本文记录:使用Paddle框架训练TSM(Temporal Shift Module)
前提条件:已经安装Paddle和PadleVideo,具体可参考前一篇文章。
1-数据准备:
以UCF101为例:内含13320 个短视频,视频类别:101 种
1. 主要包括5类动作 :人和物体交互,只有肢体动作,人与人交互,玩音乐器材,各类运动
2. 每类视频被分为25组,每组包含4-7个视频,同组视频具有一些相似的特征,比如背景、人物等
3. 视频来自YouTube,25FPS码率,320x240分辨率,avi格式,DivX编码方式,平均时长7.21秒
4. 视频按照 v_X_gY_cZ.avi的格式命名,其中X表示类别、Y表示组、Z表示视频编号,例如:v_ApplyEyeMakeup_g03 c04.avi表示ApplyEyeMakeup类别下,第03组的第04个视频

标签下载、数据下载:
# 切换到ucf101目录
cd PaddleVideo/data/ucf101# 下载annotations文件
sh download_annotations.sh# 下载UCF101的视频文件,视频会自动解压移动到videos文件夹
sh download_videos.sh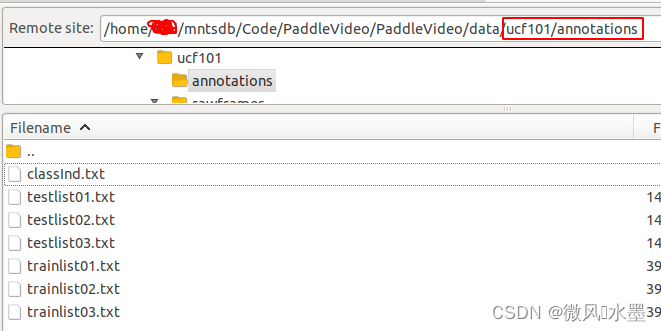
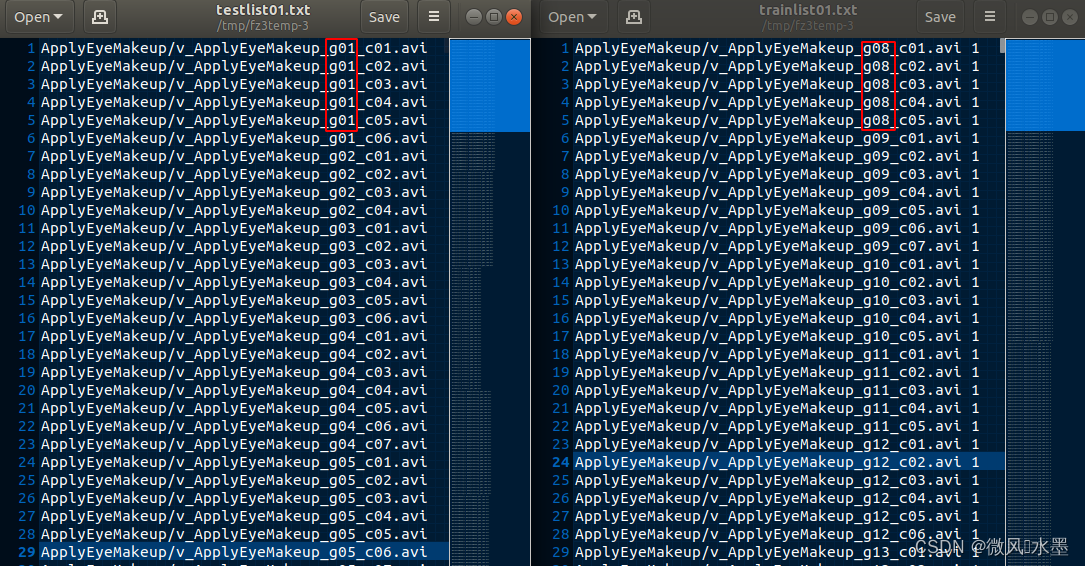
视频抽帧:自动存储到rawframes文件夹
# 提取视频文件的frames
python extract_rawframes.py ./videos/ ./rawframes/ --level 2 --ext avi生成list文件
# 生成视频文件的路径list
python build_ucf101_file_list.py videos/ --level 2 --format videos --out_list_path ./# 生成frames文件的路径list
python build_ucf101_file_list.py rawframes/ --level 2 --format rawframes --out_list_path ./参数说明:
videos/ 或者 rawframes/ : 表示视频或者frames文件的存储路径--level 2 : 表示文件的存储结构--format: 表示是针对视频还是frames生成路径list--out_list_path : 表示生成的路径list文件存储位置合并list文件
cat ucf101_train_split_*_rawframes.txt > ucf101_train.txt
cat ucf101_val_split_*_rawframes.txt > ucf101_val.txt最终文件目录结构
├── data
| ├── dataset
| │ ├── ucf101
| │ │ ├── ucf101_{train,val}.txt
| │ │ ├── ucf101_{train,val}_split_{1,2,3}_rawframes.txt
| │ │ ├── ucf101_{train,val}_split_{1,2,3}_videos.txt
| │ │ ├── annotations
| │ │ ├── videos
| │ │ │ ├── ApplyEyeMakeup
| │ │ │ │ ├── v_ApplyEyeMakeup_g01_c01.avi
| │ │ │ │ └── ...
| │ │ │ ├── YoYo
| │ │ │ │ ├── v_YoYo_g25_c05.avi
| │ │ │ │ └── ...
| │ │ │ └── ...
| │ │ ├── rawframes
| │ │ │ ├── ApplyEyeMakeup
| │ │ │ │ ├── v_ApplyEyeMakeup_g01_c01
| │ │ │ │ │ ├── img_00001.jpg
| │ │ │ │ │ ├── img_00002.jpg
| │ │ │ │ │ ├── ...
| │ │ │ │ │ ├── flow_x_00001.jpg
| │ │ │ │ │ ├── flow_x_00002.jpg
| │ │ │ │ │ ├── ...
| │ │ │ │ │ ├── flow_y_00001.jpg
| │ │ │ │ │ ├── flow_y_00002.jpg
| │ │ │ ├── ...
| │ │ │ ├── YoYo
| │ │ │ │ ├── v_YoYo_g01_c01
| │ │ │ │ ├── ...
| │ │ │ │ ├── v_YoYo_g25_c05
2-模型训练
PaddleVideo/docs/zh-CN/benchmark.md at develop · PaddlePaddle/PaddleVideo · GitHub
根据benchmark性能指标选择所需模型:初步看8帧配置下,PP-TSMv2性价比不错

预训练模型下载
根据上面的选型,到 paddlevideo/modeling/backbones 目录下打开自己选择的模型
文件中 MODEL_URLS 就是预训练模型的下载路径,手动下载
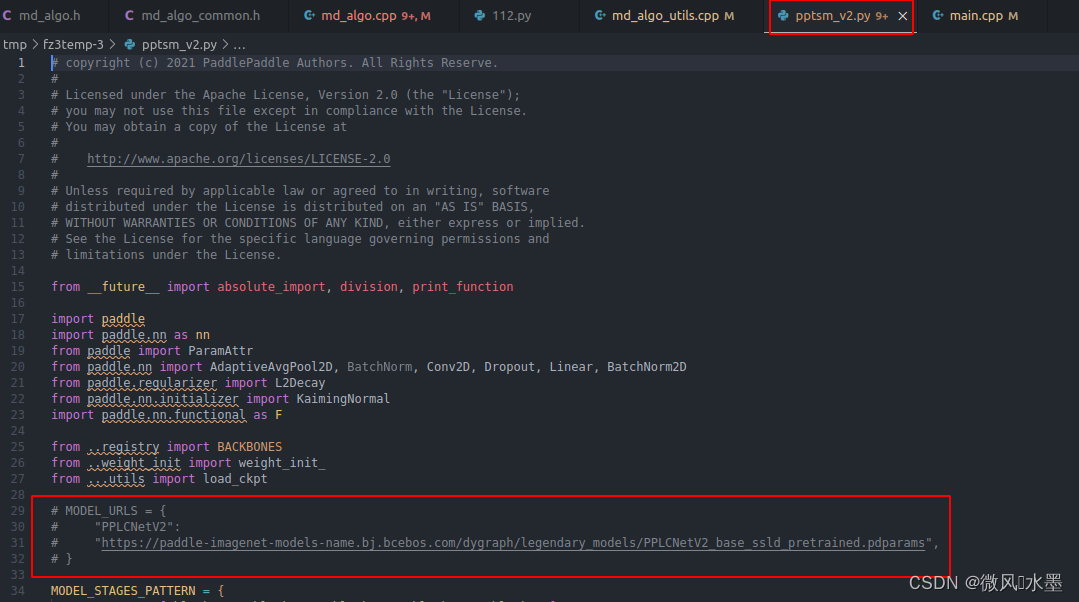
放到 PaddleVideo/data 目录

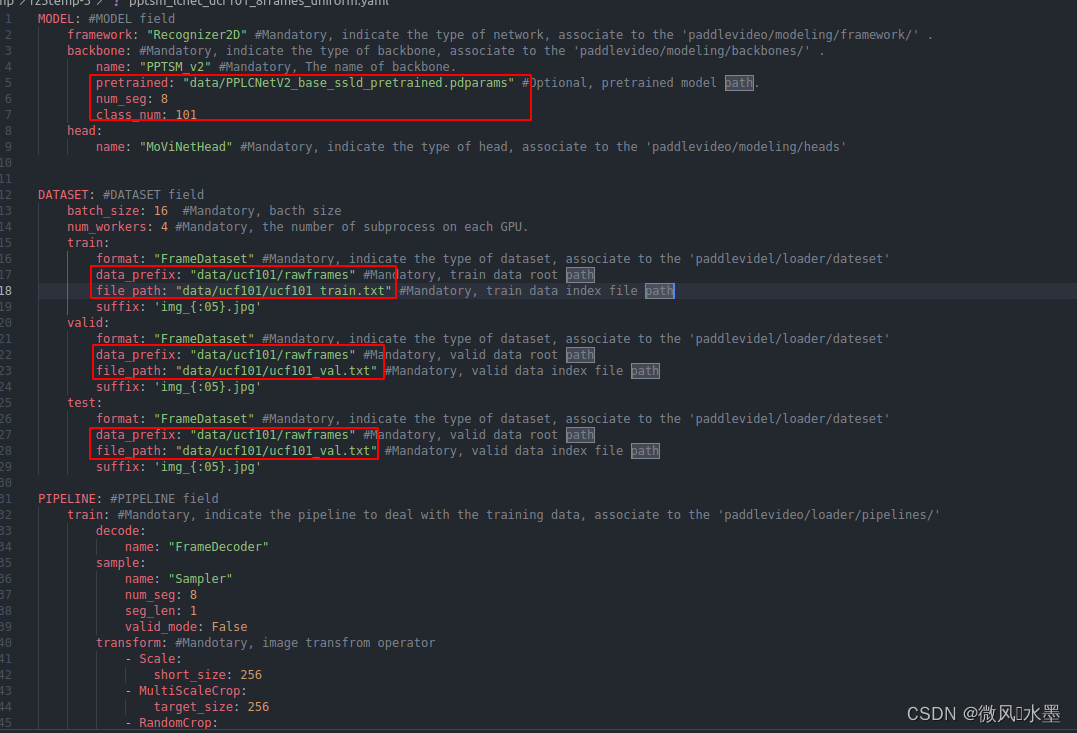
修改训练配置文件
进入PaddleVideo/configs/recognition/pptsm/v2 目录,
因为我们使用的是ucf101数据集训练,所以复制 pptsm_lcnet_k400_8frames_uniform.yaml 一份,并重命名为:pptsm_lcnet_ucf101_8frames_uniform.yaml 来进行修改

修改pretrained、num_seg、class_num、data_prefix、file_path
开启训练
单卡训练
# 单卡训练
export CUDA_VISIBLE_DEVICES=0 #指定使用的GPU显卡id
python main.py --validate -c configs/recognition/pptsm/v2/pptsm_lcnet_ucf101_8frames_uniform.yaml
多卡训练
# 多卡训练
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
python -B -m paddle.distributed.launch --gpus="0,1,2,3,4,5,6,7" --log_dir=log_pptsm main.py --validate -c configs/recognition/pptsm/v2/pptsm_lcnet_ucf101_8frames_uniform.yaml参数说明:
-c 必选参数,指定运行的配置文件路径,具体配置参数含义参考配置文档
--validate 可选参数,指定训练时是否评估
-o: 可选参数,指定重写参数,例如: -o DATASET.batch_size=16 用于重写train时batch size大小
--gpus参数指定使用的GPU显卡id
--log_dir参数指定日志保存目录 多卡训练详细说明可以参考单机多卡训练输出日志
运行日志,并默认保存在./log目录下

3-模型测试(可选-因为训练的时候已经测试了,没必要再去测试一次)
对于视频分类任务,模型测试时有两种不同的方式,中心采样(Uniform)和密集采样(Dense)。
中心采样:速度快,适合产业应用,但精度稍低。
密集采样:精度高,但由于测试要对多个clip进行预测,比较耗时。
轻量化模型PP-TSMv2统一使用中心采样方式进行评估。PP-TSM则提供两种不同的评估方式。
3.1-中心采样测试
中心采样测试,1个视频共采样1个clips。
时序上:等分成num_seg段,每段中间位置采样1帧
空间上:中心位置采样。
也可以使用如下命令对训练好的模型进行测试:
python3 main.py --test -c configs/recognition/pptsm/v2/pptsm_lcnet_ucf101_8frames_uniform.yaml -w output/ppTSMv2/ppTSMv2_best.pdparams3.2-中心采样测试
密集采样测试,1个视频共采样10*3=30个clips。
时序上:先等分10个片段,每段从起始位置开始,以64//num_seg为间隔连续采样num_seg帧;
空间上:左中,中心,右中3个位置采样。
python3 main.py --test -c configs/recognition/pptsm/v2/pptsm_lcnet_ucf101_8frames_uniform.yaml -w output/ppTSMv2/ppTSMv2_best.pdparams4-导出推理模型
# 切换到output目录
cd output# 创建inference目录存储推理模型
mkdir ppTSMv2_inference
python tools/export_model.py -c configs/recognition/pptsm/v2/pptsm_lcnet_ucf101_8frames_uniform.yaml \-p output/ppTSMv2/ppTSMv2_best.pdparams \-o output/ppTSMv2_inference├── output/ppTSMv2_inference
│ ├── ppTSMv2.pdiparams # 模型权重文件
│ ├── ppTSMv2.pdiparams.info # 模型信息文件
│ └── ppTSMv2.pdmodel # 模型结构文件5-基于python进行模型推理
python tools/predict.py --input_file data/example.avi \--config configs/recognition/pptsm/v2/pptsm_lcnet_ucf101_8frames_uniform.yaml \--model_file output/ppTSMv2_inference/ppTSMv2.pdmodel \--params_file output/ppTSMv2_inference/ppTSMv2.pdiparams \--use_gpu=True \--use_tensorrt=False
6-基于onnx进行模型推理
详见下一篇博文。
参考链接
1:PP-TSM视频分类模型PaddleVideo/docs/zh-CN/model_zoo/recognition/pp-tsm.md at develop · PaddlePaddle/PaddleVideo · GitHubAwesome video understanding toolkits based on PaddlePaddle. It supports video data annotation tools, lightweight RGB and skeleton based action recognition model, practical applications for video tagging and sport action detection. - PaddleVideo/docs/zh-CN/model_zoo/recognition/pp-tsm.md at develop · PaddlePaddle/PaddleVideo![]() https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/model_zoo/recognition/pp-tsm.md
https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/model_zoo/recognition/pp-tsm.md
2: PP-TSMv2PaddleVideo/docs/zh-CN/model_zoo/recognition/pp-tsm_v2.md at develop · PaddlePaddle/PaddleVideo · GitHubAwesome video understanding toolkits based on PaddlePaddle. It supports video data annotation tools, lightweight RGB and skeleton based action recognition model, practical applications for video tagging and sport action detection. - PaddleVideo/docs/zh-CN/model_zoo/recognition/pp-tsm_v2.md at develop · PaddlePaddle/PaddleVideo![]() https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/model_zoo/recognition/pp-tsm_v2.md
https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/model_zoo/recognition/pp-tsm_v2.md
3: ucf101数据处理
PaddleVideo/docs/zh-CN/dataset/ucf101.md at develop · PaddlePaddle/PaddleVideo · GitHubAwesome video understanding toolkits based on PaddlePaddle. It supports video data annotation tools, lightweight RGB and skeleton based action recognition model, practical applications for video tagging and sport action detection. - PaddleVideo/docs/zh-CN/dataset/ucf101.md at develop · PaddlePaddle/PaddleVideo![]() https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/dataset/ucf101.md
https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/dataset/ucf101.md