GPT建模实战:GPT建模与预测实战-CSDN博客
OpenAI的GPT(Generative Pre-trained Transformer)系列模型是自然语言处理领域的重要里程碑。从2018年至2020年,该公司相继推出了GPT-1、GPT-2和GPT-3,这些模型在文本生成和理解方面表现出了强大的能力。
GPT-1发布于2018年6月,它是基于约5GB的文本数据进行训练的,模型参数量为1.17亿。尽管参数量相对较少,但GPT-1已经展示出了强大的自然语言生成和理解能力。
仅仅几个月后,OpenAI在2019年2月推出了GPT-2。与GPT-1相比,GPT-2的训练数据量大幅增加,达到了约40GB,并且模型参数量也增加到了15亿。这使得GPT-2在自然语言处理任务中的性能得到了显著提升。
到了2020年5月,OpenAI进一步推出了GPT-3,这是一个划时代的模型。GPT-3的训练数据量达到了惊人的45TB,并且模型参数量也激增到了1750亿。这使得GPT-3在文本生成、语言理解、对话系统等多个方面都取得了前所未有的突破。
1.GPT-1
GPT,全称为“Generative Pre-Training”,代表生成式的预训练模型,是自然语言处理领域的重要技术之一。2018年,NLP领域竞争激烈,BERT和GPT是其中的佼佼者。尽管两者都很强大,但GPT因其需要预测未来的词,训练难度相对更大。BERT擅长通过完型填空理解上下文,适合文本分类和实体识别;值得一提的是,GPT作为自回归模型,专注于通过预测未来的词来生成文本,适合文本生成等任务。
那么什么叫做自回归模型呢?
例子:
英文原句:The weather is beautiful today.
当我们把这句英文输入到自回归的翻译模型中时,模型会按照以下步骤进行翻译:
-
开始符号:模型首先处理一个特殊的开始符号(比如
<BOS>,表示Beginning Of Sentence),这告诉模型它要开始生成一个句子了。 -
逐个词生成:模型首先会预测第一个词。根据英文原句和模型之前学习到的语言模式,它可能会预测出“今天”作为中文翻译的第一个词。
-
迭代预测:接下来,模型会将“今天”作为上下文,并预测下一个词。继续这个过程,模型可能会预测出“天气”作为第二个词。
-
继续生成:模型继续以之前生成的词为上下文,预测下一个词,直到生成完整的中文句子。在这个例子中,完整的翻译可能是“今天天气很好”。
-
结束符号:模型在生成完整个句子后,会预测一个特殊的结束符号(比如
<EOS>,表示End Of Sentence),标志着翻译的完成。
在这个过程中,自回归模型利用了之前生成的词作为上下文来预测下一个词,逐步构建出完整的翻译结果。这种逐个词生成的方式是自回归模型的核心特点,使得模型能够处理变长的文本序列,并生成自然流畅的翻译。
(1)网络结构
Bert与GPT整体的网络结构都是采用Transformer,但是由于Bert有上下文,其网络结构类似于Transformer的编码器,而GPT需要根据前文进行预测,其网络结构相当于Transformer的解码器。其损失函数就是预测下一个词的损失。

(2)GPT-1的缺陷
GPT-1的缺陷在于,所有下游任务都需要微调,这会带来巨大的成本,且模型的应用场景也有限。
2.GPT-2
GPT-2 是一个强大的生成式预训练模型,而 “zero-shot” 指的是模型在没有针对特定任务进行训练或微调的情况下,仅通过给定的提示或上下文来执行任务的能力。这种方法利用了模型在预训练阶段学习到的广泛知识和推理能力
在传统的机器学习方法中,通常需要为每个下游任务收集标注数据并进行训练或微调。然而,GPT-2 等大型预训练模型的出现改变了这一范式。这些模型在海量无标注数据上进行预训练,学习到了丰富的语言知识和推理能力,使得它们能够在不经过额外训练的情况下处理多种下游任务。
当面对一个新的下游任务时,我们可以通过为模型提供适当的提示或上下文来“暗示”它需要完成的任务。例如,如果我们想让 GPT-2 完成一个文本分类任务,我们可以在输入文本后添加一个描述分类目标的提示,如“请判断这段文本的情感倾向是正面还是负面”。由于 GPT-2 在预训练阶段已经学习到了大量的语言知识和推理模式,它能够根据这些提示理解任务需求,并生成相应的输出。
这种方法的优势在于无需为每个下游任务收集标注数据和进行训练,大大降低了任务的成本和复杂度。同时,由于模型在预训练阶段已经学习到了丰富的知识,它在处理下游任务时能够表现出色。
(1)采样策略
自回归模型在文本生成时,有时可能会陷入重复的模式,如连续输出相同的词汇或短语,导致生成的文本缺乏多样性。如:成语接龙:一一得一,一一得一,一一得一,一一得一,一一得一。为了避免这种情况,需要采取一些采样策略来增加生成的多样性和减少重复。
一种常见的策略是温度采样,通过调整概率分布来增加低概率词的选择机会,从而提高输出的多样性。此外,还有Top-K采样和Top-p(Nucleus)采样等方法,它们通过选择概率较高的词汇集合,并从中随机采样,以在保持文本质量的同时增加多样性。
温度采样
温度就是说对预测结果进行概率重新设计,默认温度为1就相当于直接使用softmax,温度越高相当于多样性越丰富(雨露均沾),温度越低相当于越希望得到最准的那个。
其实现方式相当于向量在进入softmax之前,同时除以一个温度

Top-K和Top-P
Top-K和Top-P是两种常用的采样策略,用于在文本生成等任务中控制模型的输出,确保生成的结果既合理又具有多样性。
Top-K采样:
- 在Top-K采样中,模型会预测下一个可能的词的概率分布,然后选择概率最高的K个词作为候选词。例如,如果设定K为10,那么模型就只会从概率最高的10个词中进行选择。
Top-P(Nucleus)采样:
- Top-P采样则是一种更为灵活的采样方式。它不是选择固定数量的最高概率词,而是选择一个概率阈值P(比如0.9或0.95),然后累加概率直到达到或超过这个阈值。
Top-K和Top-P采样都是为了剔除那些特别离谱的结果,确保模型生成的文本既合理又具有多样性。在实际应用中,可以根据具体需求和场景来选择适合的采样策略。
3.GPT-3
由于GPT-3庞大的规模和在大量文本数据上的预训练,GPT-3 能够在不进行特定任务微调的情况下,通过提供适当的提示(prompts)来执行多种自然语言处理任务。这种能力被称为“零样本学习”或“少样本学习”,它使得 GPT-3 在很多应用中都非常灵活和强大。
有3种核心的下游任务方式:
- zero shot,完全不提供示例
- one shot,提供1个示例
- few shot,提供少量示例
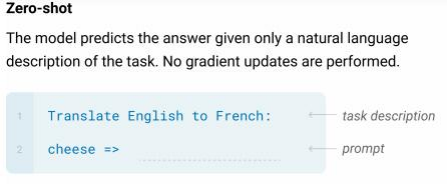


当然,给的示例越多,效果越好

(1)准备数据
在准备用于训练或微调GPT3模型的数据集时,同样需要关注数据的规模和质量。GPT3作为一个大规模预训练语言模型,对数据的要求更为严格,以确保其能够充分理解和学习语言的复杂模式和上下文关系。
首先,数据集需要足够大,因为GPT3模型具有庞大的参数数量,需要大量的数据来充分训练和优化。通过收集大量的文本数据,可以帮助模型更好地学习和生成自然、连贯的语言。
其次,数据的清洁和质量判断也是关键步骤。由于GPT3对文本的理解和生成能力非常强大,因此任何错误或低质量的文本都可能对模型产生负面影响。在准备数据时,需要对爬取的网页或其他文本来源进行质量评估和清洗,以确保数据的准确性和可靠性。
针对网页数据的准备,可能需要利用自然语言处理和机器学习技术对网页进行分类和筛选。通过构建分类器来判断网页的质量和内容相关性,从而剔除重要性低或质量差的网页。这一步骤对于提高GPT3模型的性能至关重要。
此外,如果之前有过类似的训练数据或前几代版本的GPT模型数据,可以将这些数据与新收集的数据进行整合。通过结合历史数据,可以帮助GPT3模型更好地学习和理解语言的演变和变化。
最后,在数据准备完成后,就可以开始进行GPT3模型的训练或微调了。通过充分利用高质量、大规模的数据集,可以训练出更加准确、流畅的语言模型,为用户提供更好的语言生成和理解体验。
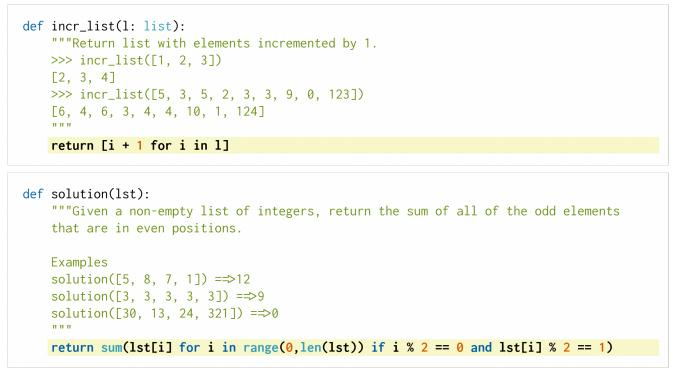
(2)evaluating Large Language Models Trained on Code
使用GPT-3在github的代码上信息重新训练,将GPT-3应用于代码生成领域。
OpenAI Codex

4.chat gpt
(1)GPT系列的问题
GPT前三代版本的文本生成模型遇到的问题是,文本生成的内容可能无法满足人的需求。同时也面临一个困境,即GPT如何不仅仅是文本生成模型,具备人的逻辑?
(2)有监督学习
这时候,我们就需要有监督学习了,即使用有监督数据对具备强大特征表示的预训练模型进行微调。需要说明的是,有监督学习优先是学习敏感的话题的回答。

(3)强化模型
在有监督模型中,预测对就是对,错就是错,但是对于生成的文本来说,我们真的能够轻易的判断对错吗?
而强化学习只是对生成的文本进行评判,即评判生成文本的满意程度。
奖励模型
首先,使用人工标注得到的各种预测结果,然后使用标注数据进行训练。
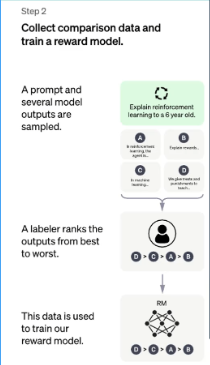
此时,损失约束的是让得分预测高的和得分预测低的差异足够大。
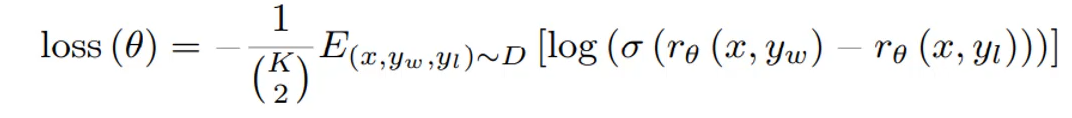
需要说明的是,这里使用的gpt是经过蒸馏的6亿参数版本的GPT。
强化学习更新参数
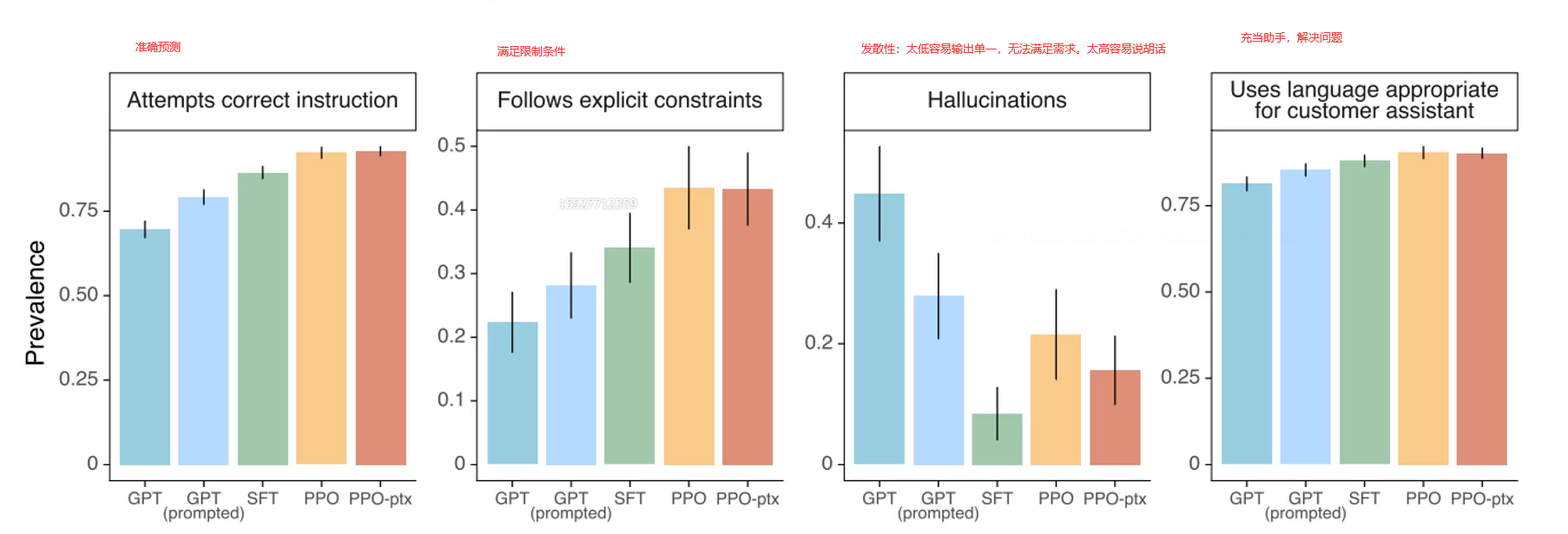
首先,使用强化模型PPO更新模型参数,此时既要更新GPT的参数,又要更新奖励模型的参数。即使二者互相提升,互相促进。

损失函数如下:损失函数不仅考虑了预测结果,还考虑的模型的泛化能力

整体思想与一篇论文很相似:Learning to summarize from human feedback

多个维度效果都有提升