目录
一.栈
1.栈的基本概念
2.栈的基本操作
3.顺序栈的实现
•顺序栈的定义
•顺序栈的初始化
•进栈操作
•出栈操作
•读栈顶元素操作
•若使用另一种方式:
4.链栈的实现
•链栈的进栈操作
•链栈的出栈操作
•读栈顶元素
二.队列
1.队列的基本概念
2.队列的基本操作
3.用顺序存储实现队列
•初始化
•入队操作
•出队操作
•获得队头元素的值
•判满/空方案
4.用链式存储实现队列
•初始化
•入队操作
•出队操作
•队列满的条件
三.双端队列
一.栈
1.栈的基本概念
栈(stack)是只允许在一端进行插入或删除操作的线性表。
栈顶:允许插入和删除的一端。最上面的元素被称为栈顶元素。
栈底:不允许插入和删除的一端。最下面的元素被称为栈底元素。
如下图所示:
进栈顺序:a1-->a2-->a3-->a4-->a5
出栈顺序:a5-->a4-->a3-->a2-->a1
所以栈的特点是后进先出(Last In First Out ( LIFO ))
补充:
n个不同元素进栈,出栈元素不同排列的个数为
。
上述公式称为卡特兰(Catalan)数,可采用数学归纳证明。

2.栈的基本操作
•Initstack(&S):初始化栈。构造一个空栈S,分配内存空间。
•DestroyStack(&L):销毁栈。销毁并释放栈s所占用的内存空间。
•Push(&S,x):进栈,若栈S未满,则将x加入使之成为新栈顶。•Pop(&S,&x):出栈,若栈S非空,则弹出栈顶元素,并用x返回。
•GetTop(S,&x):读栈顶元素。若栈S非空,则用x返回栈顶元素。
其他常用操作:
StackEmpty(S):判断一个栈S是否为空。若S为空,则返回true,否则返回false。
3.顺序栈的实现
•顺序栈的定义
#define Maxsize 10 //定义栈中元素的最大个数
typedef struct{ElemType data[Maxsize]; //静态数组存放栈中元素int top; //栈顶指针
} SqStack;void testStack(){SqStack S; //声明一个顺序栈(分配空间)
}
//这里使用声明的方式分配内存空间,并没有使用malloc函数。
//所以给这个栈分配的内存空间,会在函数结束之后又系统自动回收。声明顺序栈后,就会给各个数据元素分配连续的存储空间,大小为MaxSize*sizeof(ElemType)的空间。

•顺序栈的初始化
#define Maxsize 10 //定义栈中元素的最大个数
typedef struct{
ElemType data[Maxsize]; //静态数组存放栈中元素
int top; //栈顶指针
} SqStack;//初始化栈
void Initstack(Sqstack &S){S.top=-1; //初始化栈顶指针
}//判断栈空
bool StackEmpty(SqStack S){if(S.top==-1) //栈空return true ;else //不空return false;
}void testStack(){SqStack S;InitStack(S);
}•进栈操作
#define MaxSize 10
typedef struct{ElemType data[Maxsize];int top;
} Sqstack;//新元素入栈
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize-1) //栈满,报错return false;S.top = S.top + 1; //指针先加1S.data[s.top]=x; //新元素入栈return true;
}//或者写为
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize-1) //栈满,报错return false;S.data[++S.top]=x;return true;
}
//不能写为
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize-1) //栈满,报错return false;S.data[S.top++]=x;return true;
}//这意味着
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize-1) //栈满,报错return false; S.data[s.top]=x; //新进栈的元素会把以前的元素覆盖 S.top = S.top + 1;return true;
}•出栈操作
#define MaxSize 10
typedef struct{ElemType data[Maxsize];int top;
} Sqstack;//出栈操作
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[S.top]; //栈顶元素先出栈S.top=S.top-1; //指针再减1return true;
}
//删除操作中,top指针往下移,只是逻辑上被删除了,数据还残留在内存中。//出栈操作也可写为
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[S.top--];return true;
}//不能写为
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[--S.top];return true;
}//这意味着
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;S.top=S.top-1;x=S.data[S.top];return true;
}如果先减,再将top的值赋给x,那么x值就会返回"i",而不是"j"

•读栈顶元素操作
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int top;
} Sqstack;//出栈澡作
bool Pop(Sqstack &S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[s.top--]; //先出栈,指针再减1return true;
}//读栈顶元素
bool GetTop(Sqstack S,ElemType &x){if(S.top==-1) //栈空,报错return false;x=S.data[s.top]; //x记录栈顶元素return true;
}
//可以看到,出栈操作和读栈顶元素非常类似。•若使用另一种方式:
将top指针刚开始指向0,判断栈是否为空,即判断S.top==0,这样设计是将top指针指向下一个能插入元素的位置。

若进行入栈操作时,需要先把x放到top指针指向的位置,再让top+1,和之前的方式相反。
出栈操作也是,需要先让top-1,再把top指向的数据元素传回去。
代码如下:
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int top;
} SqStack;//初始化栈
void Initstack(Sqstack &s){S.top=0; //初始化指向0
}bool StackEmpty(Sqstack S){if(S.top==0) //栈空return true;elsereturn false;
}//入栈操作
bool Push(SqStack &S,ElemType x){if(S.top == MaxSize) //栈满,报错return false;S.data[S.top++]=x;return true;
}//出栈操作
bool Pop(Sqstack &S,ElemType &x){if(S.top==0) //栈空,报错return false;x=S.data[--S.top];return true;
}void testStack(){ 判断栈空SqStacks;//声明一个顺序栈InitStack(S);
}顺序栈的缺点是栈的大小不可变,可以在刚开始就给栈分配大片的内存空间,但这样会导致内存空间的浪费,可以使用共享栈提高内存空间的利用率。共享栈即两个栈共享同一片内存空间。
代码如下:
#define MaxSize 10
typedef struct{ElemType data[Maxsize]; //静态数组存放栈中元素int top0; //0号栈栈顶指针int top1; //1号栈浅顶指针
} Shstack;//初始化栈
void InitStack(Shstack &S){S.top0=-1; //初始化栈顶指针S.top1=Maxsize;
}
可以看到,共享栈判断栈满的条件:top0+1=top1
总结:

4.链栈的实现
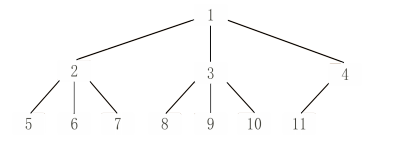
对于链栈而言,其进栈操作其实对应于链表中对头结点的"后插"操作,出栈操作对应于链表中对头结点的"后删"操作,就是将链头的一端看作栈顶的一端。
建议先看:http://t.csdnimg.cn/IknBJ
代码如下:
//链栈的定义和链表的定义是相同的,只是命名不同
typedef struct Linknode{ElemType data;struct Linknode *next;
}LiStack; //栈类型定义//带头结点
bool InitStack(LiStack &L){L=(Linknode *)malloc(sizeof(Linknode));if(L==NULL)return false; //内存不足,分配失败L->next=NULL;return true;
}bool Empty(LinkList L){return(L->next == NULL);
}//不带头结点
bool InitStack(LiStack &L){L=NULL;return true;
}bool Empty(LinkList L){return(L=NULL);
}•链栈的进栈操作
//带头结点
LiStack LiSPush(LiStack &L){Linknode *s;int x;L=(LiStack)malloc(size(Linknode));L->next=NULL;scanf("%d",&x);while(x!=9999){s=(Linknode *)malloc(sizeof(Linknode));s->data=x;s->next=L->next;L->next=s;scanf("%d",&x);}return L;
}//不带头结点
LiStack LisPush(LiStack &L){Linknode *s;int x;L=NULL;scanf("%d",&x);while(x!=9999){s=(Linknode *)malloc(sizeof(Linknode));s->data=x;s->next=L;L=s;scanf("%d",&x);}return L;
}•链栈的出栈操作
//带头结点
LiStack LisPop(LiStack &L, int &e) {if (L->next == NULL) {// 栈空,无法出栈return NULL;}Linknode *q = L->next;e = q->data;L->next = q->next;free(q);return L;
}//不带头结点
LiStack LisPop(LiStack &L, int &e) {if (L == NULL) {// 栈空,无法出栈return NULL;}Linknode *q = L;e = q->data;L = L->next;free(q);return L;
}
•读栈顶元素
//带头结点
int GetTop(LiStack &L) {if (L->next == NULL) {// 栈为空return -1; // 或者抛出异常}return L->next->data;
}//不带头结点
int GetTop(LiStack &L) {if (L == NULL) {// 栈为空return -1; // 或者抛出异常}return L->data;
}
二.队列
1.队列的基本概念
栈(stack)是只允许在一端进行插入或删除操作的线性表。队列(aueue)是只允许在一端进行插入,在另一端删除的线性表。
队头,队尾,空队列:
空队列:没有数据元素
队头:允许删除的一端
队尾:允许插入的一端

队列的特点:先进入队列的元素先出队,即先进先出(First In First Out,FIFO)。
2.队列的基本操作
Initaueue(&Q):初始化队列,构造一个空队列。
DestroyQueue(&Q):销毁队列。销毁并释放队列Q所占用的内存空间。
EnQueue(&Q,x):入队,若队列Q未满,将x加入,使之成为新的队尾。
DeQueue(&a,&x):出队,若队列Q非空,删除队头元素,并用x返回。
GetHead(a,&x):读队头元素,若队列Q非空,则将队头元素赋值给x。其他常用操作:
QueueEmpty(Q):判队列空,若队列Q为空返回true,否则返回false。
3.用顺序存储实现队列
•初始化
#define Maxsize 10 //定义队列中元素的最大个数
typedef struct{ElemType data[Maxsize]; //用静态数组存放队列元素int front,rear; //队头指针和队尾指针
}SqQueue;void testQueue(){SqQueue Q;//声明一个队列
}声明一个队列后,系统会分配一片连续的存储空间,大小为MaxSize*sizeof(ElemType),如下图所示:
队头指针:指向队头元素。
队尾指针:指向队尾元素的后一个位置。

所以还没有插入元素时,队头指针与队尾指针同时指向data[0]:

#define Maxsize 10 //定义队列中元素的最大个数
typedef struct{ElemType data[Maxsize]; //用静态数组存放队列元素int front,rear; //队头指针和队尾指针
}SqQueue;void InitQueue(SqQueue &Q){//初始时,队头和队尾指针指向0Q.rear=Q.front=0;
}//判空
bool QueueEmpty(SqQueue Q){if(Q.rear==Q.front) //队空条件return true;elsereturn false;void testQueue(){SqQueue Q;//声明一个队列InitQueue(Q);}
•入队操作
只能从队尾入队
#define MaxSize 10
typedef struct{ElemType data[Maxsize];int front,rear;
} SqQueue;//入队
bool EnQueue(SqQueue &Q,ElemType x){if(Q.rear==MaxSize) return false; //队满则报错Q.data[Q.rear]=x; //新元素插入队尾Q.rear=(Q.rear+1);return true;
}注:rear=MaxSize不能作为队列已满的判断条件,上面的写法是错误的。如下图所示,若前面的元素出队了,要再插入元素,可以从前面无数据元素的区域插入。

正确写法:
#define MaxSize 10
typedef struct{ElemType data[Maxsize];int front,rear;
} SqQueue;//入队
bool EnQueue(SqQueue &Q,ElemType x){if((Q.rear+1)%MaxSize=Q.front) //判满return false; //队满则报错Q.data[Q.rear]=x; //新元素插入队尾Q.rear=(Q.rear+1)%MaxSize; //队尾指针加1取模return true;
}这里的Q.rear=(Q.rear)%MaxSize实现的效果是:当(Q.rear+1)%MaxSize==0时,即“队满”时,会将rear指针重新指向data[0]。

这样用模运算,将存储空间在逻辑上变成了“环状。

如下图所示,队满条件是:队尾指针的再下一个位置是队头,即(Q.rear+1)%MaxSize==Q.front

为什么需要不能再插入一个元素,并且使rear和front指向同一个元素呢?
因为初始化队列的时候,rear指针与front指针就是指向同一个位置,同时我们也是通过判断rear和front指针是否指向同一个位置,判断队列是否为空的。
如果再插入一个元素,rear和front指针指向同一个位置,这样,判满与判空条件就会混淆起来。
所以必须牺牲一个存储单元,以区分队列满还是空。
•出队操作
只能让队头元素出队:
//出队(删除一个队头元素,并用x返回)
bool DeQueue(sqQueue &Q,ElemType &x){if(Q.rear==Q.front) //当队头指针与队尾指针再次指向同一个位置时,说明队空return false; //队空则报错x=Q.data[Q.front];Q.front=(Q.front+1)%Maxsize; //队头指针后移return true;
}
•获得队头元素的值
//获得队头元素的值,用x返回
bool GetHead(SqQueue Q,ElemType &x){if(Q.rear==Q.front) //队空则报错return false;x=Q.data[Q.front];return true;
}//相比于出队操作,获取队头的值不需要将队头指针后移
bool DeQueue(sqQueue &Q,ElemType &x){if(Q.rear==Q.front) //当队头指针与队尾指针再次指向同一个位置时,说明队空return false; x=Q.data[Q.front];Q.front=(Q.front+1)%Maxsize; return true;
}•判满/空方案
方案一:
以上方案中,判断队列已满的条件:队尾指针的再下一个位置是队头,即:
(Q.rear+1)%MaxSize==Q.front
队空条件:队头指针与队尾指针指向同一个地方,即:
Q.rear=Q.front
队列元素个数:
(rear+MaxSize-front)%MaxSize
例如下图,rear=2,front=3,那么队列元素个数就是:(2+10-3)%10 =9%10=9

其实也可以不用牺牲一个存储空间,下面两种方案可供参考。
方案二:
#define MaxSize 10
typedef struct{ElemType data[MaxSize];int front,rear;int size; //用size表示当前队列的长度,当入队成功size++,出队成功size--
}SqQueue;

具体代码如下:
#define MaxSize 10
typedef struct {ElemType data[MaxSize];int front, rear;int size; // 用size表示当前队列的长度,当入队成功size++,出队成功size--
} SqQueue;// 初始化队列
void InitQueue(SqQueue &Q) {Q.front = Q.rear = 0;Q.size = 0;
}// 判断队列是否为空
bool QueueIsEmpty(SqQueue Q) {return (Q.rear == Q.front) && (Q.size == 0);
}// 判断队列是否已满
bool QueueIsFull(SqQueue Q) {return (Q.rear == Q.front) && (Q.size == MaxSize);
}// 入队操作
bool EnQueue(SqQueue &Q, ElemType x) {if (QueueIsFull(Q))return false;Q.data[Q.rear] = x;Q.rear = (Q.rear + 1) % MaxSize;Q.size++;return true;
}// 出队操作
bool DeQueue(SqQueue &Q, ElemType &x) {if (QueueIsEmpty(Q)) // 队列为空return false;x = Q.data[Q.front];Q.front = (Q.front + 1) % MaxSize;Q.size--;return true;
}
方案三:
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int front,rear;int tag; //记录最近进行的是删除/插入
//每次删除操作成功时,都令tag=0,每次插入成功时,都令tag=1;
} SqQueue;只有删除操作,才能导致队空,只有插入操作,才能导致队满。所以:

具体代码如下:
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int front,rear;int tag; //记录最近进行的是删除/插入
//每次删除操作成功时,都令tag=0,每次插入成功时,都令tag=1;
} SqQueue;// 初始化队列
void InitQueue(SqQueue &Q) {Q.front = Q.rear = 0;Q.tag = 0; // 初始时没有进行过操作,设置tag为0
}// 判断队列是否为空
bool QueueIsEmpty(SqQueue Q) {return Q.front == Q.rear && Q.tag == 0;
}// 判断队列是否已满
bool QueueIsFull(SqQueue Q) {return Q.front == Q.rear && Q.tag == 1;
}// 入队操作
bool EnQueue(SqQueue &Q, ElemType x) {if (QueueIsFull(Q)) {return false;}Q.data[Q.rear] = x;Q.rear = (Q.rear + 1) % Maxsize;Q.tag = 1; // 插入成功,设置tag为1return true;
}// 出队操作
bool DeQueue(SqQueue &Q, ElemType &x) {if (QueueIsEmpty(Q)) {return false;}x = Q.data[Q.front];Q.front = (Q.front + 1) % Maxsize;Q.tag = 0; // 删除成功,设置tag为0return true;
}在考试时,也可能出现rear指向队尾元素的情况,如下图所示:
![]()
//rear指向队尾元素的后一个位置时入队操作:
Q.data[Q.rear]=x;
Q.rear=(Q.rear+1)%MaxSize;//rear指向队尾元素时入队操作:
Q.rear=(Q.rear+1)%MaxSize;
Q.data[Q.rear]=x;初始化操作:
![]()
void InitQueue(SqQueue &Q){//初始时,队头和队尾指针指向0Q.front=0;Q.rear=MaxSize-1;
}
判空操作:

//判空
bool QueueEmpty(SqQueue Q){if((Q.rear+1)%MaxSize==Q.front) //队空条件return true;elsereturn false;判满操作:
判满也不能用与判空相同的条件了:

可以牺牲一个存储空间,即队空时,队尾指针在队头指针后面一个位置,队满时,队尾指针在队头指针后面两个位置。

或者向上面说的一样,增加辅助变量,如size,tag
这里只演示牺牲一个存储空间的情况:
#define Maxsize 10
typedef struct{ElemType data[Maxsize];int front,rear;
} SqQueue;// 初始化队列
void InitQueue(SqQueue &Q) {Q.front = 0;Q.rear =MaxSze-1;}//判空
bool QueueEmpty(SqQueue Q){if((Q.rear+1)%MaxSize==Q.front) //队空条件return true;elsereturn false;//判满
bool QueueEmpty(SqQueue Q){if((Q.rear+2)%MaxSize==Q.front) //队空条件return true;elsereturn false;// 入队操作
bool EnQueue(SqQueue &Q, ElemType x) {if (QueueIsFull(Q)) {return false;}Q.rear=(Q.rear+1)%MaxSize; //先往后移一个存储空间,再赋值Q.data[Q.rear]=x;return true;
}// 出队操作
bool DeQueue(SqQueue &Q, ElemType &x) {if (QueueIsEmpty(Q)) {return false;}x = Q.data[Q.front]; Q.front = (Q.front + 1) % Maxsize;return true;
}总结:

4.用链式存储实现队列
•初始化
typedef struct LinkNode{ //链式队列结点ElemType data;struct LinkNode *next;
}LinkNode;typedef struct{ //链式队列LinkNode *front,*rear; //队列的队头和队尾指针
}LinkQueue;

typedef struct LinkNode{ //链式队列结点ElemType data;struct LinkNode *next;
}LinkNode;typedef struct{ //链式队列LinkNode *front,*rear; //队列的队头和队尾指针
}LinkQueue;//初始化队列(带头结点)
void InitQueue(LinkQueue &Q){//初始时 front、rear 都指向头结点Q.front=Q.rear=(LinkNode*)malloc(sizeof(LinkNode));Q.front->next=NULL;
}//判断队列是否为空
bool IsEmpty(LinkQueue Q){if(Q.front==Q.rear)return true;elsereturn false;
}void testLinkQueue(){LinkQueue Q; //声明一个队列InitQueue(Q); //初始化队列
}//初始化队列(不带头结点)
void InitQueue(LinkQueue &Q){//初始时 front、rear 都指向NULLQ.front=NULL;Q.rear=NULL;
}//判断队列是否为空(不带头结点)
bool IsEmpty(LinkQueue Q){if(Q.front==NULL)return true;elsereturn false;
}
•入队操作
//新元素入队(带头结点)
void EnQueue(LinkQueue &Q,ElemType x){LinkNode *s=(LinkNode *)malloc(sizeof(LinkNode));s->data=x;s->next=NULL; //新结点插入到rear之后 Q.rear->next=s; //修改表尾指针Q.rear=s;
首先申请一个新结点,并把数据元素放到这一新结点当中:s->data=x;
新插入的结点一定是队列的最后一个结点,所以该结点的next指针指向NULL:s->next=NULL
将rear指向的结点的next指针指向新申请的s结点:Q.rear->next=s;
最后表尾指针会指向新的表尾结点:Q.rear=s;
若不带头结点,在第一个元素入队时,就需要进行特殊的处理:
//新元素入队(不带头结点)
void EnQueue(LinkQueue &Q,ElemType x){LinkNode *s=(LinkNode *)malloc(sizeof(LinkNode));s->data=x;s->next=NULL;if(Q.front == NULL){ //在空队列中插入第一个元素Q.front = s; //修改队头队尾指针Q.rear=s; } else { Q.rear->next=s; //新结点插入到 rear 结点之后Q.rear=s; //修改 rear 指针}
}•出队操作
//队头元素出队(带头结点)
bool DeQueue(LinkQueue &Q,ElemType &x){if(Q.front==Q.rear)return false; //空队LinkNode *p=Q.front->next;x=p->data; //用变量x返回队头元素Q.front->next=p->next; //修改头结点的 next 指针if(Q.rear==p) //此次是最后一个结点出队Q.rear=Q.front; //修改rear指针free(p); //释放结点空间return true;
}首先用p指向要出队的结点,即头结点之后的结点:LinkNode *p=Q.front->next;
接着修改头结点的后项指针:Q.front->next=p->next;
最后释放结点p:free(p)
若此次出队的结点p是当前队列的最后一个元素,在修改完头结点的后项指针后:
还需要修改表尾指针,让其指向头结点:Q.rear=Q.front;
最后释放p:free(p)




对于不带头结点的队列:
//队头元素出队(不带头结点)
bool DeQueue(LinkQueue &Q,ElemType &x){if(Q.front==NULL) //空队return false;LinkNode *p=Q.front; //p指向此次出队的结点x=p->data; //用变量x返回队头元素Q.front=p->next; //修改 front 指针if(Q.rear==p){Q.front = NULL;Q.rear = NULL;}free(p);return true;
}每次出队的是front指针指向的结点:LinkNode *p=Q.front;
由于没有头结点,所以每一次队头出队时,就需要修改队头指针指向的结点:
Q.front=p->next;
最后一个结点出队后,将front和rear都指向NULL:Q.front=NULL;Q.rear=NULL;


•队列满的条件
对于顺序存储的队列,存储空间都是预分配的,预分配的存储空间耗尽,则队满。而对链式存储而言,一般不会对满,除非内存不足。
三.双端队列
之前学习的栈,只允许从一端插入和删除的线性表:

队列则只允许从一端插入,另一端删除的线性表:

双端队列则是允许从两端插入,也允许从两端删除的线性表:

若只使用其中一端的插入、删除操作,则效果等同于栈。所以,只要是栈能实现的功能,双端队列一定能够实现。
双端队列还可以分为:
输入受限的双端队列:只允许从一端插入、两端删除的线性表。

输出受限的双端队列:只允许从两端插入、一端删除的线性表。

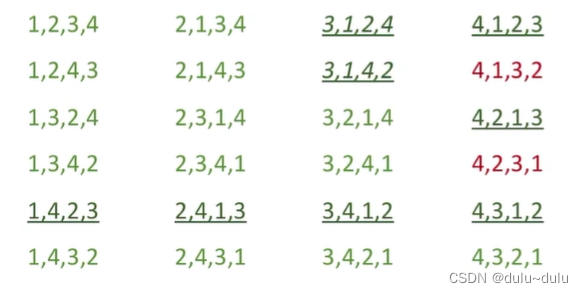
对于栈而言,合法的出栈序列有14种,可用卡特兰数计算:


对于输入受限的双端队列:

在栈中合法的序列,在双端队列中一定合法,所以只需要看“在栈中不合法”的输出队列即可。
可以得到以下结果,划线的是在栈中不合法,而在输入受限的双端队列中合法的序列:

对于输出受限的双端队列,同理: