1、引言
论文链接:
https://openaccess.thecvf.com/content/ICCV2021/papers/Touvron_Going_Deeper_With_Image_Transformers_ICCV_2021_paper.pdf
由于目前对图像 Transformer[1] 的优化问题研究很少,Hugo Touvron 等[2] 构建和优化了更深的用于图像分类的 Transformer 网络。研究了图像分类 Transformer 结构和优化的相互作用。作者通过引入 LayerScale[2] 和 Class-Attention[2] 等技术,成功构建了 CaiT[2] 模型。CaiT 的性能不会随着深度的增加而早期饱和,并在 Imagenet、Imagenet-Real 和 Imagenet V2 matched frequency 等数据集上达到或接近 SOTA。
2、方法
2.1 Cait
Cait 结构如图 1 所示,这种设计旨在规避 ViT[3] 架构的一个问题:学习的权重被要求优化两个互相矛盾的目标:
(1)指导补丁之间的自注意力,
(2)总结对线性分类器有用的信息。
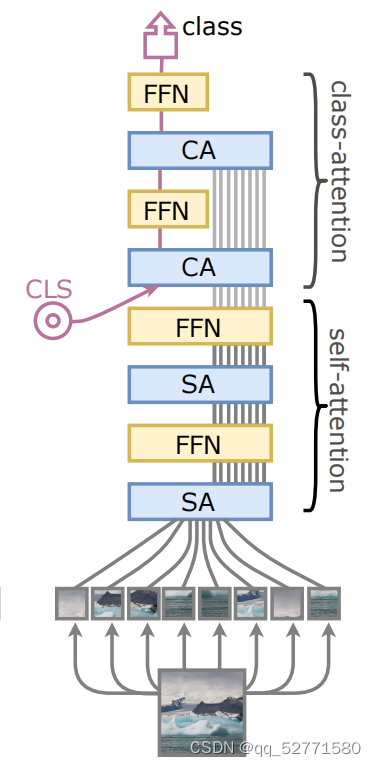
图1 Cait
Cait 由两个处理阶段组成,依次实现上述两个优化目标:
(1)和 ViT 相同的 self-attention 阶段但没有 CLS(类别嵌入),
(2)class-attention 阶段,用于将阶段一的处理结果编译为 CLS,CLS 是线性分类器的输入。与 ViT 的 self-attention 阶段的区别是,class-attention 的 q 是可学习的 CLS。
Cait 还将上述两种注意力机制的缩放因子改为根号每个头的嵌入维度大小,两种注意力机制中引入了 talking-heads attention[4],Cait 通常有 2 个 class-attention 层,并使用了随机深度。
2.2 LayerScale
LayerScale 的作用是增加图像分类 Transformer 训练时优化的稳定性,LayerScale 计算 FFN(Feed Forward Net)/Attention的输出的每个 token 与一个可学习向量(所有 token 使用同一个可学习向量)的 Hadamard 乘积,本质是对每个通道乘以一个对应的可学习标量(权重)。设一个处理阶段的第 d 个Transformer 编码块的 LayerScale 的初值均为 a,则 d<=18 时 a=0.1,18<d<=24 时 a=1e-5,d>24 时 a=1e-6。
3、总结
作者开源的的 pytorch 实现代码在:https://github.com/facebookresearch/deit。目前 Cait 在 Stanford Cars 和 CIFAR-10 数据集上的表现仍排在前 5。
参考文献
[2] Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Herve Jegou. Going deeper with image transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
[3] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov,Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021.
[4] Noam Shazeer, Zhenzhong Lan, Youlong Cheng, N. Ding, and L. Hou. Talking-heads attention. arXiv preprint arXiv:2003.02436, 2020.
![[Semi-笔记]Switching Temporary Teachers for Semi-Supervised Semantic Segmentation](https://img-blog.csdnimg.cn/direct/2499c7feca1b4841aaf9e8b28e412fd6.png)