yarn集群部署案例
我们来基于一个案例讲解yarn集群部署
我们要部署yarn集群,需要分别部署HDFS文件系统及YARN集群
Hadoop HDFS分布式文件系统,我们会启动:
- NameNode进程作为管理节点
- DataNode进程作为工作节点
- SecondaryNamenode作为辅助
同理,Hadoop YARN分布式资源调度,会启动:
- ResourceManageri进程作为管理节点
- NodeManageri进程作为工作节点
- ProxyServer、JobHistoryServeri这两个辅助节点
集群规划如下:

配置步骤
map reduce配置
- 在$HADOOP_HOME/etc/hadoop文件夹内,修改mapred-env.sh文件,添加如下环境变量,在node1配置
#设置JDK路径
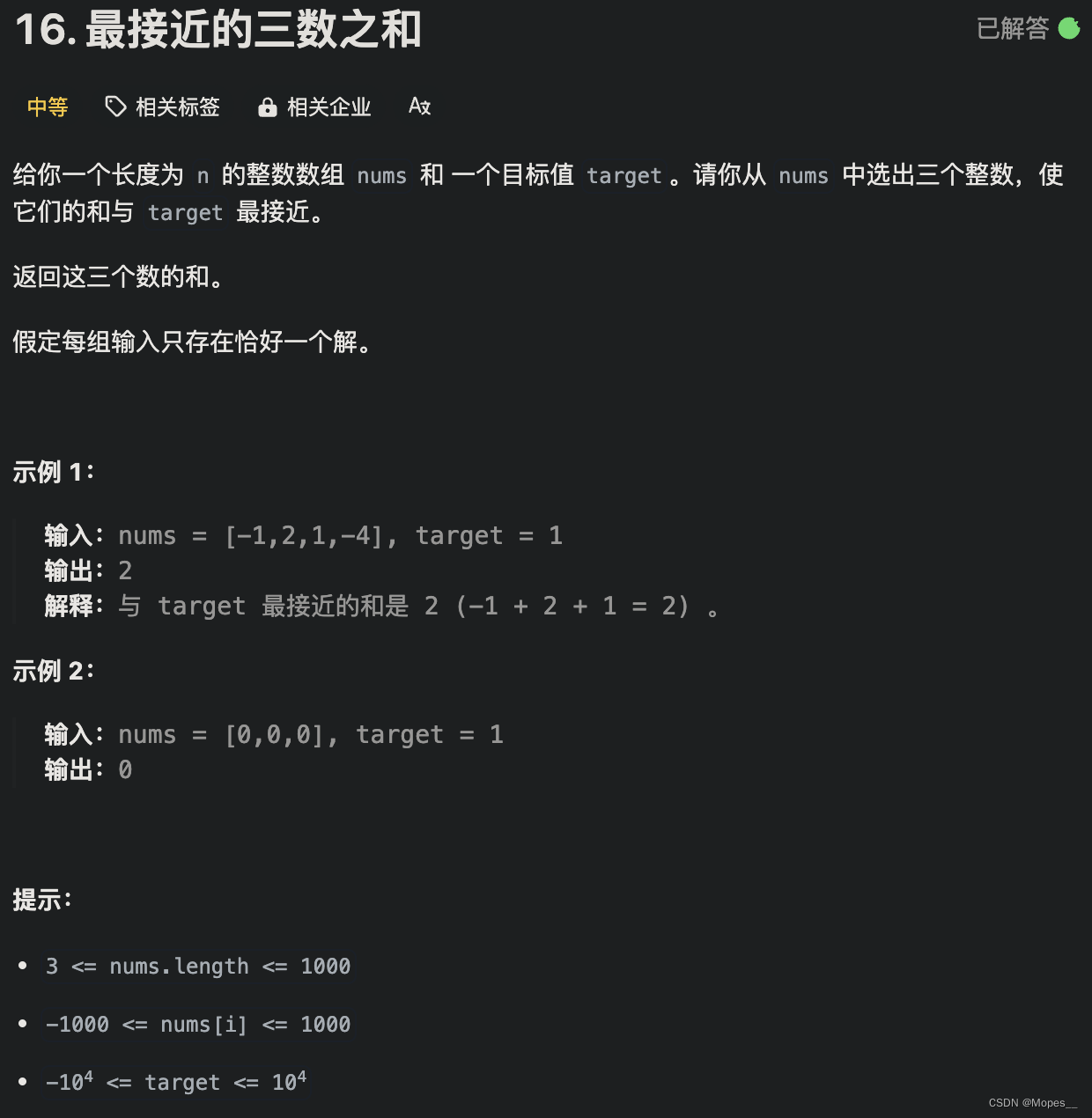
export JAVA_HOME=/export/server/jdk
#设置JobHistoryServer进程内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
#设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
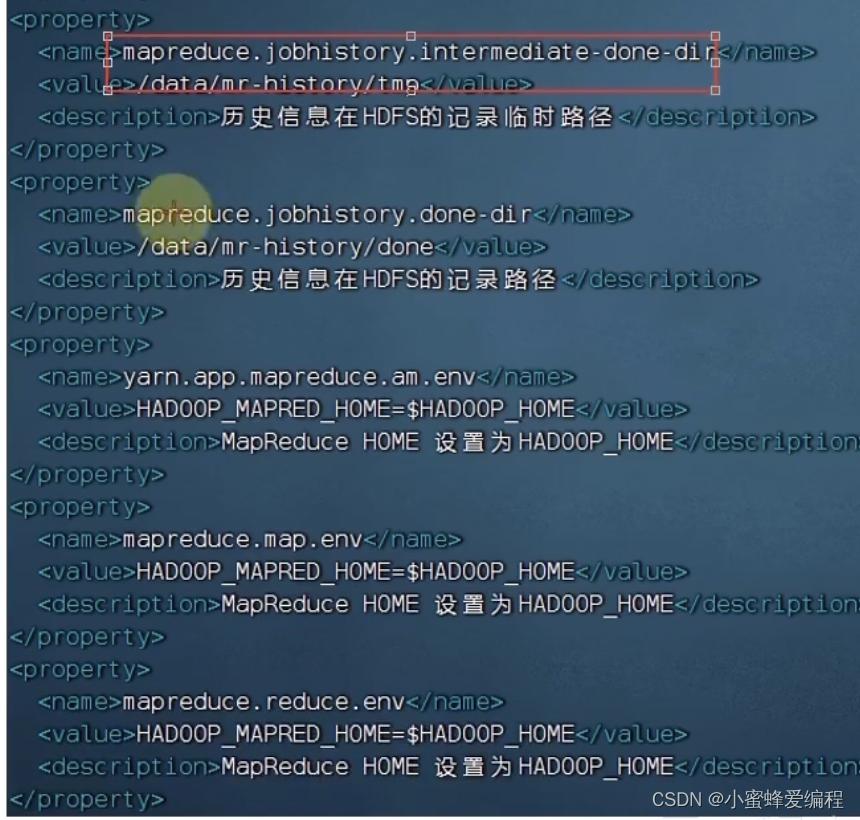
- mapred-site.xml文件,添加如下配置信息,也在node1配置
<property><name>mapreduce.f ramework.name</name><value>yarn</value><description>MapReducel的运行框架设置为YARN</description>
</property><property><name>mapreduce.jobhistory.address</name><value>nodel:10020</value><description>历史服务器通讯端口为node1:10020</description>
</property>
以及一些路径配置
yarn配置
也是在node1配置
- 在${HADOOP_HOME}/etc/hadoop文件夹内,修改yarn-env.sh文件,添加如下4行环境变量内容:
#设置DK路径的环境变量
export JAVA_HOME=/export/server/jdk
#设置HADOOP_HOME的环境变量
export HADOOP_HOME=/export/server/hadoop
#设置配置文件路径的环境变显
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
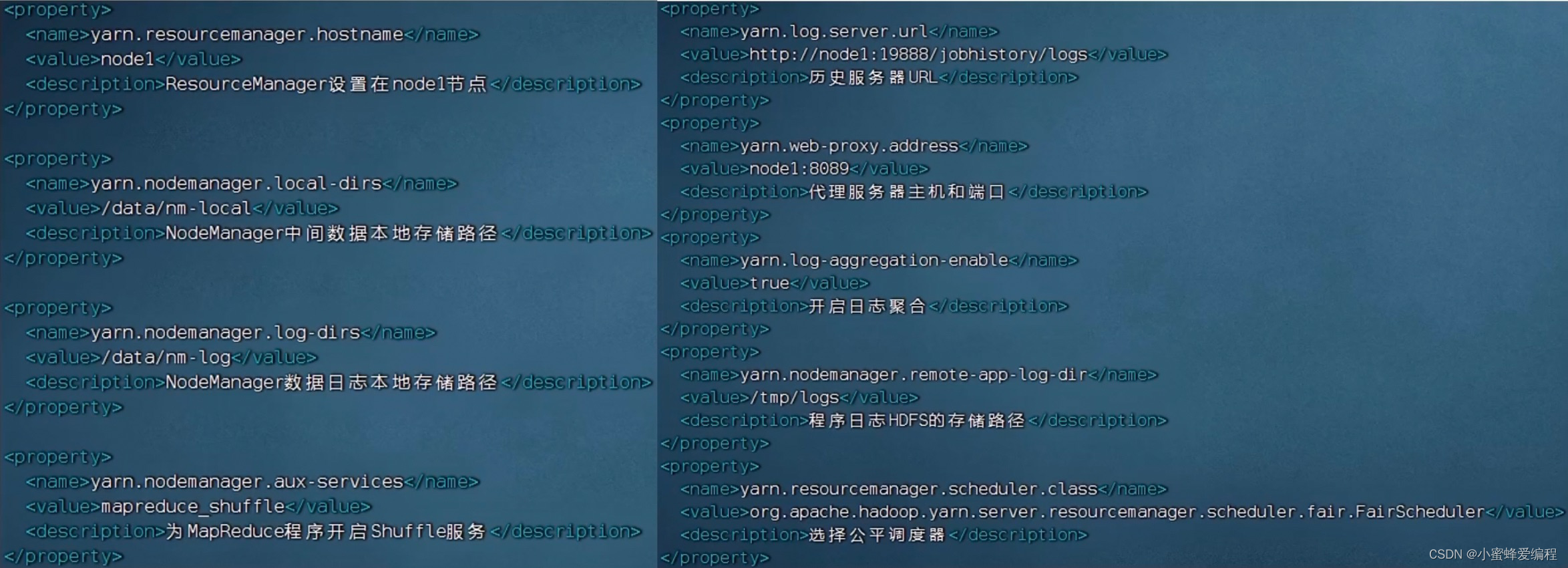
- yarn-site.xml文件,配置如图属性
配置分发
分发配置文件到其他节点
MapReduce和YARN的配置文件修改好后,需要分发到其它的服务器节点中。这里用scp命令
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:`pwd`/
分发完成配置文件,就可以启动YARN的相关进程啦。
常用的进程启动命令
一键启动YARN集群:$HADOOP HOME/sbin/start-yarn.sh
- 会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager
- 会基于workers.文件配置的主机启动NodeManager
一键停止YARN集群:$HADOOP_HOME/sbin/stop-yarn.sh
在当前机器,单独启动或停止进程
$HADOOP_HoME/bin/yarn–daemon start stop resourcemanager nodemanager proxyserver
start和stop决定启动和停止
可控制resourcemanager、nodemanager、proxyserver:三种进程历史服务器启动和停止
$HADOOP_HOME/bin/mapred–daemon start stop historyserver
我们在配置好之后,可以一键启动yarn集群,然后可以打开http://node1:8088即可看到YARN集群的监控页面(ResourceManagerl的WEB UI)
yarn集群的启停
1、一键启停脚本
启动:
$HADOOP_HOMEAsbin/start-yarn.sh
。从yarn-site.xml中读取配置,确定ResourceManager所在机器,并启动它
。读取workers文件,确定机器,启动全部的NodeManager
。在当前机器启动ProxyServer(代理服务器)
关闭
$HADOOP_HOME/sbin/stop-yarn.sh
2、单进程启停
除了一键启停外,也可以单独控制进程的启停。
·SHADOOP_HOME/bin/yarn,此程序也可以用以单独控制所在机器的进程的启停
用法:yarn–daemon(start|stop)(resourcemanager nodemanager proxyserver)
。SHADOOP_HOME/bin/mapred,此程序也可以用以单独控制所在机器的历史服务器的启停
用法:mapred–daemon(start|stop)historyserver