胶囊网络在hinton刚提出来的时候小热过一段时间,之后热度并没有维持多久。vision transformer之后基本少有人问津了。不过这个模型思路挺独特的,值得研究一下。
这个模型的提出是为了解决CNN模型学习到的特征之间没有空间上的关系,从而对于各种变换不鲁棒的缺点。
模型的整体思路如下:
1,胶囊:
抛开论文里花哨的描述,胶囊其实就是特征图上比点更大的单元,本质上我觉得类似transformer的patch。当然也有一定的差别,因为后续要用动态路由更新胶囊,所以胶囊必须要是向量,而不是标量。
2,动态路由:
由于pooling会导致信息丢失,作者使用动态路由来连接两个胶囊层,并更新胶囊。
同时,动态路由也能建立不同层胶囊(特征)在空间上的相对关系。
由于胶囊其实是向量,动态路由算法会根据这些向量的相似性(点积)和一致性(加权)来决定信息传递的路径。
3,整体结构:

1)卷积层
2)PrimaryCaps层:这层的作用就是把卷积特征转变成胶囊的形式
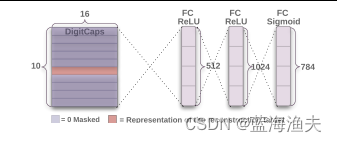
3)DigitCaps层:用动态路由迭代生成高层的胶囊。
4)解码器
4,loss
胶囊网络的损失函数主要由两部分组成:间隔损失(Margin Loss)和重构损失。
在计算间隔损失时,会使用一个阈值(通常设置为0.9和0.1)来区分正样本和负样本。如果某一类的胶囊输出向量的模长大于阈值m+(正样本阈值,例如0.9),则认为该类存在,并将其视为正样本;反之,如果输出向量的模长小于阈值m-(负样本阈值,例如0.1),则认为该类不存在,将其视为负样本。
重构损失的计算通常基于原始输入数据与重构数据之间的差异,例如使用均方误差(MSE)来衡量这种差异。
如果站在2024年的如今再来看当初的设计,其实胶囊的思路还是很像后来的transformer的,有点殊途同归的感觉。
pytorch实现:
1,实现初始胶囊
首先是会用到的压缩函数,压缩函数的作用是将向量的长度压缩到0和1之间,同时保留向量的方向不变。
公式:
![]()
def squash(inputs, axis=-1):norm = torch.norm(inputs, p=2, dim=axis, keepdim=True)scale = norm**2 / (1 + norm**2 + 1e-8) / (norm + 1e-8)return scale * inputs初始胶囊,这一层的作用是将卷积特征转换为胶囊的形式。
class PrimaryCapsule(nn.Module):def __init__(self, in_channels, out_channels, dim_caps, kernel_size, stride=1, padding=0):super(PrimaryCapsule, self).__init__()self.dim_caps = dim_capsself.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding)def forward(self, x):outputs = self.conv2d(x)outputs = outputs.reshape(x.size(0), -1, self.dim_caps)return squash(outputs)2,实现胶囊层
路由算法

这个伪代码初看起来挺乱的,我翻译成人话如下:
首先,每一次迭代由两层胶囊层做点积后再通过softmax计算出耦合系数c。
耦合系数和下层胶囊的预测计算加权和,这是个投票的过程。
再通过压缩函数,就得到了本层的胶囊v。
因为这是个迭代的过程,需要不断更新耦合系数C。
新的耦合系数由两层胶囊之间的相似度决定。
具体实现中,会对低层胶囊先做一个变换,也就是下面代码里的weight。这个权重矩阵代表的是对下层胶囊的变化,变换之后的结果Ui|j用论文里的话说叫做“prediction vectors”。
胶囊层代码:
class DenseCapsule(nn.Module):def __init__(self, in_num_caps, in_dim_caps, out_num_caps, out_dim_caps, routings=3):super(DenseCapsule, self).__init__()self.in_num_caps = in_num_capsself.in_dim_caps = in_dim_capsself.out_num_caps = out_num_capsself.out_dim_caps = out_dim_capsself.routings = routings #路由的迭代次数#初始化self.weight = nn.Parameter(0.01 * torch.randn(out_num_caps, in_num_caps, out_dim_caps, in_dim_caps))def forward(self, x):u_hat = torch.squeeze(torch.matmul(self.weight, x[:, None, :, :, None]), dim=-1)#从当前计算图中分离出x_hat,这样在后续的反向传播中不会计算其梯度 u_hat_detached = u_hat.detach()b = torch.zeros(x.size(0), self.out_num_caps, self.in_num_caps).cuda()#路由算法for i in range(self.routings):c = F.softmax(b, dim=1)if i == self.routings - 1:v = squash(torch.sum(c[:, :, :, None] * u_hat, dim=-2, keepdim=True))else:v = squash(torch.sum(c[:, :, :, None] * u_hat_detached, dim=-2, keepdim=True))b = b + torch.sum(v * u_hat_detached, dim=-1)return torch.squeeze(v, dim=-2)需要将的是u_hat_detached = u_hat.detach()这一步。将u_hat从计算图中分离出来的目的,是为了防止迭代过程中梯度不断累积,导致梯度过大。所以我们可以在后续的路由算法中看出,只有在最后一次计算路由时使用了u_hat,之前的迭代中都是使用的u_hat_detached。从而让整个路由过程中梯度只更新一次。
3,损失函数
def caps_loss(y_true, y_pred, x, x_recon, lambd=0.5):L = y_true * torch.clamp(0.9 - y_pred, min=0.) ** 2 + 0.5 * (1 - y_true) * torch.clamp(y_pred - 0.1, min=0.) ** 2L_margin = L.sum(dim=1).mean()L_recon = nn.MSELoss()(x_recon, x)return L_margin + lambd * L_recon4,整体模型
模型返回两个值,一个是预测的概率,一个是重建的图像。这两个值会分别用来计算间隔损失和重构损失。
class CapsuleNet(nn.Module):def __init__(self, input_size, classes, routings):super(CapsuleNet, self).__init__()self.input_size = input_sizeself.classes = classesself.routings = routingsself.conv1 = nn.Conv2d(input_size[0], 256, kernel_size=9, stride=1, padding=0)self.primarycaps = PrimaryCapsule(256, 256, 8, kernel_size=9, stride=2, padding=0)self.digitcaps = DenseCapsule(in_num_caps=32*6*6, in_dim_caps=8,out_num_caps=classes, out_dim_caps=16, routings=routings)self.decoder = nn.Sequential(nn.Linear(16*classes, 512),nn.ReLU(inplace=True),nn.Linear(512, 1024),nn.ReLU(inplace=True),nn.Linear(1024, input_size[0] * input_size[1] * input_size[2]),nn.Sigmoid())self.relu = nn.ReLU()def forward(self, x, y=None):x = self.relu(self.conv1(x))x = self.primarycaps(x)x = self.digitcaps(x)length = x.norm(dim=-1)if y is None:index = length.max(dim=1)[1]y = torch.zeros(length.size()).scatter_(1, index.view(-1, 1), 1.)reconstruction = self.decoder((x * y[:, :, None]).view(x.size(0), -1))return length, reconstruction.view(-1, *self.input_size)5,注意事项:
1)one-hot
在重建过程中使用的标签y是one-hot形式的,因此在训练和测试时需要加上这行代码,转换一下
targets = F.one_hot(targets, num_classes=classes).to(device)2) loss
训练和测试时的loss设置如下
loss = caps_loss(y_true=targets,y_pred=y_pred,x=imgs,x_recon=x_recon,lambd=0.5)loss = loss.to(device)其中lambd这个系数决定的是重构损失所占的比例 loss=margin_loss+lambd*recon_loss
总结:
胶囊网络分类结果不算差,在我的一些任务中train from scratch的胶囊网络就超越了imagenet1k上预训练过再finetune的vit。也超过了无预训练的VGG和resnet。(但是不如预训练过的vgg和resnet)。
这样的表现放在2017年已经很能打了,没火的原因我感觉有3个:
首先,由于胶囊网络迭代过程需要多次完整的特征图点乘特征图,所以内存消耗和时间消耗都是巨大的。我跑256的图时,24g显存的4090也只能把batch设置成5,运行速度非常慢。放在2017年,只能用1080ti来跑这个模型,简直折磨。(我2018年时也试过这个模型,训练都是按周算的,这谁愿意用啊)
另外一个原因可能是它的改进潜力不大。例如vit的核心机制是自注意力,注意力大家都玩出花来了,各种改进思路都很好借鉴。虽然vit效果很一般,但是后续的改进模型一个比一个厉害。而胶囊网络的核心路由算法想要创新就比较难。
最后还有一点就是原作者没放出胶囊网络在imagenet上的预训练模型。这个对模型热度的影响其实挺大的







![[Kubernetes[K8S]集群:Slaver从节点初始化和Join]:添加到主节点集群内](https://img-blog.csdnimg.cn/direct/b63cead751c246ae89fb3c6c379de941.png)


![[大模型]Qwen1.5-7B-Chat-GPTQ-Int4 部署环境](https://img-blog.csdnimg.cn/direct/b8c9ed143e85437fbbad7832cc8b3b8a.png#pic_center)