目录
1、bytearray函数:
1-1、Python:
1-2、VBA:
2、相关文章:
个人主页:非风V非雨-CSDN博客
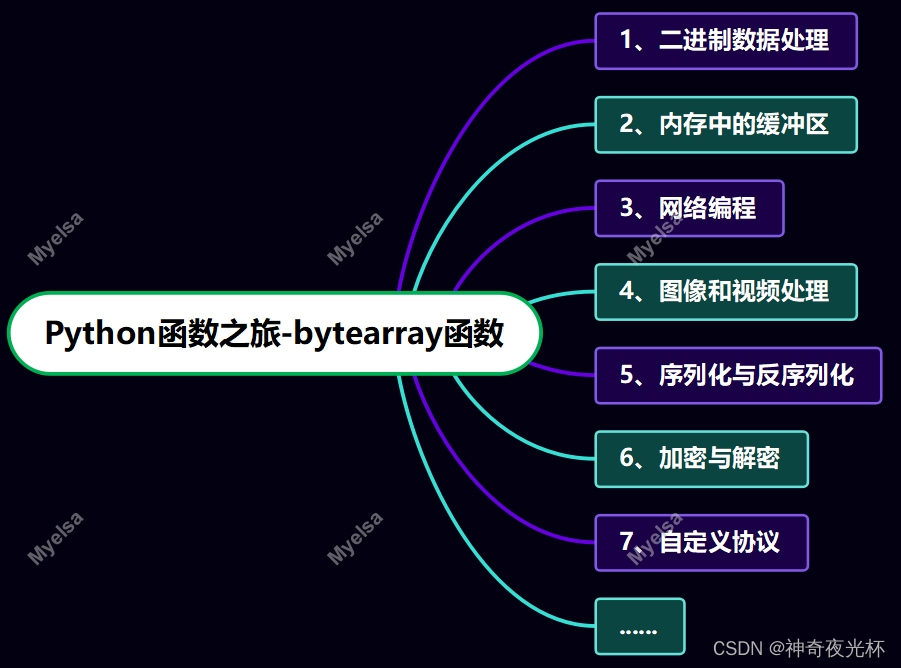
bytearray函数在Python中提供了一种可变字节序列的表示方式,这在实际编程中有多种应用场景。常见的应用场景有:
1、二进制数据处理:当需要处理二进制数据时,bytearray()是一个很好的选择。你可以使用它来存储和操作二进制数据,例如,读取或写入文件、网络通信中的数据包等。
2、内存中的缓冲区:bytearray()可以用作内存中的缓冲区,存储临时数据,并在需要时进行修改或传输。这在处理大量数据或需要频繁修改数据的场景中非常有用。
3、网络编程:在网络编程中,经常需要处理字节流。使用bytearray()可以方便地构建、修改和发送字节数据。
4、图像和视频处理:图像和视频数据通常以字节流的形式存储和传输。使用bytearray()可以方便地读取、修改和保存这些数据的特定部分,例如,修改图像的像素值或视频的编码参数。
5、序列化与反序列化:bytearray()可以用来存储序列化后的数据,如将对象转换为字节流进行存储或传输。反序列化时,可以从bytearray()中读取数据并还原为原始对象。
6、加密与解密:在加密和解密算法中,bytearray()可以用来存储和处理加密数据。你可以使用bytearray()来执行加密操作,并将加密后的数据存储在bytearray()中,或者从bytearray()中读取加密数据进行解密。
7、自定义协议:当实现自定义的通信协议时,bytearray()可以用来构建和解析协议中的字节数据。你可以使用bytearray()来定义协议的数据结构,并根据协议规范进行数据的编码和解码。
这些只是bytearray()的一些常见应用场景,实际上,在处理与字节序列相关的任何任务时,bytearray()都可以作为一个灵活且强大的工具来使用。它的可变性使得它能够在需要时轻松地进行修改和调整,而不需要创建新的字节序列对象。
1、bytearray函数:
1-1、Python:
# 1.函数:bytearray
# 2.功能:用于处理可变字节序列,即创建可修改的字节数组
# 3.语法:bytearray(source, encoding, errors)
# 4.参数:
# 4-1、source>>>
# 1、整数,包括正整数、0和负整数
# 2、字符串
# 3、可迭代对象,包括但不限于以下类型:
# 3-1、序列类型:# list(列表):有序的元素集合# tuple(元组):不可变的有序的元素集合# str(字符串):字符的有序集合# bytes(字节序列):字节的有序集合# bytearray(可变字节序列):可变的字节的有序集合# range(范围对象):表示一个不可变的整数序列# memoryview(内存视图):用于在不需要复制数据的情况下访问对象的内存
# 3-2、集合类型:# set(集合):无序且不包含重复元素的集合# frozenset(冻结集合):不可变的无序且不包含重复元素的集合
# 3-3、字典与字典视图:# dict(字典):无序的键值对集合# dict的keys()、values()、items()方法返回的视图对象
# 3-4、文件对象:# 打开的文件对象也是可迭代的,可以通过迭代逐行读取文件内容
# 3-5、自定义可迭代对象:# 任何定义了__iter__()方法的对象都可以被视为可迭代对象。这个方法应该返回一个迭代器对象
# 3-6、生成器:# 生成器函数和生成器表达式创建的生成器对象也是可迭代的
# 3-7、其他内置类型:# 某些内置的数据类型或函数返回的对象也可能是可迭代的,比如map、filter、zip等函数返回的对象
# 4-2、encoding>>>表示进行转换时采用的字符编码,默认为UTF-8编码
# 4-3、errors>>>表示错误处理方式(报错级别),常见的报错级别有:
# 1、strict:严格级别(默认级别),字符编码有报错时即抛出异常
# 2、ignore:忽略级别,字符编码有报错,忽略掉
# 3、replace:替换级别,字符编码有报错,替换成符号“?”
# 5.返回值:返回一个新的字节数组(若3个参数均未提供,则返回长度为0的字节数组)
# 6.说明:
# 6-1、如果参数source为字符串,那么参数encoding也必须提供,否则将提示TypeError错误。详情如下:# TypeError: string argument without an encoding# print(bytearray("myelsa"))
# 6-2、如果参数source为可迭代对象,那么可迭代对象的元素必须为0-255的范围内的整数,否则将抛出异常。详情如下:# ValueError: byte must be in range(0, 256)# print(bytearray([1024, 8, 6]))# TypeError: 'float' object cannot be interpreted as an integer# print(bytearray([3.14, 1.5, 6.0]))
# 6-3、bytearray()函数与bytes()函数的主要区别:前者产生的对象元素可以修改,而后者不能修改
# 7.示例:
# 应用1:二进制数据处理(增、删、改、查等操作)
# 初始化bytearray
data = bytearray([0x01, 0x02, 0x03, 0x04, 0x05])
# 打印原始数据
print("原始数据:", data)
# 增加数据
data.append(0x06)
print("增加数据后的数据:", data)
# 删除数据
del data[2]
print("删除数据后的数据:", data)
# 修改数据
data[3] = 0x07
print("修改数据后的数据:", data)
# 查找数据
index = data.find(0x04)
if index != -1:print("找到数据0x04的索引为:", index)
else:print("未找到数据0x04")
# 增加数据后的数据: bytearray(b'\x01\x02\x03\x04\x05\x06')
# 删除数据后的数据: bytearray(b'\x01\x02\x04\x05\x06')
# 修改数据后的数据: bytearray(b'\x01\x02\x04\x07\x06')
# 找到数据0x04的索引为: 2# 应用2:内存中的缓冲区(包括初始化、写入数据、读取数据、修改数据、追加数据、切片操作以及清空缓冲区)
# 创建一个bytearray作为内存缓冲区
buffer = bytearray(10) # 初始化一个大小为10的内存缓冲区
# 向内存缓冲区中写入数据
buffer[0] = 1 # 写入一个字节
buffer[1] = 2
buffer[2:5] = [3, 4, 5] # 写入多个字节
# 打印缓冲区的内容
print("缓冲区内容:", buffer)
# 读取缓冲区中的数据
first_byte = buffer[0]
print("第一个字节:", first_byte)
# 修改缓冲区中的数据
buffer[3] = 6
print("修改后的缓冲区内容:", buffer)
# 在缓冲区中追加数据
buffer.extend([7, 8, 9])
print("追加数据后的缓冲区内容:", buffer)
# 缓冲区切片操作
sub_buffer = buffer[2:7] # 获取一个子缓冲区
print("子缓冲区内容:", sub_buffer)
# 缓冲区大小
print("缓冲区大小:", len(buffer))
# 清空缓冲区
del buffer[:]
print("清空后的缓冲区内容:", buffer)
# 缓冲区内容: bytearray(b'\x01\x02\x03\x04\x05\x00\x00\x00\x00\x00')
# 第一个字节: 1
# 修改后的缓冲区内容: bytearray(b'\x01\x02\x03\x06\x05\x00\x00\x00\x00\x00')
# 追加数据后的缓冲区内容: bytearray(b'\x01\x02\x03\x06\x05\x00\x00\x00\x00\x00\x07\x08\t')
# 子缓冲区内容: bytearray(b'\x03\x06\x05\x00\x00')
# 缓冲区大小: 13
# 清空后的缓冲区内容: bytearray(b'')# 应用3:网络编程
import socket
# 创建TCP客户端
def create_tcp_client(server_address, port):client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)client_socket.connect((server_address, port))return client_socket
# 构建二进制消息
def build_message(data):# 假设我们有一个简单的协议,其中每个消息都以一个长度字节开始length = len(data).to_bytes(1, byteorder='big')message = bytearray(length) + bytearray(data, 'utf-8')return message
# 解析二进制消息
def parse_message(message):# 假设消息的第一个字节是长度length = message[0]data = message[1:length + 1].decode('utf-8')return data
# 发送消息并接收响应
def send_receive_message(client_socket, message):client_socket.sendall(message)response = client_socket.recv(4096) # 假设响应不会超过4096字节return response
# 主函数
if __name__ == "__main__":SERVER_ADDRESS = 'localhost'PORT = 12345MESSAGE = "Hello, Python!"# 创建TCP客户端client_socket = create_tcp_client(SERVER_ADDRESS, PORT)# 构建二进制消息binary_message = build_message(MESSAGE)# 发送消息并接收响应response = send_receive_message(client_socket, binary_message)# 解析响应response_data = parse_message(response)# 打印响应print("Received response:", response_data)# 关闭连接client_socket.close()# 应用4:图像和视频处理(注意:运行此程序,需要确保已经安装了pillow库)
from PIL import Image
import io
# 读取图像文件到bytearray
def read_image_to_bytearray(image_path):with open(image_path, 'rb') as file:byte_data = bytearray(file.read())return byte_data
# 将bytearray写回到图像文件
def write_bytearray_to_image(byte_data, output_path):with open(output_path, 'wb') as file:file.write(byte_data)
# 读取图像并显示
def display_image(image_path):image = Image.open(image_path)image.show()
# 主函数
if __name__ == "__main__":# 使用原始字符串或双反斜杠来处理Windows文件路径input_image_path = r'E:\python_workspace\pythonProject\input.jpg'output_image_path = r'E:\python_workspace\pythonProject\output.jpg'try:# 读取图像到bytearrayimage_bytearray = read_image_to_bytearray(input_image_path)# 显示原始图像display_image(input_image_path)# 将bytearray写回到新的图像文件write_bytearray_to_image(image_bytearray, output_image_path)# 显示从bytearray写回的图像,以验证内容是否正确display_image(output_image_path)except Exception as e:print(f"An error occurred: {e}")# 应用5:序列化与反序列化
import struct
def serialize_integers(integers):# 创建一个空的bytearraybyte_data = bytearray()# 将每个整数转换为4字节的二进制数据并添加到bytearray中for integer in integers:# 使用struct来将整数打包为4字节的二进制数据packed_integer = struct.pack('i', integer)byte_data.extend(packed_integer)return byte_data
def deserialize_integers(byte_data):integers = []# 以4字节为单位从bytearray中读取数据,并解包为整数while byte_data:# 使用struct来将4字节的二进制数据解包为整数unpacked_integer = struct.unpack('i', byte_data[:4])[0]integers.append(unpacked_integer)# 移除已处理的4字节数据byte_data = byte_data[4:]return integers
# 主函数
if __name__ == '__main__':# 用于序列化与反序列化整数列表original_integers = [3, 5, 6, 8, 10, 11, 24]# 序列化整数列表为bytearrayserialized_data = serialize_integers(original_integers)print("Serialized bytearray:", serialized_data)# 反序列化bytearray为整数列表deserialized_integers = deserialize_integers(serialized_data)print("Deserialized integers:", deserialized_integers)# 验证反序列化后的数据是否与原始数据相同assert original_integers == deserialized_integersprint("Serialization and deserialization successful!")
# Serialized bytearray: bytearray(b'\x03\x00\x00\x00\x05\x00\x00\x00\x06\x00\x00\x00\x08\x00\x00\x00\n\x00\x00\x00\x0b\x00\x00\x00\x18\x00\x00\x00')
# Deserialized integers: [3, 5, 6, 8, 10, 11, 24]
# Serialization and deserialization successful!# 应用6:加密与解密(注意:运行此程序,需确保已经安装了加密算法库pycryptodome)
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad, unpad
from Crypto.Random import get_random_bytes
def encrypt_data(key, plaintext):# AES加密要求密钥长度为16(AES128)、24(AES192)或32(AES256)字节# 如果密钥长度不足,可以通过某种方式(如哈希函数)扩展它# 这里我们假设key已经是合适的长度cipher = AES.new(key, AES.MODE_CBC)# 对明文进行填充,使其长度为16的倍数padded_plaintext = pad(plaintext, AES.block_size)# 加密填充后的明文ciphertext = cipher.encrypt(padded_plaintext)# 获取初始化向量(IV),它用于CBC模式iv = cipher.iv# 返回IV和密文,通常将它们拼接在一起return iv + ciphertext
def decrypt_data(key, encrypted_data):# 分离IV和密文iv = encrypted_data[:AES.block_size]ciphertext = encrypted_data[AES.block_size:]# 使用相同的IV和密钥创建解密器cipher = AES.new(key, AES.MODE_CBC, iv=iv)# 解密密文decrypted_padded_text = cipher.decrypt(ciphertext)# 去除填充decrypted_text = unpad(decrypted_padded_text, AES.block_size)return decrypted_text
# 主函数
if __name__ == '__main__':key = get_random_bytes(16) # 生成一个随机的16字节AES密钥plaintext = b"I love python very much" # 明文消息,必须是bytes类型# 加密encrypted_data = encrypt_data(key, plaintext)print("Encrypted data:", encrypted_data)# 解密decrypted_text = decrypt_data(key, encrypted_data)print("Decrypted text:", decrypted_text)# 验证解密后的文本是否与原始明文相同assert plaintext == decrypted_textprint("Encryption and decryption successful!")
# Encrypted data: b'\x0f`\xdd\x95\x1bA\x1d.\xc7\x1d\xb6\xa1<60\xbf\xac\x99\x86\x92\x08\xc6@\xa5\x0c\xcc\x96\x00L>\x8f\x95\x03\xc5P\x8d\x11\xd0=\x14\xf6\xa5p\xf8\xc4\x141o'
# Decrypted text: b'I love python very much'
# Encryption and decryption successful!# 应用7:自定义协议
def encode_message(data):# 将数据编码为字节data_bytes = data.encode('utf-8')# 计算消息长度,并转换为4字节的整数表示(如果需要支持更长的消息,应增加字节数)length = len(data_bytes).to_bytes(4, 'big')# 构建完整的消息:消息头(长度)+ 消息体message = bytearray(length) + bytearray(data_bytes)return message
def decode_message(message_bytes):# 检查消息长度是否至少为4字节(消息头长度)if len(message_bytes) < 4:raise ValueError("消息太短,无法包含有效的标头!")# 提取消息头中的长度信息length = int.from_bytes(message_bytes[:4], 'big')# 检查消息体长度是否与头部指定的长度一致if len(message_bytes) != 4 + length:raise ValueError("消息正文长度与标头中指定的长度不匹配!")# 提取消息体data_bytes = message_bytes[4:4 + length]# 将字节解码为字符串data = data_bytes.decode('utf-8')return data
# 主函数
if __name__ == '__main__':# 编码和解码消息original_data = "Hello, Python!"encoded_message = encode_message(original_data)print("Encoded message:", encoded_message)decoded_data = decode_message(encoded_message)print("Decoded data:", decoded_data)# 验证解码后的数据是否与原始数据相同assert original_data == decoded_dataprint("Encoding and decoding successful!")
# Encoded message: bytearray(b'\x00\x00\x00\x0eHello, Python!')
# Decoded data: Hello, Python!
# Encoding and decoding successful!1-2、VBA:
Rem 模拟Python中bytearray函数应用2:内存中的缓冲区(包括初始化、写入数据、读取数据、修改数据、追加数据、切片操作以及清空缓冲区)
Sub TestRun_1()Dim buffer() As ByteDim n As Byte, m As ByteDim first_byte As ByteDim sub_buffer() As ByteDim i As IntegerDim j As Integer' 初始化大小为10的缓冲区(索引从0到9)ReDim buffer(9)' 填充缓冲区的前5个字节For n = 0 To 4buffer(n) = n + 1Next n' 打印缓冲区内容Debug.Print "缓冲区内容:"For i = LBound(buffer) To UBound(buffer)If buffer(i) <> 0 ThenDebug.Print Hex(buffer(i)),End IfNext iDebug.Print' 读取第一个字节first_byte = buffer(0)Debug.Print "第一个字节:", Hex(first_byte)' 修改缓冲区的第4个字节buffer(3) = 6' 打印修改后的缓冲区内容Debug.Print "修改后的缓冲区内容:"For i = LBound(buffer) To UBound(buffer)If buffer(i) <> 0 ThenDebug.Print Hex(buffer(i)),End IfNext iDebug.Print' 在缓冲区末尾追加3个字节ReDim Preserve buffer(UBound(buffer) + 2)buffer(UBound(buffer) - 2) = 7buffer(UBound(buffer) - 1) = 8buffer(UBound(buffer)) = 9Next' 打印追加数据后的缓冲区内容Debug.Print "追加数据后的缓冲区内容:"For i = LBound(buffer) To UBound(buffer)If buffer(i) <> 0 ThenDebug.Print Hex(buffer(i)),End IfNext iDebug.Print' 创建子缓冲区并复制指定范围的数据ReDim sub_buffer(UBound(buffer) - LBound(buffer) - 3)j = 0For i = 2 To 5sub_buffer(j) = buffer(i)j = j + 1Next i' 打印子缓冲区内容Debug.Print "子缓冲区内容:"For i = LBound(sub_buffer) To UBound(sub_buffer)Debug.Print Hex(sub_buffer(i)),Next iDebug.Print' 打印缓冲区大小Debug.Print "缓冲区大小:", UBound(buffer) - LBound(buffer) + 1' 清空缓冲区ReDim buffer(0)' 打印清空后的缓冲区内容(实际上为空,无需循环打印)Debug.Print "清空后的缓冲区内容:"
End Sub
'缓冲区内容:
'1 2 3 4 5
'第一个字节: 1
'修改后的缓冲区内容:
'1 2 3 6 5
'追加数据后的缓冲区内容:
'1 2 3 6 5 7 8 9
'子缓冲区内容:
'3 6 5 0 0 0 0 0 0
'缓冲区大小: 12
'清空后的缓冲区内容:
'注意:1-2中的代码需粘贴到你的VBA编辑器中,按F5执行对应的Sub程序即可输出结果。
2、相关文章:
2-1、Python-VBA函数之旅-all()函数
2-2、Python-VBA函数之旅-any()函数
2-3、Python-VBA函数之旅-ascii()函数
2-4、 Python-VBA函数之旅-bin()函数
Python算法之旅:Algorithm
Python函数之旅:Function
个人主页:非风V非雨-CSDN博客
欢迎志同道合者一起交流学习,我的QQ:94509325/微信:



![[STL-list]介绍、与vector的对比、模拟实现的迭代器问题](https://img-blog.csdnimg.cn/direct/5ab1fa04520c43bf9cb1360c3dba042e.png)