一、DataStream
1,支持序列化的类型有
- 基本类型,即 String、Long、Integer、Boolean、Array
- 复合类型:Tuples、POJOs 和 Scala case classes
Tuples
Flink 自带有 Tuple0 到 Tuple25 类型
Tuple2<String, Integer> person = Tuple2.of("Fred", 35);// zero based index!
String name = person.f0;
Integer age = person.f1;POJOs
Flink 可识别为 POJO 的条件如下
- 该类是公有且独立的(没有非静态内部类)
- 该类有公有的无参构造函数
- 类(及父类)中所有的所有不被 static、transient 修饰的属性要么是公有的(且不被 final 修饰),要么是包含公有的 getter 和 setter 方法,这些方法遵循 Java bean 命名规范。
2,flink 执行数据流向
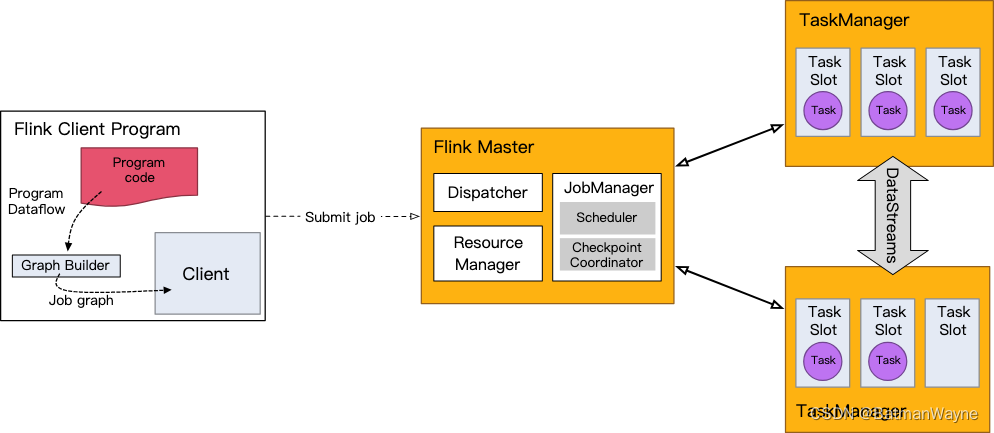
DataStream API 将构建为一个 job graph,并附加到 StreamExecutionEnvironment 。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上,后者对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task slot 中执行。
3,常见 Source
- env.fromElements
通过一个一个元素组成,e.g.
DataStream<Person> flintstones = env.fromElements(new Person("Fred", 35),new Person("Wilma", 35),new Person("Pebbles", 2));- env.fromCollection
直接使用集合构成
List<Person> people = new ArrayList<Person>();people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));DataStream<Person> flintstones = env.fromCollection(people);- env.socketTextStream("localhost", 9999)
通过网络端口获取
- env.readTextFile("file:///path");
通过具体文件获取
4,基本的 sink
xxxx.print()等等
在生产中,常用的 sink 包括各种数据库和几个 pub-sub 系统。