文章目录
5.18 卷积神经网络凸显共性的方法
5.18.1 局部连接
5.18.2 权值共享
5.18.3 池化操作
5.19 全连接、局部连接、全卷积与局部卷积
5.20 局部卷积的应用
5.21 NetVLAD池化
参考文献
5.18 卷积神经网络凸显共性的方法
5.18.1 局部连接
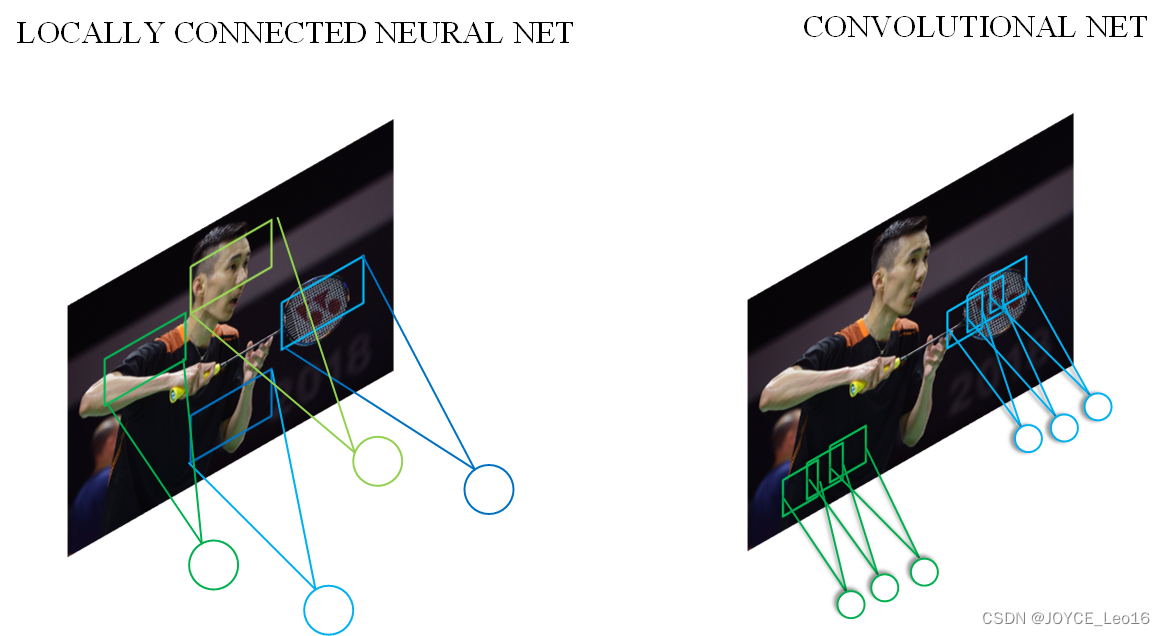
我们首先了解一个概念,感受野,即每个神经元仅与输入神经元相连接的一块区域。在图像卷积操作中,神经元在空间维度上是局部连接的,但在深度上是全连接。局部连接的思想,是受启发于身生物学里的视觉系统结构,视觉皮层的神经元就是仅用局部接受信息。对于二维图像,局部像素关联性较强。这种局部连接保证了训练后的滤波器能够对局部特征有最强的响应,使神经网络可以提取数据的局部特征。
下图是一个很经典的图示,左边是全连接,右边是局部连接。

对于一个的输入图像而言,如果下一个隐藏层的神经元数目为
个,采用全连接则有
个权值参数,如此巨大的参数量几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中
的局部图像相连接,那么此时的权值参数数量为
,将直接减少4个数量级。
5.18.2 权值共享
权值共享,即计算同一深度的神经元时采用的卷积核参数是共享的。权值共享在一定程度上讲是有意义的,是由于在神经网络中,提取的底层边缘特征与其在图中的位置无关。但是在另一些场景中是无意的,如在人脸识别任务,我们期望在不同的位置学到不同的特征。需要注意的是,权重只是对于同一深度切片的神经元是共享的。在卷积层中,通常采用多组卷积核提取不同的特征,即对应的是不同深度切片的特征,而不同深度切片的神经元权重是不共享。
相反,偏置这一权值对于同一深度切片的所有神经元都是共享的。权值共享带来的好处是大大降低了网络的训练难度。如下图,假设在局部连接中隐藏层的每一个神经元连接的是一个的局部图像,因此有
个权值参数,将这
个权值参数共享给剩下的神经元,也就是说隐藏层中
个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这
个权值参数(也就是卷积核的大小)。
这里就体现出了卷积神经网络的奇妙之处,使用少量的参数,却依然能有非常出色的性能。上述仅仅是提取图像一种特征的过程。如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像不同尺度下的特征,称之为特征图(feature map)。
5.18.3 池化操作
池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成较高的层次的特征,从而对整个图片进行表示。如下图:

5.19 全连接、局部连接、全卷积与局部卷积
大多数神经网络中高层网络通常会采用全连接层(Global Connected Layer),通过多对多的连接方式对特征进行全局汇总,可以有效地提取全局信息。但是全连接的方式需要大量的参数,是神经网络中最占资源的部分之一,因此就需要由局部连接(Local Connected Layer),仅在局部区域范围内产生神经元连接,能够有效地减少参数量。根据卷积操作的作用范围可以分为全卷积(Global Convolution)和局部卷积(Local Convolution)。
实际上这里所说的全卷积就是标准卷积,即在整个输入特征维度范围内采用相同的卷积核参数进行运算,全局共享参数的连接方式可以使神经元之间的连接参数大大减少;
局部卷积又叫平铺卷积(Tiled Convolution)或非共享卷积(Unshared Convolution),是局部连接与全卷积的折中。四者的表示如表5.11所示。
| 连接方式 | 示意图 | 说明 |
|---|---|---|
| 全连接 | 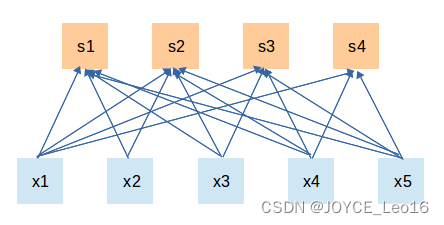 | 层间神经元完全连接,每个输出神经元可以获取到所有输入神经元的信息,有利于信息汇总,常置于网络末层;连接与连接之间独立参数,大量的连接大大增加模型的参数规模。 |
| 局部连接 |  | 层间神经元只有局部范围内的连接,在这个范围内采用全连接的方式,超过这个范围的神经元则没有连接;连接与连接之间独立参数,相比于全连接减少了感受域外的连接,有效减少参数规模。 |
| 全卷积 | 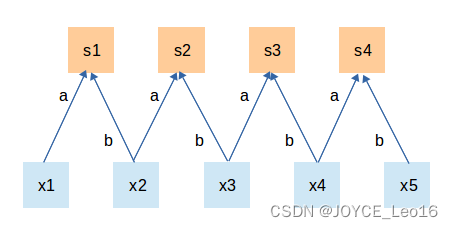 | 层间神经元只有局部范围内的连接,在这个范围内采用全连接的方式,连接所采用的参数在不同感受域之间共享,有利于提取特定模式的特征;相比于局部连接,共用感受域之间的参数可以进一步减少参数量。 |
| 局部卷积 |  | 层间神经元只有局部范围内的连接,感受域内采用全连接的方式,而感受域之间间隔采用局部连接与全卷积的连接方式;相比于全卷积成倍引入额外参数,但有更强的灵活性和表达能力;相比于局部连接,可以有效控制参数量。 |
5.20 局部卷积的应用
并不是所有的卷积都会进行权重共享,在某些特定任务中,会使用不权重共享的卷积。下面通过人脸这一任务来进行详解。在读人脸方向的一些paper中,会发现很多都会在最后加入一个Local Connected Conv,也就是不进行权重共享的卷积层。总的来说,这一步的作用就是使用3D模型来将人脸对齐,从而使CNN发挥最大的效果。

截取论文中的一部分图,经过3D对齐以后,形成的图像均是,输入到上述的网络结构中。该结构的参数如下:
- Conv:32个
的卷积核
- Max-pooling:
,stride=2
- Conv:16个
的卷积核
- Local-Conv:16个
- Local-Conv:16个
的卷积核
- Local-Conv:16个
的卷积核
- Fully-connected:4096维
- Softmax:4030维
前三层的目的在于提取低层次的特征,比如简单的边和纹理。其中Max-pooling层使得卷积的输出对微小的偏移情况更加鲁棒。但不能使用更多的Max-pooling层,因为太多的Max-pooling层会使得网络损失图像信息。全连接层将上一层的每个单元和本层的所有单元相连,用来捕捉人脸图像不同位置特征之间的相关性。最后使用softmax层用于人脸分类。中间三层都是使用参数不共享的卷积核,之所以使用参数不共享,有如下原因:
- 对齐的人脸图片中,不同的区域会有不同的统计特征,因此并不存在特征的局部稳定性,所以使用相同的卷积核会导致信息的丢失。
- 不共享的卷积核并不增加inference时特征的计算量,仅会增加训练时的计算量。使用不共享的卷积核,由于需要训练的参数量大大增加,因此往往需要通过其他方法增加数据量。
5.21 NetVLAD池化
NetVLAD是论文[15]提出的一个局部特征聚合的方法。
在传统的网络里面,例如VGG,最后一层卷积层输出的特征都是类似于Batchsize x 3 x 3 x 512这种东西,然后会经过FC聚合,或者进行一个Global Average Pooling(NIN里的做法),或者怎么样,变成一个向量型的特征,然后进行Softmax 或者其他的 Loss。
这种方法说简单点也就是输入一个图片或者什么的结构性数据,然后经过特征提取得到一个长度固定的向量,之后可以用度量的方法去进行后续的操作,比如分类啊,检索啊,相似度对比等等。
那么NetVLAD考虑的主要是最后一层卷积层输出的特征这里,我们不想直接进行欠采样或者全局映射得到特征,对于最后一层输出的W x H x D,设计一个新的池化,去聚合一个“局部特征“,这即是NetVLAD的作用。
NetVLAD的一个输入是一个W x H x D的图像特征,例如VGG-Net最后的3 x 3 x 512这样的矩阵,在网络中还需加一个维度为Batchsize。
NetVLAD还需要另输入一个标量K即表示VLAD的聚类中心数量,它主要是来构成一个矩阵C,是通过原数据算出来的每一个特征的聚类中心,C的shape即
,然后根据三个输入,VLAD是计算下式的V:
其中表示维度,从1到D,可以看到V的j是和输入与c对应的,对每个类别k,都对所有的x进行了计算,如果
属于当前类别
,
,否则
,计算每一个
和它聚类中心的残差,然后把残差加起来,即是每个类别k的结果,最后分别L2正则后拉成一个长向量后再做L2正则,正则非常的重要,因为这样才能统一所有聚类算出来的值,而残差和的目的主要是消减不同聚类上的分布不均,两者共同作用才能得到最后正常的输出。
输入与输出如下图所示:

中间得到的K个D维向量即是对D个x都进行了与聚类中心计算残差和的过程,最终把K个D维向量合起来后进行即得到最终输出的长度的一维向量。
而VLAD本身是不可微的,因为上面的a要么是0要么是1,表示要么当前描述x是当前聚类,要么不是,是个离散的,NetVLAD为了能够在深度卷积网络里使用反向传播进行训练,对a进行了修正。
那么问题就是如何重构一个a,使其能够评估当前的这个x和各个聚类的关联程度?用softmax来得到:
将这个把上面的a替换后,即是NetVLAD的公式,可以进行反向传播更新参数。
所以一共有三个可训练参数,上式a中的,上式a中的
,聚类中心
,而原始VLAD只有一个参数c。
最终池化得到的输出是一个恒定的K x D的一维向量(经过了L2正则),如果带Batchsize,输出即为Batchsize x (K x D)的二维矩阵。
NetVLAD作为池化层嵌入CNN网络即如下图所示:

原论文中采用将传统图像检索方法VLAD进行改进后应用在CNN的池化部分作为一种另类的局部特征池化,在场景检索上取得了很好的效果。
后续相继又提出了ActionVLAD、ghostVLAD等改进。
参考文献
[1] 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6):1229-1251.
[2] 常亮, 邓小明, 周明全,等. 图像理解中的卷积神经网络[J]. 自动化学报, 2016, 42(9):1300-1312.
[3] Chua L O. CNN: A Paradigm for Complexity[M]// CNN a paradigm for complexity /. 1998.
[4] He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.
[5] Hoochang S, Roth H R, Gao M, et al. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning[J]. IEEE Transactions on Medical Imaging, 2016, 35(5):1285-1298.
[6] 许可. 卷积神经网络在图像识别上的应用的研究[D]. 浙江大学, 2012.
[7] 陈先昌. 基于卷积神经网络的深度学习算法与应用研究[D]. 浙江工商大学, 2014.
[8] CS231n Convolutional Neural Networks for Visual Recognition, Stanford
[9] Machine Learning is Fun! Part 3: Deep Learning and Convolutional Neural Networks
[10] cs231n 动态卷积图:Convolution demo
[11] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
[12] Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes[C]//Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on. IEEE, 2014: 1891-1898.
[13] 魏秀参.解析深度学习——卷积神经网络原理与视觉实践[M].电子工业出版社, 2018
[14] Jianxin W U , Gao B B , Wei X S , et al. Resource-constrained deep learning: challenges and practices[J]. Scientia Sinica(Informationis), 2018.
[15] Arandjelovic R , Gronat P , Torii A , et al. [IEEE 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) - Las Vegas, NV, USA (2016.6.27-2016.6.30)] 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) - NetVLAD: CNN Architecture for Weakly Supervised Place Recognition[C]// 2016:5297-5307.