1、找出10000以内能被5或6整除,但不能被两者同时整除的数(函数)
def func():for i in range(10001):if (i % 5 == 0 or i % 6 == 0) and i % 30 != 0:print(i,end = " ")func()

2、写一个方法,计算列表所有偶数下标元素的和(注意返回值)
def sumEvenIndex(nums):total = 0for i in range(0, len(nums), 2):total += nums[i]return totalnums = [1, 2, 3, 4, 6, 10, 18, 22]
result = sumEvenIndex(nums)
print(result)
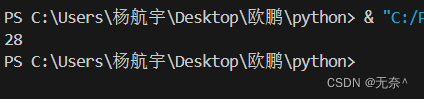
3、根据完整的路径从路径中分离文件路径、文件名及扩展名
import osdef separate_path(full_path):directory = os.path.dirname(full_path)filename_with_extension = os.path.basename(full_path)filename, extension = os.path.splitext(filename_with_extension)return directory, filename, extensionfull_path = '/Desktop/欧鹏/python/练习.py/a.txt'
directory, filename, extension = separate_path(full_path)
print(f'Directory: {directory}')
print(f'Filename: {filename}')
print(f'Extension: {extension}')

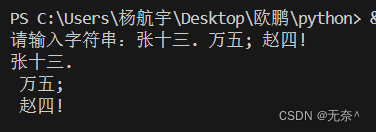
4、根据标点符号对字符串进行分行
def split_by_punctuation(text):punctuation = [".", ",", ";", ":", "!", "?"]for char in text:if char in punctuation:text = text.replace(char, char + "\n")return textinput_text = input("请输入字符串:")
result = split_by_punctuation(input_text)
print(result)
5、去掉字符串数组中每个字符串的空格
string_array = [" Hello ","China "," Python "," C++"]cleaned_array = [s.strip() for s in string_array]print(cleaned_array)

6、两个学员输入各自最喜欢的游戏名称,判断是否一致,如 果相等,则输出你们俩喜欢相同的游戏;如果不相同,则输 出你们俩喜欢不相同的游戏。
A = input("学员1请输出你喜欢的游戏:")
B = input("学员2请输出你喜欢的游戏:")if A == B:print("你们俩喜欢相同的游戏")
else:print("你们俩喜欢不相同的游戏")

7、上题中两位同学输入 lol和 LOL代表同一游戏,怎么办?
8、让用户输入一个日期格式如“2008/08/08”,将 输入的日 期格式转换为“2008年-8月-8日”。
input_date = input("请输入日期(格式为year/month/day):")year, month, day = input_date.split("/")formatted_date = f"{year}年-{int(month)}月-{int(day)}日"print("转换后的日期为:", formatted_date)

9、接收用户输入的字符串,将其中的字符进行排序(升 序),并以逆序的顺序输出,“cabed”→"abcde"→“edcba”
input_str = input("请输入一个字符串: ")sorted_str = ''.join(sorted(input_str))reversed_sorted_str = sorted_str[::-1]print(sorted_str)
print(reversed_sorted_str)

10、接收用户输入的一句英文,将其中的单词以反序输 出,“hello c java python”→“python java c hello”。
sentence = input("请输入一句英文: ")words = sentence.split()reversed_words = list(reversed(words))reversed_sentence = ' '.join(reversed_words)print(reversed_sentence)

11、从请求地址中提取出用户名和域名 http://www.163.com?userName=admin&pwd=123456
from urllib.parse import urlparse, parse_qsurl = "http://www.163.com?userName=admin&pwd=123456"
parsed_url = urlparse(url)
query_params = parse_qs(parsed_url.query)if 'userName' in query_params:username = query_params['userName'][0]
else:username = Nonedomain = parsed_url.netlocprint("用户名:", username)
print("域名:", domain)

12、有个字符串数组,存储了10个书名,书名有长有短,现 在将他们统一处理,若书名长度大于10,则截取长度8的 子串并且最后添加“...”,加一个竖线后输出作者的名字。
def process_book_names(book_names):processed_names = []author_name = "张三" for name in book_names:if len(name) > 10:processed_name = name[:8] + "..."else:processed_name = nameprocessed_names.append(processed_name + " | " + author_name)return processed_namesbook_names = ["Python Programming", "Data Science Handbook", "Machine Learning", "Deep Learning Basics", "Java Programming", "C++ Primer", "JavaScript for Beginners", "HTML & CSS", "Artificial Intelligence", "Computer Networks"]processed_books = process_book_names(book_names)for book in processed_books:print(book)

13、让用户输入一句话,找出所有"呵"的位置。
sentence = input("请输入一句话:")
positions = [pos for pos, char in enumerate(sentence) if char == "呵"]
print("所有'呵'的位置:", positions)

14、让用户输入一句话,判断这句话中有没有邪恶,如果有邪恶就替换成这种形式然后输出,如:“老牛很邪恶”,输出后变 成”老牛很**”;
sentence = input("请输入一句话:")
if "邪恶" in sentence:new_sentence = sentence.replace("邪恶", "**")print(new_sentence)
else:print("这句话中没有邪恶。")

15、判断一个字符是否是回文字符串 "1234567654321" "上海自来水来自海上"
def is_palindrome(s):return s == s[::-1]string = "1234567654321"if is_palindrome(string):print(string, "是回文字符串。")
else:print(string, "不是回文字符串。")

16、过滤某个文件夹下的所有"xx.py"python文件
17、用户管理系统的,密码加密
import hashlibdef encrypt_password(password):hashed_password = hashlib.sha256(password.encode()).hexdigest()return hashed_passwordpassword = input("请输入密码:")
encrypted_password = encrypt_password(password)
print("加密后的密码:", encrypted_password)