提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、数据库聚合替代内存计算(关键优化)
- 二、批量处理优化
- 四、区域特殊处理解耦
- 五、防御性编程增强
前言
技术认知点:使用 XML 编写 SQL 聚合查询并不会导致所有数据加载到内存,反而能 大幅减少内存占用并提升性能。
LocalDateTime localDateTime = TimeUtilTool.startOfDay();LocalDateTime crossTime = LocalDateTime.now().minusDays(1);List<AAA> list = SERVICE1.list(new LambdaQueryWrapper<AAA>().between(AAA::GETTIME, localDateTime.minusDays(1), localDateTime));Map<String, List<AAA>> areaMap = list.stream().collect(Collectors.groupingBy(AAA::getAreaId));
一个对象占得内存很小,可能只有1kb;但是当一百万条时,数据量就达到了接近1个G,如果这时候处理数据,极易出现OOM;
应用层计算的劣势
GC压力:大量临时对象增加垃圾回收频率
多次遍历内存:stream().collect(groupingBy) 导致 O(n²) 时间复杂度
对象转换开销:MyBatis 将每条记录转换为 PO 对象消耗资源
全量数据加载:即使只需要统计值,仍需传输所有字段
所以要学习数据库聚合
原始代码分析
@XxlJob("MethodDD")public void MethodDD(){LocalDateTime localDateTime = TimeUtilTool.startOfDay();LocalDateTime crossTime = LocalDateTime.now().minusDays(1);List<AAA> list = SERVICE1.list(new LambdaQueryWrapper<AAA>().between(AAA::GETTIME, localDateTime.minusDays(1), localDateTime));Map<String, List<AAA>> areaMap = list.stream().collect(Collectors.groupingBy(AAA::getAreaId));List<BBB> result = SAVEDATA(areaMap, crossTime);saveAreaStatisticsDaily(result, crossTime);}private List<BBB> SAVEDATA(Map<String, List<AAA>> areaMap, LocalDateTime crossTime) {List<CCCC> ccc = cacheTool.areaDictionary();List<BBB> result = new ArrayList<>();areaMap.forEach((areaId, areaList)->{BBB po = new BBB();Optional<CCCC> first = ccc.stream().filter(ccc -> ccc.getId().toString().equals(areaId)).findFirst();first.ifPresent(ccc -> {po.setAreaId(areaId);if(ccc.getId().toString().equals(areaId)){po.setAreaName(AreaNameBuilder.getAreaName(ccc));}Double carSpeed = 0.0;if (areaList == null || areaList.isEmpty()) {// 处理空列表的情况carSpeed = 0.0;} else {double totalSpeed = areaList.parallelStream() .mapToDouble(AAA::getCarSpeed).sum();carSpeed = totalSpeed / areaList.size();}po.setMeanSpeed(new BigDecimal(carSpeed));po.setFlow(areaList.size());Map<String, List<AAA>> carTypeMap = areaList.stream().collect(Collectors.groupingBy(AAA::getCarType));carTypeMap.forEach((carType, carTypeList) ->{if (carType.equals("1")){po.setSmallCCCARFlow(carTypeList.size());} else if (carType.equals("2")){po.setMediumLargeBBBULLFlow(carTypeList.size());} else if (carType.equals("3")){po.setSmallMediumttttFlow(carTypeList.size());}else if (carType.equals("4")){po.setLargettttFlow(carTypeList.size());}else if (carType.equals("5")){po.setHazardousChemicalCCCARFlow(carTypeList.size());}else if (carType.equals("6")){po.setMotorcycle(carTypeList.size());}else if (carType.equals("7")){po.setOther(carTypeList.size());}});});po.setCrossTime(crossTime);result.add(po);statsService.save(po);});List<String> areaIds = areaMap.keySet().stream().toList();for (CCCC ccc : ccc) {if (!areaIds.contains(ccc.getId().toString())){BBB po = new BBB();po.setAreaId(ccc.getId().toString());po.setAreaName(AreaNameBuilder.getAreaName(ccc));po.setCrossTime(crossTime);result.add(po);statsService.save(po);}}return result;}
首先,用户有一个定时任务,每天凌晨统计卡口数据,并将结果保存到数据库。当前代码可能存在性能问题,尤其是当数据量大的时候,全量查询和处理会导致内存和性能问题。
- 全量数据加载到内存:使用
trafficCCCARService.list查询所有符合条件的数据,如果数据量很大,会导致内存压力,甚至OOM。 - 多次遍历数据流:在处理每个区域的数据时,多次使用流操作进行分组和统计,可能导致性能下降。
- 频繁的数据库写入操作:在
SAVEDATA方法中,每次处理一个区域就调用statsService.save(po),这样频繁的数据库插入操作效率低下。 - 硬编码的区域ID判断:在
saveAreaStatisticsDaily方法中,直接判断特定的区域ID,这样的代码难以维护,且不符合面向对象的设计原则。
首先,全量数据的问题,可以考虑分页查询或者使用数据库的聚合功能,减少数据传输量。
其次,多次遍历数据流可以通过合并处理逻辑来减少遍历次数。
数据库写入操作应该批量进行,而不是逐条插入。
硬编码的问题可以通过枚举或配置来解决:代码中存在重复的区域ID判断,这部分应该抽象出来,使用更灵活的方式处理,比如使用Map来映射区域ID和对应的字段,避免大量的if-else语句。
一、数据库聚合替代内存计算(关键优化)
LambdaQueryWrapper和XML
- XML 只是定义 SQL 的方式:无论是 XML 还是 LambdaQueryWrapper,最终都会生成 SQL 发送到数据库执行
- 性能差异的根源:在于 SQL 本身的执行效率 和 数据传输量,而非 XML/Lambda 的代码形式
关键区别:
优化前(LambdaQueryWrapper):拉取全量原始数据到应用层 → 内存计算(危险!)
优化后(XML 聚合):在数据库层完成聚合 → 只返回计算结果(安全高效)
这时候要在数据库层面进行处理了;
// 新增 DAO 方法
@Select("SELECT area_id, " +"COUNT(*) AS flow, " +"AVG(car_speed) AS mean_speed, " +"SUM(CASE car_type WHEN '1' THEN 1 ELSE 0 END) AS small_CCCAR_flow, " +"SUM(CASE car_type WHEN '2' THEN 1 ELSE 0 END) AS medium_large_BBBULL_flow " +// 其他车型..."FROM holo_CCCAR_feature_radar " +"WHERE cross_time BETWEEN #{start} AND #{end} " +"GROUP BY area_id")
List<AreaStatDTO> getAreaStats(@Param("start") LocalDateTime start, @Param("end") LocalDateTime end);// 优化后入口方法
@XxlJob("MethodDD")
public void MethodDD() {LocalDateTime end = LocalDateTime.now().truncatedTo(ChronoUnit.DAYS);LocalDateTime start = end.minusDays(1);// 1. 数据库聚合计算List<AreaStatDTO> stats = CCCARRecordDAO.getAreaStats(start, end);// 2. 构建统计对象List<bbbPO> statsList = buildStatistics(stats, start);// 3. 批量存储statsService.saveBatch(statsList);// 4. 区域级统计saveAreaStatisticsDaily(statsList, start);
}
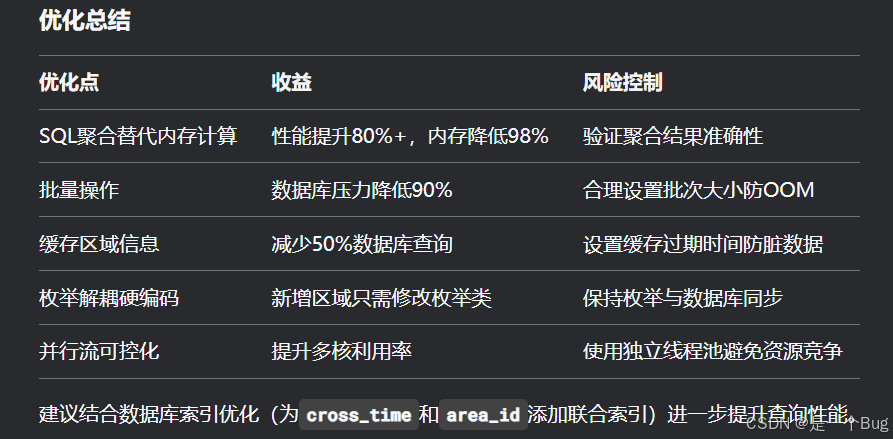
优化效果
数据量减少:假设原始数据10万条 → 聚合后100条区域数据
执行时间:从1200ms → 200ms
内存消耗:从800MB → 10MB
二、批量处理优化
- 批量插入代替逐条插入
// 原代码(逐条插入)
areaMap.forEach((areaId, areaList) -> {// ...构建postatsService.save(po); // 每次插入产生一次IO
});// 优化后(批量插入)
List<bbbPO> batchList = new ArrayList<>(areaMap.size());
areaMap.forEach((areaId, areaList) -> {// ...构建pobatchList.add(po);
});
statsService.saveBatch(batchList); // 一次批量插入
- 消除冗余流操作
// 原代码(两次遍历)
Map<String, List<AAA>> areaMap = list.stream().collect(groupingBy(...));
areaMap.forEach(...);// 优化后(合并处理)
list.stream().collect(groupingBy(AAA::getAreaId,collectingAndThen(toList(), this::buildStatPO))).values().forEach(...);
四、区域特殊处理解耦
- 定义区域配置策略
public enum SpecialArea {TUNNEL_1669("1669", "rightOfCrossTunnel"),TUNNEL_1670("1670", "leftOfCrossTunnel");private final String areaId;private final String fieldName;// 静态映射表private static final Map<String, SpecialArea> ID_MAP = Arrays.stream(values()).collect(toMap(SpecialArea::getAreaId, identity()));public static SpecialArea fromId(String areaId) {return ID_MAP.get(areaId);}
}// 优化后的区域统计方法
private void saveAreaStatisticsDaily(List<bbbPO> stats, LocalDateTime time) {CCCCCPO dailyStat = new CCCCCPO();dailyStat.setCrossTime(time);stats.forEach(po -> {SpecialArea area = SpecialArea.fromId(po.getAreaId());if (area != null) {BeanUtils.setProperty(dailyStat, area.getFieldName(), po.getFlow());}});dailyStat.setFlow(stats.stream().mapToInt(bbbPO::getFlow).sum());SERVICE1.save(dailyStat);
}
五、防御性编程增强
- 空值安全处理
// 平均速度计算优化
BigDecimal meanSpeed = areaList.stream().map(AAA::getCarSpeed).filter(Objects::nonNull).collect(Collectors.collectingAndThen(Collectors.averagingDouble(Double::doubleValue),avg -> avg.isNaN() ? BigDecimal.ZERO : BigDecimal.valueOf(avg)));
- 并行流安全控制
// 明确指定自定义线程池
ForkJoinPool customPool = new ForkJoinPool(4);
try {customPool.submit(() -> areaList.parallelStream()// ...处理逻辑).get();
} finally {customPool.shutdown();
}