原文地址:Compress GPT-4 and Claude prompts with LLMLingua-2
2024 年 4 月 1 日
向大型语言模型(LLM)发送的提示长度越短,推理速度就会越快,成本也会越低。因此,提示压缩已经成为LLM研究的热门领域。
在最新的一篇论文中,清华大学和微软的研究人员介绍了一种新的与任务无关的提示压缩技术——LLMLingua-2。LLMLingua-2比其他提示压缩方法更快、更高效,且需要的计算资源更少。对于涉及冗长提示的LLM应用来说,它可以成为一个很好的工具,压缩可以节省大量成本并改善用户体验。

任务相关的和任务无关的提示压缩
诸如思维链(CoT)推理、上下文学习和检索增强生成(RAG)等技术使LLM能够处理复杂的任务和未在训练数据中包含的知识。
然而,冗长提示的好处是以增加计算和财务需求为代价的。在某些LLM中,更长的提示可能会降低模型处理上下文信息的能力的准确性。
提示压缩通过缩短原始文本同时保留必要信息来解决这些问题。提示压缩的基本假设是,自然语言包含冗余,这些冗余对人类理解可能有用,但对LLM来说则不必要。
提示压缩可以分为“任务相关”和“任务无关”两种方法。任务相关的压缩方法会根据下游任务或当前查询来移除提示中的令牌。一种流行的方法是LongLLMLingua,它采用一种问题相关的多步骤方法,估计令牌的信息熵并移除冗余部分。其他方法使用强化学习来训练一个模型,基于下游任务提供的奖励信号来压缩提示。任务相关压缩方法的权衡之处在于它们在其他任务上的泛化能力有限。
另一方面,任务无关的方法在压缩提示时不考虑具体任务,使其更适用于更广泛的应用和黑盒LLM。一些任务无关的方法包括LLMLingua和Selective-Context。这些方法使用因果小型语言模型(SLM),如Llama-7B,来评估令牌或词汇单元的信息熵,并移除那些不增加有意义信息的部分。
LLMLingua-2是由原始LLMLingua的作者开发的,是一种任务无关的提示压缩技术。
LLMLingua-2的工作原理
当前的任务无关压缩方法存在一些局限性,这促使研究人员创建了LLMLingua的继任者。
“信息熵可能是一个次优的压缩指标,因为(一)它与提示压缩目标不一致;(二)它只利用单向上下文,可能无法捕获提示压缩所需的所有必要信息。”微软高级研究员、论文合著者钱慧武(Qianhui Wu)表示。
LLMLingua-2将提示压缩重新定义为分类任务,即确定每个令牌是否应该保留或丢弃。它利用这种任务定义来创建提示压缩训练数据集。然后,它使用数据集来训练一个用于压缩任务的轻量级双向转换器编码器模型。
“通过这种方式,它可以从完整的双向上下文中捕获提示压缩所需的所有必要信息,并保证压缩后的提示与原始提示保持一致。”
LLMLingua-2具有几个关键优势。首先,使用双向编码器可以确保捕获提示压缩所需的所有必要信息。其次,由于它使用较小的转换器模型来学习压缩目标,因此具有显著较低的延迟。第三,它的设计旨在保持对原始提示的忠实度,避免幻觉。
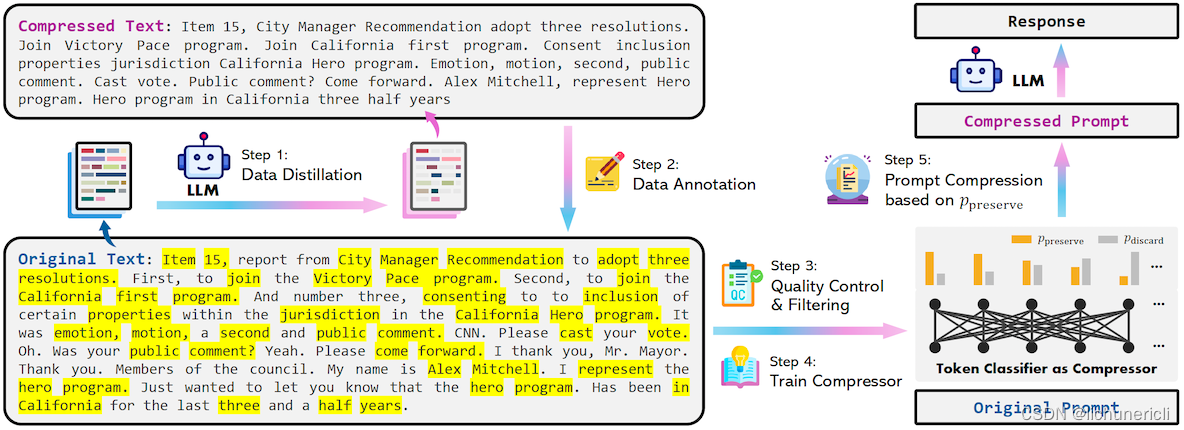
训练压缩模型
为了生成用于训练提示压缩模型的数据集,研究人员使用数据蒸馏程序从强大的LLM中提取知识。他们向GPT-4提供提示,并指示它在保留必要信息并避免幻觉的同时减少令牌。
在获得原始文本及其压缩版本的配对后,他们为每个原始文本中的令牌分配一个二进制标签,以确定在压缩后是否应保留或丢弃它。研究人员使用MeetingBank数据集创建了训练示例。
然后,他们在数据集上训练了xlm-roberta-large和multilingual-BERT转换器模型的略微修改版本,以将令牌分类为“保留”或“丢弃”。基于BERT的模型的优势在于,它们学习双向特征,而不是仅具有先前令牌知识的自回归解码器模型。这允许压缩模型学习更丰富的相关性,从而实现更好的压缩。
“在推理过程中,我们根据分类模型计算的概率来确定是否保留或丢弃原始提示中的每个令牌。”研究人员写道。

LLMLingua-2 蒸馏提示
LLMLingua-2的实际应用
研究人员在MeetingBank数据集以及几个领域外数据集(如LongBench、ZeroScrolls、GSM8K和Big Bench Hard)上测试了压缩模型。他们使用GPT-3.5-Turbo作为目标模型。但压缩模型也可以与前沿模型(如GPT-4和Claude 3)一起使用。他们还将LLMLingua-2的压缩、速度和准确性与其他方法以及原始提示进行了比较。
他们的研究结果表明,尽管LLMLingua-2的体积较小,但其压缩性能优于其他任务无关基线,并从GPT-3.5-Turbo到Mistral-7B具有良好的泛化能力。
LLM-Lingua-2实现了2-5倍的压缩率,比现有的提示压缩方法快3-6倍。这意味着,当用于需要长系统和上下文提示的应用程序时,它可以节省大量成本。LLMLingua-2还将延迟降低了1.6-2.9倍,并可将GPU内存成本降低8倍。
有趣的是,当使用Mistral-7B作为目标LLM时,研究人员发现LLMLingua-2的性能甚至优于原始提示。“我们推测,Mistral-7B可能在管理长上下文方面不如GPT-3.5-Turbo擅长。我们的方法通过提供具有更高信息密度的较短提示,有效地提高了Mistral-7B的最终推理性能。”研究人员在论文中写道。
“LLMLingua-2是一种与任务无关的提示压缩方法。”吴说。“这意味着,每当您遇到过长的上下文时,都可以使用LLMLingua-2将其压缩为较短的上下文,以适应有限的上下文窗口,减少财务成本(因为OpenAI根据令牌向用户收费),并减少LLM的推理时间。”
然而,与LongLLMlingua等任务感知压缩方法相比,LLMLingua-2在特定任务上表现不佳。
“我们将这种性能差距归因于[任务感知方法]从问题中获取的额外信息。”研究人员写道。“但是,我们的模型的与任务无关特性使其成为一种高效且具有良好泛化能力的选择,可以部署到不同场景中。”