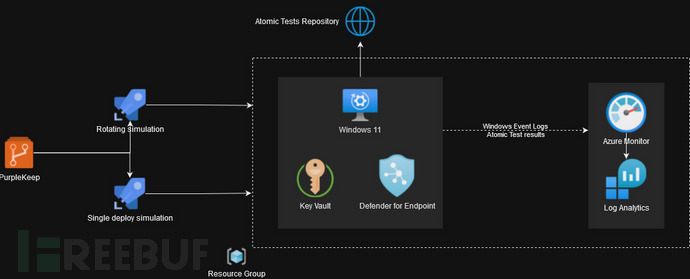
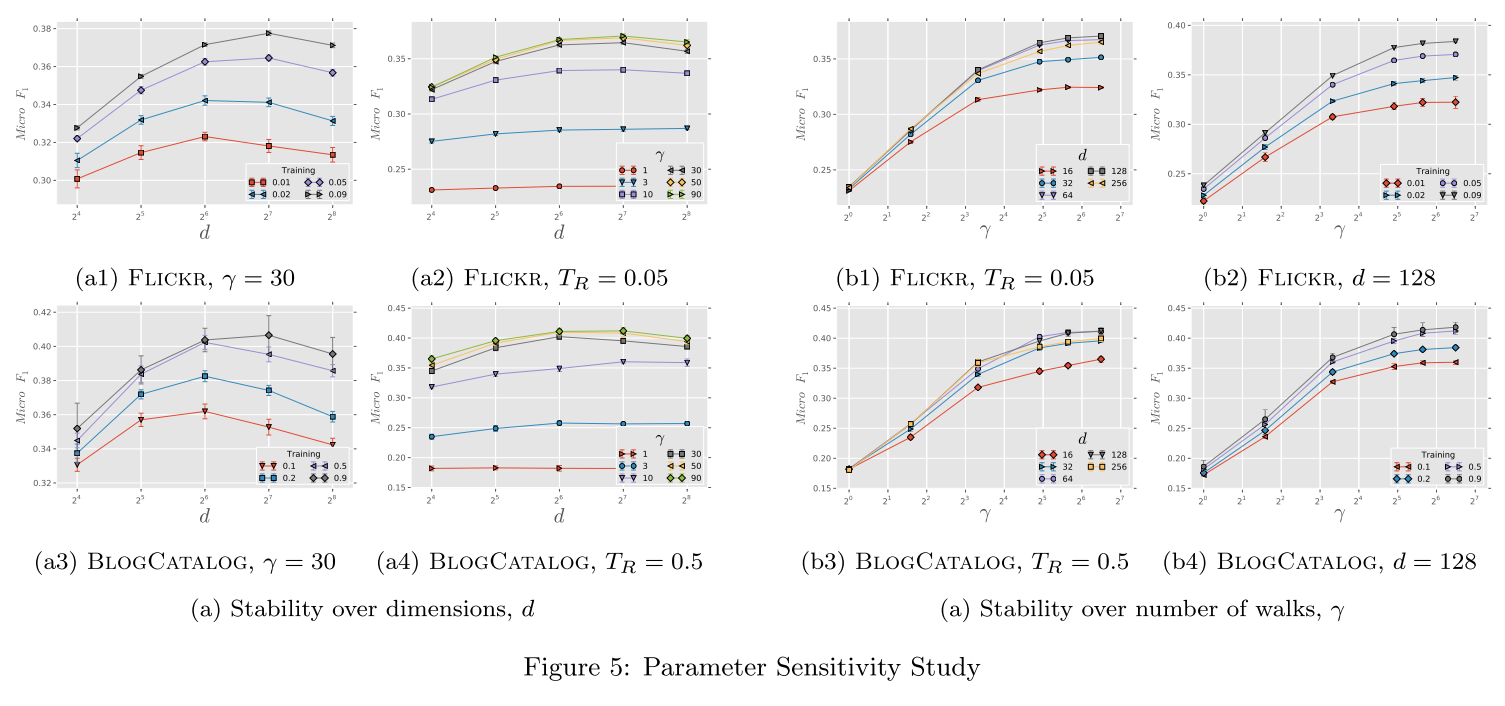
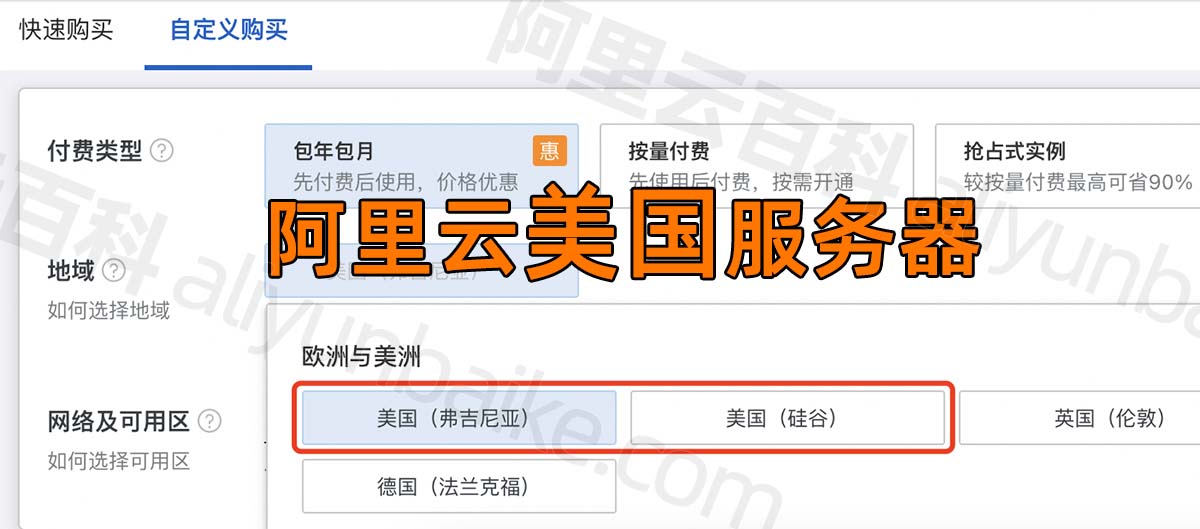
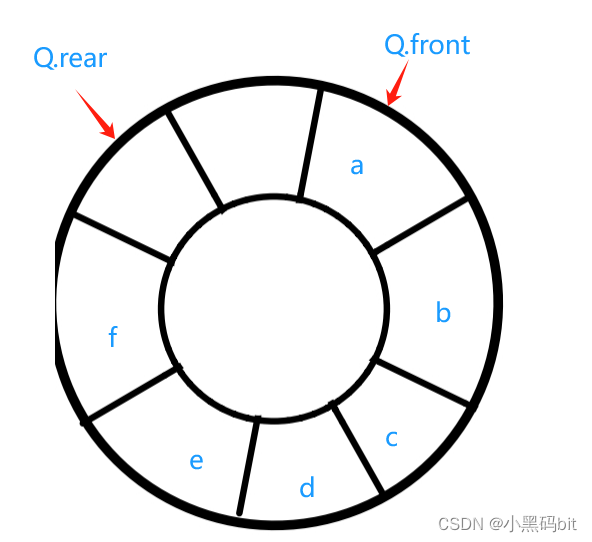
YOLOv3
- 论文简介
- 论文内容
- 1. 采用darknet53+FPN结构
- 2. 边框预测保持与YOLOv2保持一致
- 3. 沿用YOLOv2 kmeans生成先验anchors
- 4.类别预测改为多分类格式
论文简介
论文:《YOLOv3: An Incremental Improvement》
作者:Joseph Redmon, Ali Farhadi
论文下载地址:https://arxiv.org/abs/1804.02767
代码下载:https://github.com/ultralytics/yolov3
在过去一年里作者就一直在推上刷东西,直到ddl到了才写了一篇改进YOLOv3的技术报告(作者论文自己写的)。所以这篇论文文风比较随意。
论文内容

这个图主要表达的是当时几种模型在coco数据集上的的精度与推断时间。YOLOv3的三个星星表示从320、416、608这三种输入大小,也就是说随着输入大小的提高,精度也会提高。对比RetianNet的检测框架,mAP-50是57.5,而YOLOv3-608是57.9,time是198而YOLOv3-608是51,YOLOv3-608在精度和速度上都优秀于RetianNet-101-800

AP是检测精度,AP50是在IOU=50时的AP,AP75是在IOU=75时的AP,APS是小目标(目标边框小于32)的AP,M是中目标,L是大目标(目标边框大于96)
YOLOv3 608对比YOLOv2在各个维度都是远超的
对比两阶段算法,精度基本一样,但是速度是四倍的关系
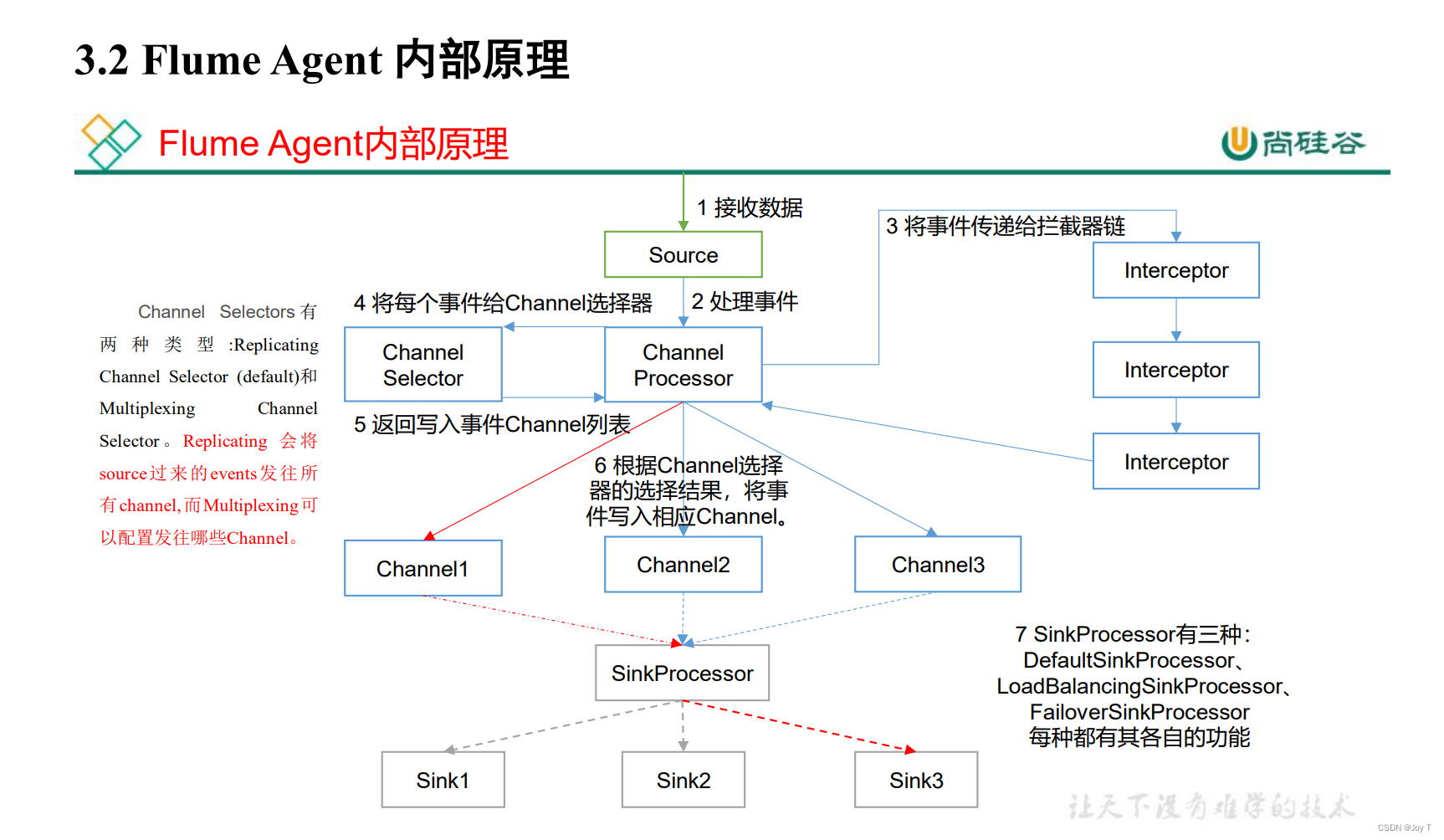
1. 采用darknet53+FPN结构

YOLOv2采用的是darknet-19,是普通的卷积和池化平铺网络,如上图

这是YOLOv3采用的darknet-53结构,每一个方框代表一个残差模块,总共有23个残差模块,残差模块是resnet提出的结构,他可以把模型拼接很深,但是不降低精度。最后拿的是32x32 16x16 8x8这仨模块的输出
darknet一方面采用残差结构,缓解了大型梯度更新慢的问题,采用金字塔FPN结构,从网络中抽取三层,分别是原图的1/8 1/16 1/32,做一个上采样和特征合并的操作,一方面加快训练和避免梯度消失,另一方面融合上下层特征,使大尺度模板检测的时候能参考小尺度特征。

这是FPN结构,大概原理是,以左上角这一层举例,把这一层抽出,进行上采样操作让他变得大一点,跟第二层的合并,把合并结果进行输出。
2. 边框预测保持与YOLOv2保持一致

其中tx ty tw th为模型预测输出
函数为sigmod函数,归一化tx ty
pw ph为anchor的宽高
cx cy为当前grid cell的坐标
bx by bw bh为最终预测的目标边框
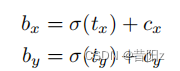
这个预测中心点的预测结果永远是girl cell右下边的效果
损失计算还是差平方和。每个输出的三个先验框会跟ground truth框做一个交并比,只会拿交并比最大的那一个作为最终预测数据。
3. 沿用YOLOv2 kmeans生成先验anchors
YOLOv3输出三个特征层,每个特征层会对应三个先验框,所以YOLOv3总共生成9个anchors。聚类的时候就会分成9类,最小的三类对应1/8特征,中间三类对应1/16,最大对应1/32.这样的效果就是小anchor对应小目标,大anchor对应大目标。

(BV1DS4y1R7zd的P9)
这里是这篇论文最大的改进点
YOLOv2是直接走骨干网络输出结果
YOLOv3是走骨干网络后输出一层19x19,再做一个上采样和上一层的concat在一起,再输出,再做一个上采样和最上边一层拼接在一起,在输出。总共输出三个尺度的tensor。每个tensor的输出是

最后把三维处理成四维。
4.类别预测改为多分类格式
实际使用的时候如果没有多分类需求,就不用这个交叉熵就行。