目录
编辑
一,HTTP协议基本认识
二,认识URL
三,http协议的格式
1,发送格式
2,回应格式
四,服务端代码
五,http报文细节
1,Post与Get方法
2,Content_lenth
3,状态码
4,Location
5,content_type
编辑
一,HTTP协议基本认识
在我之前写的文章中,我实现过自定义协议。但是,在实际的网络编程中我们是不太需要定制协议的。因为前辈早就定制好了。而HTTP协议就是其中的一种。 http协议又被叫做超文本传输协议,这是因为http的本质其实就是按照http协议从服务端拿文件资源。而http协议能够拿走所有的文件资源,所以http协议又被叫做超文本传输协议。
二,认识URL
URL:Uniform Resource Locator,中文名叫统一资源定位符。
URL的样子如下:
http://www.example.com/path/to/resource?query=string#fragment
http://是协议部分,表示这是一个使用 HTTP 协议的 URL。www.example.com是域名部分,表示资源所在的服务器的地址。/path/to/resource是路径部分,表示服务器上资源的具体位置。?query=string是查询字符串部分,用于传递参数给服务器。#fragment是片段标识符部分,用于指定资源的某一部分,通常用于网页的导航。
域名其实就是ip地址,那为什么只要有ip地址就可以访问到主机上的唯一资源呢?
因为http的端口号是默认绑定的,是统一的不需要我们再来绑定。
urlencode与urldecode
urlencode:在url中有些符号是被url默认使用了的。比如:?://。当我们的用户输入的url中带有这些字符时这些字符就会被encode。encode的规则是:将对应的字符的ASSCALL码转化为16进制,然后在前面加上%。urldecode就是反过来。当然,这个过程并不需要我们来做,有相应的工具可以帮我们完成:urlencode&&urldecode工具
三,http协议的格式
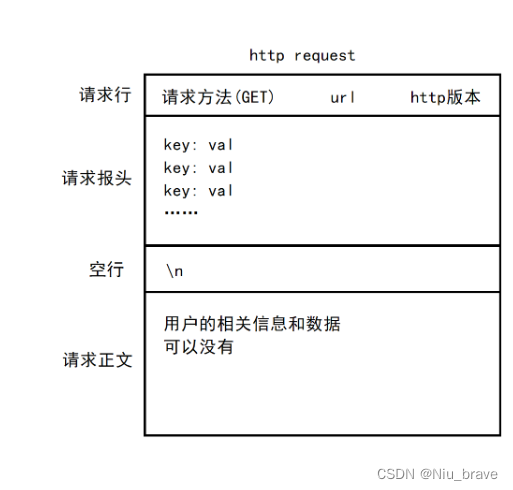
1,发送格式
当我们以http为协议向服务端发送请求时,我们发送的数据会包含如下数据:
1,请求行
2,请求报文
3,一个空行
4,请求正文
在请求行,包含如下数据:
1,method 2,url 3,http version 4,"\r\n"
图示如下:
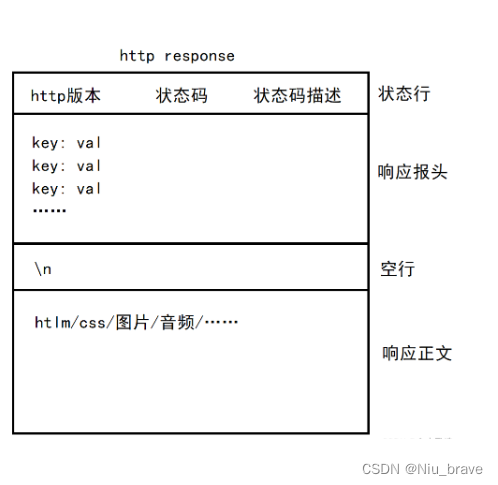
2,回应格式
当服务器在将数据发送回客户端时,会依照如下何时将数据返回:
1,状态行
2,响应报文
3,空行
4,响应正文
在状态行内,包含如下数据:
1,http version 2,状态码 3,状态码描述 4,“"\r\n"
图示如下:
四,服务端代码
在了解了http发送消息和响应消息的数据发送格式以后,我们便可以来动手写上一个能够按照http协议的格式进行响应的服务端。
实现如下:
1,为了能够更方便的使用创建套接字的接口,我对创建套接字的接口做如下封装
#pragma once
#include<iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include<cstring>
#include<arpa/inet.h>
#include<unistd.h>//定义一些变量
#define blog 10
#define defaultport 8080class Socket
{public://构造函数Socket(): sockfd_(0){}public://创建套接字bool Sock(){sockfd_ = socket(AF_INET, SOCK_STREAM, 0); // 创建套接字if (sockfd_ < 0){std::cerr << "创建套接字失败" << std::endl;return false;}int opt = 1;setsockopt(sockfd_, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));return true; // 将创建好的套接字返回}//bind,服务端只要绑定端口号bool Bind(int port = defaultport){sockaddr_in server_addr;memset(&server_addr, 0, sizeof (server_addr));//清空数据server_addr.sin_family = AF_INET;server_addr.sin_port = htons(port);server_addr.sin_addr.s_addr = INADDR_ANY;int r1 = bind(sockfd_,(sockaddr*)&server_addr,sizeof server_addr);if(r1<0){std::cerr << "bind err" << std::endl;return false;}return true;}//监听bool Listen(){int r2 = listen(sockfd_, blog);if(r2<0){std::cerr << "listen err" << std::endl;return 0;}return true;}//接收int Accept(std::string* ip,int* port){sockaddr_in cli_addr;socklen_t len = sizeof(cli_addr);int sockfd = accept(sockfd_, (sockaddr *)&cli_addr, &len);if(sockfd<0){std::cerr << "accept err" << std::endl;return -1;}char buff[64]={0};inet_ntop(AF_INET, &cli_addr, buff, sizeof(buff));*ip = buff;*port = ntohs(cli_addr.sin_port);return sockfd;}//连接bool Connect(std::string& ip,int16_t port){sockaddr_in addr_;addr_.sin_family = AF_INET;addr_.sin_port = htons(port);inet_pton(AF_INET, ip.c_str(), &(addr_.sin_addr));int r = connect(sockfd_, (sockaddr *)&addr_, sizeof (addr_));if(r<0){std::cerr << "connect err" << std::endl;return false;}return true;}//关闭void Close(){close(sockfd_);}public://成员int sockfd_;
};2,服务端代码
在做好上述封装工作以后便可以来构建服务端了,服务端的创建步骤如下:
1,类成员
1,listensockfd_: Sock类成员。主要是为了调用创建套接字的接口。
2,port_:端口号,主要是为了绑定时使用。
2,构造函数
初始化port_
3,Init函数
创建套接字 bind套接字 监听套接字
4,Start函数
1,循环接收服务端发来的连接请求,然后创建线程执行相应的任务。
2,读出客户端发来的请求。
3,然后根据http协议将请求处理出来到req中。
4,根据url判断客户端想要请求的资源是服务器那个资源。
5,读出资源发送回客户端。
在理清上面创建服务端的过程以后,便可以写出如下代码:
struct ThreadData
{int sockfd;
};class HttpServer
{public:HttpServer(int port):port_(port){} void Init(){listensocket_.Sock();//创建套接字listensocket_.Bind(port_);//绑定套接字端口listensocket_.Listen();//监听套接字}bool Start(){while (true){// 建立连接std::string ip;int port;int sockfd = listensocket_.Accept(&ip, &port_);lg(Debug, "link->%s:%d sucess,sockfd:%d", ip.c_str(), port_,sockfd);// 创建线程执行任务pthread_t td;ThreadData ts;ts.sockfd = sockfd;pthread_create(&td, nullptr, ThreadRun, &ts);}return true;}static void* ThreadRun(void*args){pthread_detach(pthread_self());//与主线程分离ThreadData* ts = static_cast<ThreadData*>(args);Helper(ts->sockfd);//处理客户端发来的消息delete ts;return nullptr;}private:Socket listensocket_;int port_;};
如何处理客户端发来的消息?
代码如下:
static void Helper(int sockfd){// 接收消息并打印char buff[1024] = {0};int n = recv(sockfd, buff, sizeof(buff), 0);if (n > 0){ //显示读出来的消息buff[n] = 0;std::cout << buff << std::endl;//读出来的消息进行解析处理,得到客户端想要访问什么资源Request req;req.Deserialize(buff);req.prase(buff);std::string path = req.Select_path();path = rootpath + path;std::cout << "debug: " << std::endl;req.Debugprint();//根据http协议的方式将资源发送会给客户端std::string text = Readrequest(path);std::string response;std::string sep = "\r\n";std::string line = "HTTP 1.1 1 OK";line += sep;std::string head = "contentlenth:";std::string len = std::to_string(text.size());head += len;head += sep;head += sep;response+=line;//状态行response += head;//报头response += text;//正文send(sockfd, response.c_str(), response.size(), 0);}}
如何对客户端的发来的消息进行处理呢?
创建一个Request类,这个类里面含有如下成员:
1, std::vector<std::string> arr :对内容进行分割
2, std::string text :将正文提取出来
######################################
3,std::string method :接收方法
4,std::string url :显示网址
5,std::string http_version :显示http的版本
6, std::string path :表示路径
类方法如下:
1,Deseralize: 对从客户端接收到的消息里的请求行和报文进行打散,打散到我的arr数组里面。并将正文提取出来。
2,prase:打散后,arr[0]便代表着请求行,包含着三个信息:method url http version。通过prase函数将这些消息获取出来。
3,DebugPrint:显示相应的消息。用于debug。
4,select_path:选择路径。
实现如下:
class Request
{public:void Deserialize(std::string message){while (true)//循环读取{int pos = message.find(sep);if(pos == std::string ::npos){break;}std::string str = message.substr(0, pos);if(str.empty())break;arr.push_back(str);message.erase(0, pos + 1);//读一行消一行}text = message;}void prase(std::string message)//将状态行的信息散开{std::stringstream s (message);s >> method >> url >> http_version;}void Debugprint(){for(auto e:arr){std::cout << e <<" "<<std::endl ;}std::cout << "method:" << method << std::endl;std::cout << "url:" << url << std::endl;std::cout<< "http_version:" << http_version << std::endl;}std::string Select_path(){if(url == "/"||url == "/html.index"){path = rootpath+"/";}else {path = url;}return path;}private:std::vector<std::string> arr;std::string text;std::string method;std::string url;std::string http_version;std::string path;
};返回消息:
当我们处理了客户端发来的消息以后,便可以得到客户端想要的资源在那个路径下。于是我们便可以将该路径对应的文件的内容读出来并返回给客户端显示。
读取文件的函数如下:
std::string Readrequest(std::string path)//从文件内读取
{ std::ifstream in(path);if(!in.is_open())return "404";std::string line;std::string content;while(getline(in,line)){content += line;}return content;//这个消息会拼接到正文,也就是text
}
五,http报文细节
1,Post与Get方法
在http的请求报头当中,经常使用的请求方法有如下两个:1,Post 2,Get
Post:
Post方法在提取form表单的参数时,通常会将参数放到正文部分来提交参数。
Get:
Get方法在提取表单的参数时,通常会将参数放到url的后面来提交参数。
相对于Get方法,Post方法提交参数的方式比较隐蔽。但是两种提交参数的方式都是不安全的。因为通过抓包都可以将报文抓取然后获取报文的所有内容。如果想要安全就得加密,加密协议就是https协议。
2,Content_lenth
在相应报文的报头里面有一个Content_lenth的字段,代表着正文的长度。报头与正文之间通过一个空行来分隔,分割以后,正文内容的大小由Content_lenth来指定,进而进行读取。
3,状态码
在http报文当中,相应报文内的状态行中会有一串数字表示响应的状态。

比如,200就代表正常,状态码描述便是ok。
通常,状态码对应的消息如下
1xx:信息型状态码。
2xx:代表请求ok,如200。
3xx:代表重定向,如301(永久重定向) 302(临时重定向)。
4xx:代表客户端请求错误,如404。
5xx:代表服务端内部错误,如501。
4,Location
Location字段一般都是和重定向状态3xx搭配使用的。当我的客户端申请访问我们已经移动后的资源时,服务端的Location字段便会指引客户端去访问移动后的资源。
5,content_type
content_type标识的是正文的文件类型。这个,content_type放在报头,指明文件类型,进而让客户端以正确的类型收取文件资源显示文件资源。
6,cookie
cookie字段的作用是储存少量信息,用于搭建临时会话。
在我们的浏览器上,其实每次访问一个资源都是需要认证的。比如你在一个浏览器上第一次访问b站,我们是不是要进行登录认证呢?是的吧,那我们看b站上的视频需不需要进行认证呢?其实也是需要的,但是cookie已经帮你吧认证信息存储起来了,所以会帮你自动登录认证。
分类:
cookie文件一般分为内存文件和硬盘文件。为了安全,一般都会设置为内存文件(会定时清理)。比如在edge 浏览器上便是内存文件。
更完整细节:

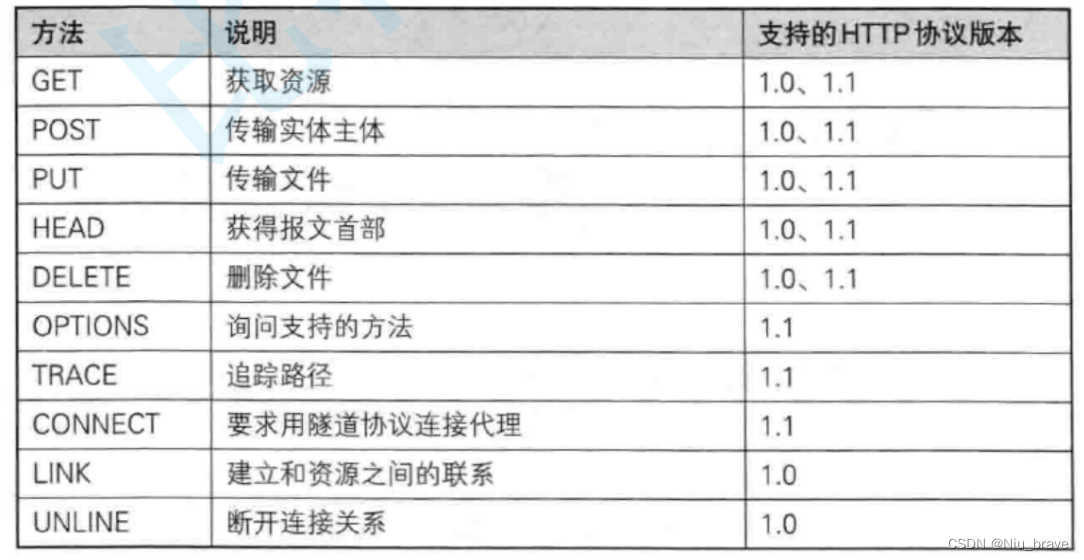
HTTP方法: