文章目录
- GraalVM运行模式
- JIT模式
- AOT模式
- GraalVM的问题和解决方案
- GraalVM企业级应用
- 传统架构的问题
- Serverless架构
- 函数计算
- Serverless应用场景
- Serverless应用
- GraalVM内存参数
GraalVM运行模式
JIT模式
-
JIT( Just-In-Time )模式 ,即时编译模式
JIT模式的处理方式满足两个特点:
✓Write Once,Run Anywhere-> 一次编写,到处运行。
✓ 预热之后,通过内置的Graal即时编译器优化热点代码,生成比Hotspot JIT更高性能的机器码。 -
GraalVM的JIT编译器在编译过程中使用了即时优化技术,包括方法内联、循环优化、逃逸分析等。这些优化技术可以提高代码的执行效率,并且针对不同的应用场景进行了优化,例如对于大型企业应用、嵌入式系统或数据密集型应用等。
AOT模式
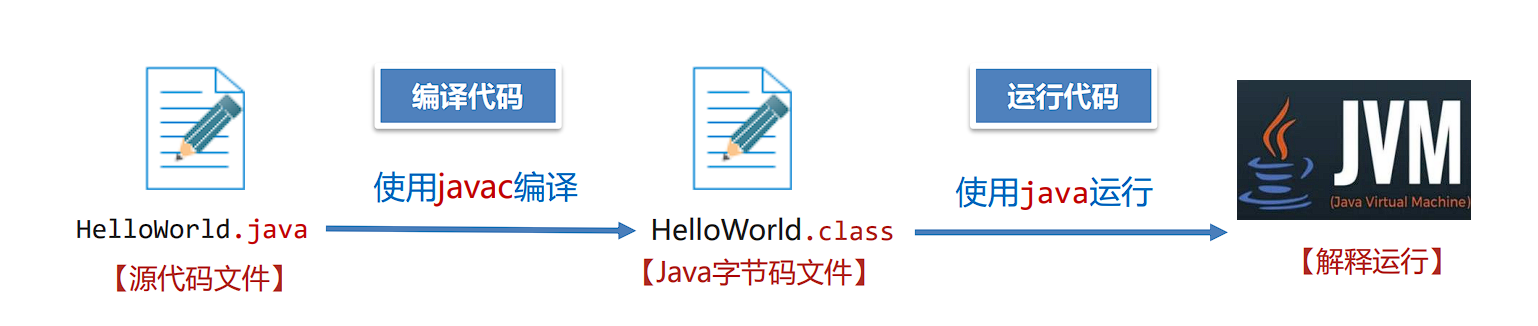
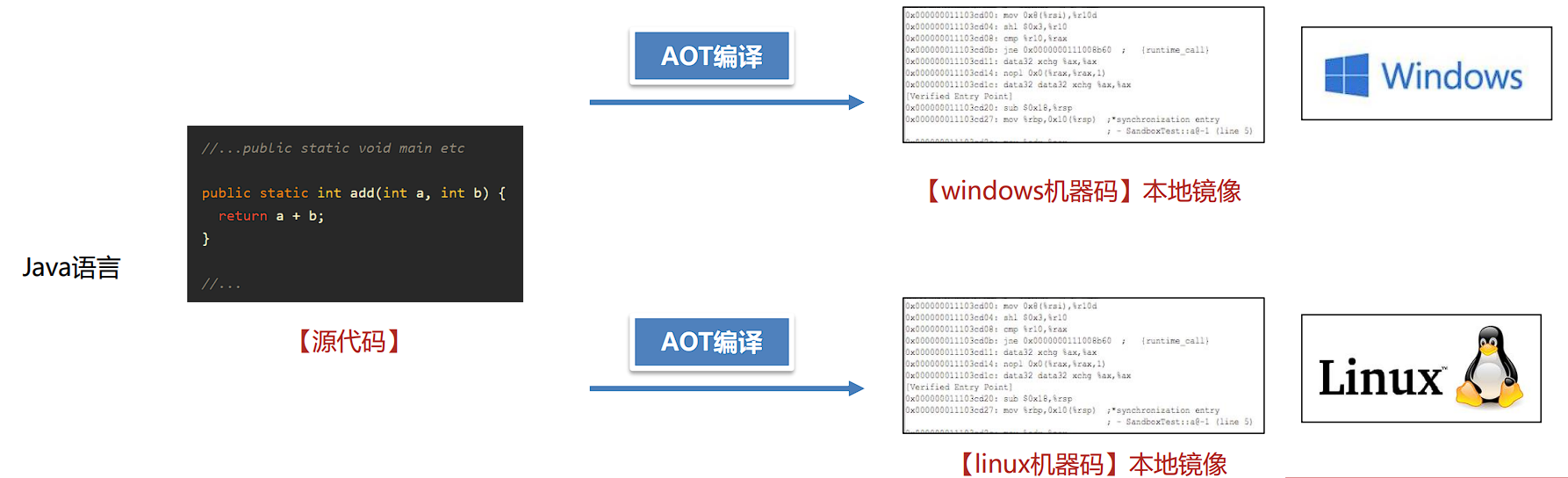
- AOT(Ahead-Of-Time)模式 ,提前编译模式
- 在AOT模式下,GraalVM将Java字节码编译成本地机器代码,并生成一个可执行文件,可以直接在目标平台上运行,而无需Java虚拟机(JVM)。这使得Java应用程序可以像传统的本地应用程序一样启动和执行,而无需依赖JVM。但是不具备跨平台特性,不同平台使用需要单独编译。这种模式生成的文件称之为Native Image本地镜像。
- GraalVM的AOT模式为Java应用程序提供了更快的启动时间和更低的内存消耗,同时仍然保持了良好的性能和跨平台的特性。这使得Java应用程序可以更好地适应云原生、嵌入式和边缘计算等场景的需求。
GraalVM的问题和解决方案
- GraalVM的AOT模式虽然在启动速度、内存和CPU开销上非常有优势,但是使用这种技术会带来几个问题:
- 跨平台问题,在不同平台下运行需要编译多次,编译平台的依赖库等环境要与运行平台保持一致。
- 使用框架之后,编译本地镜像的时间比较长,同时也需要消耗大量的CPU和内存。
- AOT 编译器在编译时,需要知道运行时所有可访问的所有类。但是Java中有一些技术在运行时创建类,例如反射、动态代理等。这些技术在很多框架比如Spring中大量使用,所以框架需要对AOT编译器进行适配解决类似的问题。
- 解决方案:
- 使用公有云的Docker等容器化平台进行在线编译,确保编译环境和运行环境是一致的,同时解决编译资源问题。
- 使用SpringBoot3等整合GraalVM AOT模式的框架版本
GraalVM企业级应用
传统架构的问题
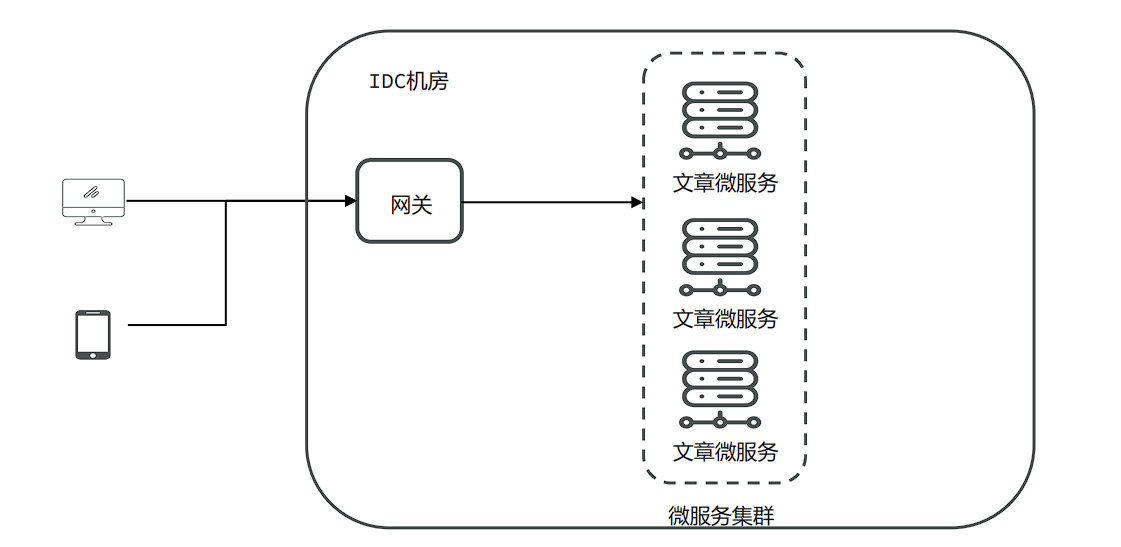
- 传统的系统架构中,服务器等基础设施的运维、安全、高可用等工作都需要企业自行完成,存在两个主要问题:
- 开销大,包括人力的开销、机房建设的开销
- 资源浪费,面对一些突发的流量冲击,比如秒杀,必须提前规划好容量准备好大量的服务器,这些服务器在其他时候会处于闲置的状态,造成大量的浪费
Serverless架构
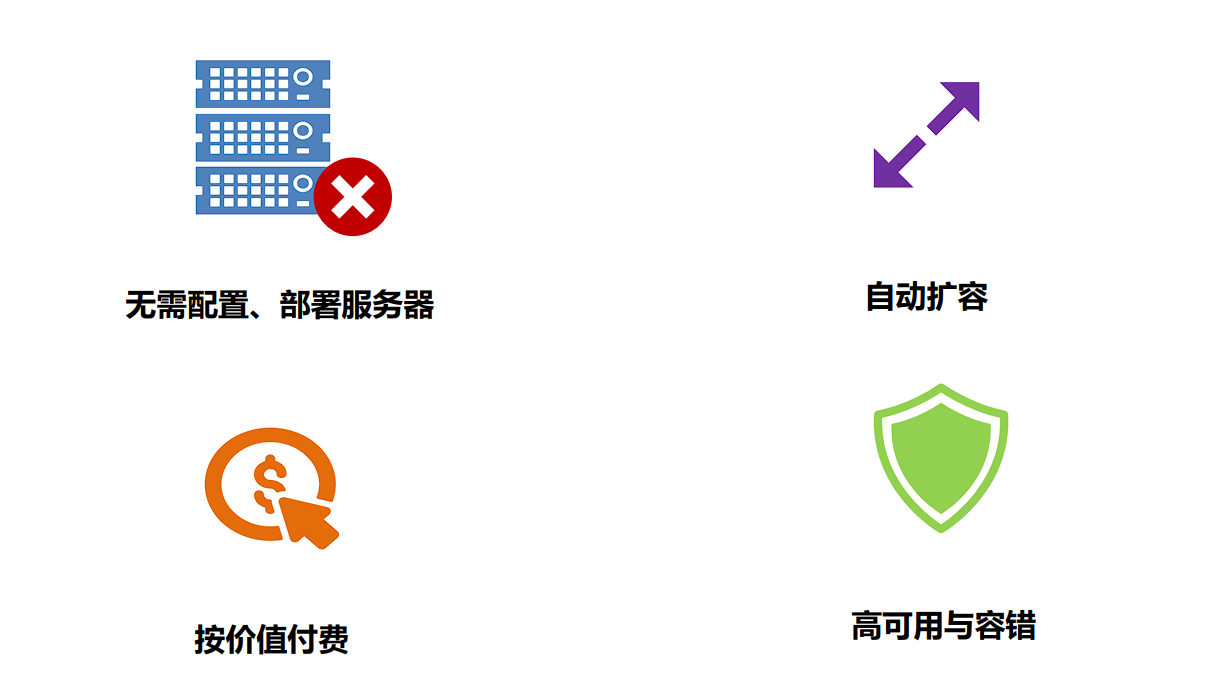
- 随着虚拟化技术、云原生技术的愈发成熟,云服务商提供了一套称为Serverless无服务器化的架构。企业无需进行服务器的任何配置和部署,完全由云服务商提供。比较典型的有亚马逊AWS、阿里云等。
函数计算
- Serverless架构中第一种常见的服务是函数计算(Function as a Service),将一个应用拆分成多个函数,每个函数会以事件驱动的方式触发。典型代表有AWS的Lambda、阿里云的FC。
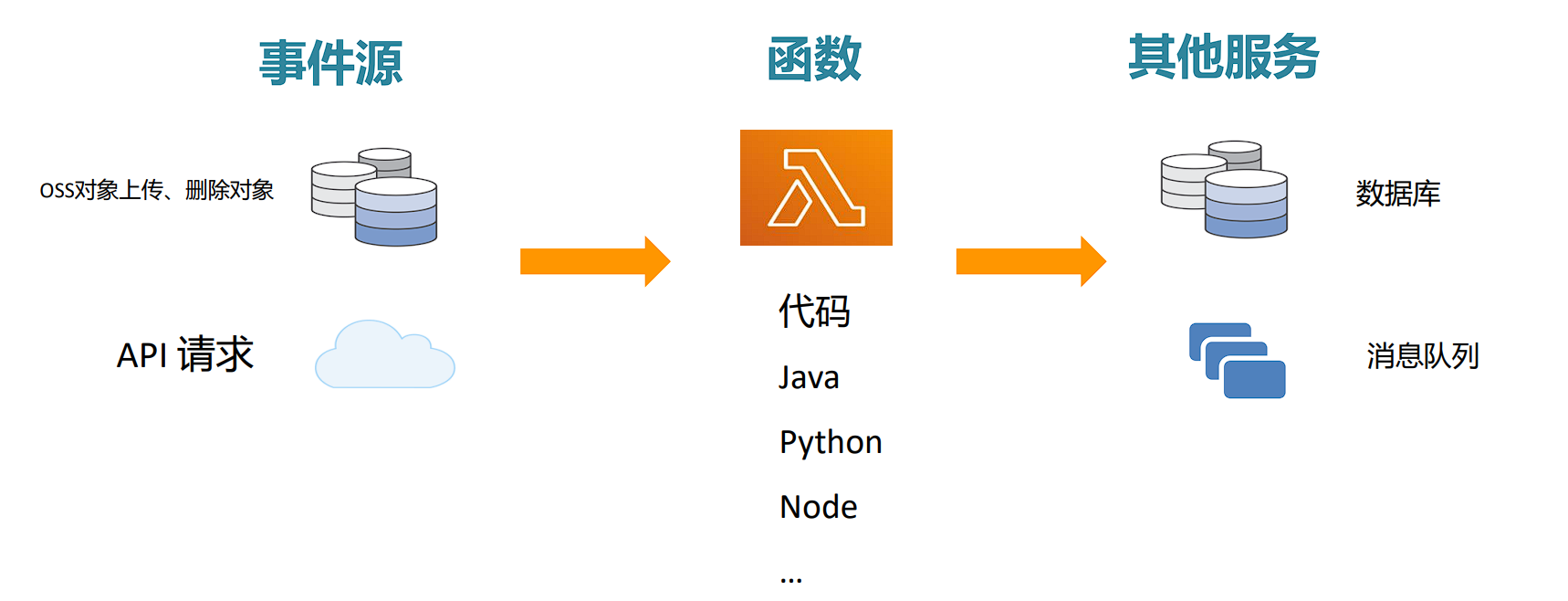
Serverless应用场景
- 函数计算主要应用场景有如下几种:
- 小程序、API服务中的接口,此类接口的调用频率不高,使用常规的服务器架构容易产生资源浪费,使用Serverless可以实现按需付费降低成本,同时支持自动伸缩能应对流量的突发情况。
- 大规模任务的处理,比如音视频文件转码、审核等,可以利用事件机制当文件上传后,自动触发对应的任务。函数计算的计费标准中包含CPU和内存使用量,使用GraalVM AOT模式编译本地镜像可以节省成本。
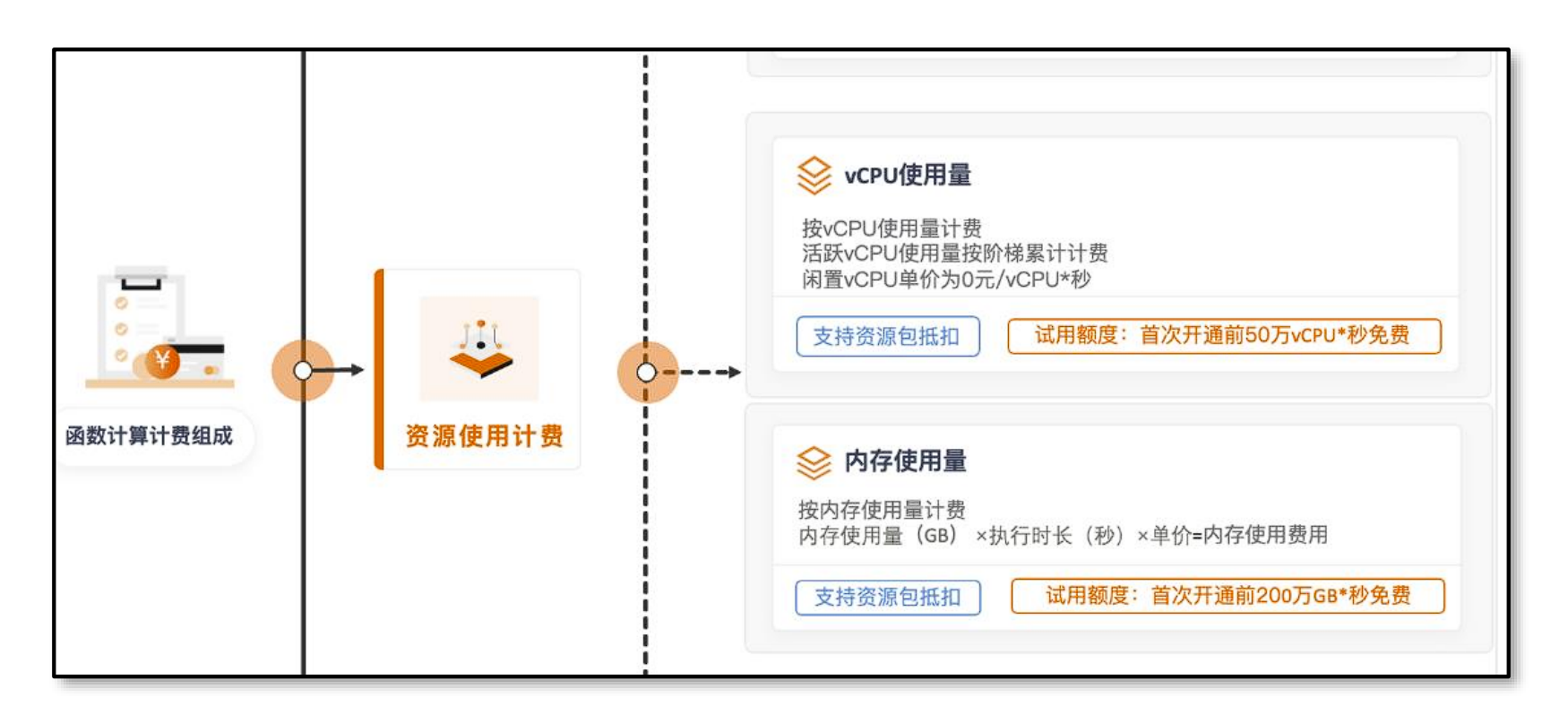
Serverless应用
- 函数计算的服务资源比较受限,比如AWS的Lambda服务一般无法支持超过15分钟的函数执行,所以云服务商提供另外一套方案:基于容器的Serverless应用,无需手动配置K8s中的Pod、Service等内容,只需选择镜像就可自动生成应用服务。
- 同样,Serverless应用的计费标准中包含CPU和内存使用量,所以使用GraalVM AOT模式编译出来的本地镜像可以节省更多的成本。

GraalVM内存参数
- 由于GraalVM是一款独立的JDK,大部分HotSpot中的虚拟机参数都不适用。
⚫ 社区版只能使用串行垃圾回收器(Serial GC),使用串行垃圾回收器的默认最大 Java 堆大小会设置为物理内存大小的 80%,调整方式为使用-Xmx最大堆大小。如果希望在编译期就指定该大小,可以在编译时添加参数-R:MaxHeapSize=最大堆大小。
⚫ G1垃圾回收器只能在企业版中使用,开启方式为添加–gc=G1参数,有效降低垃圾回收的延迟。
⚫ 另外提供一个Epsilon GC,开启方式:–gc=epsilon ,它不会产生任何的垃圾回收行为所以没有额外的内存、CPU开销。如果在公有云上运行的程序生命周期短暂不产生大量的对象,可以使用该垃圾回收器,以节省最大的资源。 -XX:+PrintGC -XX:+VerboseGC参数打印垃圾回收详细信息







![[C#]OpenCvSharp改变图像的对比度和亮度](https://img-blog.csdnimg.cn/direct/5a386bbb0889466ead78a7856997d4bf.gif)