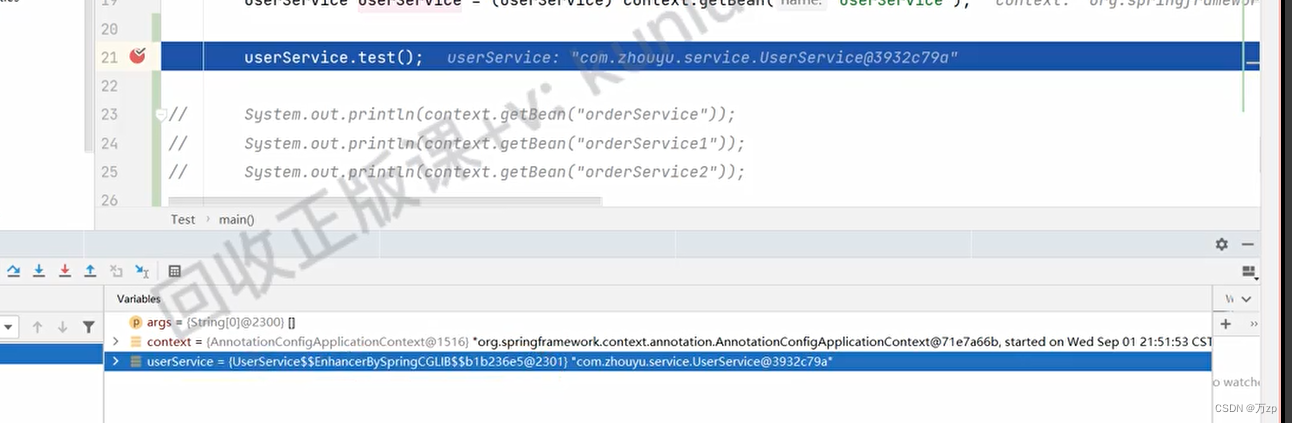
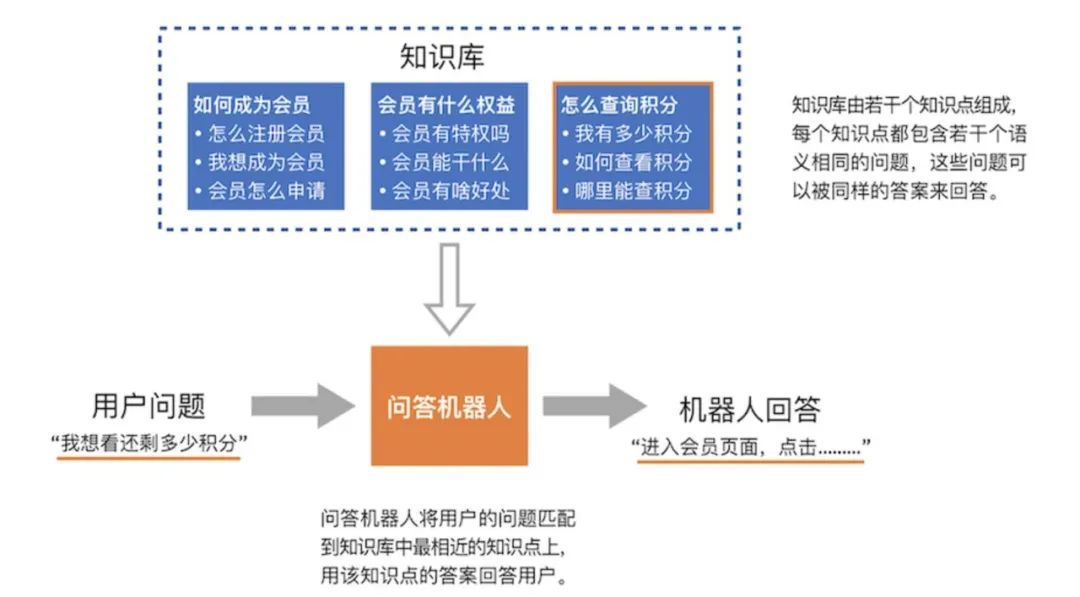
文章目录
- (近期想静下心回顾近期看的佳作,会写一下自己的总结,大家如果对此系列感兴趣,每周踢一下我,周更,持续更新)
- 0 前言
- 1 Automated deformation detection and interpretation using InSAR data and a multi-task ViT model(形变识别、注意力机制、模拟数据)
- 1.1 摘要
- 原文翻译
- 总结
- 1.2 引言
- 原文翻译
- 总结
- 1.3 方法(重点)
- 原文翻译
- (1)MT-ViT的结构
- (2)模拟训练数据
- (3)真实SAR数据
- (4)损失函数和评价指标
- (5)数据处理
- 总结
- 1.4 实验结果
- 原文翻译
- (1)模型训练
- (2)对比实验
- (3)桌面程序(新颖)
- 总结
- 1.5 讨论
- 原文翻译
- (1)模型结构的影响
- (2)模型架构的影响
- (3)patch大小的影响
- (4)池化层的影响
- (5)batch大小的影响
- (6)weighting factors on classification and localization的影响
- (7)attention maps的可视化
- (8)局限性和后续工作
- 总结
- 1.6 结论
- 1.7 数据可用
- 2 预告(相位解缠)
(近期想静下心回顾近期看的佳作,会写一下自己的总结,大家如果对此系列感兴趣,每周踢一下我,周更,持续更新)
0 前言
InSAR,合成孔径雷达干涉测量,是一种具有高精度观测潜质的影像大地测量学技术之一。 之所以说具备“潜质”,是因为InSAR的精度会受到成像过程中的路径延迟、数据处理过程中的解缠误差之类的影响,而无法达到预期的精度。这个问题并不新鲜,其实早在本世纪初,InSAR技术(尤其D-InSAR)初成体系时,就已经有许多学术大牛指出了这些问题。然而,指出也只是指出,直到现在任然没有一个团队或是个人,可以自豪的说:“劳资已克服了这些偏差,实现了无偏置的精密测量!”。至少博主目前没看到,如果有的话,我可能会狠狠地嘲笑他一番,如果嘲笑错了,那请他反方向嘲笑我,哈哈哈。

言归正传,其实,如果没有深度学习技术的催化,InSAR技术似乎已经被盖棺定论。 研究人员已经将改进InSAR的算法看做“天方夜谭”,更多的研究是通过已有技术来对地质现象(火山、地震、沉降、滑坡)进行机理解译。在我看来这似乎不是一项具有挑战性的工作。问题还在那,为什么不在继续探索并解决,现在对数据处理过程下定义是否太早了?再者,以深度学习为热点的“水文”越来越多,使得行业对于这项技术充满“怨念”。虽然博主是一个连所谓“一区TOP”都没发过的小菜鸡,但是,讲真的,博主想以后能有一个颠覆性的成果,改变领域内专家对于深度学习的看法。

但是,讲真的在做这项工作时,博主一直是在“探索”,以本人开展的“纯数据驱动来分离湍流相位”研究为例,博主已经尝试了11种数据合成方法,连续做了5个月的实验,但仍然没有突破性进展,可参考的文献微乎其微。 为了能在 卷成果 的时代存活本人也只能无奈在搞这些探索工作的同时,写一写“分割、探测、去噪、三维重建、字幕生成”等常规任务的文章。
既然,博主现在搞不出一些创新的工作,那就仅以此篇回顾一下这一年国际上对于深度学习和InSAR都讲了哪些故事,以及这些故事是如何打动“我们”的。(声明:本人对于任何已发表的学术论文都报以学习的态度,如果认识不到位,或者复现出的项目与实际项目存在差异,请批评指正。)
备注:更新节奏大概一周更新一个方向,如果长时间不更新,麻烦踢我一下,,有时可能比较忙,但是大概率是懒了。

1 Automated deformation detection and interpretation using InSAR data and a multi-task ViT model(形变识别、注意力机制、模拟数据)
第一项工作发表在JAG ([1] Abdallah M, Younis S, Wu S, et al. Automated deformation detection and interpretation using InSAR data and a multi-task ViT model[J]. International Journal of Applied Earth Observation and Geoinformation, 2024, 128: 103758. https://doi.org/10.1016/j.jag.2024.103758) ,这篇文章单位是香港理工大学 和 曼苏尔大学 。港理工作为InSAR届的泰斗级高校,这样一项富有挑战的工作出自他们也并不会让人感到意外。(最后一位更是,丁晓利老师,肃然起敬)。

这项工作的卖点我总结以下三点(在标题中我也写出了):形变识别、注意力机制、模拟数据。在这其中,通过模拟数据来识别现实场景的方式吸引了我。接触过深度学习的都会经历过做标签的过程,而现在有一篇文章告诉你,不做标签一样可以识别,是不是很兴奋?反正我是被爽到了。因为,我之前也开展过此类工作,没做出来(博主果然还是有点菜)。**看这篇文章的初衷也是想试试能不能从中获取灵感,把之前的工作捡起来。**所以,一起来学习一下吧。
1.1 摘要
原文翻译
许多地质灾害与地表变形 相关联。及时准确地检测和解释地表变形对于地质灾害的缓解至关重要。多时相干间合成孔径雷达(MT-InSAR) 是一种有效的大地测量技术,用于监测地表变形。然而,使用InSAR进行变形的准确计算和解释通常受到各种误差和专业知识不足 的限制。我们提出了一种基于Multi-Task Vision Transformer (MT-ViT) 的新型深度学习模型,用于自动检测、定位和解释单幅干涉图中的变形 。为解决InSAR应用中训练数据有限的问题,所提出的模型利用了光学图像的预训练 权重,并将其转移到模拟的InSAR数据集 中。然后,真实的干涉图用于微调 网络中的权重。设计了一个整体损失函数 ,考虑了模型中的分类和定位损失。所提出模型的有效性通过使用包含震后或火山 变形的模拟和真实的InSAR数据集进行了验证。模型的实验结果还与基于卷积神经网络(CNN)的现有技术进行了比较。结果显示,与基于CNN的方法相比,该模型在结果准确性和计算效率方面都有显著改善。MT-ViT模型达到了99.4%的分类准确率,54.1%的平均交并比(IOU) 和0.9公里的定位精度。对训练MT-ViT模型的超参数进行了全面评估,这将为未来研究提供参考。研究结果突显了MT-ViT在近实时变形监测和自动变形解释方面的潜在能力。
总结
读完摘要,这使得博主还是比较兴奋的,因为这项工作简直是我的梦中情工作。我们对这个工作进行简单的总结,大概一些这几点:首先,这篇文章的作者准确地抓住了MT-InSAR的痛点,误差多、且结果会极大受到调参的影响 ,这些作者也深有体会,在之前刚接触GAMMA的时候,简直每个结果奇形怪状,误差区域比比皆是。真实一段让人不想回忆的往事。其次,作者交代了一下这篇文章的主要工作,其实使用Transformer来分割单幅干涉图中的异常形变区域。 方法没有很吸引人,如果告诉我这只是在某个数据集上进行一个简单的测试工作的话,我认为这并不是一项值得认真阅读的工作。但是,我想说但是。吸引我的点来了,作者说:“光学预训练迁移到模拟InSAR数据集然后实现分割”,这就很梦幻了。首先,光学影像的识别一般是将其合称为三通道 彩色图像来进行识别(假彩色),而SAR数据一般由强度和振幅 构成,而作者这项工作针对MT-InSAR,那很大程度上会只用振幅也就是相位数据。那么问题就来了,把多通道的训练结果迁移到单通道,同时跨数据种类。这也太强了,至少在我看来,很梦幻。 随后,作者也介绍设计了一个损失函数,我觉得这并没有啥,可能此类文章看多了,,已经疲软。最后,看到IOU才54.1%,我又觉得我行了,如果这项工作可行的话,作者将是我一个方向的“恩人”。 不过,作为一个成熟的博士生,我还是压抑了一下自己激动地内心,调整了一下,我们接着往下看。
1.2 引言
原文翻译
地质灾害,包括地震、火山喷发、滑坡和地面沉降,对公众和关键基础设施构成重大风险。这些事件的影响已经得到广泛报道,突显了妥善应对地质灾害的重要性(Loughlin等,2015年)。在地质灾害发生之前,地表变形通常是可观察到的(Cicerone等,2009年)。及时监测和解释这种变形可以实现提前预警,并采取有益的措施应对地质灾害(Loughlin等,2015年;马等,2020年)。干涉合成孔径雷达(InSAR),尤其是多时相InSAR(MT-InSAR),已被广泛用于地表变形监测和地质灾害识别 (Sun等,2015年;Anantrasirichai等,2018年;吴等,2020年)。这种技术往往作为一种近实时的变形监测工具,尤其是随着现代SAR数据的提供,其重新访问频率和覆盖范围更广,如Sentinel-1 (Silva等,2021年)。然而,对大型InSAR数据集进行自动和及时处理仍然是一个重大挑战 (Anantrasirichai等,2019a年;Silva等,2021年)。此外,对InSAR和岩土工程领域的专业知识的缺乏也阻碍了对地表变形的及时解释(Anantrasirichai等,2018年;Rouet-Leduc等,2021年)。为解决这些问题,已经开发了各种方法,利用MT-InSAR检索变形测量,并采用不同的物理模型来理解地质灾害特征(Ansari等,2017年;王等,2020年)。尽管这些方法非常有用,但分析大量MT-InSAR干涉图进行全面的地表变形分析仍然耗时且具有挑战性。
机器学习(ML)技术的出现,如卷积神经网络(CNNs)和多任务学习(MTL),彻底改变了InSAR分析。 例如,一个显著的应用是通过将InSAR测量时间序列与独立分量分析(ICA)相结合,检测火山变形信号(Ebmeier,2016年;Gaddes等,2018年;Gaddes等,2019年)。编码器-解码器 架构已被用于识别微小的变形(Sun等,2020年)。CNNs已被用于分析累积位移,以识别单个Sentinel-1干涉图中的隐形变形信号(Anantrasirichai等,2019b年)。CNNs已被用于对火山喷发和地震事件相关的变形进行二分类,达到86%的分类准确率(Anantrasirichai等,2019a年;Brengman和Barnhart,2021年)。通过修改由牛津大学视觉几何组实验室开发的VGG16模型的全连接层,火山变形的分类准确率提高到95%,检测误差约为2公里(Gaddes等,2021年)。此外,多任务学习(MTL) 也已经得到发展,并与CNNs集成,通过训练单个模型同时执行多个相关任务 ,降低计算成本并提高训练效率(Ruder,2017年;Zhang和Yang,2018年)。
尽管CNN在InSAR数据的变形检测和解释方面取得了令人期待的结果,但这些模型所需的大量训练数据 仍然是一个挑战。然而,公开共享的InSAR结果通常具有有限的可用训练数据。研究人员已经探索了替代方法,例如使用预训练 模型(Anantrasirichai等,2018年;Gaddes等,2021年),模拟大型InSAR数据集(Brengman和Barnhart,2021年)和自监督学习技术(Bountos等,2022年)。另一方面,基于CNN的技术在变形检测的准确性方面也经常受到限制,由于缺乏考虑全局背景信息 (Bountos等,2022年),其准确性持续低于91%,这对于实现更高的准确性至关重要。
为了克服这两个问题,我们提出了一种改进的机器学习方法,基于ViT而不是CNN ,该模型利用自注意力机制来捕捉全局背景信息,这是一种在自然语言处理和计算机视觉任务中成功应用的技术(Vaswani等,2017年;Dosovitskiy等,2020年;Wang等,2022年)。为了增强在有限InSAR数据训练中的可靠性,所提出的方法被设计为一个两阶段模型 ,将在使用光学图像训练的模型的预训练权重转移到使用模拟InSAR数据集训练的模型上,然后再使用真实的SAR干涉图像对模型进行微调 。该模型结合了分类和定位损失以导出一个总损失函数 ,并包括一个池化层,用于同时对变形进行分类和定位。MT-ViT模型的有效性使用火山和震后 数据集进行评估,展示了该模型在基于单个干涉图同时检测、定位和解释地表变形模式方面的出色能力。对MT-ViT模型性能的超参数调整的全面调查进行,为使用基于ViT模型的变形解释的各种InSAR应用提供了参考。为了方便实际应用,我们开发了一个整合了训练好的MT-ViT模型的桌面应用程序,命名为SARViT,并且对公众免费开放。
论文的其余部分组织如下:模型的架构和训练过程将在第二节中介绍。第三节将呈现实验和结果。第四节将全面讨论MT-ViT的超参数,接着在第五节给出结论。
总结
总的来说,读完引言,感觉还是可以的,但是在这里作者并没有具体交代这些过程是如何实现的。因此,如果我们想知道他的研究思路还需要继续读下去。作者的新颖点不在模型 ,使用transformer在遥感图像解译上面并不是一个新鲜的话题 ,甚至模型还有点老。但是有些点还是挺让我兴奋的。引言总结为以下:作者以InSAR技术的重要性和局限性引出话题;随后指出深度学习技术可以弥补这些不足;然后指出当前此类研究的局限性(训练成本和对于全局信息的忽略);最后引出自己的工作。总的来说中规中矩,但是在最后,作者封装一个小程序还是蛮有意思的,这个我们也可以去学习,这似乎比将代码发布到github上有意思。
1.3 方法(重点)
本节将介绍MT-ViT模型的架构和训练过程,涵盖数据准备、损失函数、评估指标、数据处理以及用于训练和验证的拟合参数。
原文翻译
(1)MT-ViT的结构
MT-ViT的架构如图1(a)所示。它由patch embedding、transformer encoder和pooling layer组成。patch embedding包括将输入干涉图像分解为固定大小的patch。然后对patch进行breaking down、归一化和线性投影处理(Dosovitskiy等,2020年)。每个patch都输入一个可学习的位置嵌入,以向模型提供有关投影序列中patch位置的信息(Dosovitskiy等,2020年)。在每个序列的开头添加一个可训练的类嵌入,以嵌入分类特征。

图1. 提出的用于InSAR变形检测、定位和解释的MT-ViT模型的架构。 (a) Vision Transformer。 (b) Transformer Encoder。 © 多头注意力机制。 (d) 计算两个patch之间注意力的数学操作。
每个transformer encoder都包含一个多头注意力块和一个多层感知器神经网络(MLP),如图1(b)所示。多头注意力层由几个自注意模块的串联组成,可以同时处理所有内容,如图1(c)所示。自注意模块根据输入中所有特征向量之间的关系计算每个输入特征向量的一组注意力权重,使模型能够捕捉特征之间的长距离依赖关系和关系。在注意模块中,嵌入的patch被作为查询、键和值序列输入。查询和键表示经过点积矩阵乘法(即MatMul)生成一个表示两个嵌入patch之间注意力程度的评分矩阵,如图1(d)和公式(1)所示。评分矩阵通过一个缩放因子进行缩放,以确保在梯度计算中更稳定,因为乘法可能会产生爆炸效应。注意力分数通过softmax函数转换为概率,以驱动值矩阵提取重要信息并抑制不相关信息。MLP对受注意特征向量应用非线性变换(Dosovitskiy等人,2020)。
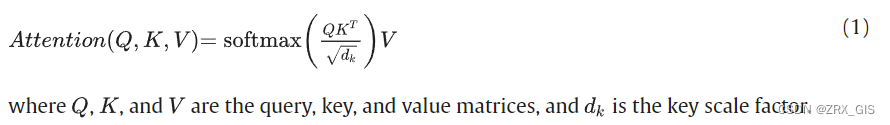
如图1(a)所示,在transformer encoder之后引入了一个pooling layer。不同的pooling layer已经被提出,包括Separate、Average和Flatten层。Separate层将嵌入分为类别和位置,计算嵌入的平均值,并将类别嵌入的输出分配给类别头,将位置嵌入分配给定位头。Average层计算嵌入的平均值,并将平均嵌入分配给分类头和定位头。Flatten层展开整个嵌入,并将展平的表示分配给分类头和定位头。汇聚层的输出是输入双MLP网络,第一个MLP网络的隐藏神经元表示类别数量,第二个MLP网络的隐藏神经元表示边界框的参数。
(2)模拟训练数据
为了训练MT-ViT模型,我们生成了一个庞大的模拟InSAR数据集,每个类别包含10万个干涉图(即火山和震源的变形分别为30万和40万个干涉图)。每个干涉图都包含了从变形信号、分层大气误差、湍流大气误差和轨道误差的线性组合中获取的解缠相位。火山变形源包括岩基和岩脉,而震源变形源包括倾滑、走滑和冲击断层。火山和震源活动的变形信号均来源于Okada模型的正向路径,具体的源参数如表1所示。模拟的变形被投影到了雷达的视线**(LOS)方向上,入射角在31至46度之间变化,并且对于Sentinal-1卫星的升轨和降轨**,方位角分别为**-12度和192度**。与地形相关的大气误差是从数字高程模型(DEM)中随机缩放获得。图2显示了用于模拟火山和震源数据集的对流层误差的空间分布。湍流大气误差是通过像素之间的空间相关性和随机更改相关长度获得的。轨道误差是使用线性斜坡方程模拟的。最后,得到的干涉图被随机遮盖,以模拟Sentinel-1干涉图的相关性。我们选择了信噪比阈值为2.0,以确保清晰的变形。对于火山变形,范围设置为0.05米到0.5米,而对于震源变形,范围设置为0.05米到1.5米。每个干涉图的标签是用于创建位移的变形源。矩形断层的中心与边界框的中心重合。边界框的长度和宽度会扩展到达到至少20%最大位移的像素为止。干涉图是基于SyInterferoPy生成器构建的,具有额外的特征。
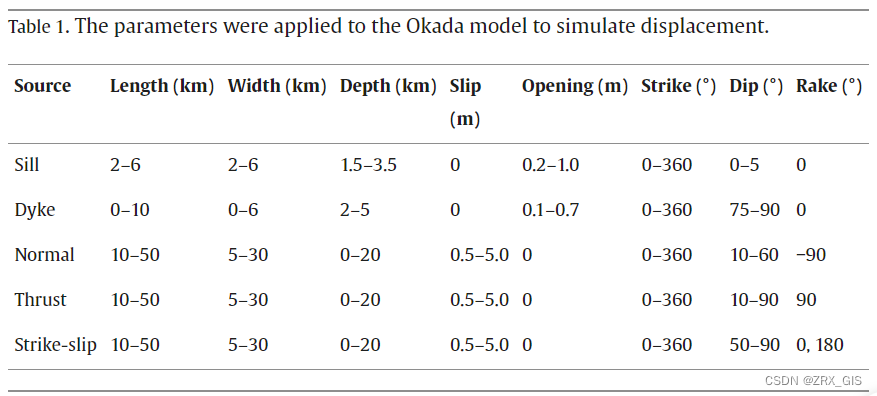
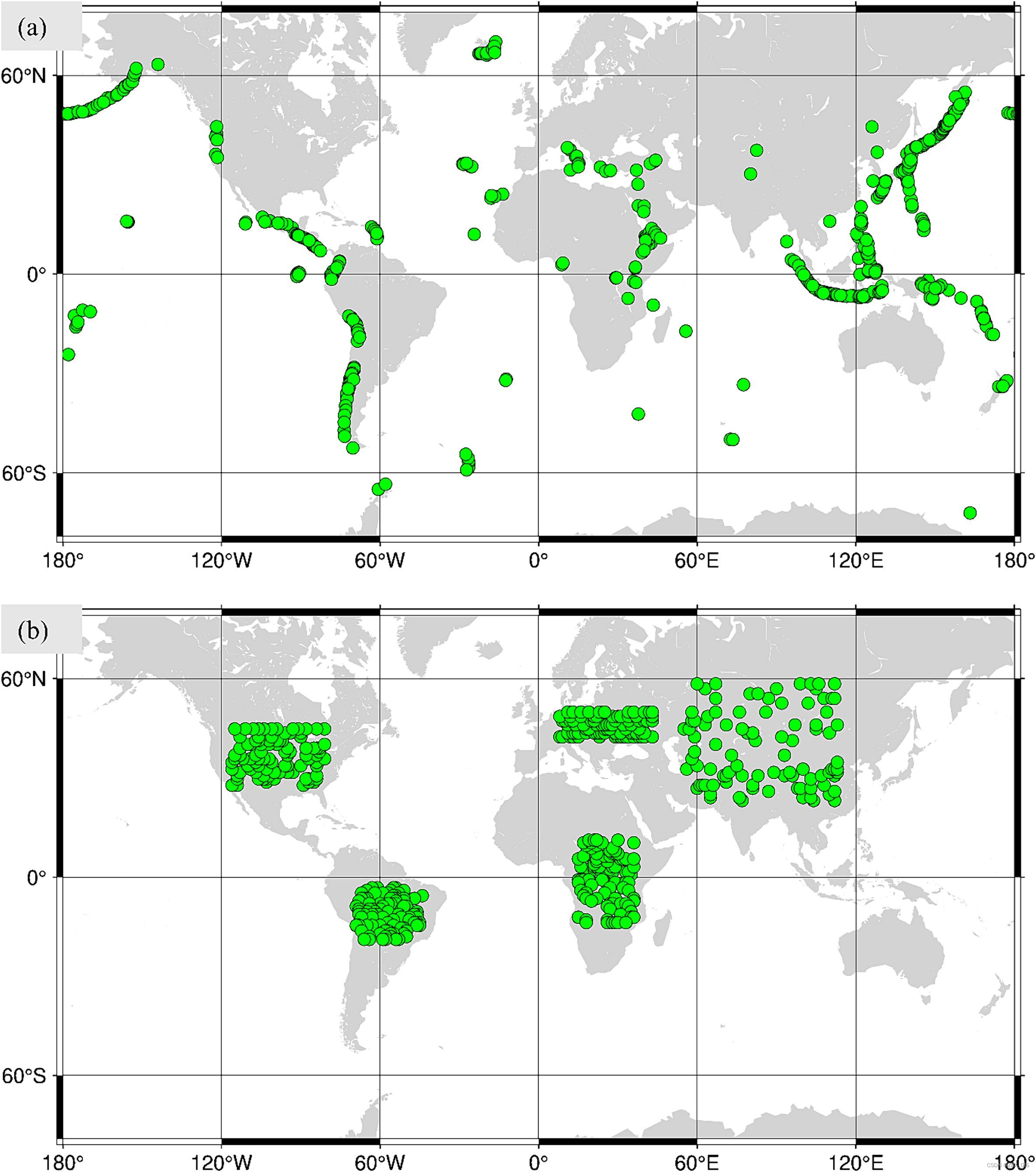
图2. 所选DEM的空间分布,用于随机生成地形相关的大气误差。每个绿色圆圈表示提取的DEM的中心。(a) 火山位置。 (b) 震源位置。
(3)真实SAR数据
公开可用的SAR火山数据集VolcNet也用于训练和测试MT-ViT模型。该数据集包含世界上最脆弱的火山地区的一系列干涉图,如图3所示。干涉图的数量约为500,000,其中仅有0.2%是岩浆火山。因此,该数据集存在不平衡的标签,如图3所示。每个时间序列中的变形持续时间和幅度也包括在内。所有可能的SAR采集组合都被用来创建干涉图。图4(a)展示了Wolf火山在2016年6月5日至6月23日之间生成的干涉图的示例。每个干涉图都标有现有的变形信号,并且变形像素被黑色边界框包围。图4(b)显示了与Wolf火山相同时期的火山信号的持续时间、幅度和类型。
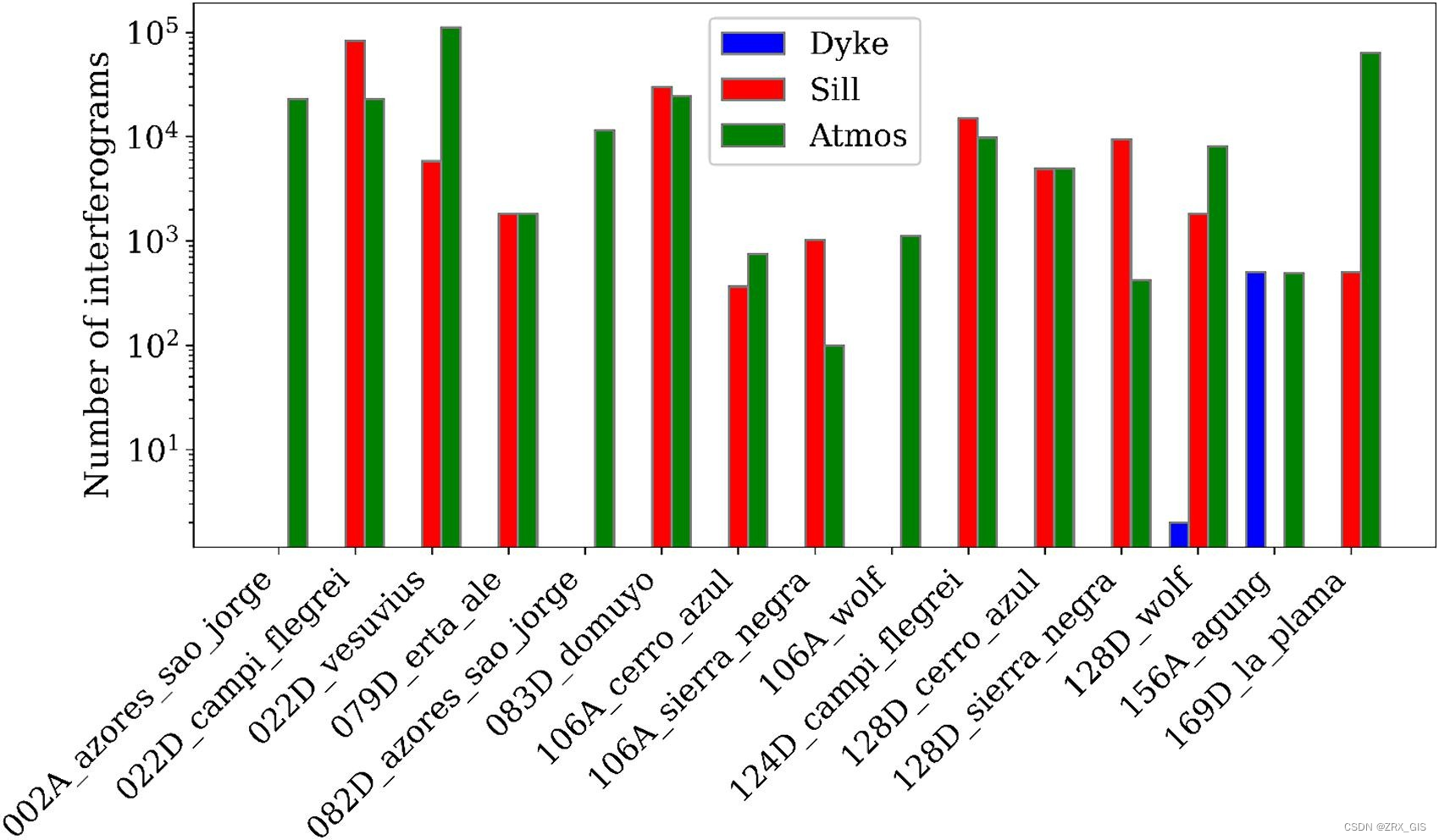
图3. 每个SAR采集时间序列生成的干涉图数量
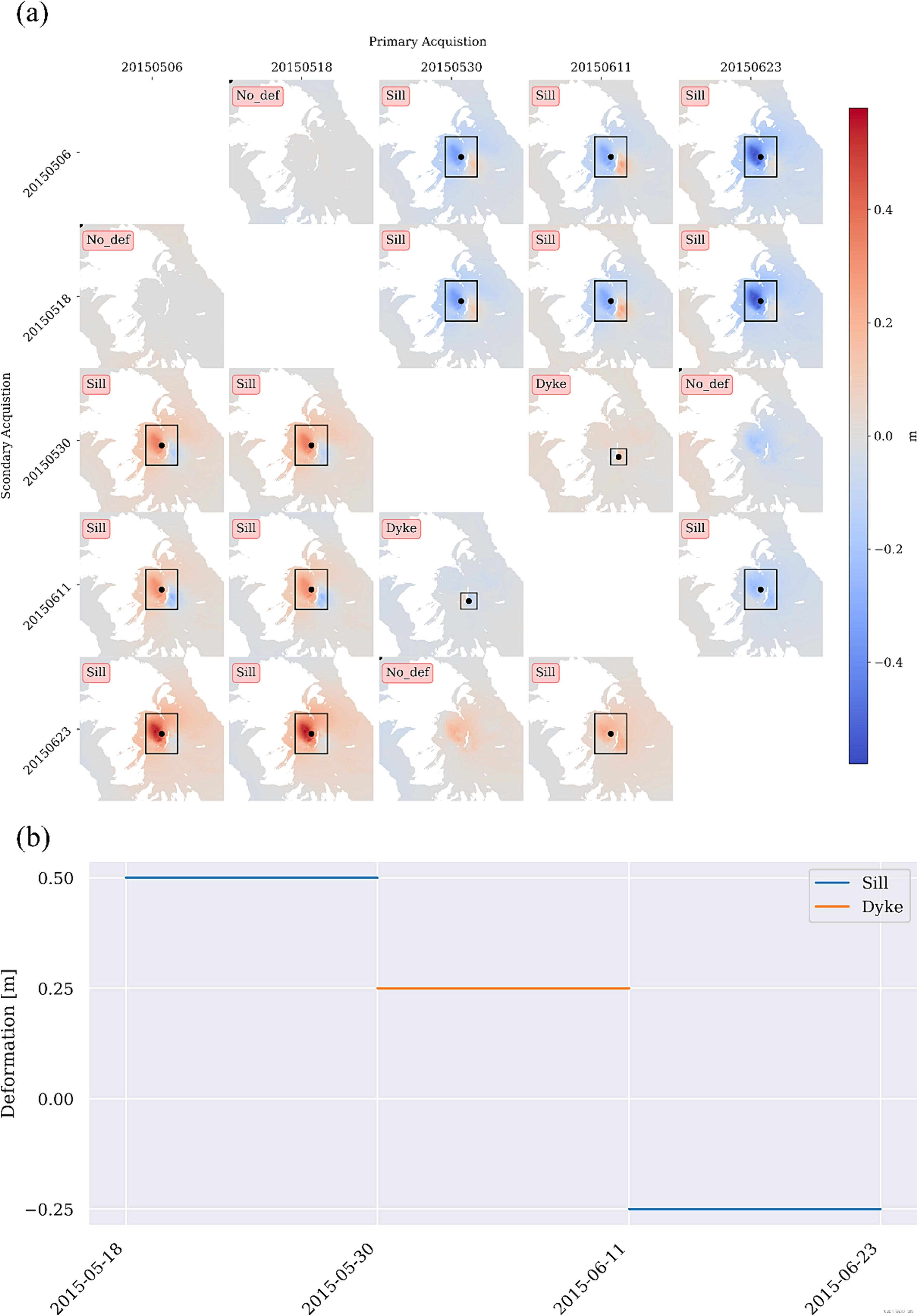
Fig. 4. Wolf Volcano生成的干涉图示例。 (a) Wolf Volcano在2016年6月5日至2016年6月23日期间Track 128D的所有可能SAR采集之间的干涉组合。位移出现在边界框内。 (b) 火山信号的幅度和类型。
此外,还生成了一些包含2016年至2021年期间一些著名地震的震后形变干涉图,如图5所示。选择了12、24和36天的时间基线来创建升降轨道的所有可能的干涉图。使用ISCE软件包(版本2.5,Roseu等,2012年)、three-arc-second SRTM DEM(Farr等,2007年)和精确轨道星历对干涉图进行处理。相位展开过程采用了最小成本流方法(Costantini,1998年)。共处理了27个干涉图,其中9个是纯噪声,其余18个包含震后形变(例如,5个倾滑断层、5个走滑断层和8个逆冲断层干涉图)。根据美国地质调查局(USGS,2022年)的报告,根据断层参数对每个干涉图进行了分类。每个干涉图是通过裁剪围绕形变模式的280×280像素区域创建的。
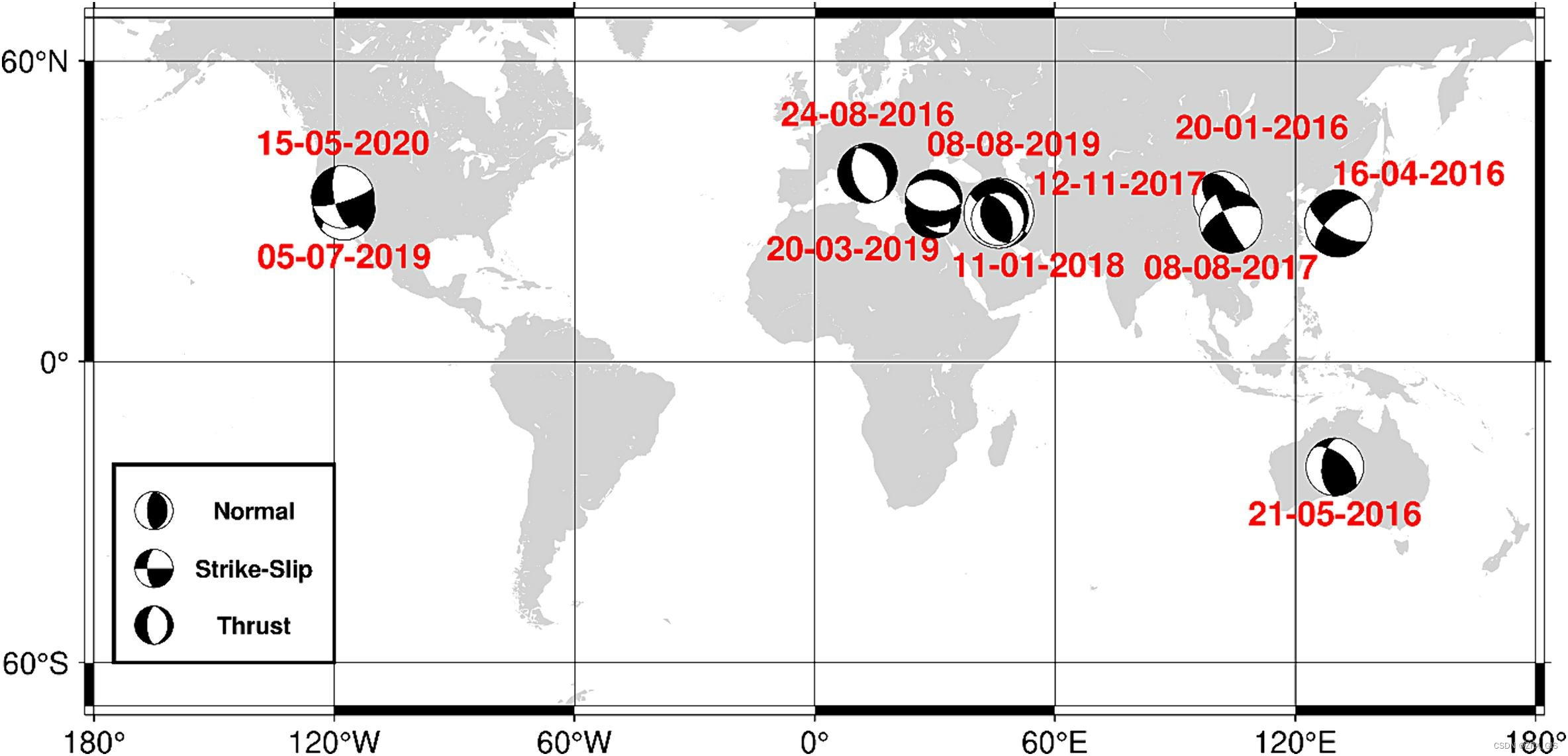
图5. 一些强震地震的分布,即在2016年至2020年期间强度超过5.2的地震,用于基于美国地质调查局(USGS,2022年)矩张报告的源参数检测震后形变的实验。
边界框的中心点放置在具有最大位移的像素处,而边界框的长度和宽度向外延伸到具有最大位移的像素的20%处,用于火山和震后形变。采用数据增强(DA)技术生成带有相关边界框的独特实际干涉图,同时保持相同的空间分辨率。增强的实际数据集包括火山和震后形变的30,000个和4,000个独特干涉图。Brengman和Barnhart(2021年)利用32个干涉图和数据增强生成了5,184个用于训练和1,152个用于验证的增强干涉图,然后用于对ResNet模型进行微调。
(4)损失函数和评价指标
MT-ViT模型集成了两个独立的头部,即分类头和定位头,分别用于解释形变信号的类型和位置。分类头通过softmax激活函数返回形变与特定类型形变源相关的概率,而定位头通过线性激活函数返回包含形变的边界框的长度、宽度和中心。分类头选择交叉熵(CE)损失函数,定位头选择均方误差(MSE)损失函数。整体精度(OA)和曲线下面积(AUC)用作分类头的评估指标,而平均绝对误差(MAE)和交并比(IoU)用作定位头的评估指标。表2总结了训练过程中使用的损失和度量函数的数学表达式。

(5)数据处理
为使数据与MT-ViT算法兼容,每个干涉图像中像素的展开相位被缩放到从**-1到1的范围内,而被屏蔽的像素被填充为0**,并且干涉图像被转换为单通道灰度张量。ViTs的预训练权重通过对通道维度的权重值进行平均调整以与干涉图像对齐。此外,还测试了不同的batch_size(8、16、32和64)和patch_size(16×16和32×32)以确定最佳值。这一点的详细讨论将在第4节中介绍。
ViT模型的训练分为两个阶段。第一阶段是在一个庞大的数据集上训练模型,典型的样本数量为1000万。第二阶段是在一个具有较少样本和变化的目标数据集上对已训练的权重进行微调。为了克服仅有有限的InSAR训练数据可用的挑战,我们在第一阶段利用了通过ImageNet21K(即1400万图像和21,843个类别)获得的ViTs的预训练权重。我们增加了一个转移阶段,将光学图像的预训练权重投影到InSAR数据域中。在第二阶段,MT-ViT模型的全连接部分在一个小型真实数据集上进行微调,其中80%用于训练,20%用于验证。CE和MSE损失函数的权重因子最初设定为1.0。然后探索了不同的权重因子(1.0、5.0、10.0和20.0)来优化模型性能。采用学习率为0.00002来防止权重扰动,并且实施了早停策略以防止过拟合并减少不必要的训练轮次。采用Adam优化器来最小化整体损失。训练是在具有16 GB内存的图形处理单元(GPU)上进行的,并在PyTorch框架中实现。
总结
有收获,但是意犹未尽。为啥没有展开讲一下如何“迁移”。博主真的很想学习一下。不过看着也很爽,就目前而言,但是整体方法部分写的有点单薄,可能是篇幅有限,是一个不错的思路,但是太概述了。回顾这部分的内容:作者先介绍MT-ViT的结构,大致上就是说这玩意由三部分构成(patch embedding、transformer encoder和pooling layer组成)。随后介绍模拟训练数据的合成。博主近期也在关注模拟数据的合成,但是就现在的模型表现而言,可以较好的完成模拟的测试集的各类下游任务,但是,无法应用在现实场景(是真的一点都不行,也可能博主采用的是纯卷积的网络,需要考虑下多头输入的这类注意力机制,慢慢来吧)。作者对数据模拟介绍的较为粗略,估计大概率是直接用的某个大佬之前的数据模拟框架,后续博主会进一步追踪参考文献。然后,作者介绍了自己用到的两个公开的数据集SAR火山数据集VolcNet和ImageNet21K,博主第一次听这两个数据集,也会进一步追踪。当然这部分还介绍了一些其他:损失函数、评价指标以及一些超参数的配置啥的,emmm,有点刷工作量的意思,,就不在这里赘述了。(不过看完这一部分,我其实对这篇文章的心情减半了很多,因为这是一项目标检测的工作,,有时我在想,你通过目标检测标注出了形变区域,但那有如何?我们似乎更关注的是形变的准确形变场以及边界,可能在我理解,去噪和分割任务才是这个领域最需要的。)
1.4 实验结果
原文翻译
在本节中,我们进行了一个实验,比较了CNN和提出的ViT模型在解释和定位火山和震后变形方面的性能。
(1)模型训练
MT-ViT模型分别使用火山和震后数据集进行训练,考虑到受影响区域的不同大小和变形的幅度。*震后变形的区域需要延伸到数十公里以包括整个变形区域(Zhao等,2021年)。因此,火山变形和震后变形的空间分辨率分别约为92米和490米。
为评估所提出的两阶段训练策略,我们首先使用模拟火山数据集 和 小型ViT架构(16×16的patch_size和平均池化层)进行训练。 然后,通过真实数据集对模型进行微调,结果显示性能不佳,OA和IoU分别低于60%和30%,主要是由于受限于模拟数据集规模,无法捕捉干涉图的注意力特征。相比之下,在第一阶段,我们使用了通过ImageNet21K数据集获得的ViTs的预训练权重。在转移阶段,每个模型都根据模拟数据集进行调整,以适应InSAR领域的预训练注意力。经过第一轮迭代后,OA显著提高至96.7%,而IoU并未超过5%,因为ViTs仅用于图像分类。在训练过程结束后,所有结果已总结在表3中。通过所提出的两阶段训练策略,模拟和真实火山数据集的最佳OA和IoU分别为99.4%和54.1%,并且在17和11轮迭代后分别实现了最低验证损失。
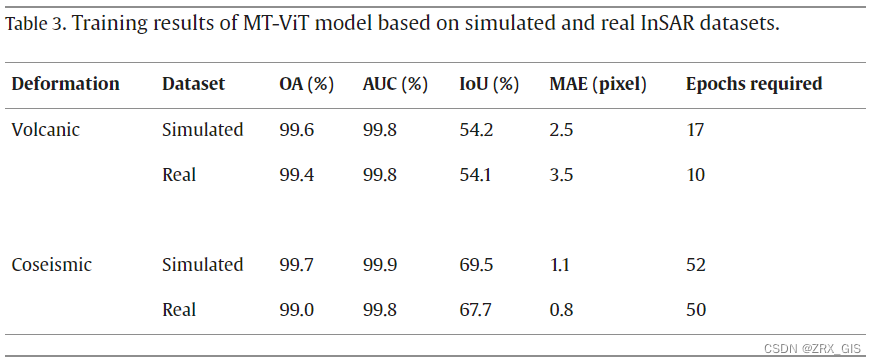
根据(Gaddes等人,2021)的先前研究,模拟更真实的InSAR数据集可以减少强大气信号引起的误分类。表3显示,实际数据集和模拟数据集的结果之间没有显著差异,表明在本研究中模拟和使用了地震和火山信号的正确性。当比较不同的变形特征,如火山和地震变形时,IoU从54.1%提高到67.7%,表明与火山变形相比,模型在定位地震变形方面表现更好。受影响区域更大以及与地震事件相关的变形有助于产生这种性能差异。地震变形的定位精度优于火山变形,定位误差保持不变,即小于1公里。变形定位的轻微差异可能是由边界计算过程和边界框的增广引起的。Brengman和Barnhart(2021)在采用两个不同通道(例如缠绕和解缠相位数据)时报告了85%的总体准确率,这些数据可能由于解缠错误而不对齐。当他们将声明合并到迁移学习中时,遇到了训练失败,导致准确率从99.7%降低到93.6%。为了解决这个问题,我们用零替换了随机像素的相关性,提高了结果的稳定性。
为进行可视化分析,我们在图6(a-c)、(d-f)和(g-i)中展示了一些火山变形检测结果的示例,这些示例包含了火山岩脉、底面/点变形和大气信号。模型在分类和定位上正确区分了大气信号。模型能够正确分类和定位变形信号。变形信号成功地被分类和定位,但在预测的变形区域和地面真实情况之间存在一些差异。经过使用真实数据集对模型进行微调后,模型能够正确分类真实干涉图中的大气伪影和变形信号,如图7所示。预测的分类头和定位头高度一致,与VUDL-NET-21模型相比表现出改进,后者在一些其他像素周围绘制边界框时预测大气信号(Gaddes等人,2021)。即使在低相干性干涉图中,提出的方法也能准确识别火山岩脉信号,如图7(c)所示。
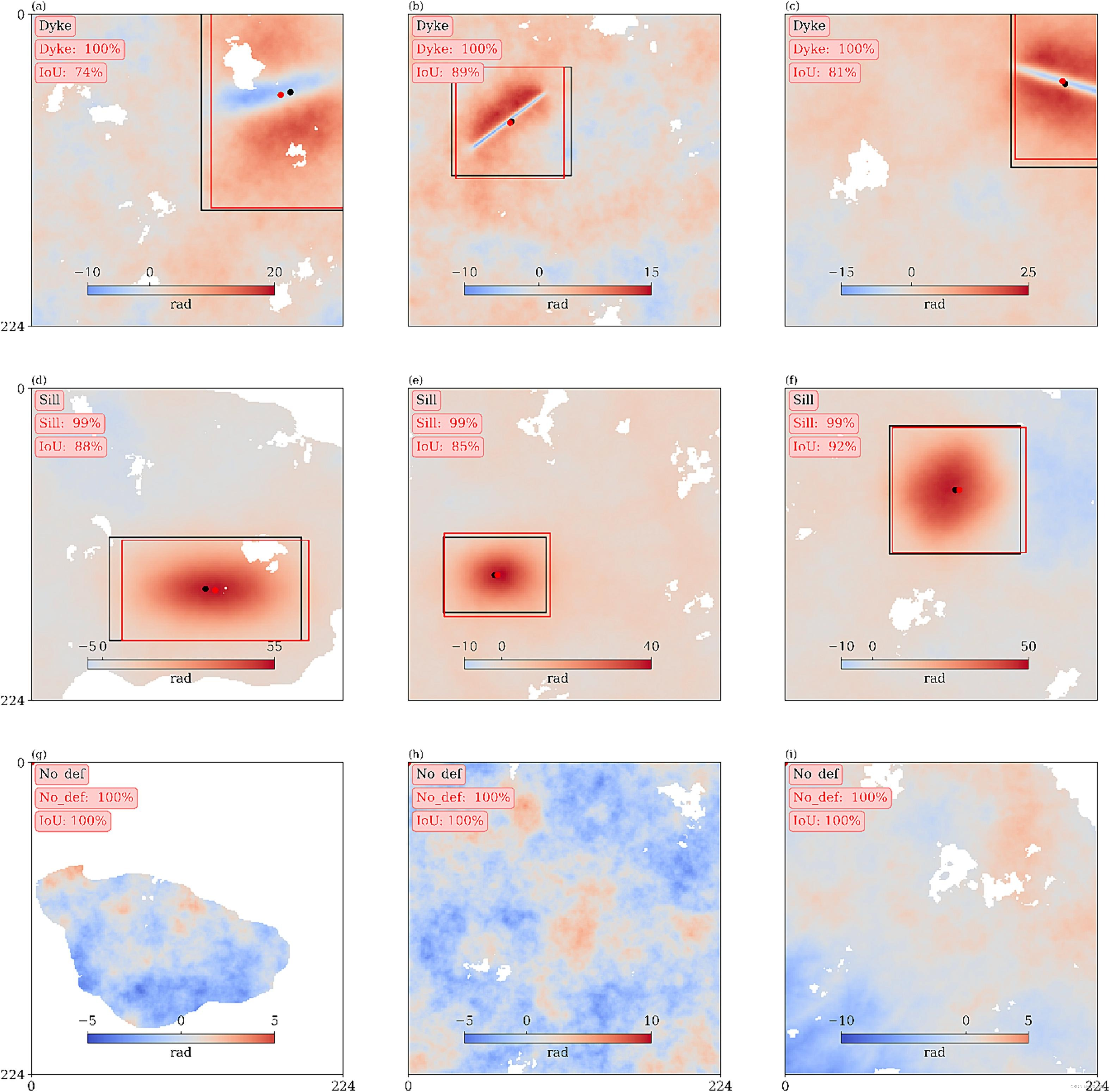
Fig. 6. 模拟InSAR数据集的检测和定位结果。第一行显示了三个包含火山岩脉的干涉图。第二行是包含底面的干涉图。第三行是包含大气信号的干涉图。地面真实信号及其边界框为黑色。预测信号的IoU和边界框为红色。边界框越大,定位误差越大。
Fig. 7. 火山变形分类和定位的结果,来自真实InSAR数据集(VolcNet)的样本。第一行显示了三个包含火山岩脉的干涉图。第二行是包含底面的干涉图。第三行是包含大气信号的干涉图。地面真实信号及其边界框为黑色。预测信号,IoU和边界框为红色。边界框越大,定位误差越大。
为了评估MT-ViT模型在区分火山喷发和大气延迟方面的能力,对涵盖各种火山的真实InSAR数据集进行了分析。图8展示了一些实验结果。可以观察到,除了Cerro Azul火山上的变形区域(如图8(d)所示)外,所有火山变形都被准确地定位,并且具有高精度。这种误判可能是由于模型被大气延迟所误导。为了进一步检查,图9展示了一个名为Wolf的火山的详细实验结果。显示了由SAR采集产生的所有干涉图对,表明了在所有干涉图对上的分类准确性,除了其中的三个。这包括2015/05/06–2015/05/18的干涉图,被错误地解释为底部/点变形,以及与2015/05/18和2015/05/06生成的干涉图,被识别为大气信号,因为火山喷发始于5月25日(2015年),以及与2015/05/30和2015/06/23生成的干涉图,被识别为底部信号。De Novellis等人(2017年)指出了Wolf火山在喷发活动期间在6月-7月发生的第二阶段变形。图4显示,该变形的幅度(即5厘米)倾向于是底部/点类型的。因此,所提出的模型还能够检测和定位后事件的变形。

Fig. 8. 来自真实InSAR数据集(VolcNet)的分类和定位结果。(a) 阿贡火山。(b) 亚速尔圣乔治火山。© 弗莱格雷山火山。(d) 塞罗阿苏尔火山。(e) 多穆约火山。(f) 埃尔塔艾勒火山。(g) 拉帕尔马火山。(h) 西耶拉内格拉火山。(i) 维苏威火山。(j) 沃尔夫火山。(k) 沃尔夫火山。(l) 沃尔夫火山。
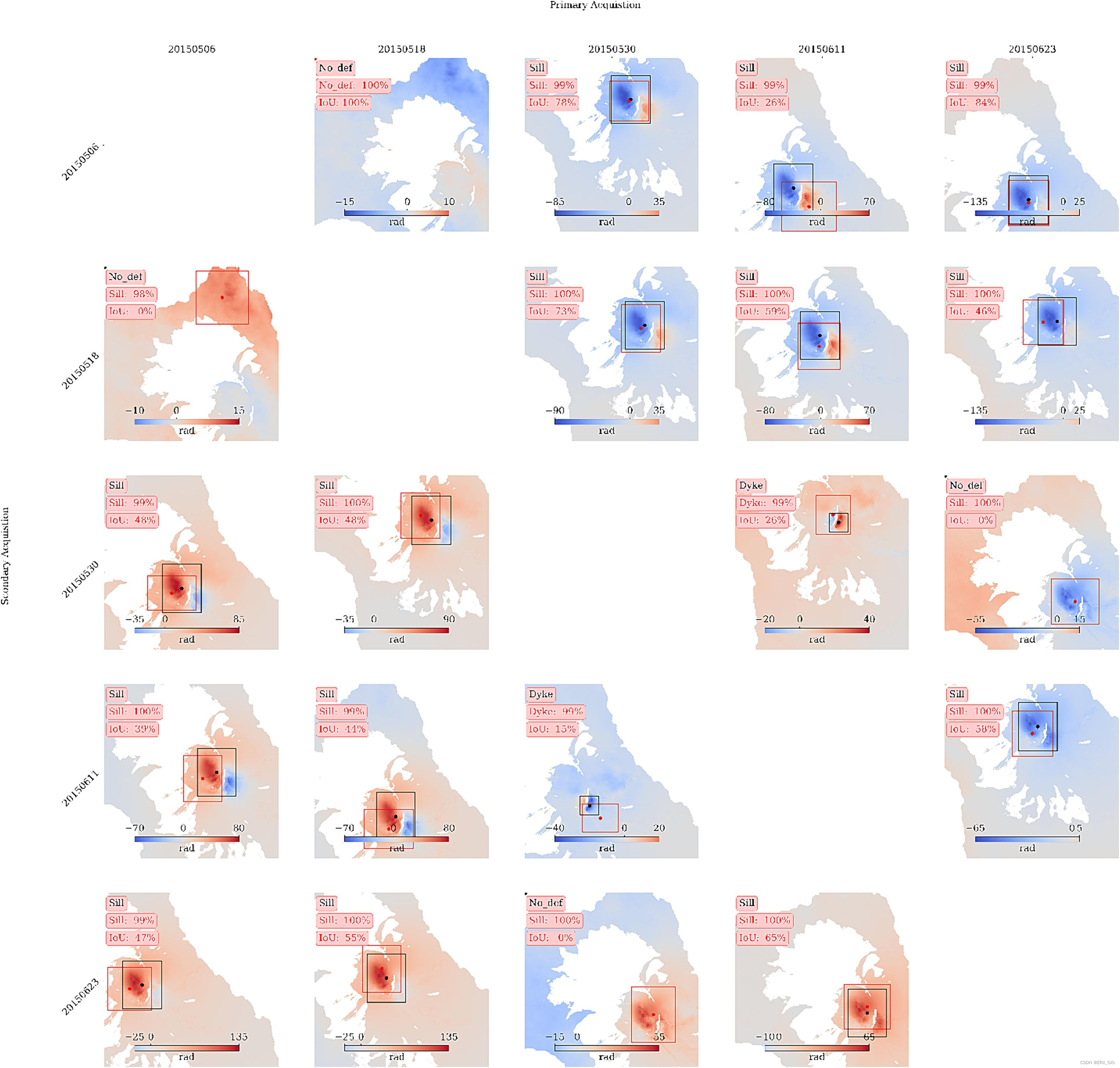
Fig. 9. 在2016年5月6日至6月23日期间使用轨道128D的所有SAR采集的所有可能组合的分类和定位结果,涵盖了沃尔夫火山。
同样地,图10展示了使用模拟的具有震后变形的干涉图的实验结果。交并比达到了约70%,定位误差为1.1公里。如图11所示,定位准确性几乎与真实干涉图相同。这表明增加真实干涉图的数量对于更稳健的微调是必要的,但干涉过程和准确标记是labor-intensive的。

Fig. 10. 使用模拟InSAR数据集进行分类和定位的结果。第一行是具有大气信号的干涉图。第二行显示包含正断层变形的干涉图。第三行给出包含走滑断层变形的干涉图。第四行包含包含逆冲断层变形的干涉图。地面真实信号及其边界框为黑色。预测信号、交并比及其边界框为红色。边界框越大,定位误差越显著。

图11. 使用真实InSAR数据集的分类和定位结果。第一行显示具有大气信号的干涉图。第二行是包含正断层变形的干涉图。第三行给出包含走滑断层变形的干涉图。第四行包含包含逆冲断层变形的干涉图。地面真实信号及其边界框为黑色。预测信号、交并比及其变形信号的边界框为红色。边界框越大,定位误差越显著。
(2)对比实验
为验证所提方法的有效性,我们进行了与Gaddes等人(2021年)的比较实验。他们更新了VGG16模型的全连接部分,并利用迁移学习保持卷积部分的权重不变,从而创建了一个MT-CNN。比较结果总结如表4所示。就可训练参数数量而言,全连接部分几乎是卷积部分的四倍,这是由于干涉图与光学图像之间特征的差异造成的。相比之下,MT-ViT的自由参数大约是MT-CNN的三分之一。在分类和定位准确性方面,MT-ViT分别显示了4%和50%的改善。定位误差减少了一半,当使用90米的SRTM时,10个像素对应约0.9公里。
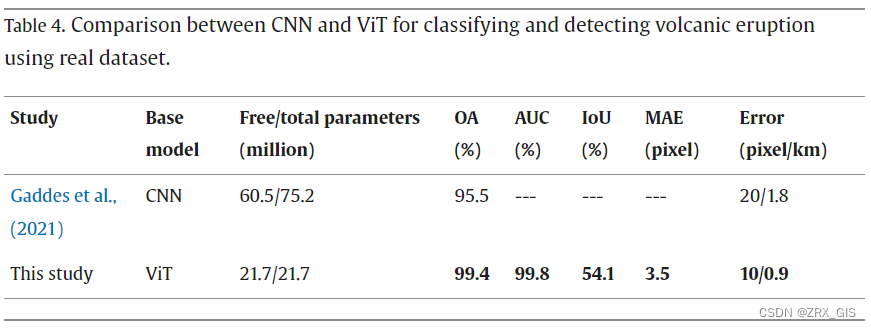
**为评估计算负载,对ResNet模型(He等,2016年)进行了修改,以执行多任务处理,并与提出的MT-ViT模型进行了比较。**更具体地说,所有实验都利用了在光学图像训练中获得的预训练权重,没有进行任何调整。ResNet模型有1350万个自由参数,其中3600个位于全连接部分。利用模拟干涉图对其进行了重新训练,并使用真实干涉图进行了微调。微调过程从仅使全连接部分可训练开始。ResNet-34的微调过程如图12所示。在每个步骤中,我们将连接的残差块的状态更改为可训练,直到达到第一个卷积块。比较结果总结如表5所示。当使用模拟数据时,CNN模型的表现优于ViT模型,而当使用真实数据时,其性能下降。当使用MT-ViT模型和真实数据时,分类和定位准确性分别提高了1%和12%。值得注意的是,如图12所示,IoU不受所使用的可训练参数的影响,并且始终低于50%。
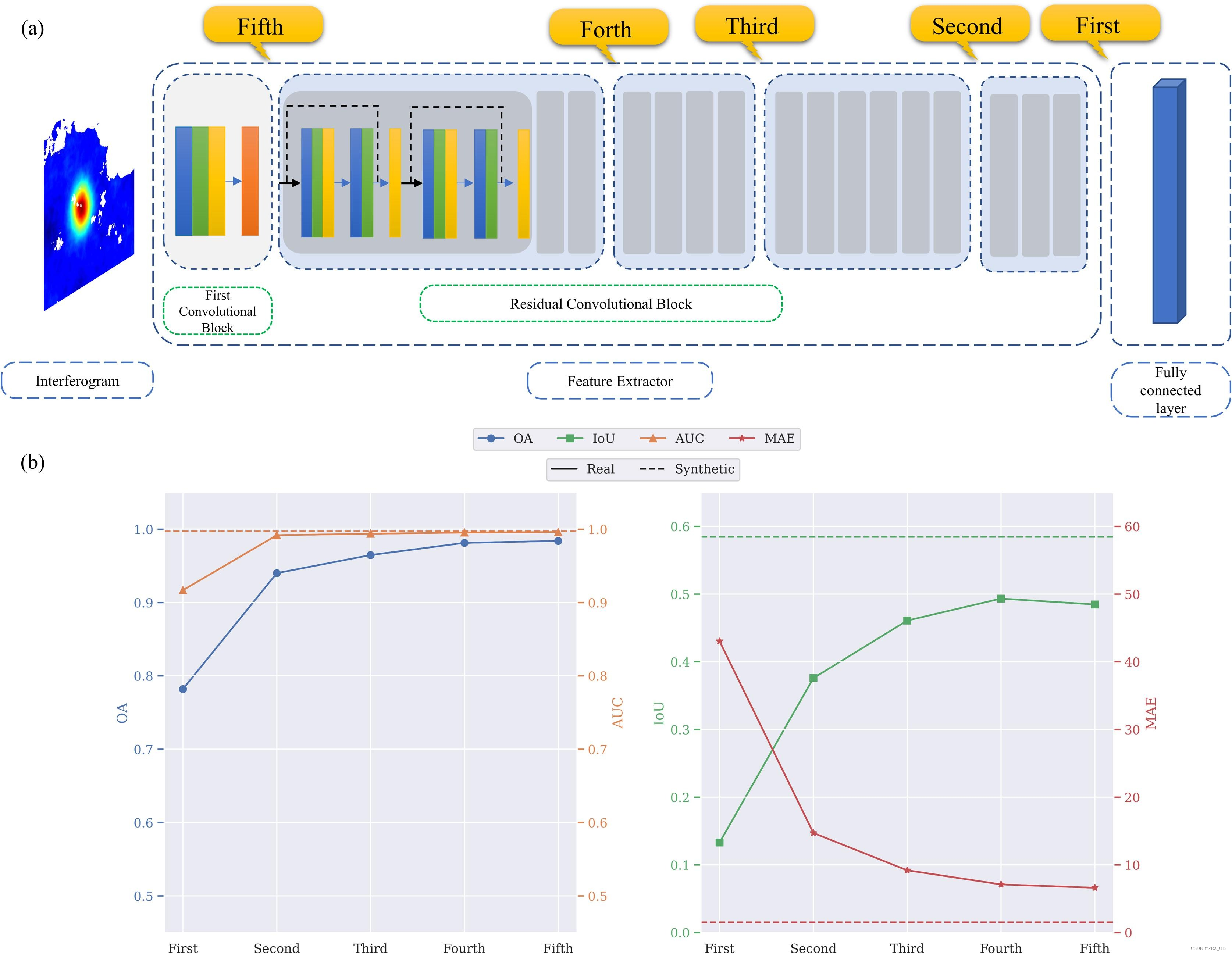
Fig. 12. ResNet-34的微调过程。 (a) ResNet-34的示意设计。 (b) 每个步骤的评估指标。 模拟数据的结果以虚线显示,而真实数据以实线显示。

(3)桌面程序(新颖)
基于本研究进行的训练,我们开发了一个桌面应用程序,采用Qt框架,将其作为免费应用程序共享。 可以通过以下链接访问:https://github.com/m-elhussieny/GeohazardLab。 应用程序的示意设计如图13所示。 用户需要选择变形类型(即,震后或火山)和输入数据(即,真实或合成)。 除了ViT架构外,它还支持ResNet模型。 用户可以从本地磁盘中选择干涉图。 应用程序可以显示正在研究的干涉图,分类标签和围绕变形区域的边界框。

总结
作者这一部分的工作还是让人眼前一亮的,很细致并且还有具体的应用。不过很可惜的一点,没有提供代码的源码,而是提供了一个编码后的小程序,,也许作者是想再发几篇或是做的在成熟之后来发布服务(也许吧)。
1.5 讨论
原文翻译
在本节中,我们将基于VolcNet数据集分析影响所提出模型的关键因素,包括架构选择、patch大小、池化层、batch大小和权重因子。
(1)模型结构的影响
可用的具有ImageNet权重的架构包括ViT(Dosovitskiy等人,2020)、ConViT(d’Ascoli等人,2022)、DeiT(Touvron等人,2021)、Swin(Liu等人,2021)、ResNet(He等人,2016)、VGG(Simonyan和Zisserman,2015)、Inception(Szegedy等人,2015)、DenseNet(Huang等人,2017)和ConvNext(Liu等人,2022),如图14所示。ViT和VGG架构在两个阶段表现出类似的性能。因此,ViT可以作为一个分类器,仅使用ImageNet权重而不进行修改。然而,ResNet架构并不适用于这个数据集。我们观察到,分类准确率提高了2%至8%,定位准确率提高了25%至40%。定性地,图15中的t-SNE图清楚地展示了将ImageNet权重转移至模拟数据的影响,使模型能够准确地区分负样本。尽管自监督学习在利用未标记数据增强特征提取器权重方面显示出巨大潜力,但需要一个大批量大小来包含足够的正负样本。对于这项研究,我们可能无法满足这种资源需求。

Fig. 14. 在VolcNet数据集上不同架构的性能比较,利用ImageNet权重转移到模拟数据集。基于ViT的模型用圆圈表示,而基于CNN的模型用方块表示。较小的形状表示使用ImageNet权重进行微调的模型,而较大的形状表示使用更新后的ImageNet权重进行微调的模型。
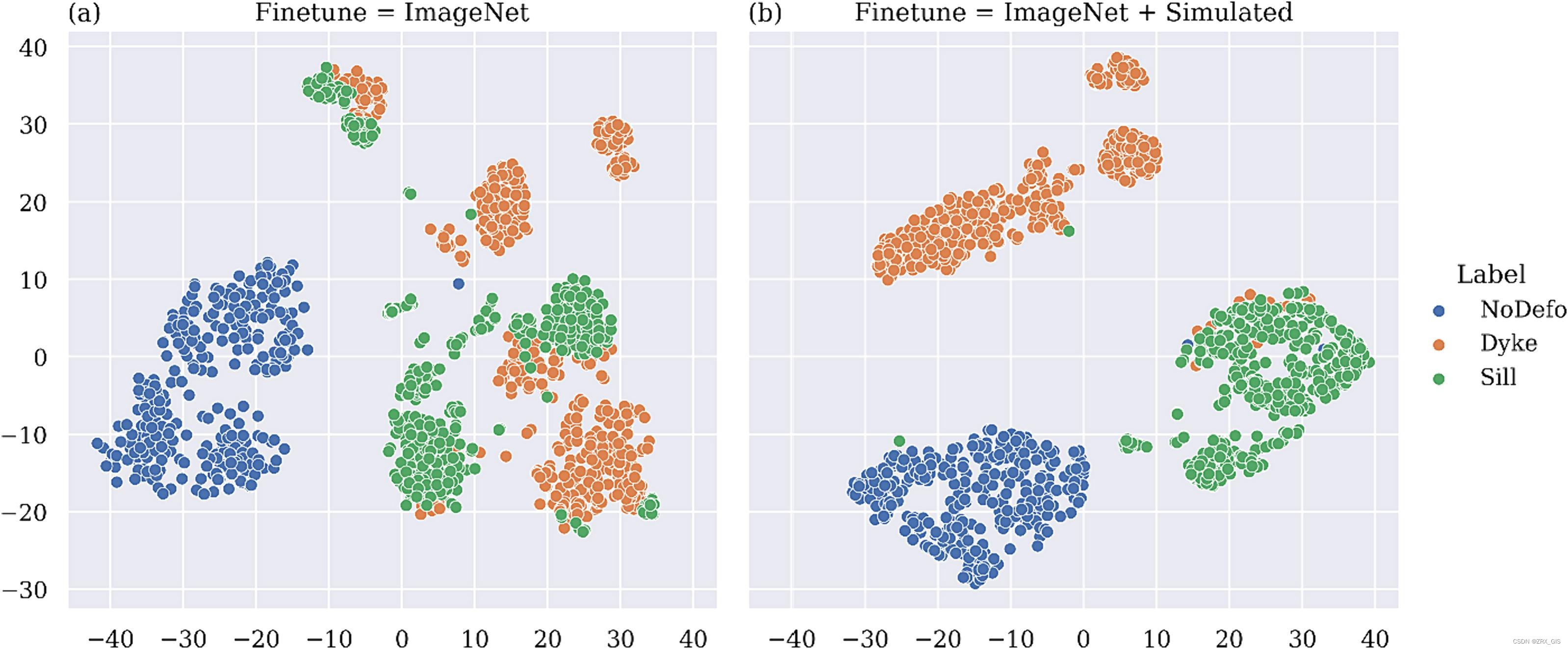
Fig. 15. 在VolcNet数据集上使用小型ViT模型进行t-sne比较,其中模型分别使用了ImageNet权重进行微调以及使用模拟数据更新的ImageNet权重。
(2)模型架构的影响
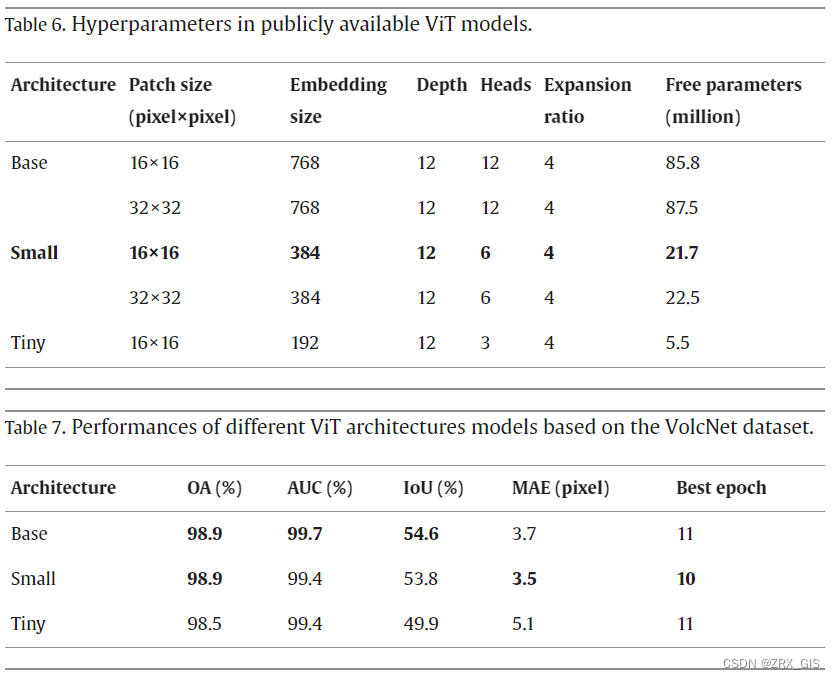
为了测试模型架构的影响,我们使用了公开可用的 ViT 模型,包括 Base、Small 和 Tiny 模型,这些模型已在表 6 中进行了总结(Dosovitskiy et al., 2020; Steiner et al., 2021)。所有模型具有相同的层(深度),但在多头注意力机制中具有不同的嵌入大小和头数。Base 模型的可训练参数数量是 Small 模型的四倍,是 Tiny 模型的十六倍。每个模型都以三通道张量作为输入,其中每个干涉图都被视为一个单通道张量。因此,patch投影层中的预训练权重在通道维度上进行了平均。模型性能比较结果见表 7。所有模型的总体准确率(OA)几乎相同,而 IoU 的最大差异为 4.7%。有趣的是,与 Base 模型相比,Small 模型在准确率方面达到了相同的OA,但在 MAE 方面提升了 5.5%,并且训练时间减少了 9%。
(3)patch大小的影响
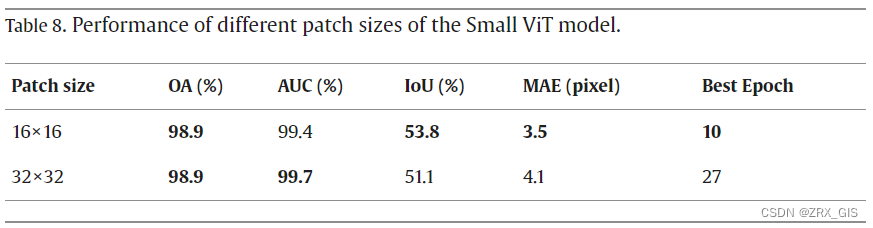
我们使用了具有 16 × 16 或 32 × 32 像素的patch大小的 Small 模型。增加patch大小降低了patch之间注意力的计算成本,并导致整体计算成本的增加。这两种patch大小之间的主要区别在于patch嵌入层和patch投影层中的可训练参数数量。投影滤波器的形状为(嵌入大小,通道数,patch大小,patch大小),而嵌入的patch的形状为(patch数量,嵌入大小)。将 224 × 224 干涉图分割成 16 × 16 的patch会产生 14 × 14 的patch,而将patch大小增加到 32 × 32 则产生 7 × 7 的patch。将patch大小从 16 × 16 增加到 32 × 32 会增加可训练参数(见表 6),但结果只显示 AUC 值略微提高(见表 8)。具有 16 × 16 patch大小的 Small ViT 模型显示出 IoU 增强了 5.3%,MAE 提高了 14.6%,训练时间减少了 62.9%。
(4)池化层的影响
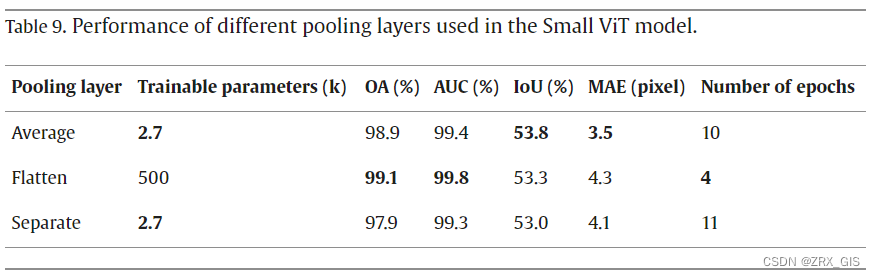
为评估不同池化层的影响,我们在变换器编码器后添加了一个池化层来调整表示流。我们使用了三种类型的池化层,即 Flatten 层、Separate 层和Average 层。根据表 9 中呈现的结果,发现 Flatten 层在分类任务中表现最佳。可训练参数约为 Separate 层和 Average 层的 185 倍。另一方面,Average 层在定位任务中表现最佳。尽管 Flatten 层所需的训练周期最少,但计算成本,即可训练参数增加,如表 9 中所示。考虑到 Average 层在定位任务中的优越性能、在分类任务中的可比性能以及更低的计算成本,下文将进一步讨论 Average 层。
(5)batch大小的影响
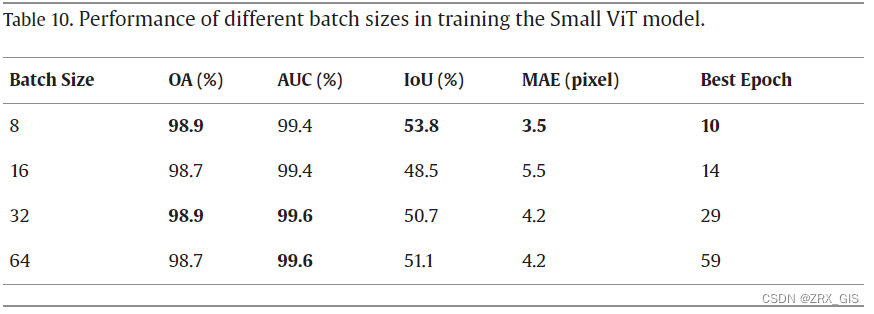
普遍认为,使用较大的批量大小可以减少并行 GPU 的计算时间。然而,这种做法可能会导致泛化性能较差。为了评估在训练过程中批量大小的影响,我们采用了批量大小为 8、16、32 和 64 个干涉图像来训练具有平均池化层和 16 × 16 的小型 ViT 模型。由于 GPU 内存的限制,我们无法使用超过 64 个干涉图像的批量大小。当批量大小超过 8 个干涉图像时,IoU 和 MAE 均降低至 50 % 以下,然后开始上升。与标准批量大小为 32 相比,批量大小为 8 的模型在 IoU、MAE 和训练时间上的表现分别提高了 6.1 %、16.7 % 和 65.5 %,如表 10 所总结的。
(6)weighting factors on classification and localization的影响
为了使 MT-ViT 模型能够同时对火山喷发信号进行分类和定位,采用了一种组合损失函数,该函数由 CE 损失和 MSE 损失的加权线性组合构成。表 11 表明,当 MSE 损失的权重因子固定为 1.0 时,增加 CE 损失的权重因子对分类和定位性能都有积极影响。相反,当 CE 损失的权重因子固定为 1.0 时,增加 MSE 损失的权重因子对性能有负面影响。通过将 CE 损失和 MSE 损失的权重因子分别设定为 20.0 和 1.0,与使用相等权重相比,OA、AUC、IoU、MAE 和训练时间的性能分别提高了 0.5 %、0.4 %、0.7 %、0.0 % 和 -20 %。我们的实验结果表明,最佳因子的选择与 Gaddes 等人 (2021) 在 CNN 模型中建议的因子不同,后者建议分类损失和定位损失的权重因子分别为 1000.0 和 1.0。建议使用 1000:1 的权重因子可以提高分类准确性,但相对于使用相等权重,会降低定位准确性。

然而,尽管 MT-ViT 能够对干涉图中呈现的变形信号进行分类,但平均 IoU 仍然需要改善。如果变形的位置是 MT-ViT 模型的关注重点,那么平均 IoU 可以进一步提高到约 63%。考虑到火山喷发引起的受影响区域可能延伸到几十公里,我们将 0.9 公里的位置误差视为可接受的精度,因此提出的 MT-ViT 可以作为定位变形的自动工具。
(7)attention maps的可视化
我们还使用注意力图验证了 MT-ViT 模型,尽管仅使用注意力图来解释模型行为是不够的,因为模型复杂且具有许多层次(Chefer 等人,2021)。注意力张量的形状为(头的数量,批次的数量)。最近邻插值方法将patch注意力插值到输入干涉图的原始大小。图16显示了三个模拟干涉图的注意力图,而图17显示了三个真实干涉图的注意力图。预期高注意力值与变形像素相关,但相反,其他区域显示较低的注意力值。MT-ViT 不仅正确返回了变形类别,而且还返回了变形的位置。图16、图17(a)、(b)、(c)和(d)显示,MT-ViT 的注意力模式与变形像素的空间分布相关。
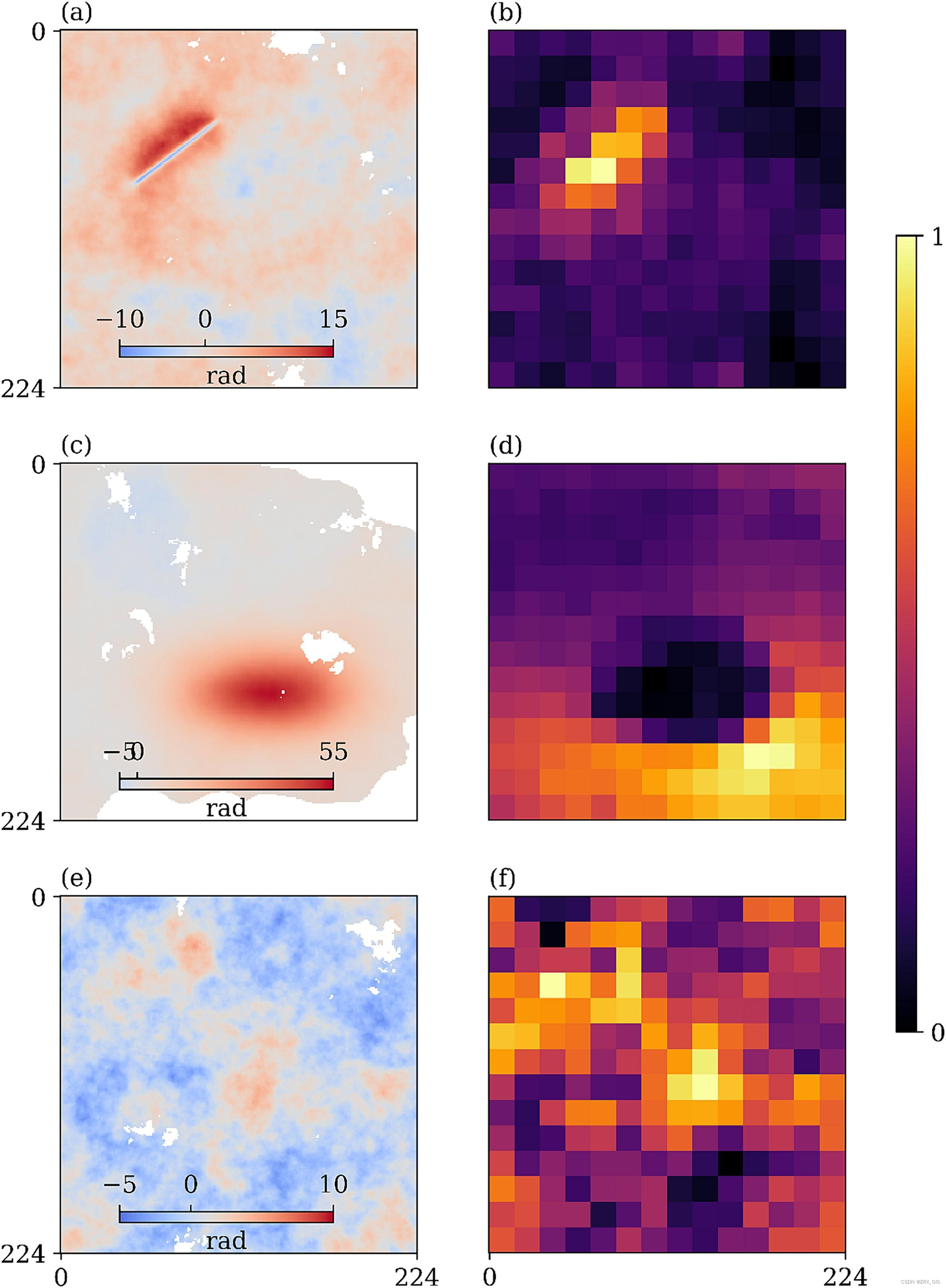
Fig. 16. 三个模拟干涉图的注意力图可视化。(a) 具有火山岩脉的干涉图。© 包含岩脉/点的干涉图。(e) 包含大气信号的干涉图。(b)、(d) 和 (f) 分别表示干涉图 (a)、© 和 (e) 上最终多头注意力块的平均值。

Fig. 17. 三个真实干涉图的注意力图可视化。(a) 具有火山岩脉的干涉图。© 包含岩脉/点的干涉图。(e) 包含大气信号的干涉图。(b)、(d) 和 (f) 分别表示干涉图 (a)、© 和 (e) 上最终多头注意力块的平均值。
(8)局限性和后续工作
ViT模型由于固定尺寸的块嵌入,即使使用全局平均池化,也将干涉图限制在224x224像素的分辨率。为了更大的灵活性,考虑使用ConViT或ConvNeXt,它们将卷积过程整合到注意力机制中。未来的改进可能涉及使用复杂的模拟来纳入各种变形来源。检测低滑动地震可能需要一个专门的架构来区分真实信号和噪声。YOLO架构可能为多源检测和解决分类和定位头之间的错位提供了合适的解决方案。
总结
虽然有些比较有凑工作量的“嫌疑”,但不可否认,这些内容并不违和。作者写的也比较详细,似乎没有太多要说的。。
1.6 结论
地质灾害调查中,对地面变形的迅速和准确检测与解释至关重要。机器学习(ML)模型已应用于基于单个或时间序列干涉图的InSAR变形解释,但通常由于训练数据的稀缺性而限制了模型的性能。在本文中,我们提出了一种先进的ML模型,利用视觉转换器架构来有效地检测、定位和解释基于单个InSAR干涉图的地面变形信号。我们使用模拟和真实的SAR数据集对模型进行了验证,重点关注火山和地震变形。实验结果表明了所提出的ML模型在地质变形检测和解释方面的有效性。以下是研究的主要结论:
(1)提出了将多任务学习技术与视觉转换器模型(MT-ViT)相结合,利用单个SAR干涉图自动检测、定位和解释变形。通过考虑ViT模型中的全局特征,变形检测的OA从95.5%提高到99.4%,而相比之下,仅专注于潜在特征的CNN网络。
(2)实验结果表明,所提出的MT-ViT模型能够检测到5厘米的变形,准确率超过99.0%。地震变形的定位精度高度依赖于SAR干涉图的空间分辨率。
(3)实验结果显示,带有16×16patch大小、平均池化层、8个干涉图批量大小和分类损失与定位损失之间的20:1权重比的Small架构是最佳选择。研究结果还表明,增加可训练参数并不总是有益的。
1.7 数据可用
https://github.com/matthew-gaddes/VolcNet