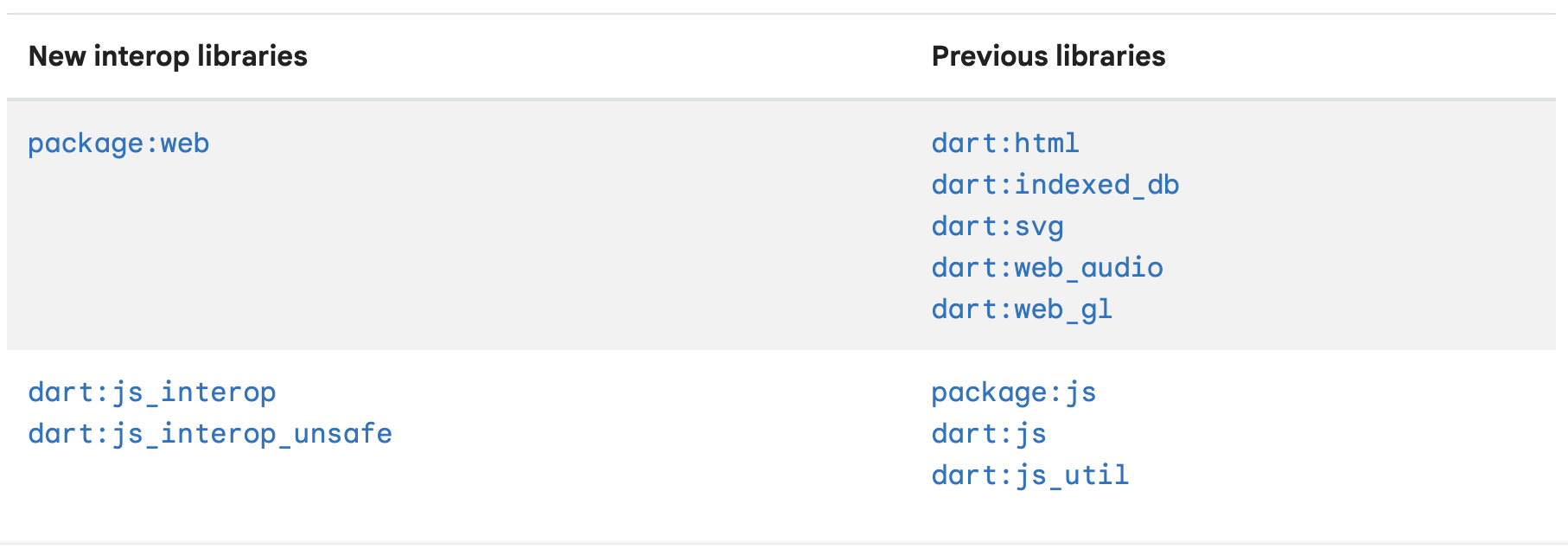
目录
引言
一、Requests库简介
二、安装与基本使用
三、requests库的特性与优势
四、requests库在实际应用中的案例
1.get请求
2.post请求
3.超时重试
4.headers设置
5.session会话
7.携带代理
8.携带身份认证
9.文件上传
10.文件下载
11.解决重定向
12.证书验证
总结
引言
在Python编程世界中,进行网络数据交互是一项至关重要的技能,而Requests库则是这一领域中最受开发者喜爱的工具之一。Requests库以其简洁易用、功能强大而著称,让HTTP客户端操作变得无比轻松,无论是获取网页内容、发送POST请求还是处理API响应,它都能提供强大的支持。本文将带领您深入了解Python Requests库,探讨其核心功能和应用场景。
一、Requests库简介
Requests库由Kenneth Reitz于2012年创建,旨在简化HTTP客户端的使用。它建立在urllib3之上,但提供了更加人性化的接口和丰富的功能特性。只需一行代码,就能发起HTTP GET、POST等各类请求,并能自动处理各种HTTP认证机制、重定向、cookies以及超时等问题。
二、安装与基本使用
在Python环境中,通过pip命令即可快速安装Requests库:
pip install requests导入库后,发起一个HTTP GET请求只需要短短几行代码:
import requestsresponse = requests.get('https://www.example.com')
print(response.status_code)
print(response.text)上述代码首先导入requests模块,然后使用get方法向指定URL发送GET请求,并将服务器返回的响应存储在response对象中。response对象包含了诸如状态码、响应体文本、headers等多种信息。
三、requests库的特性与优势
- 简洁易用:requests库的API设计非常简洁,易于上手。开发者只需关注业务逻辑,无需处理底层的HTTP细节。
- 功能强大:requests库支持多种HTTP方法、自动处理URL编码、会话、cookies等复杂操作,能够满足各种HTTP请求的需求。
- 高度可定制:requests库提供了丰富的参数和选项,允许开发者根据实际需求定制请求和响应的处理方式。
- 社区支持:requests库拥有庞大的用户群体和活跃的社区,遇到问题时可以轻松找到解决方案和支持。
四、requests库在实际应用中的案例
- 网页爬虫:使用requests库发送GET请求,抓取网页内容,并结合BeautifulSoup等库解析HTML,提取所需信息。
- API交互:与第三方API进行交互,发送POST、PUT等请求,获取或修改数据。
- 数据上报:将本地数据通过requests库发送到远程服务器进行存储或分析。
案例代码:
1.get请求
import requests
response = requests.get('https://www.example.com')
print(response.text)print(response.status_code) # 输出状态码
print(response.headers) # 输出响应头
print(response.text) # 输出响应内容(文本格式)
print(response.json()) # 输出响应内容(JSON格式,如果响应内容是JSON的话)2.post请求
import requestsimport jsondata = {'key': 'value'}json_data = json.dumps(data)response = requests.post('https://www.example.com', json=json_data)print(response.text)
3.超时重试
response = requests.get('https://api.example.com/data', timeout=5)try:response = requests.get('https://api.example.com/data', timeout=5)
except requests.exceptions.Timeout:print('Timeout! Let\'s try it again...')response = requests.get('https://api.example.com/data', timeout=5)4.headers设置
import requestsheaders = {'User-Agent': 'Mozilla/5.0'}response = requests.get('https://www.example.com', headers=headers)print(response.text)
5.session会话
import requestssession = requests.Session()# 第一个请求response1 = session.get('https://www.example.com/login')print(response1.text)# 第二个请求,会话保持response2 = session.get('https://www.example.com/dashboard')print(response2.text)
6.携带cookie
import requestscookies = {'key': 'value'}response = requests.get('https://www.example.com', cookies=cookies)print(response.text)
7.携带代理
import requestsproxies = {'http': 'http://10.10.1.10:3128','https': 'http://10.10.1.10:1080'}response = requests.get('https://www.example.com', proxies=proxies)print(response.text)
8.携带身份认证
import requestsfrom requests.auth import HTTPBasicAuthresponse = requests.get('https://www.example.com', auth=HTTPBasicAuth('username', 'password')) print(response.text)
9.文件上传
import requestsfiles = {'file': open('example.txt', 'rb')}response = requests.post('https://www.example.com/upload', files=files)print(response.text)
10.文件下载
import requestsurl = 'https://www.example.com/file.jpg'response = requests.get(url)with open('file.jpg', 'wb') as f:f.write(response.content)
11.解决重定向
import requestsresponse = requests.get('https://www.example.com', allow_redirects=False)if response.status_code == 302:redirect_url = response.headers['Location']print(f'Redirected to: {redirect_url}')
12.证书验证
import requestsresponse = requests.get('https://www.example.com', verify=False)print(response.text)
总结
requests库作为Python中处理HTTP请求的神器,以其简洁易用、功能强大、高度可定制和社区支持等特性,在实际应用中发挥着重要作用。无论是网页爬虫、API交互还是数据上报等场景,requests库都能帮助开发者更加高效地处理HTTP请求,提升开发效率。