数字化时代,数据是企业最宝贵的资产之一。然而,随着数据量的增长,数据库管理的复杂性也在不断上升。数据库故障可能导致业务中断,给公司带来巨大的财务和声誉损失。在本篇博客中,我们将分享 KaiwuDB 是如何设计故障诊断工具以及具体的示例演示
01 设计思路
遵循核心原则
- 用户友好:即使是具有不同技能水平的用户也能轻松使用我们的工具;
- 全面监控:全面监控数据库系统的各个方面,包括性能指标、系统资源和查询效率;
- 智能诊断:利用先进的算法来识别问题的根本原因;
- 自动化修复:提供一键修复建议,并在可能的情况下,自动应用这些修复;
- 扩展性:允许用户根据他们特定的需求扩展和定制工具功能。
支持关键指标采集
为确保能够提供全面的诊断,工具将对一系列关键指标进行采集,包括但不限于:
- 系统配置:数据库版本、操作系统、CPU 架构和数量、内存容量、磁盘类型和容量、挂载点、文件系统类型;
- 部署情况:是否裸机或容器部署、数据库实例的部署模式和节点数量;数据组织:数据目录的结构、本地与集群配置、系统表和参数;
- 数据库统计:业务数据库数量、各库下的表数量及表结构;
- 列特征:数值列和枚举列的统计特征,字符串列的长度和特殊字符检测;
- 日志文件:关系日志、时序日志、错误日志、审计日志;
- PID 信息:数据库进程打开句柄数、打开 MMAP 数、stat 等信息;
- 性能数据:SQL 执行计划、系统监控数据(CPU、内存、I/O)、索引使用情况和效率、数据访问模式、锁(事务冲突和等待事件)、系统事件等。
支持不同运行模式
工具将提供两种运行模式以满足不同场景需求:
- 一次性采集:快速抓取当前的系统状态和性能数据,适用于即时的问题诊断;
- 定时采集:按照预设的计划周期性地收集数据,用于长期的性能监控和趋势分析。
适配各类趋势分析
收集到的数据将被用于执行趋势分析,能力包括:
- 性能趋势:识别数据库性能随时间的变化趋势,预测潜在的性能瓶颈;
- 资源使用:追踪系统资源使用情况,帮助优化资源分配;
- 日志分析:分析日志文件,识别异常模式和频繁的错误;
- 查询优化:通过分析 SQL 执行计划,提供查询优化建议;
- 最佳实践:通过综合分析数据分布、硬件资源,提供最佳配置建议。
02 整体架构
故障诊断工具分成采集和分析两个部分:
- 采集部分对接目标操作系统/数据库/监控服务器,支持本地规则简化分析,并输出纯文本报告;
- 分析部分读取采集数据格式化后上传到分析服务器持久化,支持在线规则详细分析、预测,通过 UI 输出详细报告。

采集器实现
采集器是运维人员在现场直接使用的工具,通过操作系统、数据库以及监控服务,获取到现场的各项原始信息。默认支持采集后压缩直接导出。也可以使用本地规则做最基本的分析,如 找出并打印所有的 Error 信息。

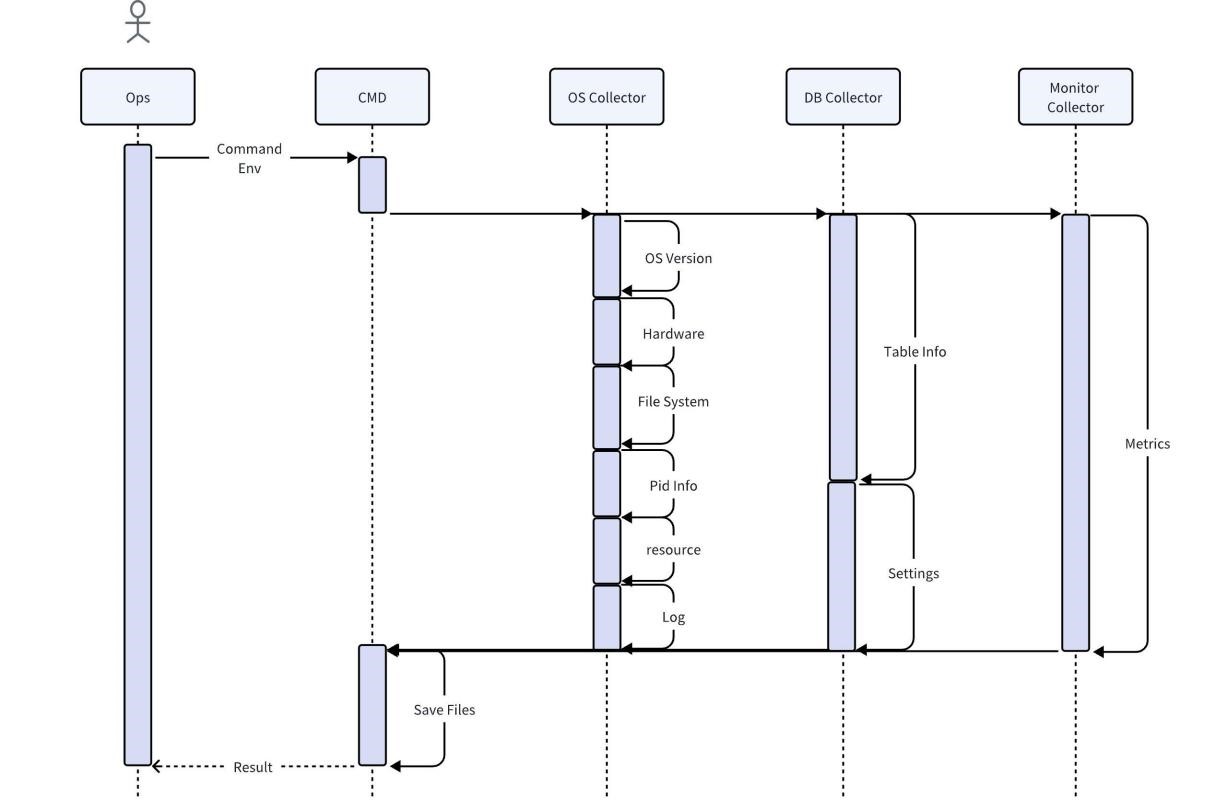
考虑到直接采集用户业务数据可能会导致暴露用户信息的风险,因此在数据库采集器收集过程中,只会抓取用户的数据特征,不进行数据复制。而其他数据为了保证完整性与准确性,在分析之前会对采集数据不进行任何加工、且保持必要的数据,提供完整信息。为节约空间,采集到的数据应被压缩。同时,采集器要兼容大部分操作系统运行且不需要额外的依赖。
规则引擎实现
为了后续的数据分析,规则引擎需要兼容采集器的数据提供标准化数据输出,并具备一定的可扩展能力。如分析特定 SQL 执行时 CPU 使用增高的情况,需要将 SQL 查询的元数据(例如 SQL 文本、执行时间等)与性能指标(例如 CPU 使用率)统一按照时序引擎的格式输出,以便分析性能瓶颈。
为了提供足够的扩展性并且能够覆盖不断扩充的规则集,包括功能性问题比如错误码校验,规则引擎从外部文件中读取规则,然后应用这些规则来分析数据。以下为部分代码示例:
Python
import pandas as pd
import json# 加载规则
def load\_rules(rule\_file): with open(rule_file, 'r') as file: return json.load(file)# 自定义规则函数,这个函数将检查特定SQL执行时CPU使用率是否有显著增加
def sql\_cpu\_bottleneck(row, threshold): # 比较当前行的CPU使用率是否超过阈值 return row\['sql\_query'\] == 'SELECT * FROM table\_name' and row\['cpu_usage'\] > threshold# 应用规则
def apply\_rules(data, rules\_config, custom_rules): for rule in rules_config: data\[rule\['name'\]\] = data.eval(rule\['expression'\])for rule\_name, custom\_rule in custom_rules.items(): data\[rule\_name\] = data.apply(custom\_rule, axis=1) return data# 读取CSV数据
df = pd.read\_csv('sql\_performance_data.csv')# 加载规则
rules\_config = load\_rules('rules.json')# 定义自定义规则
custom_rules = { 'sql\_cpu\_bottleneck': lambda row: sql\_cpu\_bottleneck(row, threshold=80)
}# 应用规则并得到结果
df = apply\_rules(df, rules\_config, custom_rules)# 输出带有规则检查结果的数据
df.to\_csv('evaluated\_sql_performance.csv', index=False)
规则文件应随着版本迭代不断扩展并支持热更新。以下是一个 JSON 格式的规则配置文件示例。规则是以 JSON 对象的形式定义的,每个规则包含一个名称以及一个 Pandas DataFrame 可理解的表达式。
JSON
\[ { "name": "high\_execution\_time", "expression": "execution_time > 5" }, { "name": "general\_high\_cpu_usage", "expression": "cpu_usage > 80" }, { "name": "slow_query", "expression": "query_time > 5" }, { "name": "error\_code\_check", "expression": "error_code not in \[0, 200, 404\]" } // 其他规则可以在此添加
\]
预测实现
诊断工具可对接预测引擎,提前发现潜在风险。如下示例使用 scikit-learn 决策树分类器训练模型,并使用该模型进行预测:
Python
from sklearn.tree import DecisionTreeClassifier
from sklearn.model\_selection import train\_test_split
from sklearn.metrics import accuracy_score# 读取CSV数据
df = pd.read\_csv('performance\_data.csv')# 假设我们已经有了一个标记了性能问题的列 'performance_issue'
# 这个列可以通过规则引擎或历史数据分析得到# 特征和标签
X = df\[\['cpu\_usage', 'disk\_io', 'query_time'\]\]
y = df\['performance_issue'\]# 分割数据集为训练集和测试集
X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42)# 创建决策树模型
model = DecisionTreeClassifier()# 训练模型
model.fit(X\_train, y\_train)# 预测测试集
y\_pred = model.predict(X\_test)# 打印准确率
print(f'Accuracy: {accuracy\_score(y\_test, y_pred)}')# 保存模型,以便以后使用
import joblib
joblib.dump(model, 'performance\_predictor\_model.joblib')# 若要使用模型进行实时预测
def predict\_performance(cpu\_usage, disk\_io, query\_time): model = joblib.load('performance\_predictor\_model.joblib') prediction = model.predict(\[\[cpu\_usage, disk\_io, query_time\]\]) return 'Issue' if prediction\[0\] == 1 else 'No issue'# 示例:使用模型预测一个新的数据点
print(predict_performance(85, 90, 3))
03 示例演示
假设场景:您是一家物联网公司的 IT 专家,发现时序数据库处理设备状态数据的查询响应时间在某些时段非常缓慢, 此时可以如何处理呢?
数据采集
您使用的数据库诊断工具开始收集以下数据:
1、查询日志:发现一个查询,频繁出现,且执行时间远高于其他查询。
Plaintext
SELECT avg(temperature) FROM device_readings
WHERE device_id = ? AND time > now() - interval '1 hour'
GROUP BY time_bucket('5 minutes', time);Plaintext
2、执行计划:该查询的执行计划显示这个 SQL 会进行全表扫描后,再进行 device_id 的过滤。
3、索引使用情况:device_readings 表上的 device_id 没有建立 TAG 索引。
4、资源使用情况:CPU 和 I/O 在执行此查询时达到高峰。
5、锁定和等待事件:没有发现异常的锁定事件。
分析和模式识别
诊断工具通过分析查询和执行计划,识别出以下模式:
- 频繁的全表扫描导致 I/O 和 CPU 负载增加;
- 由于没有适当的索引,查询不能有效地定位数据。
问题诊断
工具使用内置规则,匹配到以下诊断结果:查询效率低下是由于缺乏适当的索引导致的。
建议生成
根据这个模式,诊断工具生成以下建议:在 device_readings 表的 device_id 字段上创建一个 TAG 索引。
执行建议
数据库管理员执行以下 SQL 语句来创建索引:
SQL
ALTER TABLE device\_readings ADD TAG device\_id;
验证结果
索引创建后,数据库诊断工具再次收集数据,并发现:
- 该特定查询的执行时间显著下降;
- CPU 和 I/O 负载在查询执行期间降至正常水平;
- 网站的产品目录页面加载时间恢复正常。
算法说明
在这个例子中,诊断工具会使用以下算法和逻辑:
- 模式识别:检测查询频率和执行时间;
- 关联分析:将长执行时间的查询与执行计划和索引使用情况关联;
- 决策树或规则引擎:如果发现全表扫描且对应字段无索引,则推荐创建索引;
- 性能变化监测:创建索引后,监测性能提升情况确定建议的有效性。




![[StartingPoint][Tier1]Crocodile](https://img-blog.csdnimg.cn/img_convert/6a6e016ae303f164f5fb76e63ec0f07b.jpeg)