为什么要搭建主从集群?
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据之后,需要把数据同步到从节点中。
主从复制原理是什么?
主从复制共有三种模式:全量复制、基于长连接的命令传播、增量复制。
全量同步
从节点向主节点请求数据,主节点判断是第一次请求(这里是通过replid判断,不一致),同步版本信息(可以理解为从节点要继承主节点的replid,使其一致),同时执行bgsave,生成rdb,发送给从节点,在rdb生成期间,由于是异步的,主节点redis仍然会正常处理业务,为了避免新增加的数据没有同步给从节点,主节点将收到的写操作命令,写入到 replication buffer 缓冲区里,在从节点解析执行完rdb文件之后,它告诉一下主节点,我执行完了,主节点就把这个缓冲文件发给他,保证数据的一致性。

PS: replication buffer 缓冲区:目的主要就是给从节点发送要同步的数据。
基于长连接的命令传播:
主从服务器在完成全量同步之后,双方之间就会维护一个 TCP 长连接,通过连接继续将写操作命令传播给从服务器,来保证第一次同步后的主从服务器的数据一致性。
增量复制:
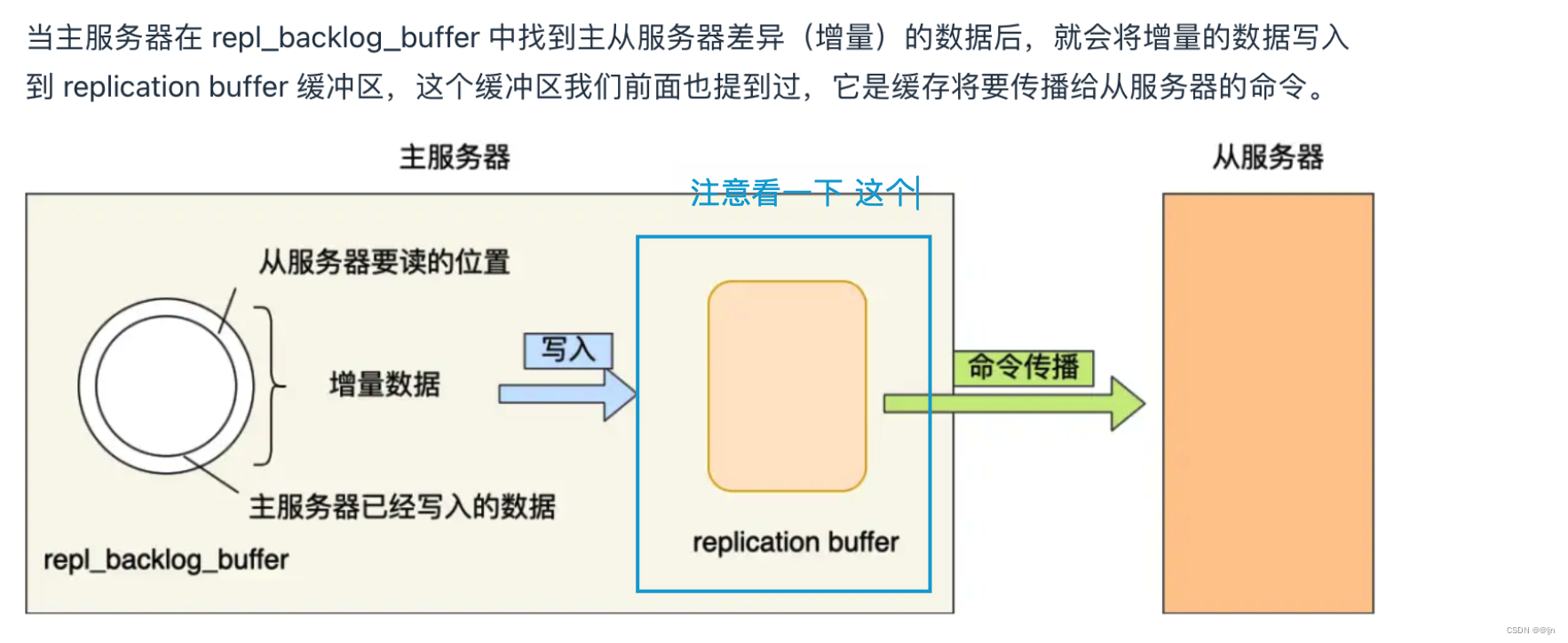
由于网络总是爱发脾气,说断开就断开,由于全量同步耗时间,增量同步的出现解决了这个问题。当网络恢复后,主节点会判断这不是第一次请求,告诉从节点,我想增量同步,你做好准备,然后主节点将断线期间所有的更新数据都发送给从节点。他的实现逻辑是靠一个:一个环形的缓冲区(repl_backlog_size ),主节点进行传播指令给从节点的时候,也会指令写在这个缓冲区,所以这个缓冲区里会保存着最近传播的写命令,通过主的写偏移量和从的读偏移量来获取断线期间的要同步的数据,当然如果从服务器判断要读的数据在这个环形缓冲区没有,就会开启全量同步,同时由于这个缓冲区是环形,也会造成数据的覆盖,所以我们要合理的设置该大小,尽量避免全量复制。






![[计算机知识] 各种小问题思考](https://img-blog.csdnimg.cn/direct/9e0d7351c3c9427291ebd7b73c2be0f4.png)