-
找出10000以内能被5或6整除,但不能被两者同时整除的数(函数)
def func():for i in range(1,50):if (i % 5 == 0 or i % 6 ==0 ):if i % 5 == 0 and i % 6 ==0:continue #利用continue跳过能被5和6整除的数print(i) func() -
写一个方法,计算列表所有偶数下标元素的和(注意返回值)
def ls_conut_o(A):count = 0for i in A:if i % 2 == 0:b = A.index(i)count += bprint(count) A = [1,2,3,4,4] ls_conut_o(A) -
根据完整的路径从路径中分离文件路径、文件名及扩展名
import osa = 'D:\User\666\python\index.txt' >>> os.path.basename(a) 'index.txt ' >>> os.path.dirname(a) ' D:\\User\\666\\python' >>> -
根据标点符号对字符串进行分行
def is_chinese(word):count = 0for ch in word:if '\u4e00' <= ch <= '\u9fff':count += 1 print(f'"{word}"这个字符中有 {count} 个汉字')word = input('请输入:') is_chinese(word) -
去掉字符串数组中每个字符串的空格
a = input('请输入字符串:') print('正在为你进行剔除空格的操作') b = '' for i in a :if i.isspace() == True:continueb += i print(f'剔除空格后的字符串为:{b}') -
两个学员输入各自最喜欢的游戏名称,判断是否一致,如 果相等,则输出你们俩喜欢相同的游戏;如果不相同,则输 出你们俩喜欢不相同的游戏。
def z(a1,a2):if a1 == a2:print("你们俩喜欢相同的游戏")elif a1 != a2:print("你们俩喜欢的游戏不相同")s1=input("请第一位同学输入游戏名称:") s2=input("请第二位同学输入游戏名称:") z(s1,s2) -
上题中两位同学输入 lol和 LOL代表同一游戏,怎么办?
def z(a1,a2):a1 = a1.upper()a2 = a2.upper()if a1 == a2:print("你们俩喜欢相同的游戏")else:print("你们俩喜欢的游戏不相同")s1=input("请第一位同学输入游戏名称:") s2=input("请第二位同学输入游戏名称:") z(s1,s2) -
让用户输入一个日期格式如“2008/08/08”,将 输入的日 期格式转换为“2008年-8月-8日”。
a = input('请输入一个时间格式:(格式如下“2008/08/08”)') li = [] for i in (a.split('/')):li.append(i) print(f'{li[0]}年-{li[1]}月-{li[2]}日') -
接收用户输入的字符串,将其中的字符进行排序(升 序),并以逆序的顺序输出,“cabed”→"abcde"→“edcba”
a = input('请输入一个字符串进行排序:') li = [] count = '' for i in a:b = int(ord(i))li.append(b) li.sort() for i in li:c = chr(i)count += c print(count) print(count[::-1]) -
接收用户输入的一句英文,将其中的单词以反序输 出,“hello c java python”→“python java c hello”。
string=input("请输入一句话:\n").split(' ') string.reverse() string=" ".join(string) print(string) -
从请求地址中提取出用户名和域名 网易
 http://www.163.com?userName=admin&pwd=123456
http://www.163.com?userName=admin&pwd=123456import reurl = "http://www.163.com?userName=admin&pwd=123456" basename = re.search(r'(.*)\?(.*)',url,re.M|re.I) print(basename.group(1)) print(basename.group(2)) -
有个字符串数组,存储了10个书名,书名有长有短,现 在将他们统一处理,若书名长度大于10,则截取长度8的 子串并且最后添加“...”,加一个竖线后输出作者的名字。
book_list = ['最初的爱情,最后的仪式','八十天环游地球','百年孤独','时间从来不语,却回答了所有问题','追忆似水年华'] for i in range (len(book_list)):if len(book_list[i]) > 10:b = book_list[i][0:8:1]c = b + '...'book_list[i] = c print(book_list) -
让用户输入一句话,找出所有"呵"的位置。
string=input("请输入数据\n") k=0 for i in string:if(string[k]=='呵'):print(k)k+=1 -
让用户输入一句话,判断这句话中有没有邪恶,如果有邪 恶就替换成这种形式然后输出,如:“老牛很邪恶”,输出后变 成”老牛很**”;
a = input("请输入一句话:") for i in range(0, len(a)-1):if a[i] == "邪":if a[i+1] == '恶':a = a.replace("邪", "*")a = a.replace("恶", "*")breakprint(a) -
判断一个字符是否是回文字符串 "1234567654321" "上海自来水来自海上"
a = input('请输入字符串,判断是否为回文数列:') if a == a[::-1]:print(f'{a}为回文数列') else:print(f'{a}不是回文数列') -
过滤某个文件夹下的所有"xx.py"python文件
import osdef filter_python_files(folder_path, keyword):for file_name in os.listdir(folder_path):if file_name.endswith(".py") and keyword in file_name:print(file_name)# 示例用法 folder_path = "/path/to/folder" # 替换为实际的文件夹路径 keyword = "xx" # 替换为实际的关键字 -
用户管理系统的,密码加密
users = [] def password_by_md5(password):md5 = hashlib.md5(password.encode("utf-8"))# 盐值md5.update(slat.encode("utf-8"))return md5.hexdigest()while True:print("\t\t欢迎登录用户管理系统")print("\t\t 1、用户注册")print("\t\t 2、用户登录")print("\t\t 3、退出系统")choice = input("请输入您的选择:")if choice == "1":while True:username = input("请输入用户名:")password = input("请输入密码:")password_again = input("请再次确认密码:")if username == None or len(username) == 0:print("对不起,用户为空")continueflag = Falsefor u in users:if u.get("username") == username:print("对不起,该用户已经存在,请重新注册")flag = Truebreakif flag:continueif password != password_again:print("两次密码不一致")continueuser = {"username": username, "password": password}users.append(user)print("用户注册成功,请登录")print("\n")breakelif choice == "2":print("\n")username = input("请输入用户名:")password = input("请输入密码:")for user in users:if user["username"] == username and user.get("password") == password:print(f"尊敬的用户{username},欢迎回来")else:print("对不起,登录失败,请重新登录")else:sys.exit()
python函数练习2
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/298423.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
【MATLAB】GA_BP神经网络时序预测算法
有意向获取代码,请转文末观看代码获取方式~
1 基本定义
GA_BP神经网络时序预测算法是一种结合了遗传算法(GA)和反向传播(BP)神经网络的时序预测方法。它利用了遗传算法的全局搜索和优化能力,以及BP神经网络的学习和逼近能力,可以更有效地预…
![[蓝桥杯练习]蓝桥王国](https://img-blog.csdnimg.cn/direct/49c5c1bc07a64720b865d3664578f955.png)
[蓝桥杯练习]蓝桥王国
单源最短路径问题-dj #include<bits/stdc.h>
#define ll long long
using namespace std;
const int N3e55,M1e65;
const ll INF0x7f7f7f7f7f7f7f;//7个7f没问题,INF < INFx
struct edge{int to;ll w;edge(int end,ll cost){toend;wcost;}
};
struct node{int id;l…

B3631 单向链表(结构体模拟链表)
输入格式 第一行一个整数 q表示操作次数。 接下来 q行,每行表示一次操作,操作具体间题目描述。 输出格式 对于每个操作 2,输出一个数字,用换行隔开。
#include<iostream>
#include<map>
#include<algorithm>
…

vue给input密码框设置眼睛睁开闭合对于密码显示与隐藏
<template><div class"login-container"><el-inputv-model"pwd":type"type"class"pwd-input"placeholder"请输入密码"><islot"suffix"class"icon-style":class"elIcon"…

Linux基础篇:文件系统介绍——根目录下文件夹含义与作用介绍
Linux文件系统介绍——文件夹含义与作用 Linux文件系统是一个组织和管理文件的层次结构。它包括了目录、子目录和文件,这些都是按照一定的规则和标准进行组织的。以下是Linux文件系统的一些关键组成部分:
1./bin:
该目录包含了系统启动和运…


【JavaScript 漫游】【052】Proxy
文章简介
本篇文章为【JavaScript 漫游】专栏的第 052 篇文章,记录了 ES6 规范中 Proxy 的知识点。
概述
Proxy 用于修改某些操作的默认行为,等同于在语言层面做出修改,所以属于一种“元编程”(meta programming)&a…

Navicat for MySQL 15免费注册方法
一、效果图如下: 注:此方法仅用于非商业用途,请勿传播,否则后果自负。
二、下载安装
下载安装包,分为32位和6位,下载文件名:Navicat for MySQL 15.zip(https://download.csdn.net/…

Linux存储的基本管理
实验环境:
系统里添加两块硬盘 ##1.设备识别##
设备接入系统后都是以文件的形式存在 设备文件名称:
SATA/SAS/USB /dev/sda,/dev/sdb ##s SATA, dDISK a第几块
IDE /dev/hd0,/dev/hd1 ##h hard
VIRTIO-BLOCK /de…
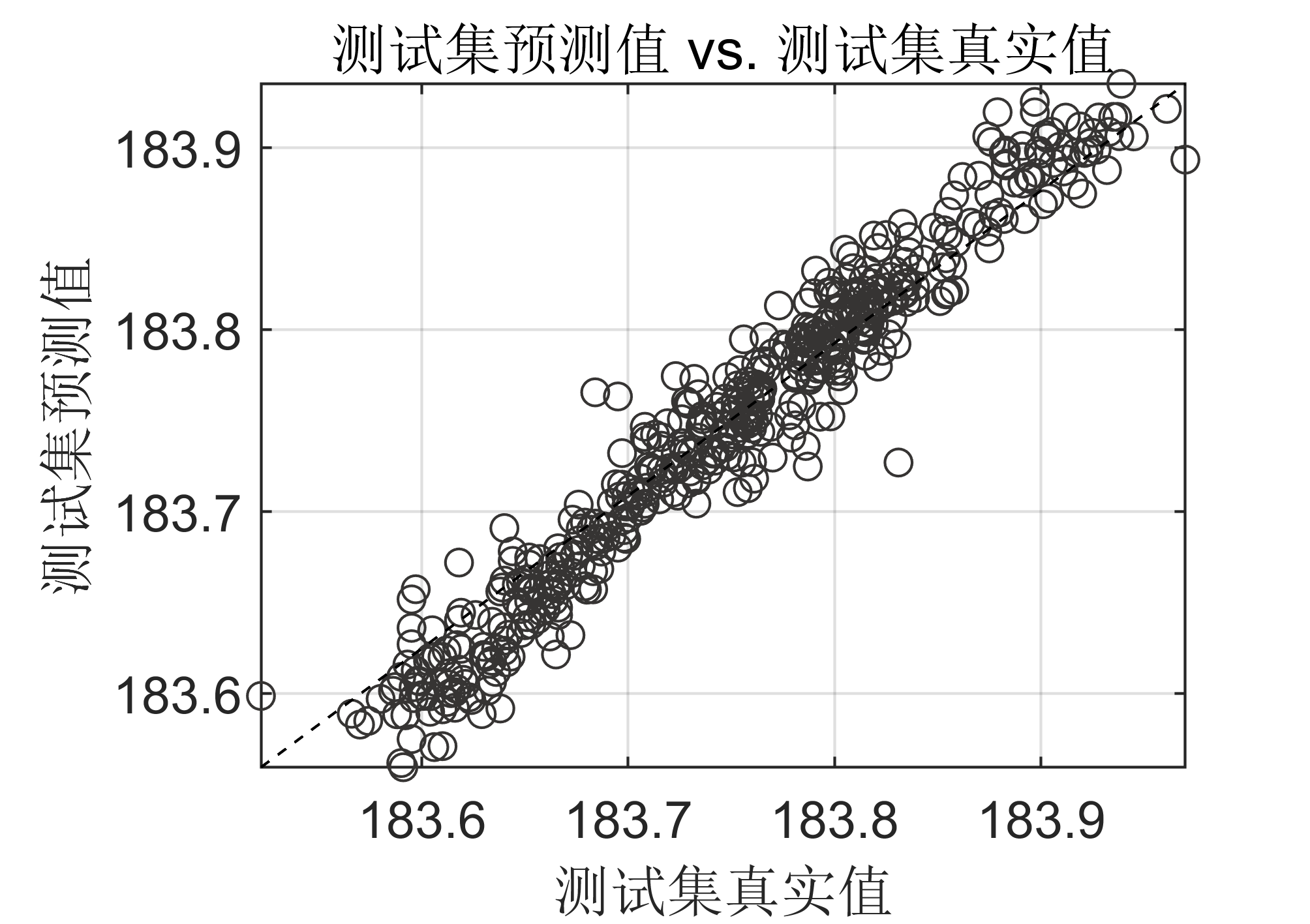
计算机网络——数据链路层(流量传输与可靠传输机制)
计算机网络——数据链路层(流量传输与可靠传输机制) 流量传输与可靠传输机制流量控制可靠传输机制 停止-等待协议无差错情况接收并检测到差错状态确认丢失或迟到状态 停等协议的效率分析后退N帧协议(Go-Back-N,简称GBN)…

PS从入门到精通视频各类教程整理全集,包含素材、作业等(9)复发
PS从入门到精通视频各类教程整理全集,包含素材、作业等
最新PS以及插件合集,可在我以往文章中找到
由于阿里云盘有分享次受限制和文件大小限制,今天先分享到这里,后续持续更新 第一课 ——第三课素材文件 https://www.alipan.c…
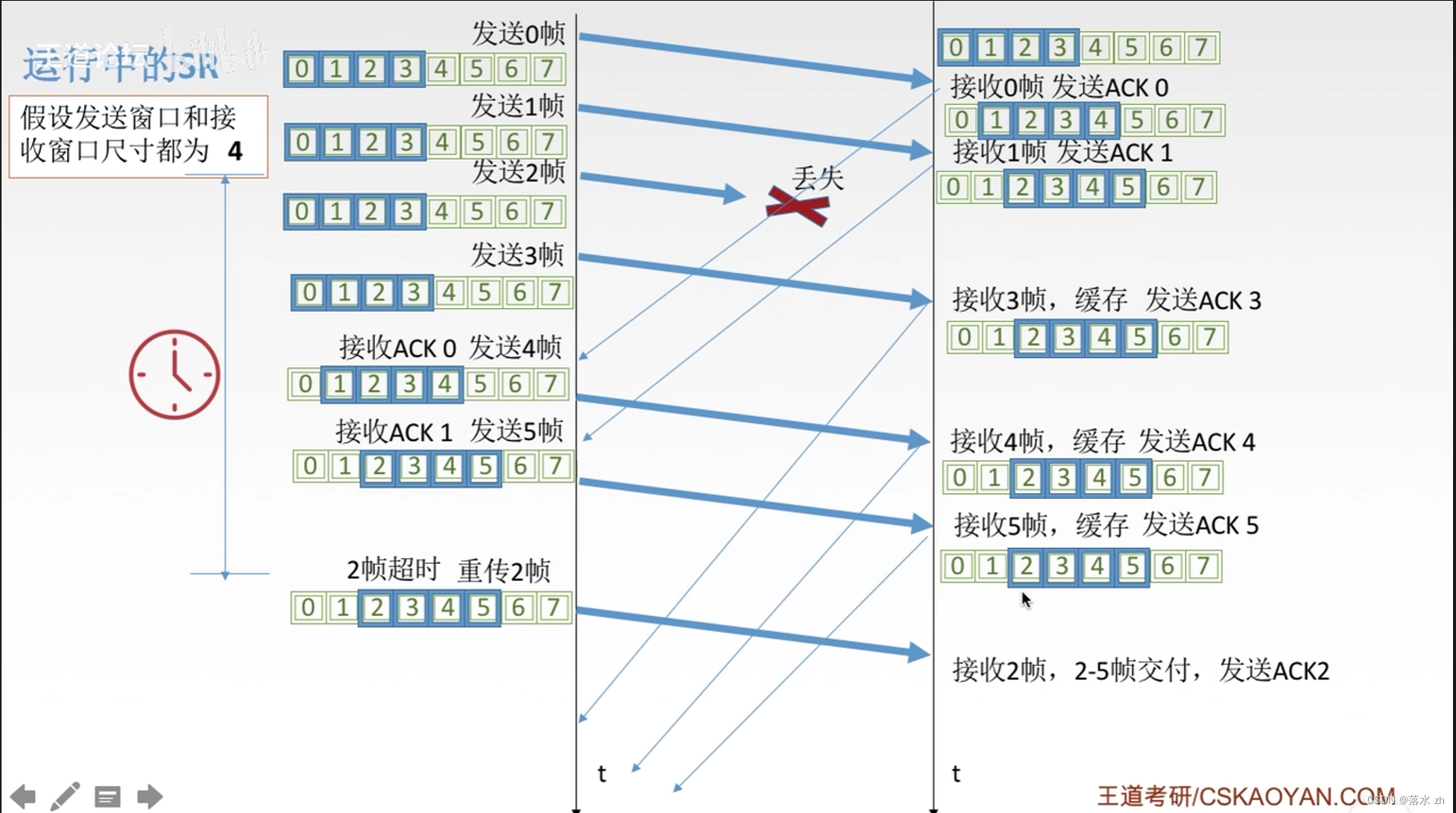
【数据结构与算法】力扣 203. 移除链表元素
题目描述
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。
示例 1: 输入: head [1,2,6,3,4,5,6], val 6
输出: [1,2,3,4,5]示例 2:
输…
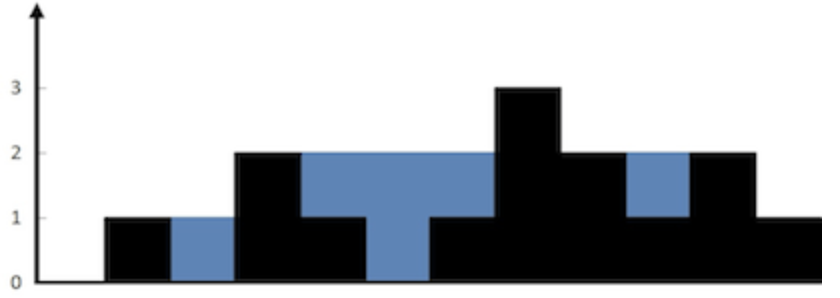
面试算法-140-接雨水
题目
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:
输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2…
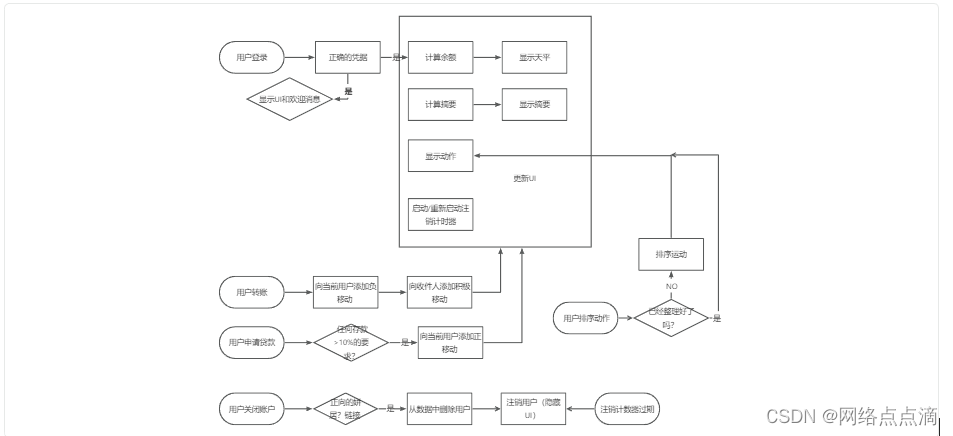
(一)小案例银行家应用程序-介绍
案例示例如下所示: 登录之后就会出现下面所示:
项目案例流程图如下
● 首先我们建立四个账号对象,用于登录
const account1 {owner: ItShare,movements: [200, 450, -400, 3000, -650, -130, 70, 1300],interestRate: 1.2, // %pin: 11…

MySQL故障排查与优化
一、MySQL故障排查
1.1 故障现象与解决方法
1.1.1 故障1
1.1.2 故障2
1.1.3 故障3
1.1.4 故障4
1.1.5 故障5
1.1.6 故障6
1.1.7 故障7
1.1.8 故障8
1.1.9 MySQL 主从故障排查
二、MySQL优化
2.1 硬件方面
2.2 查询优化 一、MySQL故障排查
1.1 故障现象与解决方…
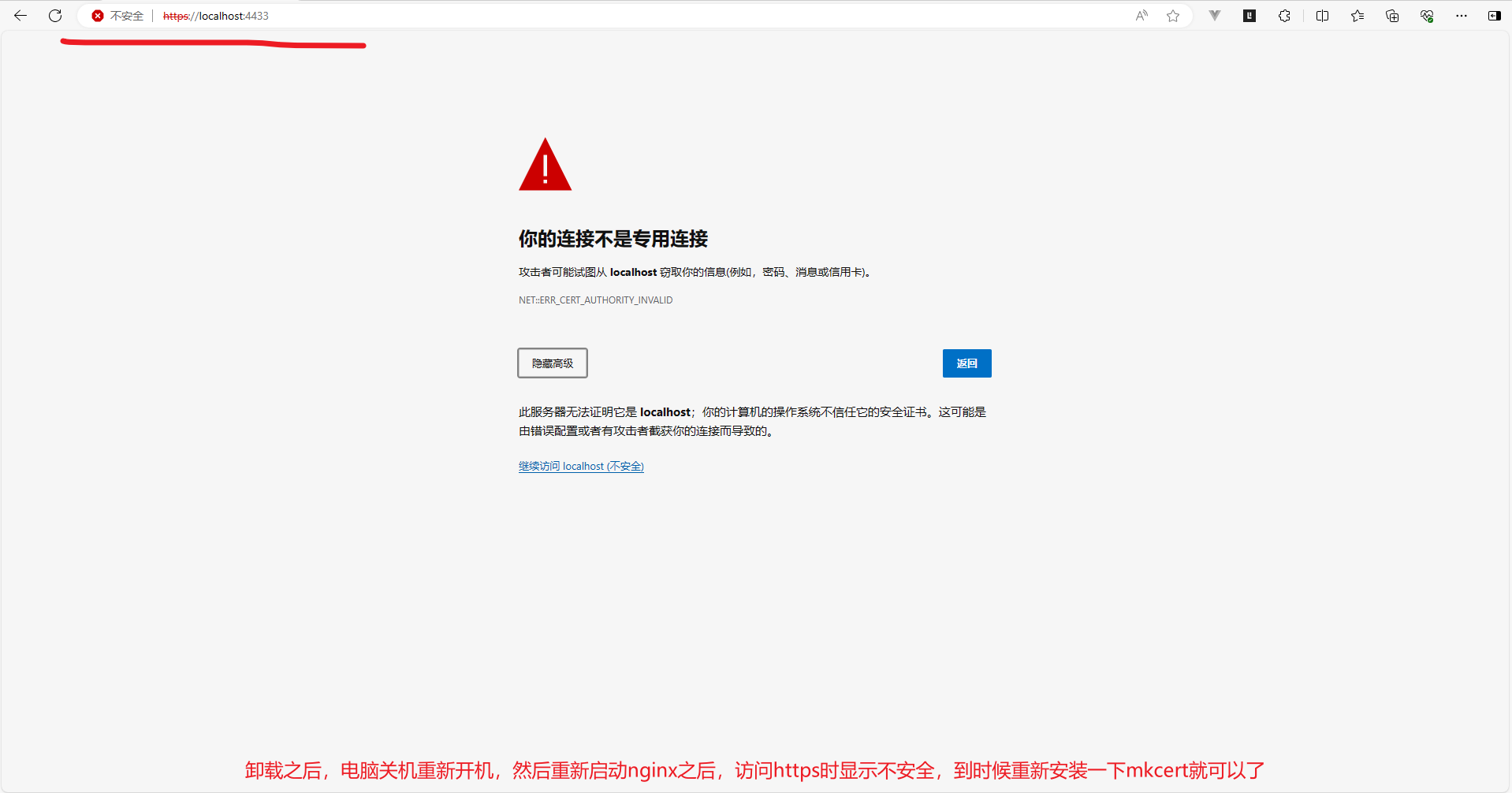
mkcert生成ssl证书+nginx部署局域网内的https服务访问问题
文章目录 mkcert生成ssl证书nginx部署局域网内的https服务访问问题1、下载mkcert查看自己的电脑是arm还是amd架构 2、安装mkcert3、测试mkcert是否安装成功4、查看CA证书存放位置5、打开windows的证书控制台6、生成自签证书,可供局域网内使用其他主机访问以下是nginx部署https服…
Prometheus+grafana环境搭建方法及流程两种方式(docker和源码包)(一)
1.选型对比
最近项目上有对项目服务及中间件的监控需求,要做实现方案调研,总结一下自己的成果,目前业界主流可选的方案有:
国外开源:
Prometheus:Prometheus - Monitoring system & time series dat…
基于Java课程选课系统设计与实现(源码+部署文档)
博主介绍: ✌至今服务客户已经1000、专注于Java技术领域、项目定制、技术答疑、开发工具、毕业项目实战 ✌ 🍅 文末获取源码联系 🍅 👇🏻 精彩专栏 推荐订阅 👇🏻 不然下次找不到 Java项目精品实…

Java设计模式:代理模式的静态和动态之分(八)
码到三十五 : 个人主页 心中有诗画,指尖舞代码,目光览世界,步履越千山,人间尽值得 ! 在软件设计中,代理模式是一种常用的设计模式,它为我们提供了一种方式来控制对原始对象的访问。在Java中&a…
最新文章
- 帝国cms做网站流程/百度推广账号注册
- 怎么做网站 白/百度推广运营这个工作好做吗
- 公司名注册查询网站/关键词网站排名查询
- 网站设置主页/百度客服电话号码
- 全屋定制设计网站推荐/网站seo推广seo教程
- 郑州网站建设维护/珠海网络推广公司
- GitCode 光引计划投稿|MilvusPlus:开启向量数据库新篇章
- OpenCV相机标定与3D重建(26)计算两个二维点集之间的部分仿射变换矩阵(2x3)函数 estimateAffinePartial2D()的使用
- Java设计模式 —— 【结构型模式】外观模式详解
- Gin-vue-admin(1):环境配置和安装
- SQL,生成指定时间间隔内的事件次序号
- 浅谈算法交易
推荐文章
- (15)衰落信道模型作用于信号是相乘还是卷积
- (C)一些题14
- (vue)获取对象的键遍历,同时循环el-tab页展示key及内容
- (二)什么是Vite——Vite 和 Webpack 区别(冷启动)
- (黑马出品_01)SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式
- (七)JavaWeb后端开发——Maven
- (三)Mysql 数据库系统全解析
- (小白教程)MPV.NET 播放器安装和添加Bilibili弹幕
- (学习笔记)Xposed模块编写(一)
- (学习笔记-进程管理)怎么避免死锁?
- (压缩PDF)Adobe Acrobat DC
- .locked勒索病毒详解 | 防御措施 | 恢复数据