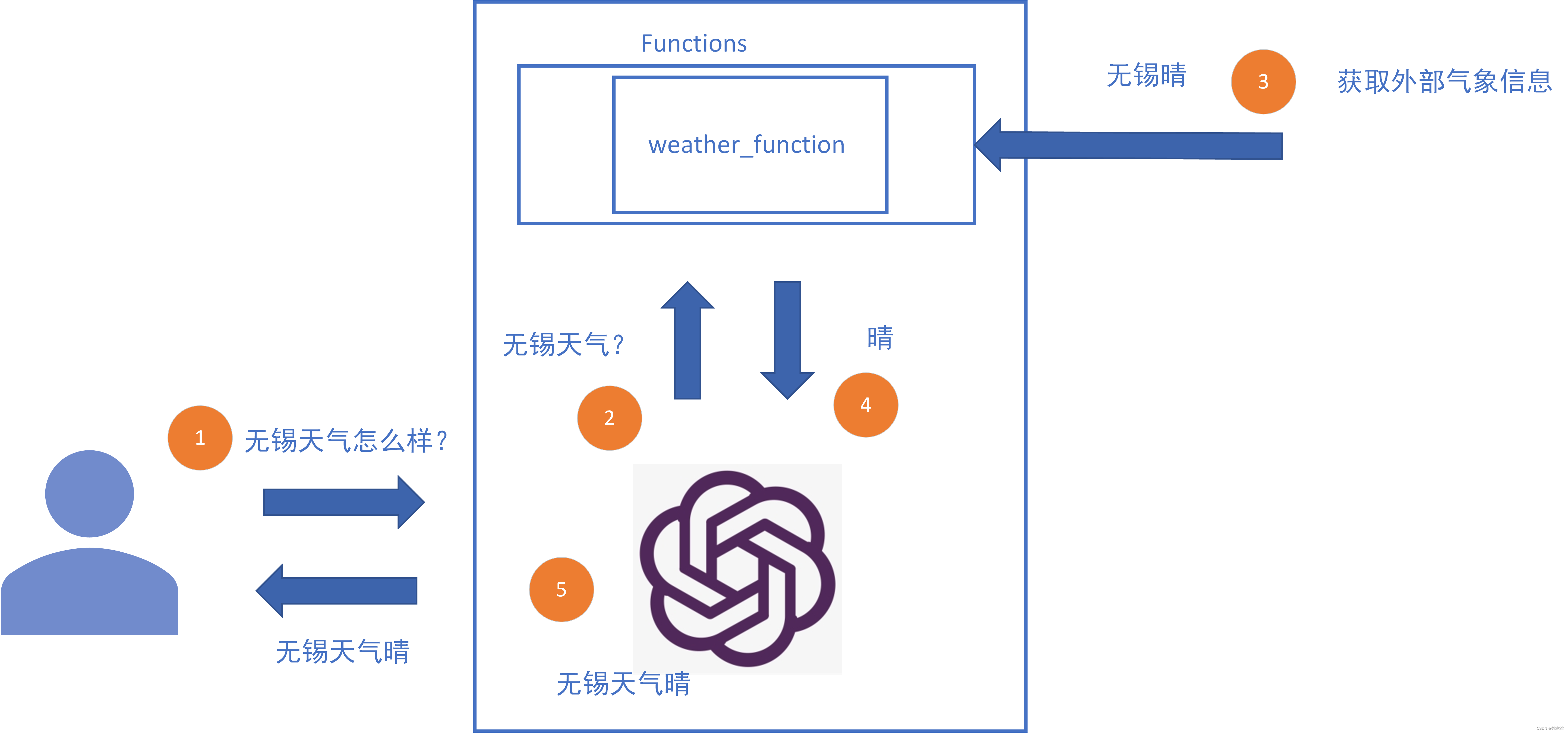
面向对象编程OOP
学习了结构体、枚举,它们可以包含自定义数据字段,也可以定义内部方法,它们提供了与对象相同的功能。
面向对象的四大特征:封装、继承、多态
通过pub标记为公有的结构体,在其他模块中可以访问使用这个结构体。但是对于结构体内部字段,如果不用pub,则仍是私有的,则可以通过定义公有方法,访问内部的属性。
src/user.rs 定义一个模块,定义了结构体model为公有,内部的属性是私有的。
pub struct model {name: String,age: i32,
}impl model {pub fn get_name(self) -> String {self.name}pub fn new(name: String) -> Self {// panic!("hello world");Self {name,age: 35,}}
}
在src/main.rs中引入使用,实例user要访问属性name不能直接访问,只能通过公有方法get_name()访问
mod user;
fn main() {let user = user::model::new(String::from("hboot"));println!("{}", user.get_name());
}
这就是 rust 封装的特点,继承是一个对象可以定义另一个对象中定义的元素,使得其获得父元素的数据和行为,而无需重复定义。
rust 继承的特点就是之前写过的 trait定义共同行为,rust 实现此 trait,从而有了 trait 上定义的方法。
因为继承导致的一些问题,子类总是共享其父类的所有特征。rust 选择了使用trait对象,而不是继承来处理这一行为。
使用trait解释面向对象的多态行为
rust 提出的 trait 概念,trait对通用行为进行抽象,然后通过impl为实现内部的方法,或采用默认实现,或覆盖默认实现。
多态是需要多个不同类型对象对同一行为做出不同响应。但是 rust 编译时运行检测,必须确定数据类型,那就只能使用运行时类型检测智能指针Box<T>声明类型。
GUI 图形界面库,元素Button、TextField都要实现draw方法,创建自定义内容并绘制到屏幕上
trait Draw {fn draw(&self);
}struct Screen {components: Vec<Box<dyn Draw>>,
}impl Screen {fn run(&self) {for component in self.components.iter() {component.draw();}}
}struct Button {width: u32,height: u32,label: String,
}impl Draw for Button {fn draw(&self) {// 内容绘制逻辑println!("button draw")}
}struct TextField {width: u32,height: u32,content: String,
}impl Draw for TextField {fn draw(&self) {// 内容绘制逻辑println!("textField draw")}
}
在主文件中调用初始化执行,实例化创建Button、TextField后,并不是直接把实例对象传递给Screen,因为这是具体类型,需要通过Box<T>包装转变为 trait 对象。screen.run()调用执行时,才知道具体传入的类型,并调用它实现的Drawtrait 里的方法。
fn main(){let button_primary = Button {width: 150,height: 150,label: String::from("确定"),};let text_field = TextField {width: 200,height: 200,content: String::from("hello rust, nice!"),};let screen = Screen {components: vec![Box::new(button_primary), Box::new(text_field)],};screen.run();
}
如果一个类型没有实现Drawtrait 对象,Screen在编译阶段就会给出错误提示。它不会去检测每个实例是否实现了draw()方法,它不需要关注具体的类型是什么。
由于不知道具体类型的定义实现,所以对于 trait,需要保证它的对象安全。
- 内部方法的返回值不能是
self - 不能有泛型类型的参数
比如非安全对象的 trait 示例,来自于 rust 标准库的Clonetrait
pub trait Clone {fn clone(&self) -> Self;
}
在很多上都有clone()方法,比如String、Vector等。它们都是类型自我调用获得一个实例类型对象,返回的Self类型确切的知道是哪一个类型。
而对于Screen,调用run()方法时,是不能知道具体的类型的。这样也就不能将Clonetrait 作为对象传递给Screen
impl Screen {fn run(&self) {for component in self.components.iter() {component.draw();}}
}
应该使用什么样的设计模式
设计模式的表现在于更好的组织代码,也可以帮我们规避掉一些逻辑问题。虽然对于同一个设计模式,可能每个人的理解不同,实现不同,但我们可以从中学习更好的设计实现。
对于一篇文章的发布,会经历草稿状态-审核中-审批完成-发布的流程,对于草稿、审核中状态时,内容不可见;只有在审核技术后内容才可见。
对于这样一个流程,我瞬间可想出的设计是,一个Blog结构,基本包含内容、状态;还有一个BlogStatus状态枚举。然后实现结构体内部方法,get_content()方法用于获取内容,初始状态为Draf,只有在状态变更为Done时,可以获取到文章内容。
创建blog.rs,以便使用结构体属性私有性特性。只能通过内部提供的方法更改状态。
pub enum BlogStatus {Draf,Pending,Done,
}pub struct Blog {content: String,status: BlogStatus,
}impl Blog {pub fn new(content: String) -> Blog {Blog {content,status: BlogStatus::Draf,}}pub fn get_content(&self) -> &str {// 需要根据状态判断// 只有审核完成的内容才可以查看match self.status {BlogStatus::Done => &self.content,_ => "",}}pub fn approval(&mut self) {self.status = BlogStatus::Pending;}pub fn publish(&mut self) {self.status = BlogStatus::Done;}
}生成文章blog,然后调用审批-发布过程,最后才能获取到文章内容。这里并没有写状态限制,也就是草稿状态不能调用publish()发布。
use blog::Blog;mod blog;
fn main(){let mut blog = Blog::new(String::from("hello rust,"));println!("{:?}", blog.get_content());blog.approval();println!("{:?}", blog.get_content());blog.publish();println!("{:?}", blog.get_content());
}
以上场景,我们可以采用状态驱动模式来设计,通过一系列的状态对象,来控制流程。
重新创建Blog结构体,现在不再有状态字段区分,将每一个状态作为结构体类型。草稿状态DraftBlog结构体
pub struct Blog {content: String,
}
pub struct DraftBlog {content: String,
}impl Blog {pub fn new(content: String) -> DraftBlog {DraftBlog { content }}pub fn get_content(&self) -> &str {&self.content}
}
impl DraftBlog {pub fn approval(self) -> PendingBlog {PendingBlog {content: self.content,}}
}
现在Blog创建不再返回自身实例,而是返回DraftBlog草稿实例,而草稿状态没有定义内部方法get_content(),所以此时无论怎么操作都取不到文章内容。
DraftBlog结构体提供了内部方法approval()发起审批,然后返回一个PendingBlog结构体实例,状态切换为审批中
pub struct PendingBlog {content: String,
}
impl PendingBlog {pub fn publish(self) -> Blog {Blog {content: self.content,}}
}
接着再由审批->发布,返回Blog的实例,这里不仅是状态的切换,还有数据所有权的转移。
fn main(){let blog = Blog::new(String::from("hello rust,hboot!"));let blog = blog.approval();let blog = blog.publish();println!("{}", blog.get_content());
}
模式与模式匹配
模式用于匹配类型中的结构,来控制程序的流程。
- 字面值
- 解构的数组、枚举、结构体、元组
- 变量
- 通配符
- 占位符
通过使用match表达式来匹配
fn main(){let name = Option::None;let name = match name {None => "hboot",Some(val) => val,};println!("{}", name);
}
match必须考虑到所有的情况,确保每一个值可以被捕获 处理。_可以匹配所有情况,用于兜底类似于 default 默认处理。
if let用于匹配指定的条件,不需要覆盖所有情况. let语句就是一种模式匹配,用于匹配后面的值;
fn main(){let default_name: Option<&str> = Some("admin");if let Some(name) = default_name {println!("hello! {}", name)};
}
while let用于条件匹配时,就一直执行。
fn main(){let mut num = 5;while num < 8 {println!("{}", num);num += 1;}
}
for循环,通过解构迭代器的枚举值
fn main(){let arr = [1, 2, 3];for (index, val) in arr.iter().enumerate() {println!("{}-{}", index, val);}
}
let语句,值解构。函数参数解构都是模式,匹配对应的参数值。
let (x,y) = (10,20);
对于可以匹配到值的模式称之为不可反驳的,而对于某些值的匹配会失败的模式称之为可反驳的。
函数参数、let 语句、for 循环都是不可反驳的,因为它们只有在值匹配时才有执行的意义;if let 、 while let都是可反驳的模式匹配。对于match分支匹配必须时可反驳的,这样才能到匹配打其他分支,只允许有一个不可反驳的分支,用于匹配其他未匹配到的模式处理。
模式语法
看看模式中所有有效的语法,以及讨论在什么时候使用。
最简单的就是匹配一个字面量,很明确就可以看出来匹配的分支是哪个。
let name = "hboot";
match name {"hboot" => println!("hello"),"admin" => println!("nice"),_ => println!("who"),
};
匹配命名变量,match内部是一个新的作用域,外部变量会被覆盖。name_other不同于外部同名变量,它会匹配到Some("hboot"),并将hboot复制给name_other。而最后的语句println!("{}", name_other)离开了match作用域,输出 test。
let name = Some("hboot");
let name_other = "test";
match name {Some("admin") => println!("nice"),Some(name_other) => println!("hello,{}", name_other),_ => println!("who"),
};println!("{}", name_other)
- 通过
|来进行多模式匹配。多个值匹配有相同的处理逻辑可以使用,name值为hboot\admin都会匹配第一个分支。
let name = "admin";
match name {"hboot" | "admin" => println!("hello,{}", name),_ => println!("who,{}", name),
};
- 通过
..=来匹配范围内的值。这个仅仅支持数字或 char 类型的值。
let num = 13;
match num {0..=20 => println!("青年"),21..=50 => println!("壮年"),_ => println!("老年"),
};
- 解构结构体、元组、枚举。可以对解构的值重新命名;可以通过解构指定的属性值来进行匹配,
struct User {name: String,age: i32,
}fn main(){let user = User {name: String::from("hboot"),age: 18,};let User {name: user_name,age,} = user;println!("{}-{}", user_name, age);
}
- 通过
_忽略值匹配,只匹配需要使用的值。age被忽略,则作用域内不存在age,不能访问。
let User {name: user_name,age:_,
} = user;println!("{}", user_name);
- 在变量前加
_,可以用来忽略未被使用的变量。这样 rust 编译器不会给出未使用警告。
fn main(){let _name = "hboot";
}
这在匹配中,非常有用,在我们不希望转移值的所有权时。
fn main(){let name = Some(String::from("hboot"));if let Some(_) = name {println!("不使用匹配值,忽略")}println!("外部可以继续使用变量,{:?}", name);
}
- 通过
..省略其他的匹配值,只匹配需要用到的值。避免产生歧义,期望匹配和期望忽略的值必须明确。
fn main(){let User {name: user_name, ..} = user;println!("{}", user_name);
}
- 匹配守卫,用于在模式匹配后继续使用
if条件处理
fn main(){let num = Some(10);match num {Some(age) if age < 20 => println!("青少年"),Some(age) if age < 50 => println!("壮年"),_ => println!("{:?}", num),}
}
@用于创建一个存放值的变量时测试其值是否在匹配模式。
fn main(){let user = User {name: String::from("admin"),age: 18,};match user {User {age: user_age @ 0..=20,..} => println!("{},青少年", user_age),User { name, age } => println!("who,{}-{}", name, age),}
}
高级特征
除了一些常用的语法之外,也有一些特定场景会很有用的功能。
不安全的 rust
rust 静态编译的特征保证了代码类型安全,从而保证了内存安全。在之前的智能指针中有提到运行时编译,不会强制检查类型安全,这个风险自行承担。除了代码层面的不安全之外,底层计算机硬件固有的不安全性,但是程序可能必须要进行一些不安全操作才能完成工作。
通过unsafe关键字来存放不安全的代码,一些不安全的操作
- 解引用裸指针
- 调用不安全的函数或方法
- 访问或修改可变静态变量
- 实现不安全 trait
- 访问
union的字段
在unsafe不安全代码块中,rust 不会关闭借用检查器或禁用其他安全检查,仍然可以获得某种程度上的代码安全。为了尽可能隔离不安全代码,可以将其抽象封装进安全代码中,对外提供 API
解引用裸指针
裸指针是类似于引用的新类型,*const T表示不可变*mut T表示可变。不可变的裸指针在解引用后不能直接赋值
不同于智能指针
- 允许忽略借用规则,可以同时拥有不可变和可变的指针,或多个指向相同位置的指针。
- 不保证指向有效的内存
- 允许为空
- 不能实现任何自动清理
通过as关键字强制转为对应的裸指针类型。这样创建的裸指针,可以很明确的知道指针是有效,所以没有使用unsafe
fn main() {let mut name = "hboot";let name_1 = &name as *const &str;let name_2 = &mut name as *mut &str;
}但我们解引用去访问其指向的数据时,无法保证有效,则必须放在unsafe块中。也就是创建不会有什么危险,使用时可能遇到问题。
unsafe {println!("{:?}", *name_1);
}
可以通过可变引用,解引用后变更值。需要注意潜在造成数据竞争的问题。
unsafe {*name_2 = "hello";println!("{:?}", *name_2);println!("{:?}", *name_1);
}
裸指针可以用于调用 C 代码接口;也可以用来构建检查器无法理解的安全抽象的代码。
调用不安全函数或方法
通过unsafe声明创建函数或方法,rust 不会去检查该函数调用时的限制、规则。需要我们自己清楚明白自己在做什么,调用该函数时可以满足函数的执行要求。
unsafe fn get_name() {}fn main(){unsafe {get_name();}
}
在不安全的函数中,可以不再使用unsafe块去调用不安全代码。
创建不安全代码的安全抽象
当然,安全的函数中,可以编写不安全的代码。通过指定位置,分割数组,并范围两个部分的引用
fn split_arr(arr: &mut [i32], t_index: usize) -> (&mut [i32], &mut [i32]) {(&mut arr[..t_index], &mut arr[t_index..])
}
split_arr会被检查器提示错误,因为我们借用了同一个 slice 两次,理论上是可以,但是 rust 不能理解,不能理解

通过使用不安全函数来处理这段逻辑,as_mut_ptr()方法获取 slice 的裸指针, slice::from_raw_parts_mut()函数,两个参数:一个裸指针和一个指定长度来创建一个 slice.
use std::slice;fn split_arr(arr: &mut [i32], t_index: usize) -> (&mut [i32], &mut [i32]) {let len = arr.len();let temp = arr.as_mut_ptr();unsafe {(slice::from_raw_parts_mut(temp, t_index),slice::from_raw_parts_mut(temp.add(t_index), len - t_index),)}
}
add()方法通过参数指定下标位置,获取另一个裸指针。调用测试
fn main(){let mut arr = [1, 2, 3, 4, 5];println!("{:?}", split_arr(&mut arr, 3));
}
使用 extern 函数调用外部代码
rust 可能需要与其他语言进行交互。可以通过extern关键字,创建与外部函数调用的接口
extern "C" {fn find(age: i32) -> i32;
}fn main(){unsafe { print!("{}", find(45)) }
}
在extern "C"列出能够调用的另一个语言中的外部函数。C部分定义了外部函数所使用的应用二进制接口(ABI)-- ABI 定义了如何在汇编语言层面调用函数。
通过extern来创建一个允许其他语言调用 rust 函数的接口。#[no_mangle]可以让 rust 忽略对此函数名称的编译;
#[no_mangle]
pub extern "C" fn find_name() {println!("hello,call this in other ")
}
访问或修改可变静态变量
全局变量也称为静态变量,通过static创建
static APP_NAME: &str = "rust-web";
静态变量与常量的区别:
- 静态变量总是有一个固定的内存地址,访问这个值总是访问同样的地址;
- 静态变量可以是可变的,访问和修改都是不安全的。
- 常量允许别赋值数据。
static mut APP_NAME: &str = "rust-web";fn main(){unsafe {println!("{}", APP_NAME);APP_NAME = "hboot";println!("{}", APP_NAME);}
}
全局可访问的可变数据,可能会造成数据竞争。尽量优先使用线程安全的智能指针 rust 自动化测试、迭代器与闭包、智能指针、无畏并发;
实现不安全 trait
一些trait存在某个方法包含编译器无法验证的不可变式时,是不安全的,通过usafe声明。此时实现该 trait 时,也需要标记为unsafe
访问union的字段
仅适用于unsafe的最后一个操作时访问union中的字段。union是一个和结构体类似的类型,它在一个实例中同时只能使用一个申明的字段。
union主要用于和 C 代码的联合体交互。
高级trait
关联类型用于在trait定义指定占位类型
关联类型将占位符类型与 trait 关联起来,在 trait 的方法中就可以使用这些占位符类型。
pub trait Iterator {type Item;fn next(&mut self) -> Option<Self::Item>;
}
实现 trait 时,需要指定Item的具体类型
struct User {name: String,age:i32
}
impl Iterator for User {type Item = String;fn next(&self) -> Option<Self::Item> {Some(self.name.clone())}
}fn main(){let user = User {name: String::from("hboot"),age: 30,};println!("{:?}", user.next());
}
关联类型看起来很像泛型,它允许指定一个函数而不指定其可以处理的类型。而它们的区别在于采用关联类型的 trait,在实现时,实现一次即可。
如果使用泛型,就需要多次为不同类型实现改 trait;且在调用时需要指定类型,以便调用具体哪一个类型的实现
pub trait Iterator<T> {fn next(&self) -> Option<T>;
}// String
impl Iterator<String> for User {fn next(&self) -> Option<String> {Some(self.name.clone())}
}
// i32
impl Iterator<i32> for User {fn next(&self) -> Option<i32> {Some(self.age)}
}
调用时,需要指定具体类型的实现
println!("{:?}", Iterator::<String>::next(&user));
println!("{:?}", Iterator::<i32>::next(&user))
默认泛型参数和运算符重载
通过为泛型类型参数指定一个默认的具体类型。在实现该 trait 时,传入的参数类型符合默认类型,则不需要再指定
trait PrintNum<Rhs = i32> {fn print(self, val: Rhs) -> Rhs;
}struct MyNum {}impl PrintNum for MyNum {fn print(self, val: i32) -> i32 {val}
}fn main(){let num = MyNum {};println!("{}", num.print(18));
}
Rhs = i32接受一个泛型参数,默认类型为i32.实现时实现 trait 方法的参数类型满足默认类型,则无需指定泛型类型.
当我们实现时不是默认的指定类型,则需要指定 trait 的泛型具体类型。
impl PrintNum<String> for MyNum {fn print(self, val: String) -> String {val}
}
有了默认类型在使用时都不需要指定,更容易使用;而且扩展类型也不会破坏现有代码。
限定语法:调用相同名称的方法
当我们实现多个 trait,它们有同名方法时,如何确定调用哪个,这里有两种情况。
实现的 trait 的方法第一个参数是self参数,则可以通过 self 的类型计算出调用哪一个。
trait Dog {fn speak(&self);
}trait Bird {fn speak(&self);
}struct Animal;impl Dog for Animal {fn speak(&self) {println!("dog");}
}
impl Bird for Animal {fn speak(&self) {println!("bird");}
}
类型Animal实现了两个 trait,它们都有speak方法。调用时需要指定调用哪一个
fn main(){let animal = Animal;Dog::speak(&animal);Bird::speak(&animal);
}
如果实现的 trait 中存在没有self参数的函数,那就必须使用完全限定语法
trait Dog {fn speak();
}trait Bird {fn speak();
}struct Animal;impl Dog for Animal {fn speak() {println!("dog");}
}
impl Bird for Animal {fn speak() {println!("bird");}
}
则在使用时,需要指定具体调用实现的哪一个 trait 的函数。
fn main(){<Animal as Dog>::speak();<Animal as Bird>::speak();
}
父级trait中依赖另一个trait,在子 trait 中则必须实现这个 trait
需要实现的 triat 如果依赖于另一个 trait,那么在实现这个 trait 时,要求类型实现了它依赖的那个 trait。
trait Animal {fn eat(&self) {println!("eat")}
}trait Dog: Animal {fn speak(&self) {println!("speak");self.eat();}
}struct Collie;impl Dog for Collie {}
traitDog依赖 traitAnimal,在类型Collie实现 traitDog时,会被需要实现 traitAnimal,否则不被编译通过
impl Animal for Collie {}fn main(){let dog = Collie;dog.speak();
}
newtype 模式在外部类型上实现外部 trait
孤儿规则 - 只要 trait 或类型对于当前 crate 是本地的话就可以在此类型上实现该 trait。
绕开这个规则的方法就是newtype模式。在一个元组结构体中带有一个字段希望实现外部 trait 的类型,那么这个元组结构体就是本地的,就可以在此之上实现 trait 了。
想在Vec<T>上实现Disaplay,它们都是定义在我们当前 crate 之外的类型
use std::fmt;struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper {fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {write!(f, "[{}]", self.0.join(","))}
}fn main(){let wrapper = Wrapper(vec![String::from("hello"), String::from("hboot")]);println!("{}", wrapper);
}
Wrapper是一个新类型,如果想要像Vec一样使用,则必须实现Vec<T>上的所有方法。可以手动实现一些方法,达到限制使用其他方法的目的。也可以通过实现Defer trait 返回其内部类型,
高级类型
为了类型安全和抽象使用newtype模式
newtype模式的数据类型封装一些实现细节,
- 确保静态值的清楚表达而不被混淆。
- 隐藏其内部的泛型类型;
- 暴露出使用内部私有 API 不同的公有 API
use std::ops::Add;struct Millimeters(u32);
struct Meters(u32);impl Add<Meters> for Millimeters {type Output = Millimeters;fn add(self, rhs: Meters) -> Self::Output {Millimeters(self.0 + (rhs.0 * 1000))}
}
类型别名创建类型同义词
通过type关键字重新命名现有类型。可以像类型一样使用
type My32 = i32;
let age: My32 = 48;println!("{}", age + 48);
类型别名用于减少代码重复。在一些函数签名或类型注解中出现的复杂表达,在多个地方使用时可以使用类型别名。
type Thunk = Box<dyn Fn() + Send + 'static>;fn test(f: Thunk) {f();
}fn main(){let f: Thunk = Box::new(|| println!("hboot"));test(f);
}
从不返回的never type
这是一个特殊的类型!表示,在函数从不返回值的时候用作返回值。不能用来创建该类型的值
continue不会返回一个值,它用于返回上层循环;panic!也不产生值,他会终止程序。他们是!类型。
fn test_never() -> ! {panic!("err")
}
动态类型大小和Sizedtrait
动态类型是在运行时才知道类型大小,被称为DST或unsized types。
str是一个动态类型,但是我们不能直接使用它来创建变量。rust 需要知道为特定类型的值需要分配多少内存,同一类型的值必须使用相同大小的内存。
常使用的&str有两个值,地址和长度。对于动态大小类型的值,意味着必须将其置于某种指针之后。
对于动态大小类型,之前已经有Box<str>或Rc<str>.还可以通过一个 trait 用于另一个 trait ,将它们置于指针之后,比如&dyn Trait 、Box<dyn Trait>
泛型函数默认只能用于在编译时已知大小的类型,可以通过?放宽这个限制
fn test_trait<T>(t: T) {// ...
}
此时,由于未知大小的类型,所以需要将参数t类型置于某指针之后&T
fn test_trait<T: ?Sized>(t: &T) {// ...
}
高级函数与闭包
函数指针
通过fn函数指针,允许我们使用函数作为另一个函数的参数。
fn main() {println!("{}", call_repeat(add_one, 30));
}fn add_one(val: i32) -> i32 {val + 1
}
fn call_repeat(add: fn(i32) -> i32, target: i32) -> i32 {add(target) + add(target)
}不同于闭包,fn是一个类型而不是一个 trait。直接指定fn作为一个参数而不是声明一个带有Fn作为 trait bounds 的参数。
函数指针实现了所有三个闭包 traitFn\FnMut\FnOnce.所以可以在期望调用闭包的函数中传递函数指针作为参数。
let num = [1, 2, 3];
let num_to_str: Vec<String> = num.iter().map(|val| val.to_string()).collect();
可以直接修改map的传参,改为函数指针。使用了完全限定语法ToString::to_string,因为存在多个实现了to_string函数的库。
let num_to_str: Vec<String> = num.iter().map(ToString::to_string).collect();
一个只期望接受fn而不是接受闭包的情况是在与不存在闭包的外部代码交互时,比如和 C 语言代码交互。
也可以指定构造函数作为接受闭包的方法的参数。
#[derive(Debug)]
struct Age(u32);fn main(){let list_of_age: Vec<Age> = (5u32..20).map(Age).collect();
}
返回闭包
闭包表现为 trait,所以它不能直接被返回。对于大多数需要返回 trait 的情况下,可以通过实现期望返回的 trait 的具体类型来代替函数返回值。
但是这不能用于闭包,因为闭包没有可以返回的具体类型。
通过函数指针fn来尝试作为闭包的返回值类型。
fn returns_closure() -> dyn Fn(i32) -> i32 {|val| val + 1
}
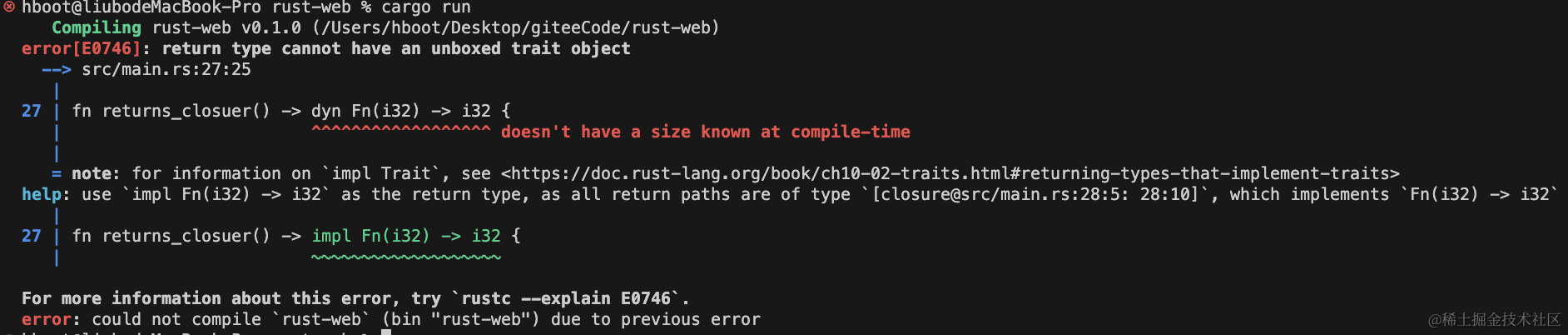
错误信息提示在编译时未知闭包大小。可以通过智能指针Box处理未知大小;
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {Box::new(|val| val + 1)
}
也可以通过impl trait的方式,就可以返回实现这个 trait 的类型值。
fn returns_closure() -> impl Fn(i32) -> i32 {|val| val + 1
}宏
一直有使用的println!宏。它表示了一系列功能,宏包括了使用macro_rules!声明宏和三种过程式宏。
三种过程式宏
- 自定义
#[derive]在结构体和枚举上通过 derive 属性添加代码。 - 类属性宏可以定义任意项的自定义属性。
- 类函数宏可以用于作为参数传递的 token
宏和函数的区别,它是一种为写其他代码而写代码的方式;它可以减少大量编写和维护的代码;可以接受不同数量的参数;宏可以给定类型上实现 trait;调用宏之前必须定义它或引入作用域。
macro_rules!声明宏
macro_rules!声明宏类似于match表达式,会根据模式匹配执行相关代码。
一个简易版的Vec!实现,#[macro_export]表明该宏可被引入作用域,可被使用。($($x:expr),*)是一个模式,匹配成功后会执行其后面的代码。
#[macro_export]
macro_rules! Vec {($($x:expr),*) => {{let mut temp_vec = Vec::new();$(temp_vec.push($x);)*temp_vec}};
}
这里的模式和上面的模式语法不同,这里的模式匹配的是 rust 的代码。$匹配该模式的 rust 代码,$x匹配 rust 的任意表达式。之后的 *表示匹配零个或多个之前的模式
let num = vec![1, 2, 3];
这里会匹配执行三次,并最终返回temp_vec
通过derive生成代码的过程宏
过程宏更像是一个函数,它可以接受 rust 代码作为参数,然后在这些代码上进行操作后产生一些其他代码。
这有点像 JS 里的高级函数,接受一个函数作为参数,增加一些逻辑代码,比如属性、方法,最后返回这个函数。
通过自定义过程宏来简写 trait 的实现过程
trait Log {fn print();
}struct Info;impl Log for Info {fn print() {println!("log-info");}
}
如果有很多个结构体需要实现Logtrait,就需要编写大量的重复实现过程。通过过程式宏可以节省这些工作量。
由于过程式宏需要在自己的 crate 中,需要重新新建一个 lib 库log_macro,并包含一个log_macro_derive过程式宏的包。
这两个包是紧密关联的,所以在同目录下创建,
$> cargo new log_macro --lib$> cd log_macro
$> cargo new log_macro_derive --lib
在log_macro需要编写功能实现的类型,在src/main.rs中定义
pub trait LogMacro {fn log_macro();
}
然后在log_macro_derive处理接收到的 rust 代码,为传入的类型实现该 trait 功能,在log_macro_derive/src/main.rs
use proc_macro::TokenStream;
use quote::quote;
use syn;#[proc_macro_derive(LogMacro)]
pub fn log_macro_derive(input: TokenStream) -> TokenStream {let ast = syn::parse(input).unwrap();impl_log_macro(&ast)
}对于log_macro_derive需要三个依赖proc_macro\quote\syn,proc_macro是 rust 自带的,用于读取和操作 rust 代码,所以无需引入;其他两个需要手动安装,syn将字符串的 rust 代码解析成可操作的数据接口,quote将 syn 解析的数据结构转为 rust 代码。
在log_macro_derive/Cargo.toml中
[lib]
proc-macro = true[dependencies]
syn = "1.0"
quote = "1.0"
通过proc_macro_derive注解,指定 trait 名称,表示将为输入代码实现此 trait。然后就是通过 syn 去解析代码,调用了impl_log_macro方法去实现具体的逻辑
fn impl_log_macro(ast: &syn::DeriveInput) -> TokenStream {let name = &ast.ident;let gen = quote! {impl LogMacro for #name{fn log_macro(){println!("hello, Macro! target is {}",stringify!(#name));}}};gen.into()
}
通过打印来看下解析后的数据结构:
ident是注解时的结构体名称,quote!编译代码,其后面模板代码,通过#name获取变量name的值。最后通过.into()方法返回 rust 编译器期望的类型TokenStream.通过cargo build检测项目是可以正常执行的。
完成了宏功能,将其引入测试。在原项目中rust-web中引入依赖
[dependencies]
log_macro={path="../rust-lib/log_macro"}
log_macro_derive={path="../rust-lib/log_macro/log_macro_derive"}
本地引入是项目的相对路径,现在可用注解来实现功能;需要同时引入log_macro、log_macro_derive,
为了方便也可以在
log_macro中将log_macro_derive作为依赖,并重新导出。
use log_macro::LogMacro;
use log_macro_derive::LogMacro;#[derive(LogMacro)]
struct Blog;#[derive(LogMacro)]
struct Log;fn main() {Blog::log_macro();Log::log_macro();
}执行cargo run可以看到打印输出。

对于 vs code 出现的rust-analyzer[unresolved-proc-macro]错误提示,这并不会影响程序执行,只是由于本地默认禁用了派生宏。通过 rust-analyzer 配置来取消提示
{"rust-analyzer.diagnostics.disabled": ["unresolved-proc-macro"]
}
属性宏添加新属性
derive派生宏可以生成代码,属性宏则可以添加新的属性,它不仅可以用于结构体和枚举,还可以用于其他项,比如函数。
新增一个 cratename_macro,为函数添加一个新的属性name。通过proc_macro_attribute注解,该宏可以作为属性使用。
use proc_macro::TokenStream;
use quote::quote;
use syn::{parse_macro_input, AttributeArgs, ItemFn};#[proc_macro_attribute]
pub fn name_macro(attr: TokenStream, item: TokenStream) -> TokenStream {let name = parse_macro_input!(attr as AttributeArgs).pop().unwrap();let name_value = match name {syn::NestedMeta::Lit(syn::Lit::Str(name)) => name.value(),_ => return quote! { compile_error!("Expected a string literal") }.into(),};let input = parse_macro_input!(item as ItemFn);let fn_name = &input.sig.ident;let gen = quote! {#input#[doc(hidden)]#[allow(non_upper_case_globals)]pub mod #fn_name {pub const name: &str = #name_value;}};gen.into()
}
首先解析宏参数attr取出最后一个值为字符串值,不是则会抛出一个编译错误。然后就是将解析到的name_value作为函数的属性name的值。
这个属性宏的依赖:
[lib]
proc_macro = true[dependencies]
proc-macro2 = "1.0.79"
quote = "1.0.35"
syn = { version = "1.0.109", features = ["full"] }然后在我们的项目rust-web中引入依赖
[dependencies]
name_macro = { path = "../rust-web-lib/name_macro" }
因为是本地开发测试的,引入时要注意路径。
use name_macro::name_macro;#[name_macro("hboot")]
fn user() {// 这里是函数体println!("{}", user::name)
}fn main() {user();println!("{}", user::name)
}在自定义函数user上使用定义的属性宏name_macro,首先要记得use name_macro::name_macro;导入属性宏。然后再使用,可以通过user::name访问属性。
执行测试打印:

类函数宏
像函数一样可以调用,类似于macro_rules!,比函数更灵活。可以接受未知数量的参数,可获取到TokenStream参数来操作 rust 代码,实现复杂的代码功能。
实现一个数值大小的类函数宏,同样的需要创建一个新的 crate。名称为compare_max:
use proc_macro::TokenStream;
use quote::quote;
use syn::Expr;#[proc_macro]
pub fn compare_max(input: TokenStream) -> TokenStream {let input = input.to_string();let mut iter = input.split(',');let left = iter.next().unwrap().trim();let right = iter.next().unwrap().trim();let left_expr: Expr = syn::parse_str(left).unwrap();let right_expr: Expr = syn::parse_str(right).unwrap();let gen = quote! {{std::cmp::max(#left_expr, #right_expr)}};gen.into()
}这里仅解析前两个参数,使用系统std::cmp::max函数来比较两个值的大小并返回。
然后在我们的项目rust-web中引入自定义 crate,导入测试
use compare_max::compare_max;
fn main() {println!("{}", compare_max!(34, 12));
}运行结果,可以看到打印输出到了34.