点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>【目标检测和Transformer】交流群
转载自:新智元
【导读】最差的人类语料,也要胜过AI生成的文本。
随着GPT-4、Stable Diffusion和Midjourney的爆火,越来越多的人开始在工作和生活中引入生成式AI技术。
甚至,有人已经开始尝试用AI生成的数据来训练AI了。难道,这就是传说中的「数据永动机」?
然而,来自牛津、剑桥、帝国理工等机构研究人员发现,如果在训练时大量使用AI内容,会引发模型崩溃(model collapse),造成不可逆的缺陷。

也就是,随着时间推移,模型就会忘记真实基础数据部分。即使在几乎理想的长期学习状态下,这个情况也无法避免。
因此研究人员呼吁,如果想要继续保持大规模数据带来的模型优越性,就必须认真对待人类自己写出来的文本。

论文地址:https://arxiv.org/abs/2305.17493v2
但现在的问题在于——你以为的「人类数据」,可能并不是「人类」写的。
洛桑联邦理工学院(EPFL)的最新研究称,预估33%-46%的人类数据都是由AI生成的。

训练数据,都是「垃圾」
毫无疑问,现在的大语言模型已经进化出了相当强大的能力,比如GPT-4可以在某些场景下生成与人类别无二致的文本。
但这背后的一个重要原因是,它们的训练数据大部分来源于过去几十年人类在互联网上的交流。
如果未来的语言模型仍然依赖于从网络上爬取数据的话,就不可避免地要在训练集中引入自己生成的文本。
对此,研究人员预测,等GPT发展到第n代的时候,模型将会出现严重的崩溃问题。
那么,在这种不可避免会抓取到LLM生成内容的情况下,为模型的训练准备由人类生产的真实数据,就变得尤为重要了。
大名鼎鼎的亚马逊数据众包平台Mechanical Turk(MTurk)从2005年启动时就已经成为许多人的副业选择。
科研人员可以发布各种琐碎的人类智能任务,比如给图像标注、调查等,应有尽有。
而这些任务通常是计算机和算法无法处理的,甚至,MTurk成为一些预算不够的科研人员和公司的「最佳选择」。
就连贝佐斯还将MTurk的众包工人戏称为「人工人工智能」。

除了MTurk,包括Prolific在内的众包平台已经成为研究人员和行业实践者的核心,能够提供创建、标注和总结各种数据的方法,以便进行调查和实验。
然而,来自EPFL的研究发现,在这个人类数据的关键来源上,有近乎一半的数据都是标注员用AI创建的。

论文地址:https://arxiv.org/abs/2306.07899v1
模型崩溃
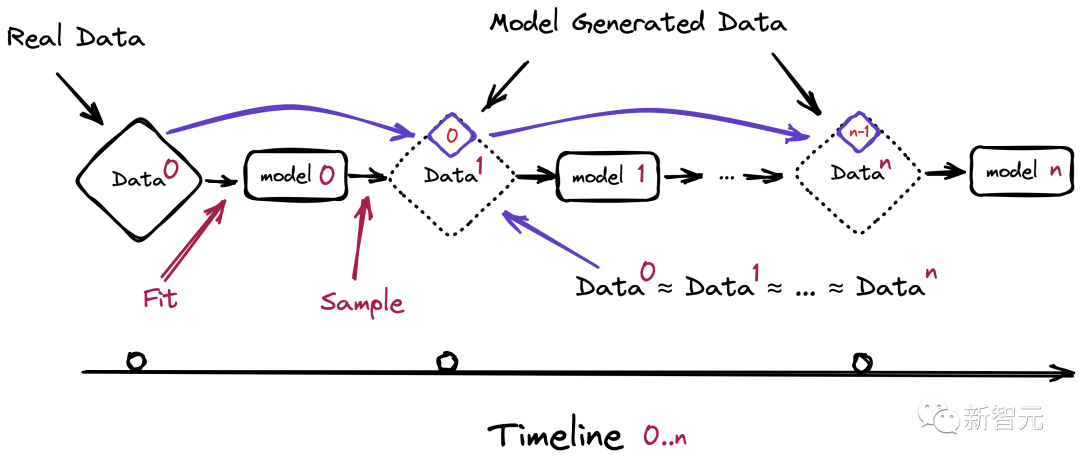
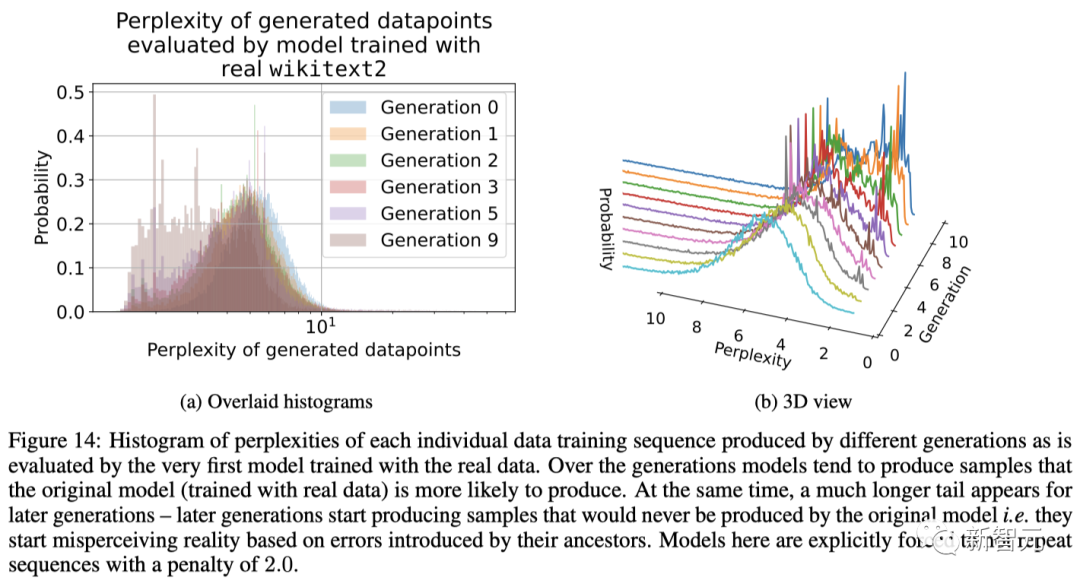
而最开始提到的「模型崩溃」,就是在给模型投喂了太多来自AI的数据之后,带来的能够影响多代的退化。
也就是,新一代模型的训练数据会被上一代模型的生成数据所污染,从而对现实世界的感知产生错误的理解。
更进一步,这种崩溃还会引发比如基于性别、种族或其他敏感属性的歧视问题,尤其是如果生成AI随着时间的推移学会在其响应中只生成某个种族,而「忘记」其他种族的存在。
而且,除了大语言模型,模型崩溃还会出现在变分自编码器(VAE)、高斯混合模型上。
需要注意的是,模型崩溃的过程与灾难性遗忘(catastrophic forgetting)不同,模型不会忘记以前学过的数据,而是开始把模型的错误想法曲解为现实,并且还会强化自己对错误想法的信念。

举个例子,比如模型在一个包含100张猫图片的数据集上进行训练,其中有10张蓝毛猫,90张黄毛猫。
模型学到的结论是,黄毛猫更普遍,同时会倾向于把蓝毛猫想象的比实际更偏黄,所以在被要求生成新数据时可能会返回一些类似绿毛猫的结果。
而随着时间的推移,蓝毛的原始特征在多个训练epoch中逐渐被侵蚀,直接从蓝色变成了绿色,最终再演变为黄色,这种渐进的扭曲和丢失少数特征的现象就是模型崩溃。

具体来说,模型崩溃可以分为两种情况:
1. 早期模型崩溃(early model collapse),模型开始丢失有关分布尾部的信息;
2. 后期模型崩溃(late model collapse),模型与原始分布的不同模式纠缠在一起,并收敛到一个与原始分布几乎没有相似之处的分布,往往方差也会非常小。
与此同时,研究人员也总结出了造成模型崩溃的两个主要原因:
其中,在更多的时候,我们会得到一种级联效应,即单个不准确的组合会导致整体误差的增加。
1. 统计近似误差(Statistical approximation error)
在重采样的每一步中,信息中非零概率都可能会丢失,导致出现统计近似误差,当样本数量趋于无限会逐渐消失,该误差是导致模型崩溃的主要原因。
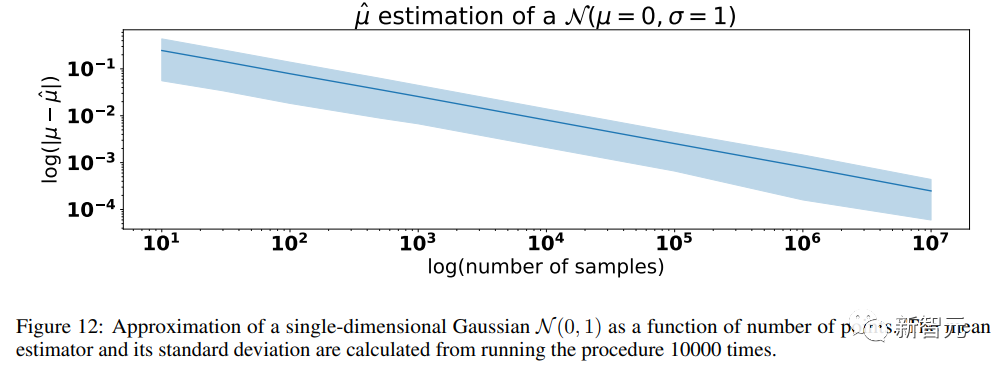
2. 函数近似误差(Functional approximation error)
该误差主要源于模型中的函数近似器表达能力不足,或者有时在原始分布支持之外的表达能力太强。
众所周知,神经网络在极限情况下是通用的函数近似器,但实际上这种假设并不总是成立的,特别是神经网络可以在原始分布的支持范围之外引入非零似然。
举个简单例子,如果我们试图用一个高斯分布来拟合两个高斯的混合分布,即使模型具有关于数据分布的完美信息,模型误差也是不可避免的。
需要注意的是,在没有统计误差的情况下,函数近似误差只会发生在第一代,一旦新的分布能被函数近似器描述出来,就会在各代模型中保持完全相同的分布。
可以说,模型强大的近似能力是一把双刃剑:其表达能力可能会抵消统计噪声,从而更好地拟合真实分布,但同样也会使噪声复杂化。
对此,论文共同一作Ilia Shumailov表示:「生成数据中的错误会累积,最终迫使从生成数据中学习的模型进一步错误地理解现实。而且模型崩溃发生得非常快,模型会迅速忘记最初学习的大部分原始数据。」

解决方法
好在,研究人员发现,我们还是有办法来避免模型崩溃的。
第一种方法是保留原始的、完全或名义上由人类生成的数据集的高质量副本,并避免与AI生成的数据混合,然后定期使用这些数据对模型进行重新训练,或者完全从头训练一遍模型。
第二种避免回复质量下降并减少AI模型中的错误或重复的方法是将全新的、干净的、由人类生成的数据集重新引入训练中。
为了防止模型崩溃,开发者需要确保原始数据中的少数派在后续数据集中得到公正的表征。
数据需要仔细备份,并覆盖所有可能的边界情况;在评估模型的性能时,需要考虑到模型将要处理的数据,甚至是最不可信的数据。
随后,当重新训练模型时,还需要确保同时包括旧数据和新数据,虽然会增加训练的成本,但至少在某种程度上有助于缓解模型崩溃。
不过,这些方法必须要内容制作者或AI公司采取某种大规模的标记机制,来区分AI生成的内容和人类生成的内容。
目前,有一些开箱即用的解决方案,比如GPTZero,OpenAI Detector,或Writer在简单的文本上工作得很好。

然而,在一些特殊的文本中,这些方法并不能有效执行。比如,在EPFL研究中有ChatGPT合成的10个总结,而GPTZero只检测到6个是合成的。
对此,研究人员通过微调自己的模型来检测AI的使用,发现ChatGPT在编写本文时是最常用的LLM。
对于构建的检测AI数据的方法,研究人员利用原始研究中的答案和用ChatGPT合成的数据,训练了一个定制的「合成-真实分类器」。
然后用这个分类器来估计重新进行的任务中合成答案的普遍性。
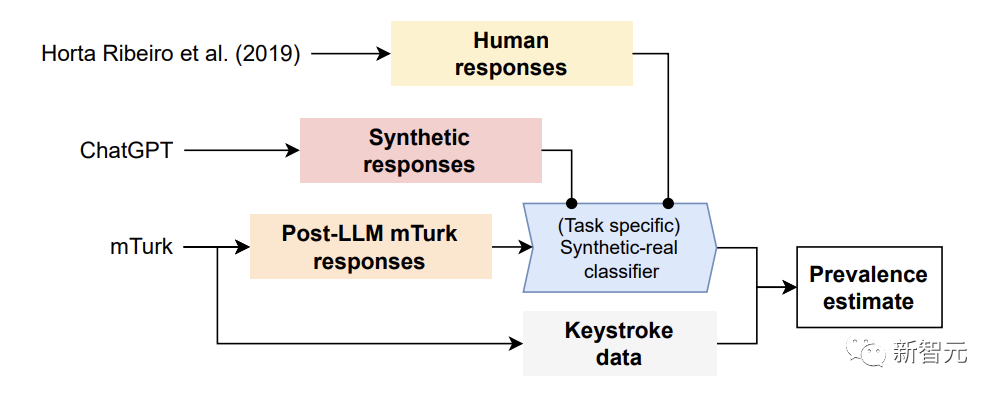
具体来讲,研究人员首先使用真正由人类撰写的MTurk回应,和合成LLM生成的回应,来训练特定任务的「合成-真实分类器」。
其次,将这个分类器用于MTurk的真实回应(其中众包人可能使用,也可能没有依赖LLM),以估计LLM使用的普遍性。
最后,研究者确认了结果的有效性,在事后比较分析击键数据与MTurk的回应。
实验结果显示,这个模型在正确识别人工智能文本方面高达99%的准确率。
此外,研究人员用击键数据验证了结果,发现:
- 完全在MTurk文本框中写的总结(不太可能是合成的)都被归类为真实的;
- 在粘贴的总结中,提取式总结和LLM的使用有明显区别。
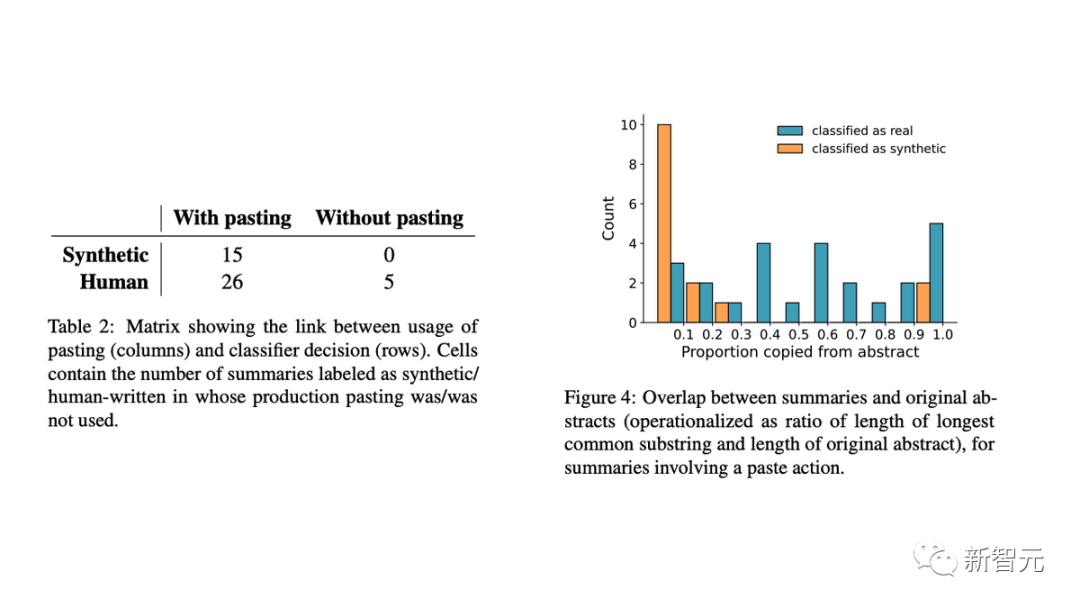
具体来讲,人工智能生成的文本通常与原始总结几乎没有相似之处。这表明AI模型正在生成新文本,而不是复制和粘贴原始内容的一部分。
「人类数据」很重要
现在,人们普遍担心LLM将塑造人类的「信息生态系统」,也就是说,在线可获得的大部分信息都是由LLM生成的。
使用综合生成数据训练的LLM的性能明显降低,就像Ilia Shumailov所称会让模型患上「痴呆症」。

而这个问题将会变得更加严重,因为随着LLM的普及,众包工作者们已经广泛使用ChatGPT等各种LLM。
但对于人类内容创作者来说,这是一个好消息,提高工作效率的同时,还赚到了钱。
但是,若想挽救LLM不陷于崩溃的边缘,还是需要真实的「人类数据」。
1. 人类数据在科学中仍然是至关重要的
2. 在合成数据上训练模型可能会带来偏见和意识形态永久化
3. 随着模型变得流行和更好/多模态,采用率只会增加

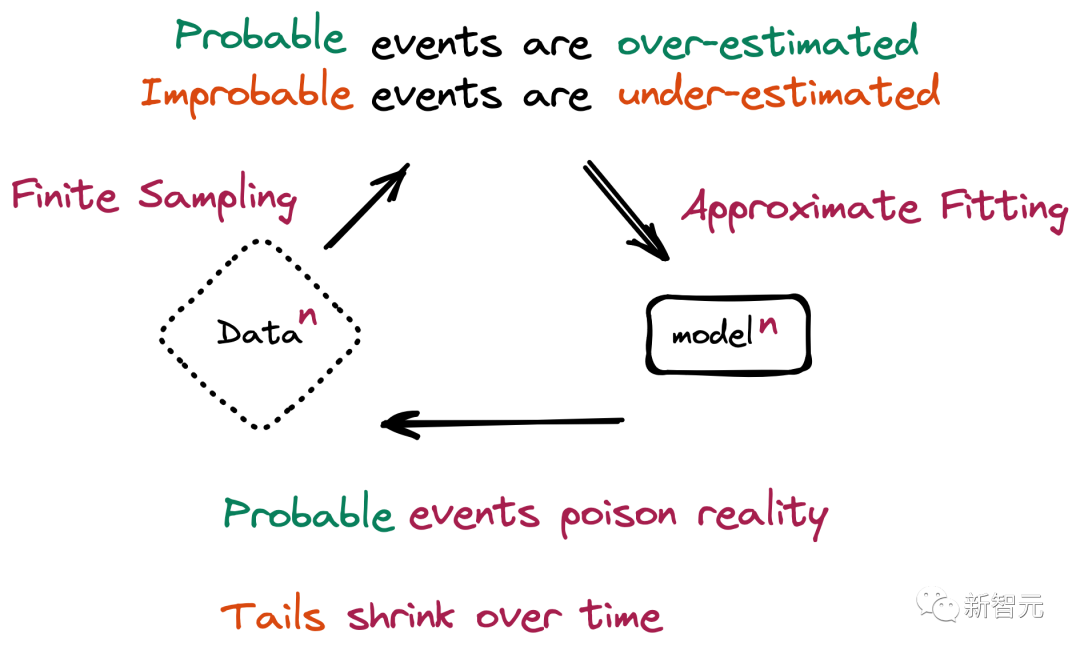
总的来说,由人类生成的原始数据可以更好地表示世界,虽然也可能包含某些劣质、概率较低的数据;而生成式模型往往只会过度拟合流行数据,并对概率更低的数据产生误解。
那么,在充斥着生成式AI工具和相关内容的未来,人类制作的内容或许会比今天更有价值,尤其是作为AI原始训练数据的来源。
参考资料:
https://arxiv.org/abs/2306.07899v1
https://arxiv.org/abs/2305.17493v2
点击进入—>【目标检测和Transformer】交流群
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者ransformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()