八、文件操作
1、读取键盘输入
input 获取标准输入,数据类型统一为字符串
#!/usr/bin/python
# -*- coding: UTF-8 -*- str = input("请输入:")
print("你输入的内容是: ", str)
这会产生如下的对应着输入的结果:
请输入:[x*5 for x in range(2,10,2)] 你输入的内容是: [10, 20, 30, 40]
3、操作文件
对文件操作的流程
-
打开文件,得到文件句柄并赋值给一个变量
-
通过句柄对文件进行操作
-
关闭文件
现有文件如下:
cat 小重山.txt
昨夜寒蛩不住鸣。
惊回千里梦,已三更。
起来独自绕阶行。
人悄悄,帘外月胧明。
白首为功名,旧山松竹老,阻归程。
欲将心事付瑶琴。
知音少,弦断有谁听。
f = open('小重山.txt',encoding='utf8') #打开文件
data=f.read() #获取文件内容
f.close() #关闭文件
注意:如果是windows系统,hello文件是utf8保存的,打开文件时open函数是通过操作系统打开的文件,而win操作系统默认的是gbk编码,所以直接打开会乱码,需要f=open(‘hello',encoding='utf8'),hello文件如果是gbk保存的,则直接打开即可。
2、文件打开模式
先介绍两种最基本的模式:
f = open('小重山.txt','w',encoding='utf8') #打开文件
f1 = open('小重山1.txt','a',encoding='utf8') #打开文件
f1.write('莫等闲1\n')
f1.write('白了少年头2\n')
f1.write('空悲切!3')
1、open() 方法
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法:
file object = open(file_name [, access_mode][, buffering])
各个参数的细节如下:
-
file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
-
access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
-
buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r')
完整的语法格式为:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
-
file: 必需,文件路径(相对或者绝对路径)。
-
mode: 可选,文件打开模式
-
buffering: 设置缓冲
-
encoding: 一般使用utf8
-
errors: 报错级别
-
newline: 区分换行符
-
closefd: 传入的file参数类型
-
opener:
mode 参数有:
| 模式 | 描述 |
|---|---|
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
下图很好的总结了这几种模式:
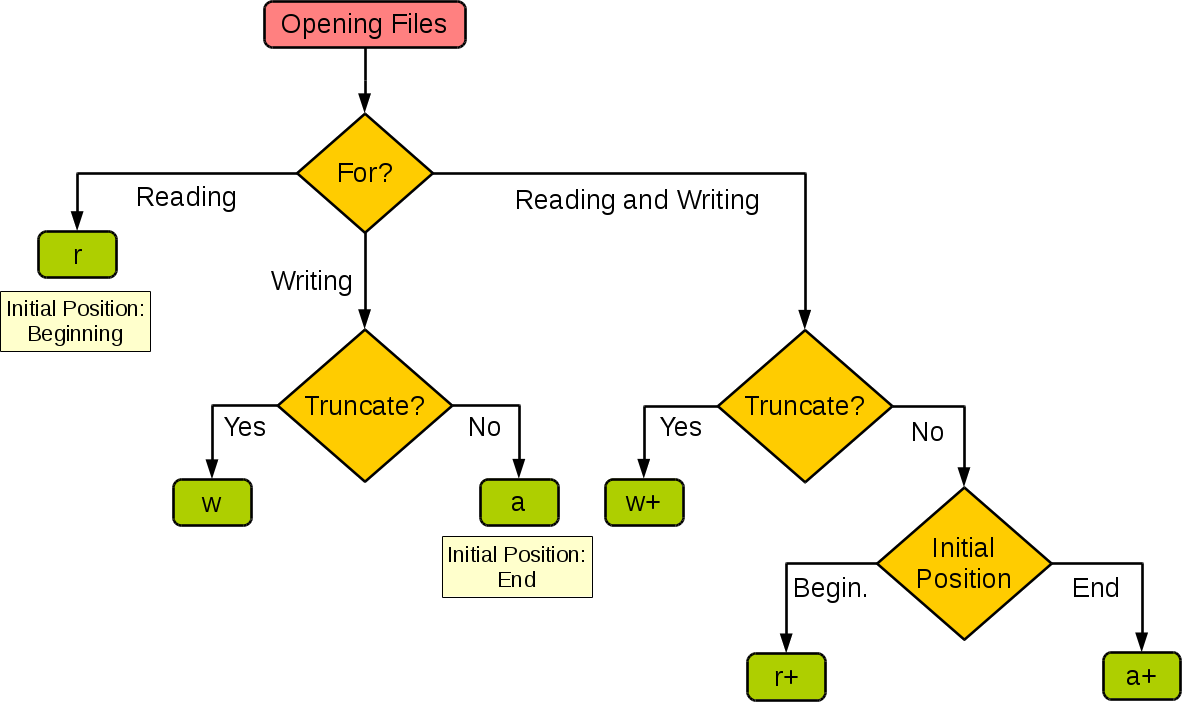
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
2、file 对象
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
以下是和file对象相关的所有属性的列表:
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
如下实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开一个文件
fo = open("foo.txt", "w")
print("文件名: ", fo.name)
print("是否已关闭 : ",fo.closed)
print("访问模式 : ",fo.mode)
以上实例输出结果:
文件名: foo.txt 是否已关闭 : False 访问模式 : w
file 对象使用 open 函数来创建,下表列出了 file 对象常用的函数:
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close() 关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.read([size])从文件读取指定的字符数,如果未给定或为负则读取所有。 |
| 3 | file.readlines([sizeint])读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| 4 | file.seek(offset[, whence]) 设置文件当前位置. |
| 5 | file.tell() 返回文件当前指针位置。 |
| 6 | file.write(str) 将字符串写入文件,返回的是写入的字符长度。 |
注:python中打开文件有两种方式,即:open(...) 和 file(...) ,本质上前者在内部会调用后者来进行文件操作,推荐使用 open。
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
3、close()方法
File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
语法:
fileObject.close()
例子:
#!/usr/bin/python
# -*- coding: UTF-8 -*-# 打开一个文件
fo = open("foo.txt", "w")
print("文件名: ", fo.name)
# 关闭打开的文件
fo.close()
以上实例输出结果:
文件名: foo.txt
读写文件:
file对象提供了一系列方法,能让我们的文件访问更轻松。来看看如何使用read()和write()方法来读取和写入文件。
4、write()方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符('\n'):
语法:
fileObject.write(string)
在这里,被传递的参数是要写入到已打开文件的内容。
例子:
#!/usr/bin/python
# -*- coding: UTF-8 -*-# 打开一个文件
fo = open("foo.txt", "w")
fo.write( "www.1000phone.com!\nVery good site!\n")
# 关闭打开的文件
fo.close()
上述方法会创建foo.txt文件,并将收到的内容写入该文件,并最终关闭文件。如果你打开这个文件,将看到以下内容:
cat foo.txt www.1000phone.com! Very good site!
5、read()方法
read()方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count])
在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
例子:
这里我们用到以上创建的 foo.txt 文件。
#!/usr/bin/python
# -*- coding: UTF-8 -*-# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print("读取的字符串是 : ", str)
# 关闭打开的文件
fo.close()
以上实例输出结果:
读取的字符串是 : www.1000phone
6、readlines() 方法
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for... in ... 结构进行理。
如果碰到结束符 EOF 则返回空字符串。
语法
readlines() 方法语法如下:
fileObject.readlines( );
返回值
返回列表,包含所有的行
#!/usr/bin/python # -*- coding: UTF-8 -*-# 打开文件 fo = open(小重山.txt", "r") print("文件名为: ", fo.name)for line in fo.readlines(): #依次读取每行 line = line.strip() #去掉每行头尾空白 print("读取的数据为: %s" % (line))# 关闭文件 fo.close()
8、with 方法
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f: ...
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open('log1') as obj1, open('log2') as obj2:pass
9、tell() 方法
tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。
Offset变量表示要移动的字节数。
From变量指定开始移动字节参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
例子:
就用我们上面创建的文件foo.txt。
#!/usr/bin/python
# -*- coding: UTF-8 -*-# 打开一个文件
fo = open("foo.txt", "r+")
str = fo.read(10)
print("读取的字符串是 : ", str)# 查找当前位置
position = fo.tell()
print("当前文件位置 : ", position)# 把指针再次重新定位到文件开头
position = fo.seek(0, 0)
str = fo.read(10)
print("重新读取字符串 : ", str)
# 关闭打开的文件
fo.close()
以上实例输出结果:
读取的字符串是 : www.1000phone 当前文件位置 : 10 重新读取字符串 : www.1000phone
10、seek() 方法
seek() 方法用于移动文件读取指针到指定位置。
seek() 方法语法如下:
fileObject.seek(offset[, whence])
参数
-
offset -- 开始的偏移量,也就是代表需要移动偏移的字节数
-
whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
返回值
该函数没有返回值。
以下实例演示了 readline() 方法的使用:
循环读取文件的内容:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开文件
fo = open("小重山.txt", "r+")
print("文件名为: ", fo.name)
line = fo.readline()
print("读取的数据为: %s" % (line))
# 重新设置文件读取指针到开头
fo.seek(0, 0)
line = fo.readline()
print("读取的数据为: %s" % (line))
#关闭文件
fo.close()
九、函数式编程介绍
1、没有使用函数式编程之前带来的问题
-
代码的组织结构不清晰,可读性差
-
实现重复的功能时,你只能重复编写实现功能的代码,导致代码冗余,白白耗费精力
-
假如某一部分功能需要扩展或更新时,需要找出所有实现此功能的地方,一一修改,无法统一管理,加大了维护难度
2、函数是什么
-
函数是对实现某一功能的代码的封装(代码分解,松耦合,按功能划分)
-
函数可以实现代码的复用,从而减少代码的重复编写
3、Python 中函数的特性
-
函数的参数可以是python 中的任意数据类型,并且参数的数量可以是零个或多个。
-
函数也可以通过关键字
return返回任何数量的 Python 中的任意数据类型,作为结果
4、函数分类
-
内置函数
-
https://docs.python.org/zh-cn/3.7/library/functions.html
为了方便我们的开发,针对一些简单的功能,python解释器已经为我们定义好了的函数即内置函数, 内部提供很多方法,常用功能罗列出来,类似为使用方便而创建的快捷方式
对于内置函数,我们可以拿来就用而无需事先定义,如len(),sum(),max()
help() type() id() bool() # 布尔值 max() min() sum() len() all() #接受一个序列,判断所有值如果是真的(非空),返回True 否则返回false l = ['aaa','bbb'] all(l) any() #只要有一个是真,就是真 练习一下 all() any()
#_*_ coding:utf-8 _*_ """ 代码注释 """ l = [1, 2, 3] a = 'aaa' print(vars()) #当前模块的所有变量 print(__file__) #当前模块文件路径 print(__doc__) #当前模块的文档信息 print(__name__) # python 默认在执行 .py 文件时,__name__ = __main__
-
自定义函数
很明显内置函数所能提供的功能是有限的,这就需要我们自己根据需求,事先定制好我们自己的函数来实现某 种功能,以后,在遇到应用场景时,调用自定义的函数即可。
-
导入函数
5、函数的定义
1 、如何自定义函数?
函数的定义中可能会涉及到如下几点:
语法
def 函数名(参数1,参数2,参数3,...):'''注释'''函数体return 返回的值 # 函数名要能反映函数本身所实现的意义
-
def:表示定义函数的关键字
-
函数名:函数的名称,日后根据函数名调用函数
-
函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
-
参数:为函数体提供数据
-
return:当函数执行完毕后,可以给调用者返回数据(以后的代码不再执行)。
实例
def f():pass def myfunc():'s' + 1
2. 函数在定义阶段都干了哪些事?
只检测定义函数所要求的语法,不执行函数体内的代码
也就说,语法错误在函数定义阶段就会检测出来,而代码的逻辑错误只有在调用执行时才会知道。
def get_result():r - 1 get_result() # 调用函数后会输出如下错误提示结果: NameError: name 'r' is not definedget_reuslt = """r - 1 """
6、函数调用
1、函数调用
函数的调用:函数名加小括号 func()
-
先找到名字
-
根据名字调用代码
def myfunc():url = "www.qfedu.com" # 调用 myfunc()
2、函数使用的原则:必须先定义,才可以调用
定义函数就是在定义“变量”,“变量”必须先定义后,才可以使用。
不定义而直接调用函数,就相当于在使用一个不存在的变量名
# 情景一
def foo():print('from foo')func()
foo() # 报错
# 情景二
def func():print('from func')
def foo():print('from foo')func()
foo() # 正常执行
# 情景三
def foo():print('from foo')func()def func():print('from func')
foo() # 可以正常执行吗?
需求,自定义函数实现监控告警(cpu,disk,mem) def email发送邮件()(连接,发送,关闭)def CPU告警()cpu > 80email发送邮件 def disk告警()disk > 80email发送邮件 def mem告警()mem > 60email发送邮件
#!/usr/bin/python3 import yagmail import sys yag = yagmail.SMTP(user='xxxx@163.com',password='',host='smtp.163.com', # 邮局的 smtp 地址port='25', # 邮局的 smtp 端口smtp_ssl=False) yag.send(to=sys.argv[1],subject=sys.argv[2],contents=sys.argv[3])
3、总结
-
函数的使用,必须遵循的原则是:先定义,后调用
-
在使用函数时,我们一定要明确地区分定义阶段和调用阶段
-
在函数体里面的任何代码都只是定义而已,只有在调用此函数时,这个函数内的代码才会执行。
# 定义阶段
def foo():print('from foo')func()
def func():print('from func')# 调用阶段
foo()
7、函数返回值 return
-
不定义,默认返回 None
-
返回多个值时,每个值用逗号隔开,也就是元组的形式
1、如何自定义返回值
使用 return 关键字
def foo():x = 1return x ret = foo() # 给你, 这一步相当于下面的一行代码,就是 foo() 执行完毕,#创建了 1 这个对象,之后把变量名 ret 分配给对象 1 # ret = 1 print(ret)
2、接收函数的返回值
注意:必须先执行函数,此函数的返回值才会被创建并返回
# 可以使用一个变量来接收一个函数的返回值
ret = foo()
print("foo 函数的返回值是:", ret)
# 也可以把函数的返回值直接作为参数来使用,这时函数 `foo` 会先被执行,
# 之后把其返回值放在其原来的位置,以供 `print` 函数作为参数使用
print("foo 函数的返回值是:", foo())
在函数执行的过程中,当在函数体内遇到了
return关键字,函数就会立刻停止执行,并返回其返回值,return之后的代码不会被执行。
def func():x = 100returnprint('ok') # 不执行
print('qf') # 执行,因为此代码已不是函数体内的代码了,注意缩进。
func()
定义一个有返回值的函数,并调用此函数
def echo(arg):return arg # 用关键字 return 定义函数的返回
# 调用函数,并用一个变量接收其返回值
ret = echo('yangge')
print(ret)
# 执行 print 的结果
'yangge'
# 当一个函数没有显式的调用 return 时,默认会返回 None
def do_nothing():print('ok')
# 下面的方式,会先执行函数体内的代码,之后把函数自身的返回值
# 放在其函数原来的位置,并且作为参数给 print
print(do_nothing())
ok # 函数体本身执行的结果
None # 函数自身的返回值# 函数可以返回一个以及多个Python 的任何数据类型的结果
8、函数的参数
以下是重点,需要加强练习,理解原理,掌握用法和技巧
-
函数的参数是为函数体内的逻辑代码提供数据的。
-
函数的参数形式有 形参和实参
-
分类有:
-
普通参数
-
默认参数
-
动态参数
-
1. 什么是形参
对于函数来说,形式参数简称形参,是指在定义函数时,定义的一个变量名;
下面的代码中,x、y、z 就是形参
def foo(x, y, z):print("第一个参数是", x)print("第二个参数是", y)print("第三个参数是", z)
2. 什么是实参
对于函数来说,实际参数简称实参。 是指在调用函数时传入的实际的数据,这会被绑定到函数的形参上; 函数调用时,将值绑定到变量名上,函数调用结束,解除绑定,并且实参将不再存在于程序中。
foo(1,2,3)
上面的 1、 2 和 3 都是实参
3. 形参分为:位置参数和默认参数
a. 位置参数
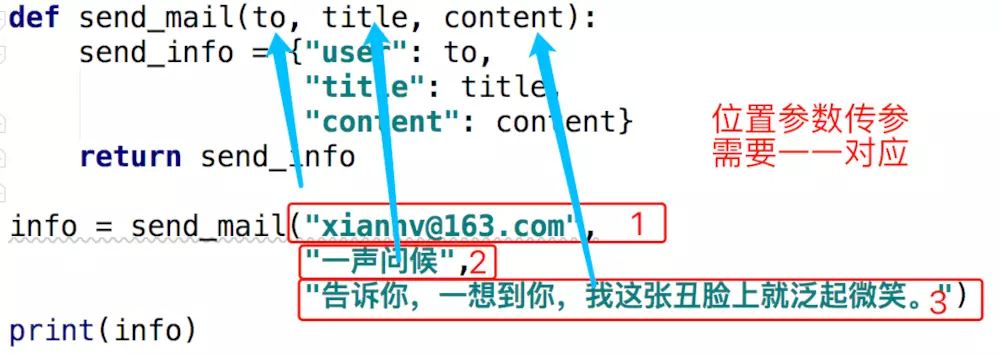
def send_mail(to, title, content):send_info = {"user": to,"title": title,"content": content}return send_info
形参的位置参数,在调用函数时必须给其传递实参。 但是,在函数内使用与否 ,没有限制。
b. 默认参数
def default_mail(title, content, to='xiannv@163.com'):send_info = {"user": to,"title": title,"content": content}return send_info
默认参数在函数定义的时候,就已经绑定了实际的值了。 调用函数时,可以给其传值,也可以不传。
不传值 就使用定义函数时绑定的值。
传值 就是使用传递的值。
同样,在函数内使用与否 ,没有限制。
4. 实参分为:位置参数和关键字参数
说的实参实质就是在调用函数时,给位置参数的进行赋值,这个行为通常叫做给函数 传参
因此,大家要明白,这里的 位置参数 和 关键字参数 是在函数调用的情况下的概念。
a. 位置参数传递参数
给形参的位置参数传参
info = send_mail("xiannv@163.com", "一生问候", "告诉你,一想到你,我这张丑脸上就泛起微笑。")
print(info)
还可以这样传参
def myfunc(x, y, z):print(x, y, z)
tuple_vec = (1, 0, 1)
dict_vec = {'x': 1, 'y': 0, 'z': 1}
>>> myfunc(*tuple_vec)
1, 0, 1
>>> myfunc(**dict_vec)
1, 0, 1
给默认参数传参
info = default_mail( "一生问候", """因为你太美好了,我等你等了这么久,才能跟你在一起,我害怕得不得了,生怕自己搞砸了""","xiannv@163.com", ) print(info)
当使用实参的位置参数传参时,需要考虑到定义函数时的形参的位置。
b. 关键字参数传递参数
info = send_mail(content="我爱你,不光是因为你的样子,还因为和你在一起时,我的样子", title="一生问候",to="jingjing@126.com") print(info)
使用关键字参数传参时,不必考虑形参的位置。但是需要注意,关键字必须和在定义函数时形参一致。
实参角度的参数结论:
-
在调用函数时,给形参的位置参数或形参的默认参数进行赋值时,可以用实参的位置参数进行传参; 此时传递的实参的顺序,必须和形参的位置顺序一一对应
-
在调用函数时,给形参的位置参数或形参的默认参数进行赋值时, 也可以使用实参的关键字参数进行传参; 此时,关键字参数之间是不区分位置顺序的
-
在调用函数时,形参的默认参数不传参数给它,此时,默认参数的值就是原来定义的值;假如传了参数,就使用传入的参数的值。
5. 万能参数: *args 和 **kwargs (动态参数)
a. 用 * 表达式接收传进来的任意多个未明确定义的位置参数
def foo(x, y, *args):print(args)
foo(1, 3, 5, 6)
list1 = [1,2,3,4,5]
foo(*list1)
foo(list1)
def foo(x, y, *args):print(args)print(x)print(y)
# foo(1, 3, 5, 6)
# foo(1,2,3,4,5,6)
# print(foo(1,2,3,4,5))
list1=['a','b','c','d']
t1=('a','b','c','d')
s1='helloworld'
#foo(list1,t1)
foo(1,2,list1,t1) # 不是序列的可以不用加*
foo(1,2,*list1) #只有在传入序列的时候加*
# 输出如下
(['a', 'b', 'c', 'd'], ('a', 'b', 'c', 'd'))
1
2
('a', 'b', 'c', 'd')+
1
2
在函数体内接收到的参数会放在元组中
b. 用 ** 表达式接收传进来的任意多个未明确定义的关键字参数
def func(x, y, **kwargs):print(kwargs)
func(1, 3, name='shark', age=18)
func(1,2,3,4,5) #是否会报错
dict1={'k1':'a','k2':'b'}
func(1,2,**dict1)
def func(x,y,*args,**kwargs):print(kwargs)print(args)print(x)print(y)
#func(1,2,3,4)
func(1,3,name='aaa',age=18)
d2 = {'k1':'aaa','k2':'18'}
l1 = [1,2,3,4]
print(type(d2))
func(1,2,*l1,**d2) # 加*号调用,就会以序列的元素为元素组成一个元祖
func(1,2,l1) # 直接调用序列,会把整个序列作为元祖的一个元素
# 输出如下
{'age': 18, 'name': 'aaa'}
()
1
3
<type 'dict'>
{'k2': '18', 'k1': 'aaa'}
(1, 2, 3, 4)
1
2
{}
([1, 2, 3, 4],)
1
2
在函数体内接收到的参数会放在字典中
相结合的方式 def func1(*args,**kwargs):print(args)print(kwargs) func1(1,2,3) func1(k1=1,k2=2) func1(1,2,3,k1='a',k2='b')
6、重要的东西,需要总结一下吧
函数参数从形参角度来说,就是在定义函数时定义的变量名,分为三种:
-
位置参数如: arg1,arg2
所用的参数是有位置的特性的,位置是固定的,传参时的值也是要一一对应的
-
默认参数如:arg = 5 -
动态参数如: *args,**kwargs, 可以同时用
三种形参在定义函数时的顺序如下:
In [108]: def position_arg(arg1, arg2, *args, **kwargs):...: pass...:
函数参数从实参角度来说,就是在调用函数时给函数传入的实际的值,分为两种
-
位置参数
在传参时,值和定义好的形参有一一对应的关系
-
关键字参数
在传参时,利用key = value 的方式传参,没有对位置的要求
十、名称空间和作用域
可以简单理解为存放变量名和变量值之间绑定关系的地方。
1、名称空间
在 Python 中有各种各样的名称空间:
-
全局名称空间:每个程序的主要部分定义了全局的变量名和变量值的对应关系,这样就叫做全局名称空间
-
局部名称空间:在函数的运行中定义的临时的空间叫做局部名称空间,只可以被这个函数所有。函数运行结束后,这个局部的名称空间就会销毁。
-
内置名称空间:内置名称空间中存放了python解释器为我们提供的名字:input,print,str,list,tuple...它们都是我们熟悉的,拿过来就可以用的方法。
1、三种名称空间之间的加载顺序
python3 test.py # 1、python解释器先启动,因而首先加载的是:内置名称空间 # 2、执行test.py文件,然后以文件为基础,加载全局名称空间 # 3、在执行文件的过程中如果调用函数,则临时产生局部名称空间
2、名字的查找顺序
当我们要使用一个变量时,先从哪里找?
局部使用:局部名称空间——>全局名称空间——>内置名称空间
x = 1 def f1():x = 10print(x) f1() # 输出 10
全局使用:全局——>内置
#需要注意的是:在全局无法查看局部的,在局部可以查看全局的,如下示例 x = 1 def f1():x = 10print(x) print(x) # 输出 1
2、作用域
作用域就是变量名的生效范围
分为: 全局作用域 和 局部作用域
1、全局作用域
内置的名称空间中的名字和全局名称空间的名字属于这个全局作用域。
-
全局作用域中的名字,在整个文件的任意位置都能被引用,全局存活,全局内都有效。
2、局部作用域
局部名称空间的名字属于局部作用域。
-
局部作用域中的名字只能在其本地局部生效和使用。
-
python中局部作用域就是函数内定义或生成的名字,临时存活,随着函数调用的结束而消失。


![[问题记录] oracle问题汇总记录](https://img-blog.csdnimg.cn/direct/c0ce29a1d53f478c9e18daa0b9e06057.png)








![[C语言][数据结构][动态内存空间的开辟]顺序表的实现!](https://img-blog.csdnimg.cn/direct/a58c5df3438f4c088fe261fe3b686e31.png)