目录
- 一、配置环境
- 1.1、显卡选择
- 1.2、下载显卡驱动
- 1.3、下载并安装Anaconda
- 1.4、配置Anaconda软件包下载服务器
- 1.5、配置虚拟环境tf_gpu
- 1.6、安装vscode
- 1.7、安装tensorflow
- 1.8、下载安装Git
- 1.9、安装TensorFlow Object Detection API框架
- 1.10、安装依赖的python软件包
- 1.11、配置环境变量
- 1.12、安装COCO API
- 1.13、编译proto文件
- 1.14、测试框架安装
- 1.15、安装LabelImg
- 二、部署流程
- 1.1、 选择预训练库
- 1.2、标注图片
- 1.3、修改pbtxt文件
- 1.4、 Xml转CSV文件
- 1.5、CSV转tfrecord文件
- 1.6、修改config文件
- 1.7、训练
- 1.8、Tensorboard观察训练过程
- 1.9、评估模型
- 1.10、检查点文件转pb
- 1.11、识别
- 三、快捷训练
- 四、LabVIEW调用
本文采用tensorflow开源的object detection api部署深度学习pb文件。
用LabVIEW2020自带的deep learning工具进行检测。
主要工作量在于object detection api的部署,主要参考《 深度学习图像识别技术:基于TensorFlow Object Detection API和OpenVINO™ 工具套件》
环境:
- window10
- anaconda3(64bit)
- python 3.6
- vscode(编辑平台,可选)
- labview2020
硬件:
1660Ti 6G
一、配置环境
- 硬件选型(显卡)
- 驱动软件版本选择和安装(显卡驱动)
- python版本选择和安装(用anaconda安装,本文python 3.6)
- TensorFlow Obejct Detection API版本选择和安装
- 依赖的全部软件和工具版本和安装
| 软件名称 | 用途 |
|---|---|
| NVIDIA显卡驱动 | TnesorFlow GPU版本依赖的显卡驱动软件 |
| Anaconda | 管理Python软件包和环境的工具 |
| Python | TensorFlow依赖的程序开发语言 |
| TensorFlow | Google开源的机器学习库 |
| TensorFlow Object Detection API | 深度学习目标检测算法的软件框架 |
1.1、显卡选择
显卡选择建议参考链接:
https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/
本文使用1660Ti
入门级别参考:GeForce GTX 1050/1060/1070
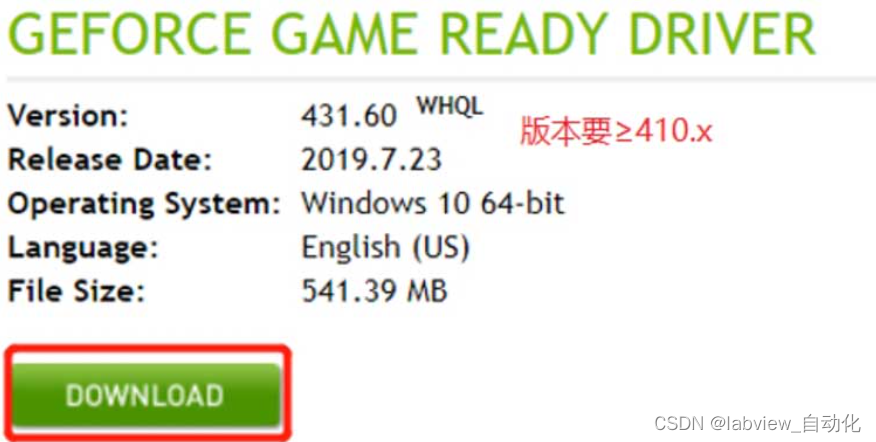
1.2、下载显卡驱动
驱动下载链接:
https://www.nvidia.com/Download/index.aspx?lang=en-us
- 根据所用显卡下载驱动,本文使用1660Ti,选择的驱动如下:

- Version保证大于410.x,安装可以选项可以全部默认
 - 确认安装完成
- 确认安装完成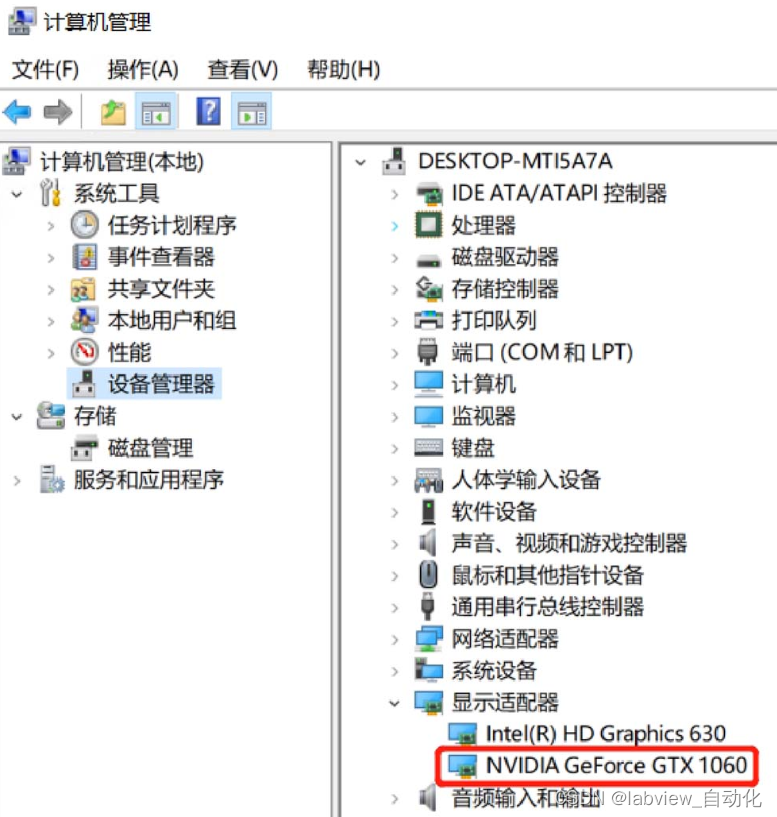
1.3、下载并安装Anaconda
国内镜像下载链接:
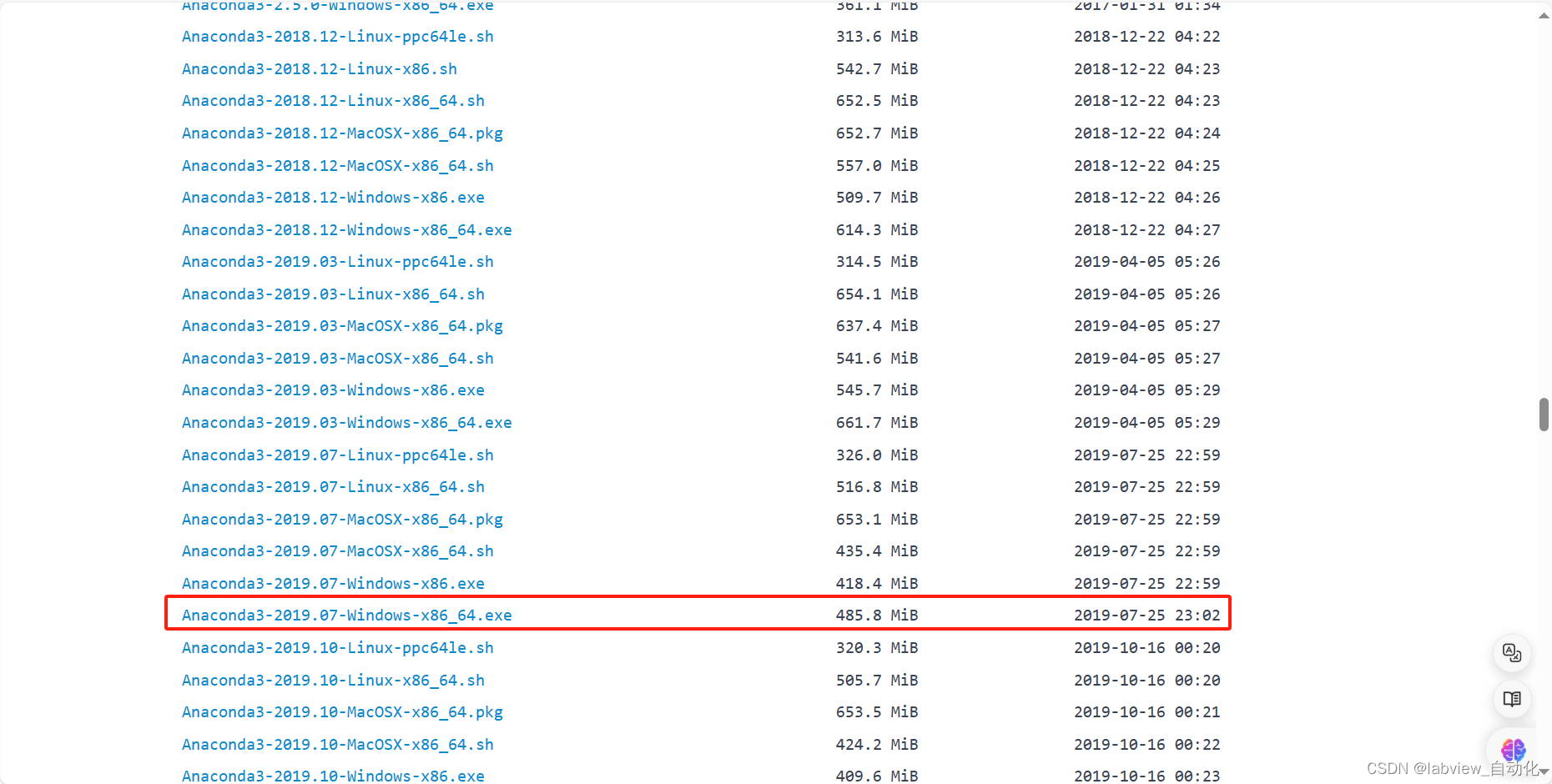
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
本文使用2019.07(64bit)版本:
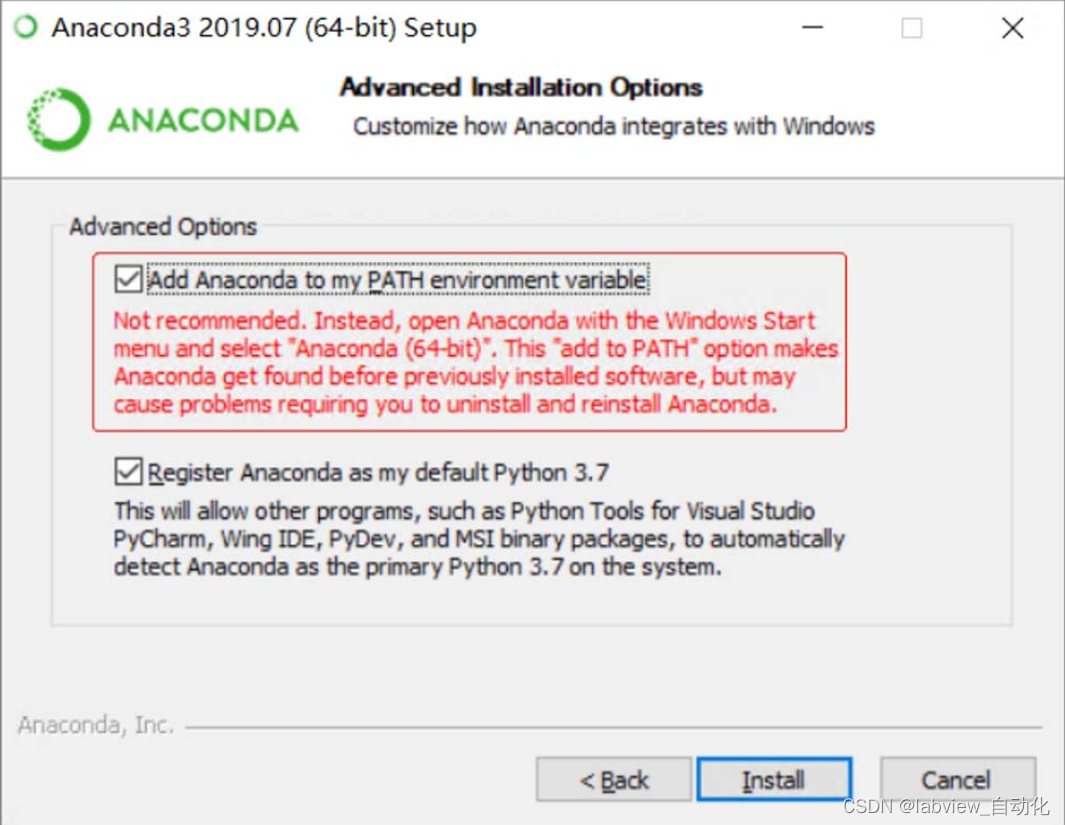
- 注意勾选"Add Anaconda to my PATH environment variable"
1.4、配置Anaconda软件包下载服务器
在默认路径C:\Users\Administrator里有.condar文件,修改为:
show_channel_urls:true
channel_alias:http://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom channels:conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmsys2:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudbioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmenpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudsimpleitk:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudssl
verify:true
1.5、配置虚拟环境tf_gpu
打开anaconda→选中"Environment"→点击"create"→Name修改为"tf_gpu",python选中"3.6"
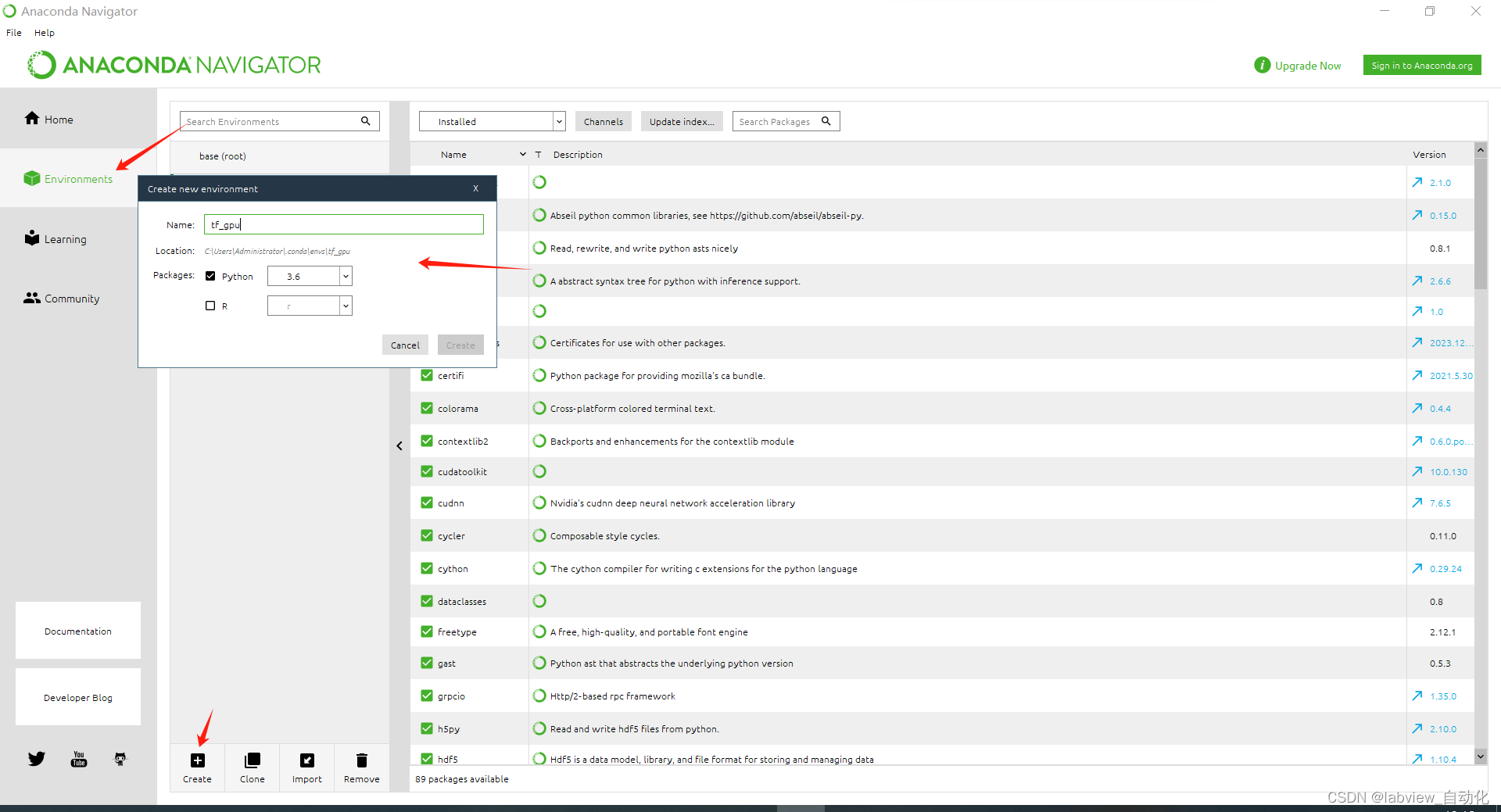
打开Anaconda如果一直停留在初始化的界面,可以通过以下方法解决
① 在路径:C:\ProgramData\Anaconda3\Lib\site-packages\anaconda_navigator\api中,找到conda_api.py,搜索yaml.load,修改为yaml.safeload
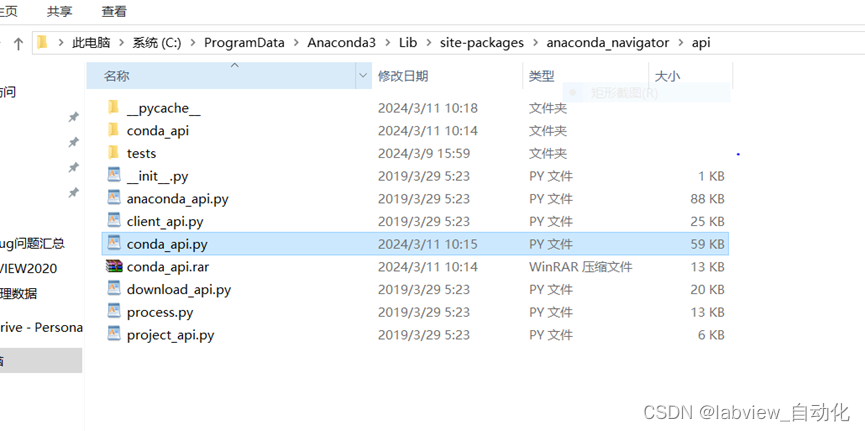
② 重启电脑后,再打开就能正常打开了。
常用的一些conda指令可以参考以下网站:
https://docs.conda.io/projects/conda/en/latest/user-guide/cheatsheet.html
本文常用的有:
- conda install:安装当前python环境对应的工具包
若安装的Python软件只依赖Python软件包,则遵循官方推荐,使用pip install安装,例如安装opencv-python;若安装的Python软件不仅依赖Python软件包,还依赖非Python软件包,则使用conda install,例如安装tensorflow-gpu,简单方便。 - conda activate:激活指定的虚拟环境,例如conda activate tf_gpu
- conda info –envs(cmd):可以查看当前conda的所有环境,带有星号的是当前激活的环境
1.6、安装vscode
vscode仅用修改对应的代码行,不作调试要求,相当于文本编辑软件,可以更换。
下载链接:
https://code.visualstudio.com/
1.7、安装tensorflow
1、win+R→输入"cmd"后,执行
2、命令行中输入后回车,等待安装完成
conda activate tf_gpu
conda install tensorflow-gpu=1.13.1
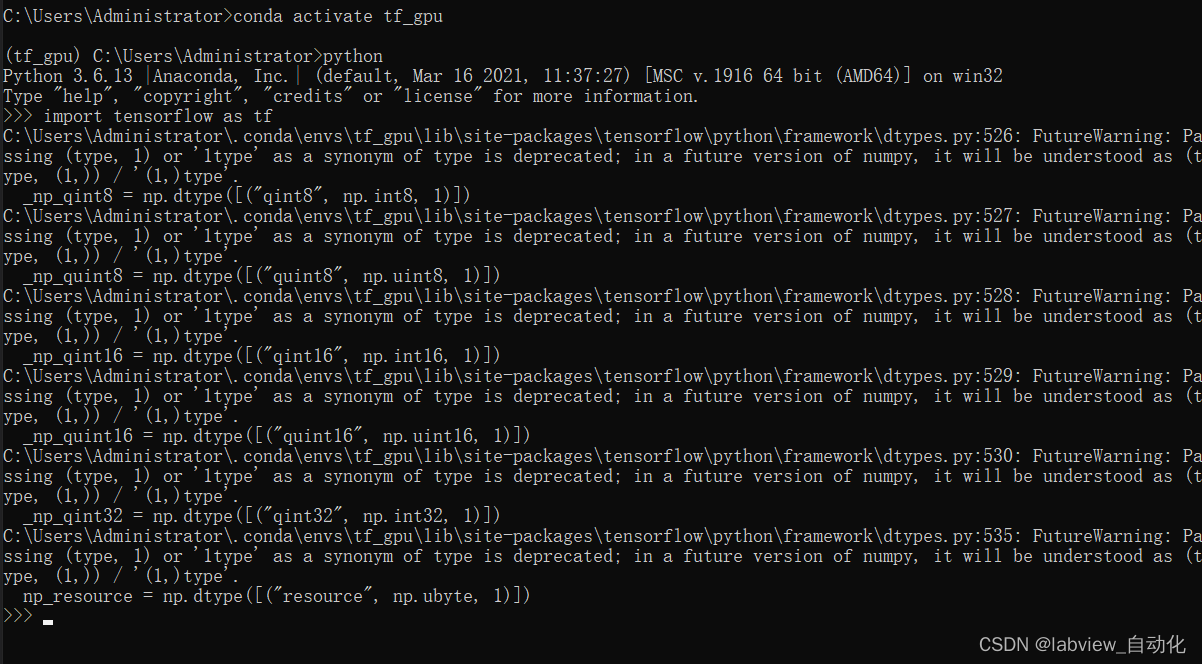
3、命令行中,输入"python"后回车,后再输入"import tensorflow as tf",显示如下信息,即安装完整
1.8、下载安装Git
下载Git,直接下载最新版本的Git就行,下载链接:
https://git-scm.com/
1.9、安装TensorFlow Object Detection API框架
TensorFlow Object Detection API是一个在TensorFlow基础上开发出来的用于计算机视觉领域实现在图像中检测并定位多个目标物体的软件框架。
1、建立文件夹目录结构,本文源路径为"D:\deep_learning\src_code\tf_train"

- addons文件夹:用于存放附加组件或其他软件工具
- workspaces文件夹:用于存放每一个具体项目的文件
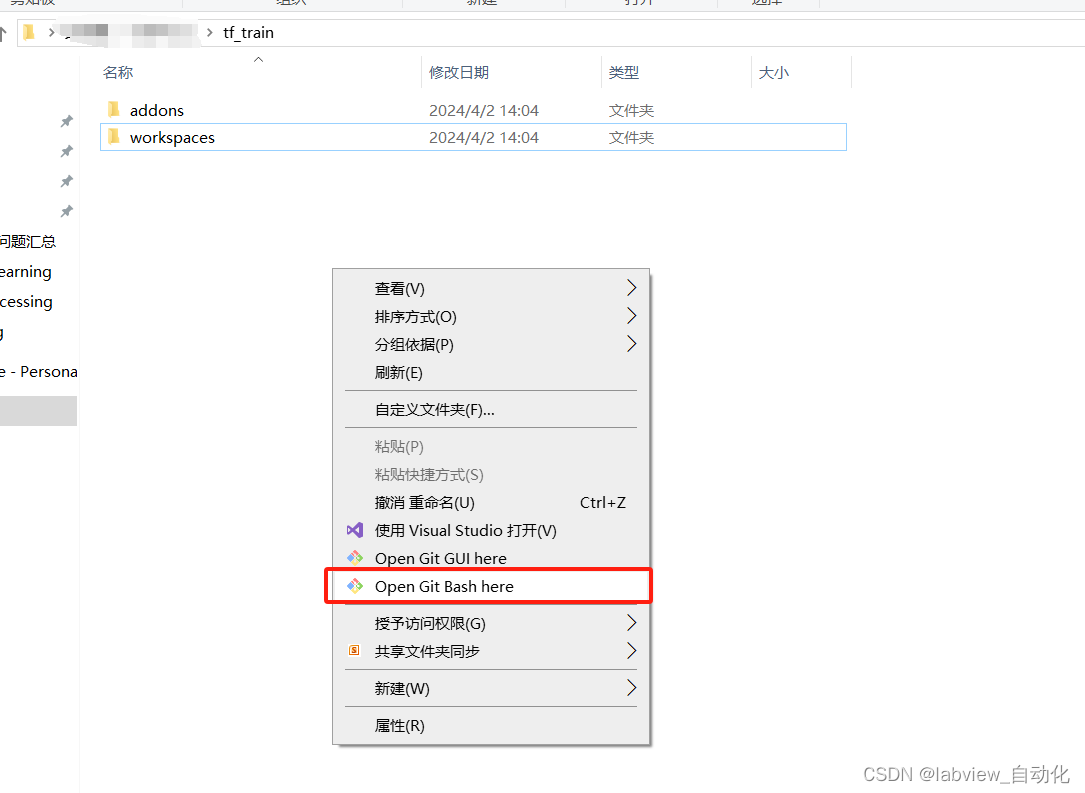
2、在tf_train空白地方右键→选中"open Git Bash here"
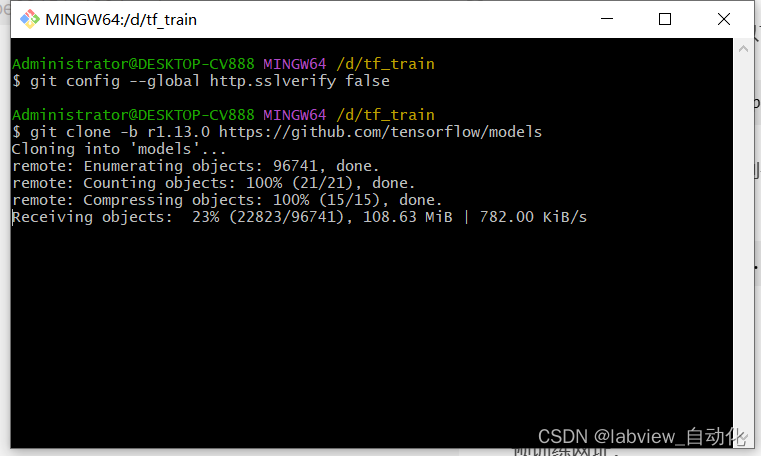
3、在Git Bash中输入以下指令
git clone -b r1.13.0 https://github.com/tensorflow/models
如果报Git SSL错误的话,则需要先关闭SSL校验
输入
git config --global http.sslverify false
如果Git太慢,可以从云盘下载
https://pan.baidu.com/s/1klGCW0ckE2BQvY4cRscRYA#list/path=%2F
提取码: h9m3
4、下载完成后,路径变为:

1.10、安装依赖的python软件包
| 软件包名称 | 用途 |
|---|---|
| matplotlib | 绘制图表 |
| pillow | 图像处理 |
| lxml | 处理XML和HTML |
| contextlib2 | with语句上下文管理 |
| cython | 让Python脚本支持C语言扩展的编译器 |
| opencv-python | OpenCV的python库 |
| 1、win+R→输入"cmd"后,执行 | |
| 2、命令行中输入后回车,等待安装完成 |
conda activate tf_gpu
3、再输入
pip install matplotlib pillow lxml contextlib2 cython opencv-python
如果碰到个别的出错,可以单独执行。
1.11、配置环境变量
为了让Python可以找到TensorFlow Object Detection API依赖的软件模块,需要配置环境变量,本文添加以下三个路径:
D:\deep_learning\src_code\tf_train\models\research
D:\deep_learning\src_code\tf_train\models\research\slim
D:\deep_learning\src_code\tf_train\models\research\object_detection
1、打开"此电脑"→右键空白处,点击"属性"
2、点击高级系统设置

3、点击环境变量

4、添加对应的环境变量

1.12、安装COCO API
1、在addons文件夹中点击鼠标右键,选中Git Bash,在Git Bash中输入
git clone https://github.com/philferriere/cocoapi
下载完成后,文件目录变为

2、在命令行中激活tf_gpu环境→输入后执行,命令行进入PythonAPI
cd /d D:\deep_learning\src_code\tf_train\addons\cocoapi\PythonAPI
3、再执行
python setup.py install
1.13、编译proto文件
1、进入"D:\deep_learning\src_code\tf_train\models\research"路径
2、在文件路径中输入cmd,弹出命令行
3、激活tf_gpu环境后,输入以下命令执行后,完成proto文件的编译
for /f gi in('dir /b object detection\protos\*.proto')do protoc object detection\protos\&i--python out=.
1.14、测试框架安装
1、从https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md下载ssd_inception_v2_coco

2、下载完成后,解压到路径"D:\deep_learning\src_code\tf_train\models\research\object_detection"中
3、注释掉26行"import matplotlib; matplotlib.use(‘Agg’)"
4、在命令行中激活tf_gpu环境,然后执行object_detection_example_1.py
5、执行结果如下,说明检测环境配置完成。
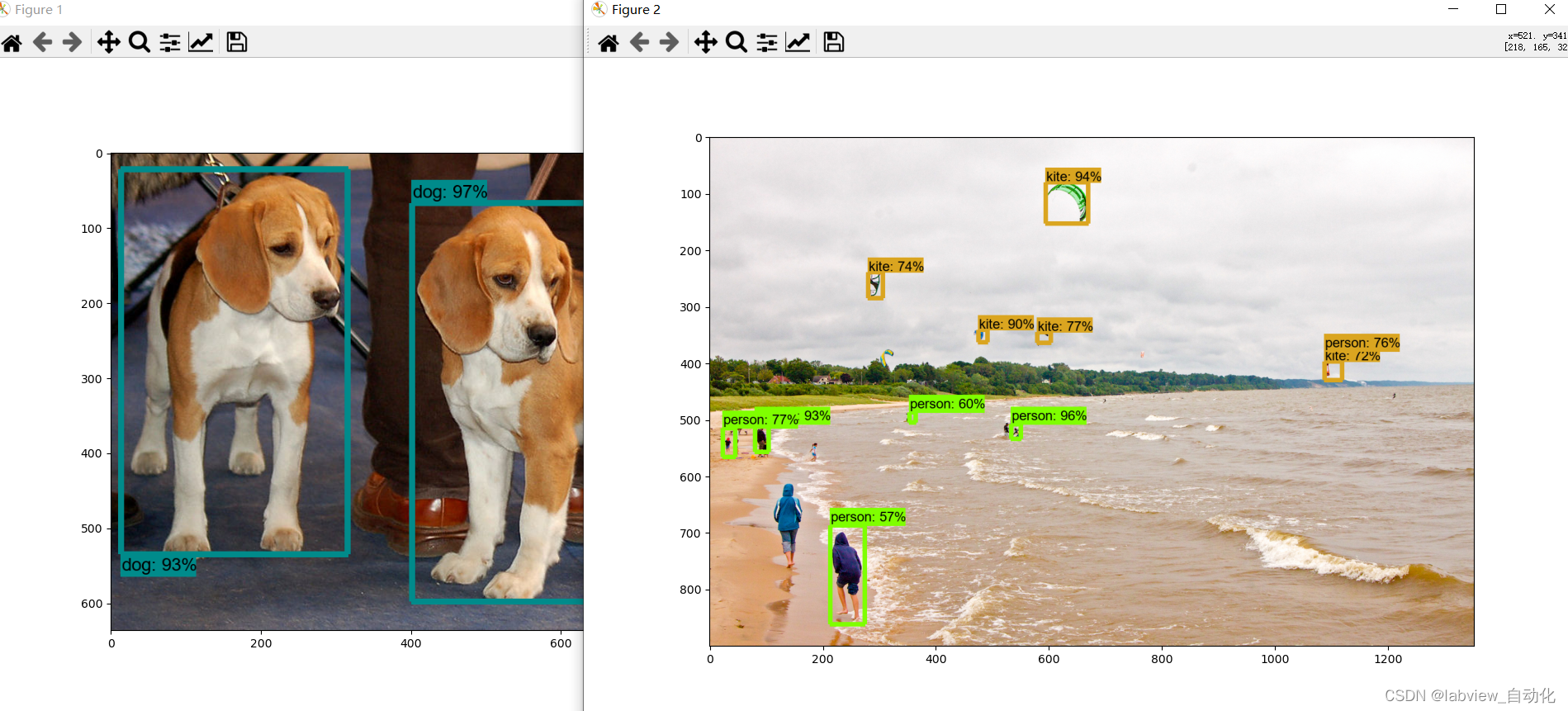
1.15、安装LabelImg
激活tf_gpu,运行pip install labelimg
二、部署流程
1.1、 选择预训练库
预训练网址:
models/research/object_detection/g3doc/tf1_detection_zoo.md at master • tensorflow/models (github.com)
本文选用ssd_mobilenet_v2_coco。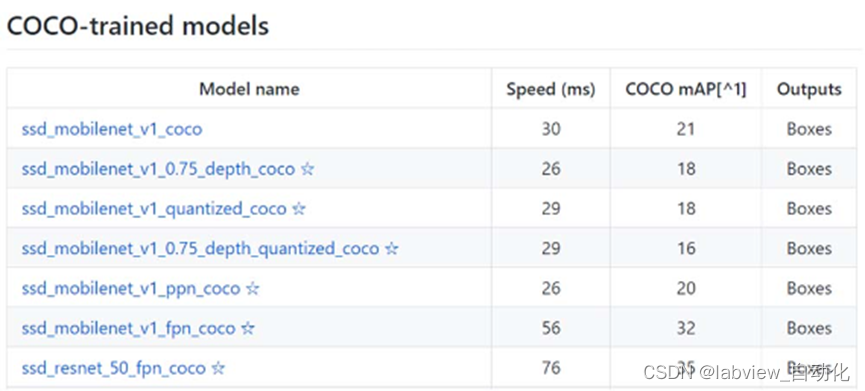
其中模型名称含义:
ssd_mobilenet_v2_coco:该模型使用了SSD(Single Shot Multibox Detector)目标检测算法,mobilenet特征提取网络,在COCO数据集上进行了训练。
- 速度(Speed)
是指该模型在NVIDIA GeForce GTX TITAN X显卡上处理600×600分辨率图像(包含预处理和后处理)的速度,这个数值可以让大家对模型运行的相对快慢有个感性的认识。例如,ssd_resnet_50_fpn_coco的运行速度就比ssd_mobilenet_v1_coco要慢。 - 平均精度均值(mAP)
是指该模型识别多类物体时,每类物体识别精度(AP)的平均值。mAP值越高,表明该模型识别精度越高。例如,ssd_resnet_50_fpn_coco的识别精度就比ssd_mobilenet_v1_coco要高。 - 输出(outputs)
有两种类型:边界框(boxes)和掩膜(Masks)
下载完的模型,放到pre_trained_model文件夹里解压

1.2、标注图片
1、准备好对应的图集。
2、用labelImg标注图片,并建立对应文件夹,包括images里面的eval,test,train,其中train里面包含图片和对应标注后以图片命名的xml文件,test是部分标注后的图片,eval是只有部分图片。

labelImg常用功能有:
- w:启用矩形框
- D:下一张
- ctrl+s:保存
- 打开在labelImg路径下的data文件夹predefined_classes.txt文件,将里面的预定义标签修改为对应的类别,本文是cat和dog。
1.3、修改pbtxt文件
修改"D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\annotations"路径中的label_map.pbtxt文件。
item {id: 1name: "cat"
}
item {id: 2name: "dog"
}
1.4、 Xml转CSV文件
执行xml_to_csv.py
- Train标注数据转csv:
Python xml_to_csv.py -i D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\images\train -o D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\annotations\train_labels.csv
- Eval标注数据转csv:
Python xml_to_csv.py -i D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\images\eval-o D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\annotations\eval_labels.csv
1.5、CSV转tfrecord文件
- 修改generate_tfrecord.py:
# 以猫狗为例,label0=cat,label1=dog,在pbtxt文件中也是
flags.DEFINE_string('label0','','Name of class[0] label')
flags.DEFINE_string('label1','','Name of class[1] label')
flags.DEFINE_string('img_path','','Name of class[1] label')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label):if row_label == "cat": # 需改动为自己的分类return 1elif row_label == "dog":return 2else:None
- 执行csv转tfrecord(train)
Python generate_tfrecord.py --label0=cat --label1=dog --csv_input= D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\annotations\train_labels.csv --output_path= D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\annotations\train.tfrecord --img_path= D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\images\train
- 执行csv转tfrecord(eval)
Python generate_tfrecord.py --label0=cat --label1=dog --csv_input= D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\annotations\eval_labels.csv --output_path= D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\annotations\eval.tfrecord --img_path= D:\deep_learning\src_code\tf_train\workspaces\cats_dogs\images\eval
1.6、修改config文件
路径在models\research\object_detection\samples\configs里,把对应的ssd_inception_v2_coco_config文件复制到training文件夹下。

① 修改num_classes:2,猫狗只有两类:

② 修改batch_size:24,可根据显存和图像大小调整,越大越耗费,速度越快,太大会报错
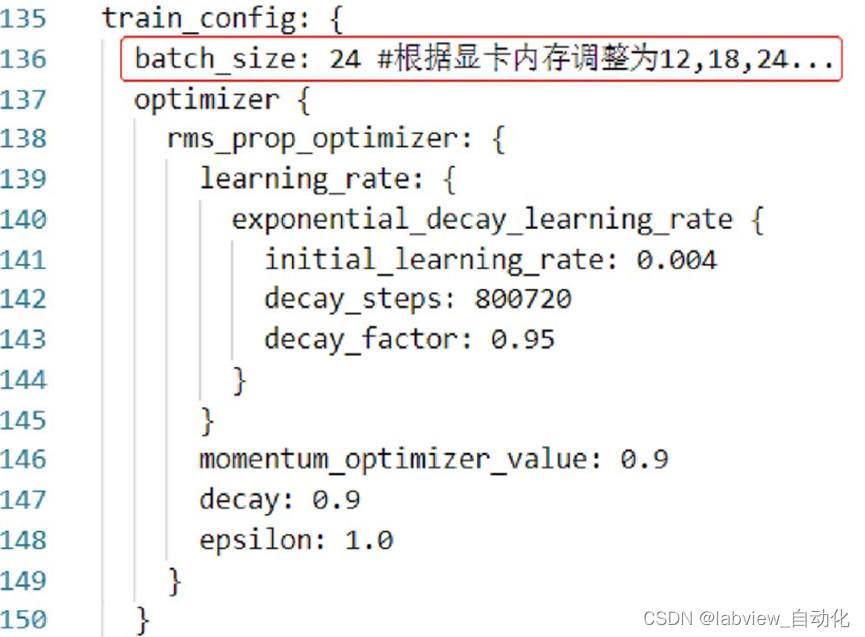
③ 把fine_tune_checkpoint删除(可选)
④ Num_step:2000,根据loss值调整
⑤ Input_path配置为train.tfrecord路径
⑥ Label_map_path改为label_map.pbtxt路径
⑦ Input_path改为eval.tfrecord路径
⑧ Label_map_path改为label_map.pbtxt路径
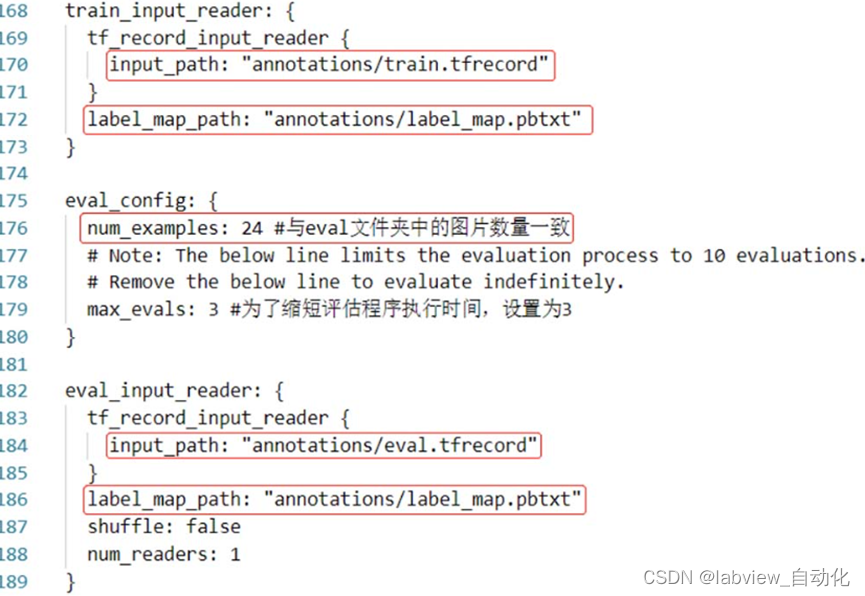
1.7、训练
执行train.py脚本:
Python train.py --logtostderr --train_dir=training\ --pipeline_config_path=training\ssd_inception_v2_coco.config
1.8、Tensorboard观察训练过程
在cat_and_dog文件夹中输入cmd,输入
Tensorboard --logdir=training\
- Training文件夹里面是包含所有检查点文件的文件夹
- 如果网址打开不了,要把网址改为localhost
1.9、评估模型
Num_example要改为对应评估的图像个数
Max_evals验证循环次数

修改tf_train\models\research\object_detection\utils\object_detection_evaluation.py,unicode改为str
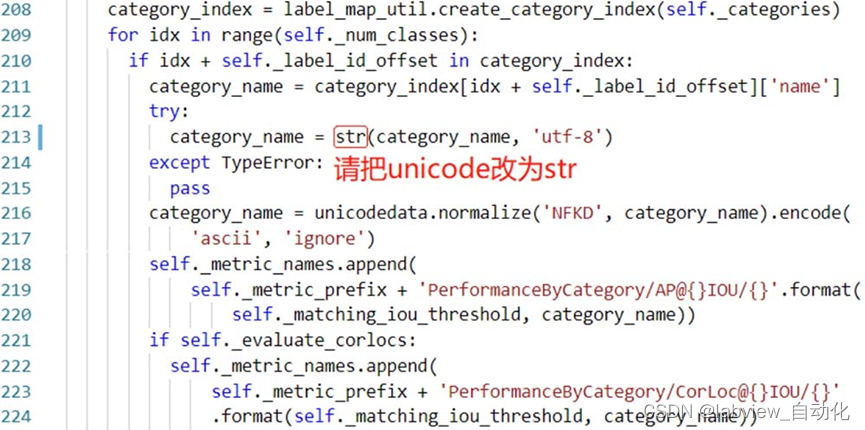
把tf_train\models\research\object_detection\legacy\eval.py文件拷到tf_train\workspaces\cats_dogs中,运行脚本
Python eval.py --logtostderr --checkpoint_dir=training --eval_dir=evaluation --pipeline_config_path=training\ssd_inception_v2_coco.config
1.10、检查点文件转pb
要注意ckpt后面的数值,需要在training文件夹里面存在一样名称的文件。
这个就是LabVIEW最终调用的PB文件。
Python export_inference_graph.py --input_type image_tensor --pipeline_config_path training\ssd_inception_v2_coco.config --trained_checkpoint_prefix training\model.ckpt-2000 --output_directory trained_frozen_models\cats_dogs_model
在这一步生成pb文件,就可以直接应用于LabVIEW的deep learning工具包进行图像识别了。
1.11、识别
① 修改模型路径:
# 第二步,导入模型ssd_inception_v2_coco_2018_01_28到内存
# ssd_inception_v2_coco_2018_01_28文件夹应与本程序放在models\research\object_detection文件夹下
# -----------------------------------------------------------
#MODEL_NAME = 'ssd_inception_v2_coco_2018_01_28'
MODEL_NAME='pre_trained_model/ssd_inception_v2_coco'
PATH_TO_FROZEN_GRAPH = MODEL_NAME + '/frozen_inference_graph.pb'
PATH_TO_LABELS = os.path.join('annotations', 'label_map.pbtxt')
② 修改图片路径:
# ## 从单张图片中检测对象子程序
# ## 图片名称:image1.jpg, image2.jpg,存放在
# ## models\research\object_detection\test_images文件夹下
#PATH_TO_IMAGES_DIR = 'test_images'
PATH_TO_IMAGES_DIR='images/eval'
TEST_IMAGE_PATHS = [os.path.join(PATH_TO_IMAGES_DIR, 'dog.{0:d}.jpg'.format(i)) for i in range(1,3)]
③ 输入命令行进行识别:python object_detection_example_2.py
三、快捷训练
以上路径生成和训练过程可以快捷完成
1、在激活tf_gpu环境后
2、快捷生成路径:
Python create_directories.py -n cats_dogs
3、快捷训练
python one_command_train.py --step 500 --batch_size 12
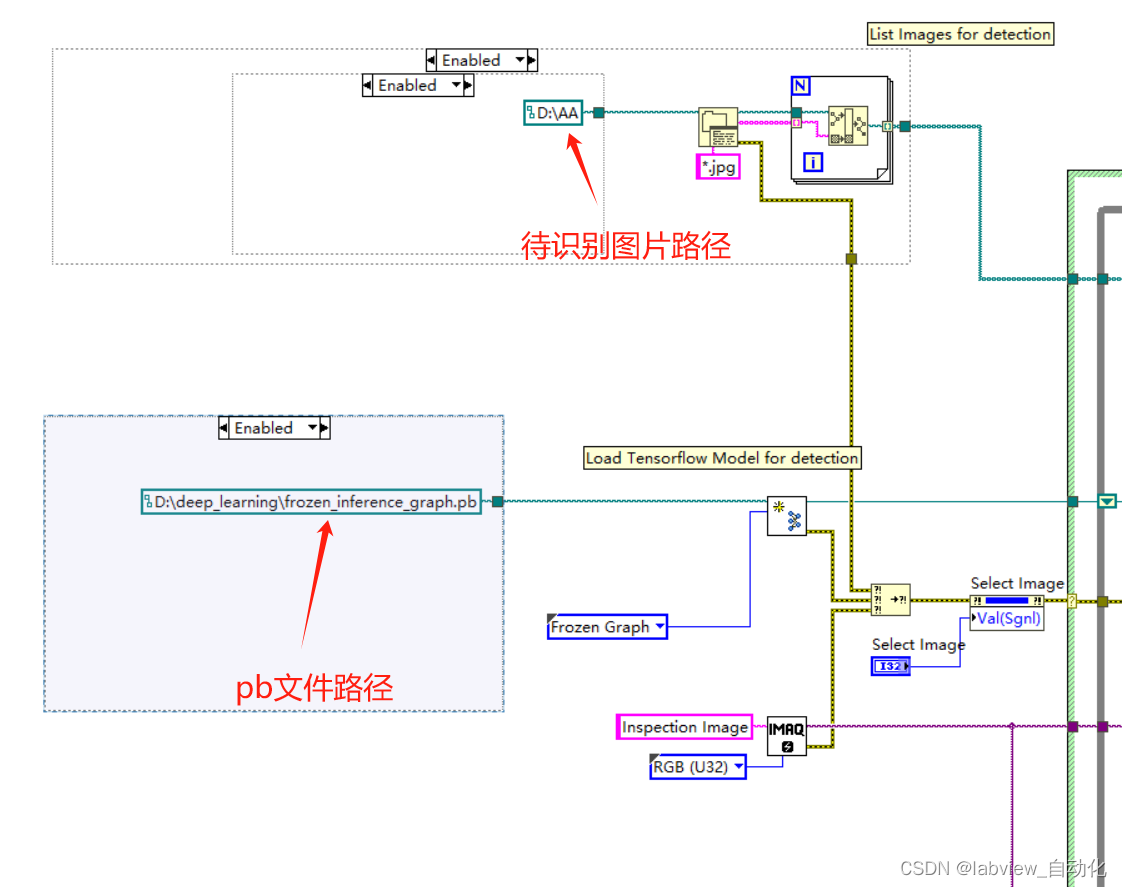
四、LabVIEW调用
可以直接使用LabVIEW2020(64bit)的例程:
1、菜单栏"help"→点击"find examples"
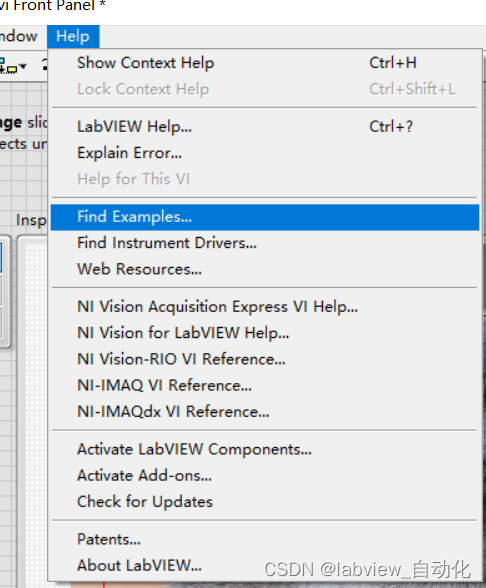
2、选中"Toolkits and Modules"→"Vision"→"Deep Learing Object Detection"→"Deep Learing Object Detection(tensorflow)"
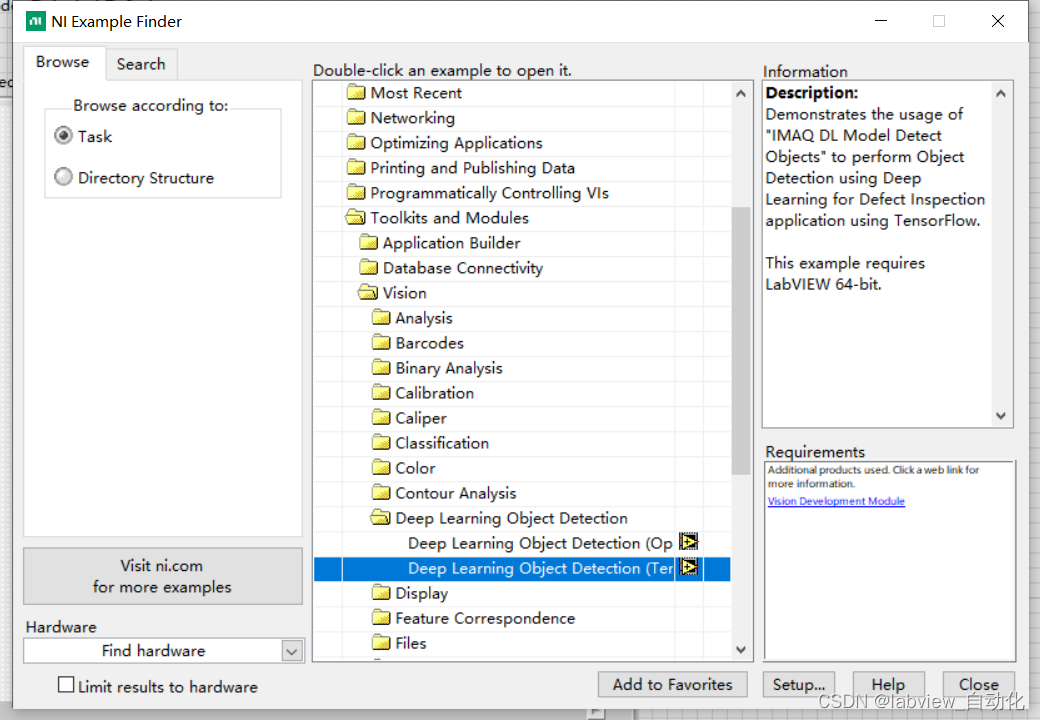
3、将pb文件路径修改为训练好的pb文件路径,识别图修改为猫狗图片路径,标签和名称修改为cat和dog