摘要
https://arxiv.org/pdf/2403.05246.pdf
UNet及其变体在医学图像分割中得到了广泛应用。然而,这些模型,特别是基于Transformer架构的模型,由于参数众多和计算负载大,使得它们不适合用于移动健康应用。最近,以Mamba为代表的状态空间模型(SSMs)已成为CNN和Transformer架构的有力竞争者。在此基础上,我们采用Mamba作为UNet中CNN和Transformer的轻量级替代方案,旨在解决真实医疗环境中计算资源限制带来的挑战。为此,我们引入了轻量级Mamba UNet(LightM-UNet),将Mamba和UNet集成在一个轻量级框架中。具体来说,LightM-UNet以纯Mamba的方式利用残差视觉Mamba层来提取深层语义特征并建模长距离空间依赖关系,具有线性计算复杂度。我们在两个真实世界的2D/3D数据集上进行了大量实验,结果表明LightM-UNet超越了现有最先进的文献方法。特别是与著名的nnU-Net相比,LightM-UNet在显著提高分割性能的同时,参数和计算成本分别降低了116倍和21倍。这凸显了Mamba在促进模型轻量化方面的潜力。我们的代码实现已公开在https://github.com/MrBlankness/LightM-UNet。
关键词:医学图像分割 · 轻量级模型 · 状态空间模型。
1 简介
UNet [16],作为医学图像分割领域一个广为人知的算法,在涉及医学器官和病灶的各种分割任务中得到了广泛应用,涵盖了多种医学图像模态。其对称的U形编解码器架构与整体的跳跃连接为分割模型奠定了基础,催生了一系列基于U形结构的研究工作 [8,15,18]。然而,作为基于卷积神经网络(CNN)的模型,UNet受限于卷积操作的固有局部性,这限制了其理解显式全局和长距离语义信息交互的能力 [2]。一些研究尝试通过采用空洞卷积层 [5]、自注意力机制 [19] 和图像金字塔 [25] 来缓解这一问题。尽管如此,这些方法在建模长距离依赖关系方面仍然存在限制。
为了赋予UNet理解全局信息的能力,最近的研究 [2,7,6] 致力于将Transformer架构 [22] 集成到UNet中,利用自注意力机制将图像视为连续补丁的序列来捕获全局信息。尽管这种方法有效,但基于Transformer的解决方案由于自注意力机制而引入了与图像大小相关的二次复杂度,导致巨大的计算开销,特别是在需要密集预测的任务中,如医学图像分割。这忽视了真实医疗环境中计算约束的重要性,无法满足移动医疗保健分割任务中对低参数和最小计算负载模型的需求 [18]。综上所述,仍有一个未解决的问题:“如何使UNet具备容纳长距离依赖性的能力,同时不增加额外的参数和计算负担?”

最近,状态空间模型(SSMs)在研究者中引起了广泛关注。在经典SSM研究 [10] 奠定的基础上,现代SSM(例如Mamba [4])不仅建立了长距离依赖关系,还展示了与输入大小相关的线性复杂度,这使得Mamba成为UNet轻量化道路上CNN和Transformer的有力竞争对手。一些当代努力,如U-Mamba [14],提出了一个混合CNN-SSM块,将卷积层提取局部特征的能力与SSM捕捉纵向依赖关系的能力相结合。然而,U-Mamba [14] 引入了大量的参数和计算负载(173.53M参数和18,057.20 GFLOPs),这使其在移动医疗环境中部署医学分割任务时面临挑战。因此,本研究中我们介绍了LightM-UNet,一个基于Mamba的轻量级U形分割模型,它在显著减少参数和计算成本的同时实现了最先进的性能(如图1所示)。这项工作的贡献主要有三个方面:
-
我们介绍了LightM-UNet,一个轻量级的UNet和Mamba的融合模型,其参数数量仅为1M。通过在2D和3D真实世界数据集上的验证,LightM-UNet超越了现有的最先进的模型。与著名的nnU-Net [8] 和同期的UMamba [14] 相比,LightM-UNet的参数数量分别减少了116倍和224倍。
-
在技术层面,我们提出了残差视觉Mamba层(RVM层),以纯Mamba的方式从图像中提取深层特征。通过最小化新参数的引入和计算开销,我们进一步利用残差连接和调整因子增强了SSM在视觉图像中建模长距离空间依赖关系的能力。
-
深入来看,与同期将UNet与Mamba整合的努力[14, 23, 17]不同,我们提倡在UNet内部使用Mamba作为CNN和Transformer的轻量级替代品,旨在解决实际医疗环境中计算资源受限所带来的挑战。据我们所知,这是首次将Mamba引入UNet作为轻量化优化策略的创新尝试。
2、方法论
虽然LightM-UNet支持2D和3D版本的医学图像分割,但为了方便起见,本文使用3D版本的LightM-UNet来描述方法论。
2.1、架构概述
所提出的LightM-UNet的整体架构如图2所示。给定一个输入图像 I ∈ R C × H × W × D I \in \mathbb{R}^{C \times H \times W \times D} I∈RC×H×W×D,其中 C , H , W C, H, W C,H,W 和 D D D 分别表示3D医学图像的通道数、高度、宽度和切片数。LightM-UNet首先使用深度可分离卷积(DWConv)层进行浅层特征提取,生成浅层特征图 F S ∈ R 32 × H × W × D F_{S} \in \mathbb{R}^{32 \times H \times W \times D} FS∈R32×H×W×D,其中32表示固定的滤波器数量。随后,LightM-UNet采用三个连续的编码器块从图像中提取深层特征。在每个编码器块之后,特征图的通道数翻倍,而分辨率减半。
因此,在第 l l l个编码器块,LightM-UNet提取深层特征 F D l ∈ R ( 32 × 2 l ) × ( H / 2 l ) × ( W / 2 l ) × ( D / 2 l ) F_{D}^{l} \in \mathbb{R}^{\left(32 \times 2^{l}\right) \times\left(H / 2^{l}\right) \times\left(W / 2^{l}\right) \times\left(D / 2^{l}\right)} FDl∈R(32×2l)×(H/2l)×(W/2l)×(D/2l),其中 l ∈ { 1 , 2 , 3 } l \in\{1,2,3\} l∈{1,2,3}。随后,LightM-UNet采用瓶颈块(Bottleneck Block)来建模长距离空间依赖关系,同时保持特征图的大小不变。之后,LightM-UNet整合三个连续的解码器块用于特征解码和图像分辨率恢复。在每个解码器块之后,特征图的通道数减半,分辨率加倍。最后,最后一个解码器块的输出与原始图像具有相同的分辨率,并包含32个特征通道。LightM-UNet使用深度可分离卷积层将通道数映射到分割目标的数量,并应用SoftMax激活函数生成图像掩码。与UNet的设计一致,LightM-UNet也采用跳跃连接为解码器提供多级别特征图。
2.2、编码器块
为了最小化参数数量和计算成本,LightM-UNet采用仅包含Mamba结构的编码器块来从图像中提取深层特征。具体来说,给定一个特征图 F l ∈ R C ˇ × H ¨ × W ~ × D ˉ F^{l} \in \mathbb{R}^{\check{C} \times \ddot{H} \times \tilde{W} \times \bar{D}} Fl∈RCˇ×H¨×W~×Dˉ,其中 C ˇ = 32 × 2 l \check{C}=32 \times 2^{l} Cˇ=32×2l, H ¨ = H / 2 l \ddot{H}=H / 2^{l} H¨=H/2l, W ~ = W / 2 l \tilde{W}=W / 2^{l} W~=W/2l, D ˉ = D / 2 l \bar{D}=D / 2^{l} Dˉ=D/2l,且 l ∈ { 1 , 2 , 3 } l \in\{1,2,3\} l∈{1,2,3},编码器块首先将特征图展平并转置为形状为 ( L ˘ , C ˇ ) (\breve{L}, \check{C}) (L˘,Cˇ)的张量,其中 L ˘ = H ¨ × W ~ × D ˉ \breve{L}=\ddot{H} \times \tilde{W} \times \bar{D} L˘=H¨×W~×Dˉ。
随后,编码器块利用 N l N_{l} Nl个连续的RVM层来捕获全局信息,并在最后一个RVM层中增加通道数。之后,编码器块将特征图重新整形并转置为形状为 ( C ˇ × 2 , H ¨ , W ~ , D ˉ ) (\check{C} \times 2, \ddot{H}, \tilde{W}, \bar{D}) (Cˇ×2,H¨,W~,Dˉ)的张量,接着进行最大池化操作以减少特征图的分辨率。最终,第 l l l个编码器块输出具有形状 ( C ˇ × 2 , H ¨ / 2 , W ~ / 2 , D ˉ / 2 ) (\check{C} \times 2, \ddot{H} / 2, \tilde{W} / 2, \bar{D} / 2) (Cˇ×2,H¨/2,W~/2,Dˉ/2)的新特征图 F l + 1 F^{l+1} Fl+1。
残差视觉曼巴层(RVM Layer)。LightM-UNet提出了残差视觉曼巴层(RVM Layer),旨在增强原始的SSM块以用于图像的深层语义特征提取。具体来说,LightM-UNet通过先进的残差连接和调整因子进一步提升了SSM的长距离空间建模能力,同时几乎不引入新的参数和计算复杂度。
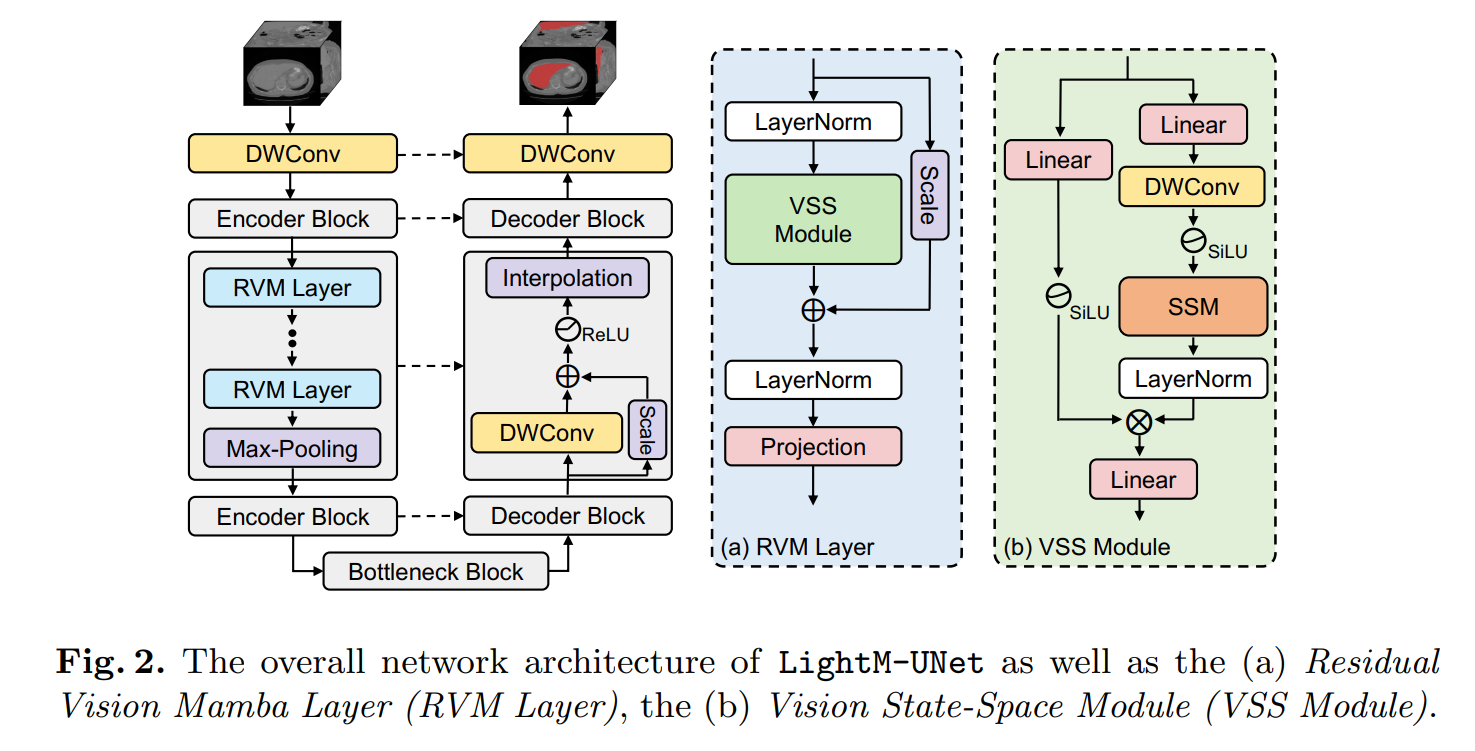
如图2(a)所示,给定输入深层特征 M i n l ∈ R L ˇ × C ˇ M_{i n}^{l} \in \mathbb{R}^{\check{L} \times \check{C}} Minl∈RLˇ×Cˇ,RVM Layer首先应用LayerNorm,然后利用VSSM来捕获空间长距离依赖关系。随后,在残差连接中使用调整因子 s ∈ R C ˇ s \in \mathbb{R}^{\check{C}} s∈RCˇ以提升性能。这一过程可以用数学公式表示如下:
M ~ l = VSSM ( LayerNorm ( M i n l ) ) + s ⋅ M i n l \widetilde{M}^{l}=\operatorname{VSSM}\left(\operatorname{LayerNorm}\left(M_{i n}^{l}\right)\right)+s \cdot M_{i n}^{l} M l=VSSM(LayerNorm(Minl))+s⋅Minl
之后,RVM Layer再次应用LayerNorm对 M ~ l \widetilde{M}^{l} M l进行归一化,并使用一个投影层将 M ~ l \widetilde{M}^{l} M l转换为更深的特征。上述过程可以表述为:
M out l = Projection ( LayerNorm ( M ~ l ) ) M_{\text {out }}^{l}=\operatorname{Projection}\left(\operatorname{LayerNorm}\left(\widetilde{M}^{l}\right)\right) Mout l=Projection(LayerNorm(M l))
视觉状态空间模块(VSS模块)。根据[13]中所述的方法,LightM-UNet引入了视觉状态空间模块(VSS模块,如图2(b)所示),用于进行长距离空间建模。VSS模块将特征 W i n l ∈ R L ˇ × C ˇ W_{i n}^{l} \in \mathbb{R}^{\check{L} \times \check{C}} Winl∈RLˇ×Cˇ作为输入,并将其分为两个并行分支进行处理。
在第一个分支中,VSS模块首先使用线性层将特征通道扩展到 λ × C ˇ \lambda \times \check{C} λ×Cˇ,其中 λ \lambda λ是预定义的通道扩展因子。随后,应用深度可分离卷积(DWConv)、SiLU激活函数[20],再跟随SSM和LayerNorm。在第二个分支中,VSS模块同样使用线性层扩展特征通道到 λ × C ˇ \lambda \times \check{C} λ×Cˇ,然后应用SiLU激活函数。之后,VSS模块使用哈达玛积(Hadamard product)将两个分支的特征进行聚合,并将通道数投影回 C ˇ \check{C} Cˇ,以生成与输入 W i n W_{i n} Win形状相同的输出 W out W_{\text {out }} Wout 。上述过程可以表述为:
W 1 = LayerNorm ( SSM ( SiLU ( DWConv ( Linear ( W in ) ) ) ) ) W 2 = SiLU ( Linear ( W in ) ) W out = Linear ( W 1 ⊙ W 2 ) \begin{array}{c} W_{1}=\operatorname{LayerNorm}\left(\operatorname{SSM}\left(\operatorname{SiLU}\left(\operatorname{DWConv}\left(\operatorname{Linear}\left(W_{\text {in }}\right)\right)\right)\right)\right) \\ W_{2}=\operatorname{SiLU}\left(\operatorname{Linear}\left(W_{\text {in }}\right)\right) \\ W_{\text {out }}=\operatorname{Linear}\left(W_{1} \odot W_{2}\right) \end{array} W1=LayerNorm(SSM(SiLU(DWConv(Linear(Win )))))W2=SiLU(Linear(Win ))Wout =Linear(W1⊙W2)
其中, ⊙ \odot ⊙表示哈达玛积。
2.3、瓶颈块
与Transformer类似,当网络深度过大时,Mamba也会遇到收敛问题[21]。因此,LightM-UNet通过连续使用四个RVM层构建瓶颈块来解决这一问题,以便进一步建模空间长期依赖关系。在这些瓶颈区域中,特征通道数和分辨率保持不变。通过这种设计,LightM-UNet能够在不增加过多计算负担的情况下,提升对图像深层特征的捕捉和提取能力。
2.4、解码器块
LightM-UNet采用解码器块来解码特征图并恢复图像分辨率。具体来说,给定来自跳跃连接的 F D l ∈ R C ˇ × H ˇ × W ˇ × D ˇ F_{D}^{l} \in \mathbb{R}^{\check{C} \times \check{H} \times \check{W} \times \check{D}} FDl∈RCˇ×Hˇ×Wˇ×Dˇ和来自前一块输出的 P i n ∈ R C ˇ × H ˇ × W ˇ × D ˇ P_{i n} \in \mathbb{R}^{\check{C} \times \check{H} \times \check{W} \times \check{D}} Pin∈RCˇ×Hˇ×Wˇ×Dˇ,解码器块首先使用加法操作进行特征融合。随后,它利用深度可分离卷积(DWConv)、残差连接和ReLU激活函数来解码特征图。此外,为了增强解码能力,残差连接中添加了一个调整因子 s ′ s^{\prime} s′。这个过程可以数学表达为:
P out = ReLU ( D W Conv ( P in + F D l ) + s ′ ⋅ ( P in + F D l ) ) P_{\text {out }}=\operatorname{ReLU}\left(D W \operatorname{Conv}\left(P_{\text {in }}+F_{D}^{l}\right)+s^{\prime} \cdot\left(P_{\text {in }}+F_{D}^{l}\right)\right) Pout =ReLU(DWConv(Pin +FDl)+s′⋅(Pin +FDl))
解码器块最终使用双线性插值将预测恢复到原始分辨率。
3、实验
数据集与实验设置。为了评估我们模型的性能,我们选择了两个公开可用的医学图像数据集:包含3D CT图像的LiTs数据集[1]和包含2D X射线图像的Montgomery&Shenzhen数据集[9]。这些数据集在现有的分割研究中得到了广泛应用[12,24],并在此处用于验证LightM-UNet的2D和3D版本的性能。数据被随机划分为训练集、验证集和测试集,比例为7:1:2。
LightM-UNet使用PyTorch框架进行实现,三个编码器块中的RVM层数分别设置为1、2和2。所有实验均在一个Quadro RTX 8000 GPU上进行。我们采用SGD作为优化器,初始学习率设为1e-4。调度器使用的是PolyLRScheduler,共训练了100个周期。此外,损失函数被设计为交叉熵损失和Dice损失的简单组合。
对于LiTs数据集,我们将图像归一化并调整大小为128×128×128,批次大小为2。对于Montgomery&Shenzhen数据集[9],图像被归一化并调整至512×512,批次大小为12。
为了评估LightM-UNet的性能,我们将其与两种基于CNN的分割网络(nnU-Net[8]和SegResNet[15])、两种基于Transformer的网络(UNETR[7]和SwinUNETR[6])以及一种基于Mamba的网络(U-Mamba[14])进行了比较。这些网络在医学图像分割竞赛中常用。此外,我们采用了平均交并比(mIoU)和Dice相似度分数(DSC)作为评估指标。
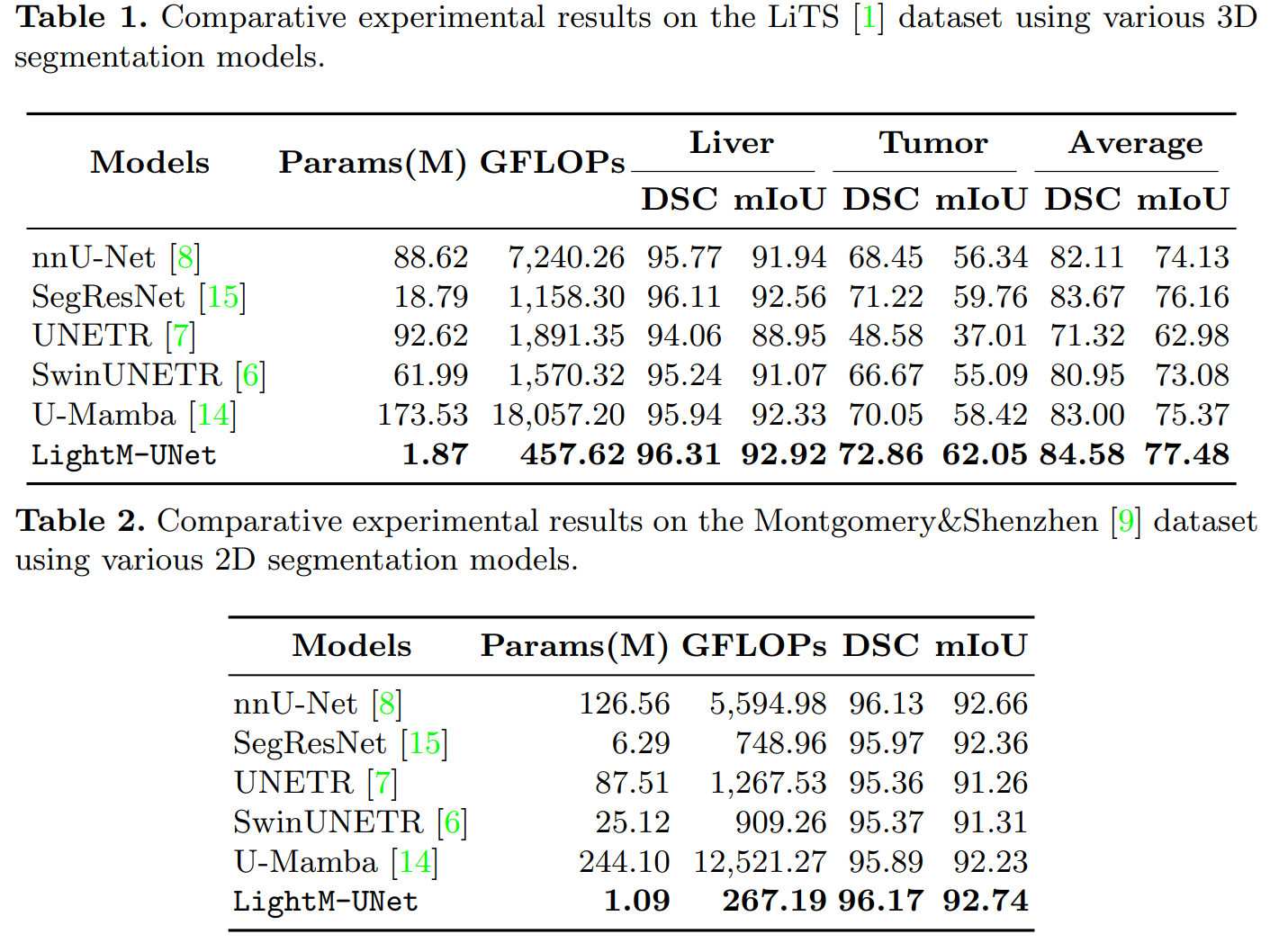
比较结果。表1中呈现的比较实验结果表明,我们的LightM-UNet在LiTS数据集[11]上实现了全面的最先进性能。值得注意的是,与像nnU-Net这样的大型模型相比,LightM-UNet不仅表现出优越的性能,而且参数数量和计算成本分别降低了47.39倍和15.82倍。与同时期的U-Mamba[14]相比,LightM-UNet在平均mIoU方面提高了2.11%。特别是对于常常太小而难以检测到的肿瘤,LightM-UNet实现了3.63%的mIoU提升。重要的是,作为将Mamba融入UNet架构的方法,LightM-UNet相比U-Mamba[14]仅使用了少1.07%的参数和少2.53%的计算资源。
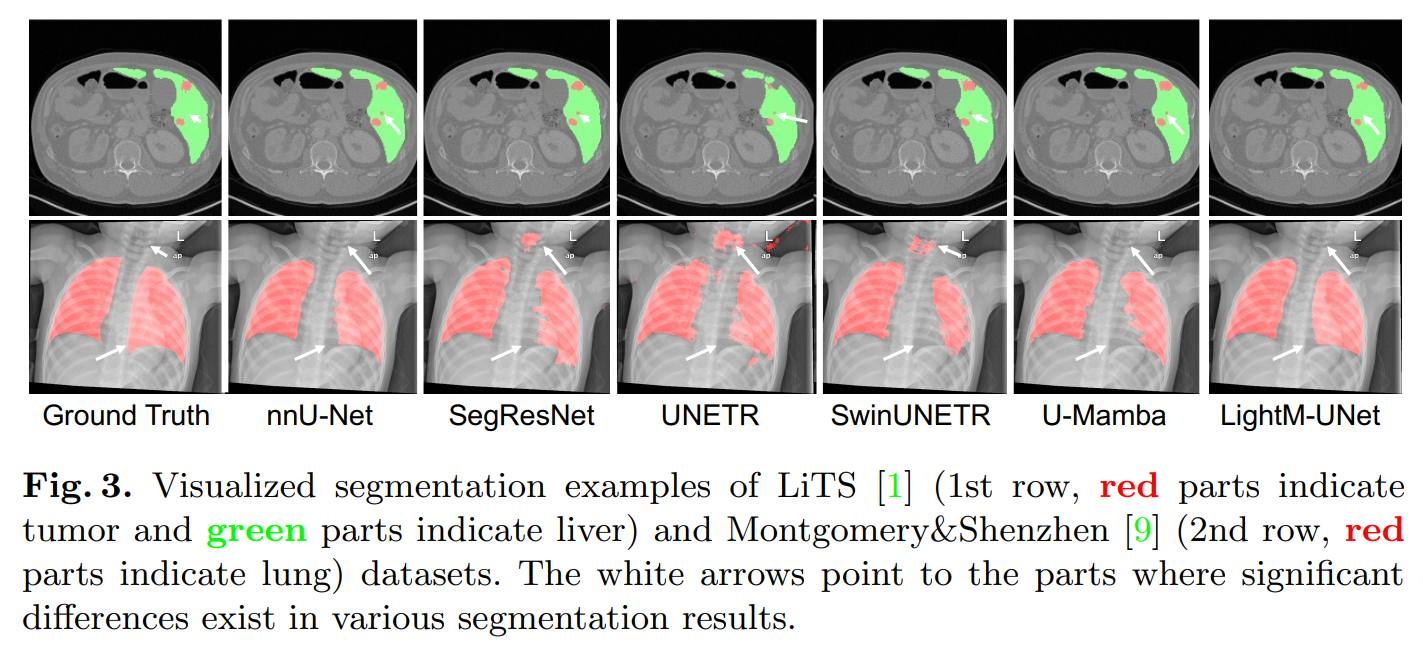
Montgomery&Shenzhen数据集[9]的实验结果总结在表2中。LightM-UNet再次取得了最优性能,并显著超越了其他基于Transformer和Mamba的文献。此外,LightM-UNet以极低的参数计数脱颖而出,仅使用了1.09M参数。这相比nnU-Net[8]和U-Mamba[14]分别减少了99.14%和99.55%的参数。为了更清楚地展示实验结果,请参考图1。图3展示了分割结果示例,说明与其他模型相比,LightM-UNet具有更平滑的分割边缘,并且不会对小物体(如肿瘤)产生错误识别。
消融实验结果。我们进行了广泛的消融实验来验证我们提出模块的有效性。首先,我们在UNet框架内分析了CNN、Transformer和Mamba的性能。具体来说,我们将LightM-UNet中的VSS模块替换为具有3×3内核的卷积操作以代表CNN,并替换为自注意力机制以代表Transformer。考虑到内存限制,对于CNN,我们替换了LightM-UNet中的所有VSS模块;而对于Transformer,我们遵循TransUNet[2]的设计,仅替换了Bottleneck块中的VSS模块。LiTS数据集[1]上的实验结果如表3所示,表明无论是用卷积还是自注意力替换VSSM都会导致性能下降。此外,卷积和自注意力还引入了大量的参数和计算开销。进一步观察发现,基于Transformer和基于VSSM的结果均优于基于卷积的结果,这证明了建模长程依赖性的好处。
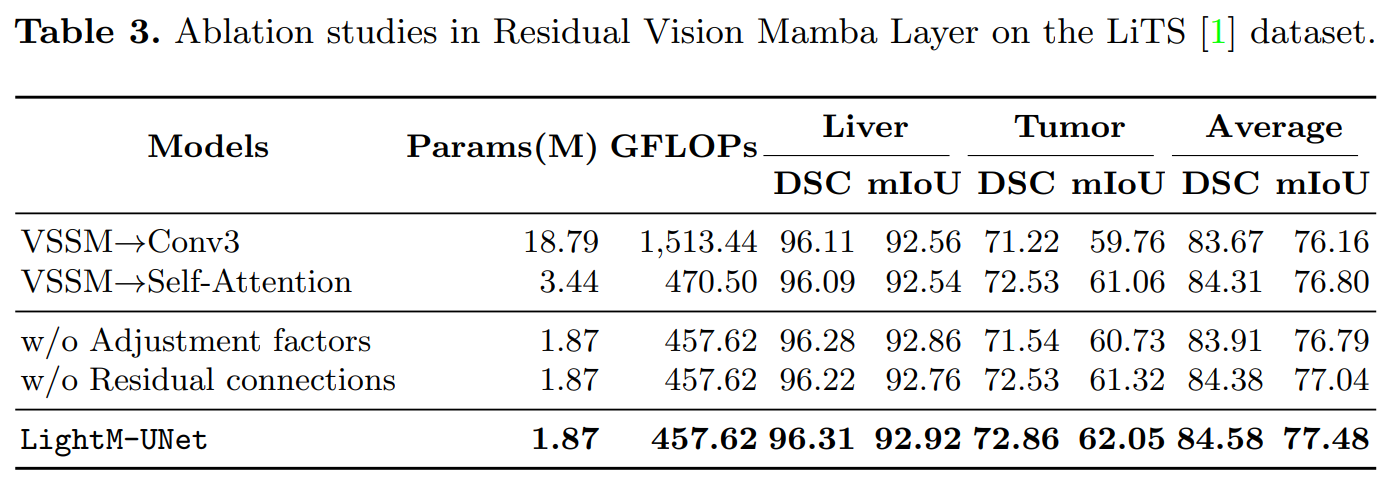
我们进一步移除了RVM层中的调整因子和残差连接。实验结果表明,移除这两个组件后,模型的参数数量和计算开销几乎没有减少,但模型性能却显著下降(mIoU下降了0.44%和0.69%)。这验证了我们的基本原则,即在不增加额外参数和计算开销的情况下提升模型性能。关于Montgomery&Shenzhen数据集[9]的额外消融分析,请参见补充材料。
4、结论
本研究中,我们介绍了LightM-UNet,这是一个基于Mamba的轻量级网络。它在2D和3D分割任务中都取得了最先进的性能,同时仅包含约1M参数,相比最新的基于Transformer的架构,参数减少了99%以上,GFLOPS也显著降低。我们通过一个统一的框架进行了严格的消融研究,验证了我们的方法,这是首次尝试将Mamba作为UNet的轻量级策略。未来的工作将包括设计更轻量级的网络,并在多个器官的更多数据集上进行验证,以促进它们在移动医疗和其他领域的应用。