集合到集合的映射或者学习给定输入查询和支持集样本之间的空间关系。

3.10 聚类中的Transformer
Recent works employ Transformers that operate on setinputs called the Set Transformers(ST)[228]for amortizedclustering.
最近的工作采用了在集合输入上运行的Transformer,称为Set Transformers(ST),用于摊销聚类。
Amortized clustering is a challenging problemthat seeks to learn a parametric function that can map aninput set of points to their corresponding cluster centers.
摊销聚类是一个具有挑战性的问题,它旨在学习一个参数化函数,能够将输入点集映射到它们对应的聚类中心。
3.11 3D分析中的Transformer
Transformers provide a promising mechanism to encoderich relationships between 3D data points.
近期的工作受到Transformer学习集合函数的能力启发,致力于利用Transformer在3D数据点之间编码丰富关系的机制。
4. 开放挑战与未来方向
The most important bottlenecksinclude requirement for large-amounts of training data andassociated high computational costs.
这些挑战包括对大量训练数据的需求以及相关的高计算成本,还存在可视化和解释Transformer模型的一些挑战。
4.1 高计算成本
a strength of Transformer modelsis their flexibility to scale to high parametric complexity.While this is a remarkable property that allows trainingenormous sized models,this results in high training andinference cost
Transformer模型的灵活性使其能够扩展到高参数复杂度,但这也导致了高训练和推理成本。
Additionally,these large-scale models require aggressivecompression(e.g.,distillation)to make them feasible for real-world settings.
除此之外,这些大规模模型需要进行激烈的压缩,以使它们适用于实际环境。
Numerous methods have beenproposed that make special design choices to perform self-attention more‘efficiently’,for instance employing pool-ing/downsampling in self-attention[97],[219],[249],localwindow-based attention[36],[250],axial-attention[179],[251],low-rank projection attention[38],[252],[253],ker-24nelizable attention[254],[255],and similarity-clusteringbased methods[246],[256].
许多方法已经提出,以更‘高效’的方式执行自注意力,例如在自注意力中使用池化/下采样、局部窗口注意力、轴向注意力、低秩投影注意力、可核化注意力和基于相似性聚类的方法等。
Therefore,thereis a pressing need to develop an efficient self-attentionmechanism that can be applied to HR images on resource-limited systems without compromising accuracy.
因此,迫切需要开发一种高效的自注意力机制,可以应用于资源有限的系统中,而不会牺牲准确性。
4.2 海量数据样本的需求
Since Transformer architectures do not inherently encodeinductive biases(prior knowledge)to deal with visual data,they typically require large amount of training to figureout the underlying modality-specific rules.
Transformer架构不会固有地编码适用于视觉数据的归纳偏差(先验知识),因此它们通常需要大量的训练来理解底层的模态特定规则。
DeiT[12]uses a distillation approach to achievedata efficiency while T2T(Tokens-to-Token)ViT[35]modelslocal structure by combining spatially close tokens together,thus leading to competitive performance when trained onlyon ImageNet from scratch(without pre-training).
DeiT使用蒸馏方法实现了数据效率,而T2T(Tokens-to-Token)ViT通过将空间上相近的标记组合在一起来模拟局部结构,从而在仅在ImageNet上进行训练时(没有预训练)实现了竞争性能。
by smoothing the local loss surface using sharpness-awareminimizer(SAM)[258],ViTs can be trained with simpledata augmentation scheme(random crop,and horizontalflip)[259],instead of employing compute intensive strongdata augmentation strategies,and can outperform theircounterpart ResNet models.
通过使用锐度感知最小化器(SAM)平滑局部损失曲面,ViT可以使用简单的数据增强方案(随机裁剪和水平翻转)进行训练,而不需要采用计算密集型的强数据增强策略,并且可以胜过它们的对应的ResNet模型。
4.3 基于视觉任务定制的Transformer设计
Although theinitial results from these simple applications are quite en-couraging and motivate us to look further into the strengthsof self-attention and self-supervised learning,current archi-tectures may still remain better tailored for language prob-lems(with a sequence structure)and need further intuitionsto make them more efficient for visual inputs.
尽管这些简单应用的初步结果相当令人鼓舞,并激励我们进一步探索自注意力和自监督学习的优势,但当前的架构可能仍然更适用于语言问题(具有序列结构),需要更多直觉来使它们对视觉输入更有效。
One may argue thatthe architectures like Transformer models should remaingeneric to be directly applicable across domains,we noticethat the high computational and time cost for pre-trainingsuch models demands novel design strategies to make theirtraining more affordable on vision problems.
尽管有人可能认为像Transformer模型这样的架构应该是通用的,可以直接应用于各个领域,但我们注意到,预训练这些模型所需的高计算成本和时间成本需要新的设计策略,使它们在视觉问题上的训练更具成本效益
4.4 ViT中的网络结构搜寻
While Nerual Architecuter Search(NAS)has been wellexplored for CNNs to find an optimized architecture,itis relatively less explored in Transformers(even for lan-guage transformers[261],[262]).
尽管神经网络架构搜索(NAS)已经在CNN中得到了广泛的探索以找到优化的架构,但在Transformer中的应用相对较少(即使是对于语言Transformer)。
It will be insightfulto further explore the domain-specific design choices(e.g.,the contrasting requirements between language and visiondomains)using NAS to design more efficient and light-weight models similar to CNNs[87].
进一步探索领域特定的设计选择(例如,语言和视觉领域之间的对比要求),使用NAS设计更高效、轻量级的模型,类似于CNN,将是具有洞察力的。
4.5 Transformer的可解释性
compared with CNNs,ViTs demonstrate strongrobustness against texture changes and severe occlusions
与CNN相比,ViTs对纹理变化和严重遮挡表现出强大的鲁棒性
The main challenge is that the attention originatingin each layer,gets inter-mixed in the subsequent layers in acomplex manner,making it difficult to visualize the relativecontribution of input tokens towards final predictions.
主要挑战在于,每一层的注意力在后续层中以复杂的方式相互交织,使得难以可视化输入令牌对最终预测的相对贡献。
Furtherprogress in this direction can help in better understandingthe Transformer models,diagnosing any erroneous behav-iors and biases in the decision process.It can also help usdesign novel architectures that can help us avoid any biases.
在这个方向上的进一步进展可以帮助更好地理解Transformer模型,诊断决策过程中的任何错误行为和偏见。它还可以帮助我们设计新的架构,以避免任何偏见。
4.6 硬件高效设计
Some recent ef-forts have been reported to compress and accelerate NLPmodels on embedded systems such as FPGAs[270].
一些最近的工作已经报道了在嵌入式系统(如FPGA)上压缩和加速NLP模型的努力。
However,such hardware efficient designs are currently lacking for the vision Transformers to enable their seamless deployment in resource-constrained devices.
然而,目前对于视觉Transformer来说,缺乏这样的硬件高效设计,以实现它们在资源受限设备上的无缝部署。
4.7 整合所有模型
Inspired by the biological systems that canprocess information from a diverse range of modalities,Perceiver model[274]aims to learn a unified model thatcan process any given input modality without makingdomain-specific architectural assumptions.
受生物系统的启发,这些系统可以处理来自各种模态的信息,Perceiver模型旨在学习一个统一的模型,可以处理任何给定的输入模态,而不需要做特定于领域的架构假设。
An interesting and openfuture direction is to achieve total modality-agnosticism inthe learning pipeline.
一个有趣且开放的未来方向是实现学习管道的完全模态无关性
5.结论
Attention has played a key role in delivering efficientand accurate computer vision systems,while simultane-ously providing insights into the function of deep neu-ral networks.
注意力在提供高效准确的计算机视觉系统方面发挥了关键作用,同时还揭示了深度神经网络功能的洞察。
Specifically,we in-clude state of the art self-attention models for image recog-nition,object detection,semantic and instance segmentation,video analysis and classification,visual question answering,visual commonsense reasoning,image captioning,vision-language navigation,clustering,few-shot learning,and 3Ddata analysis.
具体来说,我们包括了图像识别、目标检测、语义和实例分割、视频分析和分类、视觉问答、视觉常识推理、图像字幕、视觉语言导航、聚类、少样本学习和3D数据分析等领域的最新自注意力模型。
We systematically highlight the key strengthsand limitations of the existing methods and particularlyelaborate on the important future research directions.
我们系统地突出了现有方法的主要优势和局限性,并特别详细阐述了重要的未来研究方向。