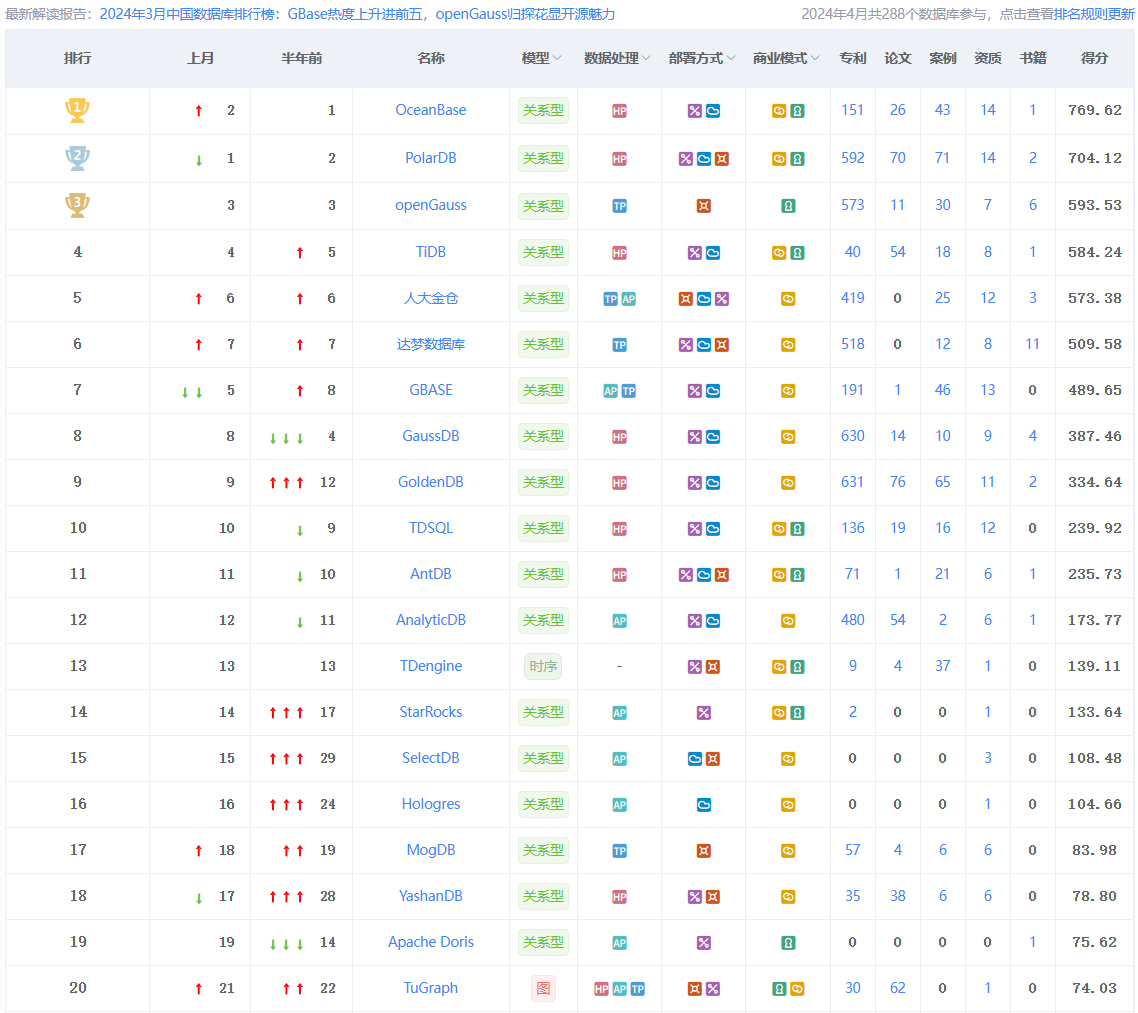
过滤顺序指的是mysql的逻辑执行顺序,个人觉得我们可以按照执行顺序来写select查询语句。
目录
- 一、执行顺序
- 二、小tips
- 三、案例
- 第一轮查询:统计每个num的出现次数
- 第二轮查询:计算**最多次数**
- 第三轮查询:找到所有出现次数为最多次数的所有数字,并找到这些数字中的最大值
- 计算结果展示:
- 补充说明
- 四、结语
一、执行顺序
-
FROM子句
这是执行的第一步,数据库系统读取指定的表和视图,这是后续所有操作的基础。 -
JOIN
如果涉及多个表,则基于JOIN条件,将表中的行组合起来。 -
WHERE子句:对行的过滤
接下来,数据库系统会过滤掉不符合WHERE条件的行。这是在聚集函数(如COUNT、SUM等)应用之前进行的,因此只作用于原始数据。
WHERE子句后面不能直接接聚合函数(如COUNT(),MAX(),SUM()等)。WHERE子句用于指定从基础数据表中选择哪些行的标准,这些标准必须是能够对每一行单独评估的布尔表达式。由于聚合函数是在行群(group)上操作的,而不是单独的行上,所以它们不能直接在WHERE子句中使用。
总之,是对原始数据的每一行进行操作!!!没法联系多行进行判断,所以不能用聚集函数!!!!! -
GROUP BY子句
将之前得到的结果集按照指定的列值进行分组,为聚集函数(如COUNT、SUM等)的应用做准备。 -
HAVING子句:对组的过滤
与WHERE类似,但它是在聚集函数应用后对分组的结果进行过滤,相比于where,涉及到了多行,所以可以使用聚集函数。
可以简单理解成:where过滤掉行,having过滤掉组,均是接的布尔表达式。
没有GROUP BY的上下文中单独使用HAVING是不常见的,而且可能不被所有SQL数据库支持。 -
SELECT
选取指定的列。
如果使用了聚集函数,那么非聚集列必须出现在GROUP BY子句中,除非它们在聚集函数内部。比如使用了select max(num),它将从每一组中找到一个最大的num,而不是整张表中找
关于增加一列:根据条件显示内容casewhen 条件1(布尔表达式) then 满足条件1要展示的结果when 条件2(布尔表达式) then 不满足条件1满足条件2的结果else 都不满足的结果 end as 别名
二、小tips
-
子查询作为数据源,必须有别名,如果是在where、having语句中,则不拥有。
-
聚集函数嵌套的问题:
不允许直接嵌套聚合函数:聚合函数(如AVG(),SUM(),MAX()等)通常不允许直接嵌套使用。也就是说,一个聚合函数的结果不能直接成为另一个聚合函数的输入,如MAX(COUNT(column))是不允许的。
允许聚合结果被其他函数处理:聚合函数的结果可以被其他非聚合函数处理,如ROUND(AVG(column), 2)是允许的。这是因为ROUND函数在这里不是在进行聚合操作,而是在对聚合操作的单一结果值进行格式化或转换。
三、案例
假设目前数据库有一个表nums:
CREATE table nums(num INTEGER
);
插入样本数据:
insert into nums(num)
values(8),(8),(3),(3),(1),(2),(5),(6);
任务:找到nums表中出现次数最多的数字,如有多个,展示最大的结果。
下面开始按照过滤顺序具体实现:
我们将任务拆分为三轮:
第一轮:统计每个num的出现次数
第二轮:计算最多次数
第三轮:找到所有出现次数为最多次数的所有数字,并找到这些数字中的最大值
在每一轮中,将按照执行顺序一步步书写语句:
- FROM
- JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- LIMIT / OFFSET
强调一下,每一步操作都是基于前面执行的结果再操作的,比如where就只会对原始from和join后的结果对行进行过滤,不会对group by的结果做过滤,这一点很重要!!!
第一轮查询:统计每个num的出现次数
- FROM:找到表nums
from nums
- JOIN
不需要涉及多个表,略。 - WHERE
不需要过滤掉任何行,所以略。 - GROUP BY
需要找到每个数字出现的次数,自然需要分组,根据num分组:
from numsgroup by num
- HAVING
不需要略掉任何组,所以略。 - SELECT
需要得到统计结果:
select count(num) as frequencyfrom numsgroup by num
这里起一个别名,因为后续查询里,这个数字需要被用到,所以记得取别名
7. DISTINCT
略
8. ORDER BY
略
9. LIMIT / OFFSET
略
第二轮查询:计算最多次数
- FROM
这里需要找到出现次数中的最大值,所以第一轮查询的结果,将作为这一轮查询的数据源。
from(select count(num) as frequencyfrom numsgroup by num) table_temp
根据前面小tips的第一条,子查询的结果如果是作为数据源,那么一定要取别名,否则会报错,别名前面可加as,也可以不加。
2. JOIN
不需要,略。
3. WHERE
虽然需要找到最高次数,看似可以在这一步对行级过滤,但是where对每一行操作时,只能看到当前行的数据,所以它不能使用max这种聚集函数得到全表的最大值,所以这一步略。
4. GROUP BY
不需要再分组了,略。
5. HAVING
没有分组了,所以它略。
6. SELECT
找到最大值,所以增加select max(frequency)
select max(frequency)from(select count(num) as frequencyfrom numsgroup by num) as table_temp
- DISTINCT
略 - ORDER BY
略 - LIMIT / OFFSET
略
第三轮查询:找到所有出现次数为最多次数的所有数字,并找到这些数字中的最大值
- FROM
是对全表进行查询,找到出现次数为最大次数的结果,所以数据源是全表。
from nums
- JOIN
略。 - WHERE
无法对原始数据直接做过滤,因为此时还不能从第一步得到的结果中知道每个数字的次数,所以略。 - GROUP BY
为得到次数,再一次做分组
from nums
group by num
- HAVING
对每一组做过滤,保留次数等于最大次数的组,判断的条件是count(num)=最大次数,最大次数为第二轮查询的结果,所以将结果嵌套进来:
from nums
group by num
having count(num)=(
select max(frequency)from(select count(num) as frequencyfrom numsgroup by num) as table_temp
)
- SELECT
目前得到了多个组结果,每个组的数字都满足出现次数等于最大次数,将数字选出来,即使用select num
select num
from nums
group by num
having count(num)=(
select max(frequency)from(select count(num) as frequencyfrom numsgroup by num) as table_temp
)
- DISTINCT
不需要去重,略。 - ORDER BY
为了找到最大值的结果,对目前的num结果降序,增加order by num desc
select num
from nums
group by num
having count(num)=(
select max(frequency)from(select count(num) as frequencyfrom numsgroup by num) as table_temp
)
order by num desc
- LIMIT / OFFSET
选择排序第一的结果limit 1,它是最大值
select num
from nums
group by num
having count(num)=(
select max(frequency)from(select count(num) as frequencyfrom numsgroup by num) as table_temp
)
order by num desc
limit 1
计算结果展示:

补充说明
关于为什么要拆分步骤一和步骤二,为什么不直接写:
select max(count(num))from numsgroup by num
会报错,原因见小tips的第二点
四、结语
我觉得我应该说清楚了where和having的区别了,也讲清楚了聚集函数为什么不能再where中使用🤔,按照执行顺序来写select语句,逻辑很清晰,不容易出错。