关于模型评估的指标,之前已经写过不少这方面的文章,最近在实践中又有了一点新的思考,本文对模型评估中的AUC指标再进行一些简单的探讨。
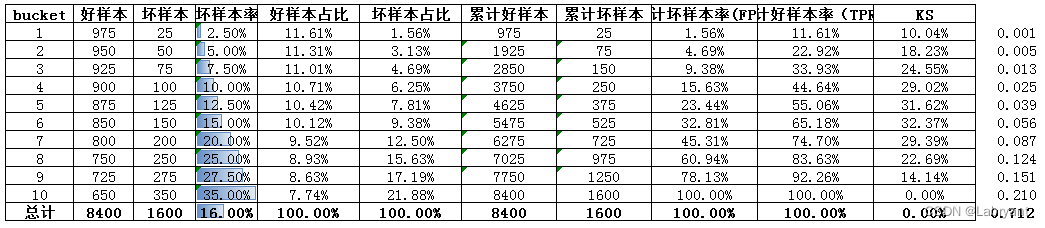
情况一,以下图中的数据为例,1代表用户发生逾期,标记为坏样本,模型预测的是用户发生逾期的概率。模型的KS为0.32,AUC为0.712,bin越小坏样本率越低。
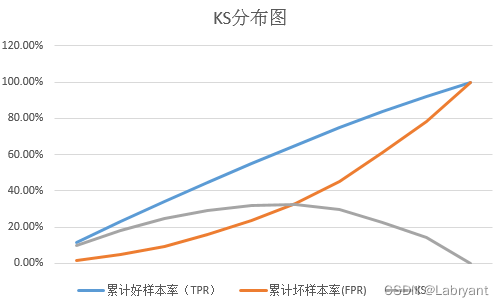

情况二,如果将1和0的定义进行互换,即1代表用户未逾期,0代表用户逾期,模型预测的是用户未逾期的概率。此时得到模型的KS为0.32,AUC为0.288,正好是1-0.712。所以预测目标如果变反,会导致AUC的值变成1-原来的AUC。特意又去翻了一下葫芦书,在介绍AUC的时候是这么写的:AUC的取值一般在0.5-1之间,如果不是的话,只要把模型预测的概率反转成1-p就可以得到一个更好的分类器。
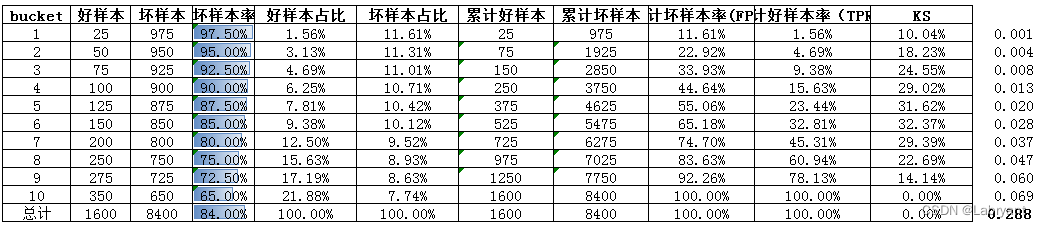
情况三,还是同最上面的例子,1代表用户发生逾期,标记为坏样本,模型预测的是用户发生逾期的概率。
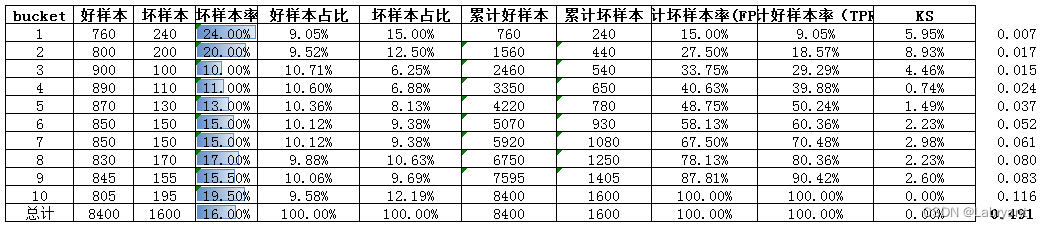
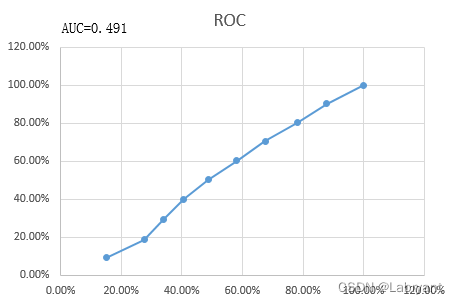
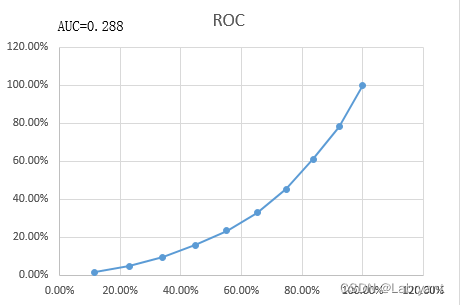
模型的AUC值为0.491,小于0.5,正常来说一般是大于0.5的。情况一中,bin越大坏样本率越高;情况二中,bin越大坏样本率越低,AUC小于0.5。所以情况三出现的原因应该是,在理应是bin越大坏样本率越高的情形中,出现了bin越大坏样本率越低的情况,简单来说就是出现了风险倒挂或者反向预测。看上表中坏样本率这一列,也可以发现bin1-2这两个bin的坏样本率出现了明显的倒挂。
下面将每两个bin合成一个bin,再看下整体的区分度情况。除了bin1-2的坏账率明显倒挂之外,其余bin仍有一定的区分度。所以即使AUC接近0.5甚至小于0.5的情况下,也不能一概而论说该模型完全没有区分度。至于倒挂的原因,这里胡乱提一个,比如从组成该模型的各变量维度上看,bin1-2确实是被该模型识别出来更好的人,但是由于对这些人提额过度超过了其真实还款能力,所以发生逾期。抛转引玉,本文不再过多展开。

最后,本文想传达的一个观点,在实践中遇到指标异常的情况,不要简单地归类为该变量/模型效果不好,还是要回到指标的计算逻辑,多思考背后的原因,一个指标也只是反映了某一部分的情况,这样也有利于加深对这些指标的理解和运用,带着好奇心去思考。
如需要文中案例,可后台回复“AUC指标”。往期关于指标的介绍文章可通过以下链接直达:
1、模型评估指标之间的联系
2、风险区分度—IV、KS和分布
【作者】:Labryant
【原创公众号】:风控猎人
【简介】:做一个有规划的长期主义者。
【转载说明】:转载请说明出处,谢谢合作!~