并发现象遍布日常生活,我们时常接触:我们可以边走路边说话;或者,左右手同时做出不一样的动作。在计算机应用程序中也有很好的例子:
- 浏览器 - 浏览器可以同时下载任意数量的文件和打开多个网页,下载时仍允许您继续浏览网页。如果某个网页无法下载,这并不会阻止网络浏览器下载其他网页。
- 电脑游戏 - 有各种各样的对象,如汽车、人类、鸟类,它们被实现为单独的线程,能够同时具有各自独立的行为。
- 文本编辑器 - 当您在编辑器中输入内容时,拼写检查、文本格式化和保存文本由多个线程同时完成。
1 什么是并发?
我们是不是经常会区分不了并发、并行、异步这些看似相近实则差异很大的概念。
下面这些人在并行工作:

并行程序将其任务分配给多个处理器,这些处理器同时主动处理所有这些任务。
下面这个家伙并发玩着8个球:

并发程序处理同时进行的所有任务,但只需简单且单独地处理每个任务,因此可以按照任务所需的任何顺序交错工作。
下面这个家伙异步地一边洗衣服,一边阅读:

异步程序将任务分配给可以各自处理的设备,让程序自由地执行其操作,直到收到结果完成的信号。
2 实现并发的两种方式
并发的实现有两种方式:多进程并发和多线程并发。
在应用软件内部,一种并发方式是,将一个应用软件拆分成多个独立进程同时运行,它们都只含单一线程,非常类似于同时运行浏览器和文字处理软件。这些独立进程可以通过所有常规的进程间通信途径相互传递信息(信号、套接字、文件、管道等)
另一种并发方式是在单一进程内运行多线程。线程非常像轻量级进程:每个线程都独立运行,并能各自执行不同的指令序列。
我们可以启用多个单线程的进程并在进程间通信,也可以在单一进程内发动多个线程而在线程间通信,后者的额外开销更低。
3 进程与线程
一个正在运行的程序称为进程,我们将进程视为一系列事件,但操作系统将进程视为普通数据对象。
进程具有上下文和状态。上下文由堆栈、堆、静态和代码内存段以及计算机寄存器的当前内容(例如状态寄存器、堆栈指针、程序计数器等)组成。

进程可处于运行、就绪或阻塞状态:

就绪状态意味着进程正在就绪队列中等待CPU。运行状态表示进程控制CPU并且当前正在运行。阻塞状态意味着进程没有运行,因为它正在等待定时器到期、信号量获取或用户输入事件。
当一个进程进入阻塞状态时,操作系统将CPU从该进程手中夺走,并将其交给就绪队列中的下一个进程。当事件发生时,被阻塞的进程进入就绪状态并加入就绪队列。进程可以具有确定其被放置在就绪队列中的位置的优先级。当一个正在运行的进程的时间片到期(例如1/100秒)时,抢占式操作系统可以将CPU从正在运行的进程中夺走,并强制它回到就绪队列中。否则我们就说操作系统是非抢占式的。Win32是抢占式的。
将CPU从正在运行的进程中夺走并将其交给下一个就绪进程称为进程切换。这涉及更改旧正在运行的进程的状态并保持其上下文,然后更改新进程的状态并恢复期上下文。
进程切换可能非常耗时,因为保存和恢复的上下文可能很大。这往往会阻碍协作流程的使用。此外,协作进程之间的通信必须使用某种进程间通信机制(IPC),例如管道或套接字。共享内存段是可能的,但很难设置。
某些操作系统允许进程将自身划分为单独的控制线程。与进程一样,线程也称为轻量级进程,有自己的状态和上下文,但线程的上下文仅由堆栈段和寄存器内容组成。其他段来自创建线程的进程。

线程间的协作很容易。线程切换速度很快,因为只需保存和恢复堆栈段和寄存器,并且特定进程创建的所有线程共享父进程的堆和静态段,通过它们可以进行通信。当然,共享内存和其他资源会引入同步问题,从而使多线程程序难以调试。
线程是对象的时间对应物。对象构造内存,线程构造时间。每个线程定义一系列与顺序相关的指令。操作系统决定不同线程中指令的执行顺序。这允许操作系统利用硬件中可能的并发机会。
线程状态
在任何时刻,线程都可以处于下图中所示的八种状态中的任何一种。大多数转换是下面讨论的线程方法:

抢占式与非抢占式调度
在单处理器计算机上有两种类型的多线程系统:抢占式和非抢占式。在非抢占式系统中,所有可运行线程都在就绪队列中等待当前正在运行的线程释放CPU。发生这种情况的原因可能是它终止、请求I/O,或者调用suspend()、wait()、sleep(t)、yield()或者stop()。我们常见的sleep(t)会强制将线程挂起t时间长度。
在抢占式系统中,CPU在固定时间片(例如一秒)内被分配给线程。如果一个线程在其时间片到期之前没有释放CPU,它将被中断,发送回就绪队列,并且CPU被分配给就绪队列中的“下一个”线程。
大多数多线程系统是抢占式的。
4 多线程
多线程主要与抢占式调度一起使用。因此,无法提前知道多个线程间的确切切换和交错。这代表了一种强烈的不确定性。如果没有进一步的关注,可变状态和不确定性会带来竞争条件的强烈危险。
当两个或多个线程竞争访问临界区(该部分包含线程间共享的状态)时,就会出现竞争条件。由于可能存在多种交错,竞争条件可能会导致各种不一致的状态。例如,一个线程可能会读取过时的状态,而另一个线程已经在更新它。当多个线程同时更改状态时,其中一个更改可能会持续,而其他更改可能会丢失,甚至受多个更改影响的不一致状态可能会持续存在。最终,我们需要机制来保护临界区并强制同步访问。
让我们来看一段代码来理解这一点。
#include <iostream>
#include <thread>int main()
{int sum = 0;auto f = [&sum](){for(int i = 0; i < 1000000; i++){sum += 1;}};std::thread t1(f);std::thread t2(f);t1.join();t2.join();std::cout << sum << std::endl;return 0;
}在此代码中,我们在两个线程上递增sum,而它们之间没有任何同步。我们期望总是能输出2000000,因为两个线程各自将其递增1000000。如果我们编译并运行此代码,我们发现事实并非如此。多次运行输出的sum值都不一样,具有强烈的不确定性。
同步的一般原语(所谓原语,一般是指由若干条指令组成的程序段,用来实现某个特定功能,在执行过程中不可被中断)是锁,它控制对临界区的访问。不同类型的锁具有不同的行为和语意。
锁允许我们串行化对临界区的访问。互斥量的使用产生临界区内线程的原子行为,因为它的执行对于其他等待线程来说表现为单个操作。识别容易受到竞争条件影响的代码部分,并仔细放置锁,以抑制不确定性并强制串行化访问。
然而,锁的概念给多线程代码带来了另一个危险。当获取的锁为释放或要获取的锁永远不可用时,不正确的锁定实际上可能会破坏程序。很明显,当开发人员必须显示放置wait和signal函数来保护时,可能会发生错误锁定。最臭名昭著的锁定问题就是所谓的死锁。当两个或多个线程竞争具有循环依赖关系的锁时,就会发生这种情况。最简单的场景中,两个线程都拥有一个单独的锁,但还需要获取另外一个线程的锁。由于没有线程可以在不获取第二个锁的情况下继续执行,因此两个线程就被阻塞并且无法执行。
下面就是一个简单的死锁示例:
int main() {std::mutex m1;std::mutex m2;std::thread t1([&m1, &m2] {print("1. Acquiring m1.");m1.lock();std::this_thread::sleep_for(std::chrono::milliseconds(10));print("1. Acquiring m2");m2.lock(); });std::thread t2([&m1, &m2] {print("2. Acquiring m2");m2.lock();std::this_thread::sleep_for(std::chrono::milliseconds(10));print("2. Acquiring m1");m1.lock();});t1.join();t2.join();
}5 死锁
在并发计算中,死锁是一种状态,这种状态下,一组成员中的每个成员都在等待另外一个成员(包括其自身)的操作,例如发送消息或释放锁。死锁是多处理系统、并行计算和和分布式系统中的常见问题。
在操作系统中,当进程或线程进入等待状态时,就可能发会发生死锁,因为所请求的系统资源由另外一个等待进程持有,而该进程可能又在等待另外一个进程持有的另外一个资源。如果一个进程由于其请求的资源在被另外一个等待进程使用而无法无限期的更改其状态,则称系统处于死锁状态。
在通信系统中,死锁的发生主要是由于信号丢失或损坏,而不是资源争用。
死锁必要条件
当且仅当系统中同时满足以下所有条件是,才会出现资源死锁情况:
- 互斥。至少一种资源必须以不可共享的模式持有。否则,将不会阻止进程(或线程)在必要时使用资源。换而言之,在任何给定时刻只有一个进程(或线程)可以使用该资源。
- 持有并等待资源。进程(或线程)当前持有至少一种资源,并请求其他进程(或线程)持有的额外资源。
- 无抢占。资源只能由持有该资源的进程(或线程)自愿释放。
- 循环等待。每个进程等待另外一个进程(或线程)占用的资源,而另外一个占用资源的进程(或线程)又等待第一个进程释(或线程)放资源。一般来说,有一组等待进程,P = {P1, P2, …, PN},其中P1在正在等待P2所持有的资源,P2正在等待P3所持有的资源,依次类推,直到PN为等待P1持有的资源。
下图显示了4个进程和一个资源。该图显示了2个进程争夺单个资源(中间灰色圆圈),然后是3个进程争夺该资源,最后是4个进程争夺同一资源的情况。

6 创建线程(join 和 detach)
创建线程的方式是构造一个std::thread对象,std::thread构造函数的参数第一个是回调函数,第二个是一个可变参数列表,可变参数列表与回调函数的参数一致,可以从源码看出:
_EXPORT_STD class thread { // class for observing and managing threads
public:class id;using native_handle_type = void*;thread() noexcept : _Thr{} {}private:
#if _HAS_CXX20friend jthread;
#endif // _HAS_CXX20template <class _Tuple, size_t... _Indices>static unsigned int __stdcall _Invoke(void* _RawVals) noexcept /* terminates */ {// adapt invoke of user's callable object to _beginthreadex's thread procedureconst unique_ptr<_Tuple> _FnVals(static_cast<_Tuple*>(_RawVals));_Tuple& _Tup = *_FnVals.get(); // avoid ADL, handle incomplete types_STD invoke(_STD move(_STD get<_Indices>(_Tup))...);_Cnd_do_broadcast_at_thread_exit(); // TRANSITION, ABIreturn 0;}template <class _Tuple, size_t... _Indices>_NODISCARD static constexpr auto _Get_invoke(index_sequence<_Indices...>) noexcept {return &_Invoke<_Tuple, _Indices...>;}#pragma warning(push) // pointer or reference to potentially throwing function passed to 'extern "C"' function under
#pragma warning(disable : 5039) // -EHc. Undefined behavior may occur if this function throws an exception. (/Wall)template <class _Fn, class... _Args>void _Start(_Fn&& _Fx, _Args&&... _Ax) {using _Tuple = tuple<decay_t<_Fn>, decay_t<_Args>...>;auto _Decay_copied = _STD make_unique<_Tuple>(_STD forward<_Fn>(_Fx), _STD forward<_Args>(_Ax)...);constexpr auto _Invoker_proc = _Get_invoke<_Tuple>(make_index_sequence<1 + sizeof...(_Args)>{});_Thr._Hnd =reinterpret_cast<void*>(_CSTD _beginthreadex(nullptr, 0, _Invoker_proc, _Decay_copied.get(), 0, &_Thr._Id));if (_Thr._Hnd) { // ownership transferred to the thread(void) _Decay_copied.release();} else { // failed to start thread_Thr._Id = 0;_Throw_Cpp_error(_RESOURCE_UNAVAILABLE_TRY_AGAIN);}}
#pragma warning(pop)public:template <class _Fn, class... _Args, enable_if_t<!is_same_v<_Remove_cvref_t<_Fn>, thread>, int> = 0>_NODISCARD_CTOR_THREAD explicit thread(_Fn&& _Fx, _Args&&... _Ax) {_Start(_STD forward<_Fn>(_Fx), _STD forward<_Args>(_Ax)...);}~thread() noexcept {if (joinable()) {_STD terminate();}}thread(thread&& _Other) noexcept : _Thr(_STD exchange(_Other._Thr, {})) {}thread& operator=(thread&& _Other) noexcept {if (joinable()) {_STD terminate();}_Thr = _STD exchange(_Other._Thr, {});return *this;}thread(const thread&) = delete;thread& operator=(const thread&) = delete;void swap(thread& _Other) noexcept {_STD swap(_Thr, _Other._Thr);}_NODISCARD bool joinable() const noexcept {return _Thr._Id != 0;}void join() {if (!joinable()) {_Throw_Cpp_error(_INVALID_ARGUMENT);}if (_Thr._Id == _Thrd_id()) {_Throw_Cpp_error(_RESOURCE_DEADLOCK_WOULD_OCCUR);}if (_Thrd_join(_Thr, nullptr) != _Thrd_success) {_Throw_Cpp_error(_NO_SUCH_PROCESS);}_Thr = {};}void detach() {if (!joinable()) {_Throw_Cpp_error(_INVALID_ARGUMENT);}_Check_C_return(_Thrd_detach(_Thr));_Thr = {};}_NODISCARD id get_id() const noexcept;_NODISCARD native_handle_type native_handle() noexcept /* strengthened */ { // return Win32 HANDLE as void *return _Thr._Hnd;}_NODISCARD static unsigned int hardware_concurrency() noexcept {return _Thrd_hardware_concurrency();}private:_Thrd_t _Thr;
};
一个线程可以等待另一个线程完成。等待其他线程的线程,需要调用被等待线程对象的 join() 函数。用法:
std::thread th(funcPtr);// Some Codeth.join();假设主线程启动了 10 个工作线程,然后需要等待他们全部完成。在它们完成工作后主线程继续做其他的事情:
#include <iostream>
#include <thread>
#include <algorithm>class WorkerThreadFunctor
{
public:void operator()() {std::cout<<"Worker Thread "<<std::this_thread::get_id()<<" is Executing"<<std::endl;}
};int main()
{// Create a Vector of Threadstd::vector<std::thread> threadList;// Add 10 thread objects in vectorfor(int i = 0; i < 10; i++){threadList.push_back( std::thread( WorkerThreadFunctor() ) );}std::cout<<"wait for all the worker thread to finish"<<std::endl;// Now wait for all the worker thread to finish i.e.// Call join() function on each of the std::thread objectfor (auto& th: threadList){th.join();}std::cout<<"Exiting from Main Thread"<<std::endl;return 0;
}输出:
Worker Thread 139872044054080 is Executing
Worker Thread 139872035661376 is Executing
Worker Thread 139872027268672 is Executing
Worker Thread 139872018875968 is Executing
Worker Thread 139872010483264 is Executing
Worker Thread 139871918224960 is Executing
Worker Thread 139872002090560 is Executing
Worker Thread 139871901439552 is Executing
wait for all the worker thread to finish
Worker Thread 139871909832256 is Executing
Worker Thread 139871893046848 is Executing
Exiting from Main Thread使用 std::thread::detach() 来 detach (分离)线程
分离的线程也被称为 "守护线程"( daemon threads ) / "后台线程" ( background threads ) 。想要分离一个线程,需要调用其所对应函数对象的 std::detach() 函数。如:
// Create a Thread
std::thread th(funcPtr);// Detach the thread i.e.
// thread will not be joinable now
th.detach();调用 detach() 后,std::thread 对象就不再和正在执行的线程有关联了。
关于join()和detach()函数的要点:
- 不要在与正在执行的线程不相关的线程对象上调用join()或detach()。在线程对象上调用join方法时,它会等待关联的线程完成。
- 避免重复调用join()或detach()。在线程对象上调用detach()会将该线程对象与正在执行的线程分离,如果对同一个线程对象调用detach()两次,程序将奔溃。
为了确保在调用join()或detach()之前的安全,建议使用joinable()方法检查线程是否连接,如给定示例中所示:
// Create thread object
std::thread threadObj( (WorkerThread()) );// Check if thread is joinable
if(threadObj.joinable())
{std::cout<<"Detaching Thread "<<std::endl;threadObj.detach();
}// Check if thread is joinable
if(threadObj.joinable())
{std::cout<<"Detaching Thread "<<std::endl;threadObj.detach();
}// Create thread object
std::thread threadObj2( (WorkerThread()) );// Check if thread is joinable
if(threadObj2.joinable())
{std::cout<<"Joining Thread "<<std::endl;threadObj2.join();
}// Check if thread is joinable
if(threadObj2.joinable())
{std::cout<<"Joining Thread "<<std::endl;threadObj2.join();
}7 原子操作(std::atomic)
原子(atomic)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为“不可被中断的一个或一系列操作”。
当特定线程对对象执行原子操作时,在原子操作进行期间,其他线程都无法读取或修改该对象。这意味着其他线程只能看到操作之前或之后的对象——没有中间状态。
让我们看下下面这段代码:
#include <iostream>
#include <thread>int main()
{int sum = 0;auto f = [&sum](){for(int i = 0; i < 1000000; i++){sum += 1;}};std::thread t1(f);std::thread t2(f);t1.join();t2.join();std::cout << sum << std::endl;return 0;
}当一个线程增加sum时,需要从内存中读取该值,修改(增加)并写入内存。换句话说,这是一个读取-修改-写入操作。
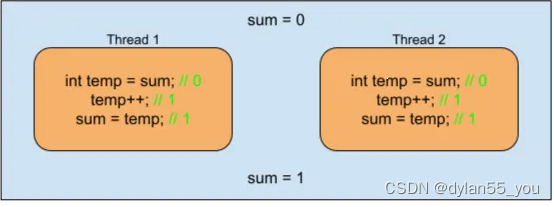
没有任何同步,两个线程会从内存中读取sum为0,然后递增,最后将1写回内存。这意味着,无论哪个线程先写入,其结果都会被另外一个线程破坏。
这被称为数据竞争,是一种未定义的行为。正如我们的例子所示,未定义的行为导致我们可能会丢失一些增量的结果。
需要注意的是,在x86上,对于内置类型(int, float, bool,....),读取和写入是原子的。在其他平台上可能并非如此,因此以不同的线程对同一变量进行非原子读取和写入意味着你可能在输出中看到各种情况。(不确定的行为对应不确定的结果)
但是你可能想知道,如果x86上的读取和写入是原子的,为什么输出仍然不一致?这是因为增量(读取-修改-写入)操作作为一个整体不是原子的。这意味着另外一个线程可以在读取和写入之间来取到值。
首先,我们可以通过将sum声明为原子变量来保证原子性。然后,我们可以将增量拆分为原子读取,然后是原子写入。
如下:
std::atomic<int> sum(0);auto f = [&sum](){for(int i = 0; i < 1000000; i++){sum = sum + 1;}
};编译运行,我们仍然会得到不一致的结果。
在底层上,x86机器上可能会发现以下情况:

- Core1的缓存自动从内存中获取sum(sum == 0),Core1然后将其递增到1。
- Core2的缓存自动从内存中获取sum(sum == 0),Core2然后将其递增到2。
- Core2将1写回其缓存,然后传递到内存(sum == 1)。
- Core1将1写回其缓存,然后也会传递到内存,并覆盖Core2写入的值(sum == 1)。
这样我们就丢失了其中一个增量的结果。
为了保证结果的一致性,我们希望确保增量操作的一致性,我们希望确保增量操作作为一个整体是原子的。我们可以更新我们的代码来实现这一点。
auto f = [&sum](){for(int i = 0; i < 1000000; i++){sum++; // Same as sum+=1;}
};这是因为std::automic重载了operator+=和operator++,它们会原子地增加值。使用fetch_add()可以实现相同的效果。通过确保读取-修改-写入操作以原子方式完成,我们实现了所需的行为。
再回来看底层实现逻辑:
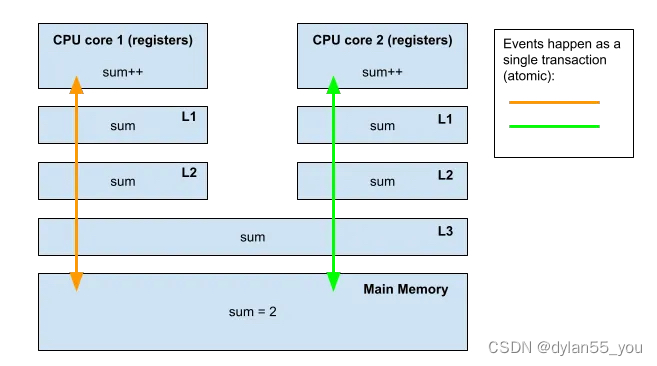
- Core1获得对sum的独占访问权限(硬件)。
- Core1的缓存从内存中获取sum(sum == 0)。
- 然后Core1将值增加到1并写入其缓存,缓存会传递到主内存并释放独占权限。
- 然后Core2将执行相同的过程并将sum增加到2。
原子类型
只有简单可复制的类型才能被作为原子类型,也即是可在内存中进行位拷贝或是使用memcpy()拷贝的类型。
这意味着具有虚拟函数或未存储在连续内存中的类型无法成为原子类型。
有些原子类型是无锁实现的,有些则不是。这取决于平台,主要是因为该平台上对原子指令有对其要求。
当原子操作不是无锁操作时,通常会使用某种类型的互斥锁或者其他锁定操作来实现,但这不影响std::automic用于原子操作的目的。
8 互斥量(std::mutex 和 std::recursive_mutex)
互斥量是一个同步原语,可用于保护共享数据不被多个线程同时访问。
std::mutex
std::mutex提供独占的、非递归的所有权语义:
- 正在调用的线程从成功调用lock或try_lock开始到调用unlock为止一直独占mutex。
- 当一个线程占有mutex时,其他线程尝试声明该互斥量的所有权限的都将被阻塞(对于lock调用)或者返回false值(对于try_lock调用)。
- 在调用lock和try_lock之前,线程不得占有mutex。
如果std::mutex在仍由某个线程占有时被销毁,或者线程在占有互斥量时被终止,则程序的行为将是未定义的。std::mutex既不可拷贝(拷贝构造)也不可移动(移动构造)。
std::mutex通常不直接访问。而是通过std::unique_lock、std::lock_guard或std::scoped_lock(C++17起)以更加安全的方式管理锁定。
下面我们从源码角度来看看,std::mutex是如何实现互斥效果的:
C:\Program Files\Microsoft Visual Studio\2022\Professional\VC\Tools\MSVC\14.36.32532\crt\src\stl\mutex.cpp
// Copyright (c) Microsoft Corporation.
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception// mutex functions#include <cstdio>
#include <cstdlib>
#include <internal_shared.h>
#include <type_traits>
#include <xthreads.h>
#include <xtimec.h>#include "primitives.hpp"extern "C" _CRTIMP2_PURE void _Thrd_abort(const char* msg) { // abort on precondition failurefputs(msg, stderr);fputc('\n', stderr);abort();
}#if defined(_THREAD_CHECK) || defined(_DEBUG)
#define _THREAD_CHECKX 1
#else // defined(_THREAD_CHECK) || defined(_DEBUG)
#define _THREAD_CHECKX 0
#endif // defined(_THREAD_CHECK) || defined(_DEBUG)#if _THREAD_CHECKX
#define _THREAD_QUOTX(x) #x
#define _THREAD_QUOT(x) _THREAD_QUOTX(x)
#define _THREAD_ASSERT(expr, msg) ((expr) ? (void) 0 : _Thrd_abort(__FILE__ "(" _THREAD_QUOT(__LINE__) "): " msg))
#else // _THREAD_CHECKX
#define _THREAD_ASSERT(expr, msg) ((void) 0)
#endif // _THREAD_CHECKX// TRANSITION, ABI: preserved for binary compatibility
enum class __stl_sync_api_modes_enum { normal, win7, vista, concrt };
extern "C" _CRTIMP2 void __cdecl __set_stl_sync_api_mode(__stl_sync_api_modes_enum) {}struct _Mtx_internal_imp_t { // ConcRT mutexint type;typename std::_Aligned_storage<Concurrency::details::stl_critical_section_max_size,Concurrency::details::stl_critical_section_max_alignment>::type cs;long thread_id;int count;Concurrency::details::stl_critical_section_interface* _get_cs() { // get pointer to implementationreturn reinterpret_cast<Concurrency::details::stl_critical_section_interface*>(&cs);}
};static_assert(sizeof(_Mtx_internal_imp_t) <= _Mtx_internal_imp_size, "incorrect _Mtx_internal_imp_size");
static_assert(alignof(_Mtx_internal_imp_t) <= _Mtx_internal_imp_alignment, "incorrect _Mtx_internal_imp_alignment");void _Mtx_init_in_situ(_Mtx_t mtx, int type) { // initialize mutex in situConcurrency::details::create_stl_critical_section(mtx->_get_cs());mtx->thread_id = -1;mtx->type = type;mtx->count = 0;
}void _Mtx_destroy_in_situ(_Mtx_t mtx) { // destroy mutex in situ_THREAD_ASSERT(mtx->count == 0, "mutex destroyed while busy");mtx->_get_cs()->destroy();
}int _Mtx_init(_Mtx_t* mtx, int type) { // initialize mutex*mtx = nullptr;_Mtx_t mutex = static_cast<_Mtx_t>(_calloc_crt(1, sizeof(_Mtx_internal_imp_t)));if (mutex == nullptr) {return _Thrd_nomem; // report alloc failed}_Mtx_init_in_situ(mutex, type);*mtx = mutex;return _Thrd_success;
}void _Mtx_destroy(_Mtx_t mtx) { // destroy mutexif (mtx) { // something to do, do it_Mtx_destroy_in_situ(mtx);_free_crt(mtx);}
}static int mtx_do_lock(_Mtx_t mtx, const xtime* target) { // lock mutexif ((mtx->type & ~_Mtx_recursive) == _Mtx_plain) { // set the lockif (mtx->thread_id != static_cast<long>(GetCurrentThreadId())) { // not current thread, do lockmtx->_get_cs()->lock();mtx->thread_id = static_cast<long>(GetCurrentThreadId());}++mtx->count;return _Thrd_success;} else { // handle timed or recursive mutexint res = WAIT_TIMEOUT;if (target == nullptr) { // no target --> plain wait (i.e. infinite timeout)if (mtx->thread_id != static_cast<long>(GetCurrentThreadId())) {mtx->_get_cs()->lock();}res = WAIT_OBJECT_0;} else if (target->sec < 0 || target->sec == 0 && target->nsec <= 0) {// target time <= 0 --> plain trylock or timed wait for time that has passed; try to lock with 0 timeoutif (mtx->thread_id != static_cast<long>(GetCurrentThreadId())) { // not this thread, lock itif (mtx->_get_cs()->try_lock()) {res = WAIT_OBJECT_0;} else {res = WAIT_TIMEOUT;}} else {res = WAIT_OBJECT_0;}} else { // check timeoutxtime now;xtime_get(&now, TIME_UTC);while (now.sec < target->sec || now.sec == target->sec && now.nsec < target->nsec) { // time has not expiredif (mtx->thread_id == static_cast<long>(GetCurrentThreadId())|| mtx->_get_cs()->try_lock_for(_Xtime_diff_to_millis2(target, &now))) { // stop waitingres = WAIT_OBJECT_0;break;} else {res = WAIT_TIMEOUT;}xtime_get(&now, TIME_UTC);}}if (res == WAIT_OBJECT_0 || res == WAIT_ABANDONED) {if (1 < ++mtx->count) { // check countif ((mtx->type & _Mtx_recursive) != _Mtx_recursive) { // not recursive, fixup count--mtx->count;res = WAIT_TIMEOUT;}} else {mtx->thread_id = static_cast<long>(GetCurrentThreadId());}}switch (res) {case WAIT_OBJECT_0:case WAIT_ABANDONED:return _Thrd_success;case WAIT_TIMEOUT:if (target == nullptr || (target->sec == 0 && target->nsec == 0)) {return _Thrd_busy;} else {return _Thrd_timedout;}default:return _Thrd_error;}}
}int _Mtx_unlock(_Mtx_t mtx) { // unlock mutex_THREAD_ASSERT(1 <= mtx->count && mtx->thread_id == static_cast<long>(GetCurrentThreadId()), "unlock of unowned mutex");if (--mtx->count == 0) { // leave critical sectionmtx->thread_id = -1;mtx->_get_cs()->unlock();}return _Thrd_success; // TRANSITION, ABI: always returns _Thrd_success
}int _Mtx_lock(_Mtx_t mtx) { // lock mutexreturn mtx_do_lock(mtx, nullptr);
}int _Mtx_trylock(_Mtx_t mtx) { // attempt to lock try_mutexxtime xt;_THREAD_ASSERT((mtx->type & (_Mtx_try | _Mtx_timed)) != 0, "trylock not supported by mutex");xt.sec = 0;xt.nsec = 0;return mtx_do_lock(mtx, &xt);
}int _Mtx_timedlock(_Mtx_t mtx, const xtime* xt) { // attempt to lock timed mutexint res;_THREAD_ASSERT((mtx->type & _Mtx_timed) != 0, "timedlock not supported by mutex");res = mtx_do_lock(mtx, xt);return res == _Thrd_busy ? _Thrd_timedout : res;
}int _Mtx_current_owns(_Mtx_t mtx) { // test if current thread owns mutexreturn mtx->count != 0 && mtx->thread_id == static_cast<long>(GetCurrentThreadId());
}void* _Mtx_getconcrtcs(_Mtx_t mtx) { // get internal cs implreturn mtx->_get_cs();
}void _Mtx_clear_owner(_Mtx_t mtx) { // set owner to nobodymtx->thread_id = -1;--mtx->count;
}void _Mtx_reset_owner(_Mtx_t mtx) { // set owner to current threadmtx->thread_id = static_cast<long>(GetCurrentThreadId());++mtx->count;
}/** This file is derived from software bearing the following* restrictions:** (c) Copyright William E. Kempf 2001** Permission to use, copy, modify, distribute and sell this* software and its documentation for any purpose is hereby* granted without fee, provided that the above copyright* notice appear in all copies and that both that copyright* notice and this permission notice appear in supporting* documentation. William E. Kempf makes no representations* about the suitability of this software for any purpose.* It is provided "as is" without express or implied warranty.*/
mtx_do_lock函数
该函数处理加锁操作。
if ((mtx->type & ~_Mtx_recursive) == _Mtx_plain) 。此判断内处理非递归互斥量,else内处理其他互斥量(例如递归互斥量)。
if (mtx->thread_id != static_cast<long>(GetCurrentThreadId()))。GetCurrentThreadId()是Win32 API中的一个函数,用于获取被调用线程的ID。从这一句可以看出如果锁已经被某一个线程占用,再来给该线程加锁是加不上的。
mtx->_get_cs()->lock()。在_Mtx_init_in_situ函数中会调用Concurrency::details::create_stl_critical_section(mtx->_get_cs()) 创一个临界区对象(可通过_get_cs()获取到):
inline void create_stl_critical_section(stl_critical_section_interface* p) {
new (p) stl_critical_section_win7;
}
class __declspec(novtable) stl_condition_variable_interface {public:virtual void wait(stl_critical_section_interface*) = 0;virtual bool wait_for(stl_critical_section_interface*, unsigned int) = 0;virtual void notify_one() = 0;virtual void notify_all() = 0;virtual void destroy() = 0;};class stl_critical_section_win7 final : public stl_critical_section_interface {public:stl_critical_section_win7() {InitializeSRWLock(&m_srw_lock);}~stl_critical_section_win7() = delete;stl_critical_section_win7(const stl_critical_section_win7&) = delete;stl_critical_section_win7& operator=(const stl_critical_section_win7&) = delete;void destroy() override {}void lock() override {AcquireSRWLockExclusive(&m_srw_lock);}bool try_lock() override {return TryAcquireSRWLockExclusive(&m_srw_lock) != 0;}bool try_lock_for(unsigned int) override {// STL will call try_lock_for once again if this call will not succeedreturn stl_critical_section_win7::try_lock();}void unlock() override {ReleaseSRWLockExclusive(&m_srw_lock);}PSRWLOCK native_handle() {return &m_srw_lock;}private:SRWLOCK m_srw_lock;};在上面临界区对象的lock()函数中,我们可以看到它会获取一个SRWLock。
SRWLock
SRWLock是Win32 API提供的一个简化(slim)读/写锁,它使单个进程的线程能够访问共享资源,它针对速度进行了优化并且占用了很少的内存(因为它做了内存的对齐处理),SRWLock不能跨进程共享。
SRWLock提供了两种线程访问共享资源的模式:
- 共享模式(Shared mode)。向多个读写线程授予共享只读访问权限,使它们能够同时从共享资源中读取数据。如果读取操作超过写入操作,则与临界区相比,这种并发性会提高性能和吞吐量。
- 独占模式(Exclusive mode)。一次向一个线程授予读/写权限。当以独占模式获取锁时,在写入者释放之前,其他线程都无法访问共享资源。
我们可以看到lock()函数中调用的是AcquireSRWLockExclusive,所以其获取的是独占模式的锁,所以std::mutex在多线程间是互斥(或独占)的。unlock()函数被调用时,其函数内会调用ReleaseSRWLockExclusive释放锁定。
std::recursive_mutex
std::recursive_mutex提供独占的、递归的所有权语义:
- 正在调用的线程在成功调用lock或try_lock时开始一段时间内独占recursive_mutex。在此期间,同一线程内可能会额外再调用lock或try_lock。当线程调用相同数量的unlock时,所有权期限结束。
- 当一个线程占有recursive_mutex时,如果其他线程尝试声明recursive_mutex的所有权,则它们将被阻塞(对于lock调用)或收到false的返回值(对于try_lock调用)。
- recursive_mutex可以被锁定的最大次数是未指定的,但是当达到很大数量(未定义,无需担心)时将抛出std::system_error并且对try_lock的调用将返回false。
如果std::mutex在仍由某个线程占有时被销毁,则程序的行为将是未定义的。
std::recursive_mutex是如何实现递归效果的,我们还是从源码(mutex.cpp)来看:
std::mutex和std::recursive_mutex在构造时,都会调用_Mtx_init函数,在该函数中会创建一个结构体:
struct _Mtx_internal_imp_t { // ConcRT mutexint type;typename std::_Aligned_storage<Concurrency::details::stl_critical_section_max_size,Concurrency::details::stl_critical_section_max_alignment>::type cs;long thread_id;int count;Concurrency::details::stl_critical_section_interface* _get_cs() { // get pointer to implementationreturn reinterpret_cast<Concurrency::details::stl_critical_section_interface*>(&cs);}
};
该结构体中存了3个成员变量:type(互斥量的类型)、thread_id(占有互斥量线程的ID)、count(执行锁定的次数)。
if (res == WAIT_OBJECT_0 || res == WAIT_ABANDONED) {if (1 < ++mtx->count) { // check countif ((mtx->type & _Mtx_recursive) != _Mtx_recursive) { // not recursive, fixup count--mtx->count;res = WAIT_TIMEOUT;}} else {mtx->thread_id = static_cast<long>(GetCurrentThreadId());}}if (1 < ++mtx->count)对count进行了++处理。
int _Mtx_unlock(_Mtx_t mtx) { // unlock mutex_THREAD_ASSERT(1 <= mtx->count && mtx->thread_id == static_cast<long>(GetCurrentThreadId()), "unlock of unowned mutex");if (--mtx->count == 0) { // leave critical sectionmtx->thread_id = -1;mtx->_get_cs()->unlock();}return _Thrd_success; // TRANSITION, ABI: always returns _Thrd_success
}unlock时,count进行了--处理,当count==0时,锁才会被释放了。
源码中有关TIME的分支是用于处理std::time_mutex、std::recursive_timed_mutex、std::shared_timed_mutex类型的互斥量。(这里不对它们进行说明,等有需要时再来补充)
9 条件变量(std::condition_variable)
在C++中,条件变量是一个同步原语,用于通知多线程环境中的其他线程共享资源可以自由访问了。
当一个线程必须等待另外一个线程执行才能继续工作的情况下,特别需要条件变量。例如:生产者-消费者关系、发送者-接受者关系等。
在这些情况下,条件变量是线程等待,直到收到其他线程的通知。它与互斥锁(std::unique_lock<std::mutex>)一起使用,以在一个线程正在处理共享资源时阻止其他线程对共享资源的访问。
std::condition_variable包含以下方法:
- wait():该函数告诉当前线程等待,直到知道收到条件变量通知。
- wait_for():该函数告诉当前线程等待一段特定的时间。如果条件变量在持续时间之前被通知,线程将被唤起。该时间被指定为相对时间。
- wait_until:该函数与wait_for()类似,但这里的持续时间定为绝对时间。
- notify_one():该函数通知等待线程之一共享资源可以自由访问了。选择的线程是随机的。
- notify_all():该函数通知所有线程。
// C++ Program to illustrate the use of Condition Variables
#include <condition_variable>
#include <iostream>
#include <mutex>
#include <thread> using namespace std; // mutex to block threads
mutex mtx;
condition_variable cv; // function to avoid spurios wakeup bool data_ready = false; // producer function working as sender void producer()
{ // Simulate data production this_thread::sleep_for(chrono::seconds(2)); // lock release lock_guard<mutex> lock(mtx); // variable to avoid spurious wakeup data_ready = true; // logging notification to console cout << "Data Produced!" << endl; // notify consumer when done cv.notify_one();
} // consumer that will consume what producer has produced
// working as reciever void consumer()
{ // locking unique_lock<mutex> lock(mtx); // waiting cv.wait(lock, [] { return data_ready; }); cout << "Data consumed!" << endl;
} // drive code int main()
{ thread consumer_thread(consumer); thread producer_thread(producer); consumer_thread.join(); producer_thread.join(); return 0;
}在此程序中,消费者线程使用条件变量cv等待,直到data_ready设置为true,而生产者线程休眠两秒以模拟数据生成。
条件变量容易出现以下错误:
- 虚假唤醒:是指消费者线程在收到生产者线程通知之前已经完成了工作,在上面的例子中,正是使用了变量data_ready来应对这个错误。
- 丢失唤醒:是指发送方发送通知时还没有接收方等待通知。
10 锁(std::lock_guard、std::unique_lock、std::scoped_lock)
std::lock_guard类是一个互斥锁包装器,它提供了一种方便的RAII-style机制,用于在作用域块的持续时间内拥有互斥锁。
当创建lock_guard对象时,它会尝试获取所给定互斥锁的所有权。当离开lock_guard对象的作用域范围时,lock_guard将被析构并释放互斥锁。
lock_guard类是不可拷贝的。
#include <iostream>
#include <mutex>
#include <string_view>
#include <syncstream>
#include <thread>volatile int g_i = 0;
std::mutex g_i_mutex; // protects g_ivoid safe_increment(int iterations)
{const std::lock_guard<std::mutex> lock(g_i_mutex);while (iterations-- > 0)g_i = g_i + 1;std::cout << "thread #" << std::this_thread::get_id() << ", g_i: " << g_i << '\n';// g_i_mutex is automatically released when lock goes out of scope
}void unsafe_increment(int iterations)
{while (iterations-- > 0)g_i = g_i + 1;std::osyncstream(std::cout) << "thread #" << std::this_thread::get_id()<< ", g_i: " << g_i << '\n';
}int main()
{auto test = [](std::string_view fun_name, auto fun){g_i = 0;std::cout << fun_name << ":\nbefore, g_i: " << g_i << '\n';{std::jthread t1(fun, 1'000'000);std::jthread t2(fun, 1'000'000);}std::cout << "after, g_i: " << g_i << "\n\n";};test("safe_increment", safe_increment);test("unsafe_increment", unsafe_increment);
}std::unique_lock是通用互斥锁所有权包装器,是一种多功能锁定机制,具有比std::lock_guard更多的功能:允许手动锁定和解锁,延迟锁定,时间约束的锁定尝试,递归锁定,锁定所有权转移以及与条件变量一起使用。类std::unique_lock是移动的(移动构造),而非拷贝的(拷贝构造)。
以上这些功能可以从源码(C:\Program Files\Microsoft Visual Studio\2022\Professional\VC\Tools\MSVC\14.36.32532\include\mutex)看到:
_EXPORT_STD template <class _Mutex>
class unique_lock { // whizzy class with destructor that unlocks mutex
public:using mutex_type = _Mutex;unique_lock() noexcept = default;_NODISCARD_CTOR_LOCK explicit unique_lock(_Mutex& _Mtx): _Pmtx(_STD addressof(_Mtx)), _Owns(false) { // construct and lock_Pmtx->lock();_Owns = true;}_NODISCARD_CTOR_LOCK unique_lock(_Mutex& _Mtx, adopt_lock_t) noexcept // strengthened: _Pmtx(_STD addressof(_Mtx)), _Owns(true) {} // construct and assume already lockedunique_lock(_Mutex& _Mtx, defer_lock_t) noexcept: _Pmtx(_STD addressof(_Mtx)), _Owns(false) {} // construct but don't lock_NODISCARD_CTOR_LOCK unique_lock(_Mutex& _Mtx, try_to_lock_t): _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock()) {} // construct and try to locktemplate <class _Rep, class _Period>_NODISCARD_CTOR_LOCK unique_lock(_Mutex& _Mtx, const chrono::duration<_Rep, _Period>& _Rel_time): _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock_for(_Rel_time)) {} // construct and lock with timeouttemplate <class _Clock, class _Duration>_NODISCARD_CTOR_LOCK unique_lock(_Mutex& _Mtx, const chrono::time_point<_Clock, _Duration>& _Abs_time): _Pmtx(_STD addressof(_Mtx)), _Owns(_Pmtx->try_lock_until(_Abs_time)) {// construct and lock with timeout
#if _HAS_CXX20static_assert(chrono::is_clock_v<_Clock>, "Clock type required");
#endif // _HAS_CXX20}_NODISCARD_CTOR_LOCK unique_lock(_Mutex& _Mtx, const xtime* _Abs_time): _Pmtx(_STD addressof(_Mtx)), _Owns(false) { // try to lock until _Abs_time_Owns = _Pmtx->try_lock_until(_Abs_time);}_NODISCARD_CTOR_LOCK unique_lock(unique_lock&& _Other) noexcept : _Pmtx(_Other._Pmtx), _Owns(_Other._Owns) {_Other._Pmtx = nullptr;_Other._Owns = false;}unique_lock& operator=(unique_lock&& _Other) noexcept /* strengthened */ {if (this != _STD addressof(_Other)) {if (_Owns) {_Pmtx->unlock();}_Pmtx = _Other._Pmtx;_Owns = _Other._Owns;_Other._Pmtx = nullptr;_Other._Owns = false;}return *this;}
....下面是一个延迟锁定的例子:
#include <iostream>
#include <mutex>
#include <thread>struct Box
{explicit Box(int num) : num_things{num} {}int num_things;std::mutex m;
};void transfer(Box& from, Box& to, int num)
{// don't actually take the locks yetstd::unique_lock lock1{from.m, std::defer_lock};std::unique_lock lock2{to.m, std::defer_lock};// lock both unique_locks without deadlockstd::lock(lock1, lock2);from.num_things -= num;to.num_things += num;// “from.m” and “to.m” mutexes unlocked in unique_lock dtors
}int main()
{Box acc1{100};Box acc2{50};std::thread t1{transfer, std::ref(acc1), std::ref(acc2), 10};std::thread t2{transfer, std::ref(acc2), std::ref(acc1), 5};t1.join();t2.join();std::cout << "acc1: " << acc1.num_things << "\n""acc2: " << acc2.num_things << '\n';
}std::scoped_lock类也是一个互斥锁包装器,它也提供了一种方便的RAII-style机制,用于在作用域块的持续时间内拥有零个或多个互斥锁。
当创建scoped_lock对象时,它会尝试获取给定互斥锁的所有权。当控制离开创建scoped_lock对象的作用域时,scoped_lock将被析构并释放互斥锁。
scoped_lock类是不可复制的。
#include <chrono>
#include <functional>
#include <iostream>
#include <mutex>
#include <string>
#include <thread>
#include <vector>
using namespace std::chrono_literals;struct Employee
{std::vector<std::string> lunch_partners;std::string id;std::mutex m;Employee(std::string id) : id(id) {}std::string partners() const{std::string ret = "Employee " + id + " has lunch partners: ";for (int count{}; const auto& partner : lunch_partners)ret += (count++ ? ", " : "") + partner;return ret;}
};void send_mail(Employee&, Employee&)
{// Simulate a time-consuming messaging operationstd::this_thread::sleep_for(1s);
}void assign_lunch_partner(Employee& e1, Employee& e2)
{static std::mutex io_mutex;{std::lock_guard<std::mutex> lk(io_mutex);std::cout << e1.id << " and " << e2.id << " are waiting for locks" << std::endl;}{// Use std::scoped_lock to acquire two locks without worrying about// other calls to assign_lunch_partner deadlocking us// and it also provides a convenient RAII-style mechanismstd::scoped_lock lock(e1.m, e2.m);// Equivalent code 1 (using std::lock and std::lock_guard)// std::lock(e1.m, e2.m);// std::lock_guard<std::mutex> lk1(e1.m, std::adopt_lock);// std::lock_guard<std::mutex> lk2(e2.m, std::adopt_lock);// Equivalent code 2 (if unique_locks are needed, e.g. for condition variables)// std::unique_lock<std::mutex> lk1(e1.m, std::defer_lock);// std::unique_lock<std::mutex> lk2(e2.m, std::defer_lock);// std::lock(lk1, lk2);{std::lock_guard<std::mutex> lk(io_mutex);std::cout << e1.id << " and " << e2.id << " got locks" << std::endl;}e1.lunch_partners.push_back(e2.id);e2.lunch_partners.push_back(e1.id);}send_mail(e1, e2);send_mail(e2, e1);
}int main()
{Employee alice("Alice"), bob("Bob"), christina("Christina"), dave("Dave");// Assign in parallel threads because mailing users about lunch assignments// takes a long timestd::vector<std::thread> threads;threads.emplace_back(assign_lunch_partner, std::ref(alice), std::ref(bob));threads.emplace_back(assign_lunch_partner, std::ref(christina), std::ref(bob));threads.emplace_back(assign_lunch_partner, std::ref(christina), std::ref(alice));threads.emplace_back(assign_lunch_partner, std::ref(dave), std::ref(bob));for (auto& thread : threads)thread.join();std::cout << alice.partners() << '\n' << bob.partners() << '\n'<< christina.partners() << '\n' << dave.partners() << '\n';
}







![[BT]BUUCTF刷题第13天(4.1)](https://img-blog.csdnimg.cn/direct/ec814b81531c41e893cba457b535895c.png)